
- Papers
Papers is Alpha. This content is part of an effort to make research more accessible, and (most likely) has lost some details from the original. You can find the original paper here.
Introduction
Interest in incorporating machine learning into scientific analyses has exploded in the last two decades. Machine learning (ML)—the process of teaching a machine to predict statistical patterns in data—has gained prominence in biology, physics, health care, and the social sciencesinter alia, yielding many successful “ML+X” collaborations. While this potential for ML+X is enormous, many researchers unfamiliar with ML methods face barriers to entry, partly because implementing complex methods can be challenging for those without strong mathematical or programming backgrounds.
As a starting point for ML newcomers, some ML+X educational material covers simpler methods such as regression. For example, the Summer Institutes for Computational Social Science (SICSS) have developed learning materials that focus on basic ML methods for network analysis and text processing. Computational social science researchers often leverage these kinds of methods to analyze web-scale data, which can shed light on complicated social processes such as political polarization.
Basic ML methods provide a useful starting place but often lack the analytical power required to handle more complex questions that other fields require. Social scientists often want to use ML to develop deep semantic representations of language or to estimate causal effects that can lead to better predictive performance. Scientists who seek to advance their understanding of ML beyond the basics are often left searching for tutorial-like materials on their own, a difficult and often time-consuming task. On the other hand, well-meaning ML experts may try to share their expertise through media such as blog posts, but they run the risk of “parachuting” into unfamiliar fields with ill-adapted solutions. Finally, many formal avenues for sharing knowledge about ML—such as academic conferences—can systematically exclude researchers outside of ML via high fees to access materials.[Among other issues, social science research generally receives less funding compared to computer science. For instance, in 2021, the NSF dispersed $283 million in funding for social, behavioral and economic sciences, versus $ 1 billion for computer and information sciences and engineering (from https://www.nsf.gov/about/congress/118/highlights/cu21.jsp , accessed 10 August 2022). This lack of funding can often prevent social science researchers from attending ML conferences where many tutorials are presented.]
We take the position that ML researchers can make their methods more accessible and inclusive to researchers outside the field by creating online instruction explicitly tailored to the fields of subject matter experts. Using the NLP+CSS tutorial series we organized in 2021-2022 as a case study, we argue that these interdisciplinary training sessions should incorporate the following Principles for Democratizing ML+X Tutorials :
-
Teach machine learning (ML) methods that are relevant and targeted to specific non-ML fields—e.g. biology, health, or the social sciences
-
Teach ML methods that are recent and cutting-edge
-
Lower start-up costs of programming languages and tooling
-
Provide open-source code that is clearly written, in context, and easily adapted to new problems
-
Reduce both monetary and time costs for participants
ML+Social Sciences Starting in summer 2021, we put our principles into action and created the NLP+CSS 201 Online Tutorial Series . We focused on an applied branch of machine learning to language data—a field called natural language processing (NLP)—aimed at early career researchers in the social sciences. This report reflects on our experience and provides clear takeaways so that others can generalize our NLP + social sciences tutorials to tutorials targeted at other ML+X disciplines.
As we describe in Section sec-methods, we incorporated the principles above into our tutorial series by: (item-relevant&item-recent) inviting experts in computational social science (CSS) to each lead a tutorial on a cutting edge NLP method; (item-tooling&item-code) working with the experts to create a learning experience that is hosted in a self-contained interactive development environment in Python—Google CoLaboratory—and uses real-world social science datasets to provide context for the method; and (item-free) hosting our tutorials live via Zoom and posting the recordings on YouTube, while providing all the materials and participation without any monetary costs to participants.
The impact of the inaugural year of our series is tangible. We created twelve stand-alone tutorials made by fifteen area-expert tutorial hosts, have 396 members on an e-mail mailing list, and accumulated total views on tutorial recordings posted to YouTube.[As of October 2022, videos available here: https://www.youtube.com/channel/UCcFcF9DkanjaK3HEk7bsd-A ] Comparing surveys pre- and post-tutorial, participants during the live sessions self-assessed as improving their knowledge of the topic by 0.77 on a 7-point Likert scale (Section sec-analysis-effectiveness). After exploring highlights of the series, we discuss areas for improvement in Section sec-conclusion, including a suggestion to frame the tutorials a “springboard” for researcher’s own exploration of advanced ML methods.
Related work
Interdisciplinary tutorials
Researchers specializing in NLP methods have proposed a variety of interdisciplinary tutorials to address social science questions, which we surveyed before we began planning our tutorial series. However, none satisfied all the principles we listed in Section sec-intro. The tutorials presented at the conferences for the Association for Computational Linguistics (ACL)[https://www.aclweb.org/portal/acl_sponsored_events ]—one of the premiere venues for NLP research—are on the cutting edge of research ($+$ item-recent) and often include code ($+$ item-code), but the ACL tutorials are also often are geared towards NLP researchers rather than researchers in fields outside of computer science ($-$ item-relevant), contain code that assumes substantial background knowledge ($-$ item-tooling) and cost hundreds of dollars to attend ($-$ item-free). Other interdisciplinary conferences such as the International Conference on Computational Social Science (IC2S2)[https://iscss.org/ic2s2/conference/ ] also have tutorials that explain recent NLP methods to computational social scientists ($+$ item-relevant,item-recent,item-code), but often the tutorials are presented with inconsistent formats ($-$ item-tooling) and cost money to attend ($-$ item-free). The Summer Institutes in Computational Social Science (SICSS)provide free ($+$ item-free) tutorials on NLP methods for social scientists ($+$ item-relevant) with accompanying code ($+$ item-tooling&item-code), but they cover only the basic NLP techniques and not cutting edge methods ($-$ item-recent), while also limiting their target audience to people already involved with CSS research.[NLP methods include word counting and basic topic modeling: https://sicss.io/curriculum (accessed 11 August 2022).]
Online learning
While not without flaws, online learning experiences such as Massive Online Open Courses (MOOCs) have proven useful in higher education when meeting physically is impossible or impractical to due to students’ geographic distance. Online courses have disrupted traditional education such as in-person college classes, but they may eventually prove most useful as a supplement rather than a replacement to traditional education. For one, computer science students have found online learning useful when it incorporates interactive components such as hands-on exercises which may not be possible to execute during a lecture. Additionally, while the centralized approach to traditional education can provide useful structure for students new to a domain, the decentralized approach of many online courses can provide room for socialization and creativity in content delivery. We intended our tutorial series to fit into the developing paradigm of online education as a decentralized and interactive experience, which would not replace but supplement social science education in machine learning. However, our tutorial series differs from MOOCs in that we limit the time committment for each topic to one hour (+item-free) and each tutorial hour is meant to be stand-alone so that researchers can watch only the topics that are relevant to them.
Methods for Tutorial Series: Process and Timeline
Tutorial content. Order, title, and number of views of the corresponding recordings on YouTube as of October, 2022. Full abstracts of each tutorial are provided in the appendix, Table tab-tutorial-abstracts.
Table Label: t-tutorial-content
Download PDF to view tableWe describe our process and timeline for creating the tutorial series with the hope that future ML+X tutorial series organizers can copy or build from our experience. Throughout our planning process, we based our decisions on the five principles mentioned earlier (item-relevant-item-free). Our tutorial series spanned two semesters: Fall 2021 (August through December) and Spring 2022 (February through May). The tutorial content is summarized in .
Interest survey
To identify relevant methods (item-relevant), for one month before each semester we distributed a survey via our personal Twitter accounts, via a Google group mailing list that we created at the beginning of the fall 2021 semester, and via topically related mailing lists (e.g. a political methods list-serv). We asked participants to list the methods that they would be most interested in learning about during a tutorial, which we then grouped into categories based on underlying similarities.
The distribution of interest categories is shown in . As expected, the responses covered many different NLP applications, including data preparation (preprocessing, multilingual), conversion of text to relevant constructs (information extraction, word embeddings, deep learning), and downstream analysis (causal inference, application). Most participants expressed interest in word embeddings, unsupervised learning, and downstream applications of NLP methods, which aligns with the current popularity of such methods.

Lessons learned Since we typically publish in NLP venues, we took a prescriptive approach to choosing the tutorial methods to present, in an attempt to more actively shape the field of computational social science (addressing item-relevant& item-recent). We used the results of the survey to brainstorm potential topics for each upcoming semester, but did not restrict ourselves to only the most popular methods. While useful, the interest surveys revealed a disconnect between our ideal tutorials, which focused on advanced NLP methods, and the participants’ ideal tutorials, e.g. entry-level methods with immediate downstream results. For example, many participants in the Spring 2022 interest survey mentioned sentiment analysis, a well-studied area of NLPthat we considered to be more introductory-level and sometimes unreliable. This was one source of tension between our expectations and those of the participants, and future tutorial series organizers may want to focus their efforts on highly-requested topics to ensure consistent participation and satisfaction (item-relevant).
Leader recruitment
Aligning with item-recent, we recruited other NLP experts who worked on cutting-edge methods to lead each individual tutorial.[We recruited tutorial leaders through our own social networks and through mutual acquaintances. We targeted post-doctoral fellows, early-career professors, and advanced graduate students.] To ensure item-tooling, we also met with the tutorial hosts to agree on a common format for the programming platform—Google CoLaboratory with Python[https://colab.research.google.com/ ]—and to help them understand the tutorials’ objectives. The process involved several meetings: an introduction meeting to scope the tutorial, and at least one planning meeting to review the slides and code to be presented. Normally, this process was guided by a paper or project for which the tutorial leader had code available. For example, the leader of tutorial T4 was able to leverage an extensive code base already tested by her lab.
Lessons learned During the planning process, we were forced to plan the tutorials one at a time due to complicated schedules among the leaders. We spread out the planning meetings during the semester so that the planning meetings would begin roughly two to three weeks before the associated tutorial. We strongly encouraged leaders to provide their code to us at least one week in advance to give us time to review it, but we found this difficult to enforce due to time constraints on the leaders’ side (e.g. some leaders had to prioritize other teaching commitments). Future organizers should set up a consistent schedule for contacting leaders in advance and agree with leaders on tutorial code that is relatively new and usable (item-recent& item-code) without presenting an undue burden for the leader, e.g. re-using existing code bases.
Participant recruitment
Even if we guaranteed item-relevant-item-free with the content developed, recruiting social science participants was essential to the success of our tutorial series. In September 2021, we set up an official mailing list through Google Groups and advertised it on social media and other methods-related list-servs.[The Google Group was only accessible to participants with Google Mail accounts, which in retrospect likely discouraged some participants who only use institutional email accounts.] The mailing list eventually hosted 396 unique participants. For all tutorials, we set up a RSVP system using Google Forms for participants to sign up, and we provided an RSVP link up to one week before each tutorial. We chose this “walled garden” approach to discourage anti-social activity such as Zoom-bombing which is often made easier by open invitation links, and to provide tutorial leaders with a better sense of their participants.


Lesson learned This process revealed significant drop-out: between 10-30% of people who signed up actually attended the tutorial. While the reasons for the drop-out remained unclear, we reasoned that people signed up for the tutorial as a back-up and were willing to miss the live session if another obligation arose, under the assumption that the recording would be available later. Although we believe in the benefits of asynchronous learning, the low number of live participants was somewhat discouraging to the live tutorial hosts.
Running the tutorials
During the tutorials, we wanted to ensure low start-up cost of the programming environment (item-tooling) and well-written code that participants could use immediately after the tutorials (item-code). We designed each tutorial to run for slightly under 60 minutes, to account for time required for introductions, transitions, and follow-up questions. The tutorial leader began the session with a presentation to explain the method of interest with minimal math, using worked examples on toy data and examples of prior research that leveraged the method.
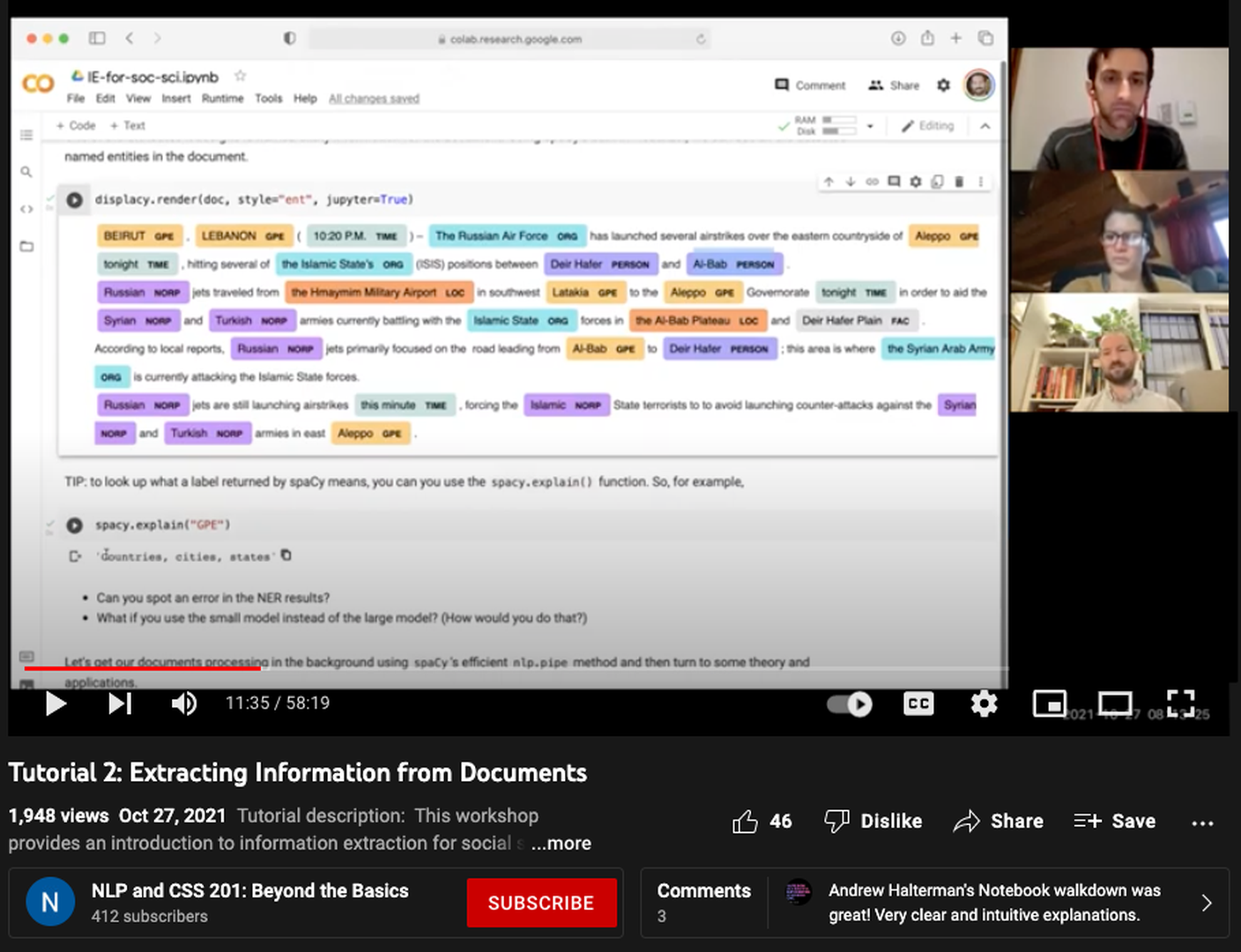
After 20-30 minutes of presentation, the tutorial leader switched to showing the code written in a Google CoLaboratory Python notebook (item-tooling), which is an internet-based coding environment that allows users to run modular blocks of Python code. The leader would load or generate a simple text dataset, often no more than several hundred documents in size, to illustrate the method’s application. Depending on the complexity of the method, the leader might start with some basic steps and then show the students increasingly complicated code snippets. In general, the leaders walked the students through separate modules that showed different aspects of the method in question. During the topic modeling session (T4), the leader showed first how to train the topic model, then provided extensive examples of what the topic output looked like and how it should be interpreted (e.g. top words per topic, example documents with high topic probabilities).[Topic models are used to identify latent groupings for words in a document, e.g. a health-related topic might include “exercise” and “nutrition.” As a point of comparison, the leader also would often show the output of a simpler “baseline” model to demonstrate the superior performance of the tutorial’s more advanced method. We show excerpts from the tutorial notebook on topic modeling in , which includes an overview of the topic model, a sample of the text data which relates to politics, and the resulting learned “topics” as lists of words.
Lessons learned
To encourage critical thinking, some of the tutorial leaders provided questions or exercises in the Colab notebooks for students to complete at a later time. The leader of the information extraction tutorial (T2) created an exercise for students to parse sentences from news text related to military activity, and then to extract all sentences that described an attack between armies. Some of these exercises posed challenges to participants who lacked experience with the data structures or function calls involved in the code. For future tutorials, leaders should consider simply showing participants how to solve a simple exercise (e.g. live-coding) rather than expecting participants to attack the problem on their own.
Example questions from tutorial sessions. Some wording changed for clarity.
Table Label: tab-tutorial-example-questions
Download PDF to view table
Participation during tutorials
During each tutorial, we—the authors of the study—acted as facilitators to help the leaders handle questions and manage time effectively. The leaders were often unable to see the live chat while presenting, and we therefore found natural break points in the presentation to answer questions sent to the chat. While we allowed for written and spoken questions, participants preferred to ask questions in the chat, possibly to avoid interrupting the presenter and to allow them to answer asynchronously.
Participants were encouraged to test out the code on their own during the tutorial, and the code was generally written to execute quickly without significant lag for e.g. downloads or model training (item-tooling). This often required the leaders to run some of the code in advance to automate less interesting components of the tutorial, e.g. selecting the optimal number of topics for the topic model.
Lessons learned Based on some of the questions received, participants seemed to engage well with the code and to follow up with some of the methods. Participants asked between 1 and 15 questions per tutorial (median 5). We show example questions from the tutorials with the largest number of questions in . The questions cover both simple closed-answer questions (“Can the code provide statistics”) and more complicated open-ended questions (“How should someone choose the model to use”). While the number of questions was relatively low overall, the participants who asked questions were engaged and curious about the limitations and ramifications of the methods being presented. To improve participant engagement via questions, future leaders may find it useful to pose their own questions throughout the code notebook (“what do you think would happen if we applied method X while setting parameter Z=1?”) as a way to guide the participants’ curiosity.
Analysis of Effectiveness
Pre- and post-surveys during live tutorials
During the live portions of the tutorials, we distributed an optional survey to participants at the beginning and end of the one-hour sessions.[During T1-T3 we were prototyping the series, so we only distributed the surveys for T4-T12.] The pre-survey consisted of three questions in a Google form: (Pre-Q1) Academic discipline background in which participants chose one of the given disciplines or wrote their own; (Pre-Q2) How many years of experience in coding/data analysis do you have? which had four options; and (Pre-Q3) How much do you currently know about the topic? which was judged on a 7-point Likert scale with 1 described as I know nothing about the topic , 4 described as I could possibly use the methods in my research, but I’d need guidance and 7 described as Knowledgeable, I could teach this tutorial. The post-survey consisted of four questions: (Post-Q1) Code: How much did you learn from the hands-on code aspect of the tutorial? ; (Post-Q2) Content: How much did you learn from the content part of the tutorial? ;(Post-Q3) Now, after the tutorial, how much do you currently know about the topic? and (Post-Q4) Any suggestions or changes we should make for the next tutorial? . Questions 1 and 2 were judged on a 5-point Likert scale with 1 described as Learned nothing new and 5 described as Learned much more than I could have on my own . Question 3 was judged on the same 7-point Likert scale as the analogous question in the pre-survey.
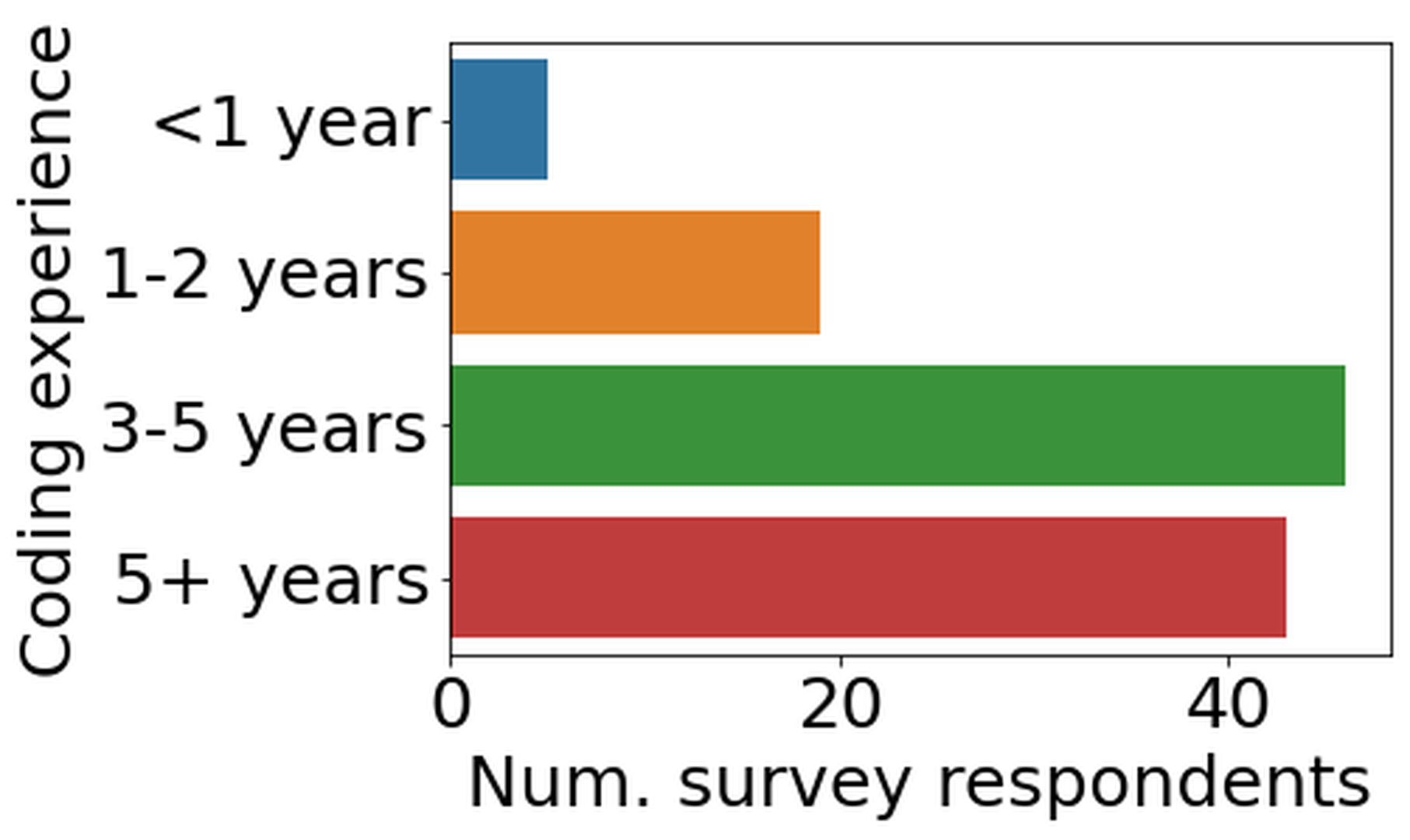
Results We report aggregated survey responses in Figure fig-allsurveys. Across the eight tutorials for which we collected data, the pre-surveys had 113 respondents total and the post-surveys had 63 respondents. Figure f-fields shows the results of the breakdown by academic discipline or background (Pre-Q1) . The three largest areas of participation came from the fields of computer science, sociology, and political science. Figure f-experience shows that our participants actually had quite a lot of experience in coding or data analysis (Pre-Q2) –78.8% of participants who responded had three or greater years of experience in coding.
Analyzing Post-Q1 about how much they learned from code, participants responded with $\mu=4, \sigma=0.94$ . Post-Q2 about learning from content was similar with $\mu=4.24, \sigma=0.9$ . Interpreting these results, many participants perceived a high degree of learning from attending the live tutorials. We measure the pre- to post-survey learning by computing the difference between the mean of Post-Q3 and mean of Pre-Q3 , and we find a difference of 0.77.[Ideally, we would look not at the aggregate participant responses but instead test the pairwise differences for each individual’s pre- versus post-survey. However, we found that only 18 participants could be matched from pre- to post-survey due to drop-out, which is too small for pairwise significance testing.] We ran a two-sided T-test to see if the pre- versus post-survey differences were greater than zero with statistical significance, which produced a t-value of 4.16 and a p-value less than $10^{-5}$ . While seemingly small in aggregate, this change represents a consistent growth in perceived knowledge among participants that is surprising considering the relatively short tutorial length of one hour. Manually reading the responses from (Post-Q4) , participants described very positive experiences, including ”very good tutorial” “Excellent tutorial!!!” and “very helpful.”
Lessons learned As Figure f-fields shows, we were successful in recruiting participants from a wide variety of social science disciplines. However, computer science or data science—top-most bar in Figure f-fields—was the most represented field. In reflection, having another organizer who was primarily focused on social science, rather than NLP, would help us recruit more CSS-oriented participants and would align better with item-relevant. Responses from Post-Q4 also indicated that the tutorials were not long enough for some participants. One participant said “It would be great to make something like this into a multi-part tutorial. It seemed like too much new material for 1 hour.” Some suggestions for future tutorial organizers could be to make the tutorials 2-3 hours long. In the first hour, the tutorial could provide an overview, followed by more advanced topics or practice in hours 2-3. It’s difficult to satisfy the trade-offs of (1) audience attention bandwidth and (2) fully explaining a particular method. We also could have improved how we set audience expectations: introducing the tutorials as a crash course and explaining that participants should expect to spend 4-5 hours on their own afterwards to learn the material in depth. Furthermore, future leaders may want to require or strongly encourage participation in the surveys to improve data collection as we had relatively low participation rates.[After all the tutorials were presented, we also sent a survey to the mailing list to ask about how much participants had learned from the tutorials and whether they used the material in their own work. We received only five responses total, therefore we do not present statistics here. ]
Downstream impact
Despite the relatively low synchronous participation (roughly 4-30 participants per session), the views on the tutorial videos posted to YouTube showed consistent growth during the tutorial series and even afterward, culminating in total views. In addition, the tutorial materials were showcased on the website for the Summer Institute for Computational Social Science,[Accessed 15 October 2022: https://sicss.io/overview .] and several tutorial leaders presented their tutorials again at an international social science conference, having prepared relevant materials as part of our series (item-code). [International Conference on Web and Social Media 2022, accessed 15 October 2022: https://www.icwsm.org/2022/index.html/#tutorials-schedule ] The tutorial series may therefore have the greatest impact not for the synchronous participants but instead for the large and growing audience of researchers who discover the materials after the fact and may not have the resources to learn about the methods via traditional methods (item-free). The success of the tutorials in other contexts also points to the beginning of a virtuous cycle, in which tutorial leaders test-drive their work in an informal setting and then present a more formal version at an academic conference.
Conclusion
Future improvements Reflecting on this experience report, we suggest the following improvements for future ML+X tutorial organizers:
- Despite the results of the pre-tutorial interest surveys, we made curatorial decisions about the content and we cannot be sure that we satisfied the needs of what participants wanted versus what we thought was important.
- Future organizers may achieve higher participation by focusing on methods with high public interest, regardless of their lower perceived utility by subject area experts.
- The two co-organizers were both computer scientists, and we largely leveraged a computer science professional network for recruitment.
- Future renditions would ideally include a social scientist co-organizer to provide better insight into current ML needs and desires among researchers (item-relevant), as well as helping tutorial participants feel more at ease with complicated ML methods.
- Despite high sign-up rates and lack of cost (item-free), participants would often fail to attend tutorials for which they had signed up.
- This may reflect a lack of commitment among participants due to the virtual presence (“just another Zoom meeting”), or a failure to send frequent reminders.
- Future tutorial organizers should experiment with other strategies for encouraging attendance, including more topical data sets, a “hackathon” setting, or a structured community to engage participants before and after the tutorial.
- We found that participants did not consistently engage in the hands-on coding segments of the tutorials.
- We recommend that future tutorial leaders either simplify the hands-on coding for short sessions, or follow up on the tutorial with additional “office hours” for interested students to try out the code and ask further questions about the method.
- Similar to some computer science courses, this approach might have a lecture component and a separate “recitation” session for asking questions about the code.
- In the early stages of the tutorial series, we focused more on executing the tutorials rather than collecting quantitative data about the participants’ experience.
- This makes it difficult to judge some aspects of the tutorials’ success, especially how the tutorials were received by participants with different backgrounds and expectations.
- With more extensive evaluation and participation in surveys, we hope that future organizers will make quicker and more effective improvements during the course of a tutorial series.
Successes Despite these drawbacks, we believe our tutorial series succeeded in its goal—to help social scientists advance their skills beyond introductory NLP methods. We hope other ML+X tutorials can build from our successes:
- We accumulated total views among our public recordings.
- Thus, we’d encourage future ML+X organizers to put even more effort into the recordings rather than live sessions.
- Although participants came in skilled—78.8% of participants who responded had three or greater years of experience in coding (Figure f-experience)–they reported aggregate increase in perceived knowledge of the methods presented—0.77 on a 7-point Likert scale.
- We generated education content for a diverse set of relevant and new NLP methods (item-relevant&item-recent) that can accelerate social science research.
- The subject matter experts who led the tutorials were able to translate complicated ML concepts into understandable, step-by-step lessons.
- We hope future ML+X organizers can take inspiration from these tutorials’ choice of content and social organization.
- Our tutorials have produced ready-to-use, modular, and freely available Python code with a low barrier to entry (item-tooling,item-code,item-free), which will provide “scaffolding” to future students seeking to start their own projects.
- We envision future ML+X organizers using this codebase as a template for releasing code in their own domain.
As machine learning methods become more available and more powerful, scientists may feel encouraged to implement these methods within their own domain-specific research. We believe tutorial series such as the one described in this report will help guide these researchers on their journey. Like the tutorials themselves, we hope that our Principles for Democratizing ML+X Tutorials () will be used as springboard toward more open and inclusive learning experiences for all researchers. Rather than wait for top-down solutions, we encourage other ML practitioners to get involved and shape the future of applied science by sharing their knowledge directly with scholars eager to know more.
Acknowledgments
We are deeply grateful for financial assistance from a Social Science Research Council (SSRC)/Summer Institutes in Computational Social Science (SICSS) Research Grant. We thank SIGCSE reviewers and various computer science education experts for their feedback on initial drafts. We thank the fifteen organizers who generously donated their expertise and time to making these tutorials possible: Connor Gilroy, Sandeep Soni, Andrew Halterman, Emaad Manzoor, Silvia Terragni, Maria Antoniak, Abe Handler, Shufan Wang, Jonathan Chang, Steve Wilson, Dhanya Sridhar, Monojit Choudhury, Sanad Rizvi, and Neha Kennard.
Appendix
We provide the full abstracts of the tutorials in Table tab-tutorial-abstracts, which the tutorial leaders wrote in coordination with the organizers.
Tutorial abstracts, provided by leaders.
Table Label: tab-tutorial-abstracts
Download PDF to view tableBibliography
1@article{birjali2021,
2 publisher = {Elsevier},
3 year = {2021},
4 pages = {107134},
5 volume = {226},
6 journal = {Knowledge-Based Systems},
7 author = {Birjali, Marouane and Kasri, Mohammed and Beni-Hssane, Abderrahim},
8 title = {A comprehensive survey on sentiment analysis: Approaches, challenges and trends},
9}
10
11@article{jordan2015machine,
12 publisher = {American Association for the Advancement of Science},
13 year = {2015},
14 pages = {255--260},
15 number = {6245},
16 volume = {349},
17 journal = {Science},
18 author = {Jordan, Michael I and Mitchell, Tom M},
19 title = {Machine learning: Trends, perspectives, and prospects},
20}
21
22@misc{mason2014computational,
23 publisher = {Springer},
24 year = {2014},
25 pages = {257--260},
26 number = {3},
27 volume = {95},
28 journal = {Machine Learning},
29 author = {Mason, Winter and Vaughan, Jennifer Wortman and Wallach, Hanna},
30 title = {Computational social science and social computing},
31}
32
33@article{beam2018big,
34 publisher = {American Medical Association},
35 year = {2018},
36 pages = {1317--1318},
37 number = {13},
38 volume = {319},
39 journal = {Jama},
40 author = {Beam, Andrew L and Kohane, Isaac S},
41 title = {Big data and machine learning in health care},
42}
43
44@article{benato2020teaching,
45 publisher = {IOP Publishing},
46 year = {2020},
47 pages = {C09011},
48 number = {09},
49 volume = {15},
50 journal = {Journal of Instrumentation},
51 author = {Benato, Lisa and Connor, PLS and Kasieczka, G and Kr{\"u}cker, D and Meyer, M},
52 title = {Teaching machine learning with an application in collider particle physics},
53}
54
55@inproceedings{ling2021first,
56 organization = {IEEE},
57 year = {2021},
58 pages = {1452--1467},
59 booktitle = {2021 IEEE Symposium on Security and Privacy (SP)},
60 author = {Ling, Chen and Balc{\i}, Utkucan and Blackburn, Jeremy and Stringhini, Gianluca},
61 title = {{A First Look at Zoombombing}},
62}
63
64@article{blei2003latent,
65 year = {2003},
66 pages = {993--1022},
67 number = {Jan},
68 volume = {3},
69 journal = {Journal of machine Learning research},
70 author = {Blei, David M and Ng, Andrew Y and Jordan, Michael I},
71 title = {{Latent Dirichlet Allocation}},
72}
73
74@article{bail2018exposure,
75 publisher = {National Acad Sciences},
76 year = {2018},
77 pages = {9216--9221},
78 number = {37},
79 volume = {115},
80 journal = {Proceedings of the National Academy of Sciences},
81 author = {Bail, Christopher A and Argyle, Lisa P and Brown, Taylor W and Bumpus, John P and Chen, Haohan and Hunzaker, MB Fallin and Lee, Jaemin and Mann, Marcus and Merhout, Friedolin and Volfovsky, Alexander},
82 title = {Exposure to opposing views on social media can increase political polarization},
83}
84
85@inproceedings{cai2019software,
86 organization = {IEEE},
87 year = {2019},
88 pages = {25--34},
89 booktitle = {2019 IEEE symposium on visual languages and human-centric computing (VL/HCC)},
90 author = {Cai, Carrie J and Guo, Philip J},
91 title = {Software developers learning machine learning: Motivations, hurdles, and desires},
92}
93
94@article{decost2020scientific,
95 publisher = {IOP Publishing},
96 year = {2020},
97 pages = {033001},
98 number = {3},
99 volume = {1},
100 journal = {Machine learning: science and technology},
101 author = {DeCost, Brian L and Hattrick-Simpers, Jason R and Trautt, Zachary and Kusne, Aaron Gilad and Campo, Eva and Green, ML},
102 title = {{Scientific AI in materials science: a path to a sustainable and scalable paradigm}},
103}
104
105@article{karniadakis2021physics,
106 publisher = {Nature Publishing Group},
107 year = {2021},
108 pages = {422--440},
109 number = {6},
110 volume = {3},
111 journal = {Nature Reviews Physics},
112 author = {Karniadakis, George Em and Kevrekidis, Ioannis G and Lu, Lu and Perdikaris, Paris and Wang, Sifan and Yang, Liu},
113 title = {Physics-informed machine learning},
114}
115
116@article{jones2019setting,
117 publisher = {Nature Publishing Group},
118 year = {2019},
119 pages = {659--660},
120 number = {11},
121 volume = {20},
122 journal = {Nature Reviews Molecular Cell Biology},
123 author = {Jones, David T},
124 title = {Setting the standards for machine learning in biology},
125}
126
127@inproceedings{wen2014sentiment,
128 organization = {Citeseer},
129 year = {2014},
130 booktitle = {Educational data mining 2014},
131 author = {Wen, Miaomiao and Yang, Diyi and Rose, Carolyn},
132 title = {Sentiment Analysis in MOOC Discussion Forums: What does it tell us?},
133}
134
135@article{koedinger2015data,
136 publisher = {Wiley Online Library},
137 year = {2015},
138 pages = {333--353},
139 number = {4},
140 volume = {6},
141 journal = {Wiley Interdisciplinary Reviews: Cognitive Science},
142 author = {Koedinger, Kenneth R and D'Mello, Sidney and McLaughlin, Elizabeth A and Pardos, Zachary A and Ros{\'e}, Carolyn P},
143 title = {Data mining and education},
144}
145
146@article{mtsweni2015stimulating,
147 publisher = {Independent Institute of Education},
148 year = {2015},
149 pages = {85--97},
150 number = {1},
151 volume = {10},
152 journal = {The Independent Journal of Teaching and Learning},
153 author = {Mtsweni, Jabu and Abdullah, Hanifa},
154 title = {Stimulating and maintaining students' interest in Computer Science using the hackathon model},
155}
156
157@inproceedings{russ2021online,
158 year = {2021},
159 pages = {1--7},
160 booktitle = {Proceedings of the 18th International Web for All Conference},
161 author = {Russ, Shanna and Hamidi, Foad},
162 title = {Online learning accessibility during the COVID-19 pandemic},
163}
164
165@article{marcelino2018learning,
166 publisher = {Elsevier},
167 year = {2018},
168 pages = {470--477},
169 volume = {80},
170 journal = {Computers in Human Behavior},
171 author = {Marcelino, Maria Jos{\'e} and Pessoa, Teresa and Vieira, Celeste and Salvador, Tatiana and Mendes, Ant{\'o}nio Jos{\'e}},
172 title = {{Learning computational thinking and Scratch at distance}},
173}
174
175@article{nguyen2020we,
176 publisher = {Frontiers Media SA},
177 year = {2020},
178 pages = {62},
179 volume = {3},
180 journal = {Frontiers in Artificial Intelligence},
181 author = {Nguyen, Dong and Liakata, Maria and DeDeo, Simon and Eisenstein, Jacob and Mimno, David and Tromble, Rebekah and Winters, Jane},
182 title = {How we do things with words: Analyzing text as social and cultural data},
183}
184
185@inproceedings{berger2018biology,
186 year = {2018},
187 pages = {233--238},
188 booktitle = {Proceedings of the 49th ACM Technical Symposium on Computer Science Education},
189 author = {Berger-Wolf, Tanya and Igic, Boris and Taylor, Cynthia and Sloan, Robert and Poretsky, Rachel},
190 title = {A biology-themed introductory CS course at a large, diverse public university},
191}
192
193@inproceedings{tu2018experience,
194 year = {2018},
195 pages = {509--514},
196 booktitle = {Proceedings of the 49th ACM Technical Symposium on Computer Science Education},
197 author = {Tu, Yu-Cheng and Dobbie, Gillian and Warren, Ian and Meads, Andrew and Grout, Cameron},
198 title = {An experience report on a boot-camp style programming course},
199}
200
201@article{faust2018deep,
202 publisher = {Elsevier},
203 year = {2018},
204 pages = {1--13},
205 volume = {161},
206 journal = {Computer methods and programs in biomedicine},
207 author = {Faust, Oliver and Hagiwara, Yuki and Hong, Tan Jen and Lih, Oh Shu and Acharya, U Rajendra},
208 title = {Deep learning for healthcare applications based on physiological signals: A review},
209}
210
211@article{toney2021fighting,
212 year = {2021},
213 pages = {10},
214 number = {1},
215 volume = {48},
216 journal = {Communications of the Association for Information Systems},
217 author = {Toney, Scott and Light, Jenn and Urbaczewski, Andrew},
218 title = {{Fighting Zoom fatigue: Keeping the zoombies at bay}},
219}
220
221@article{sharlach2019,
222 urldate = {2019-07-16},
223 url = {https://www.princeton.edu/news/2019/07/16/summer-institute-advances-social-science-digital-age},
224 year = {2019},
225 date = {2019-07-16},
226 journal = {Princeton Office of Engineering Communications},
227 title = {Summer institute advances social science in the digital age},
228 author = {Sharlach, Molly},
229}
230
231@article{summers2021artificial,
232 publisher = {Radiological Society of North America},
233 year = {2021},
234 journal = {Radiology},
235 author = {Summers, Ronald M},
236 title = {{Artificial intelligence of COVID-19 imaging: a hammer in search of a nail}},
237}
238
239@article{adame2021meaningful,
240 year = {2021},
241 journal = {Nature},
242 author = {Adame, Fernanda},
243 title = {Meaningful collaborations can end ``helicopter research''},
244}
245
246@article{saunders2018eleven,
247 publisher = {Public Library of Science San Francisco, CA USA},
248 year = {2018},
249 pages = {e1006039},
250 number = {3},
251 volume = {14},
252 journal = {PLoS computational biology},
253 author = {Saunders, Timothy E and He, Cynthia Y and Koehl, Patrice and Ong, LL Sharon and So, Peter TC},
254 title = {Eleven quick tips for running an interdisciplinary short course for new graduate students},
255}
256
257@inproceedings{ritz2018programming,
258 year = {2018},
259 pages = {239--244},
260 booktitle = {Proceedings of the 49th ACM Technical Symposium on Computer Science Education},
261 author = {Ritz, Anna},
262 title = {Programming the central dogma: An integrated unit on computer science and molecular biology concepts},
263}
264
265@inproceedings{oesper2020expanding,
266 year = {2020},
267 pages = {1214--1219},
268 booktitle = {Proceedings of the 51st ACM Technical Symposium on Computer Science Education},
269 author = {Oesper, Layla and Vostinar, Anya},
270 title = {Expanding undergraduate exposure to computer science subfields: Resources and lessons from a hands-on computational biology workshop},
271}
272
273@inproceedings{nam2010effects,
274 organization = {Asia-Pacific Society for Computers in Education Putrajaya, Malaysia},
275 year = {2010},
276 pages = {727},
277 volume = {723},
278 booktitle = {Proceedings of the 18th International Conference on Computers in Education},
279 author = {Nam, Dongsoo and Kim, Yungsik and Lee, Taewook},
280 title = {{The effects of scaffolding-based courseware for the Scratch programming learning on student problem solving skill}},
281}
282
283@inproceedings{wallace2013social,
284 organization = {IEEE},
285 year = {2013},
286 pages = {198--200},
287 booktitle = {2013 Second International Conference on E-Learning and E-Technologies in Education (ICEEE)},
288 author = {Wallace, Albin},
289 title = {Social learning platforms and the flipped classroom},
290}
291
292@article{wiley2002online,
293 year = {2002},
294 pages = {33--46},
295 number = {1},
296 volume = {3},
297 journal = {Quarterly review of distance education},
298 author = {Wiley, David A and Edwards, Erin K},
299 title = {Online self-organizing social systems: The decentralized future of online learning},
300}
301
302@article{meerbaum2013learning,
303 publisher = {Taylor \& Francis},
304 year = {2013},
305 pages = {239--264},
306 number = {3},
307 volume = {23},
308 journal = {Computer Science Education},
309 author = {Meerbaum-Salant, Orni and Armoni, Michal and Ben-Ari, Mordechai},
310 title = {Learning computer science concepts with scratch},
311}
312
313@inproceedings{tang2014environment,
314 year = {2014},
315 pages = {671--676},
316 booktitle = {Proceedings of the 45th ACM technical symposium on Computer science education},
317 author = {Tang, Terry and Rixner, Scott and Warren, Joe},
318 title = {An environment for learning interactive programming},
319}
320
321@article{lazer2009computational,
322 publisher = {American Association for the Advancement of Science},
323 year = {2009},
324 pages = {721--723},
325 number = {5915},
326 volume = {323},
327 journal = {Science},
328 author = {Lazer, David and Pentland, Alex and Adamic, Lada and Aral, Sinan and Barab{\'a}si, Albert-L{\'a}szl{\'o} and Brewer, Devon and Christakis, Nicholas and Contractor, Noshir and Fowler, James and Gutmann, Myron and others},
329 title = {Computational social science},
330}
331
332@article{twigg2003models,
333 year = {2003},
334 pages = {28--38},
335 volume = {38},
336 journal = {Educause review},
337 author = {Twigg, Carol A},
338 title = {Models for online learning},
339}
340
341@inproceedings{diaz2018addressing,
342 year = {2018},
343 pages = {1--14},
344 booktitle = {Proceedings of the 2018 chi conference on human factors in computing systems},
345 author = {D{\'\i}az, Mark and Johnson, Isaac and Lazar, Amanda and Piper, Anne Marie and Gergle, Darren},
346 title = {Addressing age-related bias in sentiment analysis},
347}
348
349@article{edelmann2020computational,
350 publisher = {NIH Public Access},
351 year = {2020},
352 pages = {61},
353 number = {1},
354 volume = {46},
355 journal = {Annual Review of Sociology},
356 author = {Edelmann, Achim and Wolff, Tom and Montagne, Danielle and Bail, Christopher A},
357 title = {Computational social science and sociology},
358}
359
360@article{abramson2019translational,
361 publisher = {IEEE},
362 year = {2019},
363 pages = {16--23},
364 number = {9},
365 volume = {52},
366 journal = {Computer},
367 author = {Abramson, David and Parashar, Manish},
368 title = {Translational research in computer science},
369}
370
371@article{harasim2000shift,
372 publisher = {Elsevier},
373 year = {2000},
374 pages = {41--61},
375 number = {1-2},
376 volume = {3},
377 journal = {The Internet and higher education},
378 author = {Harasim, Linda},
379 title = {Shift happens: Online education as a new paradigm in learning},
380}
381
382@article{vardi2012will,
383 publisher = {ACM New York, NY, USA},
384 year = {2012},
385 pages = {5--5},
386 number = {11},
387 volume = {55},
388 journal = {Communications of the ACM},
389 author = {Vardi, Moshe Y},
390 title = {{Will MOOCs destroy academia?}},
391}
392
393@article{de2011using,
394 year = {2011},
395 pages = {94--115},
396 number = {7},
397 volume = {12},
398 journal = {The International Review of Research in Open and Distributed Learning},
399 author = {De Waard, Inge and Abajian, Sean and Gallagher, Michael Sean and Hogue, Rebecca and Keskin, Nilg{\"u}n and Koutropoulos, Apostolos and Rodriguez, Osvaldo C},
400 title = {{Using mLearning and MOOCs to understand chaos, emergence, and complexity in education}},
401}Attribution
arXiv:2211.15971v1
[cs.CL]
License: cc-by-4.0


