
Papers is Alpha. This content is part of an effort to make research more accessible, and (most likely) has lost some details from the original. You can find the original paper here.
Introduction
The challenge of transparency in machine learning (ML) models and datasets continues to receive increasing attention from academia and the industry. Often, the goal has been to attain greater visibility into ML models and datasets by exposing source code, contribution trails, introducing ML-drive data analysis methods, and introducing diverse oversight. Transparency and explainability of model outcomes through the lens of datasets has become a huge concern in regulation from government bodies internationally. However, attempts to introduce standardized, practical and sustainable mechanisms for transparency that can be create value at scale often meet limited success in research and production contexts. This reflects real world constraints of the diversity of goals, workflows, and backgrounds of individual stakeholders participating in the life cycles of datasets and artificial intelligence (AI) systems.
As a step towards creating value that connects dataset success to research and production experiences, we propose a new framework for transparent and purposeful documentation of datasets, called Data Cards. A Data Card contains a structured collection of summaries gathered over the life cycle of a dataset about observable (e.g., dataset attributes) and unobservable (e.g., intended use cases) aspects needed for decisions in organizational and practice-oriented contexts. Beyond metadata, Data Cards include explanations, rationales, and instructions pertaining to the provenance, representation, usage, and fairness-informed evaluations of datasets for ML models. These artifacts emphasize information and context that shape the data, but cannot be inferred from the dataset directly.
Data Cards are designed as boundary objectsthat should be easily discoverable, presented in an accessible format at important steps of a user journey for a diverse set of readers. They encourage informed decision making about data used when building and evaluating ML models for products, policy and research.Data Cards complement other longer-form and domain-specific documentation frameworks for ethical reporting, such as Model Cards, Data Statements, and Datasheets for Datasets.
Data Cards are accompanied by frameworks that can be used to adapt them to a variety of datasets and organizational contexts. These frameworks are pivotal to establishing common ground across stakeholders to enable diverse input into decisions. Our case studies deomnstrate that creators of Data Cards were able to discover surprising future opportunities to improve their dataset design decisions, such as considering reasons for a high percentage of unknown values and the need to create a shared understanding of lexicons used in dataset labeling during problem framing within the team.
In summary, our contributions are fourfold:
-
- We document our multi-pronged development methodology in the setting of a large-scale technology company, and present a typology of stakeholders that span a typical dataset lifecycle. We translate these into corresponding objectives and principles for the creation of Data Cards to systematically reduce the knowledge asymmetries across stakeholders.
- We introduce a transparency artifact for at-scale production and research environments, Data Cards —structured summaries of essential facts about various aspects of ML datasets needed by stakeholders across a dataset’s lifecycle for responsible AI development, and describe the content (What information to present ), design (How to present information ), and evaluation (Assess the efficacy of information ) of Data Cards.
- We propose three frameworks for the construction of Data Cards that focus on information organization, question framing, and answer evaluation respectively. Specifically, we describe OFTEn, our novel knowledge acquisition framework to arm dataset producers with a robust, deliberate, and repeatable approach for producing transparent documentation.
- We present case studies on the creation of Data Cards for a computer vision dataset and a language dataset to demonstrate the impact of Data Cards as boundary objects in practice, and discuss the epistemic and organizational lessons learned in scaling Data Cards.
Our collective efforts suggest that in addition to comprehensive transparency artifacts[For the purposes of practicality, we use transparency artifacts as a general term to describe both Data and Model Cards because of their inextricably linked nature. In this paper, we primarily focus on our insights and advances on datasets and correspondingly Data Cards, our novel contribution.], the creation of structured frameworks are not only beneficial in adding nuance to the dataset documentation process itself, but also transformational in introducing human-centric and responsible practices when using datasets in ML applications.
Development Methodology
Over the course of 24 months, multiple efforts were employed to design Data Cards and its supporting frameworks, borrowing from methods in human-centered design, participatory design, and human-computer interaction. We worked with dataset and ML teams in a large technology company to iteratively create Data Cards, refining our design decisions to respond to challenges in production contexts. In parallel, we ran studies and workshops to identify opportunities and challenges in the implementation of Data Cards. In this section, we detail the various efforts and describe their impact on the development of Data Cards.
Specifically, we worked with 12 teams in a large technology company to create 22 Data Cards that describe image, language, tabular, video, audio, and relational datasets in production settings. Teams ranged in size from four to over 20 members, and were comprised of some combination of research software engineers, research scientists, data analysts and data program managers. This allowed us to observe each teams’ documentation workflows, collaborative information gathering practices, information requests from downstream stakeholders, review and assessment practices. Our co-creative approach in conjunction with feedback received across other studies yielded continuous improvements in the usability and utility of each new Data Card created.
As we worked with ML dataset and model owners to produce prototypical transparency artifacts, their drafts were evaluated in an external focus group with nine participants. These participants represented non-expert, technical use cases from User Experience (UX) and Human-Computer Interaction (HCI) research, Policy, Product Design & Development, Academia, and Law. Participants were asked to complete a paper-based questionnaire to reflect on their ideals of transparency. This was used as a basis for a broader discussion on transparency. Participants were then provided with printed artifacts which they annotated with their feedback. This allowed us to capture specific feedback and establish relationships across themes and topics in the artifacts. We concluded with a discussion reflecting on their use of transparency artifacts and an offline survey to capture their overall expectations. Through this focus group, we were able to arrive at a working definition and values of transparency relevant to domains within AI product life cycles. We further synthesized feedback on the transparency artifacts into an initial set of recommendations to combat common reader-side challenges, which were then offered as guidance to teams creating Data Cards.
Based on our experience in co-creating Data Cards with teams, we were able to consolidate recurring and overlapping questions into a canonical template that documents 31 different aspects of data sets. Questions that are were modality-specific were consolidated into appendable blocks, but largely left out of the canonical template. A follow-upMaxDiff survey (n=191) was conducted to understand the information needs in dataset documentation within our company. Through this survey, we learned the relative importance of the 31 different themes documented in a Data Card, how these vary by dataset modality and job function, further incorporated into our design of Data Cards. We observed the need for a generative framework that Data Card creators could use to add or tailor question to new datasets without compromising the readability, navigability, comparability and transparency intrinsic to the Data Card.
Our internal study recruited 30 experts spanning sixteen teams within our company. Participants represented stakeholders who (a) create datasets designed for ML use cases and (b) use or review datasets for applied and foundational model development. Over the course of three days, this group engaged in various participatory activities to capture their use cases for transparency artifacts, information requirements and strategies for evaluation of transparency artifacts. Participants were then invited to actively contribute to future discussions of Data Cards and their development as it related to the participant’s specific data domains. We found that despite their deep expertise and experience, participants were unable to provide examples of exemplary documentation, but were quick to furnish ’excellent’ examples of poor documentation. This pointed us to the need for a set of dimensions that can be used to assess transparency and documentation without conflating documentation with the dataset.
Further, we developed a structured participatory workshop-based approach to engage cross-functional stakeholders when creating transparent metadata schema for dataset documentation. This methodology was open-sourced and tested in the data domains of human computation, geo-spatial ML, multi-modal data operations, healthcare data, community-engaged research, and large-scale multitask language models. Common to all workshops, we found that teams adopting Data Cards often started with an intuition about the benefits of transparency in dataset documentation. To define the content, infrastructure, and processes for data card creation (and other complementary documentation artifacts) required that teams aligned on a shared definition of transparency, audience, and the audience’s requirements. We observed organization-specific factors that can impact long-term sustainability of scaling Data Cards, such as knowledge asymmetries between stakeholders, organizational processes that incentivize the creation and maintenance of documentation, infrastructure compatibility and readiness, and communication culture across and within stakeholder groups. While a detailed discussion of our participatory methodology to developing transparency metadata schemasand survey is beyond the scope of this paper, we introduce relevant critical frameworks from our methodology.
Framing Transparency in the Context of Data Cards
Despite the diverse backgrounds of participants across studies, a shared dominant perception was that transparency artifacts were, ironically, opaque. The opacity in documentation, quite simply, increases when language used is technical, dense, and presumptive of a reader’s background, making it difficult for non-technical stakeholders to interpret. This leads to sub-optimal decision making, and propagates asymmetries in power structures and myopic AI data practices. Participants described transparency as subjective, audience-specific and contextual. To that end, we frame our definition of transparency as “a clear, easily understandable, and plain language explanation of what something is, what it does and why it does that” , to emphasize the domain-agnostic and inclusive prerogative of transparency artifacts. We present eight characteristics of transparency that are vital for a robust discussion of the benefits, values, ethics, and limitations of AI datasets (Table tab-transparency).
Data Cards aim to provide a singular framework that allows non-traditional stakeholders across product, policy, and research to understand aspects about datasets and how they are used to make informed decisions. We found that stakeholders review role-related topics in Data Cards with amplified scrutiny, and follow-up questions progressively increase in specificity. This highlighted a fundamental principle underpinning transparency—that transparency is attained when we establish a shared and Socratic understanding of datasets based on the ability to ask and answer questions over time .
A Typology of Stakeholders
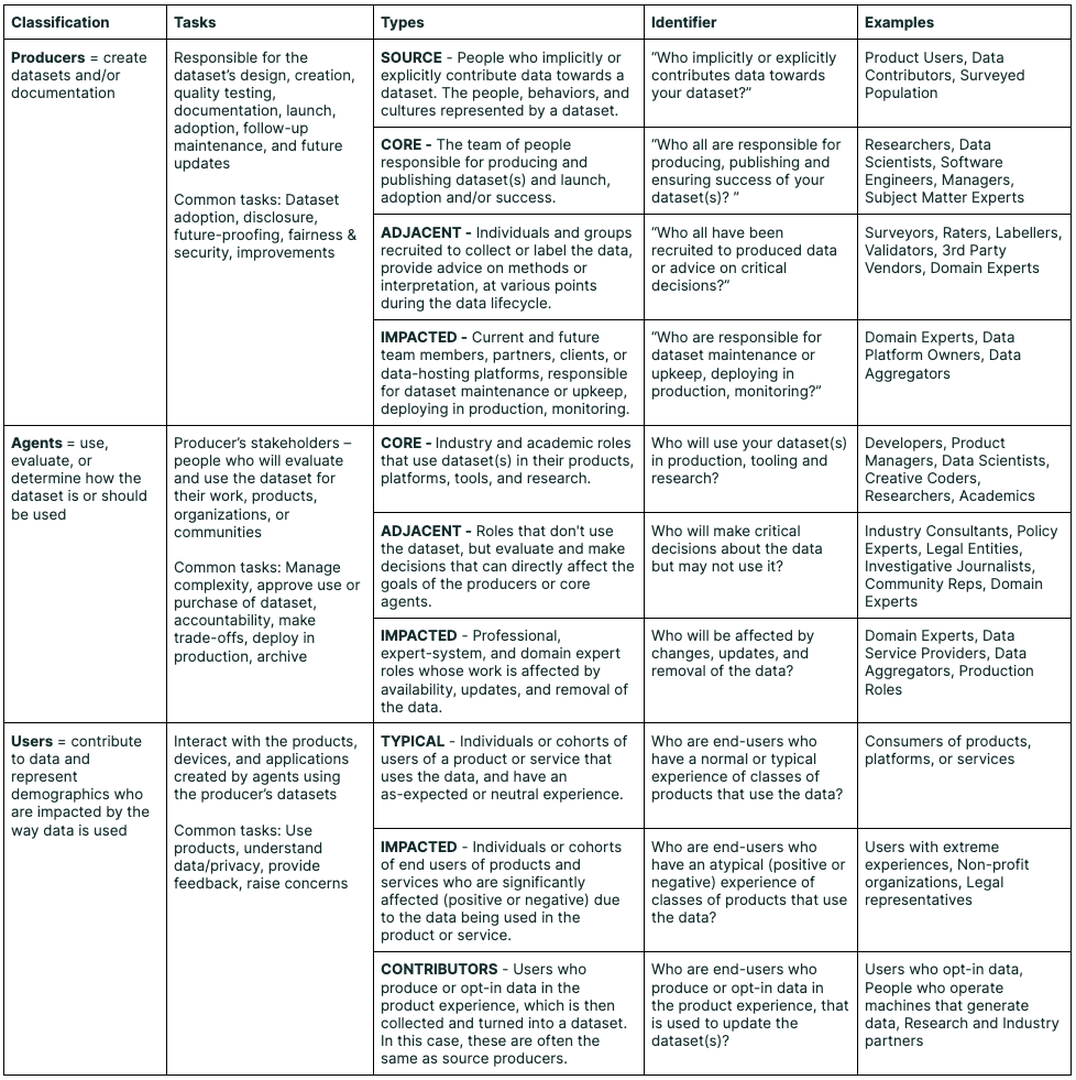
At first, our audience for Data Cards was fairly broad, comprising a mix of experts and non-experts. Frameworks proposed by Suresh, et alhave distinguished higher-level domain goals and objectives from lower-level interpretability tasks, but are limited by their epistemological framing and vast scope. We created a broad yet decomposable typology describing three stakeholders groups in a dataset’s life cycle, allowing us to consider how cross-functional stakeholders engage in decision-making on the basis of a single transparency artifact.
Producers are upstream creators of dataset and documentation, responsible for dataset collection, ownership, launch and maintenance. Producers often subscribed to a single, informal notion of “users” of Data Cards—loosely characterized by high data domain expertise, familiarity with similar datasets, and deep technical knowledge. However, in practice, we find that only a few readers or Agents actually meet all these requirements.
Agents are stakeholders who read transparency reports, and possess the agency to use or determine how themselves or others might use the described datasets or AI systems. After testing prototypes and proof of concepts with different audience groups, it became clear that agents with operational and reviewer needs were distinct categories, and includes stakeholders who may never directly use the dataset, but will engage with the Data Card (for e.g. reviewers or non-technical subject matter experts). Agents may or may not possess the technical expertise to navigate information presented in typical dataset documentation, but often have access to expertise as required.
Additionally, agents are distinct from Users , who are individuals and representatives who interact with products that rely on models trained on dataset. They may consent to providing their data as a part of the product experience. Users require a significantly different set of explanations and controls grounded within product experiences. We therefore restrict the use of Data Card for agents with access to technical expertise, and encourage the use of alternative transparency artifacts for users that are designed exclusively for that purpose.
We further dis-aggregate these high-level groups to generate awareness and emphasize the unique decisions that each sub-group must make (Fig[typologytable]). However, these groupings exist on a continuum and stakeholders may fall into more than one group concurrently, depending on the context. We used this typology to unearth assumptions that are often made about the rich intersectional attributes of individual stakeholders, such as expertise (e.g. novice or expert), data fluency (e.g. none to high), job roles (e.g. Data Scientist, Policy Maker), function performed vis-à-vis the data (Data Contributor, Rater), and goals or tasks (Publishing a dataset, Comparing datasets) when conceptualizing Data Cards. Usability studies across these groups revealed guidelines for the successful and appropriate adoption of Data Cards in practice and at scale. These are distilled into the following objectives for Data Cards:
O1. Consistent:
Data Cards must be comparable to one another, regardless of modality or domain such that claims are easy to interpret and validate within context of use. A Data Card creation effort should solicit equitable information from all datasets. While deploying one-time Data Cards is relatively easy, we find that organizations need to preserve comparability when scaling adoption.
O2. Comprehensive:
Rather than being created as a last step in a dataset’s lifecycle, it should be easy to create a Data Card concurrently with the dataset. Further, the responsibility of filling out fields in a Data Card should be distributed and assigned to the most appropriate individual. This requires standardized methods that extend beyond the Data Card, to the various reports generated in the dataset’s lifecycle.
O3. Intelligible and Concise:
Readers have varying levels of proficiency[Proficiency is a combination of data fluency and domain expertise. Data fluency is described as the familiarity and comfort that readers have in working with data that is both, in or outside of their domain of expertise. The greater the comfort with understanding, manipulating, and using data, the greater the fluency. Domain expertise is defined as “knowledge and understanding of the essential aspects of a specific field of inquiry”in reference to the domain of the dataset.] which affects their interpretation of the Data Card. In scenarios where stakeholders differences in proficiency, individuals with the strongest mental model of the dataset become de-facto decision makers. Tasks that are more urgent or challenging can reduce the participation of non-traditional stakeholders (See typologytable) in the decision, which is left to “the expert”.This risks omitting critical perspectives that reflect the situated needs of downstream and lateral stakeholders. A Data Card should efficiently communicate to the reader with the least proficiency, while enabling readers with greater proficiency to find more information as needed. The content and design of a Data Card should advance a reader’s deliberation process without overwhelming them, and encourage stakeholders cooperation towards a shared mental model of the dataset for decision-making.
O4. Explainability, Uncertainty:
Study participants reported that ‘known unknowns’ were as important as known facets of the dataset in decision making. Communicating uncertainty along with meaningful metadata was considered a feature and not a bug, allowing readers to answer questions such as “Is a specific analysis irrelevant to the dataset or were the results insignificant?” or “Is information withheld because it is proprietary or is it unknown? ”. Clear descriptions and justifications for uncertainty can lead to additional measures to mitigate risks, leading to opportunities for fairer and equitable models. This builds greater trust in the dataset and subsequently, its publishers.
Data Cards
Data Cards capture critical information about a dataset across its life cycle. Just as is true with every dataset, each Data Card is unique, and no single template satisfactorily captures the nuance of all datasets. In this section, we introduce our guiding principles, and offer a three-pronged description that elaborates on the design, content, and evaluation of Data Cards. We introduce corresponding frameworks that allow Data Cards to be tailored but preserve the utility and intent of Data Cards.
Principles
While most previous approaches take domain-specificor approachesthat have been prescriptively adopted as a way of creating transparency artifacts, our novel contributions are the generative design of Data Cards as an underlying framework for transparency reporting for readability and scaling in production contexts. To meet the objectives stated above, Data Cards have been designed along the following principles:
- P1. Flexible: Describe a wide range of datasets – live or static, datasets that are actively being curated from single or multiple sources, or those with multiple modalities.
- P2. Modular: Organize documentation into meaningful sections that are self-contained repeatable units, able to provide an end-to-end description of a single aspect of the dataset.
- P3. Extensible: Components that can be easily reconfigured or extended systematically for novel datasets, analyses, and platforms.
- P4. Accessible: Represent content at multiple granularities so readers can efficiently find and effectively navigate detailed descriptions of the dataset.
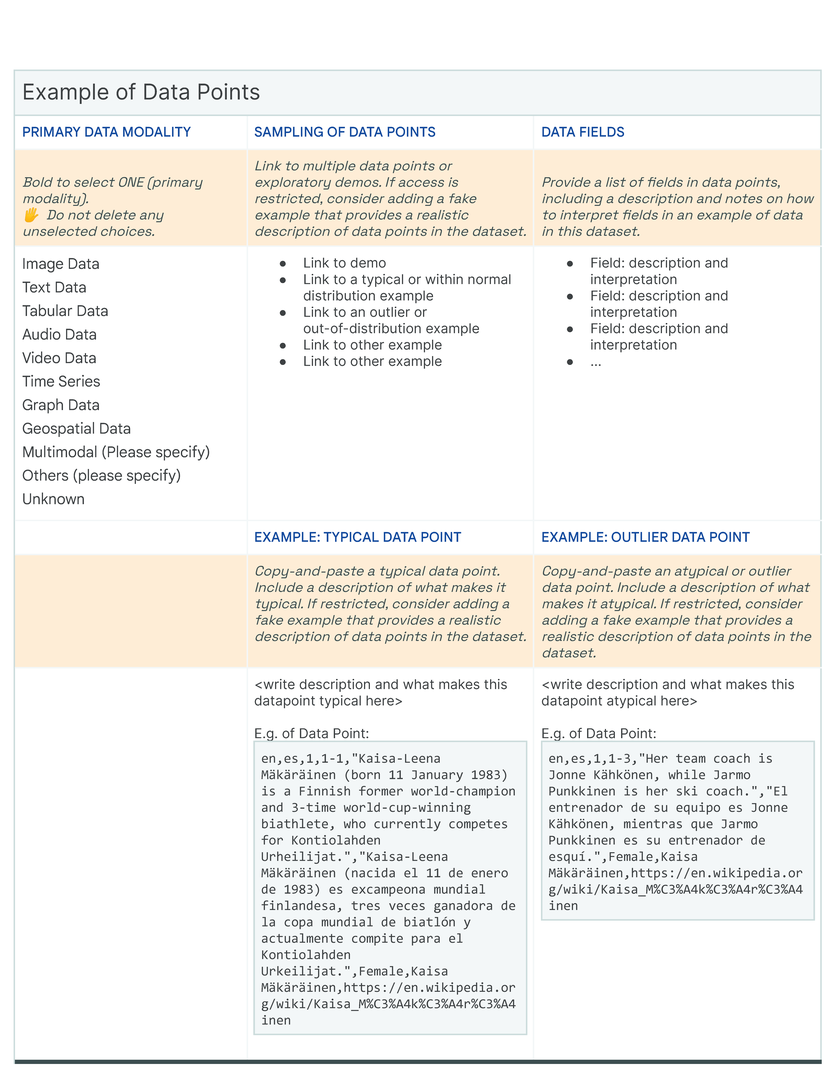
- P5. Content-agnostic: Support diverse media including multiple choice selections, long-form inputs, text, visualizations, images, code blocks, tables, and other interactive elements.
Design and Structure
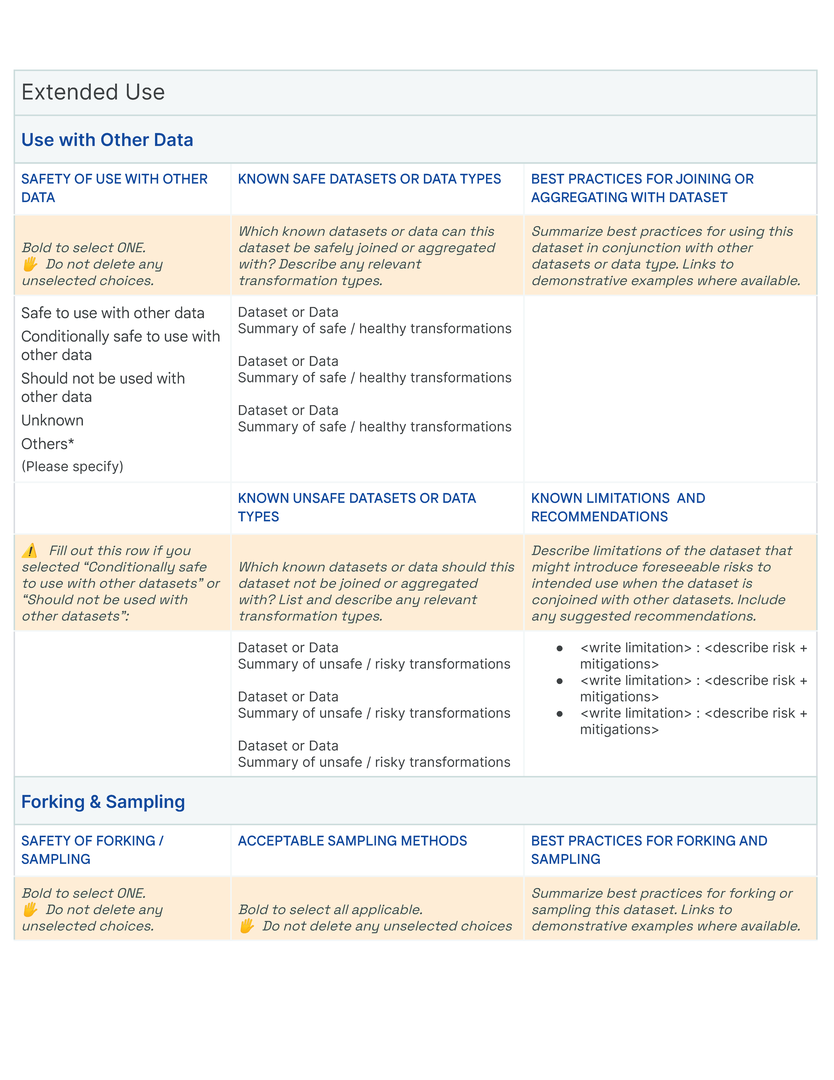
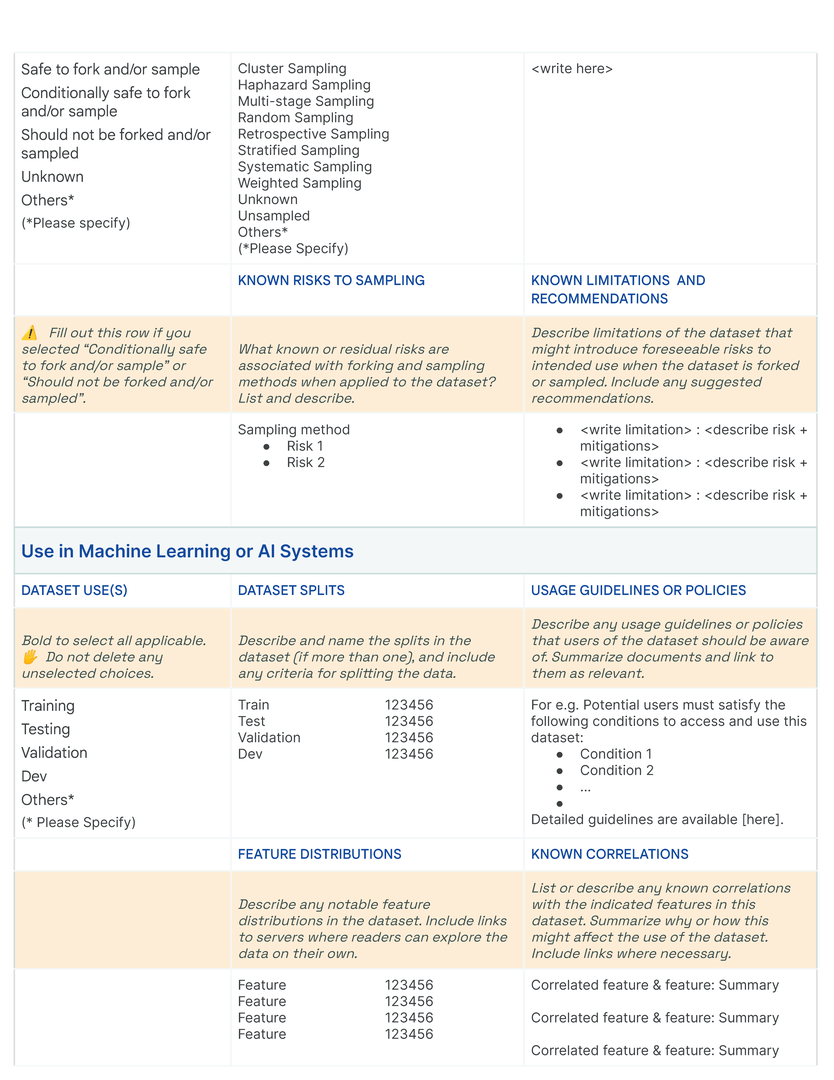
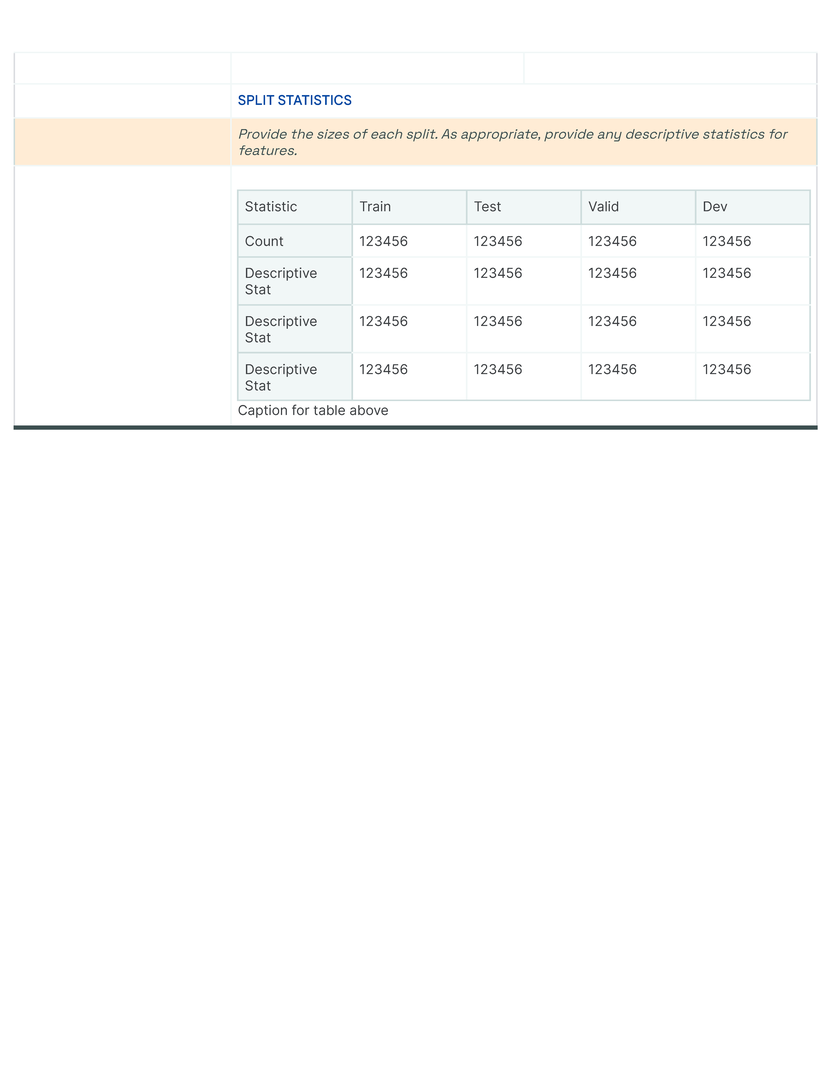
The fundamental “display” unit of a Data Card is a block which consists of a title, a question, space for additional instructions or descriptions, and an input space for answers. Answer inputs are reinforced with structure to create blocks that are specifically suited for long- or short-form text, multiple or single choice responses, tables, numbers, key value pairs, code blocks, data visualizations, tags, links, and demos of the data itself, in alignment with principles (P2 ) and (P5 ). In our templates, we iteratively introduced structures for open-ended answers, predetermined responses for multiple choice questions, and demonstrative examples where responses could be complex (Fig. fig-teaser). Producers found these assistive efforts as useful guides for setting expectations about consistency, clarity, and granularity in responses. When completed, blocks typically retained titles and answers (See fig fig-datacard).
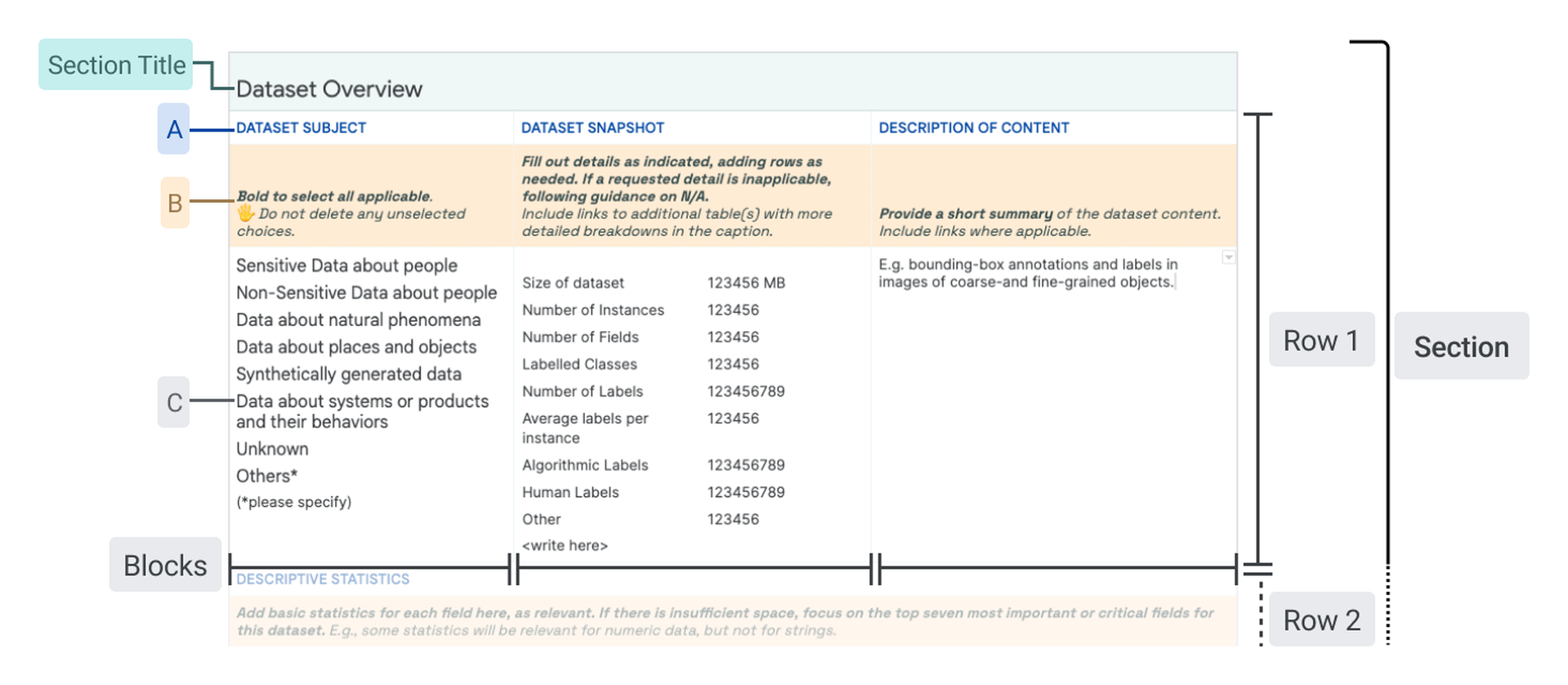
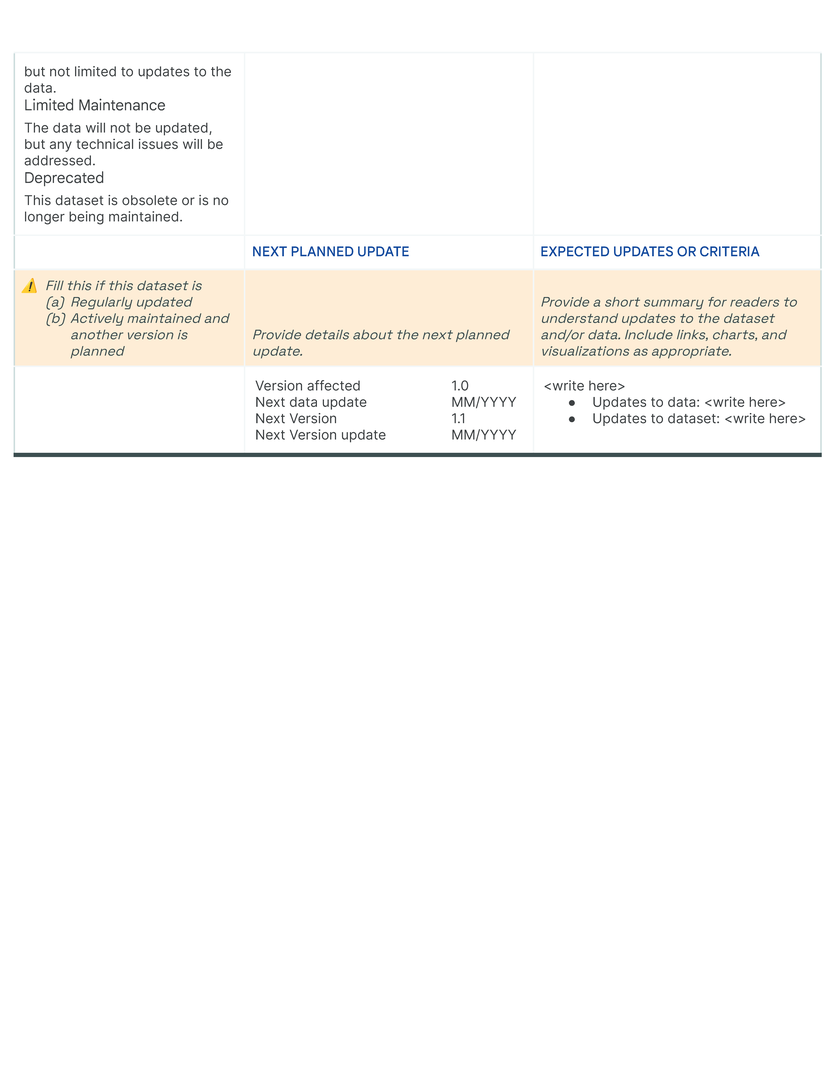
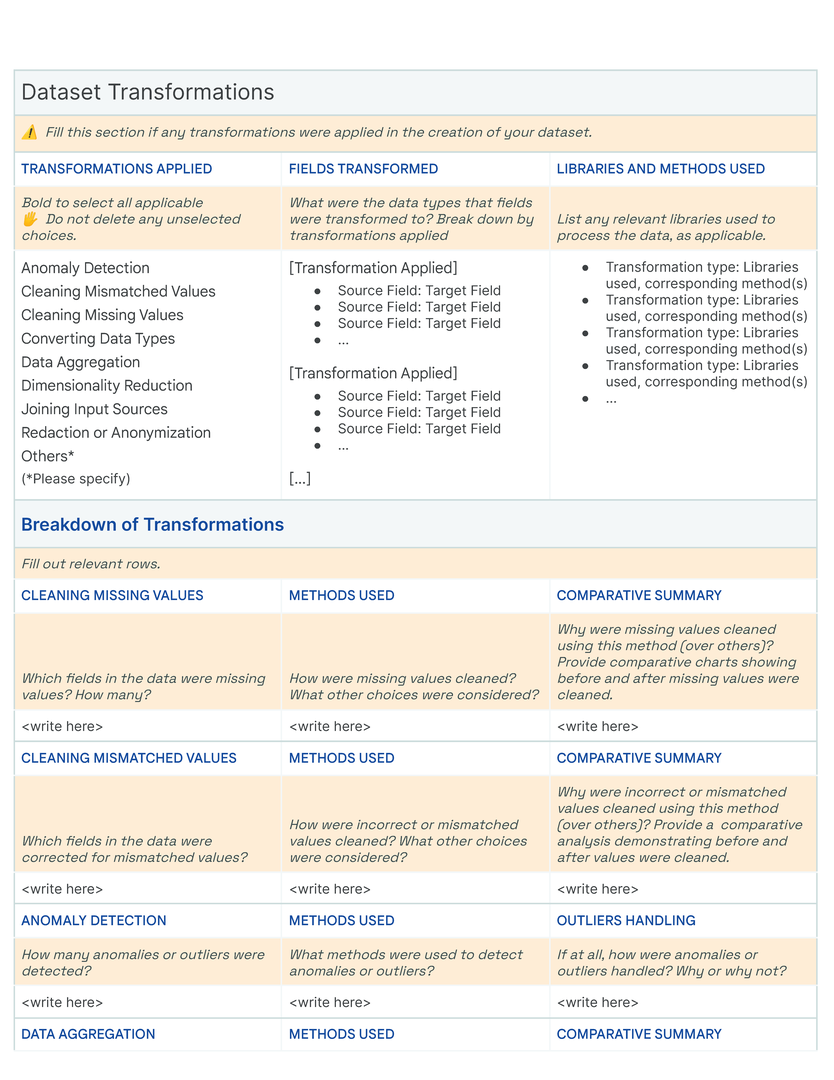
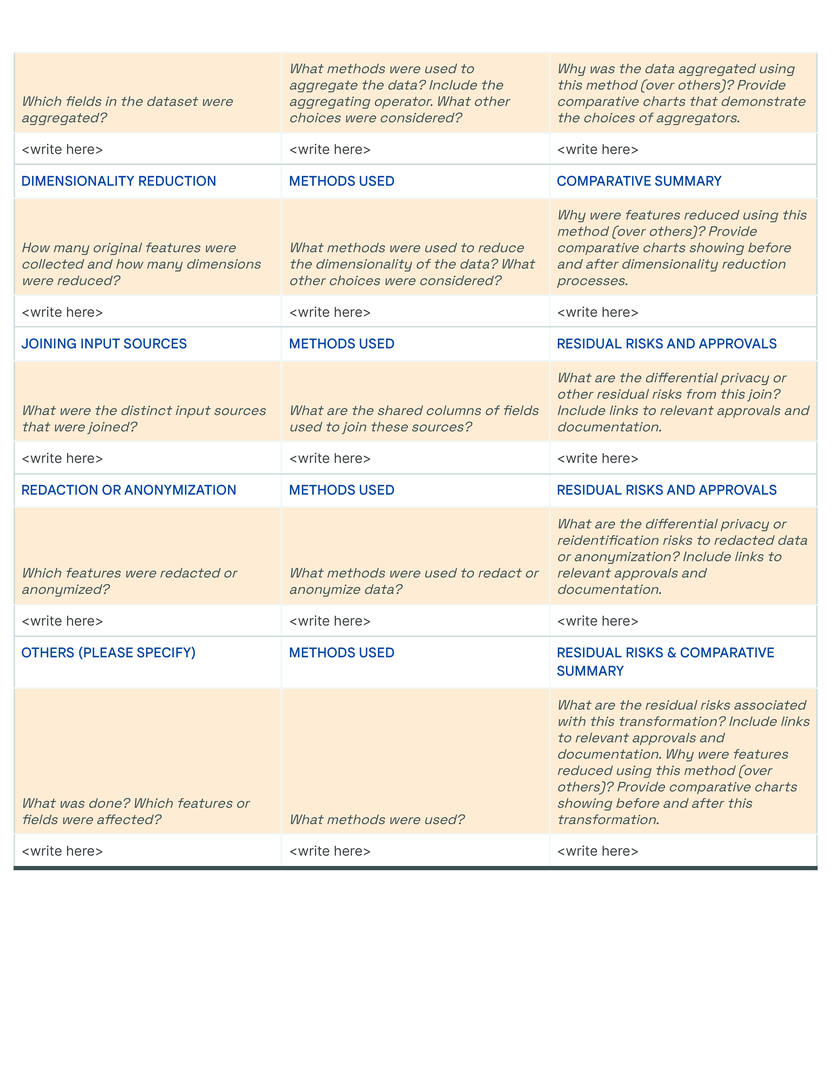
Blocks are arranged thematically and hierarchically on a grid to enable an “overview first, zoom-and-filter, details-on-demand ”presentation of the dataset. In our template, blocks with related questions are organized into rows , and rows are stacked to create sections using meaningful and descriptive titles (Figure fig-teaser). Each row is thematically self-contained so readers can effectively navigate multiple facets of a dataset in a Data Card. Answers increase in both detail and specificity across columns in the direction of the language in which the Data Card is written, allowing readers to find information at the appropriate fidelity for their tasks and decisions. Where appropriate, a single block may span multiple columns. Sections are vertically arranged based on functional importance in a nested hierarchy marked by section titles in the first Data Card [dc1]. Here, all necessary sections (dataset snapshot, motivations, extended use, collection and labeling methods) are established in order to provide greater context for interpreting sections that describe fairness-related analyses (fairness indicators, bounding box sizes). In contrast, sections in the second Data Card [dc2] are organized in a flat hierarchy, suggesting equal importance of all blocks. Variation within the formatting of the content communicates both denotative and connotative meaning.
Socratic Question-Asking Framework: Scopes
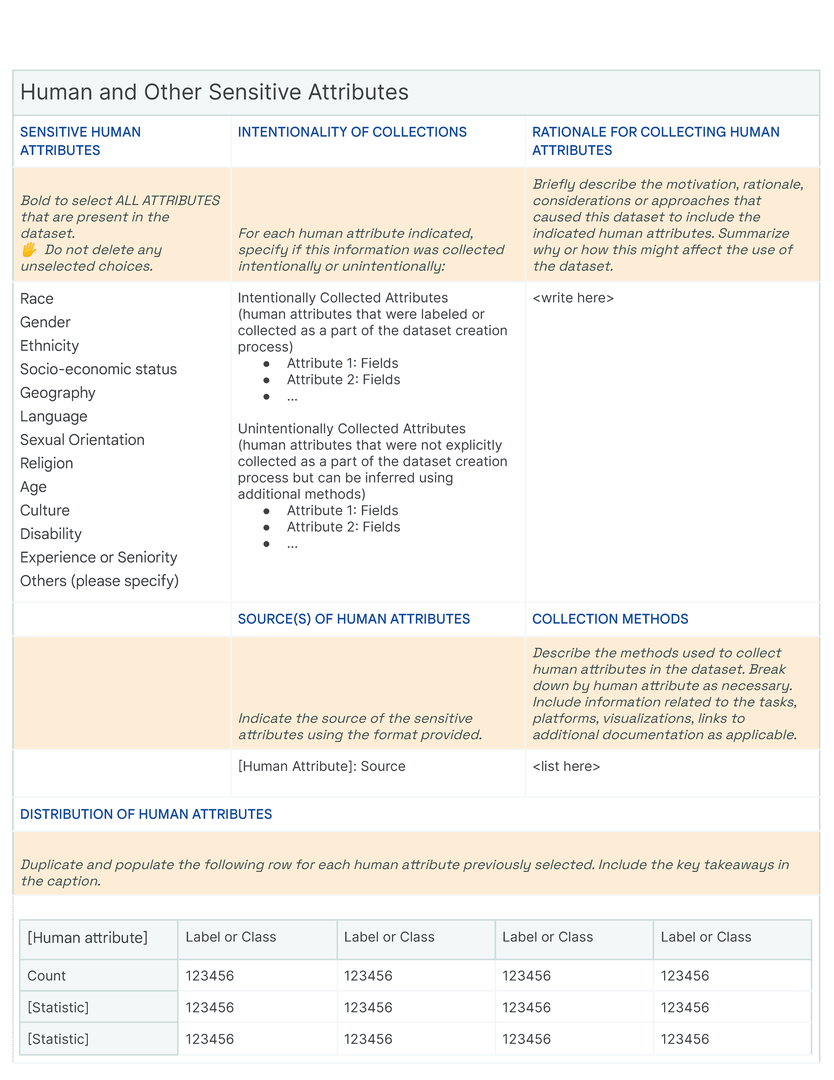
To maintain Data Cards’ accessibility (P4) and enable agents with varying proficiency levels to progressively explore content, new information needs to be introduced at multiple levels of abstraction. Further, adding ad-hoc blocks risks structurally compromising Data Cards for readers and producers alike, and can reduce its usability and integrity. Pertinent to objectives O2 and O3 , we provide a structured approach to framing and organizing questions to address common challenges in adapting Data Card templates for new datasets. Depending on its specificity, a new theme is deconstructed or a single question extrapolated into at least three questions at varying granularities, which we characterize as telescopes, periscopes, and microscopes. For the purposes of demonstration, we consider the documentation of sensitive human attributes:
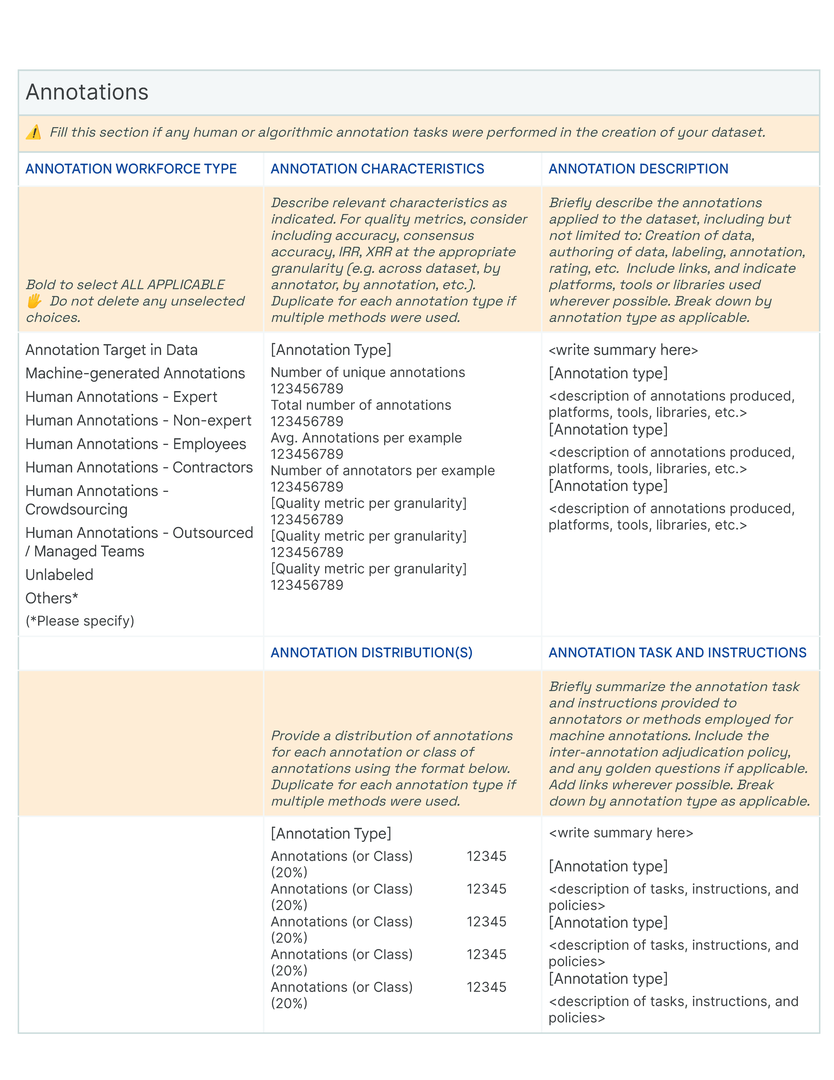
Telescopes provide an overview of the dataset. These are questions about universal attributes that are applicable across multiple datasets, for example “Does this dataset contain Sensitive Human Attributes? “. Telescopes can be framed as binary (contains, does not contain ) or multiple choice (Select all that apply: Race, Gender, Ethnicity, Socio-economic status, Geography, Language, Sexual Orientation, Religion, Age, Culture, Disability, Experience or Seniority, Others (please specify) ). These serve three specific purposes. First, telescopic questions generate enumerations or tags that are useful for knowledge management, indexing and filtering in large repository of Data Cards. Second, they introduce and set context for additional information within a row, helping readers navigate larger or more complex Data Cards. Lastly, telescopic questions introduce conditional logic to streamline the experience of filling out a Data Card. When viewed together, telescopic questions offer a shallow but wide overview of the dataset.
Periscopes provide greater technical detail pertaining to the dataset. These are questions about attributes specific to the dataset that add nuance to telescopes. For example,“For each human attribute selected, specify if this information was collected intentionally as a part of the dataset creation process, or unintentionally not explicitly collected as a part of the dataset creation process but can be inferred using additional methods)” . A periscopic question can ask for operational information such as the dataset’s shape and size, or functional information such as sources or intentions. Responses typically look like key-value pairs, short descriptions, tables, and visualizations. Since periscopes often describe analysis results, statistical summaries, and operational metadata, they are often reproducible and can be automated wherein automating generates results that are more accurate or precise than human input.
Microscopes offer fine-grained details. These are questions about the “unobservable” human processes, decisions, assumptions and policies that shape the dataset. These elicit detailed explanations of decisions or summarize longer process documents that governed responses to the corresponding periscopic questions. For example, “Briefly describe the motivation, rationale, considerations or approaches that caused this dataset to include the indicated human attributes. Summarize why or how this might affect the use of the dataset. ”. Necessarily, these are difficult to automate unless there are standardized terms or operating procedures. Answers to microscopes are typically long-form text with lists and links, data tables, and visualizations.
We find that the interpretations of a Data Card are greatly influenced by the presence or absence of these levels of abstraction. Telescopic questions are easiest to answer, but offer relatively low utility. Periscopic questions facilitate quick assessments of suitability and relevance of the dataset, essential for simple decision-making. We observed that microscopic questions were most challenging to answer since they require articulating implicit knowledge. Yet, these questions enabled agents and producers alike to assess risk, plan mitigations, and where relevant, identify opportunities for better dataset creation. Together, telescopes, periscopes, and microscopes layer useful details such that numerous readers can navigate without losing sight of the bigger picture.
Content and Schema
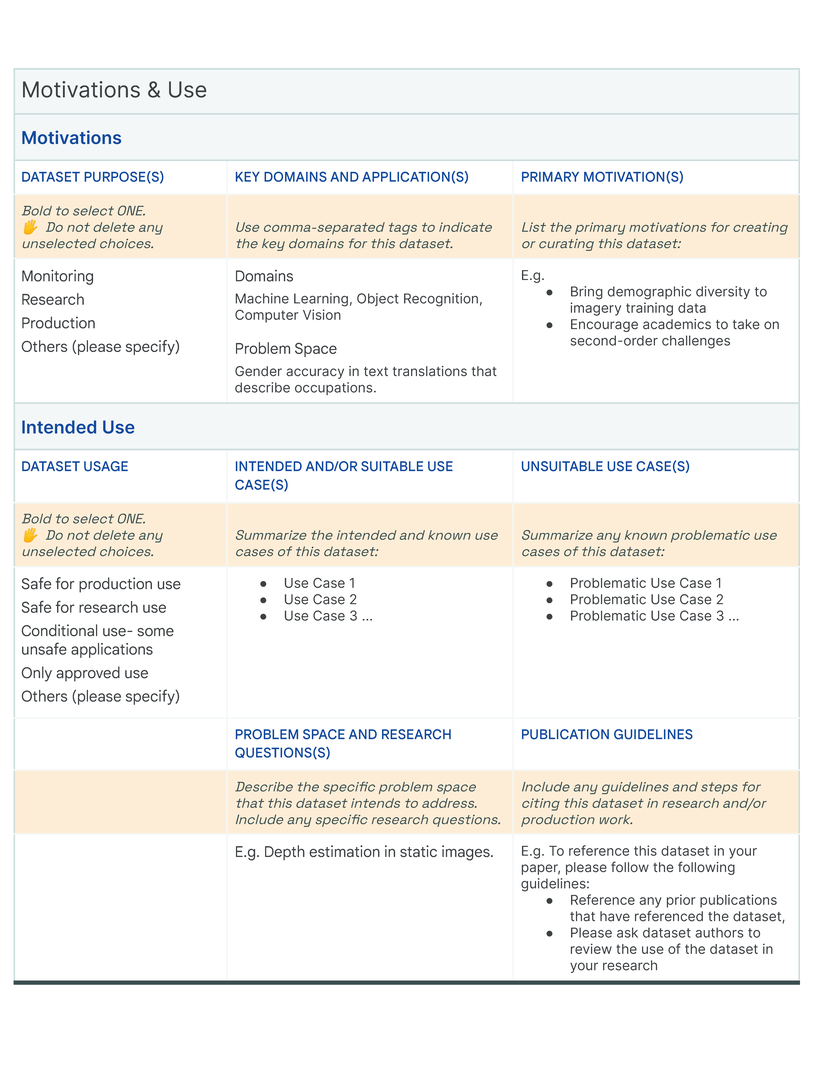
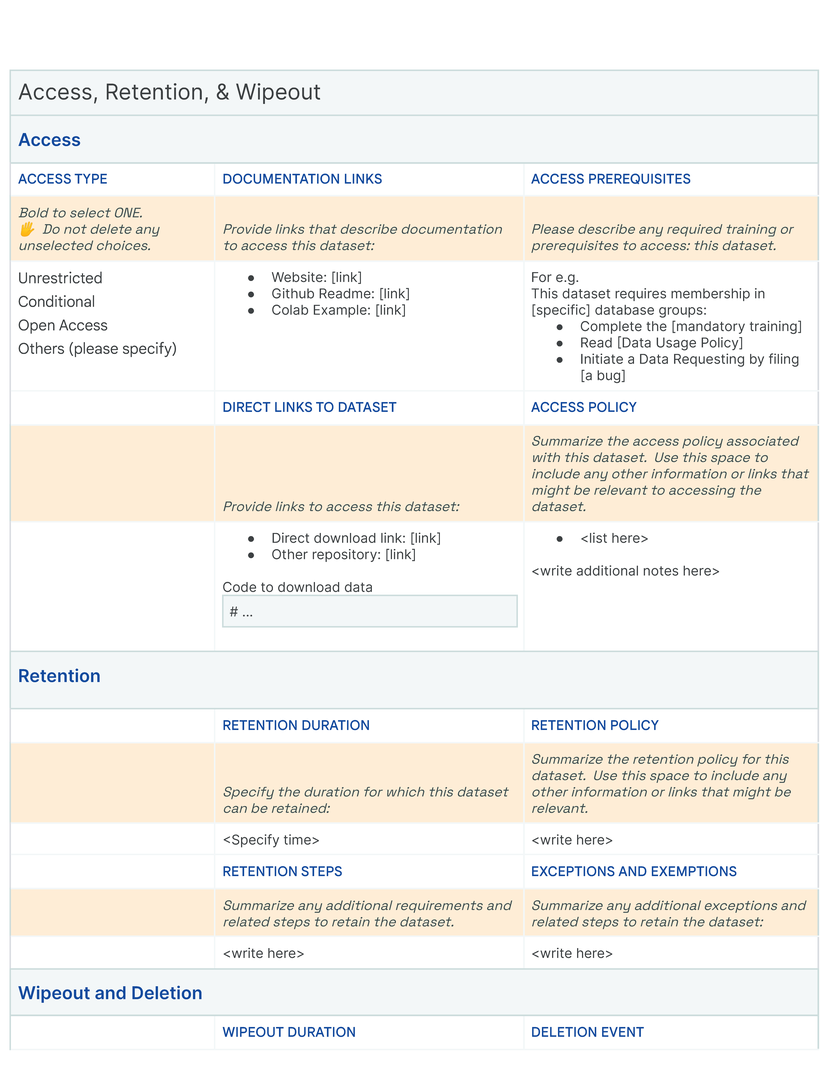
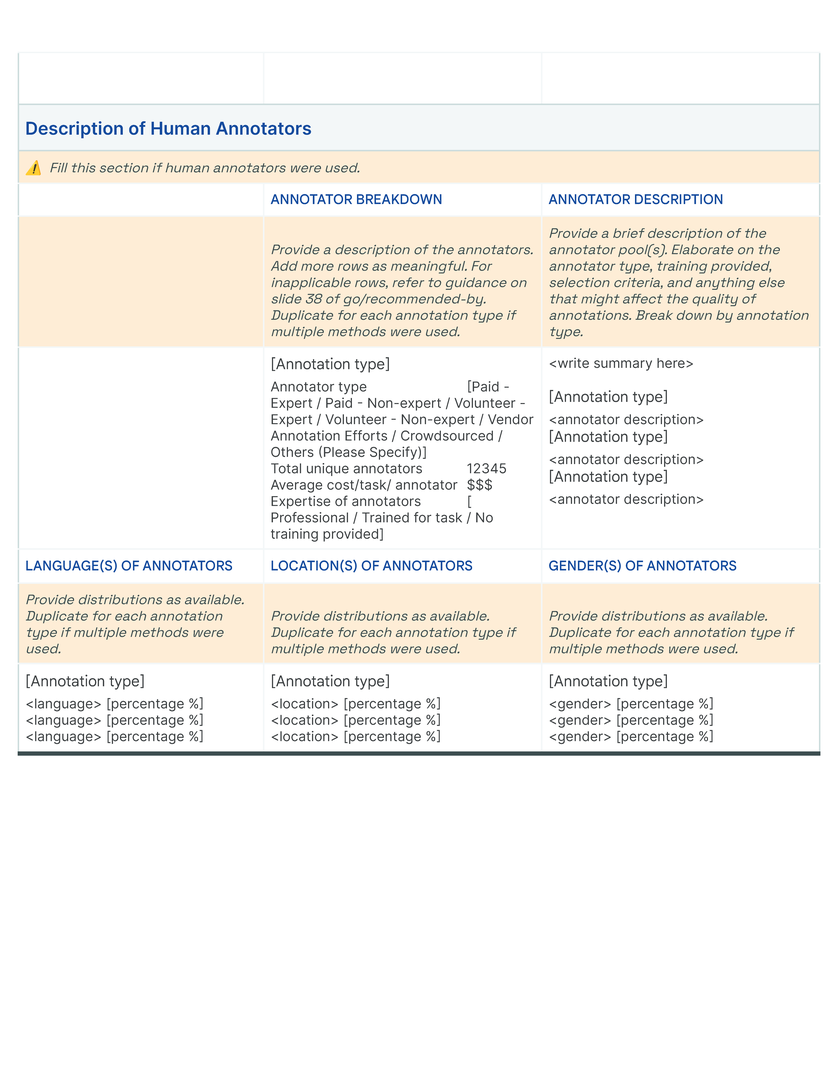
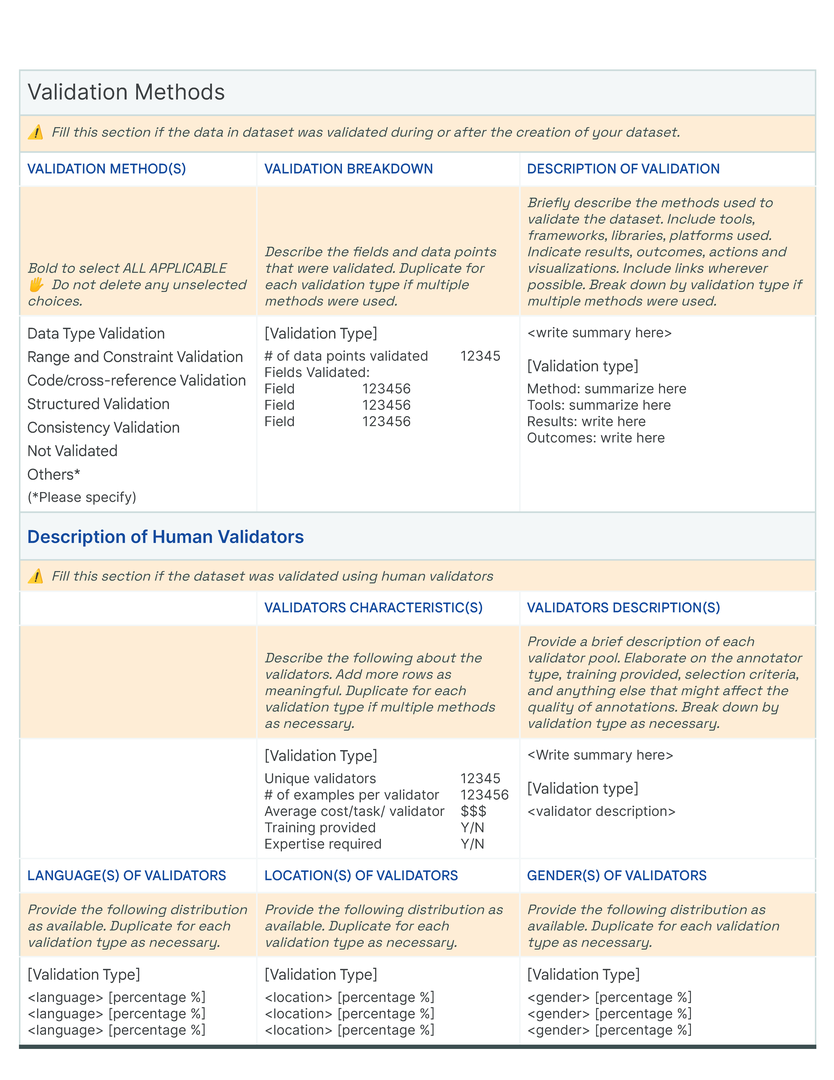
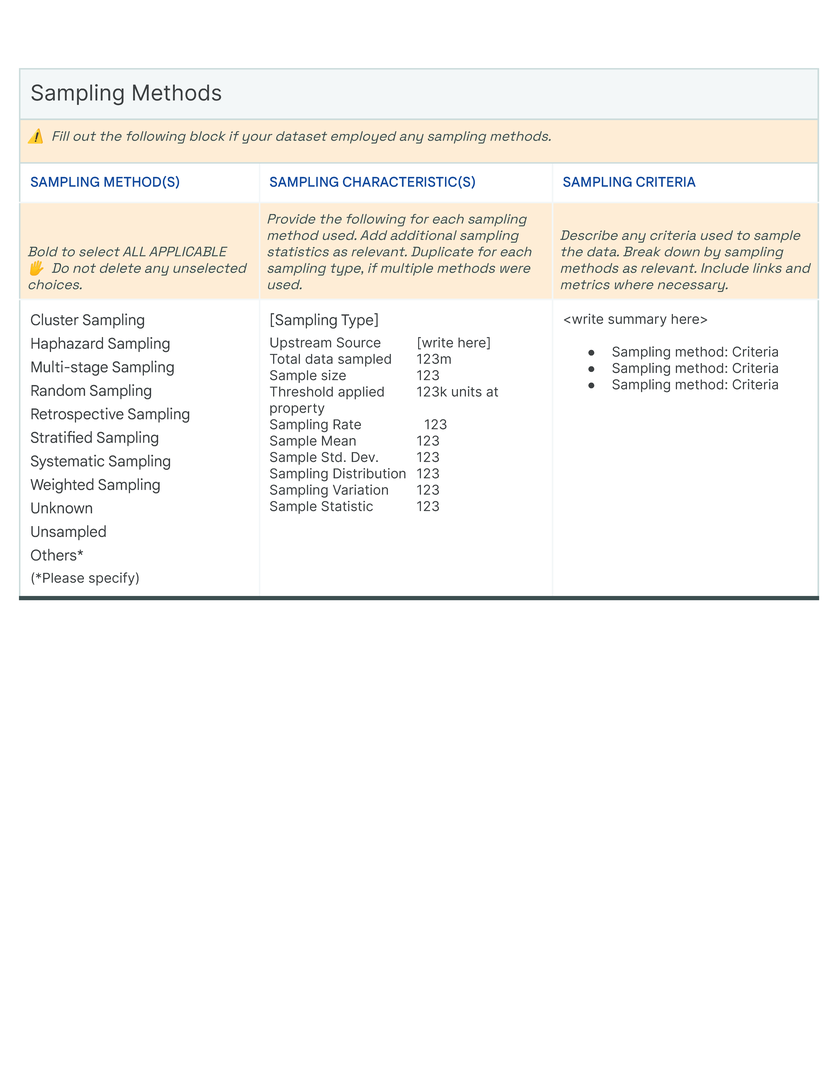
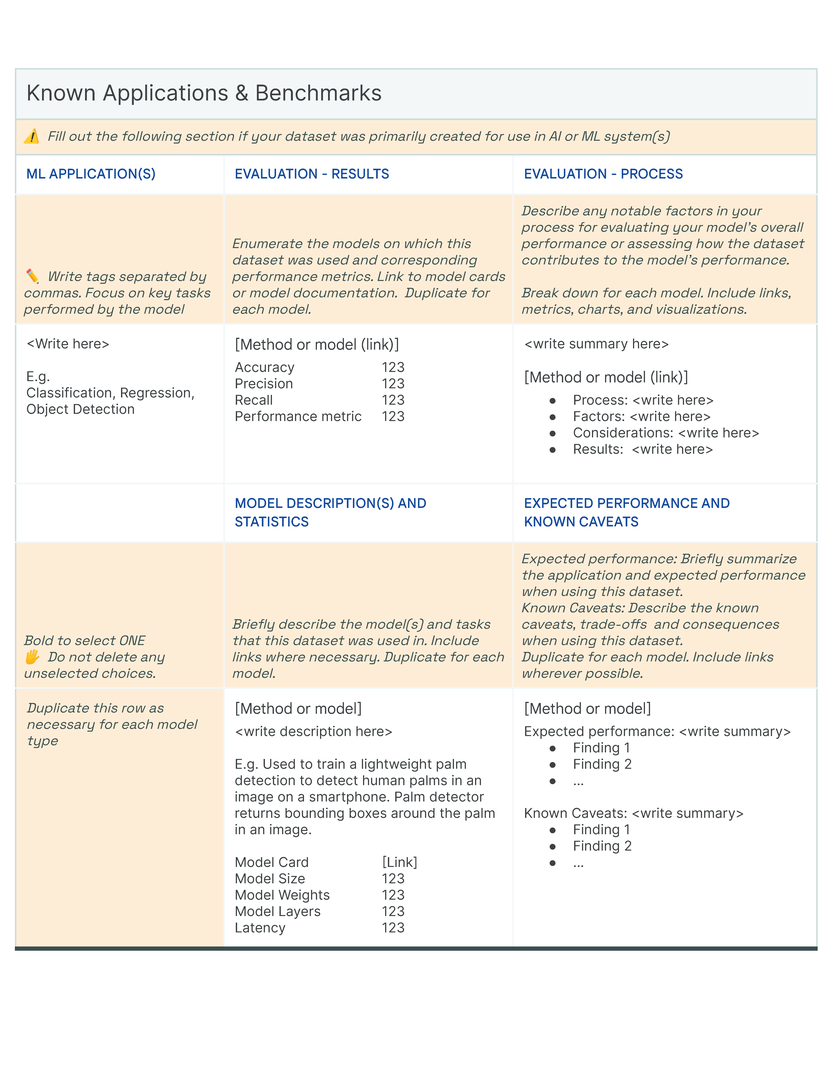
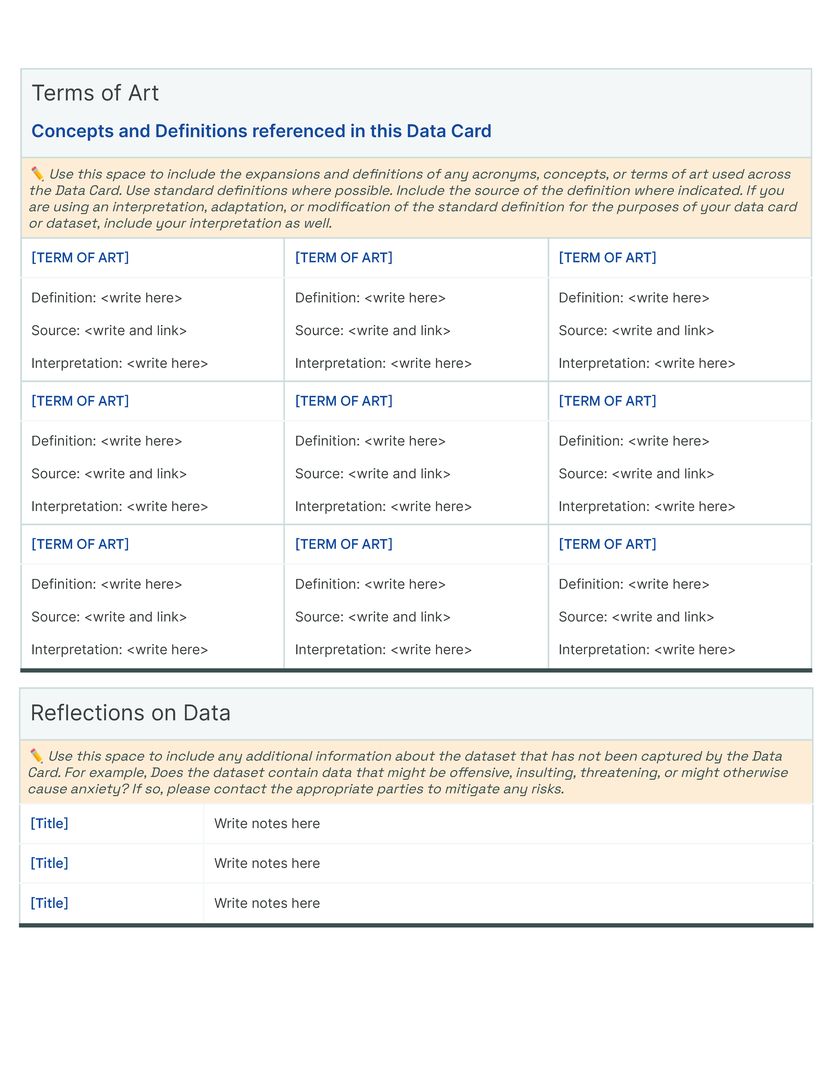
Our initial approach was to create a single template to capture the provenance, intentions, essential facts, explanations and caveats in an accessible and understandable way. In co-creating Data Cards for different types of datasets, we identified 31 broad, generalizable themes (Table tab-content-schema) that can comprehensively described any dataset (O2 ). However, these vary in importance on a per-task basis to stakeholders. Sections in our template (dc-template) demonstrate how these themes are broken down into sets of scopes (scopes-framework). To illustrate the differences in descriptions of the same theme in Data Cards, we include Data Cards from our case studies (cs1, cs2) in our appendix (dc1, dc2).
OFTEn Framework
Over time, we found it necessary to develop a consistent and repeatable approach to identify and add new themes from dataset life cycles in a Data Card that are reportable by everyone in the organization. Additionally, certain topics, such as consent, can span entire dataset life cycles with different implications at each stage. We introduce OFTEn, a conceptual tool for logically considering how a topic can promulgate across all parts of a Data Cards (P1, P3 ), that can be used inductively and deductively for detailed dataset transparency investigations.
OFTEn (Table table-often-description) is an acronym to describe common stages in the dataset life cycle (“Origins, Factuals, Transformations, Experience, and n=1 example “). Though ordered, stages are loosely defined to mirror typical non-linear dataset development practices. Of note, how agents use the dataset practice is considered a distinct stage in OFTEn, affording the flexibility to incorporate feedback from downstream stakeholders (dataset consumers, product users, and even data contributors). This establishes a trail to track the performance of AI systems trained and evaluated on the dataset, and exposes any caveats or limitations that agents should be aware of.
An OFTEn analysis of the dataset can preemptively enable the discovery of insights that would otherwise not be generally evident. Inductively, OFTEn supports activities with agents to formulate questions about datasets and related models that are important for decision-making. At its simplest, it can be visualized as a matrix in which rows represent the dataset life cycle, and columns provide prompts to frame questions (who, what, when, where, why, and how) about a given topic in the dataset’s lifecycle (Table table-often-description. Its participatory use enables reporting both dataset attributes and implicit information that can affect outcomes in real-world deployment. Deductively, we use OFTEn to assess if a Data Card accurately represents the dataset, resulting in formative effects on both, documentation and dataset. Lastly, we find that Data Cards with a clear underlying OFTEn structure are easy to expand and update. This structure allows Data Cards to capture information over time, such as feedback from downstream agents, notable differences across versions, and ad-hoc audits or investigations from producers or agents.
Evaluation of Data Cards
To understand how Data Cards were created and maintained, we worked with over 18 producers to understand workflows. We found that producers had a tendency to duplicate completed Data Cards (which described similar datasets) as a base template instead of using the provided template. While this made the Data Card easier to complete, it resulted in identical but inaccurate responses. Errors in the original Data Card would propagate in forked version. Producers would delete blocks and sections that were irrelevant to their dataset, and in specific cases, producers would semantically modify questions to suit their datasets. Though justifiable in the context of a single Data Card, these practices led to the subsequent fragmentation of forked Data Cards. Deleted but relevant questions were irrecoverable, and reconciling updates to the original template was labor-intensive. Producers resorted to answering “N/A"when they were unsure of the answer, or when uncertainty was high. These real-world constraints motivated us to identify mechanisms for assuring the quality of Data Cards, and introduce low-barrier processes across the dataset lifecycle that can be easily adopted by organizations.
Initially, we assigned two reviewers to each new Data Card created. Reviewers represent job functions typical to agents. Selected reviewers were always unfamiliar with the dataset, but typically fluent in manipulating data or the domain of the dataset. Despite their expertise, feedback provided on these Data Cards were observational and speculative in nature (“The first two listed applications are commonly used and should be understood by both practitioners and laypeople, but I’m not sure about [application] ); and often not tactical for producers to incorporate. To make feedback actionable and holistic, we worked with a mix of subject matter experts, data reviewers, functional and tactical roles at our company to identify over 98 concepts used to assess datasets and their documentation. We removed 13 usability and 8 user-experience related concepts, which are reflected in our objectives. We then consolidated the remaining concepts into 20 clusters using affinity mapping. Clusters were then classified into five umbrella topics that represent contextual decision-making signals used by our experts to evaluate the rigor with which a Data Card describes a dataset, and it’s corresponding efficacy for the reader.
Dimensions
Dimensions are directional, pedagogic vectors that describe the Data Card’s usefulness to the agents. They represent the different types of judgments readers might make, and yield qualitative insights into the consistency, comprehensiveness, utility, and readability of Data Card templates and completed Data Cards alike. Here, we briefly summarize these dimensions:
-
- Accountability : Demonstrates adequate ownership, reflection, reasoning, and systematic decision making by dataset producers.
- Utility or Use: Provides details that satisfy the needs of the readers’ responsible decision-making process to establish the suitability of datasets for their tasks and goals.
- Quality: Summarizes the rigor, integrity and completeness of the dataset, communicated in a manner that is accessible and understandable to many readers.
- Impact or Consequences of Use: Sets expectations for positive and negative outcomes as well as subsequent consequences when using or managing the dataset in suitable contexts.
- Risk and Recommendations: Makes readers aware of known potential risks and limitations, stemming from provenance, representation, use, or context of use. Provides enough information and alternatives to help readers make responsible trade-offs.
To test these dimensions, reviewers with varying levels of domain and data fluency were asked to use these dimensions when evaluating Data Cards and any associated Model Cards. Reviewers were provided a rubric in which they were to independently rate the completed Data Card on each dimension, selecting from Poor , Borderline , Average , Good , and Outstanding . In addition, reviewers were asked to provide evidence in support of their ratings, and steps that producers could take to improve that specific rating. Reviewers found it easier to offer structured and actionable feedback using these dimensions (“Utility or Use: Average. Evidence: Data Card provides all necessary steps for users who may wish to access the dataset, but it’s hard for me to determine what use cases are suitable for this dataset. I know the dataset was collected for the purpose of evaluating the performance of the [specific model], but what does the [specific model] do? Next Steps: Provide additional examples of suitable use cases, provide additional detail on what the [specific model] does under intended use case.” ). While these dimensions are primarily used to asses if Data Cards help readers arrive at acceptable conclusions about datasets, feedback from expert reviewers revealed specific opportunities to enhance the datasets themselves.
Case Studies
A Computer Vision Dataset for Fairness Research
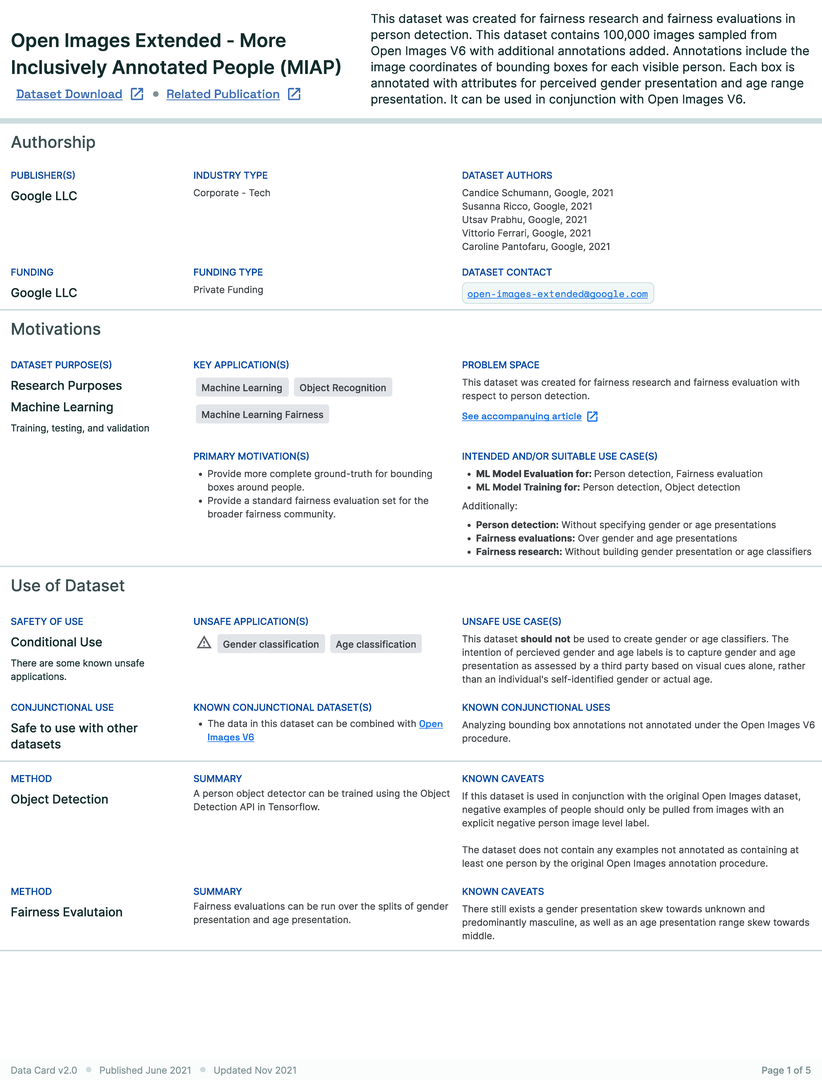
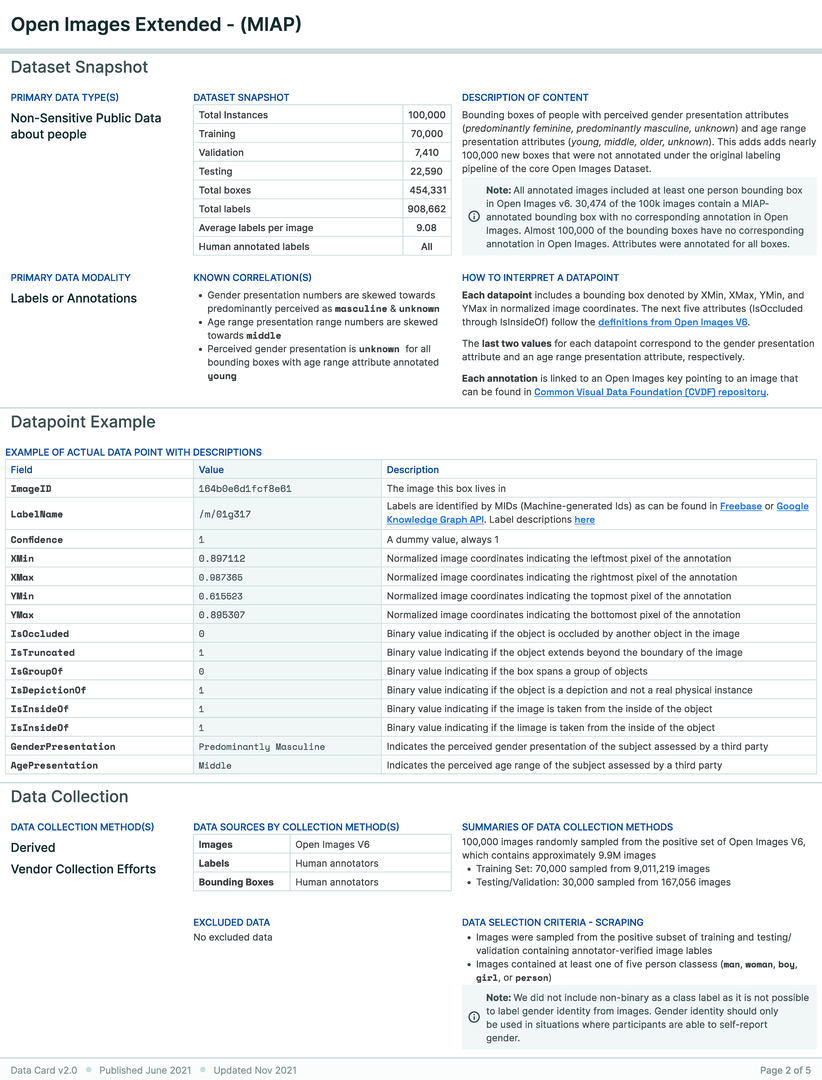
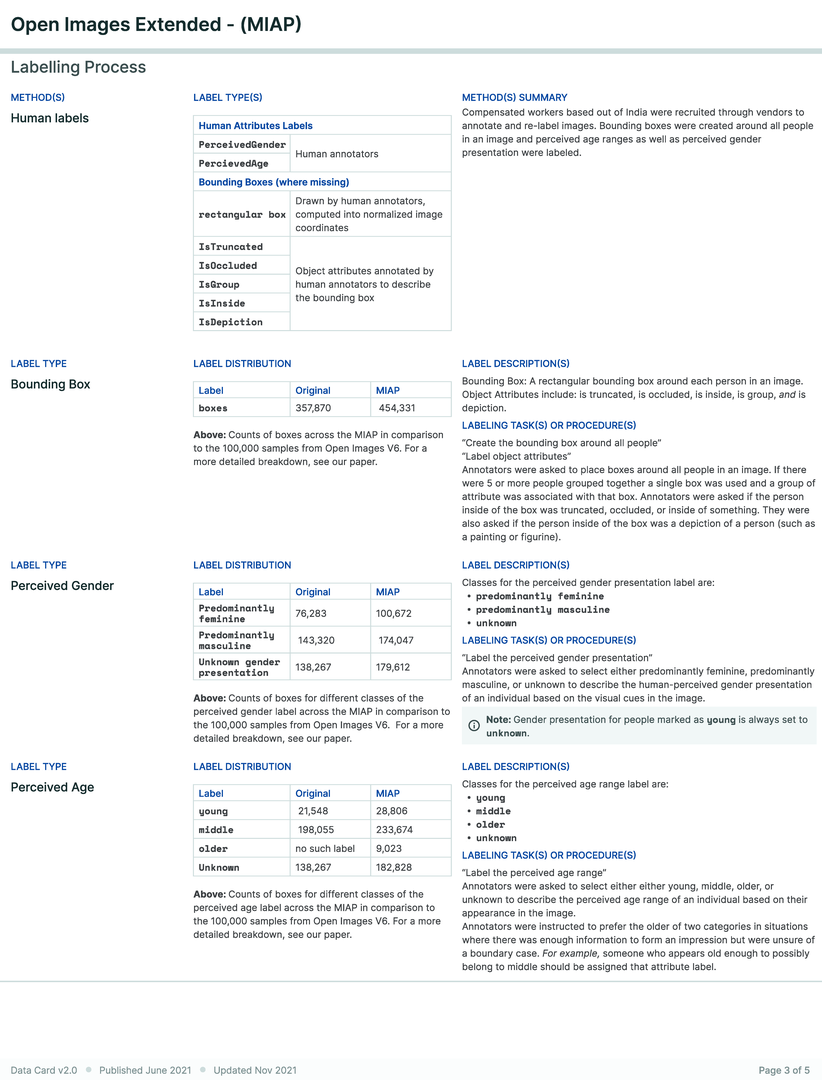
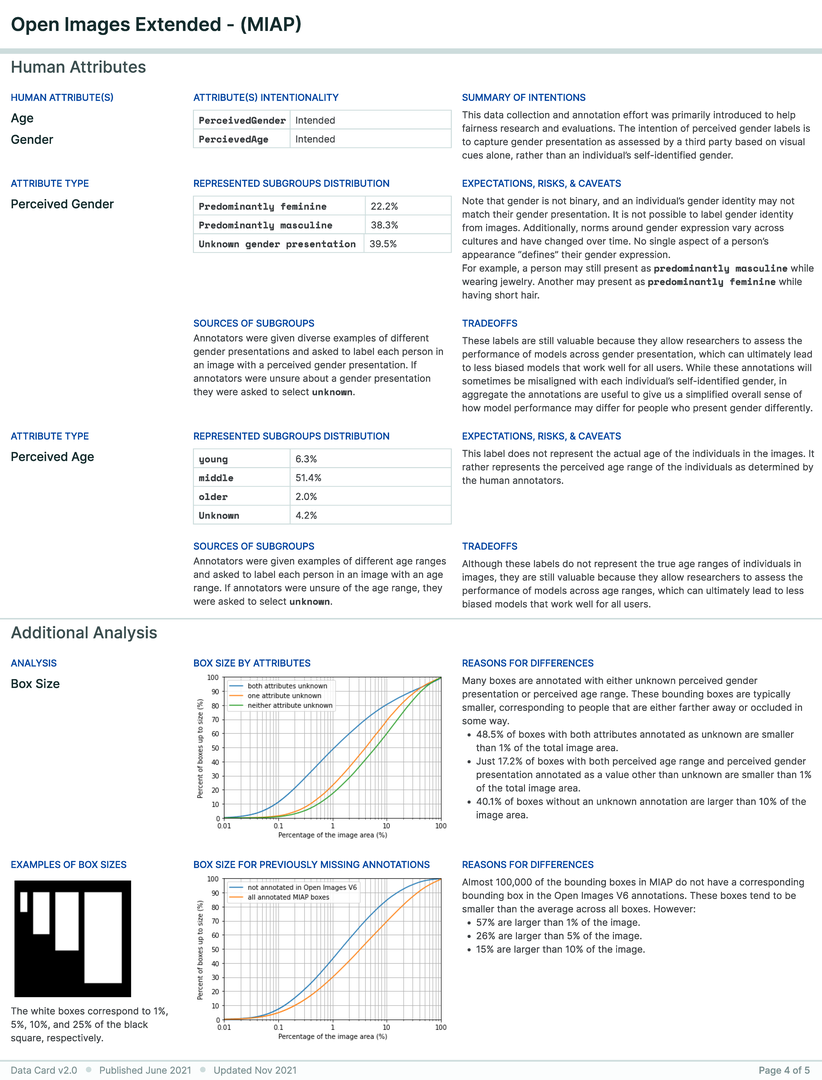
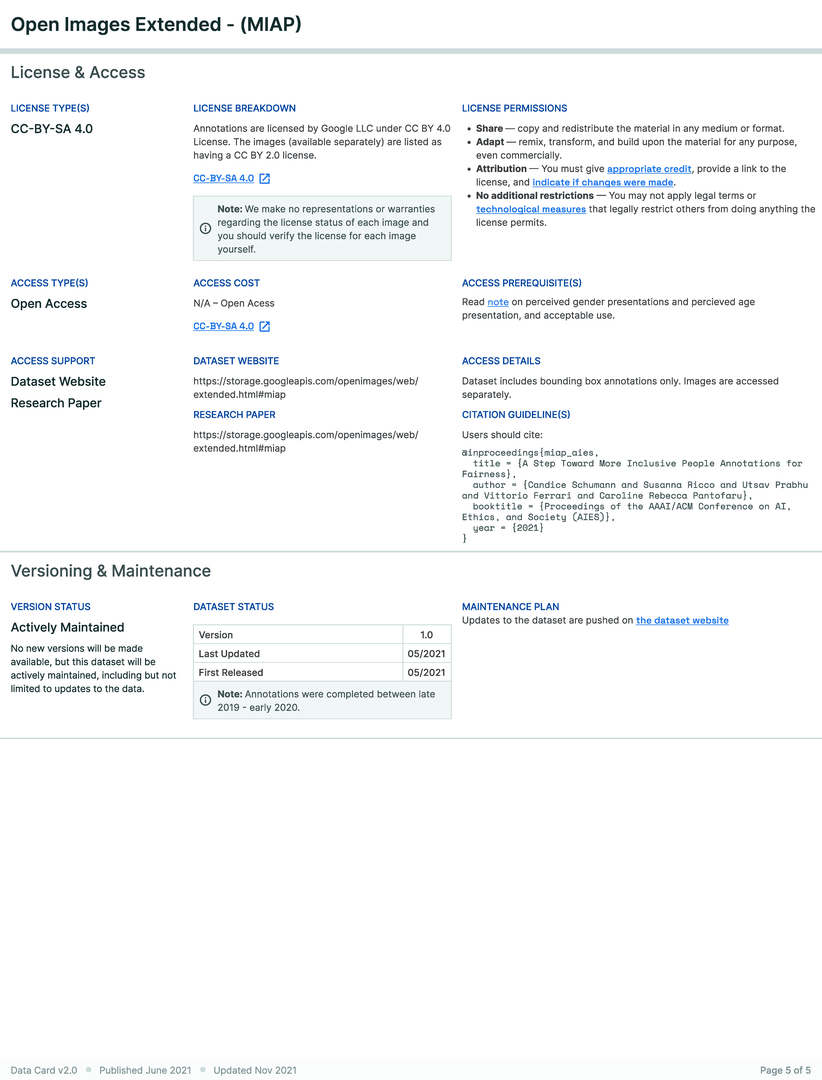
A research team created an ML training dataset for computer vision (CV) fairness techniques that described sensitive attributes about people, such as perceived gender and perceived age-range. Using Open Images, the dataset included 100,000 bounding boxes over 30,000 images. Each bounding box was manually annotated with perceived gender presentation and perceived age range presentation attributes. Given the risks associated with sensitive labels describing personal attributes weighed against the societal benefit of these labels for fairness analysis and bias mitigation, the team wanted an efficient way to provide an overview of the characteristics, limitations, and communicate acceptable uses of the dataset for internal ethics reviewers and external audiences.
Three parties were involved in the creation of this Data Card, which started after the dataset was completely prepared. First, the dataset authors who had deep tacit knowledge of the processes and decisions across the dataset’s lifecycle. They also had explicit knowledge from extensive analysis performed for the dataset release. However, this was distributed across several documents, and the Data Card was an exercise in organizing knowledge into a “readable format” that could be consistently repeated for multiple datasets. This process occurred asynchronously over a few days.
The next group involved were internal reviewers of the dataset and an accompanying paper, conducting an analysis of how the dataset aligns with responsible AI research and development practices. The analysis focused on subgroups in the labels, the trade-offs associated with each subgroup, and clarifying acceptable and unacceptable use cases of the dataset as a whole, in alignment with an established set of AI Principles. The reviewers recommended that the team create a Data Card. Creating the Data Card as a result of the review process revealed differences in perception across experts. For example, in the Data Card, producers noted that nearly 40% of perceived age-range labels were ‘unknown’. Reviewers were unable to ascertain if this was acceptable, and subsequent conversations raised further questions about the criteria used to label a bounding box with ‘unknown’ perceived age-range. It was found that ‘high’ levels of unknowns were relatively typical to datasets in this problem space, and was attributed to the size of 30% of the bounding boxes being less than 1% of the image. As a result, producers added a custom section about bounding boxes to the Data Card, and created additional supporting visualizations. Further, producers uncovered and iterated on additional Data Card fields for future CV datasets.
The last group involved in the creation of the Data Card were the authors of this paper, who provided human-centered design perspectives on the Data Card. Feedback was primarily geared towards uncovering agent information needs for acceptable conclusions about the accountability, risk & recommendations, uses, consequences, and quality of the dataset. A post-launch retrospective revealed that though the producers did not have access to dataset consumers, downstream agents reported finding the Data Card useful, and sought out templates for their own use.
A Geographically Diverse Dataset for Language Translation
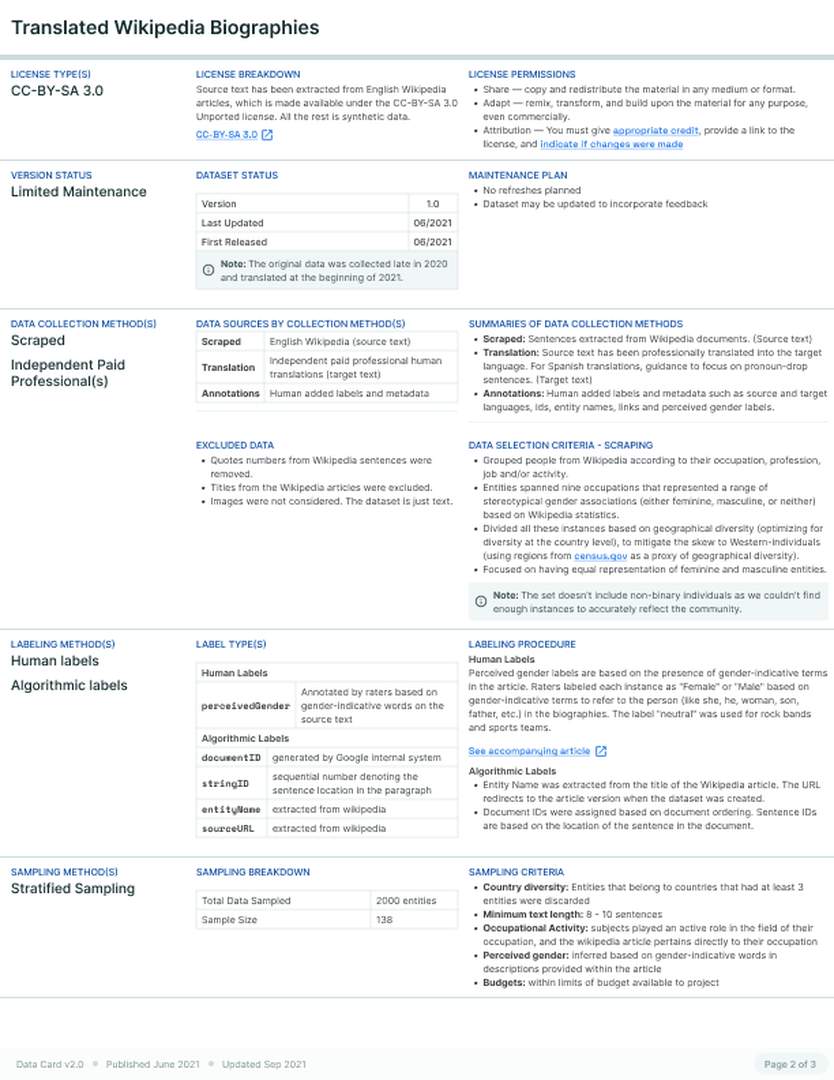
A team of software engineers and a product manager noticed that certain models were “picking up” names to define a person’s gender. Upon investigation, they found that previous training datasets did not have sufficient names that were uncommon in English or belonged to a non-American geography. They also found that model creators were making assumptions about these datasets. In response, the team decided to create a geographically diverse dataset from a limited set of publicly curated data from Wikipedia.
However, it became clear that a truly diverse dataset would need to consider race, age, gender, background and profession as well. While countries were acceptable proxies for geographic representation, gender would need to be inferred from the entity descriptions. Without an awareness of the goals of the dataset or the definitions of gender in the data design, the team was concerned that model creators could make assumptions leading to inappropriate dataset use. To communicate these two aspects, the team created a Data Card for readers with and without technical expertise.
Experts responsible for the design, data extraction, cleaning and curation of the dataset worked with a human-centered designer in an iterative process to produce the Data Cardafter the dataset was created. While the documentation process itself took approximately 20 hours, the Data Card prompted the team to reflect on how data was selected, reviewed and created. They specifically considered what they did and did not know about the dataset, their assumptions, the advantages and limitations of the dataset. In doing so, the team was forced to rethink design decisions which increased the overall timeline, but resulted in a more principled and intentional dataset of geographically diverse biographies.
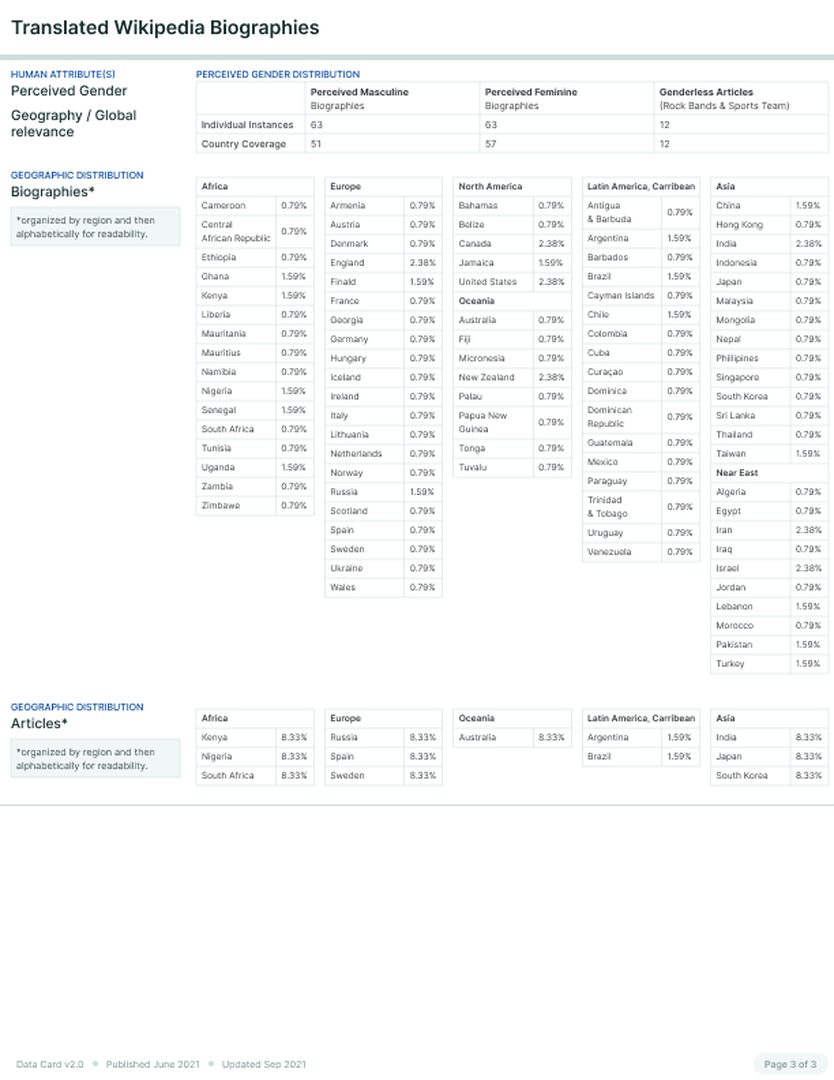
The team utilized the Data Card to engage in overall clearer discussions with stakeholders. In particular, experts stakeholders pointed out that gender is difficult to ascertain in the dataset. These conversations helped the team agree on a definition of perceived gender that relied on gender-indicative terms within the text of the data, using the labels “masculine”, “feminine”, and “neutral” for biographies describing collections of individuals. The team found that some discussions around the Data Card were actually about the dataset, and noted the usefulness of this feedback if received during the design stage. The final Data Card describes the data selection criteria, sampling criteria, sources of fields, and emphasizes the distribution of countries by continental regions. In addition, the team was able to clearly justify reasons for not including non-binary individuals, excluding collected data, and the limitations of this dataset.
Discussion
Experiences and outcomes from Case Studies
While both teams appreciated the transparency added to their respective datasets, creating Data Cards as a final step significantly increased the perception of work required. Rather than a post-implementation task, creating Data Cards as the dataset is created offers several benefits. First, it enables the inclusion of multiple perspectives (engineering, research, user experience, legal, and ethical) to enhance the readability and relevance of documentation, and the dataset quality over time. Then, it forces the aggregation of disparate documentation across the dataset lifecycle into a single, ground truth document accessible to stakeholders. Lastly, it facilitates early feedback on responsible AI practices from experts and non-experts that can affect data design and analyses. Of note, teams that developed multiple Data Cards over a period started developing a nuanced vocabulary to express uncertainty that accurately reflected the status of the information.
Data Cards as Boundary Objects
Data Cards are designed to embody a high degree of interpretive flexibility. A single Data Card can support tasks such as conducting reviews and audits, determining use in AI systems or research, comparison of multiple datasets, reproduction of research, or tracking of dataset adoption by various groups. For example, data practitioners seeking to evaluate the quality of a dataset for benchmarking or analysis; AI practitioners determining use case suitability of a dataset for deployment in new or existing models; product managers assessing the downstream effects to make data-related decisions about model or product optimizations for the desired user experience; policy stakeholders evaluating the representativeness of a dataset in relation to end users, and the role of various agencies involved in the creating the dataset creation. Importantly, while Data Cards are able to hold a common identity across these groups, they allow stakeholders to analytically make decisions using dimensions, constructs and vocabulary that are meaningful to their own communities of practice. Data Cards are able to facilitate collaborative work across stakeholders, while supporting individual decision making without consensus.
Our design of Data Cards enables the embedding of relevant sections into transparency artifacts that describe ML models and AI systems. Conversely, sections in the Data Card are designed to capture documentation surrounding the use of datasets in ML models. This establishes a network of artifacts that stakeholders can examine when conducting fairness and accountability interrogations, and achieve overall better results for meta-problems across the domain such as knowledge transfer, dataset reusability, organizational governance, and oversight mechanisms. Data Cards, therefore, effectively act as boundary objectsand where relevant, boundary infrastructures.
Path to Adoption
Following our initial Data Card release, public and private organizations have since sought to adopt similar constructs (,,). Within our organization, we observed an increase in non-mandated Data Cards created by individuals who organically came across completed Data Cards. While these speak to the utility of Data Cards as a documentation artifact, its quality and comprehensiveness depend on the rigor of the producers, the nuance in expressing uncertainty, and their knowledge of the dataset. Organizational factors include the presence of minimum or mandatory content requirements, process incentives, training materials, and infrastructure for creating and sharing Data Cards. While we propose a relatively comprehensive template for documenting datasets in Data Cards, industry-wide adoption could be spurred by agreed-upon interoperability and content standards that serve as a means for producers and agents to develop more equitable mental models of datasets.
Infrastructure and Automation
Critical to an organization’s success is its ability to tailor Data Cards to their datasets, models, and technological stack. Knowledge management infrastructures must be connected to data and model pipelines so new knowledge can be seamlessly incorporated into the Data Card, keeping it up to date. We find that Blocks allows for easy implementation on interactive platforms (digital forms, repositories, dataset catalogs) and adaptation for non-interactive surfaces (PDFs, documents, physical papers, markdown files). While both these case studies produced static PDFs, sections and fields can be easily implemented in a browser-based user interface, configured for views tailored to different stakeholders.
Centralized repositories that can perform search-and-filter operations over hundreds of Data Cards have long-tail benefits for agents in identifying the most suitable datasets for their tasks; measurably distributing the accountability of how datasets are used. We observed a marked preference for infrastructures that enables stakeholder collaboration and co-creation of Data Cards, linking and storage of extraneous artifacts, and the partial automation of visualizations, tables and analyses results. Interestingly, we observed that readers had strong opinions about not automating certain fields in the Data Card, especially when responses contain assumptions or rationales that help interpret results. Fields should be automated to guarantee accuracy and antifragility at all times, preventing the misrepresentation and the subsequent legitimizing of poor quality datasets. Implicit knowledge is articulated by providing contextual, human-written explanations of methods, assumptions, decisions and baselines.
Conclusion
We present Data Cards, a framework for transparent and purposeful documentation of datasets. We describe our underlying approach, objectives and the human-centered design of Data Cards. We introduce frameworks for structuring, adapting, and evaluating Data Cards. We then detail qualitative and anecdotal evidence for the efficacy of Data Cards towards creating responsible AI systems through two case studies. A limitation of our approach was the use of Google Docs for Data Card templates. This allowed stakeholders to collaborate and preserved a forensic history of the development of the Data Card, producers were limited to providing answers using text, tables and images. Iterating on individual fields caused template fragmentation and the loss of the original intent, as observed in our first case study. Additionally, this format prevented us from streamlining the collection experience or introducing automations, a much requested feature from producers. Future work requires a more principled approach for extending and adapting Data Card templates without compromising comparability. Insights from studies call for participatory approaches that engage diverse, non-traditional stakeholders early into the dataset and Data Card development process. We believe that adopting a co-creative approach that spans the entire dataset life cycle will result in a deliberate approach to automation in documentation. Lastly, defining quantitative measures to assess the true value of Data Cards will require adoption at both breadth and depth in the industry. Further investigation is needed into the perceived and actual importance of the content of Data Cards to tasks for different stakeholder groups. Together, Data Cards templates and frameworks encourage customized implementations that foster a culture for deep, detailed documentation. These help produce Data Cards that are consistent not only in and of themselves, but also co-create practical industry standards. Data Cards are capable of thoughtfully explaining the implications of datasets while highlighting unknowns appropriately. They reveals insights about inherent aspects of dataset that cannot be intrinsically determined by interacting with the dataset. Data Cards can be powerful vehicles that emphasize the ethical considerations of a dataset in ways that can be practically acted upon and support production and research decisions, supporting transparent and well-informed development of large AI models capable of supporting multiple, user-facing tasks.
Typology of Stakeholders
OFTEn Framework as a generative tool
In this figure, we demonstrate how it can be used to generate questions about data consent across a dataset’s life cycle. During the creation of our template (dc-template), OFTEn was used to anticipate standardization requirements and enable the forensic investigation of dataset documentation over time.
Table Label: often-matrix
Download PDF to view tableData Card for Computer Vision Dataset
Data Card for Language Translation Dataset

Data Card Template
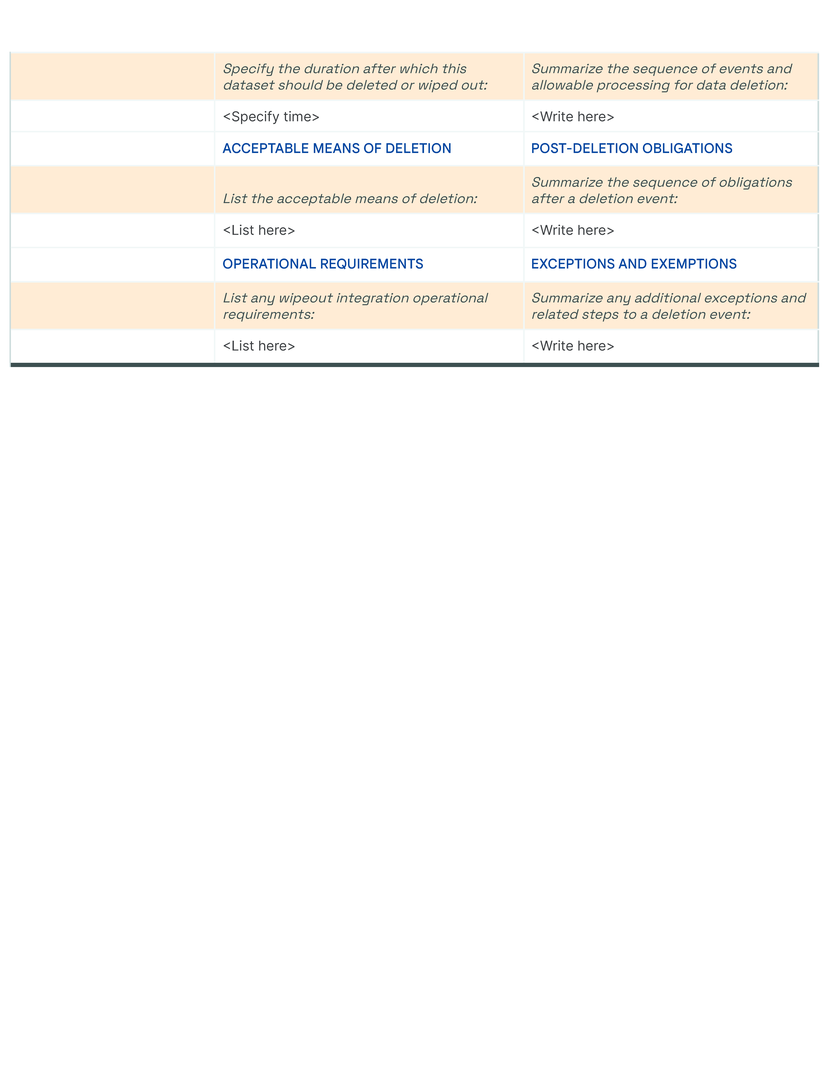
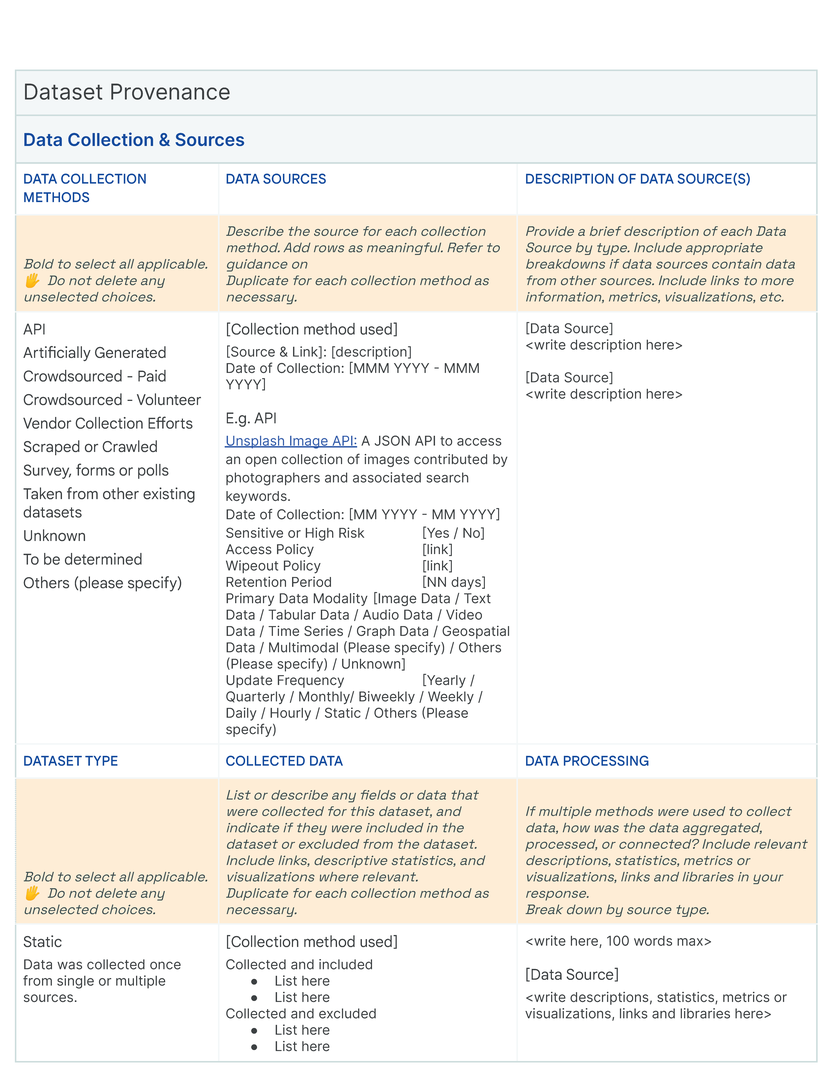
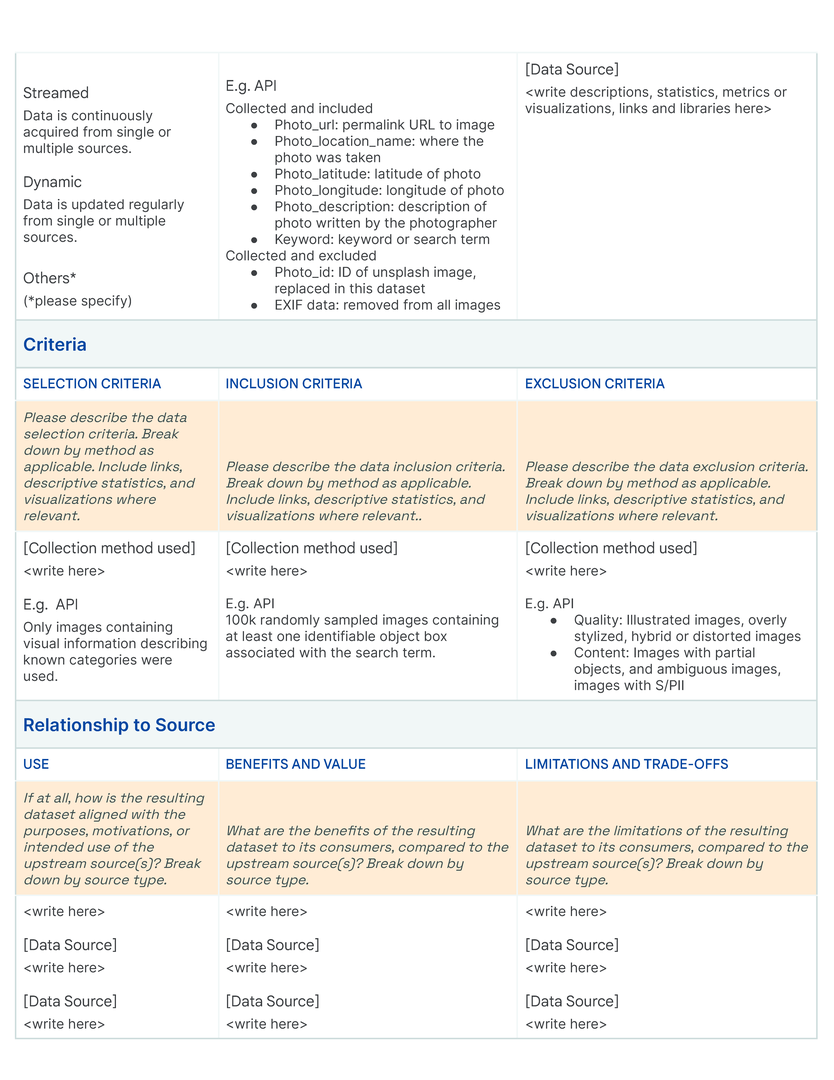
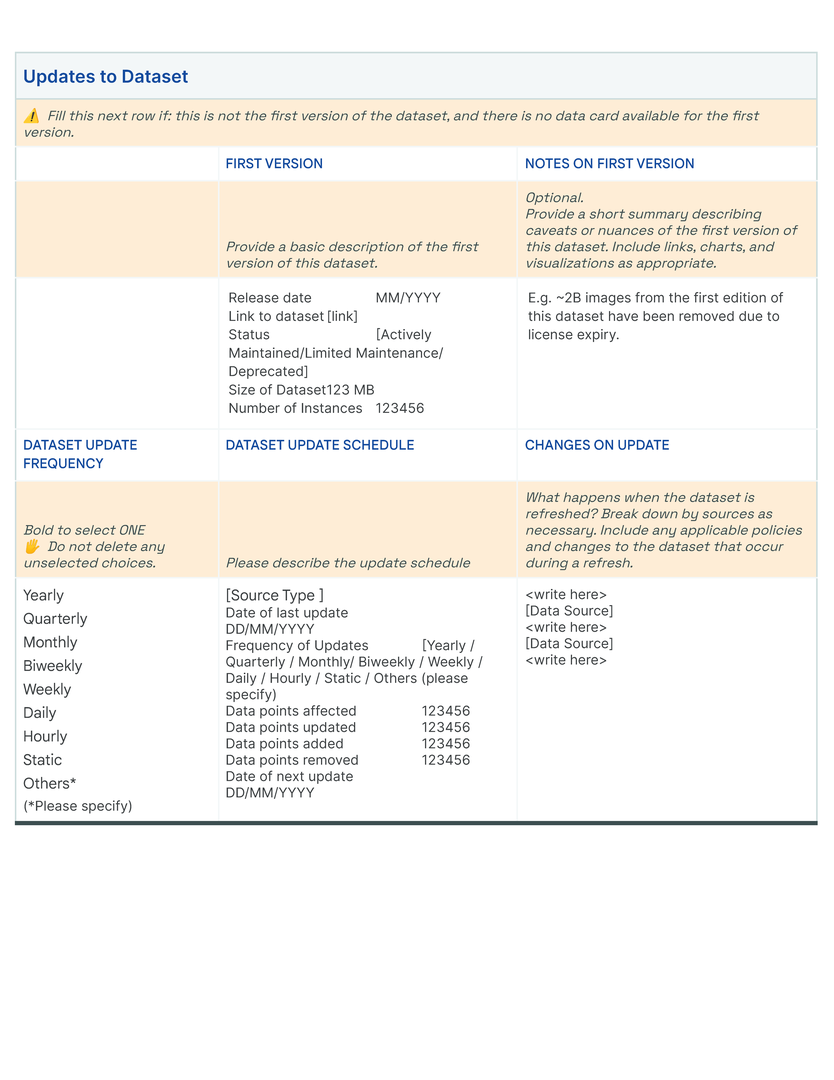

Bibliography
1@article{gebru2018datasheets,
2 year = {2018},
3 journal = {arXiv preprint arXiv:1803.09010},
4 author = {Gebru, Timnit and Morgenstern, Jamie and Vecchione, Briana and Vaughan, Jennifer Wortman and Wallach, Hanna and Daum{\'e} III, Hal and Crawford, Kate},
5 title = {Datasheets for datasets},
6}
7
8@inproceedings{mitchell2019model,
9 year = {2019},
10 pages = {220--229},
11 booktitle = {Proceedings of the conference on fairness, accountability, and transparency},
12 author = {Mitchell, Margaret and Wu, Simone and Zaldivar, Andrew and Barnes, Parker and Vasserman, Lucy and Hutchinson, Ben and Spitzer, Elena and Raji, Inioluwa Deborah and Gebru, Timnit},
13 title = {Model cards for model reporting},
14}
15
16@article{mcmillan2021reusable,
17 year = {2021},
18 journal = {arXiv preprint arXiv:2108.07374},
19 author = {McMillan-Major, Angelina and Osei, Salomey and Rodriguez, Juan Diego and Ammanamanchi, Pawan Sasanka and Gehrmann, Sebastian and Jernite, Yacine},
20 title = {Reusable Templates and Guides For Documenting Datasets and Models for Natural Language Processing and Generation: A Case Study of the HuggingFace and GEM Data and Model Cards},
21}
22
23@inproceedings{hutchinson2021towards,
24 year = {2021},
25 pages = {560--575},
26 booktitle = {Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency},
27 author = {Hutchinson, Ben and Smart, Andrew and Hanna, Alex and Denton, Emily and Greer, Christina and Kjartansson, Oddur and Barnes, Parker and Mitchell, Margaret},
28 title = {Towards accountability for machine learning datasets: Practices from software engineering and infrastructure},
29}
30
31@misc{holland2018dataset,
32 primaryclass = {cs.DB},
33 archiveprefix = {arXiv},
34 eprint = {1805.03677},
35 year = {2018},
36 author = {Sarah Holland and Ahmed Hosny and Sarah Newman and Joshua Joseph and Kasia Chmielinski},
37 title = {The Dataset Nutrition Label: A Framework To Drive Higher Data Quality Standards},
38}
39
40@article{reisman2018algorithmic,
41 year = {2018},
42 pages = {1--22},
43 journal = {AI Now Institute},
44 author = {Reisman, Dillon and Schultz, Jason and Crawford, Kate and Whittaker, Meredith},
45 title = {Algorithmic impact assessments: A practical framework for public agency accountability},
46}
47
48@article{bellamy2018ai,
49 year = {2018},
50 journal = {arXiv preprint arXiv:1810.01943},
51 author = {Bellamy, Rachel KE and Dey, Kuntal and Hind, Michael and Hoffman, Samuel C and Houde, Stephanie and Kannan, Kalapriya and Lohia, Pranay and Martino, Jacquelyn and Mehta, Sameep and Mojsilovic, Aleksandra and others},
52 title = {AI Fairness 360: An extensible toolkit for detecting, understanding, and mitigating unwanted algorithmic bias},
53}
54
55@article{saleiro2018aequitas,
56 year = {2018},
57 journal = {arXiv preprint arXiv:1811.05577},
58 author = {Saleiro, Pedro and Kuester, Benedict and Hinkson, Loren and London, Jesse and Stevens, Abby and Anisfeld, Ari and Rodolfa, Kit T and Ghani, Rayid},
59 title = {Aequitas: A bias and fairness audit toolkit},
60}
61
62@article{kuznetsova2020open,
63 publisher = {Springer},
64 year = {2020},
65 pages = {1956--1981},
66 number = {7},
67 volume = {128},
68 journal = {International Journal of Computer Vision},
69 author = {Kuznetsova, Alina and Rom, Hassan and Alldrin, Neil and Uijlings, Jasper and Krasin, Ivan and Pont-Tuset, Jordi and Kamali, Shahab and Popov, Stefan and Malloci, Matteo and Kolesnikov, Alexander and others},
70 title = {The open images dataset v4},
71}
72
73@incollection{star1989structure,
74 publisher = {Elsevier},
75 year = {1989},
76 pages = {37--54},
77 booktitle = {Distributed artificial intelligence},
78 author = {Star, Susan Leigh},
79 title = {The structure of ill-structured solutions: Boundary objects and heterogeneous distributed problem solving},
80}
81
82@incollection{shneiderman2003eyes,
83 publisher = {Elsevier},
84 year = {2003},
85 pages = {364--371},
86 booktitle = {The craft of information visualization},
87 author = {Shneiderman, Ben},
88 title = {The eyes have it: A task by data type taxonomy for information visualizations},
89}
90
91@article{star1989institutional,
92 publisher = {Sage Publications London},
93 year = {1989},
94 pages = {387--420},
95 number = {3},
96 volume = {19},
97 journal = {Social studies of science},
98 author = {Star, Susan Leigh and Griesemer, James R},
99 title = {Institutional ecology,translations' and boundary objects: Amateurs and professionals in Berkeley's Museum of Vertebrate Zoology, 1907-39},
100}
101
102@article{bender2018data,
103 publisher = {MIT Press},
104 year = {2018},
105 pages = {587--604},
106 volume = {6},
107 journal = {Transactions of the Association for Computational Linguistics},
108 author = {Bender, Emily M and Friedman, Batya},
109 title = {Data statements for natural language processing: Toward mitigating system bias and enabling better science},
110}
111
112@inproceedings{ehsan2021expanding,
113 year = {2021},
114 pages = {1--19},
115 booktitle = {Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems},
116 author = {Ehsan, Upol and Liao, Q Vera and Muller, Michael and Riedl, Mark O and Weisz, Justin D},
117 title = {Expanding explainability: Towards social transparency in ai systems},
118}
119
120@inproceedings{holstein2019improving,
121 year = {2019},
122 pages = {1--16},
123 booktitle = {Proceedings of the 2019 CHI conference on human factors in computing systems},
124 author = {Holstein, Kenneth and Wortman Vaughan, Jennifer and Daum{\'e} III, Hal and Dudik, Miro and Wallach, Hanna},
125 title = {Improving fairness in machine learning systems: What do industry practitioners need?},
126}
127
128@article{hong2020human,
129 publisher = {ACM New York, NY, USA},
130 year = {2020},
131 pages = {1--26},
132 number = {CSCW1},
133 volume = {4},
134 journal = {Proceedings of the ACM on Human-Computer Interaction},
135 author = {Hong, Sungsoo Ray and Hullman, Jessica and Bertini, Enrico},
136 title = {Human factors in model interpretability: Industry practices, challenges, and needs},
137}
138
139@inproceedings{suresh2021beyond,
140 year = {2021},
141 pages = {1--16},
142 booktitle = {Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems},
143 author = {Suresh, Harini and Gomez, Steven R and Nam, Kevin K and Satyanarayan, Arvind},
144 title = {Beyond Expertise and Roles: A Framework to Characterize the Stakeholders of Interpretable Machine Learning and their Needs},
145}
146
147@inproceedings{chander2018working,
148 year = {2018},
149 booktitle = {IUI Workshops},
150 author = {Chander, Ajay and Srinivasan, Ramya and Chelian, Suhas and Wang, Jun and Uchino, Kanji},
151 title = {Working with beliefs: AI transparency in the enterprise},
152}
153
154@article{felzmann2020towards,
155 publisher = {Springer},
156 year = {2020},
157 pages = {3333--3361},
158 number = {6},
159 volume = {26},
160 journal = {Science and Engineering Ethics},
161 author = {Felzmann, Heike and Fosch-Villaronga, Eduard and Lutz, Christoph and Tam{\`o}-Larrieux, Aurelia},
162 title = {Towards transparency by design for artificial intelligence},
163}
164
165@inproceedings{antunes2018fairness,
166 organization = {IEEE},
167 year = {2018},
168 pages = {188--193},
169 booktitle = {2018 48th Annual IEEE/IFIP International Conference on Dependable Systems and Networks Workshops (DSN-W)},
170 author = {Antunes, Nuno and Balby, Leandro and Figueiredo, Flavio and Lourenco, Nuno and Meira, Wagner and Santos, Walter},
171 title = {Fairness and transparency of machine learning for trustworthy cloud services},
172}
173
174@article{barclay2020framework,
175 publisher = {Wiley Online Library},
176 year = {2020},
177 pages = {e6129},
178 journal = {Concurrency and Computation: Practice and Experience},
179 author = {Barclay, Iain and Taylor, Harrison and Preece, Alun and Taylor, Ian and Verma, Dinesh and de Mel, Geeth},
180 title = {A framework for fostering transparency in shared artificial intelligence models by increasing visibility of contributions},
181}
182
183@book{mccue2014data,
184 publisher = {Butterworth-Heinemann},
185 year = {2014},
186 author = {McCue, Colleen},
187 title = {Data mining and predictive analysis: Intelligence gathering and crime analysis},
188}
189
190@inproceedings{bhatt2021uncertainty,
191 year = {2021},
192 pages = {401--413},
193 booktitle = {Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society},
194 author = {Bhatt, Umang and Antor{\'a}n, Javier and Zhang, Yunfeng and Liao, Q Vera and Sattigeri, Prasanna and Fogliato, Riccardo and Melan{\c{c}}on, Gabrielle and Krishnan, Ranganath and Stanley, Jason and Tickoo, Omesh and others},
195 title = {Uncertainty as a form of transparency: Measuring, communicating, and using uncertainty},
196}
197
198@misc{chumann_ricco_prabhu_ferrari_pantofaru_2021,
199 year = {2021},
200 author = {chumann, Candice and Ricco, Susanna and Prabhu, Utsav and Ferrari, Vittorio and Pantofaru, Caroline},
201 publisher = {Google},
202 journal = {Open Images Extended - More Inclusive Annotated People Data Card},
203 url = {https://storage.googleapis.com/openimages/open_images_extended_miap/Open\%20Images\%20Extended\%20-\%20MIAP\%20-\%20Data\%20Card.pdf},
204}
205
206@misc{austermann_linch_stella_webster_2021,
207 year = {2021},
208 author = {Austermann, Anja and Linch, Michelle and Stella, Romina and Webster, Kellie},
209 publisher = {Google LLC},
210 journal = {Translated Wikipedia Biographies Data Card},
211 url = {https://storage.googleapis.com/gresearch/translate-gender-challenge-sets/Data\%20Card.pdf},
212}
213
214@misc{craftplaybook,
215 urldate = {2021-30-09},
216 date = {2021-03-15},
217 organization = {Google},
218 url = {https://facctconference.org/2021/acceptedcraftsessions.html#data_cards},
219 title = {Data Cards Playbook: Participatory Activities for Dataset Documentation},
220 author = {Pushkarna, Mahima and Zaldivar, Andrew and Nanas, Daniel},
221}
222
223@article{leigh2010not,
224 publisher = {Sage Publications Sage CA: Los Angeles, CA},
225 year = {2010},
226 pages = {601--617},
227 number = {5},
228 volume = {35},
229 journal = {Science, Technology, \& Human Values},
230 author = {Leigh Star, Susan},
231 title = {This is not a boundary object: Reflections on the origin of a concept},
232}
233
234@misc{gembenchmark,
235 urldate = {2022-01-10},
236 date = {2022-01-10},
237 url = {https://gem-benchmark.com/data_cards},
238 year = {2022},
239 title = {Natural Language Generation, its Evaluation and Metrics Data Cards},
240 author = {GEM},
241}
242
243@misc{huggingfacecards,
244 urldate = {2022-01-10},
245 date = {2022-01-10},
246 url = {https://huggingface.co/docs/datasets/v1.12.0/dataset_card.html},
247 year = {2021},
248 title = {HuggingFace - Create a Dataset Card},
249 author = {HuggingFace},
250}
251
252@misc{jaic,
253 urldate = {2022-01-10},
254 date = {2022-01-10},
255 year = {2021},
256 url = {https://www.ai.mil/blog_09_03_21_ai_enabling_ai_with_data_cards.html},
257 title = {Enabling AI with Data Cards},
258 author = {Joint Artificial Intelligence Center Public Affairs},
259}
260
261@misc{oix,
262 urldate = {2022-01-10},
263 year = {2020},
264 date = {2022-01-10},
265 url = {https://research.google/static/documents/datasets/open-images-extended-crowdsourced.pdf},
266 title = {Open Images Extended - Crowdsourced Data Card},
267 author = {Anurag Batra, Parker Barnes},
268}
269
270@misc{kyd,
271 urldate = {2022-01-10},
272 date = {2022-01-10},
273 url = {https://knowyourdata.withgoogle.com/},
274 year = {2022},
275 title = {Know Your Data},
276 author = {People + AI Research Initiative},
277}Attribution
arXiv:2204.01075v1
[cs.HC]
License: cc-by-4.0


