
- Papers
Papers is Alpha. This content is part of an effort to make research more accessible, and (most likely) has lost some details from the original. You can find the original paper here.
Introduction
Artificial intelligence (AI) has had and will continue to have a central role in countless aspects of life, livelihood, and liberty. AI is bringing forth a sea-change that is not only limited to technical domains, but is a truly sociotechnical phenomenon affecting healthcare, education, commerce, finance, and criminal justice, not to mention day-to-day life. AI offers both promise and perils. A report published by Martha Lane Fox’s Doteveryone think tankreveals that 59% of tech workers have worked on products they felt harmful to society, and more than 25% of workers in AI who had such an experience quit their jobs as a result. This was particularly marked in relation to AI products. The rise of activism – which has been regarded as one of the current few mechanisms to keep big tech companies in check– against negative social impacts of big tech have brought Social Responsibility of AI into the spotlight of the media, the general public, and AI technologists and researchers. Even researchers in universities and research institutes are trying hard to rectify the mistakes made by algorithms. Stanford’s COVID-19 vaccine allocation algorithm, for example, prioritizes older employees over front-line workers, turning much of our attention again to the transparency and fairness of AI.
Research directed towards developing fair, transparent, accountable, and ethical AI algorithms has burgeoned with a focus on decision-making algorithms such as scoring or classification to mitigate unwanted bias and achieve fairness. However, this narrow subset of research risks blinding us to the challenges and opportunities that are presented by the full scope of AI. To identify potential higher-order effects on safety, privacy, and society at large, it is critical to think beyond algorithmic bias, to capture all the connections among different aspects related to AI algorithms. Therefore, this survey complements prior work through a holistic understanding of the relations between AI systems and humans. In this work, we begin by introducing an inclusive definition of Social Responsibility of AI . Drawing on theories in business research, we then present a pyramid of Social Responsibility of AI that outlines four specific AI responsibilities in a hierarchy. This is adapted from the pyramid proposed for Corporate Social Responsibility (CSR) by carroll1991pyramid. In the second part of the survey, we review major aspects of AI algorithms and provide a systematic framework – Socially Responsible AI Algorithms (SRAs) – that aims to understand the connections among these aspects. In particular, we examine the subjects and causes of socially indifferent AI algorithms[We define “indifferent” as the complement of responsible rather than “irresponsible”.], define the objectives , and introduce the means by which we can achieve SRAs. We further discuss how to leverage SRAs to improve daily life of human beings and address challenging societal issues through protecting, informing , and preventing/mitigating . We illustrate these ideas using recent studies on several emerging societal challenges. The survey concludes with open problems and challenges in SRAs.
Differences from Existing Surveys. Some recent surveys focus on specific topics such as bias and fairness, interpretability/explainability, and privacy-preservation. These surveys successfully draw great attention to the social responsibility of AI, leading to further developments in this important line of research. However, as indispensable components of socially responsible AI, these topics have been presented in their own self-contained ways. These works pave the way for looking at socially responsible AI holistically. Therefore, our survey aims to frame socially responsible AI with a more systematic view that goes beyond discussion of each independent line of research. We summarize our contributions as follows:
- We formally define social responsibility of AI with three specified dimensions: principles, means , and objectives . We then propose the pyramid of social responsibility of AI, describing its four fundamental responsibilities: functional, legal, ethical , and philanthropic responsibilities. The pyramid embraces the entire range of AI responsibilities involving efforts from various disciplines.
- We propose a systematic framework that discusses the essentials of socially responsible AI algorithms (SRAs) – including its subjects, causes, means , and objectives – and the roles of SRAs in protecting, informing users, and preventing them from negative impact of AI. This framework subsumes existing topics such as fairness and interpretability.
- We look beyond prior research in socially responsible AI and identify an extensive list of open problems and challenges, ranging from understanding why we need AI systems to showing the need to define new AI ethics principles and policies. We hope our discussions can spark future research on SRAs.
Intended Audience and Paper Organization. This survey is intended for AI researchers, AI technologists, researchers, and practitioners from other disciplines who would like to contribute to making AI more socially responsible with their expertise. The rest of the survey is organized as follows: Section 2 introduces the definition and the pyramid of social responsibility of AI, and compares definitions of similar concepts. Section 3 discusses the framework of socially responsible algorithms and its essentials, followed by Section 4 that illustrates the roles of SRAs using several emerging societal issues as examples. Section 5 details the open problems and challenges that socially responsible AI currently confronts. The last section concludes the survey.
Social Responsibility of AI
Social Responsibility of AI includes efforts devoted to addressing both technical and societal issues. While similar concepts (e.g., “Ethical AI”) repeatedly appear in the news, magazines, and scientific articles, “Social Responsibility of AI” has yet to be properly defined. In this section, we first attempt to provide an inclusive definition and then propose the Pyramid of Social Responsibility of AI to outline the various responsibilities of AI in a hierarchy: functional responsibilities, legal responsibilities, ethical responsibilities, and philanthropic responsibilities. At last, we compare “Socially Responsible AI” with similar concepts.
What is Social Responsibility of AI?
Social Responsibility of AI refers to a human value-driven process where values such as Fairness, Transparency, Accountability, Reliability and Safety, Privacy and Security, and Inclusiveness are the principles; designing Socially Responsible AI Algorithms is the means; and addressing the social expectations of generating shared value – enhancing both AI’s ability and benefits to society – is the main objective.
Here, we define three dimensions of Social Responsibility of AI: the principles lay the foundations for ethical AI systems; the means to reach the overarching goal of Social Responsibility of AI is to develop Socially Responsible AI Algorithms; and the objective of Social Responsibility of AI is to improve both AI’s capability and humanity with the second being the proactive goal.
The Pyramid of Social Responsibility of AI
Social Responsibility of AI should be framed in such a way that the entire range of AI responsibilities are embraced. Adapting Carroll’s Pyramid of CSRin the AI context, we suggest four kinds of social responsibilities that constitute the Social Responsibility of AI: functional, legal, ethical, and philanthropic responsibilities, as shown in Figure pyramid. By modularizing AI responsibilities, we hope to help AI technologists and researchers to reconcile these obligations and simultaneously fulfill all the components in the pyramid. All of these responsibilities have always existed, but functional responsibilities have been the main consideration until recently. Each type of responsibility requires close consideration.
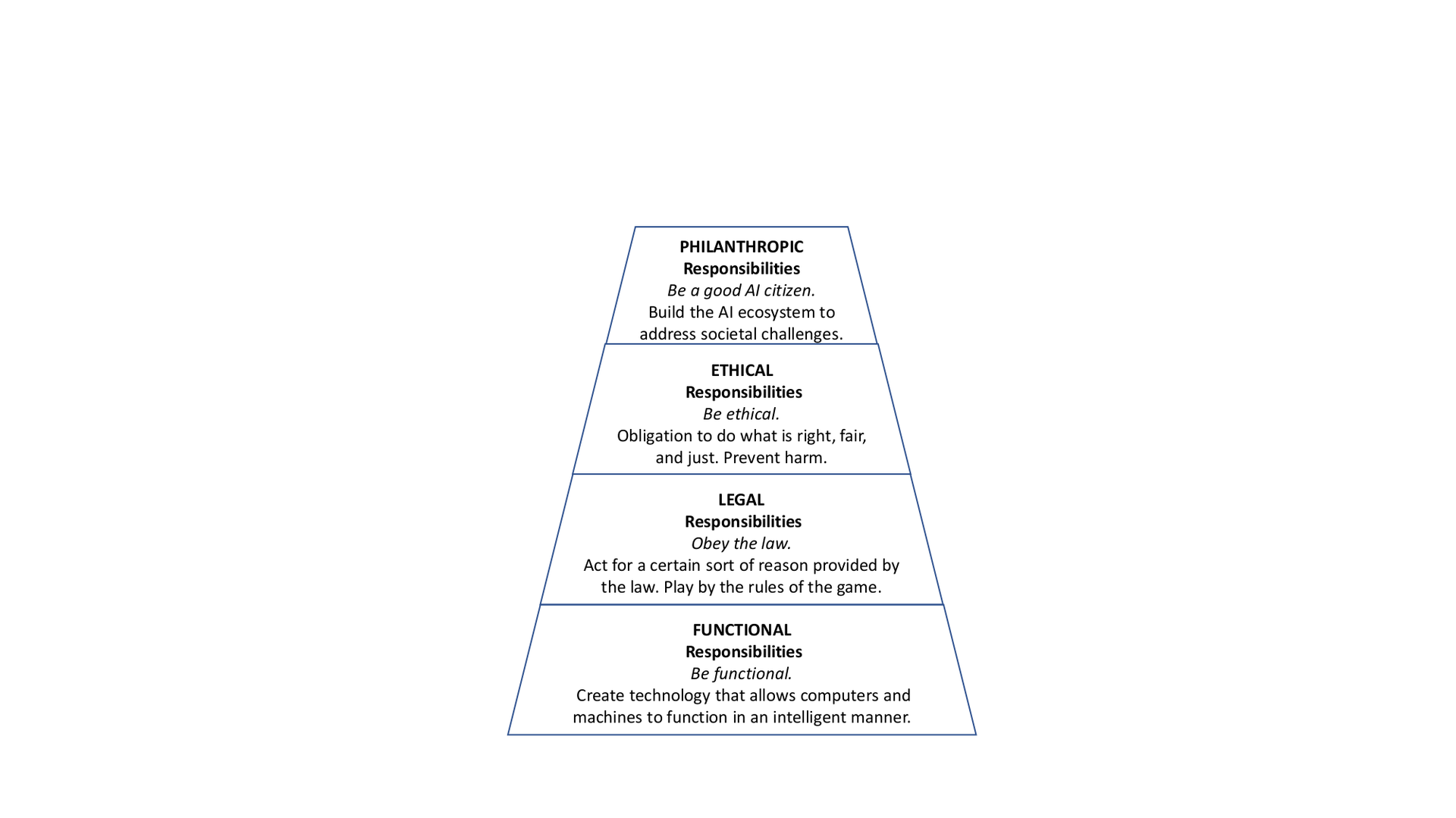
The pyramid portrays the four components of Social Responsibility of AI, beginning with the basic building block notion that the functional competence of AI undergirds all elseFunctional responsibilities_ require AI systems to perform in a manner consistent with profits maximization, operating efficiency, and other key performance indicators. Meanwhile, AI is expected to obey the law, which codifies the acceptable and unacceptable behaviors in our society. That is, legal responsibilities require AI systems to perform in a manner consistent with expectations of government and law. All AI systems should at least meet the minimal legal requirements. At its most fundamental level, ethical responsibilities are the obligation to do what is right, just, and fair, and to prevent or mitigate negative impact on stakeholders (e.g., users, the environment). To fulfill its ethical responsibilities, AI systems need to perform in a manner consistent with societal expectations and ethical norms, which cannot be compromised in order to achieve AI’s functional responsibilities. Finally, in philanthropic responsibilities , AI systems are expected to be good AI citizens and to contribute to tackling societal challenges such as cancer and climate change. Particularly, it is important for AI systems to perform in a manner consistent with the philanthropic and charitable expectations of society to enhance people’s quality of life. The distinguishing feature between ethical and philanthropic responsibilities is that the latter are not expected in an ethical sense. For example, while communities desire AI systems to be applied to humanitarian projects or purposes, they do not regard the AI systems as unethical if they do not provide such services. We explore the nature of Social Responsibility of AI by focusing on its components to help AI technologists to reconcile these obligations. Though these four components are depicted as separate concepts, they are not mutually exclusive. It is necessary for AI technologists and researchers to recognize that these obligations are in a constant but dynamic tension with one another.
Comparisons of Similar Concepts
Based on Definition 1 and the pyramid of socially responsibility of AI, we compare Socially Responsible AI with other similar concepts, as illustrated in Table comparisons. The results show that Socially Responsible AI holds a systematic view that subsumes existing concepts and further considers the fundamental responsibilities of AI systems – to be functional and legal, as well as their philanthropic responsibilities – to be able to improve life quality of well beings and address challenging societal issues. In the rest of this survey, we focus our discussions on the ethical (Section 3, essentials of SRAs) and philanthropic (Section 4, roles of SRAs) responsibilities of AI given that both the functional and legal responsibilities are the usual focuses in AI research and development. An overview of SRAs research is illustrated in Figure outline, which we will refer back to throughout the remainder of the survey. Importantly, in our view, the essentials of SRAs work toward ethical responsibilities, and their roles in society encompass both ethical and philanthropic responsibilities.
Definitions of concepts similar to Socially Responsible AI.
Table Label: comparisons
Download PDF to view table[2]https://www.cognizant.com/glossary/human-centered-ai
Socially Responsible AI Algorithms (SRAs)
The role of AI technologists and researchers carries a number of responsibilities. The most obvious is developing accurate, reliable, and trustworthy algorithms that can be depended on by their users. Yet, this has never been a trivial task. For example, due to the various types of human biases, e.g., confirmation bias, gender bias, and anchoring bias, AI technologists and researchers often inadvertently inject these same kinds of bias into the developed algorithms, especially when using machine learning techniques. For example, supervised machine learning is a common technique for learning and validating algorithms through manually annotated data, loss functions, and related evaluation metrics. Numerous uncertainties – e.g., imbalanced data, ill-defined criteria for data annotation, over-simplified loss functions, and unexplainable results – potentially lurk in this “beautiful” pipeline and will eventually lead to negative outcomes such as biases and discrimination. With the growing reliance on AI in almost any field in our society, we must bring upfront the vital question about how to develop Socially Responsible AI Algorithms . While conclusive answers are yet to be found, we attempt to provide a systematic framework of SRAs (illustrated in Figure sras) to discuss the components of AI’s ethical responsibilities, the roles of SRAs in terms of AI’s philanthropic and ethical responsibilities, and the feedback from users routed back as inputs to SRAs. We hope to broaden future discussions on this subject. In this regard, we define SRAs as follows:
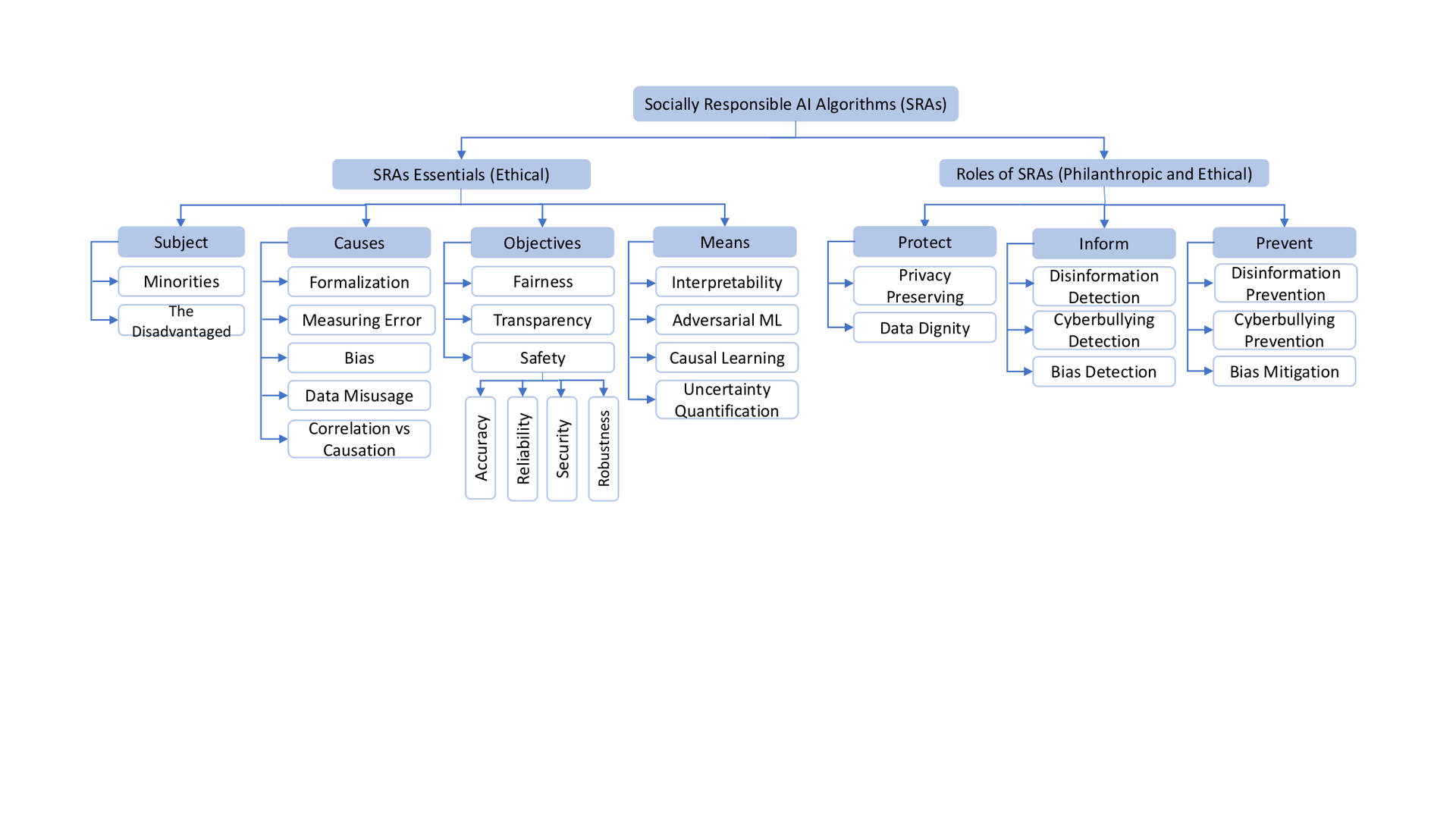

Socially Responsible AI Algorithms are the intelligent algorithms that prioritize the needs of all stakeholders as the highest priority, especially the minoritized and disadvantaged users, in order to make just and trustworthy decisions. These obligations include protecting and informing users; preventing and mitigating negative impact; and maximizing the long-term beneficial impact. Socially Responsible AI Algorithms constantly receive feedback from users to continually accomplish the expected social values.
In this definition, we highlight that the functional (e.g., maximizing profits) and societal (e.g., transparency) objectives are integral parts of AI algorithms. SRAs aim to be socially responsible while still meeting and exceeding business objectives.
Subjects of Socially Indifferent AI Algorithms
Every human being can be a potential victim of socially indifferent AI algorithms. Mirroring society, the ones who suffer the most, both in frequency and severity, are minorities and disadvantaged groups such as black, indigenous and people of color (BIPOC), and females. For example, Google mislabeled an image of two black people as “gorillas”and more frequently showed ads of high-paying jobs to males than females. Similar gender bias was also found in Facebook algorithms behind the job ads. In domains with high-stakes decisions, e.g., financial services, healthcare, and criminal justice, it is not uncommon to identify instances where socially indifferent AI algorithms favor privileged groups. For example, the algorithm used in Correctional Offender Management Profiling for Alternative Sanctions (COMPAS) was found almost twice as likely to mislabel a black defendant as a future risk than a white defendant. Identifying the subjects of socially indifferent AI algorithms depends on the context. In another study, the journalistic organization ProPublica[https://www.propublica.org/] investigated algorithms that determine online prices for Princeton Review’s tutoring classes. The results showed that people who lived in higher income areas were charged twice as much as the general public and than people living in a zip code with high population density. Asians were 1.8 times more likely to pay higher price, regardless of their income. Analogously, these AI algorithms might put poor people who cannot afford internet service at disadvantage because they simply have never seen such data samples in the training process.
When it comes to purpose-driven collection and use of data, each individual can be the subject of socially indifferent AI algorithms. Users’ personal data are frequently collected and used without their consent. Such data includes granular details such as contact information, online browsing and session record, social media consumption, location and so on. While most of us are aware of our data being used, few have controls to where and how the data is used, and by whom. The misuse of data and lack of knowledge causes users to become the victims of privacy-leakage and distrust.
Causes of Socially Indifferent AI Algorithms
There are many potential factors that can cause AI algorithms to be socially indifferent. Here, we list several causes that have been frequently discussed in literature. They are formalization, measuring errors, bias, privacy, and correlation versus causation.
Formalization
AI algorithms encompass data formalization, label formalization, formalization of loss function and evaluation metrics. We unconsciously make some frame of reference commitment to each of these formalizations. Firstly, the social and historical context are often left out when transforming raw data into numerical feature vectors. Therefore, AI algorithms are trained on pre-processed data with important contextual information missing. Secondly, data annotation can be problematic for a number of reasons. For example, what are the criteria? Who defines the criteria? Who are the annotators? How can it be ensured that they all follow the criteria? What we have for model training are only proxies of the true labels. Ill-formulated loss functions can also result in socially indifferent AI algorithms. Many loss functions in the tasks are over-simplified to solely focus on maximizing profits and minimizing losses. The concerns of unethical optimization are recently discussed by beale2019unethical. Unknown to AI systems, certain strategies in the optimization space that are considered as unethical by stakeholder may be selected to satisfy the simplified task requirements. Lastly, the use of inappropriate benchmarks for evaluation may push algorithms away from the overarching goal of the task and fuel injustice.
Measuring Errors
Another cause of socially indifferent AI algorithms is the errors when measuring algorithm performance. When reporting results, researchers typically proclaim the proposed algorithms can achieve certain accuracy or F1 scores. However, this is based on assumptions that the training and test samples are representative of the target population and their distributions are similar enough. Yet, how often does the assumption hold in practice? As illustrated in Figure measureerror, with non-representative samples, the learned model can achieve zero training error and perform well on the testing data at the initial stage. However, with more data being tested later, the model performance deteriorates because the learned model does not represent the true model.

Bias
Bias is one of the most discussed topics regarding responsible AI. We here focus on the data bias, automation bias, and algorithmic bias.
Data Bias. Data, especially big data, is often heterogeneous – data with high variability of types and formats, e.g., text, image, and video. The availability of multiple data sources brings unprecedented opportunities as well as unequivocally presented challenges. For instance, high-dimensional data such as text is infamous for the danger of overfitting and the curse of dimensionality. Additionally, it is rather challenging to find subset of features that are predictive but uncorrelated. The required number samples for generalization also grows proportionally with feature dimension. One example is how the U.S. National Security Agency tried to use AI algorithms to identify potential terrorists. The Skynet project collected cellular network traffic in Pakistan and extracted 80 features for each cell phone user with only 7 known terrorists. The algorithm ended up identifying an Al Jazeera reporter covering Al Qaeda as a potential terrorist. Data heterogeneity is also against the well known $i.i.d.$ assumption in most learning algorithms. Therefore, training these algorithms on heterogeneous data can result in undesired results. Imbalanced subgroups is another source of data bias. As illustrated in, regression analysis based on the subgroups with balanced fitness level suggests positive correlation between BMI and daily pasta calorie intake whereas that based on less balanced data shows almost no relationship.
Automation Bias. This type of bias refers to our preference to results suggested by automated decision-making systems while ignoring the contradictory information. Too much reliance on the automated systems without sparing additional thoughts in making final decisions, we might end up abdicating decision responsibility to AI algorithms.
Algorithmic Bias. Algorithmic bias regards biases added purely by the algorithm itself. Some algorithms are inadvertently taught prejudices and unethical biases by societal patterns hidden in the data. Typically, models fit better to features that frequently appear in the data. For example, an automatic AI recruiting tool will learn to make decisions for a given applicant of a software engineer position using observed patterns such as “experience”, “programming skills”, “degree”, and “past projects”. For a position where gender disparity is large, the algorithms mistakenly interpret this collective imbalance as a useful pattern in the data rather than undesirable noise that should have been discarded. Algorithmic bias is systematic and repeatable error in an AI system that creates discriminated outcome, e.g., privileging wealthy users over others. It can amplify, operationalize, and even legitimize institutional bias.
Data Misuse
Data is the fuel and new currency that has empowered tremendous progress in AI research. Search engines have to rely on data to craft precisely personalized recommendation that improves the online experience of consumers, including online shopping, book recommendation, entertainment, and so on. However, users’ data are frequently misused without the consent and awareness of users. One example is the Facebook-Cambridge Analytical scandalwhere millions of Facebook users’ personal data was collected by Cambridge Analytica, without their consent. In a more recent study, researchers show that Facebook allows advertisers to exploit its users’ sensitive information for tailored ad campaigns. To make things worse, users often have no clue about where, how, and why their data is being used, and by whom. The lack of knowledge and choice over their data causes users to undervalue their personal data, and further creates issues such as privacy and distrust.
Correlation vs Causation
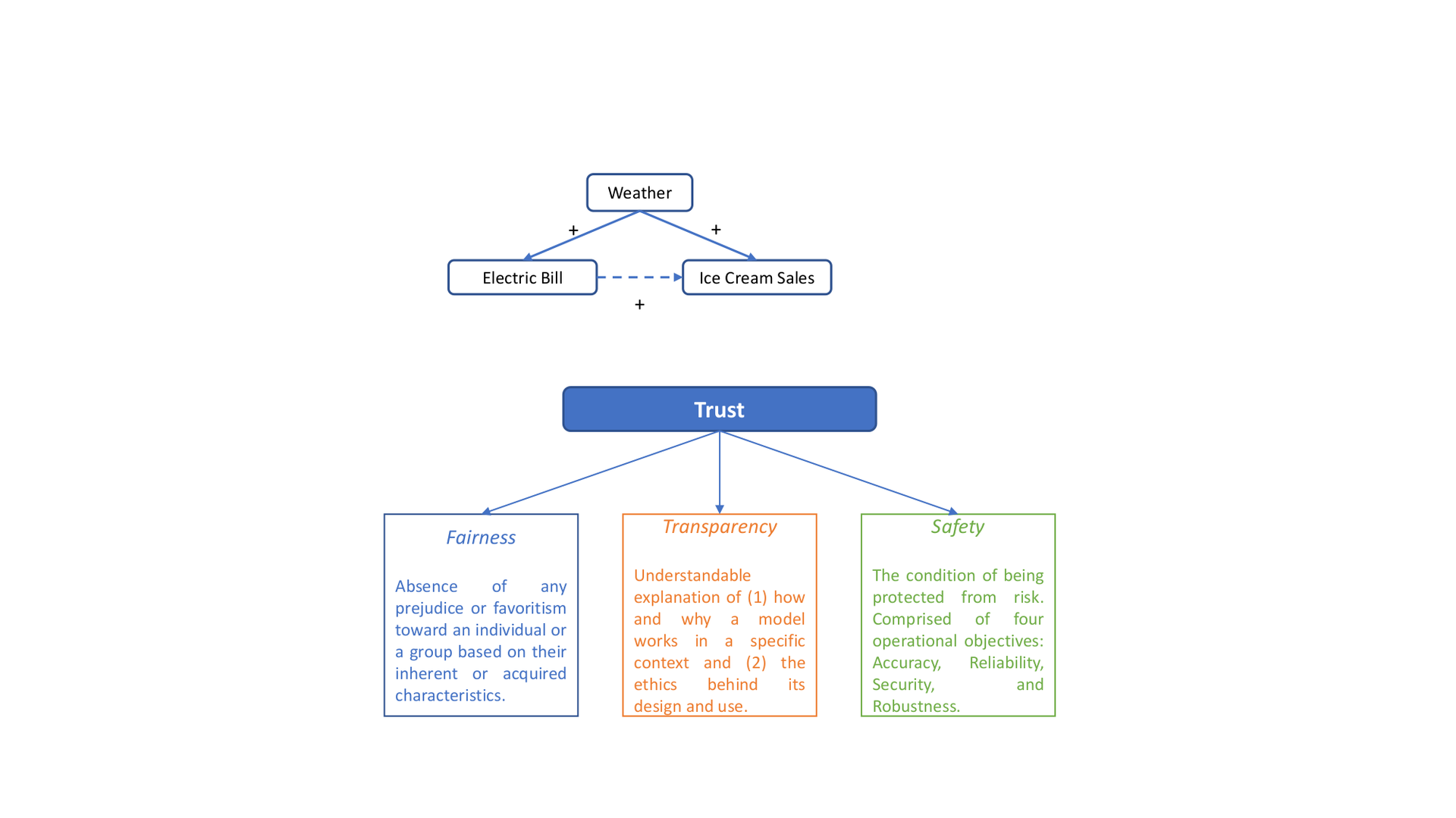
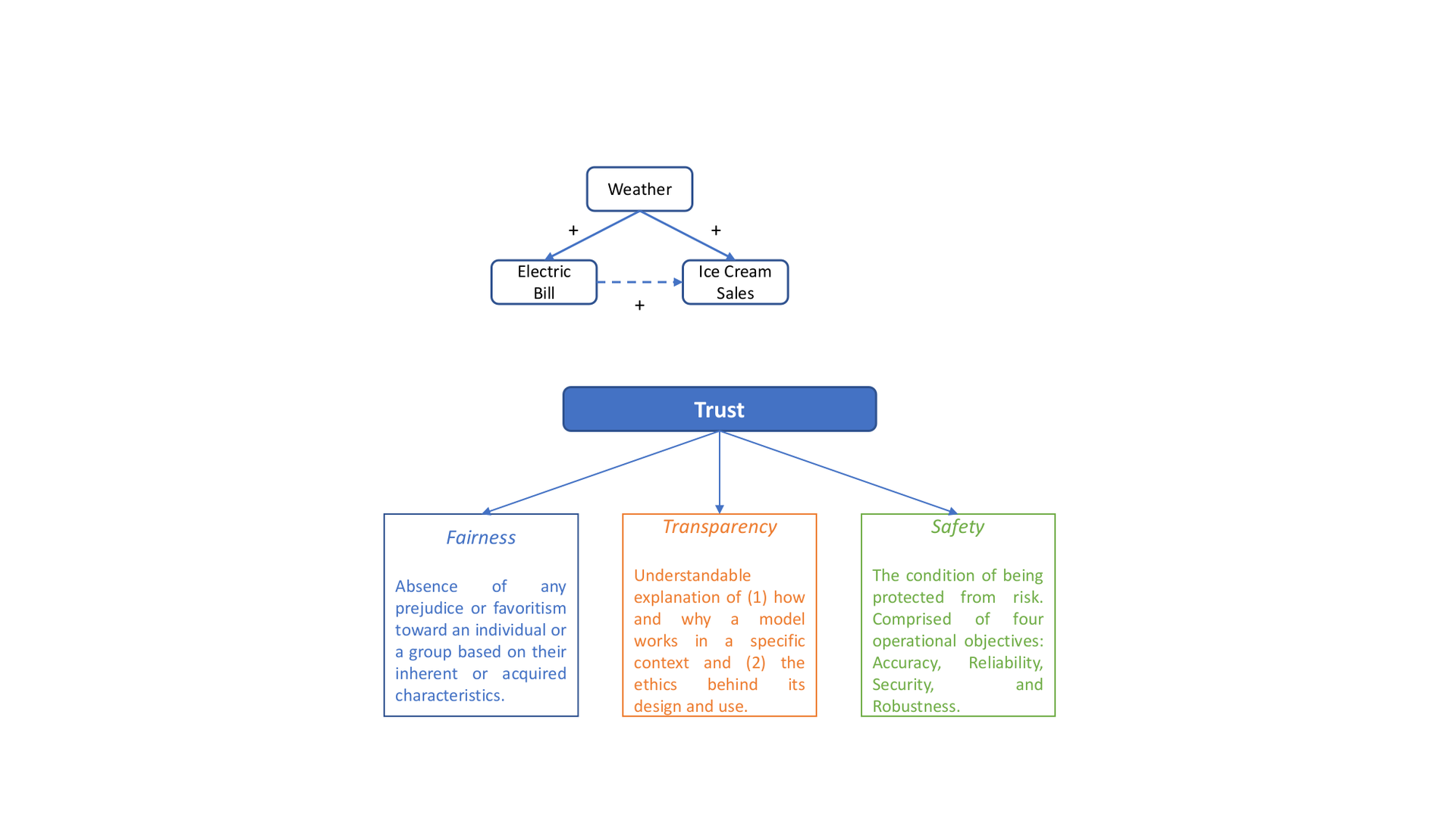
AI Algorithms can become socially indifferent when correlation is misinterpreted as causation. For example, in the diagram in Figure icecream, we observe a strong correlation between the electric bill of an ice cream shop and ice cream sales. Apparently, high electric bill cannot cause the ice cream sales to increase. Rather, weather is the common cause of electric bill and the sale, i.e., high temperature causes high electric bill and the increased ice cream sales. Weather – the confounder – creates a spurious correlation between electric bill and ice cream sales. Causality is a generic relationship between the cause and the outcome. While correlation helps with prediction, causation is important for decision making. One typical example is Simpson’s Paradox. It describes a phenomenon where a trend or association observed in subgroups maybe opposite to that observed when these subgroups are aggregated. For instance, in the study of analyzing the sex bias in graduation admissions at UC Berkeley, the admission rate was found higher in male applicants when using the entire data. However, when the admission data were separated and analyzed over the departments, female candidates had equal or even higher admission rate over male candidates.
Objectives of Socially Responsible AI Algorithms
Essentially, the goal is to (re)build trust in AI. By definition, trust is the “firm belief in the reliability, truth or ability of someone or something”[Definition from Oxford Languages.]. It is a high-level concept that needs to be specified by more concrete objectives. We here discuss the SRAs objectives that have been discussed comparatively frequently in literature. They are fairness, transparency, and safety as illustrated in Figure objective.
Fairness
Fairness in AI has gained substantial attentions in both research and industry since 2010. For decades, researchers found it rather challenging to present a unified definition of fairness in part because fairness is a societal and ethical concept. This concept is mostly subjective, changes over social context, and evolves over time, making fairness a rather challenging goal to achieve in practice. Because SRAs is a decision-making process commensurate with social values, we here adopt a fairness definition in the context of decision-making:
“Fairness is the absence of any prejudice or favoritism toward an individual or a group based on their inherent or acquired characteristics”.
Note that even an ideally “fair” AI system defined in a specific context might still lead to biased decisions as the entire decision making process involves numerous elements such as policy makers and environment. While the concept of fairness is difficult to pin down, unfairness/bias/discrimination might be easier to identify. There are six types of discrimination. Direct discrimination results from protected attributes of individuals while indirect discrimination from seemingly neural and non-protected attributes. Systemic discrimination relates to policies that may show discrimination against subgroups of population. Statistical discrimination occurs when decision makers use average statistics to represent individuals. Depending whether the differences amongst different groups can be justified or not, we further have explainable and unexplainable discrimination.
Transparency
Transparency is another important but quite ambiguous concept. This is partly because AI alone can be defined in more than 70 ways. When we seek a transparent algorithm, we are asking for an understandable explanation of how it works: What does the training set look like? Who collected the data? What is the algorithm doing? There are mainly three types of transparency with regard to human interpretability of AI algorithms: For a developer , the goal of transparency is to understand how the algorithm works and get a sense of why; for a deployer who owns and releases the algorithm to the public, the goal of transparency is to make the consumers to feel safe and comfortable to use the system; and what transparency means to a user is understanding what the AI system is doing and why. We may further differentiate global transparency from local transparency, the former aims to explain the entire system whereas the latter explains a decision within a particular context.
Yet, at the same time, disclosures about AI can pose potential risks: explanations can be hacked and releasing additional information may make AI more vulnerable to attacks. It is becoming clear that transparency is often beneficial but not universally good. The AI “transparency paradox” encourages different parties of AI systems to think more carefully about how to balance the transparency and the risks it poses. We can also see related discussions in recent work such as. The paper studied how the widely recognized interpretable algorithms LIMEand SHAPcould be hacked. As the authors illustrated, explanations can be purposefully manipulated, leading to a loss of trust not only in the model but also in its explanations. Consequently, while working towards the goal of transparency, we must also recognize that privacy and security are the indispensable conditions we need to satisfy.
Safety
Because AI systems operate in a world with much uncertainty, volatility, and flux, another objective of SRAs is to be safe, accurate, and reliable. There are four operational objectives relevant to Safety: accuracy, reliability, security, and robustness. In machine learning, accuracy is typically measured by error rate or the fraction of instances for which the algorithm produces an incorrect output. As a standard performance metric, accuracy should be the fundamental component to establishing the approach to safe AI. It is necessary to specify a proper performance measure for evaluating any AI systems. For instance, when data for classification tasks is extremely imbalanced, precision, recall, and F1 scores are more appropriate than accuracy. The objective of reliability is to ensure that AI systems behave as we anticipate. It is a measure of consistency and is important to establish confidence in the safety of AI systemsSecurity_ encompasses the protection of information integrity, confidentiality, and continuous functionality to its users. Under harsh conditions (e.g., adversarial attack, perturbations, and implementation error), AI systems are expected to functions reliably and accurately, i.e., Robustness .
Means Towards Socially Responsible AI Algorithms
In this section, we review four primary machine learning techniques and statistical methods for achieving the goals of SRAs – interpretability and explainability, adversarial machine learning, causal learning, and uncertainty quantification. Existing surveys have conducted comprehensive reviews on each of these techniques: e.g., interpretablity, causal learning, adversarial machine learning, and uncertainty quantification. We thereby focus on the basics and the most frequently discussed methods in each means.
Interpretability and Explainability
Interpretability and explanability are the keys to increasing transparency of AI algorithms. This is extremely important when we leverage these algorithms for high-stakes prediction applications, which deeply impact people’s lives. Existing work in machine learning interpretability can be categorized according to different criteria. Depending on when the interpretability methods are applicable (before, during, or after building the machine learning model), we have pre-model (before), in-model (during), and post-model (after) interpretability. Pre-model techniques are only applicable to the data itself. It requires an in-depth understanding of the data before building the model, e.g., sparsity and dimensionality. Therefore, it is closely related to data interpretability, in which classic descriptive statistics and data visualization methods are often used, including Principal Component Analysisand t-SNE, and clustering methods such as $k$ -means. In-model interpretability asks for intrinsically interpretable AI algorithms (e.g., yang2016hierarchical), we can also refer to it as intrinsic interpretability. It can be achieved through imposition of constraints on the model such as causality, sparsity, or physical conditions from domain knowledge. In-model interpretability answers question how the model works. Decision trees, rule-based models, linear regression, attention network, and disentangled representation learning are in-model interpretability techniques. Post-model interpretability, or post-hoc interpretability (e.g., mordvintsev2015inceptionism,ribeiro2016should), is applied after model training. It answers the question what else can the model tell us. Post-model interpretability include local explanations, saliency maps, example-based explanations, influence functions, feature visualization, and explaining by base interpretable models.
Another criterion to group current interpretability techniques is model-specific vs model-agnostic. Model-specific interpretation is based on internals of a specific model. To illustrate, the coefficients of a linear regression model belong to model-specific interpretation. Model-agnostic methods do not have access to the model inner workings, rather, they are applied to any machine learning model after it has been trained. Essentially, the goal of interpretability is to help the user understand the decisions made by the machine learning models through the tool explanation . There are pragmatic and non-pragmatic theories of explanation. The former indicates that explanation should be a good answer that can be easily understood by the audience. The non-pragmatic theory emphasizes the correctness of the answer to the why-question. Both need to have the following properties: expressive power, translucency, portability, and algorithmic complexity.
Adversarial Machine Learning
Machine learning models, especially deep learning models, are vulnerable to crafted adversarial examples, which are imperceptible to human eyes but can easily fool deep neural networks (NN) in the testing/deploying stage. Adversarial examples have posed great concerns in the security and integrity of various applications. Adversarial machine learning, therefore, closely relates to the robustness of SRAs.
The security of any machine learning model is measured with regard to the adversarial goals and capabilities. Identifying the threat surfaceof an AI system built on machine learning models is critical to understand where and how an adversary may subvert the system under attack. For example, the attack surface in a standard automated vehicle system can be defined with regard to the data processing pipeline. Typically, there are three types of attacks the attack surface can identify: evasion attack – the adversary attempts to evade the system by manipulating malicious samples during testing phase, poisoning attack – the adversary attempts to poison the training data by injecting carefully designed samples into the learning process, and exploratory attack – it tries to collect as much information as possible about the learning algorithm of the underlying system and pattern in training data. Depending on the amount of information available to an adversary about the system, we can define different types of adversarial capabilities. In the training phase (i.e., training phase capabilities), there are three broad attack strategies: (1) data injection. The adversary can only augment new data to the training set; (2) data modification. The adversary has full access to the training data; and (3) logic corruption. The adversary can modify the learning algorithm. In the testing phase (i.e., testing phase capabilities), adversarial attacks focus on producing incorrect outputs. For white-box attack, an adversary has full knowledge about the model used for prediction: algorithm used in training, training data distribution, and the parameters of the fully trained model. The other type of attack is black-box attack, which, on the contrary, assumes no knowledge about the model and only uses historical information or information about the settings. The primary goal of black-box attack is to train a local model with the data distribution, i.e., non-adaptive attack, and with carefully selected dataset by querying the target model, i.e., adaptive attack.
Exploratory attacks do not have access to the training data but aim to learn the current state by probing the learner. Commonly used techniques include model inversion attack, model extraction using APIs, and inference attack. The popular attacks are evasion attacks where malicious inputs are craftily manipulated so as to fool the model to make false predictions. Poisoning attacks, however, modify the input during the training phase to obtain the desired results. Some of the well-known techniques are generative adversarial network (GAN), adversarial examples generation (including training phase modification, e.g., barreno2006can, and testing phase modification, e.g., papernot2016distillation), GAN-based attack in collaborative deep learning, and adversarial classification.
Causal Learning
Causal inference and reasoning is a critical ingredient for AI to achieve human-level intelligence, an overarching goal of Socially Responsible AI. The momentum of integrating causality into responsible AI is growing, as witnessed by a number of works (e.g., kusner2017counterfactual,xu2019achieving,holzinger2019causability) studying SRAs through causal learning methods.
Basics of Causal Learning. The two fundamental frameworks in causal learning are _structural causal models_and potential outcome. Structural causal models rely on the causal graph, which is a special class of Bayesian network with edges denoting causal relationships. A more structured format is referred to as structural equations. One of the fundamental notions in structural causal models is the do -calculus, an operation for intervention . The difficulty to conduct causal study is the difference between the observational and interventional distribution, the latter describes what the distribution of outcome $Y$ is if we were to set covariates $X=x$ . Potential outcome framework interprets causality as given the treatment and outcome, we can only observe one potential outcome. The counterfactuals – potential outcome that would have been observed if the individual had received a different treatment – however, can never be observed in reality. These two frameworks are the foundations of causal effect estimation (estimating effect of a treatment) and causal discovery (learning causal relations amongst different variables).
Many important concepts in causal inference have been adapted to AI such as intervention and counterfactual reasoning. Here, we introduce the causal concept most frequently used in SRAs – propensity score, defined as “conditional probability of assignment to a particular treatment given a vector of observed covariates”. A popular propensity-based approach is Inverse Probability of Treatment Weighting. To synthesize a randomized control trial, it uses covariate balancing to weigh instances based on their propensity scores and the probability of an instance to receive the treatment. Let $t_i$ and $x_i$ be the treatment assignment and covariate of instance $i$ , the weight $w_i$ is typically computed by the following formula:
\[ w_i=\frac{t_i}{P(t_i|x_i)}+\frac{1-t_i}{1-P(t_i|x_i)}, \]where $P(t_i|x_i)$ quantifies the propensity score. The weighted average of the observed outcomes for the treatment and control groups are defined as
\[ \hat{\tau}=\frac{1}{n_1}\sum_{i:t_i=1}w_iy_i-\frac{1}{n_0}\sum_{i:t_i=0}w_iy_i, \]where $n_1$ and $n_0$ denote the sizes of the treated and controlled groups.
Causal Learning for SRAs. Firstly, it is becoming increasingly popular to use causal models to solve fairness-related issues. For example, the subject of causality and its importance to address fairness issue was discussed in. Causal models can also be used to discover and eliminate discrimination to make decisions that are irrespective of sensitive attributes, on individual-, group-, and system-level, see, e.g.,. Secondly, bias alleviation is another field where causal learning methods are frequently discussed and affect many machine learning applications at large. The emerging research on debiasing recommender systemcan serve as one example. Due to the biased nature of user behavior data, recommender systems inevitably involve with various discrimination-related issues: recommending less career coaching services and high-paying jobs to women, recommending more male-authored books, and minorities are less likely to become social influencers. Gender and ethnic biases were even found in a broader context, e.g., word embeddings trained on 100 years of text data. Causal approaches such asaim to mitigate such bias in word embedding relations.
Thirdly, causal learning methods also have had discernible achievements in transparency, especially the interpretability of black-box algorithms. Causality is particularly desired since these algorithms only capture correlations not real causes. Further, it has been suggested that counterfactual explanations are the highest level of interpretability. For model-based interpretations, causal interpretability aims to explain the causal effect of a model component on the final decision. One example to differentiate it from traditional interpretability is only causal interpretability is able to answer question such as “What is the effect of the $n$ -th filter of the $m$ -th layer of a neural network on the prediction of the model?”.Counterfactual explanations is a type of example-based explanations, in which we look for data instances that can explain the underlying data distributions. Counterfactual explanations are human friendly, however, it is possible to have different true versions of explanations for the predicted results, i.e., the Rashomon effect. Studies such asare proposed to address this issue. For detailed discussion on causal interpretability, please refer to. Lastly, causal learning is inherently related to the robustness or adaptability of AI systems, which have been noted to lack the capability of reacting to new circumstances they are not trained for. Causal relationship, however, is expected to be invariant and robust across environments. This complements intensive earlier efforts toward “transfer learning”, “domain adaptation”, and “lifelong learning”. Some current work seeking to extrapolate the relationship between AI robustness and causality includes the independent causal mechanism principle, invariant prediction, and disentangled causal mechanism.
Uncertainty Quantification
AI research continues to develop new state-of-the-art algorithms with superior performance and large-scaled datasets with high quality. Even using the best models and training data, it is still infeasible for AI systems to cover all the potential situations when deployed into real-world applications. As a matter of fact, AI systems always encounter new samples that are different from those used for training. The core question is how to leverage the strengths of these uncertainties. Recent research, e.g.,, has advocated to measure, communicate, and use uncertainty as a form of transparency. There are also tools such as IBM’s Uncertainty Quantification 360[http://uq360.mybluemix.net/overview] to provide AI practitioners access to related resources as common practices for AI transparency. Consequently, uncertainty quantification plays a crucial role in the optimization and decision-making process in SRAs. There are typically two kinds of uncertainties in risk analysis processes: first, the aleatory uncertainty describes the inherent randomness of systems. For example, an AI system can present different results even with the same set of inputs. The uncertainty arises from underlying random variations within the data. Second, the epistemic uncertainty represents the effect of an unknown phenomenon or an internal parameter. The primary reason leading to this type of uncertainty is the lack of observed data. As the variation among the data in aleatory uncertainty is often observable, we can well quantify the uncertainty and assess the risks. Quantification of epistemic uncertainty is more challenging because AI systems are forced to extrapolate over unseen situations. In the literature of uncertainty quantification, one of the most widely recognized techniques are prediction intervals (PI). For neural-network-based models, PI can be categorized into multi-step PI construction methods (e.g., Bayesian method) and direct PI construction methods (e.g., lower upper bound estimation). Here, we briefly discuss several methods in each category. Please refer to the surveyfor more details.
Multi-Step Prediction Intervals Construction Methods. Delta method, Bayesian method, Mean-Variance Estimation method, and Bootstrap method are the four conventional multi-step methods reported in literature. Delta method constructs PIs through nonlinear regression using Tylor series expansion. Particularly, we linearize neural network models through optimization by minimizing the error-based loss function, sum square error. Under the assumption that uncertainty is from normal and homogeneous distribution, we then employ standard asymptotic theory to construct PIs. Delta method has been used in numerous case studies, e.g.,. Bayesian learning provides a natural framework for constructing PIsas it optimizes the posterior distribution of parameters from the assumed prior distribution. Despite its high generalization power, Bayesian techniques are limited by large computational complexity due to the calculation of Hessian matrix. Bootstrap method is the most popular among the four conventional multi-step PI construction methods. It includes smooth, parametric, wild, pairs, residual, Gaussian process, and other types of bootstrap techniques. In NN-based pairs bootstrap algorithm, for example, the key is to generate bootstrapped pairs by uniform sampling with replacement from the original training data. The estimation is then conducted for a single bootstrapped dataset.
Direct Prediction Intervals Construction Methods. This category of methods can tackle some of the limitations in previous methods, such as high demanding in computational power and stringent assumptions. When NN models are constructed through direct training without any assumptions, they can provide more adaptive and smarter PIs for any distribution of targets. Lower Upper Bound estimation method is such a technique that can be applied to arbitrary distribution of targets with more than one order reduced computation time. It directly calculates the lower and the upper bounds through trained NNs. Initially, Lower Upper Bound estimation NNs are optimized with the coverage width-based criterion, which presents several limitations. With all the benefits of the original Lower Upper Bound estimation method, the NN-based Direct Interval Forecasting methodhas much shorter computation time and narrower PIs credited to the improved cost function and the reduced average coverage error. Other approaches for improving the cost function of Lower Upper Bound estimation include the normalized root-mean-square width and particle swarm optimization, optimal system by, the independent width and penalty factors, the deviation from mid-interval consideration, and the deviation information-based criterion.
Roles of SRAs
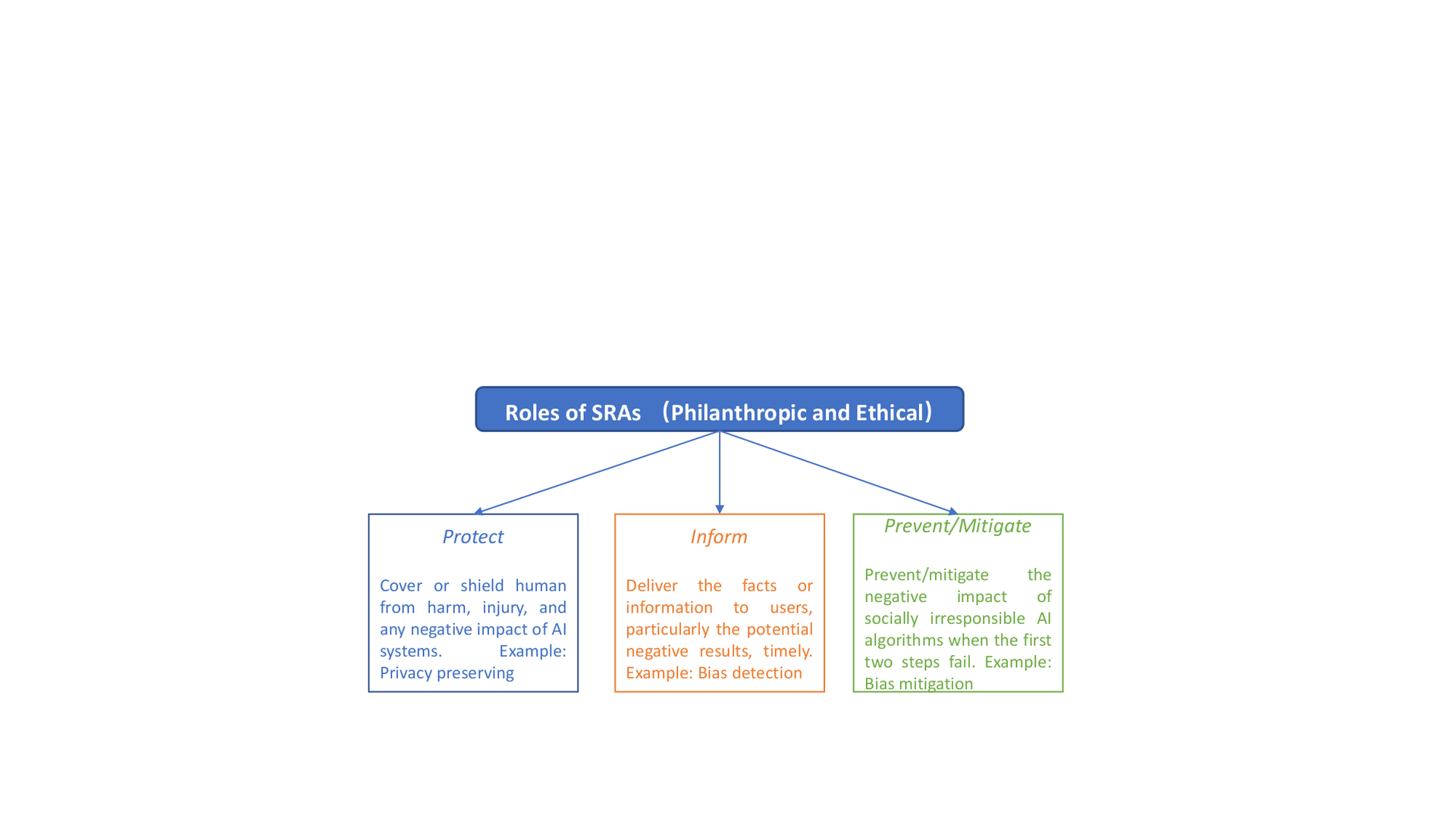
So far, we have introduced the essentials of SRAs to achieve the expected ethical responsibilities. But pragmatic questions regarding their intended use remain: How to operationalize SRAs? What can SRAs eventually do for societal well-being to address societal challenges? Both ethical and philanthropic responsibilities are indispensable ingredients of the answers. While the ultimate goal of SRAs is to do good and be a good AI citizen , their ethical responsibilities should be ensured first. When AI fails to fulfill its ethical responsibilities, its philanthropic benefits can be insignificant. For instance, despite the immense public good of COVID-19 vaccines, there has been great controversy about algorithms for their distribution, which have been shown to be inequitable. Some argue that distribution algorithms should prioritize saving more lives and bringing the economy back more rapidly; they support such an `unfair’ allocation, but we would argue that that is not unfairness, but simply a difference of values and ethics. In our view, roles of SRAs are expected to encompass both ethical and philanthropic responsibilities. In this survey, we describe three dimensions that SRAs can help with to improve the quality of human life as illustrated in Figure cando: Protect (e.g., protect users’ personal information), Inform (e.g., fake news early detection), and Prevent/Mitigate (e.g., cyberbullying mitigation). We illustrate each dimension with research findings in several emerging societal issues. Particularly, for protecting dimension, we focus on privacy preserving and data dignity; for informing and preventing/mitigating dimensions, we discuss three societal issues that raise growing concerns recently: disinformation, abusive language, and unwanted bias. Because there are many various forms of abusive language such as hate speech and profanity, and the body of work related to each form is vast and diverse, spanning multiple interconnected disciplines, this survey uses the form of cyberbullying as a representative for the illustrations.
Protecting
The protecting dimension aims to cover or shield humans (especially the most vulnerable or at-risk) from harm, injury, and negative impact of AI systems, in order to intervene. This can be the protection of users’ personal data and their interactions with AI systems. Two typical examples are privacy preserving and data dignity.
Privacy-Preserving
The capability of deep learning models has been greatly improved by the emerging powerful infrastructures such as clouds and collaborative learning for model training. The fuel of this power, however, comes from data, particularly sensitive data. This has raised growing privacy concerns such as illegitimate use of private data and the disclosure of sensitive data. Existing threats against privacy are typically from attacks such as the adversarial examples we discussed in Sec. adversary. Specifically, there are direct information exposure (e.g., untrusted clouds), which is caused by direct intentional or unintentional data breaches, and indirect (inferred) information exposure (e.g., parameter inference), which is caused by direct access to the model or output. Existing privacy-preserving mechanisms can be classified into three categories, namely, private data aggregation methods, private training, and private inference.
Data aggregation methods are either context-free or context-aware. A context-free approach such as differential privacy, is unaware of the context or what the data will be used for. Context-aware approach such as information-theoretic privacy, on the other hand, is aware of the context in which the data will be used. A naïve technique for privacy protection is to remove identifiers from data, such as name, address, and zip code. It has been used for protecting patients’ information while processing their medical records, but the results are unsatisfying. The k-Anonymity method can prevent information from re-identification by showing at least $k$ samples with exact same set of attributes for given combination of attributes that the adversary has access to. The most commonly used data aggregation method is differential privacy, which aims to estimate the effect of removing an individual from the dataset and keep the effect of the inclusion of one’s data small. Some notable work includes the Laplace mechanism, differential privacy with Advanced Composition, and local differential privacy.
Information-theoretic privacy is a context-aware approach that explicitly models the dataset statistics. By contrast, context-free methods assume worse-case dataset statistics and adversaries. This line of research was studied by diaz2019robustness, pinceti2019data, and varodayan2011smart. The second type of privacy-preserving mechanism works during the training phase. Established work in private training is mostly used to guarantee differential privacy or semantic security and encryption. The two most common methods for encryption are homomorphic encryptionand secure multi-party computation. The third type of privacy-preserving mechanism works during the inference phase. It aims at the trained systems that are deployed to offer inference-as-a-service. Most methods in private inference are similar to those in private training, except for the information-theoretic privacy. It is typically used to offer information-theoretic mathematical or empirical evidence of how these methods operate to improve privacy. There is also work using differential privacy, homomorphic encryption, and secure multi-party computation.
Data Dignity
Beyond privacy preserving, what is more urgent to accomplish is data dignity. It allows users to have absolute control to how their data is being used and they are paid accordingly. Data dignity encompasses the following aspects:
- To help users objectively determine the benefits and risks associated with their digital presence and personal data.
- To let users control how their data will be used and the purpose of using the data.
- To allow users to negotiate the terms of using their data.
- To give users complete right and autonomy to be found, analyzed, or forgotten, apart from the fundamental right over their data. There are business models such as the Microsoft Data Bank designed to give users the control of their data and those shared by the Art of Researchabout how people can buy and sell their personal data.
Informing
The informing dimension aims to deliver the facts or information to users, particularly the potential negative results, in a timely way. We illustrate it with a focus on the discussions of detecting disinformation, cyberbullying, and bias.
Disinformation Detection
Disinformation is false information that is deliberately created and spread to deceive people, a social group, organization, or country. The online information ecosystem is never short of disinformation and misinformation, and the growing concerns have been raised recently. Tackling disinformation is rather challenging mainly because (1) disinformation exists almost in all domains; (2) it is ever-changing with new problems, challenges, and threats emerging every day; (3) it entails the joint efforts of interdisciplinary research – computer science, social science, politics, policy making, and psychology, cognitive science. Accurate and efficient identification of disinformation is the core to combat disinformation. Existing prominent approaches for disinformation detection primarily rely on news content, social context, user comments, fact-checking tools, and explainable and cross-domain detection.
Early work on disinformation detection has been focused on hand-crafted features extracted from text, such as lexical and syntactic features. Apart from text, online platforms also provide abundant social information that can be leveraged to enrich the textual features, e.g., number of re-tweets and likes on Twitter. Informed by theories in social science and network science, another line of work exploits social network information to improve the detection performance. Common features are social context, user profile, user engagement, and relationships among news articles, readers, and publishers. A unique function of online platforms is that they allow users to interact through comments. Recent work has shown that user comments can provide weak supervision signal for identifying the authenticity of news articles, which enables early detection of disinformation. When the user comments are unavailable, it is possible to learn users’ response to news articles and then generate user responses. Fact-checking can be achieved manually or automatically. Manual fact-checking relies on domain experts or crowdsourced knowledge from users. Automatic fact-checking uses structure knowledge bases such as knowledge graph to verify the authenticity of news articles, see, e.g.,. Beyond within-domain detection, other tasks such as cross-domain detection, explanation, and causal understanding of fake news disseminationhave also been discussed in literature.
Cyberbullying Detection
Cyberbullying differs from other forms of abusive language in that it is not an one-off incident but “aggressively intentional acts carried out by a group or an individual using electronic forms of contact, repeatedly or over time against victims who cannot easily defend themselves”. The increasingly reported number of cyberbullying cases on social media and the resulting detrimental impact have raised great concerns in society. Cyberbullying detection is regularly figured as a binary classification problem. While it shares some similarities with document classification, it should be noted that cyberbullying identification is inherently more complicated than simply identifying oppressive content.
Distinct characteristics of cyberbullying such as power imbalance and repetition of aggressive acts are central to marking a message or a social media sessionas cyberbullying. Several major challenges in cyberbullying detection have been discussed in literature such as the formulation of the unique bullying characteristics, e.g., repetition, data annotation, and severe class imbalance. Depending on the employed features, established work can be classified into four categories: content-based, sentiment-based, user-based, and network-based methods. Features extracted from social media content are lexical items such as keywords, Bag of Words, pronoun and punctuation. Empirical evaluations have shown that textual features are the most informative predictors for cyberbullying detection. For instance, using number of offensive terms as content features is effective in detecting offensive and cursing behavior; Computing content similarity between tweets from different users can help capture users’ personality traits and peer influence, two important factors of cyberbullying occurrences. Sentiment-based features typically include key-words, phrases and emojis, and they are often combined with content-based features. A notable workidentified seven types of emotions in tweets such as anger, empathy, and fear. User-based features are typical characteristics of users, e.g., personality (e.g., hostility), demographics (e.g., age), and user activity (e.g., active users). Hostility and neuroticism are found to be strongly related to cyberbullying behavior. Further, gender and age are indicative of cyberbullying in certain cases. Network-based features measure the sociability of online users, e.g., number of friends, followers, and network embeddedness. In addition, a number of methods seek to capture the temporal dynamics to characterize the repetition of cyberbullying, such as.
Bias Detection
Compared to the well-defined notions of fairness, bias detection is much less studied and the solution is not as straightforward as it may seem. The challenges arise from various perspectives. First, the data and algorithms used to make a decision are often not available to policy makers or enforcement agents. Second, algorithms are becoming increasingly complex and the uninterpretability limits an investigator’s ability to identify systematic discrimination through analysis of algorithms. Rather, they have to examine the output from algorithms to check for anomalous results, increasing the difficulty and uncertainty of the task.
Data exploratory analysis is a simple but effective tool to detect data bias. In this initial step of data analysis, we can use basic data statistics and visual exploration to understand what is in a dataset and the characteristics of the data. For algorithmic bias, one of the earliest methods is to compare the selection rate of different groups. Discrimination is highly possible if the selection rate for one group is sufficiently lower than that for other groups. For example, the US Equal Employment Opportunity Commission (EEOC) advocates the “four-fifths rule” or “80% rule”to identify a disparate impact. Suppose $Y$ denotes a binary class (e.g., hire or not), $A$ is the protected attribute (e.g., gender), a dataset presents disparate impact if
\[ \frac{Pr(Y=1|A=0)}{Pr(Y=1|A=1)} \leq \tau =0.8. \]However, statistical disparity does not necessarily indicate discrimination. If one group has disproportionately more qualified members, we may expect the differences between groups in the results.
A more frequently used approach is regression analysis, which is performed to examine the likelihood of favorable (or adverse) decisions across groups based on sensitive attributes. A significant, non-zero coefficient of the sensitive attributes given a correctly specified regression signals the presence of discrimination. However, we cannot guarantee to observe all the factors the decision maker considers. Therefore, instead of using rate at which decisions are made (e.g., the loan approval rates), bias detection can be based on the success rate of the decisions (e.g., the payback rate of the approved applicants), i.e., the outcome test . Another less popular statistical approach for bias detection is benchmarking. The major challenge of benchmarking analysis is identifying the distribution of the sensitive attributes of the benchmark population where sensitive attributes are unlikely to influence the identification of being at-risk. Some solutions can be seen in. Recently, AI researchers have developed tools to automatically detect bias. For instance, drawing on techniques in natural language processing and moral foundation theories, the tool by mokhberian2020moral can understand structure and nuances of content consistently showing up on left-leaning and right-leaning news sites, aiming to help consumers better prepare for unfamiliar news source. In earlier efforts, an international research group launched a non-profit organization Project Implicit[https://implicit.harvard.edu/implicit] in 1998 aimed at detecting implicit social bias.
Preventing/Mitigating
If both of the first two dimensions fail, we may rely on the last dimension to prevent/mitigate the negative impact of socially indifferent AI algorithms on the end-users. We continue the discussions about disinformation, cyberbullying, and bias, with a focus on the prevention and mitigation strategies.
Disinformation Prevention/Mitigation
Preventing the generation/spread of disinformation and mitigating its negative impact is an urgent task because disinformation typically spread fasterthan normal information due to the catchy news content and the ranking algorithms operating behind the online news platforms. To increase user engagement, social recommender systems are designed to recommend popular posts and trending content. Therefore, disinformation often gains more visibility. An effective approach for disinformation mitigation is to govern this visibility of news, e.g., recommendation and ranking based algorithms. Mitigation also relates to early detection.
Network intervention can slow down the spread of disinformation by influencing the exposed users in a social network. For example, we can launch a counter-cascade that consists of fact-checked version of false news articles. This is commonly referred to as the influence limitation or minimization problem. Given a network with accessible counter-cascade, the goal is to find a (minimum) set of nodes in this network such that the effect of the original cascade can be minimized. A variety of approximation algorithmshave been proposed to solve the NP-hard problem and the variants. When applied to disinformation mitigation, they seek to inoculate as many nodes as possible in a short period of time. It is possible to extend the two cascades into tasks with multiple cascades, where we can further consider the different priorities of these cascades, i.e., each cascade influences the node in the network differently. The second method for disinformation mitigation is content flagging: social media platforms allow users to flag' or report’ a news content if they find it offensive, harmful, and/or false. Big social media companies such as Facebook hired professional moderators to manually investigate and/or remove these content. However, considering the millions of news generated/spread every minute, it is impractical for these moderators to manually review all the news. The solution comes to the crowd wisdom – users can choose to `flag’ the content if it violates the community guidelines of the platform. Some platforms can further provide feedback for these users about if their fact-check is correct or not. User behavior is an effective predictor for disinformation detection, therefore, the third prevention method leverages the differences between user behaviors to identify susceptible or gullible users. For example, it is shown inthat groups of vulnerable Twitter users can be identified in fake news consumption. Other studiesalso suggest that older people are more likely to spread disinformation.
Cyberbullying Prevention/Mitigation
In contrast to the large amount of work in cyberbullying detection, efforts for its prevention and mitigation have been a few. Some research suggests that prevention/mitigation strategies are defined at different levels. At technological level, we can consider providing parental control service, firewall blocking service, online services rules, text-message control, and mobile parental control, e.g., KnowBullying and BullyBlocker. Another effective tool is psychological approach, such as talking and listening to cyber-victims, providing counseling services, encouraging victims to make new relations and join social clubs. At education level, we are responsible to educate end-users, help improve their technical and cognitive skills. At administrative level, it is important for organizations and government to develop policies to regulate using free service and enhance workplace environment. Therefore, the goal of cyberbullying prevention/mitigation can only be accomplished with interdisciplinary collaborations, e.g., psychology, public health, computer science, and other behavioral and social sciences. One example is that computer and social scientists attempted to understand behavior of users in realistic environments by designing social media site for experimentation such as controlled study and post-study survey.
Existing solutions to preventing cyberbullying can report/control/warn about message content (e.g., dinakar2012common,vishwamitra2017mcdefender), provide support for victims (e.g., vishwamitra2017mcdefender), and educate both victims and bullies (e.g., dinakar2012common). A variety of anti-bully apps are also available to promote well-being of users. For example, NoMoreBullyingMe App provides online meditation techniques to support victims; “Honestly” Appencourages users to share positive responses with each other (e.g., sing a song). However, current cyberbullying prevention strategies often do not work as desired because of the complexity and nuance with which adolescents bully others online.
Bias Mitigation
Prior approaches for bias mitigation focus on either designing fair machine learning algorithms or theorizing on the social and ethical aspects of machine learning discrimination. From the technical aspect, approaches to fairness typically can be categorized into pre-processing (prior to modelling), in-processing (at the point of modelling), and post-processing (after modelling). One condition to use pre-processing approaches is that the algorithm is allowed to modify the training data. We can then transform the data to remove the discrimination. In-processing approaches eliminate bias by modifying algorithms during the training process. We can either incorporate fairness notion into the objective function or impose fairness constraint. When neither training data nor model can be modified, we can use post-processing approaches to reassign the predicted labels based on a defined function and a holdout set which was not used in the model training phase. Most of these approaches are built on the notion of protected or sensitive variables that define the (un)privileged groups. Commonly used protected variables are age, gender, marital status, race, and disabilities. A shared characteristic of these groups is they are disproportionately (less) more likely to be positively classified. Fairness measures are important to quantify fairness in the development of fairness approaches. However, creating generalized notions of fairness quantification is a challenging task. Depending on the protected target, fairness metrics are usually designed for individual fairness (e.g., every one is treated equally), group fairness (e.g., different groups such as women vs men are treated equally), or subgroup fairness. Drawing on theories in causal inference, individual fairness also includes counterfactual fairness which describes that a decision is fair towards an individual if the result was same when s/he had taken a different sensitive attribute.
Recent years have witnessed immense progress of fair machine learning – a variety of methods have been proposed to address bias and discrimination over different applications. We focus on two mainstream methods: fair classification and fair regression. A review of machine learning fairness can be referred to.
(1) Fair Classification. For a (binary) classifier with sensitive variable $S$ , the target variable $Y$ , and the classification score $R$ , general fairness desiderata have three “non-discrimination” criteria: Independence , i.e., $R\indep S$ ; Separation , i.e., $R\indep S|Y$ ; and Sufficiency , i.e., $Y\indep S | R$ . Fair machine learning algorithms need to adopt/create specific fairness definitions that fit into context. Common methods in fair classification include blinding, causal methods, transformation, sampling and subgroup analysis, adversarial learning, reweighing, and regularization and constraint optimization.
(2) Fair Regression. The goal of fair regression is to jointly minimize the difference between true and predicted values and ensure fairness. It follows the general formulation of fair classification but with continuous rather than binary/categorical target variable. Accordingly, the fairness definition, metrics, and the basic algorithms are adapted from classification to regression. For example, it is suggested using statistical parity and bounded-group-loss metrics to measure fairness in regression. Bias in linear regression is considered as the effects of a sensitive attribute on the target variable through the mean difference between groups and AUC metrics. One commonly used approach in fair regression is regularization, e.g.,.
Apart from fair machine learning, algorithm operators are encouraged to share enough details about how research is carried out to allow others to replicate it. This is a leap for mitigating bias as it helps end-users with different technical background to understand how the algorithm works before making any decision. It is also suggested that AI technologists and researchers develop a bias impact statement as a self-regulatory practice. It can help probe and avert any potential biases that are injected into or resultant from algorithmic decision. Some example questions in the statement are “What will the automated decision do?”, “How will potential bias be detected?”, and “What are the operator incentives”. In algorithm design, researchers are also responsible to encourage the role of diversity within the team, training data, and the level of cultural sensitivity. The “diversity-in-design” mechanism aims to take deliberate and transparent actions to address the upfront cultural biases and stereotypes. Furthermore, we might also consider updating nondiscrimination and other civil rights laws to interpret and redress online disparate impacts. An example of such consideration is to unambiguously define the thresholds and parameters for the disparate treatments of protected groups before the algorithm design.
Open Problems and Challenges
This survey reveals that the current understanding of SRAs is insufficient and future efforts are in great need. Here, we describe several primary challenges, as summarized in Figure challenges, in an attempt to broaden the discussions on future directions and potential solutions.
Causal Learning. The correlation fallacy causes AI algorithms to meet with fundamental obstacles in order to commit social responsibility. These obstacles are robustness, explainability, and cause-effect connections. The era of big data has changed the ways of learning causality, and meanwhile, causal learning becomes an indispensable ingredient for AI systems to achieve human-level intelligence. There are a number of benefits to incorporate causality in the next-generation of AI. For example, teaching AI algorithms to understand “why” can help them transfer their knowledge to different but similar domains. Early efforts in SRAs attempted to employ causal learning concept and methods such as intervention, counterfactual, do -calculus, propensity scoring to address fairness (e.g., counterfactual fairness) and interpretability (causal interpretability) issues. They have shown prominent results in these tasks.
Context Matters. Context is the core to SRAs due to its inherently elaborate nature, e.g., the “Transparency Paradox”. Understanding and quantifying the relationships among the various principles (some are tradeoffs and some are not), e.g., fairness, transparency, and safety, have to be placed in specific context. One such context is the social context . Existing SRAs (e.g., fair machine learning), once introduced into a new social context, may render current technical interventions ineffective, inaccurate, and even dangerously misguided. A recent studyfound that while fair ranking algorithms such as Det-Greedyhelp increase the exposure of minority candidates, their effectiveness is limited by the job contexts in which employers have a preference to particular genders. How to properly integrate social context into SRAs is still an open problemAlgorithmic context_ (e.g., supervised learning, unsupervised learning, and reinforcement learning) is also extremely important when designing SRAs for the given data. A typical example is the feedback loop problem in predictive policing. A subtle algorithmic choice can have huge ramifications on the results. Consequently, we need to understand the algorithmic context to make the right algorithmic choices when designing socially responsible AI systems. Designing context-aware SRAs is the key to achieving Social Responsibility of AI.
Responsible Model Release and Governance. Nontransparent model reporting is one of the main causes of AI indifferent behaviors. As a critical step to clarify the intended use cases of AI systems and the contexts for which they are well suited, responsible model release and governance has been receiving growing attentions from both industry and academia. One role of SRAs is to bring together the tools, solutions, practices, and people to govern the built AI systems across its life cycle. At this early stage, some research results suggested that released models be accompanied by documentation detailing various characteristics of the systems, e.g., what it does, how it works, and why it matters. For example, the AI FactSheetsadvocates to use a factsheet completed and voluntarily released by AI developers to increase the transparency of their services. A similar concept is model cards, short documents that provide benchmarked evaluation for the trained AI models in a variety of conditions, e.g., different cultural or demographic groups. Typically, a model card should include the model details, intended use, evaluation metrics, training/evaluation data, ethical considerations, and caveats and recommendations. To help increase transparency, manage risk, and build trust in AI, AI technologists and researchers are responsible to address various challenges faced in creating useful AI release documentationand develop effective AI governance tools.
AI Defenses. Developing AI systems that outwit malicious AI is still at an early stage. Since we have not fully understood how AI systems work, they are not only vulnerable to attack but also likely to fail in surprising ways. As a result, it is critical and urgent to work on designing systems that are provably robust to help ensure that the AI systems are not vulnerable to adversaries. At least two capabilities an “AI firewall” needs to be equipped with: one capability is to probe an AI algorithm for weaknesses (e.g., perturb the input of an AI system to make it misbehave) and the other one is to automatically intercept potentially problematic inputs. Some big tech companies have started building their own AI defenses to identify the weak spots, e.g., the “red team” in Facebook, the software framework released by Microsoft, Nvidia, IBM, and 9 other companies. AI defenses reflect the fundamental weakness in modern AI and make AI systems more robust and intelligent.
AI Ethics Principles and Policies. Current AI principles and policies for ethical practice have at least two common criticisms: (1) they are too vaguely formulated to prove to be helpful in guiding practice; and (2) they are defined primarily by AI researchers and powerful people with mainstream populations in mind. For the first criticism, to help operationalize AI principles in practice and organizations confront inevitable value trade-offs, it has been suggested to redefine AI principles based on philosophical theories in applied ethics. Particularly, it categorizes published AI principles (e.g., fairness, accountability, and transparency) into three widely used core principles in applied ethics: autonomy, beneficence (avoiding harm and doing good), and justice. The core principles “invoke those values that theories in moral and political philosophy argue to be intrinsically valuable, meaning their value is not derived from something else”. Existing AI principles are instrumental principles that “build on concepts whose values are derived from their instrumental effect in protecting and promoting intrinsic values”. Operationazable AI principles help effectively put ethical AI in practice and reduce the responsible AI Gap in companies. To address the second criticism, we need to best elicit the inputs and values of diverse voices from the Subjects of SRAs, i.e., the minority and disadvantaged groups, and incorporate their perspectives into the tech policy document design process. If we align values of AI systems through a panel of people (who are compensated for doing this), they too can influence the system behavior, and not just the powerful people or AI researchers.
Understanding Why . Many AI systems are designed and developed without fully understanding why : What do we wish the AI system do? This is often the reason that these systems fail to represent the goals of the real tasks, a primary source of AI risks. The problem can become more challenging when the AI system is animated through a number of lines of code that lack nuance, creating a machine that does not align with our true intentions. As the first step, understanding why clearly defines our social expectation of AI systems and paves way for more specific questions such as “What is the problem? Who will define it? and what are the right people to include?”. Answering why helps us effectively abolish the development of socially indifferent AI systems in the first place and also helps understand the kinds of deception an AI system may learn by itself.
Long-Term Effect. SRAs include social concepts such as fairness that can evolve over time along with the constant changes of human values and social dynamics. This raises the concerns about the commitment SRAs need to fulfill in the long term. For example, despite the various types of fairness definitions, once introduced into the dimension of time, the number of fairness definitions may be explosive. In addition, current fairness criteria may be considered as unfair in the future. Fairness criteria are essentially designed to promote long-term well-being. However, even a static fairness notion can fail to protect the target groups when there is a feedback loop in the overall system. How to build AI systems that can commit long-term responsibility is extremely challenging and rarely studied thus far. Initial results of long-term fairnesshighlight the importance of measurement and temporal modeling in the evaluation of fairness criteria.
Humans in the Loop. While existing techniques in SRAs have indeed made significant progress towards responsible AI systems, their usefulness can be limited in some settings where the decisions made are actually poorer for every individual. For issues of fairness in prediction, for example, many findings (e.g., pfohl2020empirical) have shown the concerns about the fairness-performance trade-off: the imposition of fairness comes at a cost to model performance. Predictions are less reliable and moreover, different notions of fairness can make approaches to fairness conflict with one another. Having human in the loop matters when it comes to contextualizing the objectives of SRAs, especially for high-stake decisions. For instance, there are situations where the cut-off values of fairness for two subgroups are different, and humans can help calibrate the differences.
Responsible AI Gap in Industry. The far-reaching effect of reputational damage and employee disengagement result from AI misbehavior has forced company executives to begin understanding the risks of poorly designed AI systems and the importance of SRAs. While seeing many potential benefits of developing responsible AI systems such as increasing market share and long-term profitability, companies lack the knowledge of how to cross the “Responsible AI Gap” between principles and tangible actions. This is partly because companies view responsible AI solely as risk-avoidance mechanism and overlook its financial rewards. To capture the benefits of responsible AI in companies’ day-to-day business, companies need to go far beyond SRAs and examine every aspect of the end-to-end AI systems. A recent articlesuggested six basic steps to bridge the gulf between responsible AI and the reality: Empower responsible AI leadership, Develop principles, policies, and training, Establish human and AI governance, Conduct Responsible AI reviews, Integrate tools and methods, and Build and test a response plan . Even though the gap might be huge, small efforts built over time can let SRAs achieve a transformational impact on the businesses.
Interdisciplinary Research. Current public dialog on SRAs has been focused on a narrow subset of fields, blinding us to the opportunities presented by interdisciplinary research. It is necessary to work with researchers from different disciplines whose contributions are sorely needed, e.g., psychologist, social scientist, educators, and humanities. Non-profit organizations are both the beneficiaries and benefactors of SRAs. In partnering with non-profits and social enterprises will not only unleash AI’s potential for benefiting societal well-being, but also let AI technologists and researchers have the opportunity to encounter the real problems we are currently facing. A better understanding of what problems need to be solved helps identify SRAs that need to be created. Moreover, as big tech companies bankroll more work of academic researchers, much of ethics-based research gets concentrated in the hands of a few companies that can afford it. This is problematic because we are over reliant on the same companies that are producing socially indifferent AI systems. We need interdisciplinary and decentralized research to create SRAs and simultaneously achieve the four levels in the pyramid of Social Responsibility of AI.
SRAs for Social Good. The last challenge regards the intended use of SRAs. When SRAs are leveraged to uplift humanity, a trust in AI is further enhanced. There has been a burgeoning of AI-for-social-good movement that produces AI algorithms to help reduce poverty, hunger, inequality, injustice, climate change, ill health, and other causes of human suffering. Compared to deploying cutting-edge AI systems to solve these critical issues, a more urgent question to examine is “What makes an AI project good” in order to prevent the detrimental consequences of AI. In addition to Protecting, Informing, and Preventing, social good applications also relate closely to Fundraise and Greenlight. Applying SRAs to target solicitations for donations largely helps with fundraising for non-profits, charitable organizations, and universities. Greenlight describes how SRAs can help allocate grants and other types of resources by predicting the success rates of project proposals. It plays an important role in improving execution effectiveness of organizations. Developing social good applications that leverage power of SRAs to benefit society is an equally endeavor for AI technologists and researchers.
Conclusion
This survey examines multiple dimensions of research in Social Responsibility of AI, seeking to broaden the current discussions primarily focused on decision-making algorithms that perform scoring and classification tasks. We argue that having a full scope of AI to capture the connections among all the major dimensions is the key to Socially Responsible AI Algorithms (SRAs). This work starts with an inclusive definition of Social Responsibility of AI, highlighting the principles (e.g., Fairness, Inclusiveness), means (e.g., SRAs), and objective (e.g., improving humanity). To better frame the Social Responsibility of AI, we also introduce the pyramid with four-level responsibilities of AI systems: functional responsibilities, legal responsibilities, ethical responsibilities, and philanthropic responsibilities. We then focus our discussions on how to achieve Social Responsibility of AI via the proposed framework SRAs. In the definition of SRAs, we emphasize that the functional and societal aspects are integral parts of AI algorithms. Given that both the functional and legal responsibilities are the usual focuses in AI research and development, we particularly investigate the essentials to achieve AI’s ethical responsibilities: the subjects, causes, objectives, and means. For the intended use (i.e., roles) of SRAs, we discuss the need of philanthropic and ethical responsibilities for AI systems to protect and inform users, and prevent/mitigate the negative impact. We conclude with several open problems and major challenges in SRAs. At this pivotal moment in the development of AI, it is of vital importance to discuss AI ethics and specify Social Responsibility of AI. Drawing from the theory of moral license– when humans are good, we give ourselves moral license to be bad – we argue that simply asking AI to do good is insufficient and inefficient, and more can be done for AI technologists and researchers to develop socially responsible AI systems. We hope this work can propel future research in various fields to tackle together the challenges and steer a course towards a beneficial AI future.
Acknowledgements
This material is based upon work supported by, or in part by, the U.S. Army Research Laboratory (ARL), the U.S. Army Research Office (ARO), the Office of Naval Research (ONR) under contract/grant numbers W911NF2110030, W911NF2020124, and N00014-21-1-4002, as well as by the National Science Foundation (NSF) grants 1909555 and 2036127. We thank Dr. Lise Getoor and Dr. Hosagrahar V. Jagadish for their invaluable suggestions. 0.2in
Bibliography
1@article{angwin2016machine,
2 year = {2016},
3 pages = {2016},
4 volume = {23},
5 journal = {ProPublica, May},
6 author = {Angwin, Julia and Larson, Jeff and Mattu, Surya and Kirchner, Lauren},
7 title = {Machine bias},
8}
9
10@article{angwin2015tiger,
11 year = {2015},
12 pages = {2015},
13 volume = {1},
14 journal = {Retrieved September},
15 author = {Angwin, Julia and Larson, Jeff},
16 title = {The tiger mom tax: Asians are nearly twice as likely to get a higher price from Princeton review},
17}
18
19@article{dwork2014algorithmic,
20 year = {2014},
21 pages = {211--407},
22 number = {3-4},
23 volume = {9},
24 journal = {FnT-TCS},
25 author = {Dwork, Cynthia and Roth, Aaron and others},
26 title = {The algorithmic foundations of differential privacy.},
27}
28
29@inproceedings{selbst2019fairness,
30 year = {2019},
31 pages = {59--68},
32 booktitle = {FAT*},
33 author = {Selbst, Andrew D and Boyd, Danah and Friedler, Sorelle A and Venkatasubramanian, Suresh and Vertesi, Janet},
34 title = {Fairness and abstraction in sociotechnical systems},
35}
36
37@book{peters2017elements,
38 publisher = {The MIT Press},
39 year = {2017},
40 author = {Peters, Jonas and Janzing, Dominik and Sch{\"o}lkopf, Bernhard},
41 title = {Elements of causal inference},
42}
43
44@inproceedings{suter2019robustly,
45 organization = {PMLR},
46 year = {2019},
47 pages = {6056--6065},
48 booktitle = {ICML},
49 author = {Suter, Raphael and Miladinovic, Djordje and Sch{\"o}lkopf, Bernhard and Bauer, Stefan},
50 title = {Robustly disentangled causal mechanisms: Validating deep representations for interventional robustness},
51}
52
53@misc{bengio2019meta,
54 year = {2019},
55 journal = {arXiv preprint arXiv:1901.10912},
56 author = {Bengio, Yoshua and Deleu, Tristan and Rahaman, Nasim and Ke, Rosemary and Lachapelle, S{\'e}bastien and Bilaniuk, Olexa and Goyal, Anirudh and Pal, Christopher},
57 title = {A meta-transfer objective for learning to disentangle causal mechanisms},
58}
59
60@misc{arjovsky2019invariant,
61 year = {2019},
62 journal = {arXiv preprint arXiv:1907.02893},
63 author = {Arjovsky, Martin and Bottou, L{\'e}on and Gulrajani, Ishaan and Lopez-Paz, David},
64 title = {Invariant risk minimization},
65}
66
67@misc{scholkopf2019causality,
68 year = {2019},
69 journal = {arXiv preprint arXiv:1911.10500},
70 author = {Sch{\"o}lkopf, Bernhard},
71 title = {Causality for machine learning},
72}
73
74@article{chen2018lifelong,
75 publisher = {Morgan \& Claypool Publishers},
76 year = {2018},
77 pages = {1--207},
78 number = {3},
79 volume = {12},
80 journal = {Synthesis Lectures on Artificial Intelligence and Machine Learning},
81 author = {Chen, Zhiyuan and Liu, Bing},
82 title = {Lifelong machine learning},
83}
84
85@techreport{hosen2015prediction,
86 institution = {Deakin Univeristy},
87 year = {2015},
88 author = {Hosen, Mohammad Anwar},
89 title = {Prediction interval-based modelling and control of nonlinear processes},
90}
91
92@article{ho2001neural,
93 publisher = {IEEE},
94 year = {2001},
95 pages = {323--332},
96 number = {4},
97 volume = {24},
98 journal = {IEEE Transactions on Electronics Packaging Manufacturing},
99 author = {Ho, SL and Xie, M and Tang, LC and Xu, K and Goh, TN},
100 title = {Neural network modeling with confidence bounds: a case study on the solder paste deposition process},
101}
102
103@article{young2019toward,
104 publisher = {Springer},
105 year = {2019},
106 pages = {89--103},
107 number = {2},
108 volume = {21},
109 journal = {Ethics and Information Technology},
110 author = {Young, Meg and Magassa, Lassana and Friedman, Batya},
111 title = {Toward inclusive tech policy design: a method for underrepresented voices to strengthen tech policy documents},
112}
113
114@inproceedings{hind2020experiences,
115 year = {2020},
116 pages = {1--8},
117 booktitle = {Extended Abstracts of the 2020 CHI Conference on Human Factors in Computing Systems},
118 author = {Hind, Michael and Houde, Stephanie and Martino, Jacquelyn and Mojsilovic, Aleksandra and Piorkowski, David and Richards, John and Varshney, Kush R},
119 title = {Experiences with Improving the Transparency of {AI} Models and Services},
120}
121
122@article{arnold2019factsheets,
123 publisher = {IBM},
124 year = {2019},
125 pages = {6--1},
126 number = {4/5},
127 volume = {63},
128 journal = {IBM Journal of Research and Development},
129 author = {Arnold, Matthew and Bellamy, Rachel KE and Hind, Michael and Houde, Stephanie and Mehta, Sameep and Mojsilovi{\'c}, Aleksandra and Nair, Ravi and Ramamurthy, K Natesan and Olteanu, Alexandra and Piorkowski, David and others},
130 title = {FactSheets: Increasing trust in {AI} services through supplier's declarations of conformity},
131}
132
133@inproceedings{ungar1996estimating,
134 year = {1996},
135 booktitle = {Proc. of the 9th Yale WALS},
136 author = {Ungar, Lyle H and De Veaux, Richard D and Rosengarten, Evelyn},
137 title = {Estimating prediction intervals for artificial neural networks},
138}
139
140@misc{dybowski2001confidence,
141 publisher = {Cambridge Univ. Press},
142 year = {2001},
143 pages = {298--326},
144 journal = {Clinical Applications of ANNs},
145 author = {Dybowski, Richard and Roberts, Stephen J},
146 title = {Confidence intervals and prediction intervals for feed-forward neural networks},
147}
148
149@article{zio2006study,
150 publisher = {IEEE},
151 year = {2006},
152 pages = {1460--1478},
153 number = {3},
154 volume = {53},
155 journal = {IEEE Transactions on Nuclear Science},
156 author = {Zio, Enrico},
157 title = {A study of the bootstrap method for estimating the accuracy of artificial neural networks in predicting nuclear transient processes},
158}
159
160@article{khosravi2014constructing,
161 publisher = {IEEE},
162 year = {2014},
163 pages = {1810--1815},
164 number = {8},
165 volume = {26},
166 journal = {IEEE Transactions on Neural Networks and Learning Systems},
167 author = {Khosravi, Abbas and Nahavandi, Saeid and Srinivasan, Dipti and Khosravi, Rihanna},
168 title = {Constructing optimal prediction intervals by using neural networks and bootstrap method},
169}
170
171@inproceedings{marin2016prediction,
172 organization = {IEEE},
173 year = {2016},
174 pages = {328--335},
175 booktitle = {2016 FUZZ-IEEE},
176 author = {Mar{\'\i}n, Luis G and Valencia, Felipe and S{\'a}ez, Doris},
177 title = {Prediction interval based on type-2 fuzzy systems for wind power generation and loads in microgrid control design},
178}
179
180@article{quan2014particle,
181 publisher = {Elsevier},
182 year = {2014},
183 pages = {172--180},
184 volume = {127},
185 journal = {Neurocomputing},
186 author = {Quan, Hao and Srinivasan, Dipti and Khosravi, Abbas},
187 title = {Particle swarm optimization for construction of neural network-based prediction intervals},
188}
189
190@article{hosen2014improving,
191 publisher = {IEEE},
192 year = {2014},
193 pages = {4420--4429},
194 number = {7},
195 volume = {62},
196 journal = {IEEE Transactions on Industrial Electronics},
197 author = {Hosen, Mohammad Anwar and Khosravi, Abbas and Nahavandi, Saeid and Creighton, Douglas},
198 title = {Improving the quality of prediction intervals through optimal aggregation},
199}
200
201@article{wan2013probabilistic,
202 publisher = {IEEE},
203 year = {2013},
204 pages = {1033--1044},
205 number = {3},
206 volume = {29},
207 journal = {IEEE Transactions on Power Systems},
208 author = {Wan, Can and Xu, Zhao and Pinson, Pierre and Dong, Zhao Yang and Wong, Kit Po},
209 title = {Probabilistic forecasting of wind power generation using extreme learning machine},
210}
211
212@article{chu2015real,
213 publisher = {Elsevier},
214 year = {2015},
215 pages = {234--244},
216 volume = {83},
217 journal = {Renewable Energy},
218 author = {Chu, Yinghao and Li, Mengying and Pedro, Hugo TC and Coimbra, Carlos FM},
219 title = {Real-time prediction intervals for intra-hour DNI forecasts},
220}
221
222@inproceedings{errouissi2015bootstrap,
223 organization = {IEEE},
224 year = {2015},
225 pages = {1919--1924},
226 booktitle = {2015 IEEE ECCE},
227 author = {Errouissi, Rachid and Cardenas-Barrera, Julian and Meng, Julian and Castillo-Guerra, Eduardo and Gong, Xun and Chang, Liuchen},
228 title = {Bootstrap prediction interval estimation for wind speed forecasting},
229}
230
231@article{kasiviswanathan2016comparison,
232 publisher = {Springer},
233 year = {2016},
234 pages = {22},
235 number = {1},
236 volume = {2},
237 journal = {Modeling Earth Systems and Environment},
238 author = {Kasiviswanathan, KS and Sudheer, KP},
239 title = {Comparison of methods used for quantifying prediction interval in artificial neural network hydrologic models},
240}
241
242@article{lu2009prediction,
243 publisher = {Springer},
244 year = {2009},
245 pages = {345},
246 number = {4},
247 volume = {18},
248 journal = {Neural Computing and Applications},
249 author = {Lu, Tao and Viljanen, Martti},
250 title = {Prediction of indoor temperature and relative humidity using neural network models: model comparison},
251}
252
253@article{hwang1997prediction,
254 publisher = {Taylor \& Francis},
255 year = {1997},
256 pages = {748--757},
257 number = {438},
258 volume = {92},
259 journal = {Journal of the American Statistical Association},
260 author = {Hwang, JT Gene and Ding, A Adam},
261 title = {Prediction intervals for artificial neural networks},
262}
263
264@inproceedings{staahl2020evaluation,
265 organization = {Springer},
266 year = {2020},
267 pages = {556--568},
268 booktitle = {IPMU},
269 author = {St{\aa}hl, Niclas and Falkman, G{\"o}ran and Karlsson, Alexander and Mathiason, Gunnar},
270 title = {Evaluation of Uncertainty Quantification in Deep Learning},
271}
272
273@article{kabir2018neural,
274 publisher = {IEEE},
275 year = {2018},
276 pages = {36218--36234},
277 volume = {6},
278 journal = {IEEE Access},
279 author = {Kabir, HM Dipu and Khosravi, Abbas and Hosen, Mohammad Anwar and Nahavandi, Saeid},
280 title = {Neural network-based uncertainty quantification: A survey of methodologies and applications},
281}
282
283@misc{beale2019unethical,
284 year = {2019},
285 journal = {arXiv preprint arXiv:1911.05116},
286 author = {Beale, Nicholas and Battey, Heather and Davison, Anthony C and MacKay, Robert S},
287 title = {An Unethical Optimization Principle},
288}
289
290@inproceedings{ensign2018runaway,
291 year = {2018},
292 pages = {160--171},
293 booktitle = {FAT*},
294 author = {Ensign, Danielle and Friedler, Sorelle A and Neville, Scott and Scheidegger, Carlos and Venkatasubramanian, Suresh},
295 title = {Runaway feedback loops in predictive policing},
296}
297
298@inproceedings{kairouz2014extremal,
299 year = {2014},
300 pages = {2879--2887},
301 booktitle = {NeurIPS},
302 author = {Kairouz, Peter and Oh, Sewoong and Viswanath, Pramod},
303 title = {Extremal mechanisms for local differential privacy},
304}
305
306@inproceedings{erlingsson2014rappor,
307 year = {2014},
308 pages = {1054--1067},
309 booktitle = {CCS},
310 author = {Erlingsson, {\'U}lfar and Pihur, Vasyl and Korolova, Aleksandra},
311 title = {Rappor: Randomized aggregatable privacy-preserving ordinal response},
312}
313
314@inproceedings{varodayan2011smart,
315 organization = {IEEE},
316 year = {2011},
317 pages = {1932--1935},
318 booktitle = {ICASSP},
319 author = {Varodayan, David and Khisti, Ashish},
320 title = {Smart meter privacy using a rechargeable battery: Minimizing the rate of information leakage},
321}
322
323@article{goldwasser1984probabilistic,
324 publisher = {Elsevier},
325 year = {1984},
326 pages = {270--299},
327 number = {2},
328 volume = {28},
329 journal = {JCSS},
330 author = {Goldwasser, Shafi and Micali, Silvio},
331 title = {Probabilistic encryption},
332}
333
334@inproceedings{gentry2009fully,
335 year = {2009},
336 pages = {169--178},
337 booktitle = {STOC},
338 author = {Gentry, Craig},
339 title = {Fully homomorphic encryption using ideal lattices},
340}
341
342@inproceedings{makri2019epic,
343 organization = {Springer},
344 year = {2019},
345 pages = {473--492},
346 booktitle = {CT-RSA},
347 author = {Makri, Eleftheria and Rotaru, Dragos and Smart, Nigel P and Vercauteren, Frederik},
348 title = {{EPIC}: efficient private image classification (or: Learning from the masters)},
349}
350
351@misc{malekzadeh2019mobile,
352 year = {2019},
353 pages = {49--58},
354 booktitle = {IoTDI},
355 author = {Malekzadeh, Mohammad and Clegg, Richard G and Cavallaro, Andrea and Haddadi, Hamed},
356 title = {Mobile sensor data anonymization},
357}
358
359@inproceedings{malekzadeh2018protecting,
360 year = {2018},
361 pages = {1--6},
362 booktitle = {Proceedings of the 1st Workshop on Privacy by Design in Distributed Systems},
363 author = {Malekzadeh, Mohammad and Clegg, Richard G and Cavallaro, Andrea and Haddadi, Hamed},
364 title = {Protecting sensory data against sensitive inferences},
365}
366
367@misc{malekzadeh2020privacy,
368 publisher = {Elsevier},
369 year = {2020},
370 pages = {101132},
371 journal = {Pervasive and Mobile Computing},
372 author = {Malekzadeh, Mohammad and Clegg, Richard G and Cavallaro, Andrea and Haddadi, Hamed},
373 title = {Privacy and utility preserving sensor-data transformations},
374}
375
376@inproceedings{wang2018not,
377 year = {2018},
378 pages = {2407--2416},
379 booktitle = {KDD},
380 author = {Wang, Ji and Zhang, Jianguo and Bao, Weidong and Zhu, Xiaomin and Cao, Bokai and Yu, Philip S},
381 title = {Not just privacy: Improving performance of private deep learning in mobile cloud},
382}
383
384@inproceedings{gilad2016cryptonets,
385 year = {2016},
386 pages = {201--210},
387 booktitle = {ICML},
388 author = {Gilad-Bachrach, Ran and Dowlin, Nathan and Laine, Kim and Lauter, Kristin and Naehrig, Michael and Wernsing, John},
389 title = {Cryptonets: Applying neural networks to encrypted data with high throughput and accuracy},
390}
391
392@article{chabanne2017privacy,
393 year = {2017},
394 pages = {35},
395 volume = {2017},
396 journal = {IACR Cryptol. ePrint Arch.},
397 author = {Chabanne, Herv{\'e} and de Wargny, Amaury and Milgram, Jonathan and Morel, Constance and Prouff, Emmanuel},
398 title = {Privacy-Preserving Classification on Deep Neural Network.},
399}
400
401@inproceedings{liu2017oblivious,
402 year = {2017},
403 pages = {619--631},
404 booktitle = {CCS},
405 author = {Liu, Jian and Juuti, Mika and Lu, Yao and Asokan, Nadarajah},
406 title = {Oblivious neural network predictions via minionn transformations},
407}
408
409@book{pacepa2013disinformation,
410 publisher = {Wnd Books},
411 year = {2013},
412 author = {Pacepa, Ion Mihai and Rychlak, Ronald J},
413 title = {Disinformation: Former Spy Chief Reveals Secret Strategy for Undermining Freedom, Attacking Religion, and Promoting Terrorism},
414}
415
416@misc{bhattacharjee2020disinformation,
417 year = {2020},
418 journal = {arXiv preprint arXiv:2010.09113},
419 author = {Bhattacharjee, Amrita and Shu, Kai and Gao, Min and Liu, Huan},
420 title = {Disinformation in the Online Information Ecosystem: Detection, Mitigation and Challenges},
421}
422
423@inproceedings{feng2012syntactic,
424 year = {2012},
425 pages = {171--175},
426 booktitle = {ACL},
427 author = {Feng, Song and Banerjee, Ritwik and Choi, Yejin},
428 title = {Syntactic stylometry for deception detection},
429}
430
431@misc{ott2011finding,
432 year = {2011},
433 journal = {arXiv preprint arXiv:1107.4557},
434 author = {Ott, Myle and Choi, Yejin and Cardie, Claire and Hancock, Jeffrey T},
435 title = {Finding deceptive opinion spam by any stretch of the imagination},
436}
437
438@inproceedings{shu2019beyond,
439 year = {2019},
440 pages = {312--320},
441 booktitle = {WSDM},
442 author = {Shu, Kai and Wang, Suhang and Liu, Huan},
443 title = {Beyond news contents: The role of social context for fake news detection},
444}
445
446@inproceedings{shu2018understanding,
447 organization = {IEEE},
448 year = {2018},
449 pages = {430--435},
450 booktitle = {2018 IEEE MIPR},
451 author = {Shu, Kai and Wang, Suhang and Liu, Huan},
452 title = {Understanding user profiles on social media for fake news detection},
453}
454
455@article{shu2020fakenewsnet,
456 publisher = {Mary Ann Liebert, Inc., publishers 140 Huguenot Street, 3rd Floor New~…},
457 year = {2020},
458 pages = {171--188},
459 number = {3},
460 volume = {8},
461 journal = {Big Data},
462 author = {Shu, Kai and Mahudeswaran, Deepak and Wang, Suhang and Lee, Dongwon and Liu, Huan},
463 title = {FakeNewsNet: A Data Repository with News Content, Social Context, and Spatiotemporal Information for Studying Fake News on Social Media},
464}
465
466@inproceedings{della2018automatic,
467 organization = {IEEE},
468 year = {2018},
469 pages = {272--279},
470 booktitle = {2018 FRUCT},
471 author = {Della Vedova, Marco L and Tacchini, Eugenio and Moret, Stefano and Ballarin, Gabriele and DiPierro, Massimo and de Alfaro, Luca},
472 title = {Automatic online fake news detection combining content and social signals},
473}
474
475@misc{shu2020leveraging,
476 year = {2020},
477 journal = {arXiv preprint arXiv:2004.01732},
478 author = {Shu, Kai and Zheng, Guoqing and Li, Yichuan and Mukherjee, Subhabrata and Awadallah, Ahmed Hassan and Ruston, Scott and Liu, Huan},
479 title = {Leveraging Multi-Source Weak Social Supervision for Early Detection of Fake News},
480}
481
482@inproceedings{qian2018neural,
483 year = {2018},
484 pages = {3834--3840},
485 volume = {18},
486 booktitle = {IJCAI},
487 author = {Qian, Feng and Gong, Chengyue and Sharma, Karishma and Liu, Yan},
488 title = {Neural User Response Generator: Fake News Detection with Collective User Intelligence.},
489}
490
491@article{ciampaglia2015computational,
492 publisher = {Public Library of Science San Francisco, CA USA},
493 year = {2015},
494 pages = {e0128193},
495 number = {6},
496 volume = {10},
497 journal = {PloS One},
498 author = {Ciampaglia, Giovanni Luca and Shiralkar, Prashant and Rocha, Luis M and Bollen, Johan and Menczer, Filippo and Flammini, Alessandro},
499 title = {Computational fact checking from knowledge networks},
500}
501
502@article{janicka2019cross,
503 year = {2019},
504 number = {3},
505 volume = {23},
506 journal = {Computaci{\'o}n y Sistemas},
507 author = {Janicka, Maria and Pszona, Maria and Wawer, Aleksander},
508 title = {Cross-Domain Failures of Fake News Detection},
509}
510
511@inproceedings{shu2019defend,
512 year = {2019},
513 pages = {395--405},
514 booktitle = {KDD},
515 author = {Shu, Kai and Cui, Limeng and Wang, Suhang and Lee, Dongwon and Liu, Huan},
516 title = {d{EFEND}: Explainable fake news detection},
517}
518
519@article{vosoughi2018spread,
520 publisher = {AAAS},
521 year = {2018},
522 pages = {1146--1151},
523 number = {6380},
524 volume = {359},
525 journal = {Science},
526 author = {Vosoughi, Soroush and Roy, Deb and Aral, Sinan},
527 title = {The spread of true and false news online},
528}
529
530@inproceedings{rajabi2019user,
531 organization = {Springer},
532 year = {2019},
533 pages = {234--244},
534 booktitle = {SBP-BRiMS},
535 author = {Rajabi, Zahra and Shehu, Amarda and Purohit, Hemant},
536 title = {User behavior modelling for fake information mitigation on social web},
537}
538
539@misc{salawu2017approaches,
540 publisher = {IEEE},
541 year = {2017},
542 journal = {IEEE Transactions on Affective Computing},
543 author = {Salawu, Semiu and He, Yulan and Lumsden, Joanna},
544 title = {Approaches to automated detection of cyberbullying: A survey},
545}
546
547@misc{cheng2020session,
548 year = {2020},
549 journal = {IEEE Internet Computing, Special Issue on Cyber-Social Health: Promoting Good and Countering Harm on Social Media},
550 author = {Cheng, Lu and Silva, Yasin and Hall, Deborah and Liu, Huan},
551 title = {Session-based Cyberbullying Detection: Problems and Challenges},
552}
553
554@inproceedings{cheng2020unsupervised,
555 year = {2020},
556 booktitle = {CIKM},
557 author = {Cheng, Lu and Shu, Kai and Wu, Siqi and Silva, Yasin N and Hall, Deborah L and Liu, Huan},
558 title = {Unsupervised Cyberbullying Detection via Time-Informed Gaussian Mixture Model},
559}
560
561@article{guess2019less,
562 publisher = {AAAS},
563 year = {2019},
564 pages = {eaau4586},
565 number = {1},
566 volume = {5},
567 journal = {Science Advances},
568 author = {Guess, Andrew and Nagler, Jonathan and Tucker, Joshua},
569 title = {Less than you think: Prevalence and predictors of fake news dissemination on Facebook},
570}
571
572@inproceedings{budak2011limiting,
573 year = {2011},
574 pages = {665--674},
575 booktitle = {WWW},
576 author = {Budak, Ceren and Agrawal, Divyakant and El Abbadi, Amr},
577 title = {Limiting the spread of misinformation in social networks},
578}
579
580@inproceedings{nguyen2012containment,
581 year = {2012},
582 pages = {213--222},
583 booktitle = {Web Science},
584 author = {Nguyen, Nam P and Yan, Guanhua and Thai, My T and Eidenbenz, Stephan},
585 title = {Containment of misinformation spread in online social networks},
586}
587
588@inproceedings{tong2018misinformation,
589 year = {2018},
590 pages = {341--351},
591 booktitle = {NeurIPS},
592 author = {Tong, Amo and Du, Ding-Zhu and Wu, Weili},
593 title = {On misinformation containment in online social networks},
594}
595
596@inproceedings{cheng2021causal,
597 year = {2021},
598 booktitle = {KDD},
599 author = {Cheng, Lu and Guo, Ruocheng and Shu, Kai and Liu, Huan},
600 title = {Causal Understanding of Fake News Dissemination on Social Media},
601}
602
603@article{diaz2019robustness,
604 publisher = {IEEE},
605 year = {2019},
606 pages = {1949--1978},
607 number = {4},
608 volume = {66},
609 journal = {IEEE Transactions on Information Theory},
610 author = {Diaz, Mario and Wang, Hao and Calmon, Flavio P and Sankar, Lalitha},
611 title = {On the robustness of information-theoretic privacy measures and mechanisms},
612}
613
614@inproceedings{cheng2021mitigating,
615 year = {2021},
616 booktitle = {Proceedings of ACL},
617 author = {Cheng, Lu and Mosallanezhad, Ahmadreza and Silva, Yasin N and Hall, Deborah L and Liu, Huan},
618 title = {Mitigating Bias in Session-based Cyberbullying Detection: A Non-Compromising Approach},
619}
620
621@inproceedings{pinceti2019data,
622 organization = {IEEE},
623 year = {2019},
624 pages = {1--5},
625 booktitle = {2019 IEEE PESGM},
626 author = {Pinceti, Andrea and Kosut, Oliver and Sankar, Lalitha},
627 title = {Data-driven generation of synthetic load datasets preserving spatio-temporal features},
628}
629
630@misc{mehrabi2019survey,
631 year = {2019},
632 journal = {arXiv preprint arXiv:1908.09635},
633 author = {Mehrabi, Ninareh and Morstatter, Fred and Saxena, Nripsuta and Lerman, Kristina and Galstyan, Aram},
634 title = {A survey on bias and fairness in machine learning},
635}
636
637@inproceedings{narayanan2008robust,
638 organization = {IEEE},
639 year = {2008},
640 pages = {111--125},
641 booktitle = {2008 IEEE sp},
642 author = {Narayanan, Arvind and Shmatikov, Vitaly},
643 title = {Robust de-anonymization of large sparse datasets},
644}
645
646@inproceedings{dwork2006calibrating,
647 organization = {Springer},
648 year = {2006},
649 pages = {265--284},
650 booktitle = {Theory of Cryptography Conference},
651 author = {Dwork, Cynthia and McSherry, Frank and Nissim, Kobbi and Smith, Adam},
652 title = {Calibrating noise to sensitivity in private data analysis},
653}
654
655@article{homer2008resolving,
656 publisher = {Public Library of Science},
657 year = {2008},
658 pages = {e1000167},
659 number = {8},
660 volume = {4},
661 journal = {PLoS Genet},
662 author = {Homer, Nils and Szelinger, Szabolcs and Redman, Margot and Duggan, David and Tembe, Waibhav and Muehling, Jill and Pearson, John V and Stephan, Dietrich A and Nelson, Stanley F and Craig, David W},
663 title = {Resolving individuals contributing trace amounts of DNA to highly complex mixtures using high-density SNP genotyping microarrays},
664}
665
666@article{sweeney2002k,
667 publisher = {World Scientific},
668 year = {2002},
669 pages = {557--570},
670 number = {05},
671 volume = {10},
672 journal = {IJUFKS},
673 author = {Sweeney, Latanya},
674 title = {k-anonymity: A model for protecting privacy},
675}
676
677@article{cabanas2020does,
678 publisher = {ACM New York, NY, USA},
679 year = {2020},
680 pages = {62--69},
681 number = {1},
682 volume = {64},
683 journal = {Communications of the ACM},
684 author = {Caba{\~n}as, Jos{\'e} Gonz{\'a}lez and Cuevas, {\'A}ngel and Arrate, Aritz and Cuevas, Rub{\'e}n},
685 title = {Does Facebook use sensitive data for advertising purposes?},
686}
687
688@techreport{list2018corporate,
689 institution = {National Bureau of Economic Research},
690 year = {2018},
691 author = {List, John A and Momeni, Fatemeh},
692 title = {When corporate social responsibility backfires: Theory and evidence from a natural field experiment},
693}
694
695@inproceedings{getoor2019responsible,
696 organization = {IEEE},
697 year = {2019},
698 pages = {1--1},
699 booktitle = {Big Data},
700 author = {Getoor, Lise},
701 title = {Responsible Data Science},
702}
703
704@article{dinakar2012common,
705 publisher = {ACM New York, NY, USA},
706 year = {2012},
707 pages = {1--30},
708 number = {3},
709 volume = {2},
710 journal = {ACM TiiS},
711 author = {Dinakar, Karthik and Jones, Birago and Havasi, Catherine and Lieberman, Henry and Picard, Rosalind},
712 title = {Common sense reasoning for detection, prevention, and mitigation of cyberbullying},
713}
714
715@inproceedings{dadvar2013improving,
716 organization = {Springer},
717 year = {2013},
718 pages = {693--696},
719 booktitle = {ECIR},
720 author = {Dadvar, Maral and Trieschnigg, Dolf and Ordelman, Roeland and de Jong, Franciska},
721 title = {Improving cyberbullying detection with user context},
722}
723
724@inproceedings{kontostathis2013detecting,
725 year = {2013},
726 pages = {195--204},
727 booktitle = {Web Science},
728 author = {Kontostathis, April and Reynolds, Kelly and Garron, Andy and Edwards, Lynne},
729 title = {Detecting cyberbullying: query terms and techniques},
730}
731
732@inproceedings{cheng2019pi,
733 year = {2019},
734 pages = {5829--5835},
735 booktitle = {IJCAI},
736 author = {Cheng, Lu and Li, Jundong and Silva, Yasin N and Hall, Deborah L and Liu, Huan},
737 title = {{PI}-Bully: Personalized Cyberbullying Detection with Peer Influence.},
738}
739
740@inproceedings{biel2011you,
741 organization = {Citeseer},
742 year = {2011},
743 pages = {446--449},
744 booktitle = {ICWSM},
745 author = {Biel, Joan-Isaac and Aran, Oya and Gatica-Perez, Daniel},
746 title = {You are known by how you vlog: Personality impressions and nonverbal behavior in youtube.},
747}
748
749@article{mishna2012risk,
750 publisher = {Elsevier},
751 year = {2012},
752 pages = {63--70},
753 number = {1},
754 volume = {34},
755 journal = {Children and Youth Services Review},
756 author = {Mishna, Faye and Khoury-Kassabri, Mona and Gadalla, Tahany and Daciuk, Joanne},
757 title = {Risk factors for involvement in cyber bullying: Victims, bullies and bully--victims},
758}
759
760@article{al2016cybercrime,
761 publisher = {Elsevier},
762 year = {2016},
763 pages = {433--443},
764 volume = {63},
765 journal = {Computers in Human Behavior},
766 author = {Al-garadi, Mohammed Ali and Varathan, Kasturi Dewi and Ravana, Sri Devi},
767 title = {Cybercrime detection in online communications: The experimental case of cyberbullying detection in the Twitter network},
768}
769
770@misc{chen2020henin,
771 year = {2020},
772 journal = {arXiv preprint arXiv:2010.04576},
773 author = {Chen, Hsin-Yu and Li, Cheng-Te},
774 title = {HENIN: Learning Heterogeneous Neural Interaction Networks for Explainable Cyberbullying Detection on Social Media},
775}
776
777@inproceedings{ge2021improving,
778 year = {2021},
779 pages = {496--506},
780 booktitle = {Proceedings of the Web Conference 2021},
781 author = {Ge, Suyu and Cheng, Lu and Liu, Huan},
782 title = {Improving Cyberbullying Detection with User Interaction},
783}
784
785@inproceedings{ashktorab2016designing,
786 year = {2016},
787 pages = {3895--3905},
788 booktitle = {CHI},
789 author = {Ashktorab, Zahra and Vitak, Jessica},
790 title = {Designing cyberbullying mitigation and prevention solutions through participatory design with teenagers},
791}
792
793@inproceedings{al2013cyber,
794 organization = {IEEE},
795 year = {2013},
796 pages = {126--133},
797 booktitle = {ICCSIT},
798 author = {Al Mazari, Ali},
799 title = {Cyber-bullying taxonomies: Definition, forms, consequences and mitigation strategies},
800}
801
802@inproceedings{silva2016bullyblocker,
803 organization = {IEEE},
804 year = {2016},
805 pages = {1377--1379},
806 booktitle = {ASONAM},
807 author = {Silva, Yasin N and Rich, Christopher and Hall, Deborah},
808 title = {BullyBlocker: Towards the identification of cyberbullying in social networking sites},
809}
810
811@article{kraft2009effectiveness,
812 year = {2009},
813 number = {2},
814 volume = {3},
815 journal = {International Journal of Cyber Criminology},
816 author = {Kraft, Ellen M and Wang, Jinchang},
817 title = {Effectiveness of cyber bullying prevention strategies: A study on students' perspectives.},
818}
819
820@inproceedings{vishwamitra2017mcdefender,
821 year = {2017},
822 pages = {37--42},
823 booktitle = {CODASPY},
824 author = {Vishwamitra, Nishant and Zhang, Xiang and Tong, Jonathan and Hu, Hongxin and Luo, Feng and Kowalski, Robin and Mazer, Joseph},
825 title = {MCDefender: Toward effective cyberbullying defense in mobile online social networks},
826}
827
828@inproceedings{difranzo2018upstanding,
829 year = {2018},
830 pages = {1--12},
831 booktitle = {CHI},
832 author = {DiFranzo, Dominic and Taylor, Samuel Hardman and Kazerooni, Franccesca and Wherry, Olivia D and Bazarova, Natalya N},
833 title = {Upstanding by design: Bystander intervention in cyberbullying},
834}
835
836@article{beigi2020survey,
837 publisher = {ACM New York, NY, USA},
838 year = {2020},
839 pages = {1--38},
840 number = {1},
841 volume = {1},
842 journal = {ACM Transactions on Data Science},
843 author = {Beigi, Ghazaleh and Liu, Huan},
844 title = {A survey on privacy in social media: Identification, mitigation, and applications},
845}
846
847@phdthesis{ashktorab2017designing,
848 year = {2017},
849 author = {Ashktorab, Zahra},
850 title = {Designing Cyberbullying Prevention and Mitigation Tools},
851}
852
853@article{pearl2019seven,
854 publisher = {ACM New York, NY, USA},
855 year = {2019},
856 pages = {54--60},
857 number = {3},
858 volume = {62},
859 journal = {Communications of the ACM},
860 author = {Pearl, Judea},
861 title = {The seven tools of causal inference, with reflections on machine learning},
862}
863
864@misc{liu2018delayed,
865 year = {2018},
866 journal = {arXiv preprint arXiv:1803.04383},
867 author = {Liu, Lydia T and Dean, Sarah and Rolf, Esther and Simchowitz, Max and Hardt, Moritz},
868 title = {Delayed impact of fair machine learning},
869}
870
871@inproceedings{hu2018short,
872 year = {2018},
873 pages = {1389--1398},
874 booktitle = {The Web Conference},
875 author = {Hu, Lily and Chen, Yiling},
876 title = {A short-term intervention for long-term fairness in the labor market},
877}
878
879@article{balakrishnan2015cyberbullying,
880 publisher = {Elsevier},
881 year = {2015},
882 pages = {149--157},
883 volume = {46},
884 journal = {Computers in Human Behavior},
885 author = {Balakrishnan, Vimala},
886 title = {Cyberbullying among young adults in Malaysia: The roles of gender, age and Internet frequency},
887}
888
889@inproceedings{jagadish2019responsible,
890 organization = {ACM},
891 year = {2019},
892 pages = {1--1},
893 booktitle = {2019 WSDM},
894 author = {Jagadish, V. H.},
895 title = {Responsible Data Science},
896}
897
898@inproceedings{dwork2008differential,
899 organization = {Springer},
900 year = {2008},
901 pages = {1--19},
902 booktitle = {TAMC},
903 author = {Dwork, Cynthia},
904 title = {Differential privacy: A survey of results},
905}
906
907@book{schaefer2017information,
908 publisher = {Cambridge University Press},
909 year = {2017},
910 author = {Schaefer, Rafael F and Boche, Holger and Khisti, Ashish and Poor, H Vincent},
911 title = {Information Theoretic Security and Privacy of Information Systems},
912}
913
914@article{li2017feature,
915 publisher = {ACM New York, NY, USA},
916 year = {2017},
917 pages = {1--45},
918 number = {6},
919 volume = {50},
920 journal = {CSUR},
921 author = {Li, Jundong and Cheng, Kewei and Wang, Suhang and Morstatter, Fred and Trevino, Robert P and Tang, Jiliang and Liu, Huan},
922 title = {Feature selection: A data perspective},
923}
924
925@article{bickel1975sex,
926 publisher = {AAAS},
927 year = {1975},
928 pages = {398--404},
929 number = {4175},
930 volume = {187},
931 journal = {Science},
932 author = {Bickel, Peter J and Hammel, Eugene A and O'Connell, J William},
933 title = {Sex bias in graduate admissions: Data from {B}erkeley},
934}
935
936@article{blyth1972simpson,
937 publisher = {Taylor \& Francis},
938 year = {1972},
939 pages = {364--366},
940 number = {338},
941 volume = {67},
942 journal = {Journal of the American Statistical Association},
943 author = {Blyth, Colin R},
944 title = {On {S}impson's paradox and the sure-thing principle},
945}
946
947@article{guo2020survey,
948 publisher = {ACM New York, NY, USA},
949 year = {2020},
950 pages = {1--37},
951 number = {4},
952 volume = {53},
953 journal = {CSUR},
954 author = {Guo, Ruocheng and Cheng, Lu and Li, Jundong and Hahn, P Richard and Liu, Huan},
955 title = {A survey of learning causality with data: Problems and methods},
956}
957
958@article{baeza2018bias,
959 publisher = {ACM New York, NY, USA},
960 year = {2018},
961 pages = {54--61},
962 number = {6},
963 volume = {61},
964 journal = {Communications of the ACM},
965 author = {Baeza-Yates, Ricardo},
966 title = {Bias on the web},
967}
968
969@inproceedings{craven1996extracting,
970 year = {1996},
971 pages = {24--30},
972 booktitle = {NeurIPS},
973 author = {Craven, Mark and Shavlik, Jude W},
974 title = {Extracting tree-structured representations of trained networks},
975}
976
977@article{erhan2009visualizing,
978 year = {2009},
979 pages = {1},
980 number = {3},
981 volume = {1341},
982 journal = {University of Montreal},
983 author = {Erhan, Dumitru and Bengio, Yoshua and Courville, Aaron and Vincent, Pascal},
984 title = {Visualizing higher-layer features of a deep network},
985}
986
987@misc{koh2017understanding,
988 year = {2017},
989 journal = {arXiv preprint arXiv:1703.04730},
990 author = {Koh, Pang Wei and Liang, Percy},
991 title = {Understanding black-box predictions via influence functions},
992}
993
994@inproceedings{kim2016examples,
995 year = {2016},
996 pages = {2280--2288},
997 booktitle = {NeurIPS},
998 author = {Kim, Been and Khanna, Rajiv and Koyejo, Oluwasanmi O},
999 title = {Examples are not enough, learn to criticize! criticism for interpretability},
1000}
1001
1002@misc{simonyan2013deep,
1003 year = {2013},
1004 journal = {arXiv preprint arXiv:1312.6034},
1005 author = {Simonyan, Karen and Vedaldi, Andrea and Zisserman, Andrew},
1006 title = {Deep inside convolutional networks: Visualising image classification models and saliency maps},
1007}
1008
1009@misc{Schwab_2021,
1010 month = {Feb},
1011 year = {2021},
1012 author = {Schwab, Katharine},
1013 journal = {Fast Company},
1014 abstractnote = {Big Tech has used its power to control the field of AI ethics and avoid accountability. Now, the ouster of Timnit Gebru is putting the movement for equitable tech in the spotlight.},
1015 howpublished = {\url{https://www.fastcompany.com/90608471/timnit-gebru-google-ai-ethics-equitable-tech-movement}},
1016 title = {‘This is bigger than just Timnit’: How Google tried to silence a critic and ignited a movement},
1017}
1018
1019@misc{people2019,
1020 year = {2019},
1021 journal = {Doteveryone},
1022 howpublished = {\url{https://doteveryone.org.uk/wp-content/uploads/2019/04/PeoplePowerTech_Doteveryone_May2019.pdf}},
1023 author = {Miller C, Coldicutt R.},
1024 title = {People, Power and Technology: The Tech Workers’ View},
1025}
1026
1027@misc{Carpenter2015,
1028 year = {2015},
1029 author = {Carpenter, Julia},
1030 journal = {Washington Post},
1031 abstractnote = {Is the Google algorithm sexist -- or is it us?},
1032 howpublished = {\url{https://www.washingtonpost.com/news/the-intersect/wp/2015/07/06/googles-algorithm-shows-prestigious-job-ads-to-men-but-not-to-women-heres-why-that-should-worry-you/}},
1033}
1034
1035@misc{Horwitz_2021,
1036 month = {April},
1037 year = {2021},
1038 author = {Horwitz, Jeff},
1039 journal = {Wall Street Journal},
1040 abstractnote = {Researchers found Facebook systems were more likely to present certain job ads to users if their gender identity reflected the concentration of that gender in a particular position or industry.},
1041 howpublished = {\url{https://www.wsj.com/articles/facebook-shows-men-and-women-different-job-ads-study-finds-11617969600}},
1042 issn = {0099-9660},
1043 title = {Facebook Algorithm Shows Gender Bias in Job Ads, Study Finds},
1044}
1045
1046@misc{FacebookCambridge2021,
1047 month = {July},
1048 year = {2021},
1049 author = {Wikipedia},
1050 journal = {Wikipedia},
1051 note = {Page Version ID: 1035933869},
1052 howpublished = {\url{https://en.wikipedia.org/w/index.php?title=Facebook\%E2\%80\%93Cambridge_Analytica_data_scandal&oldid=1035933869}},
1053}
1054
1055@misc{Marr_2021,
1056 month = {July},
1057 year = {2021},
1058 author = {Marr, Bernard},
1059 abstractnote = {The amount of data we produce every day is truly […]},
1060 howpublished = {\url{https://bernardmarr.com/how-much-data-do-we-create-every-day-the-mind-blowing-stats-everyone-should-read/}},
1061}
1062
1063@misc{social2020,
1064 year = {2020},
1065 author = {Siegel, Eric},
1066 journal = {KDnuggets},
1067 abstractnote = {We often discuss applying data science and machine learning techniques in term so of how they help your organization or business goals. But, these algorithms aren’t limited to only increasing the bottom line. Developing new applications that leverage the predictive power of AI to benefit society and those communities in…},
1068 howpublished = {\url{https://www.kdnuggets.com/how-machine-learning-works-for-social-good.html/}},
1069}
1070
1071@misc{Knight2020,
1072 year = {2020},
1073 author = {Knight, Will},
1074 journal = {Wired},
1075 abstractnote = {Robust Intelligence is among a crop of companies that offer to protect clients from efforts at deception.},
1076 howpublished = {\url{https://www.wired.com/story/company-uses-ai-outwit-malicious-ai/}},
1077 issn = {1059-1028},
1078 title = {This Company Uses {AI} to Outwit Malicious {AI}},
1079}
1080
1081@misc{Rivero2020,
1082 year = {2020},
1083 author = {Rivero, Nicolás},
1084 journal = {Quartz},
1085 abstractnote = {In one topsy-turvy week, Google presented a case study in the perils of turning AI research over to Big Tech.},
1086 howpublished = {\url{https://qz.com/1945293/the-dangers-of-letting-google-lead-ai-research/}},
1087 title = {Google showed us the danger of letting corporations lead {AI} research},
1088}
1089
1090@misc{Br_2015,
1091 year = {2015},
1092 author = { Shaul, Brandy},
1093 abstractnote = {The app allows users to ask their Facebook friends questions, receiving anonymous, positive feedback to boost their confidence., The app allows users to ask their Facebook friends questions, receiving anonymous, positive feedback to boost their confidence.},
1094 howpublished = {\url{https://www.adweek.com/performance-marketing/honestly-looks-to-combat-cyberbullying-on-ios-android/}},
1095 title = {Honestly Looks to Combat Cyberbullying on iOS, Android},
1096}
1097
1098@misc{IBM_2020,
1099 month = {December},
1100 year = {2020},
1101 author = {Dobrin, Seth},
1102 journal = {Watson Blog},
1103 abstractnote = {IBM is commercializing key automated documentation capabilities from IBM Research’s AI FactSheets into Watson Studio in Cloud Pak for Data throughout 2021.},
1104 howpublished = {\url{https://www.ibm.com/blogs/watson/2020/12/how-ibm-is-advancing-ai-governance-to-help-clients-build-trust-and-transparency/}},
1105}
1106
1107@misc{NSA,
1108 month = {March},
1109 year = {2019},
1110 author = {Gershgorn, Dave},
1111 journal = {Popular Science},
1112 abstractnote = {Machine learning algorithms used by the U.S. National Security Agency to identify potential terrorists in Pakistan might be ineffective.},
1113 howpublished = {\url{https://www.popsci.com/nsas-skynet-might-not-be-able-to-tell-what-makes-terrorist/}},
1114}
1115
1116@misc{Safer2020,
1117 month = {February},
1118 year = {2020},
1119 author = {Grover, Vandita},
1120 abstractnote = {On Safer Internet Day, we explore whether transparency and obtaining consent are enough for customer data privacy or will data dignity shape the digital future.},
1121 howpublished = {\url{https://www.martechadvisor.com/articles/data-governance/data-dignity-for-better-data-privacy/}},
1122}
1123
1124@misc{Hart2019,
1125 month = {June},
1126 year = {2019},
1127 author = {Hart, Vi},
1128 howpublished = {\url{https://theartofresearch.org/data-dignity-at-radicalxchange/}},
1129 title = {Data Dignity at RadicalxChange - The Art of Research},
1130}
1131
1132@misc{Vaccine_2020,
1133 month = {November},
1134 year = {2020},
1135 author = {Cowen, Tyler},
1136 journal = {Bloomberg.com},
1137 abstractnote = {Priority should be given to methods that will save more lives and bring back the economy more rapidly.},
1138 howpublished = {\url{https://www.bloomberg.com/opinion/articles/2020-11-23/vaccine-distribution-shouldn-t-be-fair}},
1139}
1140
1141@misc{Yeo_2020,
1142 month = {May},
1143 year = {2020},
1144 author = {Yeo, Catherine},
1145 journal = {Fair Bytes},
1146 abstractnote = {What does it mean for a machine learning algorithm to be “transparent”?},
1147 howpublished = {\url{https://medium.com/fair-bytes/what-is-transparency-in-ai-bd08b2e901ac}},
1148 title = {What is Transparency in {AI}?},
1149}
1150
1151@misc{robust_2021,
1152 month = {Mar},
1153 year = {2021},
1154 author = {Wikipedia},
1155 note = {Page Version ID: 1009774103},
1156 abstractnote = {In computer science, robustness is the ability of a computer system to cope with errors during execution and cope with erroneous input. Robustness can encompass many areas of computer science, such as robust programming, robust machine learning, and Robust Security Network. Formal techniques, such as fuzz testing, are essential to showing robustness since this type of testing involves invalid or unexpected inputs. Alternatively, fault injection can be used to test robustness. Various commercial products perform robustness testing of software analysis.},
1157 howpublished = {\url{https://en.wikipedia.org/w/index.php?title=Robustness_(computer_science)&oldid=1009774103}},
1158}
1159
1160@misc{Safety2019,
1161 year = {2019},
1162 author = {
1163Feige, Ilya},
1164 journal = {Faculty},
1165 abstractnote = {In this blog, we attempt to describe the space of Artificial Intelligence (AI) Safety; namely, all the things that someone might mean when they say “AI Safety”.},
1166 howpublished = {\url{https://faculty.ai/blog/what-is-ai-safety/}},
1167}
1168
1169@misc{covid2021,
1170 month = {March},
1171 year = {2021},
1172 author = {Branswell, Helen},
1173 journal = {STAT},
1174 abstractnote = {A wide-ranging Q&A with Richard Hatchett, CEO of CEPI, the Coalition for Epidemic Preparedness Innovations.},
1175 howpublished = {\url{https://www.statnews.com/2021/03/08/a-pandemic-expert-weighs-in-on-the-long-road-ahead-for-covid-19-vaccine-distribution/}},
1176}
1177
1178@misc{CambridgeAnalytica2021,
1179 month = {July},
1180 year = {2021},
1181 author = {Wikipedia},
1182 note = {Page Version ID: 1036071985},
1183 abstractnote = {Cambridge Analytica Ltd (CA) was a British political consulting firm that came to prominence through the Facebook–Cambridge Analytica data scandal. It was started in 2013 as a subsidiary of the private intelligence company and self-described “global election management agency” SCL Group by long-time SCL executives Nigel Oakes, Alexander Nix and Alexander Oakes, with Nix as CEO. The company had close ties to the Conservative Party (UK), the British royal family and the British military. The firm maintained offices in London, New York City, and Washington, DC. The company closed operations in 2018 in the course of the Facebook–Cambridge Analytica data scandal, although related firms still exist.},
1184 howpublished = {\url{https://en.wikipedia.org/w/index.php?title=Cambridge_Analytica&oldid=1036071985}},
1185}
1186
1187@misc{Stanford,
1188 month = {December},
1189 year = {2020},
1190 author = {Asimov, Nanette},
1191 journal = {GovTech},
1192 abstractnote = {Stanford Medicine officials also studied guidelines — then built a mathematical algorithm that prioritized people who on paper were at high risk for COVID-19, such as older employees. But not all who came into contact with patients were doctors and nurses.},
1193 howpublished = {\url{https://www.govtech.com/em/safety/Stanfords-Vaccine-Algorithm-Left-Frontline-Workers-at-Back-of-Line-.html}},
1194}
1195
1196@misc{Guynn2015,
1197 year = {2015},
1198 author = {Guynn, Jessica},
1199 journal = {USA TODAY},
1200 abstractnote = {Google apologizes after Jacky Alciné reported he and friend were identifed as ``gorillas''},
1201 howpublished = {\url{https://www.usatoday.com/story/tech/2015/07/01/google-apologizes-after-photos-identify-black-people-as-gorillas/29567465/}},
1202}
1203
1204@misc{six2020,
1205 howpublished = {\url{https://www.bcg.com/publications/2020/six-steps-for-socially-responsible-artificial-intelligence}},
1206 year = {2020},
1207 author = {Mills, Steven and Baltassis, Elias and Santinelli, Maximiliano and Carlisi, Cathy and Duranton, Sylvain and Gallego, Andrea},
1208 title = {Six Steps to Bridge the Responsible {AI} Gap},
1209}
1210
1211@inproceedings{mitchell2019model,
1212 year = {2019},
1213 pages = {220--229},
1214 booktitle = {FAT*},
1215 author = {Mitchell, Margaret and Wu, Simone and Zaldivar, Andrew and Barnes, Parker and Vasserman, Lucy and Hutchinson, Ben and Spitzer, Elena and Raji, Inioluwa Deborah and Gebru, Timnit},
1216 title = {Model cards for model reporting},
1217}
1218
1219@article{canca2020operationalizing,
1220 publisher = {ACM New York, NY, USA},
1221 year = {2020},
1222 pages = {18--21},
1223 number = {12},
1224 volume = {63},
1225 journal = {Communications of the ACM},
1226 author = {Canca, Cansu},
1227 title = {Operationalizing {AI} ethics principles},
1228}
1229
1230@article{bellamy2019ai,
1231 publisher = {IBM},
1232 year = {2019},
1233 pages = {4--1},
1234 number = {4/5},
1235 volume = {63},
1236 journal = {IBM Journal of Research and Development},
1237 author = {Bellamy, Rachel KE and Dey, Kuntal and Hind, Michael and Hoffman, Samuel C and Houde, Stephanie and Kannan, Kalapriya and Lohia, Pranay and Martino, Jacquelyn and Mehta, Sameep and Mojsilovi{\'c}, Aleksandra and others},
1238 title = {{AI} Fairness 360: An extensible toolkit for detecting and mitigating algorithmic bias},
1239}
1240
1241@inproceedings{goel2018non,
1242 year = {2018},
1243 pages = {116--116},
1244 booktitle = {AIES},
1245 author = {Goel, Naman and Yaghini, Mohammad and Faltings, Boi},
1246 title = {Non-discriminatory machine learning through convex fairness criteria},
1247}
1248
1249@inproceedings{kamishima2012fairness,
1250 organization = {Springer},
1251 year = {2012},
1252 pages = {35--50},
1253 booktitle = {ECML PKDD},
1254 author = {Kamishima, Toshihiro and Akaho, Shotaro and Asoh, Hideki and Sakuma, Jun},
1255 title = {Fairness-aware classifier with prejudice remover regularizer},
1256}
1257
1258@inproceedings{krasanakis2018adaptive,
1259 year = {2018},
1260 pages = {853--862},
1261 booktitle = {The Web Conference},
1262 author = {Krasanakis, Emmanouil and Spyromitros-Xioufis, Eleftherios and Papadopoulos, Symeon and Kompatsiaris, Yiannis},
1263 title = {Adaptive sensitive reweighting to mitigate bias in fairness-aware classification},
1264}
1265
1266@inproceedings{menon2018cost,
1267 year = {2018},
1268 pages = {107--118},
1269 booktitle = {FAT*},
1270 author = {Menon, Aditya Krishna and Williamson, Robert C},
1271 title = {The cost of fairness in binary classification},
1272}
1273
1274@inproceedings{calmon2017optimized,
1275 year = {2017},
1276 pages = {3992--4001},
1277 booktitle = {NeurIPS},
1278 author = {Calmon, Flavio and Wei, Dennis and Vinzamuri, Bhanukiran and Ramamurthy, Karthikeyan Natesan and Varshney, Kush R},
1279 title = {Optimized pre-processing for discrimination prevention},
1280}
1281
1282@inproceedings{geyik2019fairness,
1283 year = {2019},
1284 pages = {2221--2231},
1285 booktitle = {KDD},
1286 author = {Geyik, Sahin Cem and Ambler, Stuart and Kenthapadi, Krishnaram},
1287 title = {Fairness-aware ranking in search \& recommendation systems with application to linkedin talent search},
1288}
1289
1290@misc{suhr2020does,
1291 year = {2020},
1292 journal = {arXiv preprint arXiv:2012.00423},
1293 author = {S{\"u}hr, Tom and Hilgard, Sophie and Lakkaraju, Himabindu},
1294 title = {Does Fair Ranking Improve Minority Outcomes? Understanding the Interplay of Human and Algorithmic Biases in Online Hiring},
1295}
1296
1297@misc{pfohl2020empirical,
1298 publisher = {Elsevier},
1299 year = {2020},
1300 pages = {103621},
1301 journal = {Journal of Biomedical Informatics},
1302 author = {Pfohl, Stephen R and Foryciarz, Agata and Shah, Nigam H},
1303 title = {An empirical characterization of fair machine learning for clinical risk prediction},
1304}
1305
1306@article{varshney2019trustworthy,
1307 publisher = {ACM New York, NY, USA},
1308 year = {2019},
1309 pages = {26--29},
1310 number = {3},
1311 volume = {25},
1312 journal = {XRDS: Crossroads, The ACM Magazine for Students},
1313 author = {Varshney, Kush R},
1314 title = {Trustworthy machine learning and artificial intelligence},
1315}
1316
1317@inproceedings{galhotra2017fairness,
1318 year = {2017},
1319 pages = {498--510},
1320 booktitle = {ESEC/FSE},
1321 author = {Galhotra, Sainyam and Brun, Yuriy and Meliou, Alexandra},
1322 title = {Fairness testing: testing software for discrimination},
1323}
1324
1325@inproceedings{feldman2015certifying,
1326 year = {2015},
1327 pages = {259--268},
1328 booktitle = {KDD},
1329 author = {Feldman, Michael and Friedler, Sorelle A and Moeller, John and Scheidegger, Carlos and Venkatasubramanian, Suresh},
1330 title = {Certifying and removing disparate impact},
1331}
1332
1333@inproceedings{jiang2020identifying,
1334 year = {2020},
1335 pages = {702--712},
1336 booktitle = {AISTATS},
1337 author = {Jiang, Heinrich and Nachum, Ofir},
1338 title = {Identifying and correcting label bias in machine learning},
1339}
1340
1341@misc{celis2016fair,
1342 year = {2016},
1343 journal = {arXiv preprint arXiv:1610.07183},
1344 author = {Celis, L Elisa and Deshpande, Amit and Kathuria, Tarun and Vishnoi, Nisheeth K},
1345 title = {How to be fair and diverse?},
1346}
1347
1348@misc{feng2019learning,
1349 year = {2019},
1350 journal = {arXiv preprint arXiv:1904.13341},
1351 author = {Feng, Rui and Yang, Yang and Lyu, Yuehan and Tan, Chenhao and Sun, Yizhou and Wang, Chunping},
1352 title = {Learning fair representations via an adversarial framework},
1353}
1354
1355@misc{zhang2016causal,
1356 year = {2016},
1357 journal = {arXiv preprint arXiv:1611.07509},
1358 author = {Zhang, Lu and Wu, Yongkai and Wu, Xintao},
1359 title = {A causal framework for discovering and removing direct and indirect discrimination},
1360}
1361
1362@misc{narendra2018explaining,
1363 year = {2018},
1364 journal = {arXiv preprint arXiv:1811.04376},
1365 author = {Narendra, Tanmayee and Sankaran, Anush and Vijaykeerthy, Deepak and Mani, Senthil},
1366 title = {Explaining deep learning models using causal inference},
1367}
1368
1369@misc{wang2018deconfounded,
1370 year = {2018},
1371 journal = {arXiv preprint arXiv:1808.06581},
1372 author = {Wang, Yixin and Liang, Dawen and Charlin, Laurent and Blei, David M},
1373 title = {The deconfounded recommender: A causal inference approach to recommendation},
1374}
1375
1376@book{molnar2020interpretable,
1377 publisher = {Lulu. com},
1378 year = {2020},
1379 author = {Molnar, Christoph},
1380 title = {Interpretable Machine Learning},
1381}
1382
1383@article{wachter2017counterfactual,
1384 publisher = {HeinOnline},
1385 year = {2017},
1386 pages = {841},
1387 volume = {31},
1388 journal = {Harv. JL \& Tech.},
1389 author = {Wachter, Sandra and Mittelstadt, Brent and Russell, Chris},
1390 title = {Counterfactual explanations without opening the black box: Automated decisions and the GDPR},
1391}
1392
1393@article{wold1987principal,
1394 publisher = {Elsevier},
1395 year = {1987},
1396 pages = {37--52},
1397 number = {1-3},
1398 volume = {2},
1399 journal = {Chemometrics and intelligent laboratory systems},
1400 author = {Wold, Svante and Esbensen, Kim and Geladi, Paul},
1401 title = {Principal component analysis},
1402}
1403
1404@article{maaten2008visualizing,
1405 year = {2008},
1406 pages = {2579--2605},
1407 number = {Nov},
1408 volume = {9},
1409 journal = {JMLR},
1410 author = {Maaten, Laurens van der and Hinton, Geoffrey},
1411 title = {Visualizing data using t-SNE},
1412}
1413
1414@article{lipton2018mythos,
1415 publisher = {ACM New York, NY, USA},
1416 year = {2018},
1417 pages = {31--57},
1418 number = {3},
1419 volume = {16},
1420 journal = {Queue},
1421 author = {Lipton, Zachary C},
1422 title = {The mythos of model interpretability},
1423}
1424
1425@misc{mordvintsev2015inceptionism,
1426 year = {2015},
1427 author = {Mordvintsev, Alexander and Olah, Christopher and Tyka, Mike},
1428 title = {Inceptionism: Going deeper into neural networks},
1429}
1430
1431@inproceedings{yang2016hierarchical,
1432 year = {2016},
1433 pages = {1480--1489},
1434 booktitle = {NAACL HLT},
1435 author = {Yang, Zichao and Yang, Diyi and Dyer, Chris and He, Xiaodong and Smola, Alex and Hovy, Eduard},
1436 title = {Hierarchical attention networks for document classification},
1437}
1438
1439@incollection{robnik2018perturbation,
1440 publisher = {Springer},
1441 year = {2018},
1442 pages = {159--175},
1443 booktitle = {Human and Machine Learning},
1444 author = {Robnik-{\v{S}}ikonja, Marko and Bohanec, Marko},
1445 title = {Perturbation-based explanations of prediction models},
1446}
1447
1448@article{hartigan1979algorithm,
1449 publisher = {JSTOR},
1450 year = {1979},
1451 pages = {100--108},
1452 number = {1},
1453 volume = {28},
1454 journal = {Journal of the Royal Statistical Society. Series C (applied statistics)},
1455 author = {Hartigan, John A and Wong, Manchek A},
1456 title = {Algorithm AS 136: A k-means clustering algorithm},
1457}
1458
1459@article{rudin2019stop,
1460 publisher = {Nature Publishing Group},
1461 year = {2019},
1462 pages = {206--215},
1463 number = {5},
1464 volume = {1},
1465 journal = {Nature Machine Intelligence},
1466 author = {Rudin, Cynthia},
1467 title = {Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead},
1468}
1469
1470@article{hirano2003efficient,
1471 publisher = {Wiley Online Library},
1472 year = {2003},
1473 pages = {1161--1189},
1474 number = {4},
1475 volume = {71},
1476 journal = {Econometrica},
1477 author = {Hirano, Keisuke and Imbens, Guido W and Ridder, Geert},
1478 title = {Efficient estimation of average treatment effects using the estimated propensity score},
1479}
1480
1481@misc{liu2019generative,
1482 year = {2019},
1483 journal = {arXiv preprint arXiv:1907.03077},
1484 author = {Liu, Shusen and Kailkhura, Bhavya and Loveland, Donald and Han, Yong},
1485 title = {Generative counterfactual introspection for explainable deep learning},
1486}
1487
1488@misc{grath2018interpretable,
1489 year = {2018},
1490 journal = {arXiv preprint arXiv:1811.05245},
1491 author = {Grath, Rory Mc and Costabello, Luca and Van, Chan Le and Sweeney, Paul and Kamiab, Farbod and Shen, Zhao and Lecue, Freddy},
1492 title = {Interpretable credit application predictions with counterfactual explanations},
1493}
1494
1495@inproceedings{joachims2017unbiased,
1496 year = {2017},
1497 pages = {781--789},
1498 booktitle = {WSDM},
1499 author = {Joachims, Thorsten and Swaminathan, Adith and Schnabel, Tobias},
1500 title = {Unbiased learning-to-rank with biased feedback},
1501}
1502
1503@inproceedings{wang2018position,
1504 year = {2018},
1505 pages = {610--618},
1506 booktitle = {WSDM},
1507 author = {Wang, Xuanhui and Golbandi, Nadav and Bendersky, Michael and Metzler, Donald and Najork, Marc},
1508 title = {Position bias estimation for unbiased learning to rank in personal search},
1509}
1510
1511@article{zhang2017anti,
1512 publisher = {Springer},
1513 year = {2017},
1514 pages = {1--16},
1515 number = {1},
1516 volume = {4},
1517 journal = {JDSA},
1518 author = {Zhang, Lu and Wu, Xintao},
1519 title = {Anti-discrimination learning: a causal modeling-based framework},
1520}
1521
1522@article{zhang2014advanced,
1523 publisher = {IEEE},
1524 year = {2014},
1525 pages = {2706--2715},
1526 number = {5},
1527 volume = {30},
1528 journal = {IEEE Transactions on Power Systems},
1529 author = {Zhang, Guoyong and Wu, Yonggang and Wong, Kit Po and Xu, Zhao and Dong, Zhao Yang and Iu, Herbert Ho-Ching},
1530 title = {An advanced approach for construction of optimal wind power prediction intervals},
1531}
1532
1533@inproceedings{stoica2018algorithmic,
1534 year = {2018},
1535 pages = {923--932},
1536 booktitle = {The Web Conference},
1537 author = {Stoica, Ana-Andreea and Riederer, Christopher and Chaintreau, Augustin},
1538 title = {Algorithmic Glass Ceiling in Social Networks: The effects of social recommendations on network diversity},
1539}
1540
1541@misc{parafita2019explaining,
1542 year = {2019},
1543 journal = {arXiv preprint arXiv:1909.08891},
1544 author = {Parafita, {\'A}lvaro and Vitri{\`a}, Jordi},
1545 title = {Explaining visual models by causal attribution},
1546}
1547
1548@misc{chattopadhyay2019neural,
1549 year = {2019},
1550 journal = {arXiv preprint arXiv:1902.02302},
1551 author = {Chattopadhyay, Aditya and Manupriya, Piyushi and Sarkar, Anirban and Balasubramanian, Vineeth N},
1552 title = {Neural network attributions: A causal perspective},
1553}
1554
1555@misc{pearl2018theoretical,
1556 year = {2018},
1557 journal = {arXiv preprint arXiv:1801.04016},
1558 author = {Pearl, Judea},
1559 title = {Theoretical impediments to machine learning with seven sparks from the causal revolution},
1560}
1561
1562@article{moraffah2020causal,
1563 publisher = {ACM},
1564 year = {2020},
1565 pages = {18--33},
1566 number = {1},
1567 volume = {22},
1568 journal = {SIGKDD Explorations},
1569 author = {Moraffah, Raha and Karami, Mansooreh and Guo, Ruocheng and Raglin, Adrienne and Liu, Huan},
1570 title = {Causal Interpretability for Machine Learning-Problems, Methods and Evaluation},
1571}
1572
1573@inproceedings{yang2020causal,
1574 year = {2020},
1575 pages = {9434--9441},
1576 booktitle = {AAAI},
1577 author = {Yang, Zekun and Feng, Juan},
1578 title = {A Causal Inference Method for Reducing Gender Bias in Word Embedding Relations.},
1579}
1580
1581@article{garg2018word,
1582 publisher = {National Acad Sciences},
1583 year = {2018},
1584 pages = {E3635--E3644},
1585 number = {16},
1586 volume = {115},
1587 journal = {PNAS},
1588 author = {Garg, Nikhil and Schiebinger, Londa and Jurafsky, Dan and Zou, James},
1589 title = {Word embeddings quantify 100 years of gender and ethnic stereotypes},
1590}
1591
1592@inproceedings{ekstrand2018exploring,
1593 year = {2018},
1594 pages = {242--250},
1595 booktitle = {RecSys},
1596 author = {Ekstrand, Michael D and Tian, Mucun and Kazi, Mohammed R Imran and Mehrpouyan, Hoda and Kluver, Daniel},
1597 title = {Exploring author gender in book rating and recommendation},
1598}
1599
1600@article{karimi2018homophily,
1601 publisher = {Nature Publishing Group},
1602 year = {2018},
1603 pages = {1--12},
1604 number = {1},
1605 volume = {8},
1606 journal = {Scientific Reports},
1607 author = {Karimi, Fariba and G{\'e}nois, Mathieu and Wagner, Claudia and Singer, Philipp and Strohmaier, Markus},
1608 title = {Homophily influences ranking of minorities in social networks},
1609}
1610
1611@article{datta2015automated,
1612 publisher = {Sciendo},
1613 year = {2015},
1614 pages = {92--112},
1615 number = {1},
1616 volume = {2015},
1617 journal = {PoPETs},
1618 author = {Datta, Amit and Tschantz, Michael Carl and Datta, Anupam},
1619 title = {Automated experiments on ad privacy settings: A tale of opacity, choice, and discrimination},
1620}
1621
1622@article{lambrecht2019algorithmic,
1623 publisher = {INFORMS},
1624 year = {2019},
1625 pages = {2966--2981},
1626 number = {7},
1627 volume = {65},
1628 journal = {Management Science},
1629 author = {Lambrecht, Anja and Tucker, Catherine},
1630 title = {Algorithmic bias? An empirical study of apparent gender-based discrimination in the display of STEM career ads},
1631}
1632
1633@inproceedings{nabi2018fair,
1634 organization = {NIH Public Access},
1635 year = {2018},
1636 pages = {1931},
1637 volume = {2018},
1638 booktitle = {AAAI},
1639 author = {Nabi, Razieh and Shpitser, Ilya},
1640 title = {Fair inference on outcomes},
1641}
1642
1643@inproceedings{calders2013controlling,
1644 organization = {IEEE},
1645 year = {2013},
1646 pages = {71--80},
1647 booktitle = {ICDM},
1648 author = {Calders, Toon and Karim, Asim and Kamiran, Faisal and Ali, Wasif and Zhang, Xiangliang},
1649 title = {Controlling attribute effect in linear regression},
1650}
1651
1652@misc{agarwal2019fair,
1653 year = {2019},
1654 journal = {arXiv preprint arXiv:1905.12843},
1655 author = {Agarwal, Alekh and Dud{\'\i}k, Miroslav and Wu, Zhiwei Steven},
1656 title = {Fair regression: Quantitative definitions and reduction-based algorithms},
1657}
1658
1659@inproceedings{xu2019achieving,
1660 year = {2019},
1661 pages = {1452--1458},
1662 booktitle = {IJCAI},
1663 author = {Xu, Depeng and Wu, Yongkai and Yuan, Shuhan and Zhang, Lu and Wu, Xintao},
1664 title = {Achieving Causal Fairness through Generative Adversarial Networks.},
1665}
1666
1667@inproceedings{pearl2010causal,
1668 year = {2010},
1669 pages = {39--58},
1670 booktitle = {Causality: Objectives and Assessment},
1671 author = {Pearl, Judea},
1672 title = {Causal inference},
1673}
1674
1675@book{pearl2009causality,
1676 publisher = {Cambridge university press},
1677 year = {2009},
1678 author = {Pearl, Judea},
1679 title = {Causality},
1680}
1681
1682@article{rosenbaum1983central,
1683 publisher = {Oxford University Press},
1684 year = {1983},
1685 pages = {41--55},
1686 number = {1},
1687 volume = {70},
1688 journal = {Biometrika},
1689 author = {Rosenbaum, Paul R and Rubin, Donald B},
1690 title = {The central role of the propensity score in observational studies for causal effects},
1691}
1692
1693@article{rubin1974estimating,
1694 publisher = {American Psychological Association},
1695 year = {1974},
1696 pages = {688},
1697 number = {5},
1698 volume = {66},
1699 journal = {Journal of Educational Psychology},
1700 author = {Rubin, Donald B},
1701 title = {Estimating causal effects of treatments in randomized and nonrandomized studies},
1702}
1703
1704@article{holzinger2019causability,
1705 publisher = {Wiley Online Library},
1706 year = {2019},
1707 pages = {e1312},
1708 number = {4},
1709 volume = {9},
1710 journal = {Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery},
1711 author = {Holzinger, Andreas and Langs, Georg and Denk, Helmut and Zatloukal, Kurt and M{\"u}ller, Heimo},
1712 title = {Causability and explainability of artificial intelligence in medicine},
1713}
1714
1715@inproceedings{dwork2018decoupled,
1716 year = {2018},
1717 pages = {119--133},
1718 booktitle = {FAT*},
1719 author = {Dwork, Cynthia and Immorlica, Nicole and Kalai, Adam Tauman and Leiserson, Max},
1720 title = {Decoupled classifiers for group-fair and efficient machine learning},
1721}
1722
1723@misc{bechavod2017penalizing,
1724 year = {2017},
1725 journal = {arXiv preprint arXiv:1707.00044},
1726 author = {Bechavod, Yahav and Ligett, Katrina},
1727 title = {Penalizing unfairness in binary classification},
1728}
1729
1730@article{calders2010three,
1731 publisher = {Springer},
1732 year = {2010},
1733 pages = {277--292},
1734 number = {2},
1735 volume = {21},
1736 journal = {Data Mining and Knowledge Discovery},
1737 author = {Calders, Toon and Verwer, Sicco},
1738 title = {Three naive {B}ayes approaches for discrimination-free classification},
1739}
1740
1741@inproceedings{dwork2012fairness,
1742 year = {2012},
1743 pages = {214--226},
1744 booktitle = {ITCS},
1745 author = {Dwork, Cynthia and Hardt, Moritz and Pitassi, Toniann and Reingold, Omer and Zemel, Richard},
1746 title = {Fairness through awareness},
1747}
1748
1749@misc{johnson2016impartial,
1750 year = {2016},
1751 journal = {arXiv preprint arXiv:1608.00528},
1752 author = {Johnson, Kory D and Foster, Dean P and Stine, Robert A},
1753 title = {Impartial predictive modeling: Ensuring fairness in arbitrary models},
1754}
1755
1756@inproceedings{hardt2016equality,
1757 year = {2016},
1758 pages = {3315--3323},
1759 booktitle = {NeurIPS},
1760 author = {Hardt, Moritz and Price, Eric and Srebro, Nati},
1761 title = {Equality of opportunity in supervised learning},
1762}
1763
1764@misc{berk2017convex,
1765 year = {2017},
1766 journal = {arXiv preprint arXiv:1706.02409},
1767 author = {Berk, Richard and Heidari, Hoda and Jabbari, Shahin and Joseph, Matthew and Kearns, Michael and Morgenstern, Jamie and Neel, Seth and Roth, Aaron},
1768 title = {A convex framework for fair regression},
1769}
1770
1771@misc{weller2017challenges,
1772 year = {2017},
1773 journal = {arXiv preprint arXiv:1708.01870},
1774 author = {Weller, Adrian},
1775 title = {Challenges for transparency},
1776}
1777
1778@article{d2017conscientious,
1779 publisher = {Mary Ann Liebert, Inc. 140 Huguenot Street, 3rd Floor New Rochelle, NY 10801 USA},
1780 year = {2017},
1781 pages = {120--134},
1782 number = {2},
1783 volume = {5},
1784 journal = {Big Data},
1785 author = {d'Alessandro, Brian and O'Neil, Cathy and LaGatta, Tom},
1786 title = {Conscientious classification: A data scientist's guide to discrimination-aware classification},
1787}
1788
1789@article{legg2007collection,
1790 publisher = {IOS Press},
1791 year = {2007},
1792 pages = {17},
1793 volume = {157},
1794 journal = {FAIA},
1795 author = {Legg, Shane and Hutter, Marcus and others},
1796 title = {A collection of definitions of intelligence},
1797}
1798
1799@inproceedings{slack2020fooling,
1800 year = {2020},
1801 pages = {180--186},
1802 booktitle = {AIES},
1803 author = {Slack, Dylan and Hilgard, Sophie and Jia, Emily and Singh, Sameer and Lakkaraju, Himabindu},
1804 title = {Fooling lime and shap: Adversarial attacks on post hoc explanation methods},
1805}
1806
1807@inproceedings{kusner2017counterfactual,
1808 year = {2017},
1809 pages = {4066--4076},
1810 booktitle = {NeurIPS},
1811 author = {Kusner, Matt J and Loftus, Joshua and Russell, Chris and Silva, Ricardo},
1812 title = {Counterfactual fairness},
1813}
1814
1815@misc{loftus2018causal,
1816 year = {2018},
1817 journal = {arXiv preprint arXiv:1805.05859},
1818 author = {Loftus, Joshua R and Russell, Chris and Kusner, Matt J and Silva, Ricardo},
1819 title = {Causal reasoning for algorithmic fairness},
1820}
1821
1822@inproceedings{ribeiro2016should,
1823 year = {2016},
1824 pages = {1135--1144},
1825 booktitle = {KDD},
1826 author = {Ribeiro, Marco Tulio and Singh, Sameer and Guestrin, Carlos},
1827 title = {``{W}hy should {I} trust you?'' Explaining the predictions of any classifier},
1828}
1829
1830@misc{leslie2019understanding,
1831 year = {2019},
1832 journal = {arXiv preprint arXiv:1906.05684},
1833 author = {Leslie, David},
1834 title = {Understanding artificial intelligence ethics and safety},
1835}
1836
1837@inproceedings{lundberg2017unified,
1838 year = {2017},
1839 pages = {4765--4774},
1840 booktitle = {NeurIPS},
1841 author = {Lundberg, Scott M and Lee, Su-In},
1842 title = {A unified approach to interpreting model predictions},
1843}
1844
1845@misc{thiebes2020trustworthy,
1846 publisher = {Springer},
1847 year = {2020},
1848 pages = {1--18},
1849 journal = {Electronic Markets},
1850 author = {Thiebes, Scott and Lins, Sebastian and Sunyaev, Ali},
1851 title = {Trustworthy artificial intelligence},
1852}
1853
1854@incollection{singh2021trustworthy,
1855 year = {2021},
1856 pages = {449--453},
1857 booktitle = {8th ACM IKDD CODS and 26th COMAD},
1858 author = {Singh, Richa and Vatsa, Mayank and Ratha, Nalini},
1859 title = {Trustworthy {AI}},
1860}
1861
1862@article{carvalho2019machine,
1863 publisher = {Multidisciplinary Digital Publishing Institute},
1864 year = {2019},
1865 pages = {832},
1866 number = {8},
1867 volume = {8},
1868 journal = {Electronics},
1869 author = {Carvalho, Diogo V and Pereira, Eduardo M and Cardoso, Jaime S},
1870 title = {Machine learning interpretability: A survey on methods and metrics},
1871}
1872
1873@misc{yao2020causal,
1874 year = {2020},
1875 journal = {arXiv preprint arXiv:2002.02770},
1876 author = {Yao, Liuyi and Chu, Zhixuan and Li, Sheng and Li, Yaliang and Gao, Jing and Zhang, Aidong},
1877 title = {A Survey on Causal Inference},
1878}
1879
1880@misc{chakraborty2018adversarial,
1881 year = {2018},
1882 journal = {arXiv preprint arXiv:1810.00069},
1883 author = {Chakraborty, Anirban and Alam, Manaar and Dey, Vishal and Chattopadhyay, Anupam and Mukhopadhyay, Debdeep},
1884 title = {Adversarial attacks and defences: A survey},
1885}
1886
1887@misc{tjoa2019XAI,
1888 year = {2020},
1889 journal = {IEEE Transactions on Neural Networks and Learning Systems},
1890 author = {Tjoa, E. and Guan, C},
1891 title = {A Survey on Explainable Artificial Intelligence (XAI): Toward Medical XAI},
1892}
1893
1894@inproceedings{papernot2016distillation,
1895 organization = {IEEE},
1896 year = {2016},
1897 pages = {582--597},
1898 booktitle = {IEEE Symposium on SP},
1899 author = {Papernot, Nicolas and McDaniel, Patrick and Wu, Xi and Jha, Somesh and Swami, Ananthram},
1900 title = {Distillation as a defense to adversarial perturbations against deep neural networks},
1901}
1902
1903@article{smith2008cyberbullying,
1904 publisher = {Wiley Online Library},
1905 year = {2008},
1906 pages = {376--385},
1907 number = {4},
1908 volume = {49},
1909 journal = {Journal of Child Psychology and Psychiatry},
1910 author = {Smith, Peter K and Mahdavi, Jess and Carvalho, Manuel and Fisher, Sonja and Russell, Shanette and Tippett, Neil},
1911 title = {Cyberbullying: Its nature and impact in secondary school pupils},
1912}
1913
1914@inproceedings{dani2017sentiment,
1915 organization = {Springer},
1916 year = {2017},
1917 pages = {52--67},
1918 booktitle = {ECML PKDD},
1919 author = {Dani, Harsh and Li, Jundong and Liu, Huan},
1920 title = {Sentiment informed cyberbullying detection in social media},
1921}
1922
1923@inproceedings{mokhberian2020moral,
1924 organization = {Springer},
1925 year = {2020},
1926 pages = {206--219},
1927 booktitle = {SocInfo},
1928 author = {Mokhberian, Negar and Abeliuk, Andr{\'e}s and Cummings, Patrick and Lerman, Kristina},
1929 title = {Moral Framing and Ideological Bias of News},
1930}
1931
1932@misc{lee2019algorithmic,
1933 year = {2019},
1934 journal = {Center for Technology Innovation, Brookings. Tillg{\"a}nglig online: https://www. brookings. edu/research/algorithmic-bias-detection-and-mitigation-bestpractices-and-policies-to-reduce-consumer-harms/\# footnote-7 (2019-10-01)},
1935 author = {Lee, Nicol Turner and Resnick, Paul and Barton, Genie},
1936 title = {Algorithmic bias detection and mitigation: Best practices and policies to reduce consumer harms},
1937}
1938
1939@inproceedings{mcconnell2001race,
1940 year = {2001},
1941 booktitle = {ACJS, Washington, DC},
1942 author = {McConnell, Elizabeth H and Scheidegger, Amie R},
1943 title = {Race and speeding citations: Comparing speeding citations issued by air traffic officers with those issued by ground traffic officers},
1944}
1945
1946@misc{lange2001speed,
1947 year = {2001},
1948 journal = {Public Services Research Institute},
1949 author = {Lange, James E and Blackman, Kenneth O and Johnson, Mark B},
1950 title = {Speed violation survey of the New Jersey Turnpike: Final report},
1951}
1952
1953@article{becker1993nobel,
1954 publisher = {The University of Chicago Press},
1955 year = {1993},
1956 pages = {385--409},
1957 number = {3},
1958 volume = {101},
1959 journal = {Journal of Political Economy},
1960 author = {Becker, Gary S},
1961 title = {Nobel lecture: The economic way of looking at behavior},
1962}
1963
1964@techreport{ayres2010testing,
1965 institution = {mimeo, Yale Law School},
1966 year = {2010},
1967 author = {Ayres, Ian},
1968 title = {Testing for discrimination and the problem of” included variable bias”,”},
1969}
1970
1971@misc{fu2020ai,
1972 year = {2020},
1973 journal = {Detection, Mitigation and Implications (July 26, 2020)},
1974 author = {Fu, Runshan and Huang, Yan and Singh, Param Vir},
1975 title = {{AI} and Algorithmic Bias: Source, Detection, Mitigation and Implications},
1976}
1977
1978@inproceedings{huang2014cyber,
1979 year = {2014},
1980 pages = {3--6},
1981 booktitle = {SAM},
1982 author = {Huang, Qianjia and Singh, Vivek Kumar and Atrey, Pradeep Kumar},
1983 title = {Cyberbullying detection using social and textual analysis},
1984}
1985
1986@inproceedings{cheng2019hierarchical,
1987 organization = {SIAM},
1988 year = {2019},
1989 pages = {235--243},
1990 booktitle = {SDM},
1991 author = {Cheng, Lu and Guo, Ruocheng and Silva, Yasin and Hall, Deborah and Liu, Huan},
1992 title = {Hierarchical attention networks for cyberbullying detection on the instagram social network},
1993}
1994
1995@inproceedings{cheng2019xbully,
1996 year = {2019},
1997 pages = {339--347},
1998 booktitle = {WSDM},
1999 author = {Cheng, Lu and Li, Jundong and Silva, Yasin N and Hall, Deborah L and Liu, Huan},
2000 title = {Xbully: Cyberbullying detection within a multi-modal context},
2001}
2002
2003@article{cheng2021modeling,
2004 publisher = {ACM New York, NY},
2005 year = {2021},
2006 pages = {1--23},
2007 number = {2},
2008 volume = {2},
2009 journal = {ACM/IMS Transactions on Data Science},
2010 author = {Cheng, Lu and Guo, Ruocheng and Silva, Yasin N and Hall, Deborah and Liu, Huan},
2011 title = {Modeling temporal patterns of cyberbullying detection with hierarchical attention networks},
2012}
2013
2014@inproceedings{xu2012learning,
2015 organization = {ACL},
2016 year = {2012},
2017 pages = {656--666},
2018 booktitle = {NAACL HLT},
2019 author = {Xu, Jun-Ming and Jun, Kwang-Sung and Zhu, Xiaojin and Bellmore, Amy},
2020 title = {Learning from bullying traces in social media},
2021}
2022
2023@misc{mirshghallah2020privacy,
2024 year = {2020},
2025 journal = {arXiv preprint arXiv:2004.12254},
2026 author = {Mirshghallah, Fatemehsadat and Taram, Mohammadkazem and Vepakomma, Praneeth and Singh, Abhishek and Raskar, Ramesh and Esmaeilzadeh, Hadi},
2027 title = {Privacy in Deep Learning: A Survey},
2028}
2029
2030@article{boulemtafes2020review,
2031 publisher = {Elsevier},
2032 year = {2020},
2033 pages = {21--45},
2034 volume = {384},
2035 journal = {Neurocomputing},
2036 author = {Boulemtafes, Amine and Derhab, Abdelouahid and Challal, Yacine},
2037 title = {A review of privacy-preserving techniques for deep learning},
2038}
2039
2040@inproceedings{hitaj2017deep,
2041 year = {2017},
2042 pages = {603--618},
2043 booktitle = {CCS},
2044 author = {Hitaj, Briland and Ateniese, Giuseppe and Perez-Cruz, Fernando},
2045 title = {Deep models under the GAN: information leakage from collaborative deep learning},
2046}
2047
2048@inproceedings{dalvi2004adversarial,
2049 year = {2004},
2050 pages = {99--108},
2051 booktitle = {KDD},
2052 author = {Dalvi, Nilesh and Domingos, Pedro and Sanghai, Sumit and Verma, Deepak},
2053 title = {Adversarial classification},
2054}
2055
2056@inproceedings{goodfellow2014generative,
2057 year = {2014},
2058 pages = {2672--2680},
2059 booktitle = {NeurIPS},
2060 author = {Goodfellow, Ian and Pouget-Abadie, Jean and Mirza, Mehdi and Xu, Bing and Warde-Farley, David and Ozair, Sherjil and Courville, Aaron and Bengio, Yoshua},
2061 title = {Generative adversarial nets},
2062}
2063
2064@inproceedings{barreno2006can,
2065 year = {2006},
2066 pages = {16--25},
2067 booktitle = {ASIACCS},
2068 author = {Barreno, Marco and Nelson, Blaine and Sears, Russell and Joseph, Anthony D and Tygar, J Doug},
2069 title = {Can machine learning be secure?},
2070}
2071
2072@inproceedings{fredrikson2014privacy,
2073 year = {2014},
2074 pages = {17--32},
2075 booktitle = {USENIX Security},
2076 author = {Fredrikson, Matthew and Lantz, Eric and Jha, Somesh and Lin, Simon and Page, David and Ristenpart, Thomas},
2077 title = {Privacy in pharmacogenetics: An end-to-end case study of personalized warfarin dosing},
2078}
2079
2080@inproceedings{shokri2017membership,
2081 organization = {IEEE},
2082 year = {2017},
2083 pages = {3--18},
2084 booktitle = {2017 IEEE Symposium on SP},
2085 author = {Shokri, Reza and Stronati, Marco and Song, Congzheng and Shmatikov, Vitaly},
2086 title = {Membership inference attacks against machine learning models},
2087}
2088
2089@article{ateniese2015hacking,
2090 publisher = {Inderscience Publishers (IEL)},
2091 year = {2015},
2092 pages = {137--150},
2093 number = {3},
2094 volume = {10},
2095 journal = {International Journal of Security and Networks},
2096 author = {Ateniese, Giuseppe and Mancini, Luigi V and Spognardi, Angelo and Villani, Antonio and Vitali, Domenico and Felici, Giovanni},
2097 title = {Hacking smart machines with smarter ones: How to extract meaningful data from machine learning classifiers},
2098}
2099
2100@inproceedings{tramer2016stealing,
2101 year = {2016},
2102 pages = {601--618},
2103 booktitle = {USENIX Security},
2104 author = {Tram{\`e}r, Florian and Zhang, Fan and Juels, Ari and Reiter, Michael K and Ristenpart, Thomas},
2105 title = {Stealing machine learning models via prediction apis},
2106}
2107
2108@inproceedings{fredrikson2015model,
2109 year = {2015},
2110 pages = {1322--1333},
2111 booktitle = {CCS},
2112 author = {Fredrikson, Matt and Jha, Somesh and Ristenpart, Thomas},
2113 title = {Model inversion attacks that exploit confidence information and basic countermeasures},
2114}
2115
2116@article{yuan2019adversarial,
2117 publisher = {IEEE},
2118 year = {2019},
2119 pages = {2805--2824},
2120 number = {9},
2121 volume = {30},
2122 journal = {IEEE Transactions on Neural Networks and Learning Systems},
2123 author = {Yuan, Xiaoyong and He, Pan and Zhu, Qile and Li, Xiaolin},
2124 title = {Adversarial examples: Attacks and defenses for deep learning},
2125}
2126
2127@misc{papernot2016towards,
2128 year = {2016},
2129 journal = {arXiv preprint arXiv:1611.03814},
2130 author = {Papernot, Nicolas and McDaniel, Patrick and Sinha, Arunesh and Wellman, Michael},
2131 title = {Towards the science of security and privacy in machine learning},
2132}
2133
2134@misc{akhtar2019brief,
2135 year = {2019},
2136 author = {Akhtar, Zahid and Dasgupta, Dipankar},
2137 title = {A brief survey of Adversarial Machine Learning and Defense Strategies},
2138}
2139
2140@misc{zhou2015survey,
2141 year = {2015},
2142 journal = {arXiv preprint arXiv:1508.03326},
2143 author = {Zhou, Li},
2144 title = {A survey on contextual multi-armed bandits},
2145}
2146
2147@misc{caton2020fairness,
2148 year = {2020},
2149 journal = {arXiv preprint arXiv:2010.04053},
2150 author = {Caton, Simon and Haas, Christian},
2151 title = {Fairness in Machine Learning: A Survey},
2152}
2153
2154@article{carroll1991pyramid,
2155 publisher = {Bloomington},
2156 year = {1991},
2157 pages = {39--48},
2158 number = {4},
2159 volume = {34},
2160 journal = {Business Horizons},
2161 author = {Carroll, Archie B and others},
2162 title = {The pyramid of corporate social responsibility: Toward the moral management of organizational stakeholders},
2163}
2164
2165@misc{bhatt2020uncertainty,
2166 year = {2020},
2167 journal = {arXiv preprint arXiv:2011.07586},
2168 author = {Bhatt, Umang and Antor{\'a}n, Javier and Zhang, Yunfeng and Liao, Q Vera and Sattigeri, Prasanna and Fogliato, Riccardo and Melancon, Gabrielle Gauthier and Krishnan, Ranganath and Stanley, Jason and Tickoo, Omesh and others},
2169 title = {Uncertainty as a form of transparency: Measuring, communicating, and using uncertainty},
2170}
2171
2172@article{dhurandhar2018explanations,
2173 year = {2018},
2174 pages = {592--603},
2175 volume = {31},
2176 journal = {NeurIPS},
2177 author = {Dhurandhar, Amit and Chen, Pin-Yu and Luss, Ronny and Tu, Chun-Chen and Ting, Paishun and Shanmugam, Karthikeyan and Das, Payel},
2178 title = {Explanations based on the missing: Towards contrastive explanations with pertinent negatives},
2179}
2180
2181@article{varshney2017safety,
2182 publisher = {Mary Ann Liebert, Inc. 140 Huguenot Street, 3rd Floor New Rochelle, NY 10801 USA},
2183 year = {2017},
2184 pages = {246--255},
2185 number = {3},
2186 volume = {5},
2187 journal = {Big Data},
2188 author = {Varshney, Kush R and Alemzadeh, Homa},
2189 title = {On the safety of machine learning: Cyber-physical systems, decision sciences, and data products},
2190}
2191
2192@article{sattigeri2019fairness,
2193 publisher = {IBM},
2194 year = {2019},
2195 pages = {3--1},
2196 number = {4/5},
2197 volume = {63},
2198 journal = {IBM Journal of Research and Development},
2199 author = {Sattigeri, Prasanna and Hoffman, Samuel C and Chenthamarakshan, Vijil and Varshney, Kush R},
2200 title = {Fairness GAN: Generating datasets with fairness properties using a generative adversarial network},
2201}
2202
2203@inproceedings{wei2020optimized,
2204 year = {2020},
2205 booktitle = {AISTATS},
2206 author = {Wei, Dennis and Ramamurthy, Karthikeyan Natesan and Calmon, Flavio du Pin},
2207 title = {Optimized score transformation for fair classification},
2208}
2209
2210@misc{abdalla2020grey,
2211 year = {2020},
2212 journal = {arXiv preprint arXiv:2009.13676},
2213 author = {Abdalla, Mohamed and Abdalla, Moustafa},
2214 title = {The Grey Hoodie Project: Big Tobacco, Big Tech, and the threat on academic integrity},
2215}Attribution
arXiv:2101.02032v5
[cs.CY]
License: cc-by-4.0


