
- Papers
Papers is Alpha. This content is part of an effort to make research more accessible, and (most likely) has lost some details from the original. You can find the original paper here.
Introduction
Millions of people rely on recommender systems daily. Examples of recommendation based activities include listening to music via streaming services, shopping for products and services online, and browsing through social media streams. What we can choose from in the context of these activities is determined by algorithmic decision architectures that are optimised for a specified target such as maximising engagement, maximising the click through rate[https://en.wikipedia.org/wiki/Click-through_rate ], or increasing the sales. To enable these functionalities, recommender systems employ increasingly sophisticated user behaviour models that incorporate information on users’ past behaviours, preferences, interactions and created content.
Machine learning (ML) models that enable recommendations and that are trained on user data may unintentionally leverage information on human characteristics that are considered vulnerabilities (e.g., depression, young age, gambling addiction). In simple terms, an ML model may include a parameterised representation of a person’s vulnerability. Algorithmic decisions that are based on models using such representations could be considered manipulative, because the use of algorithmic decisions based on representations of vulnerabilities might have a deteriorating impact on the vulnerability condition of individuals. Among the prohibited artificial intelligence (AI) applications listed in article 15 of the European Commission’s proposal for a Regulation on Artificial Intelligence, are applications that perform manipulative or exploitative online practices producing physical or psychological harms to individuals or exploit their vulnerability on the basis of age or disability.
The use of ML models that exploit or impact the vulnerability of persons can become an ethical and potentially legal issue, because it could lead to manipulation, reduced agency/autonomy, or altered behaviour of individuals, in a way that is not necessarily in their best interest. Currently it is difficult to know whether a given model’s decisions are based on vulnerability-related information. However, public mandates for AI auditing must address this issue, and explainable AI (XAI) methods may be necessary for detecting vulnerability exploitation by ML based recommendation systems.
In this paper we are concerned with the problem of vulnerability detection by machine learning models, and our specific contributions are the following.
-
We define and describe examples of potential vulnerabilities and how they manifest in behaviour.
-
Weargue, by means of a literature review, that machine learning models can and are being used to detect vulnerabilities.
-
We illustrate cases in which vulnerabilities are likely to play a role in algorithmic decision making based on behavioural and contextual data.
-
To ameliorate the current situation, we further propose a set of requirements that methods must fulfil in order to:
- detect the potential for vulnerability modelling,
- detect whether vulnerable groups are treated differently by the model, and
- detect whether an ML model has created an internal representation of vulnerability.
The paper structure follows the above order of contributions. We conclude with an outlook perspective on the importance to not only regulate applied AI systems on a technical level, but to put the human at the centre of this process.
Vulnerability in the context of machine learning
In the context of algorithmic decisions systems, it is challenging to draw the line between persuasivesystems and manipulation. It is not simple to identify where free will ends and where manipulation startsHence, to understand the possible impact that machine learning systems can have on individuals from vulnerable groups, we need to establish a definition of vulnerabilities and create an understanding of how machine learning with big behavioural data can model these.
Vulnerability The United Nations define vulnerabilities as “The conditions determined by physical, social, economic and environmental factors or processes which increase the susceptibility of an individual, a community, assets or systems to the impacts of hazards.”[https://www.undrr.org/terminology/vulnerability ]. Unlike in physical environments, where physical disabilities and vulnerabilities are impactful (e.g., paraplegia), in digital environments, psychological vulnerabilities (e.g., depression) are more exposed to exploitation and discrimination. Hence, here we are primarily concerned with psychological and social factors which increase the susceptibility of an individual to the impacts of hazards.
When consideringpsychological vulnerabilities, it can be helpful to distinguish between stable (i.e., traits; anxiety disorder) and momentary characteristics (i.e., states; momentary anxiety) of a person. In that regard, we define vulnerabilities for the purposes of this article as follows:
- A person is vulnerable if their permanent or momentary psychological characteristics makes it particularly difficult for them to make autonomous choices and to exert agency over their actions under full consideration of their consequences and outcomes.
It is “the quality or state of being exposed to the possibility of being attacked or harmed, either physically or emotionally.”. For this reason, vulnerable individuals can be exposed to additional forms of harm or an aggravation of their condition (e.g., aggravation from mild depression to major depression) without their awareness and the agency to prevent or counteract it.
For the purpose of this article, we will use symptoms of major depressionas an illustrative example of a relatively stable psychological vulnerability for which first evidence suggests the possibility to model it using machine learning and digital footprints. The identification of people who are suffering the symptoms of major depression can in certain contexts be in violation of several ethical principles.
Exploitable vulnerabilities in algorithmic decision systems
In machine learning systems, vulnerabilities can be automatically exploited when the vulnerable state or condition of an individual becomes entangled with the optimisation criteria of an algorithmic system (i.e., recommender system). For example, depressive users on a social media platform might engage more with content that is emotionally charged with feelings of sadness, depression, and hopelessness. This behavioural tendency or “interest” might be picked up by the optimisation algorithm of that platform that is designed to maximise user engagement based on behaviour. Consequently, the platform could provide an increasing number of similar content to the user. While this optimisation procedure is effective to optimise user-engagement and harmless for non-vulnerable users (e.g., providing increasingly specific content on taco recipes), the increased provision of depression-related content to users with the vulnerable condition might aggravate the depressive symptoms of the user (e.g., reinforcement of perception of worthlessness) while increasing their engagement with the platform.
It is difficult – and outside our aim – to analyse the underlying causal patterns between mental states and compulsive behaviours. There is, however, sufficient reason to consider that emotions of depression, anxiety,individuals having a negative view of themselves, coincide with mental conditions that lead to compulsive behaviours. For example,conclude that “Compulsive buying is frequent among bipolar patients going through a manic phase. In most cases, the behaviour is associated with other impulse control disorders or dependence disorders and a high level of impulsivity”. Similarly,conclude that “Our data emphasises the frequency of association between ICDs (impulse control disorders) and major depression, and 29% of the depressed patients also had an ICD”. Shopping as a coping behaviour for stress also is investigated in, who report that “more stress release was found with larger amounts spent”.state that “Although no studies directly compare a cohort of ICD patients with a cohort of mood disorder patients, available data suggest that ICDs and bipolar disorder share a number of features: (1) phenomenological similarities, including harmful, dangerous, or pleasurable behaviours, impulsivity, and similar affective symptoms and dysregulation …”. One could argue that these are exactly the kind of behaviours social media usage is likely to reflect, probably even before they are discovered clinically or by the individuals themselves.
This insight must be combined with the knowledge that data based models for identifying and predicting mental health conditions are used for commercial purposes. For example, a leaked Facebook document reported by The Australianrevealed that the platform uses data based models to identify young, meaning down to $14$ year old, individuals feeling vulnerable, i.e. “worthless”, “insecure”, “stressed”, “defeated”, “overwhelmed”, “anxious”, “nervous”, “stupid”, “silly”, “useless”, and “a failure”. Furthermore, the document, marked “Confidential: Internal Only”, outlines how Facebook can target “moments when young people need a confidence boost”, and reveals an interest in helping advertisers target moments in which young users desire “looking good and body confidence” or “working out and losing weight”.
As stated by: “A key ethics challenge for using social networking site data (…) will be to ensure that vulnerable individuals have a comprehensive and sustained understanding of what participation involves…”. We fully agree with this conclusion, and argue that most users of social platforms do indeed not have such a comprehensive and sustained understanding. Sadly, this is neither a novelty nor a controversial stance. However, we also argue that this problem exists on two levels, one level being the mere flow of information, or desire of social media platforms to inform users of how their data is being used. The second level is more subtle as well as technical, since “understanding of what participation involves” requires an understanding of the models used to analyse the data of the individual. Such understanding of non-interpretable models is at present often not possible, commonly referred to as the “black box” problem in machine learning and artificial intelligence.
This must be considered in light of the observation that the reviews quoted in the beginning of this section –, reporting the general tendency of machine learning methods replacing traditional forms of data analysis – consequently report an increase in non-interpretable models being proposed to predict psychological constructs and to detect mental health disorders.
All these things can be considered vulnerabilities, and in section sec-digbehdat we summarise research suggesting that AI can be used to detect such vulnerabilities.
Digital behavioural data for assessing psychological constructs
Unlike physical characteristics (e.g., body height), latent psychological characteristics of individuals cannot be measured directly but need to be estimated from reports, observations, or psychometric tests (e.g., cognitive abilities) of peoples thoughts, feelings, and behaviours. For example, most forms of mental health disorders are diagnosed via standardised self-report scales and structured clinical interviews. However, the self-reported information that is collected in this diagnostic process is highly subjective and retrospective. This is problematic because many psycho-pathological conditions impact peoples cognitive abilities (e.g., concentration, memory), hence potentially bias the obtained information. Moreover, self-reports are subject to a myriad of methodological influencesand intentional faking.
New approaches have been developed to assess psychological phenomena and psychopathology combining objective data on people`s digital behavioural and online footprints with machine learning. Text data in particular has long been considered as a valid source of information on psychological processes. As early as 1982reported that patients could be classified into groups suffering from depression and paranoia based on linguistic speech analysis. More recent workhas demonstrated that personal characteristics and traits can be inferred from text and other digital footprints on social media platforms. Others have demonstrated that these data can be used to predict individual well-beingand future mental illness.
Particularly well explored is depression, including comorbidity such as self-harm, and anorexia. Quantifiable signals in Twitter data relevant to bipolar disorder, major depressive disorder, post-traumatic-stress disorder and seasonal affective disorder were demonstrated by, who constructed data-based models capable of separating diagnosed from control users for each disorder. These systematic reviews,, provide an overview of these approaches.
Another growing body of research suggests that more fine-grained behavioural and contextual data that can be collected with of-the-shelf smartphones allow for similarly accurate predictions of psychological phenomena with much smaller samples. Computational inferences from mobile sensing data include a number of psychologically-relevant individual differences including demographics, moral values, and personality traits. Latest work, has started to explore the feasibility to predict clinical depression levels using messaging texts and sensor readings from smartphones. Finally, efforts to recognise unstable psychological states such as affective-emotional statesor cognitionproved more challenging and constitute an area of ongoing research. The algorithmic recognition of these states is highly relevant to the understanding of more complex psychological phenomena such as depression, yet more difficult to achieve.
Extant evidence sufficiently suggests that information about psychological traits and mental health states can be linked to digital behavioural footprints. However, it should be noted that despite a large body of research literature on the subject, obtaining clinically valid diagnostic information on individuals is challenging. This, as discussed in, leads to subsidiary “proxy diagnostic signals”, meaning characteristic online behaviours, being used instead in this kind of research.also report that these diagnostic signals lead to models with poor external validity, cautioning against their use for clinical decision-making.
While data based tools assessing mental health can certainly be used to help vulnerable individuals – suicide prevention tools have for instance been available on Facebook for more than ten years– their existence also raises several concerns: The general desirability of subsequent interventions has not been democratically agreed upon. Whether the use of data for this purpose can really be characterised as voluntary for Facebook users is not clear, as evidenced by e.g. the public dispute of the study `Experimental Evidence of Massive-Scale Emotional Contagion Through Social Networks’, including its editorial expression of concern. Showing that social media data can be used for emotional contagion – “leading people to experience (…) emotions without their awareness” –, this study together with the existing body of literature lead to the conclusion that not only can data and machine learning models be used to detect emotional states and mental health conditions, but that such models are already being successfully developed and used to change them.
Due to this fact caution is warranted in the way how these normally protected information is treated in digital environments.
Towards detecting vulnerability exploitation in machine learning models
As evidenced in the previous section, ML models are being successfully developed with the purpose of modelling vulnerability. Thus, we must consider whether models developed for other purposes – for example targeted advertisement – on data that contains information about vulnerability, are in fact modelling and thus exploiting this information incidentally.
As discussed in , there is no single marker for vulnerability: it is not directly represented by data features, and must be deduced. While age is something that can be a data feature, human beings do not have e.g. written somewhere on their body, and no single behaviour is uniquely linked to . Furthermore, vulnerability is context dependent. Therefore, in order to detect vulnerabilities, one would have to test for specific ones, and given the relevant context. To illustrate, we provide a list of examples of vulnerabilities in their contexts, see . This list is certainly not exhaustive, and merely included for illustration. A complete list of vulnerabilities to test for would have to be created by legislative operators in the respective administrative region (e.g., the European Union) and kept updated by national agencies and government organs charged with data and/or consumer protection.
Non-exhaustive list of potential vulnerabilities and corresponding relevant contexts. Abbreviations: Post traumatic stress disorder (PTSD); Generalized anxiety disorder (GDA).
Table Label: tab-vulnerabilities
Download PDF to view tablePsychological conditions that can form the base for vulnerabilities are ascertained by psychologists who in turn have to use self-reported feelings and behavioural tendencies to find out whether a person has a mental illness or vulnerability. Alternatively, machine learning models can use data containing language or behavioural patterns to construct latent features representing mental illness or vulnerability in a person. However, if a model is not specifically constructed to detect a vulnerability, how can we be sure that it hasn’t constructed latent features representing vulnerabilities, and exploits these to achieve its goal?
In order to understand whether and how a machine learning model incorporates vulnerabilities, we need to be able to answer some questions about this suspected model. It should also be clear who is able to understand the relationship between the predictions of the model and a specified vulnerability. In addition, there needs to be an understanding of how to sufficiently empower concerned stakeholders to enforce necessary changes to the suspected model and to mitigate the creation and the use of ethically undesirable models in general. Namely, not to simply impose restrictive regulations that prohibit certain model use, but rather to create tools to detect and measure what models do wrong and when.
Information contained in data
Is sufficient information about a given vulnerability contained in the training data of the model?
A data based model consisting only of operations on the input data – which is the case for all ML models, including neural networks – cannot add information beyond what is present in the input data. This is formalised in the Data Processing Inequality, stating that post-processing cannot increase information. Therefore, the necessary information for detecting a vulnerability must be present in the data available to the model under scrutiny. If it is, then there is a possibility that the model uses this information, although this might not be the prime objective of the model.
In order to model the manic phase in a bipolar disorder, the data used by the model must contain either direct or indirect information about manic behaviour.
Information about mental states and vulnerability can either be directly available (e.g., questionnaire data, estimates from models), or indirectly through correlation structures in the data. For example, depression symptoms can be characterised by feelings of sadness, fearfulness, emptiness or hopelessness – information that is frequently expressed in self-statements (e.g., text messages, see). Depressive episodes can also be indicated by more basic behavioural patterns such as unusual diurnal activity (i.e., sleep irregularities) or reduced physical activity, which can also be reflected in digital behavioural data. Knowing common symptoms of depression (e.g. from), we can flag data sets containing information about these behaviours as disposed for modelling depression.
Model behaviour
Are vulnerable groups systematically treated differently by the model?
Assuming we know the true vulnerability status of individuals, we can either monitor the predictions of the model under scrutiny, or attempt to directly compare the model to one that is known to incorporate the vulnerability of interest. The former is done by systematically analysing the predictions of the model and investigate whether there is a high correlation with the predictions of vulnerability.
Assume that we have a data set containing true labels of low impulse control in individuals, and want to investigate whether a targeted advertisement recommender model exploits the vulnerability of these individuals to cause compulsive buying behaviour. Then, we could let the recommender model predict on the data describing the low impulse control individuals as well as a control group consisting of individuals not sharing the vulnerability, and compare the scores assigned to all individuals by the model. If a significantly higher number of individuals with low impulse control are identified as potential buyers by the recommender model, then this model is likely to exploit knowledge of the low impulse control in its prediction. This approach is possible in the case of compulsive buying, since we know that it is possible to predict compulsive buying from pathological personality traits, see e.g..
The second approach relies on the availability of a model that intentionally predicts the vulnerability of interest and that could serve as a “ground truth” source. Here, we give an example to illustrate this approach.
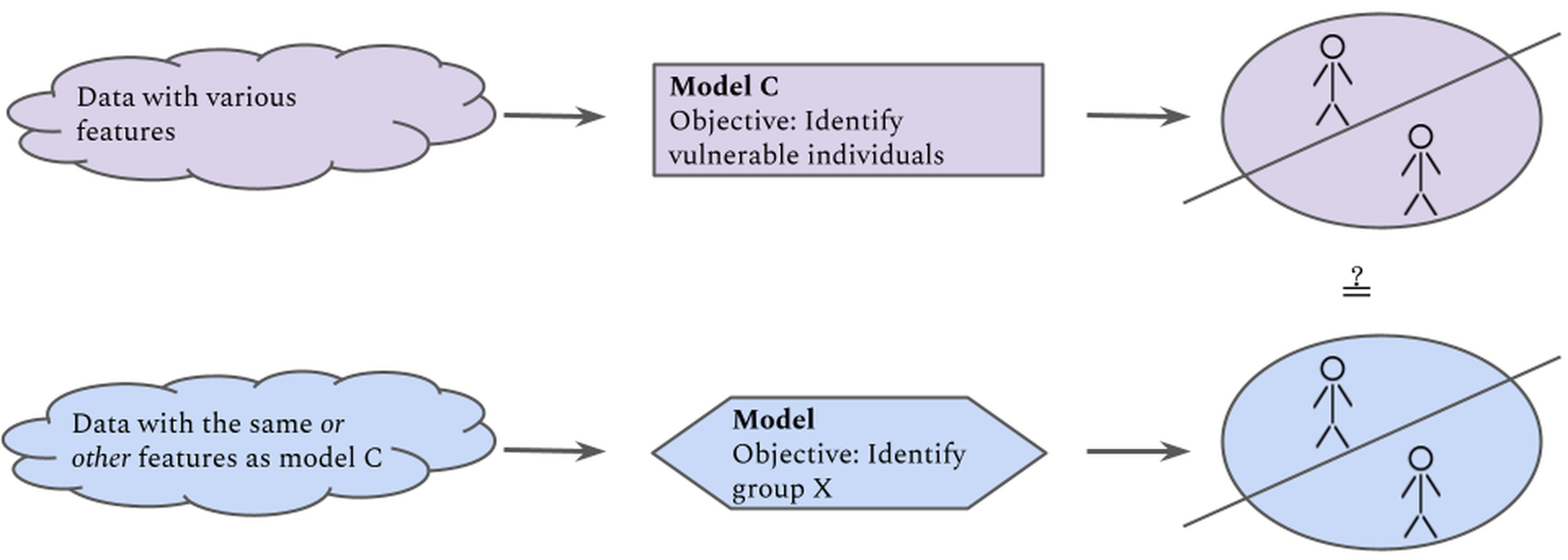
We can train a model $C$ to detect in individuals, and construct a test data set consisting of both individuals having as well as non-afflicted individuals. We can then compare directly how many of the individuals assigned the vulnerability label by $C$ are also identified by the model under scrutiny, either by being assigned to the same class (in the case of classification) or given similar scores (in the case of regression). This method is visualised in . Note that the features each model is trained on need not be the same in order to give the two models the same information about an individual’s vulnerability; most behavioural data are proxy variables.
XAI and existing methods
Has the model built an internal representation of vulnerability?
This approach is introspective, i.e. it involves investigating the internal parameters of the model in order to infer whether these contain sufficient information to separate vulnerable from non-vulnerable individuals. Restricting ourselves to neural networks, we can use methods allowing us to probe the internal state of a neural network for concepts, as described in. Interpreting neural networks’ latent features as human concepts has been studied for a variety of data and model types, including for words, images, and chess.
If we regard a specific vulnerability, for instance , as a concept, we can use concept activation methods to find out whether a neural network model has internalised a representation of this vulnerability as follows. A labelled data set consisting of people with and without the affliction is assembled, and used as positive and negative probes for the concept. Providing this data to the neural network, we collect the activations of its internal layers, and investigate whether these activations can be used to separate the afflicted individuals from the non afflicted individuals in the test data set. The accuracy with which this can be done indicates to which degree the neural network has represented the vulnerability concept. If we can identify representation of a concept by a late layer inside the neural network, or throughout the entire model, we can assume that it has found this information useful andmakes use of it for itsits classification.
Does the model assign high importance to features associated with a vulnerability?
Feature importance attribution methods can be used in order to determine which features have a high impact on a model’s prediction, i.e. which features are “perceived as important by the model itself”. Popular libraries for generating feature attributions include SHAP, SAGE, and LIME. Based on the resulting feature importances, a domain expert on human psychology can assess whether the model makes use of features that are informative with respect to a vulnerability.
Fairness and vulnerability
The concern that a decision-making algorithm, regardless of whether it is model-based or rule-based, treats disadvantaged groups of people differently, falls within the domain of fairness in AI. Fairness in AI is concerned with protecting the ethical value of justice. The justice principle is concerned with how people are treated and embodies the idea that decisions about individuals should be based on just arguments, the consequence of which is that similar people should be treated similarly. Group fairness in particular is concerned with ensuring that decisions to recommend an allocation of a resource, such as a job interview, are not directly or indirectly biased with respect to a legally protected feature of the applicant, for example race.
The fundamental question of fairness is “Is a particular group in treated unjustly or harmed?”. The group in question can be defined by protected attributes, such as race, religion, gender, etc. In principle, groups can also be characterised by vulnerability, and group fairness methods can be applied to issues of detecting vulnerability and de-biasing of a model used in a decision-making algorithm. In practice this might be difficult.
In order to use fairness metrics to detect vulnerability bias in decision-making, knowing the exact set of features that characterise that vulnerability is necessary. The set of features that characterise a protected group is always given, typically defined by law. On the other hand,for many mental health conditions, a clear set of diagnostic features is not available.
Most group fairness metrics assume the existence of a desirable model classification and measure the proportionality of two groups being classified. The de-biasing methods for ML models are a collection of methods that deploy different changes in the decision-making pipeline, which result in enforcing proportionality in desirable and undesirable decisions across two groups. At first glance, such methods could be shoehorned to change the proportion of vulnerable group members vs others that are, for example, targeted with a particular link. But these methods are effective in adjusting small differences and trading off model accuracy for group proportionality. If the overlap between vulnerable people and targeted people is large, current de-biasing methods would not be effective.
Challenges and call to action
We argue that methods for determining whether a model is in fact exploiting vulnerabilities must be developed and integrated in auditory frameworks. In this section, we first address challenges associated with developing such methods in , before pointing to the protections for vulnerable groups in specific regulation in .
Data describing vulnerabilities
In order to apply the model monitoring, model comparison or concept detection approaches described in Examples 2, 3 and 4 respectively, labelled data sets describing vulnerable individuals would have to be created. This immediately poses an ethical challenge: we would have to decide whether collecting and labelling data describing vulnerabilities is unethical, although the purpose is to identify and regulate models that do this. As we regard the creation, storage and use of such data sets as too risky to defend the potential gain, we wish to point out a possible alternative venue of research involving synthetic data. It could be possible to generate synthetic data, based on psychological descriptions of vulnerability traits. Similar venues are currently being explored in the context of medical data, to facilitate training ML models for clinical decision support without having to collect and store medical data, although not without challenges of its own.
Intentionally modelling vulnerability
There are also challenges associated with the creation and use of models trained to identify a state that can constitute a vulnerability, i.e. with the approach described in Example 2 and creating “model $C$”. The development of such models requires diagnostic, meaning sensitive and privacy protected, information about individuals. Hence there are many challenges and professional requirements that need to be met for safe and ethical handling and development of such models.
It has been argued[See for examplefor the discussion regarding ML use in detecting sexual orientation.] that models with such capabilities should not be developed due to the risk of abuse. However, we argue that the existence of models accidentally or covertly having the capabilities of identifying vulnerabilities constitutes a far greater risk of abuse – understanding something is often better than dogmatically banning it. This opens up a discussion on proportionality which is common in privacy law, and outside the scope of this paper. Still, we wish to point out the interesting trade-off that arises as developing type $C$ models helps detect accidental vulnerability modelling, while focusing the attention on difficult questions such as “Who should develop type $C$ models? Who should be trusted with using type $C$ models to test models already deployed? Can type $C$ models be distributed, or does their containing latent features describing vulnerability force us to consider them as containing sensitive information?
We most adamantly do not intend to argue that all platforms using models trained on publicly available behavioural data should also ask their users to provide sensitive data about their mental health status, in order to develop type $C$ models for testing.
Microtargeting and regulation
Theapproaches we describe in section sec-approach require access to the models themselves in addition to labelled data containing vulnerable individuals. Researchers and private initiatives typically do not have access to the commonly used recommender systems nor to the necessary data. Since many of the models that should be tested for vulnerability modelling are proprietary, we cannot require or expect that research groups be given access to these. It is only regulatory and supervisory authorities that can require such access in auditory processes. However, an effective regulatory framework for the protection of vulnerable individuals in AI may be hard to attain. The core problem with establishing and enforcing regulation is articulating the concern: what are the issues that we would like to avoid and where do they occur.
One area in which there is an articulated concern, and some legal protection, for the identification andexploitation of vulnerable states is targeted advertising, or rather its specific digital version called `microtargeting'.
Targeted advertising is advertising directed at an audience with certain characteristics. Although this type of marketing has always existed, the availability of data traces and online advertising has created the option to microtarget audiences and customers. Microtargeting is the practice ofusing data mining and AI techniques to infer personal traits of people and use them to adjust the marketing campaign to those traits. Micro-targetinggives advertisers the ability to exploit recipients’ personal characteristics and potential vulnerabilities.
It is not entirely clear how effective micro-targeting is in persuading individuals. What is clear is that micro-targeting at present is not transparent as to what data it uses to tailor exposure to content. If exploitation of vulnerabilities is happening, there are no mechanisms to detect it and mitigate it.
Online targeted advertisement is subject to data related and regulations in the European Union.identifythe following rules on online targeted advertising:
- the ePrivacy Directive (Directive 2002/58/ED, as amended);
- the GDPR (Regulation (EU) 2016/679, as amended);
- the eCommerce Directive (Directive 2000/31/EC);
- the Unfair Commercial Practices Directive (Directive 2005/29/EC, as amended);
- the Directive on Misleading and Comparative Advertising (Directive 2006/114/EC, as amended);
- the Audiovisual Media Services Directive (Directive (EU) 2018/1808);
- the Consumer Rights Directive (Directive 2011/83/EU, as amended);
- The Digital Markets Act (“DMA”); and
- The Digital Services Act (“DSA”)
Most of these regulations are concerned with obtaining the informed consent from a user for the processing of their data, as well as clearly indicating which legal or natural person has commissioned the advertising. The Audiovisual Media Services Directive prohibits the use of surreptitious or subliminal techniques of advertising when those cannot be readily recognised as such, however, micro-targeting is not considered a surreptitious or subliminal technique.
Most regulations are not explicitly concerned with vulnerable individuals. An exception is the recently agreed Digital Services Act (DSA). Article 63 specifies:
The obligations on assessment and mitigation of risks should trigger, on a case-by-case basis, the need for providers of very large online platforms and of very large online search engines to assess and, where necessary, adjust the design of their recommender systems, for example by taking measures to prevent or minimise biases that lead to the discrimination of persons in vulnerable situations, in particular where this is in conformity with data protection law and when the information is personalised on the basis of special categories of personal data, within the meaning of Article 9 of the Regulation (EU) 2016/679. In addition, and complementing the transparency obligations applicable to online platforms as regards their recommender systems, providers of very large online platforms and of very large online search engines should consistently ensure thatrecipients of their service enjoy alternative options which are not based on profiling, within the meaning of Regulation (EU) 2016/679, for the main parameters of their recommender systems. Such choices should be directly accessible from the interface where the recommendations are presented.
Concern and request for protection for vulnerable recipients occurs twice in the DSA, in both case minors are used as an example of such group of recipients.
Conclusion
In the very same way that specific vulnerabilities can lead to a feeling of being overwhelmed in the affected person, it seems that machine learning engineers, policy makers, and ethics specialists shy away from addressing them in the design and audit of autonomous learning systems. Both conditions need to be ameliorated. We are only now beginning to explore the power of behavioural prediction models and their potential for monetising.
To to protect vulnerable individuals and groups, three essential conditions must be met: i) understanding how vulnerable states can be exploited, ii) detecting when information about vulnerability is being used by an algorithm, iii) and creating social and financial incentives for preventing exploitation of vulnerabilities.
The study of the relationships between individuals’ vulnerabilities and their online behaviours, which may be exploited or monetised, falls within the realm of the behavioural sciences. This research can lead to the development of technology and laws that help prevent exploitation, but it also has the potential to aid exploiters in their efforts. One often proposed solution to this dilemma is to prohibit research that aims to understand such correlational patterns. However, this approach also has drawbacks, as it may prevent the advancement of knowledge and the creation of interventions to help vulnerable individuals.
Around the clock observation can be a privilege in monitoring a condition for those who can afford it (e.g., relapse prediction). It can also be a tool for oppression through surveillance. Combined with modern tools offering cheap and consistent unobtrusive observation, ML can help us understand mental health conditions that we otherwise would not be able to afford. Dishonest actors will always be able to identify exploitable vulnerabilities because complete and outright prohibition of methods whose impact we do not fully understand is not feasible.
We propose several approaches to identifying if an ML model uses information related to vulnerability. It is difficult to evaluate the approaches we propose because data sets to do so are not available. In domains in which we can easily suspect information on vulnerabilities is used, such as targeted advertising, the information is on who is being offered which content is understandably hard to come by. One approach would be to consider proxy domains, such as recommendations of movies or songs and look into who is being recommended what type of entertainment. This is what theinvestigation attempted.We would still be left with the problem of having access to the information of the actual mental state of individuals.This is not information that should be publicly available. This is why iii) is not only needed but necessary.
Advertising is an example of a context in which we can clearly see how vulnerabilities can be monetised and exploited. It is not necessarily the only such example. And even in this context, regulation is hard to agree on and enforce in time. In order to make AI safe and trustworthy, it is imperative that regulators engage in a debate and collaborate with experts in AI ethics, XAI and the behavioural sciences, to understand vulnerabilities and to regulate the domain.
Acknowledgement. The contribution of C.S. was partially funded by a research collaboration with armasuisse (contract: 8203004934) and by an internal University of Bergen grant for visiting researchers.
Bibliography
1@misc{pargent2022,
2 month = {Apr},
3 year = {2022},
4 author = {Pargent, Florian and Schoedel, Ramona and Stachl, Clemens},
5 publisher = {PsyArXiv},
6 doi = {10.31234/osf.io/89snd},
7 url = {psyarxiv.com/89snd},
8 title = {Best Practices in Supervised Machine Learning: A Tutorial for Psychologists},
9}
10
11@article{Saeb2016,
12pages = {e2537},
13month = {Sep},
14year = {2016},
15author = {Saeb, Sohrab and Lattie, Emily G and Schueller, Stephen M and Kording, Konrad P and Mohr, David C},
16journal = {PeerJ},
17doi = {10.7717/peerj.2537},
18issn = {2167/8359},
19volume = {4},
20title = {The relationship between mobile phone location sensor data and depressive symptom severity},
21}
22
23@article{Shneiderman2020,
24pages = {495/504},
25month = {Apr},
26year = {2020},
27author = {Shneiderman, Ben},
28publisher = {Taylor {\&} Francis},
29journal = {International Journal of Human-Computer Interaction},
30number = {6},
31doi = {10.1080/10447318.2020.1741118},
32issn = {1044-7318},
33volume = {36},
34title = {Human-Centered Artificial Intelligence: Reliable, Safe {\&} Trustworthy},
35}
36
37@article{Koch2022,
38pages = {106990},
39month = {Jan},
40year = {2022},
41author = {Koch, Timo and Romero, Peter and Stachl, Clemens},
42publisher = {Pergamon},
43journal = {Computers in Human Behavior},
44doi = {10.1016/j.chb.2021.106990},
45issn = {07475632},
46volume = {126},
47title = {Age and gender in language, emoji, and emoticon usage in instant messages},
48}
49
50@article{Malmi2016,
51language = {en},
52pages = {635/638},
53year = {2016},
54author = {Malmi, Eric and Weber, Ingmar},
55journal = {Proceedings of the International AAAI Conference on Web and Social Media},
56number = {11},
57doi = {10.1609/icwsm.v10i1.14776},
58issn = {2334/0770},
59rights = {Copyright (c) 2021 Proceedings of the International AAAI Conference on Web and Social Media},
60volume = {10},
61title = {You Are What Apps You Use: Demographic Prediction Based on User`s Apps},
62}
63
64@article{Sundsoy2016,
65numpages = {6},
66eprint = {1612.03870},
67eprinttype = {arXiv},
68url = {http://arxiv.org/abs/1612.03870},
69year = {2016},
70volume = {abs/1612.03870},
71journal = {CoRR},
72title = {Estimating individual employment status using mobile phone network
73data},
74author = {P{\aa}l Sunds{\o}y and
75Johannes Bjelland and
76Bj{\o}rn{-}Atle Reme and
77Eaman Jahani and
78Erik Wetter and
79Linus Bengtsson},
80}
81
82@article{Insel2017,
83pages = {1215-1216},
84month = {Oct},
85year = {2017},
86author = {Insel, Thomas R.},
87journal = {JAMA},
88number = {13},
89doi = {10.1001/jama.2017.11295},
90issn = {0098-7484},
91volume = {318},
92title = {Digital Phenotyping: Technology for a New Science of Behavior},
93}
94
95@article{Goerigk2020,
96pages = {153/168},
97year = {2020},
98author = {Goerigk, Stephan and Hilbert, Sven and Jobst, Andrea and Falkai, Peter and B{\"u}hner, Markus and Stachl, Clemens and Bischl, Bernd and Coors, Stefan and Ehring, Thomas and Padberg, Frank and Sarubin, Nina},
99journal = {European Archives of Psychiatry and Clinical Neuroscience},
100number = {2},
101doi = {10.1007/s00406/018/0967/2},
102issn = {14338491},
103volume = {270},
104title = {Predicting instructed simulation and dissimulation when screening for depressive symptoms},
105}
106
107@article{Moshe2021,
108language = {English},
109year = {2021},
110author = {Moshe, Isaac and Terhorst, Yannik and Opoku Asare, Kennedy and Sander, Lasse Bosse and Ferreira, Denzil and Baumeister, Harald and Mohr, David C. and Pulkki-Råback, Laura},
111publisher = {Frontiers},
112journal = {Frontiers in Psychiatry},
113doi = {10.3389/fpsyt.2021.625247},
114url = {https://www.frontiersin.org/articles/10.3389/fpsyt.2021.625247/full},
115issn = {1664-0640},
116volume = {0},
117title = {Predicting Symptoms of Depression and Anxiety Using Smartphone and Wearable Data},
118}
119
120@misc{kim_tcav,
121url = {http://proceedings.mlr.press/v80/kim18d/kim18d.pdf},
122year = {2018},
123author = {Been Kim and Martin Wattenberg and Justin Gilmer and Carrie Jun Cai and James Wexler and Fernanda Viegas and Rory Abbott Sayres},
124title = {Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV)},
125}
126
127@inbook{Klenk2020,
128language = {en},
129collection = {Philosophical Studies Series},
130pages = {81-100},
131year = {2020},
132author = {Klenk, Michael},
133publisher = {Springer International Publishing},
134booktitle = {Ethics of Digital Well-Being: A Multidisciplinary Approach},
135doi = {10.1007/978-3-030-50585-1_4},
136url = {https://doi.org/10.1007/978-3-030-50585-1_4},
137isbn = {978-3-030-50585-1},
138title = {Digital Well-Being and Manipulation Online},
139series = {Philosophical Studies Series},
140address = {Cham},
141}
142
143@incollection{Dsm5,
144address = {Washington DC},
145publisher = {American Psychiatric Association Publishing},
146language = {en},
147year = {2022},
148author = {{American Psychiatric Association}},
149edition = {5},
150doi = {10.1176/appi.books.9780890425787},
151url = {https://doi.org/10.1176/appi.books.9780890425787},
152booktitle = {Diagnostic and statistical manual of mental disorders},
153title = {Major depressive disorder},
154}
155
156@article{alphazero_concepts,
157eprint = {https://www.pnas.org/doi/pdf/10.1073/pnas.2206625119},
158url = {https://www.pnas.org/doi/abs/10.1073/pnas.2206625119},
159doi = {10.1073/pnas.2206625119},
160year = {2022},
161pages = {e2206625119},
162number = {47},
163volume = {119},
164journal = {Proceedings of the National Academy of Sciences},
165title = {Acquisition of chess knowledge in AlphaZero},
166author = {Thomas McGrath and Andrei Kapishnikov and Nenad Tomašev and Adam Pearce and Martin Wattenberg and Demis Hassabis and Been Kim and Ulrich Paquet and Vladimir Kramnik },
167}
168
169@article{Schoedel2020,
170pages = {733-752},
171month = {May},
172year = {2020},
173editor = {Rauthmann, John},
174author = {Schoedel, Ramona and Pargent, Florian and Au, Quay and V{\"o}lkel, Sarah Theres and Schuwerk, Tobias and B{\"u}hner, Markus and Stachl, Clemens},
175publisher = {John Wiley & Sons, Ltd},
176journal = {European Journal of Personality},
177number = {5},
178note = {Citation Key: Schoedel2020},
179doi = {10.1002/per.2258},
180issn = {10990984},
181volume = {34},
182title = {To Challenge the Morning Lark and the Night Owl: Using Smartphone Sensing Data to Investigate Day-Night Behaviour Patterns},
183}
184
185@inproceedings{NIPS2013_words,
186series = {NIPS'13},
187location = {Lake Tahoe, Nevada},
188numpages = {9},
189pages = {3111-3119},
190booktitle = {Proceedings of the 26th International Conference on Neural Information Processing Systems -- Volume 2},
191abstract = {The recently introduced continuous Skip-gram model is an efficient method for learning high-quality distributed vector representations that capture a large number of precise syntactic and semantic word relationships. In this paper we present several extensions that improve both the quality of the vectors and the training speed. By subsampling of the frequent words we obtain significant speedup and also learn more regular word representations. We also describe a simple alternative to the hierarchical softmax called negative sampling.An inherent limitation of word representations is their indifference to word order and their inability to represent idiomatic phrases. For example, the meanings of "Canada" and "Air" cannot be easily combined to obtain "Air Canada". Motivated by this example, we present a simple method for finding phrases in text, and show that learning good vector representations for millions of phrases is possible.},
192address = {Red Hook, NY, USA},
193publisher = {Curran Associates Inc.},
194year = {2013},
195title = {Distributed Representations of Words and Phrases and Their Compositionality},
196author = {Mikolov, Tomas and Sutskever, Ilya and Chen, Kai and Corrado, Greg and Dean, Jeffrey},
197}
198
199@article{Vaerenbergh2013,
200pages = {195-217},
201year = {2013},
202author = {Vaerenbergh, Yves Van and Thomas, Troy D.},
203journal = {International Journal of Public Opinion Research},
204number = {2},
205note = {Citation Key: Vaerenbergh2013},
206doi = {10.1093/ijpor/eds021},
207issn = {0954-2892},
208volume = {25},
209title = {Response styles in survey research: A literature review of antecedents, consequences, and remedies},
210}
211
212@article{Mueller2021,
213language = {en},
214pages = {14007},
215month = {Jul},
216year = {2021},
217author = {M{\"u}ller, Sandrine R. and Chen, Xi (Leslie) and Peters, Heinrich and Chaintreau, Augustin and Matz, Sandra C.},
218publisher = {Nature Publishing Group},
219journal = {Scientific Reports},
220number = {11},
221doi = {10.1038/s41598-021-93087-x},
222issn = {2045-2322},
223rights = {2021 The Author(s)},
224volume = {11},
225title = {Depression predictions from GPS-based mobility do not generalize well to large demographically heterogeneous samples},
226}
227
228@inproceedings{concepts_gans,
229address = {New York, USA},
230publisher = {IEEE},
231doi = {10.1109/ICCV.2017.244},
232pages = {2242-2251},
233number = {},
234volume = {},
235year = {2017},
236title = {Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks},
237booktitle = {2017 IEEE International Conference on Computer Vision (ICCV)},
238author = {Zhu, Jun-Yan and Park, Taesung and Isola, Phillip and Efros, Alexei A.},
239}
240
241@article{Panicheva2022,
242language = {en},
243pages = {1-43},
244month = {Dec},
245year = {2022},
246author = {Panicheva, Polina and Mararitsa, Larisa and Sorokin, Semen and Koltsova, Olessia and Rosso, Paolo},
247publisher = {SpringerOpen},
248journal = {EPJ Data Science},
249number = {11},
250doi = {10.1140/epjds/s13688-022-00333-x},
251issn = {2193-1127},
252rights = {2022 The Author(s)},
253volume = {11},
254title = {Predicting subjective well-being in a high-risk sample of Russian mental health app users},
255}
256
257@inproceedings{Lundberg2017AUA,
258series = {NIPS'17},
259location = {Long Beach, California, USA},
260numpages = {10},
261pages = {4768-4777},
262booktitle = {Proceedings of the 31st International Conference on Neural Information Processing Systems},
263abstract = {Understanding why a model makes a certain prediction can be as crucial as the prediction's accuracy in many applications. However, the highest accuracy for large modern datasets is often achieved by complex models that even experts struggle to interpret, such as ensemble or deep learning models, creating a tension between accuracy and interpretability. In response, various methods have recently been proposed to help users interpret the predictions of complex models, but it is often unclear how these methods are related and when one method is preferable over another. To address this problem, we present a unified framework for interpreting predictions, SHAP (SHapley Additive exPlanations). SHAP assigns each feature an importance value for a particular prediction. Its novel components include: (1) the identification of a new class of additive feature importance measures, and (2) theoretical results showing there is a unique solution in this class with a set of desirable properties. The new class unifies six existing methods, notable because several recent methods in the class lack the proposed desirable properties. Based on insights from this unification, we present new methods that show improved computational performance and/or better consistency with human intuition than previous approaches.},
264address = {Red Hook, NY, USA},
265publisher = {Curran Associates Inc.},
266isbn = {9781510860964},
267year = {2017},
268title = {A Unified Approach to Interpreting Model Predictions},
269author = {Lundberg, Scott M. and Lee, Su-In},
270}
271
272@inproceedings{covert_sage,
273year = {2020},
274volume = {33},
275address = {One Broadway 12th Floor Cambridge, MA 02142},
276url = {https://proceedings.neurips.cc/paper/2020/file/c7bf0b7c1a86d5eb3be2c722cf2cf746-Paper.pdf},
277title = {Understanding Global Feature Contributions With Additive Importance Measures},
278publisher = {Curran Associates, Inc.},
279pages = {17212--17223},
280editor = {H. Larochelle and M. Ranzato and R. Hadsell and M.F. Balcan and H. Lin},
281booktitle = {Advances in Neural Information Processing Systems},
282author = {Covert, Ian and Lundberg, Scott M and Lee, Su-In},
283}
284
285@article{Allport1942,
286pages = {71},
287year = {1942},
288author = {Allport, Gordon Willard},
289journal = {Marriage and Family Living},
290number = {3},
291volume = {4},
292title = {The use of personal documents in psychological science.},
293}
294
295@article{Stachl2021PS,
296pages = {1-22},
297month = {Jul},
298year = {2021},
299author = {Stachl, Clemens and Boyd, Ryan L. and Horstmann, Kai T. and Khambatta, Poruz and Matz, Sandra C. and Harari, Gabriella M.},
300journal = {Personality Science},
301doi = {10.5964/PS.6115},
302issn = {2700-0710},
303volume = {2},
304title = {Computational Personality Assessment},
305}
306
307@misc{Rauber2019,
308copyright = {arXiv.org perpetual, non-exclusive license},
309year = {2019},
310publisher = {arXiv},
311title = {Modeling patterns of smartphone usage and their relationship to cognitive health},
312keywords = {Machine Learning (cs.LG), Human-Computer Interaction (cs.HC), Machine Learning (stat.ML), FOS: Computer and information sciences, FOS: Computer and information sciences},
313author = {Rauber, Jonas and Fox, Emily B. and Gatys, Leon A.},
314url = {https://arxiv.org/abs/1911.05683},
315doi = {10.48550/ARXIV.1911.05683},
316}
317
318@inproceedings{lime,
319series = {KDD '16},
320location = {San Francisco, California, USA},
321keywords = {explaining machine learning, interpretable machine learning, black box classifier, interpretability},
322numpages = {10},
323pages = {1135-1144},
324booktitle = {Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining},
325doi = {10.1145/2939672.2939778},
326url = {https://doi.org/10.1145/2939672.2939778},
327address = {New York, NY, USA},
328publisher = {Association for Computing Machinery},
329isbn = {9781450342322},
330year = {2016},
331title = {"Why Should I Trust You?": Explaining the Predictions of Any Classifier},
332author = {Ribeiro, Marco Tulio and Singh, Sameer and Guestrin, Carlos},
333}
334
335@inproceedings{Gordon2019,
336pages = {1-12},
337month = {May},
338year = {2019},
339author = {Gordon, Mitchell L. and Garys, Leon and Guestrin, Carlos and Bigham, Jeffrey P. and Trister, Andrew and Patel, Kayur},
340publisher = {Association for Computing Machinery},
341booktitle = {Conference on Human Factors in Computing Systems - Proceedings},
342doi = {10.1145/3290605.3300398},
343url = {http://dl.acm.org/citation.cfm?doid=3290605.3300398},
344isbn = {978-1-4503-5970-2},
345title = {App usage predicts cognitive ability in older adults},
346address = {New York, New York, USA},
347}
348
349@article{Israel2020,
350pages = {1-19},
351month = {Aug},
352year = {2020},
353volume = {53},
354author = {Israel, Laura S. F. and Sch{\"o}nbrodt, Felix D.},
355publisher = {Springer},
356journal = {Behavior Research Methods},
357doi = {10.3758/s13428-020-01435-y},
358issn = {1554-3528},
359title = {Predicting affective appraisals from facial expressions and physiology using machine learning},
360}
361
362@article{Liu2022,
363pages = {7-14},
364month = {Apr},
365year = {2022},
366author = {Liu, Tony and Meyerhoff, Jonah and Eichstaedt, Johannes C. and Karr, Chris J. and Kaiser, Susan M. and Kording, Konrad P. and Mohr, David C. and Ungar, Lyle H.},
367publisher = {Elsevier},
368journal = {Journal of Affective Disorders},
369doi = {10.1016/J.JAD.2021.12.048},
370issn = {0165-0327},
371volume = {302},
372title = {The relationship between text message sentiment and self-reported depression},
373}
374
375@article{Stachl2020PNAS,
376abstract = {Smartphones enjoy high adoption rates around the globe. Rarely more than an arm’s length away, these sensor-rich devices can easily be repurposed to collect rich and extensive records of their users’ behaviors (e.g., location, communication, media consumption), posing serious threats to individual privacy. Here we examine the extent to which individuals’ Big Five personality dimensions can be predicted on the basis of six different classes of behavioral information collected via sensor and log data harvested from smartphones. Taking a machine-learning approach, we predict personality at broad domain (rmedian = 0.37) and narrow facet levels (rmedian = 0.40) based on behavioral data collected from 624 volunteers over 30 consecutive days (25,347,089 logging events). Our cross-validated results reveal that specific patterns in behaviors in the domains of 1) communication and social behavior, 2) music consumption, 3) app usage, 4) mobility, 5) overall phone activity, and 6) day- and night-time activity are distinctively predictive of the Big Five personality traits. The accuracy of these predictions is similar to that found for predictions based on digital footprints from social media platforms and demonstrates the possibility of obtaining information about individuals’ private traits from behavioral patterns passively collected from their smartphones. Overall, our results point to both the benefits (e.g., in research settings) and dangers (e.g., privacy implications, psychological targeting) presented by the widespread collection and modeling of behavioral data obtained from smartphones.},
377eprint = {https://www.pnas.org/doi/pdf/10.1073/pnas.1920484117},
378url = {https://www.pnas.org/doi/abs/10.1073/pnas.1920484117},
379doi = {10.1073/pnas.1920484117},
380year = {2020},
381pages = {17680-17687},
382number = {30},
383volume = {117},
384journal = {Proceedings of the National Academy of Sciences},
385title = {Predicting personality from patterns of behavior collected with smartphones},
386author = {Clemens Stachl and Quay Au and Ramona Schoedel and Samuel D. Gosling and Gabriella M. Harari and Daniel Buschek and Sarah Theres V{\"o}lkel and Tobias Schuwerk and Michelle Oldemeier and Theresa Ullmann and Heinrich Hussmann and Bernd Bischl and Markus B{\"u}hner },
387}
388
389@article{Azucar2018,
390pages = {150-159},
391month = {Apr},
392year = {2018},
393author = {Azucar, Danny and Marengo, Davide and Settanni, Michele},
394publisher = {Pergamon},
395doi = {10.1016/j.paid.2017.12.018},
396issn = {01918869},
397journal = {Personality and Individual Differences},
398volume = {124},
399title = {Predicting the Big 5 personality traits from digital footprints on social media: A meta-analysis},
400}
401
402@misc{lexico,
403note = {[Online; accessed 18-January-2018]},
404howpublished = {\url{https://en.oxforddictionaries.com/definition/vulnerability}},
405year = {2018},
406author = {{Oxford University Press}},
407title = {English Oxford Living Dictionaries},
408}
409
410@misc{medium_stereotypes,
411note = {[Online; accessed 01-January-2022]},
412year = {2022},
413howpublished = {\url{https://medium.com/@blaisea/do-algorithms-reveal-sexual-orientation-or-just-expose-our-stereotypes-d998fafdf477}},
414title = {Do algorithms reveal sexual orientation or just expose our stereotypes?},
415author = {Ag{\"u}era y Arcas, Blaise and Todorov, Alexander and Mitchell, Margaret},
416}
417
418@misc{who_depression,
419accessed = {14 December 2021},
420url = {http://ghdx.healthdata.org/gbd-results-tool?params=gbd-api-2019-permalink/d780dffbe8a381b25e1416884959e88b},
421institution = {Global Health Data Exchange (GHDx)},
422author = {{Institute of Health Metrics and Evaluation}},
423}
424
425@inproceedings{abbasi2019fairness,
426organization = {SIAM},
427year = {2019},
428pages = {801-809},
429booktitle = {Proceedings of the 2019 SIAM International Conference on Data Mining},
430author = {Abbasi, Mohsen and Friedler, Sorelle A and Scheidegger, Carlos and Venkatasubramanian, Suresh},
431title = {Fairness in representation: quantifying stereotyping as a representational harm},
432}
433
434@incollection{martin1990mental,
435address = {U.S.A},
436publisher = {Butterworth Publishers},
437year = {1990},
438edition = {3},
439booktitle = {Clinical Methods: The History, Physical, and Laboratory Examinations},
440author = {Martin, David C},
441title = {The mental status examination},
442}
443
444@article{facebook_depression2018,
445journal = {Proceedings of the National Academy of Sciences},
446eprint = {https://www.pnas.org/content/115/44/11203.full.pdf},
447url = {https://www.pnas.org/content/115/44/11203},
448issn = {0027-8424},
449publisher = {National Academy of Sciences},
450doi = {10.1073/pnas.1802331115},
451year = {2018},
452pages = {11203-11208},
453number = {44},
454volume = {115},
455title = {Facebook language predicts depression in medical records},
456author = {Eichstaedt, Johannes C. and Smith, Robert J. and Merchant, Raina M. and Ungar, Lyle H. and Crutchley, Patrick and Preo{\c t}iuc-Pietro, Daniel and Asch, David A. and Schwartz, H. Andrew},
457}
458
459@article{thorstad2019predicting,
460publisher = {Springer},
461year = {2019},
462pages = {1586-1600},
463number = {4},
464volume = {51},
465journal = {Behavior research methods},
466author = {Thorstad, Robert and Wolff, Phillip},
467title = {Predicting future mental illness from social media: A big-data approach},
468}
469
470@inproceedings{schwartz2014towards,
471pages = {118--125},
472doi = {10.3115/v1/W14-3214},
473url = {https://aclanthology.org/W14-3214},
474publisher = {Association for Computational Linguistics},
475address = {Baltimore, Maryland, USA},
476year = {2014},
477month = {June},
478booktitle = {Proceedings of the Workshop on Computational Linguistics and Clinical Psychology: From Linguistic Signal to Clinical Reality},
479author = {Schwartz, H. Andrew and
480Eichstaedt, Johannes and
481Kern, Margaret L. and
482Park, Gregory and
483Sap, Maarten and
484Stillwell, David and
485Kosinski, Michal and
486Ungar, Lyle},
487title = {Towards Assessing Changes in Degree of Depression through {F}acebook},
488}
489
490@article{inkster2016decade,
491publisher = {Elsevier},
492year = {2016},
493pages = {1087-1090},
494number = {11},
495volume = {3},
496journal = {The Lancet Psychiatry},
497author = {Inkster, Becky and Stillwell, David and Kosinski, Michal and Jones, Peter},
498title = {A decade into Facebook: where is psychiatry in the digital age?},
499}
500
501@inbook{mental_health_some2019,
502numpages = {16},
503pages = {1-16},
504booktitle = {Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems},
505url = {https://doi.org/10.1145/3290605.3300364},
506address = {New York, NY, USA},
507publisher = {Association for Computing Machinery},
508isbn = {9781450359702},
509year = {2019},
510title = {Methodological Gaps in Predicting Mental Health States from Social Media: Triangulating Diagnostic Signals},
511author = {Ernala, Sindhu Kiranmai and Birnbaum, Michael L. and Candan, Kristin A. and Rizvi, Asra F. and Sterling, William A. and Kane, John M. and De Choudhury, Munmun},
512}
513
514@article{tadesse2019detection,
515publisher = {IEEE},
516year = {2019},
517pages = {44883-44893},
518volume = {7},
519journal = {IEEE Access},
520author = {Tadesse, Michael M and Lin, Hongfei and Xu, Bo and Yang, Liang},
521title = {Detection of depression-related posts in reddit social media forum},
522}
523
524@inproceedings{cohan-etal-2018-smhd,
525pages = {1485-1497},
526url = {https://aclanthology.org/C18-1126},
527publisher = {Association for Computational Linguistics},
528address = {Santa Fe, New Mexico, USA},
529year = {2018},
530month = {August},
531booktitle = {Proceedings of the 27th International Conference on Computational Linguistics},
532author = {Cohan, Arman and
533Desmet, Bart and
534Yates, Andrew and
535Soldaini, Luca and
536MacAvaney, Sean and
537Goharian, Nazli},
538title = {{SMHD}: a Large-Scale Resource for Exploring Online Language Usage for Multiple Mental Health Conditions},
539}
540
541@inproceedings{Yates2017DepressionAS,
542abstract = {Users suffering from mental health conditions often turn to online resources for support, including specialized online support communities or general communities such as Twitter and Reddit. In this work, we present a framework for supporting and studying users in both types of communities. We propose methods for identifying posts in support communities that may indicate a risk of self-harm, and demonstrate that our approach outperforms strong previously proposed methods for identifying such posts. Self-harm is closely related to depression, which makes identifying depressed users on general forums a crucial related task. We introduce a large-scale general forum dataset consisting of users with self-reported depression diagnoses matched with control users. We show how our method can be applied to effectively identify depressed users from their use of language alone. We demonstrate that our method outperforms strong baselines on this general forum dataset.},
543pages = {2968--2978},
544doi = {10.18653/v1/D17-1322},
545url = {https://aclanthology.org/D17-1322},
546publisher = {Association for Computational Linguistics},
547address = {Copenhagen, Denmark},
548year = {2017},
549month = {September},
550booktitle = {Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing},
551author = {Yates, Andrew and
552Cohan, Arman and
553Goharian, Nazli},
554title = {Depression and Self-Harm Risk Assessment in Online Forums},
555}
556
557@article{oxman1982language,
558pages = {88-97},
559number = {3},
560volume = {131},
561publisher = {American Psychiatric Assn},
562year = {1982},
563journal = {The American journal of psychiatry},
564author = {Oxman, Thomas E and Rosenberg, Stanley D and Tucker, Gary J},
565title = {The language of paranoia},
566}
567
568@inproceedings{ramiirez2018upf,
569address = {online},
570publisher = {CEUR Workshop Proceedings},
571year = {2018},
572pages = {1-12},
573booktitle = {Cappellato L, Ferro N, Nie JY, Soulier L, editors. Working Notes of CLEF 2018-Conference and Labs of the Evaluation Forum; 2018 Sep 10-14; Avignon, France.[Avignon]: CEUR Workshop Proceedings},
574author = {Ram{\'\i}{\i}rez-Cifuentes, Diana and Freire, Ana},
575title = {UPF's Participation at the CLEF eRisk 2018: Early Risk Prediction on the Internet},
576}
577
578@inproceedings{coppersmith2014quantifying,
579year = {2014},
580address = {Baltimore, Maryland, USA},
581publisher = {Association for Computational Linguistics},
582pages = {51-60},
583booktitle = {Proceedings of the workshop on computational linguistics and clinical psychology: From linguistic signal to clinical reality},
584author = {Coppersmith, Glen and Dredze, Mark and Harman, Craig},
585title = {Quantifying mental health signals in Twitter},
586}
587
588@misc{facebook_suicide_prevention,
589url = {http://newsroom.fb.com/news/2017/03/building-a-safer-community-with-new-suicide-prevention-tools/},
590title = {Building a safer community with new suicide prevention tools},
591publisher = {Facebook},
592year = {2017},
593author = {Callison-Burch, Vanessa and Guadagno, Jennifer and Davis Antigone},
594}
595
596@article{aboureihanimohammadi2020identification,
597year = {2020},
598pages = {1--12},
599number = {4},
600volume = {7},
601journal = {Journal of Cognitive Psychology},
602author = {Aboureihani Mohammadi, M and Fadaei Moghadam Heydarabadi, M and Zardary, S and Heysieattalab, S},
603title = {Identification Psychological Disorders Based on Data in Virtual Environments Using Machine Learning},
604}
605
606@article{arabic_depression2020,
607doi = {10.1109/ACCESS.2020.2981834},
608pages = {57317-57334},
609number = {},
610volume = {8},
611year = {2020},
612title = {Predicting Depression Symptoms in an Arabic Psychological Forum},
613journal = {IEEE Access},
614author = {Alghamdi, Norah Saleh and Hosni Mahmoud, Hanan A. and Abraham, Ajith and Alanazi, Samar Awadh and García-Hernández, Laura},
615}
616
617@article{de2013predicting,
618pages = {128-137},
619month = {Aug.},
620year = {2021},
621author = {De Choudhury, Munmun and Gamon, Michael and Counts, Scott and Horvitz, Eric},
622journal = {Proceedings of the International AAAI Conference on Web and Social Media},
623number = {1},
624abstractnote = { <p> Major depression constitutes a serious challenge in personal and public health. Tens of millions of people each year suffer from depression and only a fraction receives adequate treatment. We explore the potential to use social media to detect and diagnose major depressive disorder in individuals. We first employ crowdsourcing to compile a set of Twitter users who report being diagnosed with clinical depression, based on a standard psychometric instrument. Through their social media postings over a year preceding the onset of depression, we measure behavioral attributes relating to social engagement, emotion, language and linguistic styles, ego network, and mentions of antidepressant medications. We leverage these behavioral cues, to build a statistical classifier that provides estimates of the risk of depression, before the reported onset. We find that social media contains useful signals for characterizing the onset of depression in individuals, as measured through decrease in social activity, raised negative affect, highly clustered egonetworks, heightened relational and medicinal concerns, and greater expression of religious involvement. We believe our findings and methods may be useful in developing tools for identifying the onset of major depression, for use by healthcare agencies; or on behalf of individuals, enabling those suffering from depression to be more proactive about their mental health.},
625doi = {10.1609/icwsm.v7i1.14432},
626url = {https://ojs.aaai.org/index.php/ICWSM/article/view/14432},
627volume = {7},
628title = {Predicting Depression via Social Media},
629}
630
631@inproceedings{orabi2018deep,
632abstract = {Mental illness detection in social media can be considered a complex task, mainly due to the complicated nature of mental disorders. In recent years, this research area has started to evolve with the continuous increase in popularity of social media platforms that became an integral part of people{'}s life. This close relationship between social media platforms and their users has made these platforms to reflect the users{'} personal life with different limitations. In such an environment, researchers are presented with a wealth of information regarding one{'}s life. In addition to the level of complexity in identifying mental illnesses through social media platforms, adopting supervised machine learning approaches such as deep neural networks have not been widely accepted due to the difficulties in obtaining sufficient amounts of annotated training data. Due to these reasons, we try to identify the most effective deep neural network architecture among a few of selected architectures that were successfully used in natural language processing tasks. The chosen architectures are used to detect users with signs of mental illnesses (depression in our case) given limited unstructured text data extracted from the Twitter social media platform.},
633pages = {88--97},
634doi = {10.18653/v1/W18-0609},
635url = {https://aclanthology.org/W18-0609},
636publisher = {Association for Computational Linguistics},
637address = {New Orleans, LA},
638year = {2018},
639month = {June},
640booktitle = {Proceedings of the Fifth Workshop on Computational Linguistics and Clinical Psychology: From Keyboard to Clinic},
641author = {Husseini Orabi, Ahmed and
642Buddhitha, Prasadith and
643Husseini Orabi, Mahmoud and
644Inkpen, Diana},
645title = {Deep Learning for Depression Detection of {T}witter Users},
646}
647
648@article{lejoyeux2002impulse,
649publisher = {LWW},
650year = {2002},
651pages = {310-314},
652number = {5},
653volume = {190},
654journal = {The Journal of nervous and mental disease},
655author = {Lejoyeux, Michel and Arbaretaz, Marie and McLOUGHLIN, MARY and Ad{\`e}s, Jean},
656title = {Impulse control disorders and depression},
657}
658
659@article{Kramer8788,
660journal = {Proceedings of the National Academy of Sciences},
661eprint = {https://www.pnas.org/content/111/24/8788.full.pdf},
662url = {https://www.pnas.org/content/111/24/8788},
663issn = {0027-8424},
664publisher = {National Academy of Sciences},
665doi = {10.1073/pnas.1320040111},
666year = {2014},
667pages = {8788-8790},
668number = {24},
669volume = {111},
670title = {Experimental evidence of massive-scale emotional contagion through social networks},
671author = {Kramer, Adam D. I. and Guillory, Jamie E. and Hancock, Jeffrey T.},
672}
673
674@article{lejoyeux1997study,
675publisher = {[Memphis, Tenn., Physicians Postgraduate Press]},
676year = {1997},
677pages = {169-173},
678number = {4},
679volume = {58},
680journal = {Journal of Clinical Psychiatry},
681author = {Lejoyeux, Michel and Tassain, Valerie and Solomon, Jacquelyn and Ades, Jean},
682title = {Study of compulsive buying in depressed patients},
683}
684
685@article{mcelroy1996impulse,
686publisher = {Elsevier},
687year = {1996},
688pages = {229-240},
689number = {4},
690volume = {37},
691journal = {Comprehensive psychiatry},
692author = {McElroy, Susan L and Pope Jr, Harrison G and Keck Jr, Paul E and Hudson, James I and Phillips, Katharine A and Strakowski, Stephen M},
693title = {Are impulse-control disorders related to bipolar disorder?},
694}
695
696@article{yasuhisa2001,
697doi = {10.1111/1468-5884.00179},
698journal = {Japanese Psychological Research},
699volume = {43},
700title = {Shopping as a coping behavior for stress},
701pages = {},
702month = {11},
703year = {2001},
704author = {Hama, Yasuhisa},
705}
706
707@misc{arstechnica_teens2017,
708year = {2017},
709author = {ArsTechnica},
710url = {https://arstechnica.com/information-technology/2017/05/facebook-helped-advertisers-target-teens-who-feel-worthless/},
711title = {Report: Facebook helped advertisers target teens who feel ``worthless''},
712}
713
714@article{Bell1985,
715eprint = {https://doi.org/10.1057/jors.1985.106},
716url = {https://doi.org/10.1057/jors.1985.106},
717doi = {10.1057/jors.1985.106},
718publisher = {Taylor & Francis},
719year = {1985},
720pages = {613-619},
721number = {7},
722volume = {36},
723journal = {Journal of the Operational Research Society},
724title = {Why Expert Systems Fail},
725author = {Michael Z. Bell},
726}
727
728@article{Barredo2020,
729author = {Alejandro {Barredo Arrieta} et.\ al.},
730url = {https://www.sciencedirect.com/science/article/pii/S1566253519308103},
731doi = {https://doi.org/10.1016/j.inffus.2019.12.012},
732issn = {1566-2535},
733year = {2020},
734pages = {82-115},
735volume = {58},
736journal = {Information Fusion},
737title = {Explainable Artificial Intelligence ({XAI}): Concepts, taxonomies, opportunities and challenges toward responsible {AI}},
738}
739
740@article{computer_ethics,
741doi = {10.1111/j.1467-9973.1985.tb00173.x},
742journal = {Metaphilosophy},
743volume = {16},
744title = {What Is Computer Ethics?},
745pages = {266-275},
746month = {08},
747year = {2007},
748author = {Moor, James},
749}
750
751@inproceedings{ethics_by_design,
752series = {AIES '18},
753location = {New Orleans, LA, USA},
754keywords = {machine ethics, multi-agent systems, ethics by design},
755numpages = {7},
756pages = {60-66},
757booktitle = {Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society},
758doi = {10.1145/3278721.3278745},
759url = {https://doi.org/10.1145/3278721.3278745},
760address = {New York, NY, USA},
761publisher = {Association for Computing Machinery},
762isbn = {9781450360128},
763year = {2018},
764title = {Ethics by Design: Necessity or Curse?},
765author = {Dignum, Virginia and Baldoni, Matteo and Baroglio, Cristina and Caon, Maurizio and Chatila, Raja and Dennis, Louise and G\'{e}nova, Gonzalo and Haim, Galit and Klie\ss{}, Malte S. and Lopez-Sanchez, Maite and Micalizio, Roberto and Pav\'{o}n, Juan and Slavkovik, Marija and Smakman, Matthijs and van Steenbergen, Marlies and Tedeschi, Stefano and van der Toree, Leon and Villata, Serena and de Wildt, Tristan},
766}
767
768@article{principles_alone,
769doi = {10.1038/s42256-019-0114-4},
770journal = {Nature Machine Intelligence},
771volume = {1},
772title = {Principles alone cannot guarantee ethical AI},
773pages = {},
774month = {11},
775year = {2019},
776author = {Mittelstadt, Brent},
777}
778
779@article{aiethics_landscape,
780doi = {10.1038/s42256-019-0088-2},
781journal = {Nature Machine Intelligence},
782volume = {1},
783title = {The global landscape of AI ethics guidelines},
784pages = {},
785month = {09},
786year = {2019},
787author = {Jobin, Anna and Ienca, Marcello and Vayena, Effy},
788}
789
790@article{ethics_of_aiethics,
791pages = {99-120},
792month = {Feb},
793year = {2020},
794author = {Hagendorff, Thilo},
795publisher = {Springer Science and Business Media LLC},
796journal = {Minds and Machines},
797number = {1},
798doi = {10.1007/s11023-020-09517-8},
799url = {dx.doi.org/10.1007/s11023-020-09517-8},
800issn = {1572-8641},
801volume = {30},
802title = {The Ethics of AI Ethics: An Evaluation of Guidelines},
803}
804
805@inproceedings{aiethics_policy,
806series = {AIES '20},
807location = {New York, NY, USA},
808numpages = {6},
809pages = {153-158},
810booktitle = {Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society},
811doi = {10.1145/3375627.3375804},
812url = {https://doi.org/10.1145/3375627.3375804},
813address = {New York, NY, USA},
814publisher = {Association for Computing Machinery},
815isbn = {9781450371100},
816year = {2020},
817title = {What's Next for AI Ethics, Policy, and Governance? A Global Overview},
818author = {Schiff, Daniel and Biddle, Justin and Borenstein, Jason and Laas, Kelly},
819}
820
821@inbook{social_dilemma1,
822doi = {10.1057/9780230377769_13},
823isbn = {978-1-349-39988-8},
824title = {Social Dilemmas},
825pages = {254-272},
826month = {01},
827year = {1998},
828author = {Rapoport, Anatol},
829}
830
831@article{social_dilemma2,
832pages = {183-214},
833volume = {24},
834year = {1998},
835journal = {Review of Sociology},
836author = {P. Kollock},
837title = {Social Dilemmas: The Anatomy of Cooperation},
838}
839
840@article{frankel_professional_1989,
841pages = {109-115},
842note = {ZSCC: 0000551},
843year = {1989},
844author = {Frankel, Mark S.},
845journal = {Journal of Business Ethics},
846number = {2-3},
847language = {en},
848doi = {10.1007/BF00382575},
849url = {http://link.springer.com/10.1007/BF00382575},
850shorttitle = {Professional codes},
851issn = {0167-4544, 1573-0697},
852volume = {8},
853title = {Professional codes: {Why}, how, and with what impact?},
854}
855
856@book{camenisch_grounding_1983,
857annote = {Name index: p. 150},
858keywords = {Ethics},
859note = {ZSCC: 0000096},
860year = {1983},
861author = {Camenisch, Paul F.},
862publisher = {Haven Publications},
863isbn = {978-0-930586-11-9},
864title = {Grounding professional ethics in a pluralistic society},
865address = {New York, N.Y},
866}
867
868@book{pavalko_sociology_1988,
869year = {1988},
870collaborator = {{Internet Archive}},
871author = {Pavalko, Ronald M.},
872publisher = {Itasca, Ill. : F.E. Peacock},
873urldate = {2021-03-22},
874language = {eng},
875url = {http://archive.org/details/sociologyofoccup00pava},
876isbn = {978-0-87581-324-0},
877title = {Sociology of occupations and professions},
878}
879
880@inproceedings{Wieringa2020,
881series = {FAT\* '20},
882location = {Barcelona, Spain},
883keywords = {accountability theory, algorithmic accountability, data-driven governance, algorithmic systems},
884numpages = {18},
885pages = {1-18},
886booktitle = {Proceedings of the },
887address = {New York, NY, USA},
888publisher = {ACM},
889isbn = {9781450369367},
890year = {2020},
891title = {What to Account for When Accounting for Algorithms: A Systematic Literature Review on Algorithmic Accountability},
892author = {Wieringa, Maranke},
893}
894
895@article{Moor:2006,
896bdsk-url-1 = {http://dx.doi.org/10.1109/MIS.2006.80},
897year = {2006},
898volume = {21},
899url = {http://dx.doi.org/10.1109/MIS.2006.80},
900title = {The Nature, Importance, and Difficulty of Machine Ethics},
901publisher = {IEEE Educational Activities Department},
902pages = {18-21},
903numpages = {4},
904number = {4},
905month = {July},
906keywords = {computer ethics, ethical agents, machine ethics, machine ethics, computer ethics, ethical agents},
907journal = {IEEE Intelligent Systems},
908issn = {1541-1672},
909doi = {10.1109/MIS.2006.80},
910date-modified = {2020-08-03 12:34:22 +0200},
911date-added = {2020-08-03 12:34:22 +0200},
912author = {Moor, J. H.},
913address = {Piscataway, NJ, USA},
914acmid = {1159006},
915}
916
917@article{Bovens2007,
918year = {2007},
919eprint = {https://onlinelibrary.wiley.com/doi/pdf/10.1111/j.1468-0386.2007.00378.x},
920url = {https://onlinelibrary.wiley.com/doi/abs/10.1111/j.1468-0386.2007.00378.x},
921doi = {10.1111/j.1468-0386.2007.00378.x},
922pages = {447-468},
923number = {4},
924volume = {13},
925journal = {European Law Journal},
926title = {Analysing and Assessing Accountability: A Conceptual Framework1},
927author = {Bovens, Mark},
928}
929
930@incollection{lundberg2017,
931url = {https://papers.nips.cc/paper/7062-a-unified-approach-to-interpreting-model-predictions},
932publisher = {Curran Associates, Inc.},
933year = {2017},
934pages = {4765-4774},
935editor = {I. Guyon and U. V. Luxburg and S. Bengio and H. Wallach and R. Fergus and S. Vishwanathan and R. Garnett},
936booktitle = {Advances in Neural Information Processing Systems 30},
937author = {Lundberg, Scott M and Lee, Su-In},
938title = {{A Unified Approach to Interpreting Model Predictions}},
939}
940
941@article{ieee_ethical,
942url = {https://www.techstreet.com/ieee/searches/32889743},
943doi = {},
944month = {9},
945year = {2021},
946title = {IEEE Standard Model Process for Addressing Ethical Concerns during System Design},
947journal = {IEEE 7000-2021},
948author = {},
949}
950
951@misc{leslie_david_2019,
952url = {https://doi.org/10.5281/zenodo.3240529},
953doi = {10.5281/zenodo.3240529},
954publisher = {Zenodo},
955year = {2019},
956month = {June},
957title = {{Understanding artificial intelligence ethics and
958safety: A guide for the responsible design and
959implementation of AI systems in the public sector}},
960author = {Leslie, David},
961}
962
963@inproceedings{gilpin_2018,
964doi = {10.1109/DSAA.2018.00018},
965pages = {80-89},
966number = {},
967volume = {},
968year = {2018},
969title = {Explaining Explanations: An Overview of Interpretability of Machine Learning},
970booktitle = {2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA)},
971author = {Gilpin, Leilani H. and Bau, David and Yuan, Ben Z. and Bajwa, Ayesha and Specter, Michael and Kagal, Lalana},
972}
973
974@book{Bromberger1993,
975year = {1993},
976author = {Sylvain Bromberger},
977title = {On What We Know We Don't Know: Explanation, Theory, Linguistics, and How Questions Shape Them},
978}
979
980@article{miller2019,
981keywords = {Explanation, Explainability, Interpretability, Explainable AI, Transparency},
982author = {Tim Miller},
983url = {https://www.sciencedirect.com/science/article/pii/S0004370218305988},
984doi = {https://doi.org/10.1016/j.artint.2018.07.007},
985issn = {0004-3702},
986year = {2019},
987pages = {1-38},
988volume = {267},
989journal = {Artificial Intelligence},
990title = {Explanation in artificial intelligence: Insights from the social sciences},
991}
992
993@misc{mill1843liberty,
994publisher = {London UK: Longmans, Green,},
995year = {1843},
996author = {Mill, John Stuart},
997title = {Of Liberty and Necessity, Ch. II, Book VI. A System of Logic},
998}
999
1000@book{josephson1996,
1001publisher = {Cambridge University Press},
1002year = {1996},
1003author = {Josephson, John R and Josephson, Susan G},
1004title = {Abductive inference: Computation, philosophy, technology},
1005}
1006
1007@article{wongkoblap2017researching,
1008publisher = {JMIR Publications Inc., Toronto, Canada},
1009year = {2017},
1010pages = {228},
1011number = {6},
1012volume = {19},
1013journal = {Journal of medical Internet research},
1014author = {Wongkoblap, Akkapon and Vadillo, Miguel A and Curcin, Vasa},
1015title = {Researching mental health disorders in the era of social media: systematic review},
1016}
1017
1018@article{Schwartz2016PredictingIW,
1019pages = {516-27},
1020volume = {21},
1021year = {2016},
1022journal = {Pacific Symposium on Biocomputing. Pacific Symposium on Biocomputing},
1023author = {H. A. Schwartz and Maarten Sap and Margaret L. Kern and Johannes C. Eichstaedt and Adam Kapelner and Megha Agrawal and Eduardo Blanco and Lukasz Dziurzynski and Gregory J. Park and David Stillwell and Michal Kosinski and Martin E. P. Seligman and Lyle H. Ungar},
1024title = {Predicting Individual Well-Being Through the Language of Social Media},
1025}
1026
1027@incollection{Lewis1986,
1028title = {Causal Explanation},
1029author = {David K. Lewis},
1030editor = {David Lewis},
1031year = {1986},
1032pages = {214-240},
1033booktitle = {Philosophical Papers Vol. Ii},
1034publisher = {Oxford University Press},
1035}
1036
1037@article{bdcc5020020,
1038doi = {10.3390/bdcc5020020},
1039issn = {2504-2289},
1040url = {https://www.mdpi.com/2504-2289/5/2/20},
1041article-number = {20},
1042number = {2},
1043year = {2021},
1044volume = {5},
1045journal = {Big Data and Cognitive Computing},
1046title = {Traceability for Trustworthy AI: A Review of Models and Tools},
1047author = {Mora-Cantallops, Mar{\c{}}al and S{\'a}nchez-Alonso, Salvador and Garc{\'i}a-Barriocanal, Elena and Sicilia, Miguel-Angel},
1048}
1049
1050@article{10.3389/frobt.2021.665729,
1051issn = {2296-9144},
1052doi = {10.3389/frobt.2021.665729},
1053url = {https://www.frontiersin.org/article/10.3389/frobt.2021.665729},
1054year = {2021},
1055pages = {225},
1056volume = {8},
1057journal = {Frontiers in Robotics and AI},
1058title = {IEEE P7001: A Proposed Standard on Transparency},
1059author = {Winfield, Alan F. T. and Booth, Serena and Dennis, Louise A. and Egawa, Takashi and Hastie, Helen and Jacobs, Naomi and Muttram, Roderick I. and Olszewska, Joanna I. and Rajabiyazdi, Fahimeh and Theodorou, Andreas and Underwood, Mark A. and Wortham, Robert H. and Watson, Eleanor},
1060}
1061
1062@article{Floridi2019Unified,
1063day = {1},
1064month = {7},
1065year = {2019},
1066date = {2019-07-01},
1067author = {Floridi, Luciano and Cowls, Josh},
1068volume = {1},
1069url = {https://hdsr.mitpress.mit.edu/pub/l0jsh9d1},
1070title = {A Unified Framework of Five Principles for AI in Society},
1071publisher = {},
1072note = {https://hdsr.mitpress.mit.edu/pub/l0jsh9d1},
1073number = {1},
1074doi = {10.1162/99608f92.8cd550d1},
1075journal = {Harvard Data Science Review},
1076}
1077
1078@techreport{EU2019,
1079url = {
1080https://digital-strategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai},
1081year = {2019},
1082title = {ETHICS GUIDELINES
1083FOR TRUSTWORTHY AI},
1084author = {High-Level Expert Group on Artificial Intelligence},
1085}
1086
1087@misc{cyras2020,
1088primaryclass = {cs.AI},
1089archiveprefix = {arXiv},
1090eprint = {2009.00418},
1091year = {2020},
1092author = {Kristijonas Cyras and Ramamurthy Badrinath and Swarup Kumar Mohalik and Anusha Mujumdar and Alexandros Nikou and Alessandro Previti and Vaishnavi Sundararajan and Aneta Vulgarakis Feljan},
1093title = {Machine Reasoning Explainability},
1094}
1095
1096@incollection{sep-justice,
1097publisher = {Metaphysics Research Lab, Stanford University},
1098edition = {{F}all 2021},
1099 year = {2021},
1100 howpublished = {\url{https://plato.stanford.edu/archives/fall2021/entries/justice/}},
1101editor = {Edward N. Zalta},
1102booktitle = {The {Stanford} Encyclopedia of Philosophy},
1103title = {{Justice}},
1104author = {Miller, David},
1105}
1106
1107@article{UDIT2020,
1108year = {2020},
1109url = {http://slavkovik.com/UDIT_2020_paper_10.pdf},
1110title = {Teaching {AI E}thics: Observations and Challenges},
1111journal = {Norwegian Conference on Didactics in IT education},
1112author = {Marija Slavkovik},
1113abstract = {This report summarises the experience in teaching Artificial Intelligence (AI)
1114Ethics as an elective masters level course at the University of Bergen. The
1115goal of the summary is twofold: 1) to draw lessons for teaching this in-high
1116demand very new discipline; 2) to serve as a basis in developing a bachelor
1117level AI Ethics course for students of artificial intelligence. AI Ethics as a
1118topic is particularly challenging to teach as the discipline itself is very new
1119and no textbooks have been established. The added challenge is introducing
1120methodologies and skills from humanity- and social sciences to students of
1121computational and information sciences.},
1122}
1123
1124@inproceedings{Nordichi2020,
1125publisher = {{ACM}},
1126booktitle = {Proceedings of the 11th Nordic Conference on Human-Computer Interaction,
1127October 25 - 29, 2020, Tallinn, Estonia},
1128note = {Available at https://arxiv.org/abs/2006.13985},
1129year = {2020},
1130title = {Circumvention by design - dark patterns in cookie consents for online
1131news outlets},
1132author = {Than Htut Soe and
1133Oda Elise Nordberg and
1134Frode Guribye and
1135Marija Slavkovik},
1136}
1137
1138@book{Dignum19,
1139bibsource = {dblp computer science bibliography, https://dblp.org},
1140biburl = {https://dblp.org/rec/series/aifta/Dignum19.bib},
1141timestamp = {Fri, 08 Nov 2019 13:09:13 +0100},
1142isbn = {978-3-030-30370-9},
1143doi = {10.1007/978-3-030-30371-6},
1144url = {https://doi.org/10.1007/978-3-030-30371-6},
1145year = {2019},
1146publisher = {Springer},
1147series = {Artificial Intelligence: Foundations, Theory, and Algorithms},
1148title = {Responsible Artificial Intelligence - How to Develop and Use {AI}
1149in a Responsible Way},
1150author = {Virginia Dignum},
1151}
1152
1153@book{Anderson11,
1154publisher = { Cambridge University Press},
1155year = {2011},
1156title = {Machine Ethics},
1157editor = {Michael Anderson and Susan Leigh Anderson},
1158}
1159
1160@book{KearnsR2019,
1161year = {2019},
1162publisher = {Oxford University Press},
1163author = {Michael Kearns and Aaron Roth},
1164title = {The Ethical Algorithm: The Science of Socially Aware Algorithm Design},
1165}
1166
1167@article{Mehrabi2019,
1168bibsource = {dblp computer science bibliography, https://dblp.org},
1169biburl = {https://dblp.org/rec/journals/corr/abs-1908-09635.bib},
1170timestamp = {Thu, 29 Aug 2019 16:32:34 +0200},
1171eprint = {1908.09635},
1172archiveprefix = {arXiv},
1173url = {http://arxiv.org/abs/1908.09635},
1174year = {2019},
1175volume = {abs/1908.09635},
1176journal = {CoRR},
1177title = {A Survey on Bias and Fairness in Machine Learning},
1178author = {Ninareh Mehrabi and
1179Fred Morstatter and
1180Nripsuta Saxena and
1181Kristina Lerman and
1182Aram Galstyan},
1183}
1184
1185@article{Gunning2019,
1186pages = {44-58},
1187month = {Jun.},
1188year = {2019},
1189author = {Gunning, David and Aha, David},
1190journal = {AI Magazine},
1191number = {2},
1192doi = {10.1609/aimag.v40i2.2850},
1193url = {https://www.aaai.org/ojs/index.php/aimagazine/article/view/2850},
1194volume = {40},
1195title = {DARPA's Explainable Artificial Intelligence ({XAI}) Program},
1196}
1197
1198@incollection{Diakopoulos20,
1199doi = {10.1093/oxfordhb/9780190067397.013.11},
1200publisher = {Oxford University Press},
1201month = {Jul},
1202year = {2020},
1203editor = {Markus D. Dubber and Frank Pasquale and Sunit Das},
1204booktitle = {The Oxford Handbook of Ethics of AI},
1205author = {Nicholas Diakopoulos},
1206title = {Transparency},
1207}
1208
1209@inproceedings{Wieringa2020,
1210series = {FAT\* '20},
1211location = {Barcelona, Spain},
1212keywords = {accountability theory, algorithmic accountability, data-driven governance, algorithmic systems},
1213numpages = {18},
1214pages = {1-18},
1215booktitle = {Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency},
1216doi = {10.1145/3351095.3372833},
1217url = {https://doi.org/10.1145/3351095.3372833},
1218address = {New York, NY, USA},
1219publisher = {Association for Computing Machinery},
1220isbn = {9781450369367},
1221year = {2020},
1222title = {What to Account for When Accounting for Algorithms: A Systematic Literature Review on Algorithmic Accountability},
1223author = {Wieringa, Maranke},
1224}
1225
1226@inproceedings{Fiesler2020,
1227series = {SIGCSE 'ß20},
1228location = {Portland, OR, USA},
1229keywords = {ethics, syllabi, curriculum, professional responsibility},
1230numpages = {7},
1231pages = {289-295},
1232booktitle = {Proceedings of the 51st ACM Technical Symposium on Computer Science Education},
1233doi = {10.1145/3328778.3366825},
1234url = {https://doi.org/10.1145/3328778.3366825},
1235address = {New York, NY, USA},
1236publisher = {Association for Computing Machinery},
1237isbn = {9781450367936},
1238year = {2020},
1239title = {What Do We Teach When We Teach Tech Ethics? A Syllabi Analysis},
1240author = {Fiesler, Casey and Garrett, Natalie and Beard, Nathan},
1241}
1242
1243@misc{NYTethics,
1244note = {[Online; accessed 20-May-2020]},
1245publisher = {The New York Times},
1246year = {2017},
1247howpublished = {\url{https://www.nytimes.com/2017/11/14/opinion/academia-tech-algorithms.html}},
1248title = {The {Ivory} Tower Can't Keep Ignoring Tech},
1249author = {Cathy O'Neil},
1250}
1251
1252@article{JobinIV2019,
1253bdsk-url-1 = {https://doi.org/10.1038/s42256-019-0088-2},
1254year = {2019},
1255url = {https://doi.org/10.1038/s42256-019-0088-2},
1256title = {The global landscape of {AI} ethics guidelines},
1257journal = {Nature Machine Intelligence},
1258doi = {10.1038/s42256-019-0088-2},
1259date-modified = {2019-09-08 11:39:43 +0200},
1260author = {Jobin, A. and Ienca, M. and Vayena, E.},
1261abstract = {In the past five years, private companies, research institutions and public sector organizations have issued principles and guidelines for ethical artificial intelligence (AI). However, despite an apparent agreement that AI should be `ethical', there is debate about both what constitutes `ethical AI' and which ethical requirements, technical standards and best practices are needed for its realization. To investigate whether a global agreement on these questions is emerging, we mapped and analysed the current corpus of principles and guidelines on ethical AI. Our results reveal a global convergence emerging around five ethical principles (transparency, justice and fairness, non-maleficence, responsibility and privacy), with substantive divergence in relation to how these principles are interpreted, why they are deemed important, what issue, domain or actors they pertain to, and how they should be implemented. Our findings highlight the importance of integrating guideline-development efforts with substantive ethical analysis and adequate implementation strategies.},
1262}
1263
1264@article{Hagendorff:2020,
1265year = {2020},
1266volume = {30},
1267url = {https://doi.org/10.1007/s11023-020-09517-8},
1268title = {The Ethics of AI Ethics: An Evaluation of Guidelines},
1269pages = {99-120},
1270number = {1},
1271journal = {Minds and Machines},
1272isbn = {1572-8641},
1273doi = {10.1007/s11023-020-09517-8},
1274author = {Hagendorff, Thilo},
1275abstract = {Current advances in research, development and application of artificial intelligence (AI) systems have yielded a far-reaching discourse on AI ethics. In consequence, a number of ethics guidelines have been released in recent years. These guidelines comprise normative principles and recommendations aimed to harness the ``disruptive''potentials of new AI technologies. Designed as a semi-systematic evaluation, this paper analyzes and compares 22 guidelines, highlighting overlaps but also omissions. As a result, I give a detailed overview of the field of AI ethics. Finally, I also examine to what extent the respective ethical principles and values are implemented in the practice of research, development and application of AI systems---and how the effectiveness in the demands of AI ethics can be improved.},
1276}
1277
1278@misc{tth,
1279note = {The package is TTH, available at http://hutchinson.belmont.ma.us/tth/ .},
1280}
1281
1282@misc{use2e,
1283note = {As the mark-up of the \TeX\ source for this document makes clear, your file should be coded in \LaTeX 2${\varepsilon}$, not \LaTeX\ 2.09 or an earlier release. Also, please use the \texttt{article} document class.},
1284}
1285
1286@misc{inclme,
1287note = {Among whom are the author of this document. The ``real'' references and notes contained herein were compiled using B{\small{IB}}\TeX\ from the sample .bib file \texttt{scibib.bib}, the style package \texttt{scicite.sty}, and the bibliography style file \texttt{Science.bst}.},
1288}
1289
1290@misc{nattex,
1291note = {One of the equation editors we use, Equation Magic (MicroPress Inc., Forest Hills, NY; http://www.micropress-inc.com/), interprets native \TeX\ source code and generates an equation as an OLE picture object that can then be cut and pasted directly into Word. This editor, however, does not handle \LaTeX\ environments (such as \texttt{\{array\}} or \texttt{\{eqnarray\}}); it can interpret only \TeX\ codes. Thus, when there's a choice, we ask that you avoid these \LaTeX\ calls in displayed math --- for example, that you use the \TeX\ \verb+\matrix+ command for ordinary matrices, rather than the \LaTeX\ \texttt{\{array\}} environment.},
1292}
1293
1294@inproceedings{Klyubin2005,
1295doi = {10.1109/CEC.2005.1554676},
1296pages = {128-135},
1297number = {},
1298volume = {1},
1299year = {2005},
1300title = {Empowerment: a universal agent-centric measure of control},
1301booktitle = {2005 IEEE Congress on Evolutionary Computation},
1302author = {Alexander S. {Klyubin} and Daniel {Polani} and Chrystopehr L. {Nehaniv}},
1303}
1304
1305@article{Light,
1306year = {1999},
1307volume = {40},
1308title = {When Computers Were Women},
1309publisher = {[The Johns Hopkins University Press, Society for the History of Technology]},
1310pages = {455-483},
1311number = {3},
1312journal = {Technology and Culture},
1313author = {Jennifer S. Light},
1314url = {http://www.jstor.org/stable/25147356},
1315issn = {0040165X, 10973729},
1316}
1317
1318@book{Ifrah2001,
1319publisher = {John Wiley},
1320address = { New York},
1321year = {2001},
1322title = {The universal history of computing : from the abacus to the quantum computer},
1323author = {Ifrah, Georges},
1324}
1325
1326@misc{mehrabi2019survey,
1327primaryclass = {cs.LG},
1328archiveprefix = {arXiv},
1329eprint = {1908.09635},
1330year = {2019},
1331author = {Ninareh Mehrabi and Fred Morstatter and Nripsuta Saxena and Kristina Lerman and Aram Galstyan},
1332title = {A Survey on Bias and Fairness in Machine Learning},
1333}
1334
1335@inproceedings{KearnsNRW18,
1336bibsource = {dblp computer science bibliography, https://dblp.org},
1337biburl = {https://dblp.org/rec/conf/icml/KearnsNRW18.bib},
1338timestamp = {Tue, 08 Oct 2019 14:34:26 +0200},
1339url = {http://proceedings.mlr.press/v80/kearns18a.html},
1340year = {2018},
1341publisher = {{PMLR}},
1342pages = {2569-2577},
1343volume = {80},
1344series = {Proceedings of Machine Learning Research},
1345booktitle = {Proceedings of the 35th International Conference on Machine Learning,
1346{ICML} 2018, Stockholmsm{\"{a}}ssan, Stockholm, Sweden, July
134710-15, 2018},
1348title = {Preventing Fairness Gerrymandering: Auditing and Learning for Subgroup
1349Fairness},
1350editor = {Jennifer G. Dy and
1351Andreas Krause},
1352author = {Michael J. Kearns and
1353Seth Neel and
1354Aaron Roth and
1355Zhiwei Steven Wu},
1356}
1357
1358@article{Chouldechova17,
1359bibsource = {dblp computer science bibliography, https://dblp.org},
1360biburl = {https://dblp.org/rec/journals/bigdata/Chouldechova17.bib},
1361timestamp = {Thu, 28 Nov 2019 10:42:39 +0100},
1362doi = {10.1089/big.2016.0047},
1363url = {https://doi.org/10.1089/big.2016.0047},
1364year = {2017},
1365pages = {153-163},
1366number = {2},
1367volume = {5},
1368journal = {Big Data},
1369title = {Fair Prediction with Disparate Impact: {A} Study of Bias in Recidivism
1370Prediction Instruments},
1371author = {Alexandra Chouldechova},
1372}
1373
1374@article{ChouldechovaR20,
1375bibsource = {dblp computer science bibliography, https://dblp.org},
1376biburl = {https://dblp.org/rec/journals/cacm/ChouldechovaR20.bib},
1377timestamp = {Tue, 12 May 2020 16:49:21 +0200},
1378doi = {10.1145/3376898},
1379url = {https://doi.org/10.1145/3376898},
1380year = {2020},
1381pages = {82-89},
1382number = {5},
1383volume = {63},
1384journal = {Commun. {ACM}},
1385title = {A snapshot of the frontiers of fairness in machine learning},
1386author = {Alexandra Chouldechova and
1387Aaron Roth},
1388}
1389
1390@article{Dwork2011,
1391bibsource = {dblp computer science bibliography, https://dblp.org},
1392biburl = {https://dblp.org/rec/journals/corr/abs-1104-3913.bib},
1393timestamp = {Mon, 13 Aug 2018 16:48:46 +0200},
1394eprint = {1104.3913},
1395archiveprefix = {arXiv},
1396url = {http://arxiv.org/abs/1104.3913},
1397year = {2011},
1398volume = {abs/1104.3913},
1399journal = {CoRR},
1400title = {Fairness Through Awareness},
1401author = {Cynthia Dwork and
1402Moritz Hardt and
1403Toniann Pitassi and
1404Omer Reingold and
1405Richard S. Zemel},
1406}
1407
1408@inproceedings{Ben-NaimL14,
1409bibsource = {dblp computer science bibliography, https://dblp.org},
1410biburl = {https://dblp.org/rec/conf/atal/Ben-NaimL14.bib},
1411timestamp = {Thu, 25 Sep 2014 09:28:51 +0200},
1412url = {http://dl.acm.org/citation.cfm?id=2615868},
1413year = {2014},
1414publisher = {{IFAAMAS/ACM}},
1415pages = {853-860},
1416booktitle = {International conference on Autonomous Agents and Multi-Agent Systems,
1417{AAMAS} '14, Paris, France, May 5-9, 2014},
1418title = {Evaluating power of agents from dependence relations in boolean games},
1419editor = {Ana L. C. Bazzan and
1420Michael N. Huhns and
1421Alessio Lomuscio and
1422Paul Scerri},
1423author = {Jonathan Ben{-}Naim and
1424Emiliano Lorini},
1425}
1426
1427@inproceedings{PereiraPS13,
1428bibsource = {dblp computer science bibliography, https://dblp.org},
1429biburl = {https://dblp.org/rec/conf/atal/PereiraPS13.bib},
1430timestamp = {Sat, 16 May 2015 12:22:58 +0200},
1431url = {http://dl.acm.org/citation.cfm?id=2485187},
1432year = {2013},
1433publisher = {{IFAAMAS}},
1434pages = {1289-1290},
1435booktitle = {International conference on Autonomous Agents and Multi-Agent Systems,
1436{AAMAS} '13, Saint Paul, MN, USA, May 6-10, 2013},
1437title = {Bases of social power for agents},
1438editor = {Maria L. Gini and
1439Onn Shehory and
1440Takayuki Ito and
1441Catholijn M. Jonker},
1442author = {Gon{\c{c}}alo Duarte Garcia Pereira and
1443Rui Prada and
1444Pedro Alexandre Santos},
1445}
1446
1447@article{Baum20,
1448bibsource = {dblp computer science bibliography, https://dblp.org},
1449biburl = {https://dblp.org/rec/journals/ais/Baum20.bib},
1450timestamp = {Wed, 19 Feb 2020 09:51:46 +0100},
1451doi = {10.1007/s00146-017-0760-1},
1452url = {https://doi.org/10.1007/s00146-017-0760-1},
1453year = {2020},
1454pages = {165-176},
1455number = {1},
1456volume = {35},
1457journal = {{AI} Soc.},
1458title = {Social choice ethics in artificial intelligence},
1459author = {Seth D. Baum},
1460}
1461
1462@article{Rahwan18,
1463bibsource = {dblp computer science bibliography, https://dblp.org},
1464biburl = {https://dblp.org/rec/journals/ethicsit/Rahwan18.bib},
1465timestamp = {Fri, 30 Nov 2018 13:27:26 +0100},
1466doi = {10.1007/s10676-017-9430-8},
1467url = {https://doi.org/10.1007/s10676-017-9430-8},
1468year = {2018},
1469pages = {5-14},
1470number = {1},
1471volume = {20},
1472journal = {Ethics and Information Technoly},
1473title = {Society-in-the-loop: programming the algorithmic social contract},
1474author = {Iyad Rahwan},
1475}
1476
1477@inproceedings{NoothigattuGADR18,
1478bibsource = {dblp computer science bibliography, https://dblp.org},
1479biburl = {https://dblp.org/rec/conf/aaai/NoothigattuGADR18.bib},
1480timestamp = {Tue, 23 Oct 2018 06:42:15 +0200},
1481url = {https://www.aaai.org/ocs/index.php/AAAI/AAAI18/paper/view/17052},
1482year = {2018},
1483publisher = {{AAAI} Press},
1484pages = {1587-1594},
1485booktitle = {Proceedings of the Thirty-Second {AAAI} Conference on Artificial Intelligence,
1486(AAAI-18), the 30th innovative Applications of Artificial Intelligence
1487(IAAI-18), and the 8th {AAAI} Symposium on Educational Advances in
1488Artificial Intelligence (EAAI-18), New Orleans, Louisiana, USA, February
14892-7, 2018},
1490title = {A Voting-Based System for Ethical Decision Making},
1491editor = {Sheila A. McIlraith and
1492Kilian Q. Weinberger},
1493author = {Ritesh Noothigattu and
1494Snehalkumar (Neil) S. Gaikwad and
1495Edmond Awad and
1496Sohan Dsouza and
1497Iyad Rahwan and
1498Pradeep Ravikumar and
1499Ariel D. Procaccia},
1500}
1501
1502@inproceedings{RossiL19,
1503bibsource = {dblp computer science bibliography, https://dblp.org},
1504biburl = {https://dblp.org/rec/conf/atal/RossiL19.bib},
1505timestamp = {Wed, 29 May 2019 16:37:38 +0200},
1506url = {http://dl.acm.org/citation.cfm?id=3331664},
1507year = {2019},
1508publisher = {International Foundation for Autonomous Agents and Multiagent Systems},
1509pages = {3-4},
1510booktitle = {Proceedings of the 18th International Conference on Autonomous Agents
1511and MultiAgent Systems, {AAMAS} '19, Montreal, QC, Canada, May 13-17,
15122019},
1513title = {Preferences and Ethical Priorities: Thinking Fast and Slow in {AI}},
1514editor = {Edith Elkind and
1515Manuela Veloso and
1516Noa Agmon and
1517Matthew E. Taylor},
1518author = {Francesca Rossi and
1519Andrea Loreggia},
1520}
1521
1522@article{Liao2018,
1523bibsource = {dblp computer science bibliography, https://dblp.org},
1524biburl = {https://dblp.org/rec/journals/corr/abs-1812-05362.bib},
1525timestamp = {Mon, 15 Apr 2019 17:08:26 +0200},
1526eprint = {1812.05362},
1527archiveprefix = {arXiv},
1528url = {http://arxiv.org/abs/1812.05362},
1529year = {2018},
1530volume = {abs/1812.05362},
1531journal = {CoRR},
1532title = {Representation, Justification and Explanation in a Value Driven Agent:
1533An Argumentation-Based Approach},
1534author = {Beishui Liao and
1535Michael Anderson and
1536Susan Leigh Anderson},
1537}
1538
1539@inproceedings{AndersonA14,
1540bibsource = {dblp computer science bibliography, https://dblp.org},
1541biburl = {https://dblp.org/rec/conf/aaai/AndersonA14.bib},
1542timestamp = {Mon, 15 Apr 2019 17:08:25 +0200},
1543url = {http://www.aaai.org/ocs/index.php/AAAI/AAAI14/paper/view/8308},
1544year = {2014},
1545publisher = {{AAAI} Press},
1546 pages = {253-261},
1547 booktitle = {Proceedings of the Twenty-Eighth {AAAI} Conference on Artificial Intelligence,
1548July 27 -31, 2014, Qu{\'{e}}bec City, Qu{\'{e}}bec, Canada},
1549title = {GenEth: {A} General Ethical Dilemma Analyzer},
1550editor = {Carla E. Brodley and
1551Peter Stone},
1552author = {Michael Anderson and
1553Susan Leigh Anderson},
1554}
1555
1556@article{DennisFSW16,
1557bibsource = {dblp computer science bibliography, https://dblp.org},
1558biburl = {https://dblp.org/rec/journals/ras/DennisFSW16.bib},
1559timestamp = {Mon, 24 Feb 2020 15:57:54 +0100},
1560doi = {10.1016/j.robot.2015.11.012},
1561url = {https://doi.org/10.1016/j.robot.2015.11.012},
1562year = {2016},
1563pages = {1-14},
1564volume = {77},
1565journal = {Robotics Auton. Syst.},
1566title = {Formal verification of ethical choices in autonomous systems},
1567author = {Louise A. Dennis and
1568Michael Fisher and
1569Marija Slavkovik and
1570Matt Webster},
1571}
1572
1573@incollection{Sen1974,
1574year = {1974},
1575pages = {54-67},
1576publisher = {Camalot Press, Oxford},
1577editor = {Stephan K{\"o}rner },
1578booktitle = {Practical Reason},
1579title = {Choice, Orderings and Morality},
1580author = {Amartya Sen},
1581}
1582
1583@inproceedings{SchwindM18,
1584bibsource = {dblp computer science bibliography, https://dblp.org},
1585biburl = {https://dblp.org/rec/conf/aaai/SchwindM18.bib},
1586timestamp = {Tue, 23 Oct 2018 06:42:15 +0200},
1587url = {https://www.aaai.org/ocs/index.php/AAAI/AAAI18/paper/view/16279},
1588year = {2018},
1589publisher = {{AAAI} Press},
1590pages = {1949-1956},
1591booktitle = {Proceedings of the Thirty-Second {AAAI} Conference on Artificial Intelligence,
1592(AAAI-18), the 30th innovative Applications of Artificial Intelligence
1593(IAAI-18), and the 8th {AAAI} Symposium on Educational Advances in
1594Artificial Intelligence (EAAI-18), New Orleans, Louisiana, USA, February
15952-7, 2018},
1596title = {On Consensus in Belief Merging},
1597editor = {Sheila A. McIlraith and
1598Kilian Q. Weinberger},
1599author = {Nicolas Schwind and
1600Pierre Marquis},
1601}
1602
1603@book{PooleMackworth17,
1604year = {2017},
1605username = {flint63},
1606url = {http://artint.info/2e/html/ArtInt2e.html},
1607title = {Artificial Intelligence: Foundations of Computational Agents},
1608timestamp = {2018-04-16T12:41:15.000+0200},
1609publisher = {Cambridge University Press},
1610keywords = {01801 102 book safari ai agent knowledge processing plan learn intro},
1611isbn = {978-0-521-51900-7},
1612intrahash = {e4ec397b0ebf6769d87584d7fd8cb6f4},
1613interhash = {6a01b002d9efaab2dabb291411ccfd1b},
1614groups = {public},
1615file = {Excerpt (from DRM eBook):2017/PooleMackworth17intro.pdf:PDF;Fist Edition 2010:2010/PooleMackworth10.pdf:PDF;eBooks.com:https\://sec.ebooks.com/account/view-all.asp:URL;Cambridge University Press Product Page:http\://www.cambridge.org/9781107195394:URL;Amazon Search inside:http\://www.amazon.de/gp/reader/110719539X/:URL;Related Web Site:http\://aispace.org/:URL},
1616edition = {2},
1617biburl = {https://www.bibsonomy.org/bibtex/2e4ec397b0ebf6769d87584d7fd8cb6f4/flint63},
1618author = {Poole, David and Mackworth, Alan},
1619address = {Cambridge, UK},
1620added-at = {2017-10-22T13:53:07.000+0200},
1621abstract = {Artificial intelligence, including machine learning, has emerged as a transformational science and engineering discipline. Artificial Intelligence: Foundations of Computational Agents presents AI using a coherent framework to study the design of intelligent computational agents. By showing how the basic approaches fit into a multidimensional design space, readers learn the fundamentals without losing sight of the bigger picture. The new edition also features expanded coverage on machine learning material, as well as on the social and ethical consequences of AI and ML. The book balances theory and experiment, showing how to link them together, and develops the science of AI together with its engineering applications. Although structured as an undergraduate and graduate textbook, the book's straightforward, self-contained style will also appeal to an audience of professionals, researchers, and independent learners. The second edition is well-supported by strong pedagogical features and online resources to enhance student comprehension.},
1622}
1623
1624@book{Bellman1978,
1625publisher = {Boyd \& Fraser Publishing Company},
1626year = {1978},
1627title = {An Introduction to Artificial Intelligence: Can Computers Think?},
1628author = {Richard E. Bellman},
1629}
1630
1631@book{ListPettit,
1632publisher = { Oxford Scholarship Online},
1633year = {2011},
1634author = {Christian List and Philip Pettit},
1635title = {Group Agency: The Possibility, Design, and Status of Corporate Agents},
1636}
1637
1638@mastersthesis{Tisi2020,
1639year = {2020},
1640school = {University of Amsterdam},
1641title = {A moderate emergentist account of group agency},
1642author = {Flavio Tisi},
1643}
1644
1645@article{Belamy2018,
1646bibsource = {dblp computer science bibliography, https://dblp.org},
1647biburl = {https://dblp.org/rec/journals/corr/abs-1810-01943.bib},
1648timestamp = {Tue, 30 Oct 2018 10:49:09 +0100},
1649eprint = {1810.01943},
1650archiveprefix = {arXiv},
1651url = {http://arxiv.org/abs/1810.01943},
1652year = {2018},
1653volume = {abs/1810.01943},
1654journal = {CoRR},
1655title = {{AI} Fairness 360: An Extensible Toolkit for Detecting, Understanding,
1656and Mitigating Unwanted Algorithmic Bias},
1657author = {Rachel K. E. Bellamy and
1658Kuntal Dey and
1659Michael Hind and
1660Samuel C. Hoffman and
1661Stephanie Houde and
1662Kalapriya Kannan and
1663Pranay Lohia and
1664Jacquelyn Martino and
1665Sameep Mehta and
1666Aleksandra Mojsilovic and
1667Seema Nagar and
1668Karthikeyan Natesan Ramamurthy and
1669John T. Richards and
1670Diptikalyan Saha and
1671Prasanna Sattigeri and
1672Moninder Singh and
1673Kush R. Varshney and
1674Yunfeng Zhang},
1675}
1676
1677@inproceedings{Verma2018,
1678series = {FairWare18},
1679location = {Gothenburg, Sweden},
1680numpages = {7},
1681pages = {1-7},
1682booktitle = {Proceedings of the International Workshop on Software Fairness},
1683abstract = {Algorithm fairness has started to attract the attention of researchers in AI, Software Engineering and Law communities, with more than twenty different notions of fairness proposed in the last few years. Yet, there is no clear agreement on which definition to apply in each situation. Moreover, the detailed differences between multiple definitions are difficult to grasp. To address this issue, this paper collects the most prominent definitions of fairness for the algorithmic classification problem, explains the rationale behind these definitions, and demonstrates each of them on a single unifying case-study. Our analysis intuitively explains why the same case can be considered fair according to some definitions and unfair according to others.},
1684doi = {10.1145/3194770.3194776},
1685url = {https://doi.org/10.1145/3194770.3194776},
1686address = {New York, NY, USA},
1687publisher = {Association for Computing Machinery},
1688isbn = {9781450357463},
1689year = {2018},
1690title = {Fairness Definitions Explained},
1691author = {Verma, Sahil and Rubin, Julia},
1692}
1693
1694@article{Wang2018,
1695year = {2018},
1696volume = {114},
1697title = {{Deep neural networks are more accurate than humans at detecting sexual orientation from facial images}},
1698publisher = {American Psychological Association Inc.},
1699pages = {246-257},
1700number = {2},
1701month = {feb},
1702keywords = {Computational social science,Facial morphology,Prenatal hormone theory,Privacy,Sexual orientation},
1703journal = {Journal of Personality and Social Psychology},
1704issn = {00223514},
1705doi = {10.1037/pspa0000098},
1706author = {Wang, Yilun and Kosinski, Michal},
1707}
1708
1709@article{RODRIGUES2020,
1710author = {Rowena Rodrigues},
1711url = {https://www.sciencedirect.com/science/article/pii/S2666659620300056},
1712doi = {https://doi.org/10.1016/j.jrt.2020.100005},
1713issn = {2666-6596},
1714year = {2020},
1715pages = {100005},
1716volume = {4},
1717journal = {Journal of Responsible Technology},
1718title = {Legal and human rights issues of AI: Gaps, challenges and vulnerabilities},
1719}
1720
1721@article{xai_survey_2020,
1722author = {Alejandro {Barredo Arrieta} and Natalia Díaz-Rodríguez and Javier {Del Ser} and Adrien Bennetot and Siham Tabik and Alberto Barbado and Salvador Garcia and Sergio Gil-Lopez and Daniel Molina and Richard Benjamins and Raja Chatila and Francisco Herrera},
1723url = {https://www.sciencedirect.com/science/article/pii/S1566253519308103},
1724doi = {https://doi.org/10.1016/j.inffus.2019.12.012},
1725issn = {1566-2535},
1726year = {2020},
1727pages = {82-115},
1728volume = {58},
1729journal = {Information Fusion},
1730title = {Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI},
1731}
1732
1733@techreport{Basl2021,
1734year = {2021},
1735note = {\url{https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX\%3A52021PC0206}},
1736institution = {Atlantic Council Geothec Centre},
1737title = {Getting from Commitment to Content
1738in AI and Data Ethics: Justice and Explainability},
1739author = {Basl, John and
1740Sandler, Ronald and
1741Tiell, Steven},
1742}
1743
1744@article{edwards2017slave,
1745publisher = {HeinOnline},
1746year = {2017},
1747pages = {18},
1748volume = {16},
1749journal = {Duke L. \& Tech. Rev.},
1750author = {Edwards, Lilian and Veale, Michael},
1751title = {Slave to the algorithm: Why a right to an explanation is probably not the remedy you are looking for},
1752}
1753
1754@article{wachter2017right,
1755publisher = {Oxford University Press},
1756year = {2017},
1757pages = {76-99},
1758number = {2},
1759volume = {7},
1760journal = {International Data Privacy Law},
1761author = {Wachter, Sandra and Mittelstadt, Brent and Floridi, Luciano},
1762title = {Why a right to explanation of automated decision-making does not exist in the general data protection regulation},
1763}
1764
1765@article{selbst2017meaningful,
1766publisher = {Oxford University Press},
1767year = {2017},
1768pages = {233-242},
1769number = {4},
1770volume = {7},
1771journal = {International Data Privacy Law},
1772author = {Selbst, Andrew D and Powles, Julia},
1773title = {Meaningful information and the right to explanation},
1774}
1775
1776@book{barocas-hardt-narayanan,
1777year = {2019},
1778address = {online},
1779note = {\url{http://www.fairmlbook.org}},
1780publisher = {fairmlbook.org},
1781author = {Solon Barocas and Moritz Hardt and Arvind Narayanan},
1782title = {Fairness and Machine Learning},
1783}
1784
1785@incollection{rodolfa2020bias,
1786publisher = {Chapman and Hall/CRC},
1787year = {2020},
1788pages = {281-312},
1789booktitle = {Big data and social science},
1790author = {Rodolfa, Kit T and Saleiro, Pedro and Ghani, Rayid},
1791title = {Bias and fairness},
1792}
1793
1794@article{Kosinski2013,
1795year = {2013},
1796volume = {110},
1797title = {{Private traits and attributes are predictable from digital records of human behavior.}},
1798pmid = {23479631},
1799pages = {5802-5},
1800number = {15},
1801month = {apr},
1802journal = {Proceedings of the National Academy of Sciences of the United States of America},
1803issn = {1091-6490},
1804doi = {10.1073/pnas.1218772110},
1805author = {Kosinski, Michal and Stillwell, David and Graepel, Thore},
1806}
1807
1808@inproceedings{SlavkovikSPA21,
1809doi = {10.1145/3461702.3462626},
1810url = {https://doi.org/10.1145/3461702.3462626},
1811year = {2021},
1812publisher = {{ACM}},
1813pages = {967-977},
1814address = {Virtual
1815Event, USA, May 19-21, 2021},
1816booktitle = {{AIES} '21: {AAAI/ACM} Conference on AI, Ethics, and Society},
1817title = {Digital Voodoo Dolls},
1818editor = {Marion Fourcade and
1819Benjamin Kuipers and
1820Seth Lazar and
1821Deirdre K. Mulligan},
1822author = {Marija Slavkovik and
1823Clemens Stachl and
1824Caroline Pitman and
1825Jonathan Askonas},
1826}
1827
1828@book{Nifosi2017,
1829doi = {10.4324/9781315734354},
1830journal = {The Protection of Vulnerable Groups under International Human Rights Law},
1831isbn = {9781315734354},
1832title = {The Protection of Vulnerable Groups under International Human Rights Law},
1833pages = {1-291},
1834month = {07},
1835year = {2017},
1836author = {Nifosi-Sutton, N.},
1837}
1838
1839@article{Winfield2021,
1840abstract = {This paper describes IEEE P7001, a new draft standard on transparency of autonomous systems<xref ref-type="fn" rid="fn1"><sup>1</sup></xref>. In the paper, we outline the development and structure of the draft standard. We present the rationale for transparency as a measurable, testable property. We outline five stakeholder groups: users, the general public and bystanders, safety certification agencies, incident/accident investigators and lawyers/expert witnesses, and explain the thinking behind the normative definitions of âlevelsâ of transparency for each stakeholder group in P7001. The paper illustrates the application of P7001 through worked examples of both specification and assessment of fictional autonomous systems.},
1841issn = {2296-9144},
1842doi = {10.3389/frobt.2021.665729},
1843url = {https://www.frontiersin.org/article/10.3389/frobt.2021.665729},
1844year = {2021},
1845pages = {225},
1846volume = {8},
1847journal = {Frontiers in Robotics and AI},
1848title = {IEEE P7001: A Proposed Standard on Transparency},
1849author = {Winfield, Alan F. T. and Booth, Serena and Dennis, Louise A. and Egawa, Takashi and Hastie, Helen and Jacobs, Naomi and Muttram, Roderick I. and Olszewska, Joanna I. and Rajabiyazdi, Fahimeh and Theodorou, Andreas and Underwood, Mark A. and Wortham, Robert H. and Watson, Eleanor},
1850}
1851
1852@phdthesis{kroll2015accountable,
1853school = {Princeton University},
1854year = {2015},
1855author = {Kroll, Joshua Alexander},
1856title = {Accountable algorithms},
1857}
1858
1859@article{breidbach2020accountable,
1860publisher = {Emerald Publishing Limited},
1861year = {2020},
1862journal = {Journal of Service Management},
1863author = {Breidbach, Christoph F and Maglio, Paul},
1864title = {Accountable algorithms? The ethical implications of data-driven business models},
1865}
1866
1867@article{danks2017regulating,
1868publisher = {IEEE},
1869year = {2017},
1870pages = {88-91},
1871number = {1},
1872volume = {32},
1873journal = {IEEE Intelligent Systems},
1874author = {Danks, David and London, Alex John},
1875title = {Regulating autonomous systems: Beyond standards},
1876}
1877
1878@inproceedings{kingston2016liability,
1879organization = {Springer},
1880year = {2016},
1881pages = {269-279},
1882booktitle = {International Conference on Innovative Techniques and Applications of Artificial Intelligence},
1883author = {Kingston, John KC},
1884title = {Artificial intelligence and legal liability},
1885}
1886
1887@article{amann2020explainability,
1888publisher = {Springer},
1889year = {2020},
1890pages = {1-9},
1891number = {1},
1892volume = {20},
1893journal = {BMC Medical Informatics and Decision Making},
1894author = {Amann, Julia and Blasimme, Alessandro and Vayena, Effy and Frey, Dietmar and Madai, Vince I},
1895title = {Explainability for artificial intelligence in healthcare: a multidisciplinary perspective},
1896}
1897
1898@article{naghibi2015,
1899publisher = {Springer},
1900year = {2015},
1901pages = {5217-5236},
1902number = {14},
1903volume = {29},
1904journal = {Water resources management},
1905author = {Naghibi, Seyed Amir and Pourghasemi, Hamid Reza},
1906title = {A comparative assessment between three machine learning models and their performance comparison by bivariate and multivariate statistical methods in groundwater potential mapping},
1907}
1908
1909@article{ahmed2010,
1910publisher = {Taylor \& Francis},
1911year = {2010},
1912pages = {594-621},
1913number = {5-6},
1914volume = {29},
1915journal = {Econometric Reviews},
1916author = {Ahmed, Nesreen K and Atiya, Amir F and Gayar, Neamat El and El-Shishiny, Hisham},
1917title = {An empirical comparison of machine learning models for time series forecasting},
1918}
1919
1920@article{Stachl2020,
1921eprint = {https://doi.org/10.1002/per.2257},
1922url = {https://doi.org/10.1002/per.2257},
1923doi = {10.1002/per.2257},
1924year = {2020},
1925pages = {613-631},
1926number = {5},
1927volume = {34},
1928journal = {European Journal of Personality},
1929title = {Personality Research and Assessment in the Era of Machine Learning},
1930author = {Clemens Stachl and Florian Pargent and Sven Hilbert and Gabriella M. Harari and Ramona Schoedel and Sumer Vaid and Samuel D. Gosling and Markus {B\"u}hner},
1931}
1932
1933@article{xai_review_2020,
1934author = {Alejandro {Barredo Arrieta} and Natalia Díaz-Rodríguez and Javier {Del Ser} and Adrien Bennetot and Siham Tabik and Alberto Barbado and Salvador Garcia and Sergio Gil-Lopez and Daniel Molina and Richard Benjamins and Raja Chatila and Francisco Herrera},
1935url = {https://www.sciencedirect.com/science/article/pii/S1566253519308103},
1936doi = {https://doi.org/10.1016/j.inffus.2019.12.012},
1937issn = {1566-2535},
1938year = {2020},
1939pages = {82-115},
1940volume = {58},
1941journal = {Information Fusion},
1942title = {Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI},
1943}
1944
1945@article{xai_review_2021,
1946pages = {3503-3568},
1947volume = {55},
1948year = {2022},
1949journal = {Artif. Intell. Rev.},
1950author = {Dang Minh and H. Xiang Wang and Y. Fen Li and Tan N. Nguyen},
1951title = {Explainable artificial intelligence: a comprehensive review},
1952}
1953
1954@misc{cyras2020machine,
1955primaryclass = {cs.AI},
1956archiveprefix = {arXiv},
1957eprint = {2009.00418},
1958year = {2020},
1959author = {Kristijonas Cyras and Ramamurthy Badrinath and Swarup Kumar Mohalik and Anusha Mujumdar and Alexandros Nikou and Alessandro Previti and Vaishnavi Sundararajan and Aneta Vulgarakis Feljan},
1960title = {Machine Reasoning Explainability},
1961}
1962
1963@inproceedings{datta2016algorithmic,
1964organization = {IEEE},
1965year = {2016},
1966pages = {598-617},
1967booktitle = {2016 IEEE symposium on security and privacy (SP)},
1968author = {Datta, Anupam and Sen, Shayak and Zick, Yair},
1969title = {Algorithmic transparency via quantitative input influence: Theory and experiments with learning systems},
1970}
1971
1972@article{shrikumar2016,
1973title = {Not Just a Black Box: Learning Important Features Through Propagating Activation Differences},
1974pages = {},
1975month = {05},
1976year = {2016},
1977author = {Shrikumar, Avanti and Greenside, Peyton and Shcherbina, Anna and Kundaje, Anshul},
1978}
1979
1980@article{strumbelj2014explaining,
1981publisher = {Springer},
1982year = {2014},
1983pages = {647-665},
1984number = {3},
1985volume = {41},
1986journal = {Knowledge and information systems},
1987author = {{\v{S}}trumbelj, Erik and Kononenko, Igor},
1988title = {Explaining prediction models and individual predictions with feature contributions},
1989}
1990
1991@article{10.1145/3398069,
1992keywords = {machine learning, health care, ethics, society + AI, AI applications, real-world interventions, interpretability, Mental health, interaction design, systematic review, mental illness},
1993numpages = {53},
1994articleno = {34},
1995month = {aug},
1996journal = {ACM Trans. Comput.-Hum. Interact.},
1997abstract = {High prevalence of mental illness and the need for effective mental health care, combined with recent advances in AI, has led to an increase in explorations of how the field of machine learning (ML) can assist in the detection, diagnosis and treatment of mental health problems. ML techniques can potentially offer new routes for learning patterns of human behavior; identifying mental health symptoms and risk factors; developing predictions about disease progression; and personalizing and optimizing therapies. Despite the potential opportunities for using ML within mental health, this is an emerging research area, and the development of effective ML-enabled applications that are implementable in practice is bound up with an array of complex, interwoven challenges. Aiming to guide future research and identify new directions for advancing development in this important domain, this article presents an introduction to, and a systematic review of, current ML work regarding psycho-socially based mental health conditions from the computing and HCI literature. A quantitative synthesis and qualitative narrative review of 54 papers that were included in the analysis surfaced common trends, gaps, and challenges in this space. Discussing our findings, we (i) reflect on the current state-of-the-art of ML work for mental health, (ii) provide concrete suggestions for a stronger integration of human-centered and multi-disciplinary approaches in research and development, and (iii) invite more consideration of the potentially far-reaching personal, social, and ethical implications that ML models and interventions can have, if they are to find widespread, successful adoption in real-world mental health contexts.},
1998doi = {10.1145/3398069},
1999url = {https://doi.org/10.1145/3398069},
2000issn = {1073-0516},
2001number = {5},
2002volume = {27},
2003address = {New York, NY, USA},
2004publisher = {Association for Computing Machinery},
2005issue_date = {October 2020},
2006year = {2020},
2007title = {Machine Learning in Mental Health: A Systematic Review of the HCI Literature to Support the Development of Effective and Implementable ML Systems},
2008author = {Thieme, Anja and Belgrave, Danielle and Doherty, Gavin},
2009}
2010
2011@article{Stepin2021,
2012doi = {10.1109/ACCESS.2021.3051315},
2013pages = {11974-12001},
2014number = {},
2015volume = {9},
2016year = {2021},
2017title = {A Survey of Contrastive and Counterfactual Explanation Generation Methods for Explainable Artificial Intelligence},
2018journal = {IEEE Access},
2019author = {Stepin, Ilia and Alonso, Jose M. and Catala, Alejandro and Pereira-Fari{\~n}a, Mart{\'i}n},
2020}
2021
2022@article{Burkart2021,
2023pages = {245-317},
2024year = {2021},
2025author = {Burkart, Nadia and Huber, Marco F.},
2026publisher = {AI Access Foundation},
2027doi = {10.1613/jair.1.12228},
2028issn = {1076-9757},
2029journal = {Journal of Artificial Intelligence Research},
2030volume = {70},
2031title = {A Survey on the explainability of Supervised machine learning},
2032}
2033
2034@misc{islam2021explainable,
2035primaryclass = {cs.AI},
2036archiveprefix = {arXiv},
2037eprint = {2101.09429},
2038year = {2021},
2039author = {Sheikh Rabiul Islam and William Eberle and Sheikh Khaled Ghafoor and Mohiuddin Ahmed},
2040title = {Explainable Artificial Intelligence Approaches: A Survey},
2041}
2042
2043@article{Beaudry2012AnIP,
2044pages = {432-441},
2045volume = {12},
2046year = {2012},
2047journal = {Quantum Inf. Comput.},
2048author = {Normand J. Beaudry and Renato Renner},
2049title = {An intuitive proof of the data processing inequality},
2050}
2051
2052@techreport{fare2022,
2053note = {\url{https://fare.org.au/transparency-report/}},
2054year = {2022},
2055institution = {Foundation for Alcohol research and education},
2056title = {Advertisements on digital platforms: How transparent and observable are they?},
2057author = {Kiah Hawker and
2058Nicholas Carah and
2059Daniel Angus and Aimee Brownbill and Xue Ying and Amy Dobson and Brady Robards},
2060}
2061
2062@article{Rook1986,
2063eprint = {https://academic.oup.com/jcr/article-pdf/14/2/189/5181402/14-2-189.pdf},
2064url = {https://doi.org/10.1086/209105},
2065doi = {10.1086/209105},
2066issn = {0093-5301},
2067abstract = {{What is impulse buying? Despite the marketing and lifestyle factors that encourage it today, impulse buying is not yet well understood. This is due in part to the longstanding absence of a compelling conceptualization of this distinctive type of purchasing behavior. This article reviews extant research on impulsive behavior and then introduces a new interpretation of impulse buying. Following this are the results of an exploratory study that investigates the phenomenology of consumers' impulse buying episodes. The research identifies: (1) the subjective experiences that distinguish the onset of the buying impulse, (2) how consumers cope with their impulsive urges to buy, and (3) the types of negative consequences they incur as a result of their impulsive buying.}},
2068month = {09},
2069year = {1987},
2070pages = {189-199},
2071number = {2},
2072volume = {14},
2073journal = {Journal of Consumer Research},
2074title = {{The Buying Impulse}},
2075author = {Rook, Dennis W.},
2076}
2077
2078@inproceedings{Mathur2021,
2079series = {CHI '21},
2080location = {Yokohama, Japan},
2081numpages = {18},
2082articleno = {360},
2083booktitle = {Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems},
2084abstract = {There is a rapidly growing literature on dark patterns, user interface designs—typically related to shopping or privacy—that researchers deem problematic. Recent work has been predominantly descriptive, documenting and categorizing objectionable user interfaces. These contributions have been invaluable in highlighting specific designs for researchers and policymakers. But the current literature lacks a conceptual foundation: What makes a user interface a dark pattern? Why are certain designs problematic for users or society? We review recent work on dark patterns and demonstrate that the literature does not reflect a singular concern or consistent definition, but rather, a set of thematically related considerations. Drawing from scholarship in psychology, economics, ethics, philosophy, and law, we articulate a set of normative perspectives for analyzing dark patterns and their effects on individuals and society. We then show how future research on dark patterns can go beyond subjective criticism of user interface designs and apply empirical methods grounded in normative perspectives.},
2085doi = {10.1145/3411764.3445610},
2086url = {https://doi.org/10.1145/3411764.3445610},
2087address = {New York, NY, USA},
2088publisher = {Association for Computing Machinery},
2089isbn = {9781450380966},
2090year = {2021},
2091title = {What Makes a Dark Pattern... Dark? Design Attributes, Normative Considerations, and Measurement Methods},
2092author = {Mathur, Arunesh and Kshirsagar, Mihir and Mayer, Jonathan},
2093}
2094
2095@article{Lorenz-Spreen2021,
2096bdsk-url-1 = {https://doi.org/10.1038/s41598-021-94796-z},
2097year = {2021},
2098volume = {11},
2099url = {https://doi.org/10.1038/s41598-021-94796-z},
2100title = {Boosting people's ability to detect microtargeted advertising},
2101pages = {15541},
2102number = {1},
2103journal = {Scientific Reports},
2104isbn = {2045-2322},
2105id = {Lorenz-Spreen2021},
2106doi = {10.1038/s41598-021-94796-z},
2107date-modified = {2022-11-16 11:40:07 +0100},
2108date-added = {2022-11-16 11:40:07 +0100},
2109date = {2021/07/30},
2110author = {Lorenz-Spreen, Philipp and Geers, Michael and Pachur, Thorsten and Hertwig, Ralph and Lewandowsky, Stephan and Herzog, Stefan M.},
2111abstract = {Online platforms'data give advertisers the ability to `microtarget''recipients'personal vulnerabilities by tailoring different messages for the same thing, such as a product or political candidate. One possible response is to raise awareness for and resilience against such manipulative strategies through psychological inoculation. Two online experiments (total {\$}{\$}N= 828{\$}{\$}) demonstrated that a short, simple intervention prompting participants to reflect on an attribute of their own personality---by completing a short personality questionnaire---boosted their ability to accurately identify ads that were targeted at them by up to 26 percentage points. Accuracy increased even without personalized feedback, but merely providing a description of the targeted personality dimension did not improve accuracy. We argue that such a `boosting approach,''which here aims to improve people's competence to detect manipulative strategies themselves, should be part of a policy mix aiming to increase platforms'transparency and user autonomy.},
2112}
2113
2114@misc{Covington2022,
2115year = {2022},
2116publisher = {Inside Privacy, Covington},
2117note = {\url{https://www.insideprivacy.com/advertising-marketing/eu-rules-on-online-targeted-advertising/}},
2118date = {August 31},
2119author = {Dan Cooper and Anna Oberschelp de Meneses and Diane Valat},
2120title = {EU Rules on Online Targeted Advertising},
2121}
2122
2123@article{Kalimeri2019,
2124doi = {https://doi.org/10.1016/j.chb.2018.11.024},
2125pages = {428-445},
2126volume = {92},
2127journal = {Computers in Human Behavior},
2128title = {Predicting demographics, moral foundations, and human values from digital behaviours},
2129year = {2019},
2130author = {Kalimeri, Kyriaki Beir{\'o} and Mariano G. Delfino and Matteo Raleigh, Robert and Cattuto, Ciro},
2131}
2132
2133@article{deepfake_ecg,
2134url = {https://europepmc.org/articles/PMC8578227},
2135pages = {21896},
2136issn = {2045-2322},
2137journal = {Scientific reports},
2138year = {2021},
2139month = {November},
2140volume = {11},
2141number = {1},
2142doi = {10.1038/s41598-021-01295-2},
2143author = {Thambawita, Vajira and Isaksen, Jonas L and Hicks, Steven A and Ghouse, Jonas and Ahlberg, Gustav and Linneberg, Allan and Grarup, Niels and Ellervik, Christina and Olesen, Morten Salling and Hansen, Torben and Graff, Claus and Holstein-Rathlou, Niels-Henrik and Strümke, Inga and Hammer, Hugo L and Maleckar, Mary M and Halvorsen, Pål and Riegler, Michael A and Kanters, Jørgen K},
2144title = {DeepFake electrocardiograms using generative adversarial networks are the beginning of the end for privacy issues in medicine},
2145}
2146
2147@article{chen2021synthetic,
2148publisher = {Nature Publishing Group},
2149year = {2021},
2150pages = {493--497},
2151number = {6},
2152volume = {5},
2153journal = {Nature Biomedical Engineering},
2154author = {Chen, Richard J and Lu, Ming Y and Chen, Tiffany Y and Williamson, Drew FK and Mahmood, Faisal},
2155title = {Synthetic data in machine learning for medicine and healthcare},
2156}
2157
2158@article{Harnish2021,
2159abstract = {We applied both a cross-sectional design and an experience sampling method to the study of compulsive buying. A sample was drawn from Prolific Academic comprised of undergraduate students in the U.S., which was supplemented by a sample of undergraduate students who attended a public university in the northeast U.S. Results from the cross-sectional design revealed that lower detachment and higher antagonism conceived by the DSM-5's dimensional model of pathological personality traits, as well as lower pain of paying (the anticipated negative affect associated with spending one's money), predicted greater compulsive buying. Results from the experience sampling design indicated that higher antagonism was related to increased spending preoccupation, and that greater interpersonal conflict was related to both greater spending behavior and increased spending preoccupation. Finally, results revealed a moderation effect for detachment and academic load on spending behavior such that those who were high in detachment and reported a lower academic load engaged in more spending habits. Results are discussed in terms of how pathological personality traits and spending habits are impacted by interpersonal constructs that influence spending habits.},
2160keywords = {Compulsive buying, Pain of paying, Experience sampling, Detachment, Antagonism, Interpersonal conflicts},
2161author = {Richard J. Harnish and Michael J. Roche and K. Robert Bridges},
2162url = {https://www.sciencedirect.com/science/article/pii/S0191886921001963},
2163doi = {https://doi.org/10.1016/j.paid.2021.110821},
2164issn = {0191-8869},
2165year = {2021},
2166pages = {110821},
2167volume = {177},
2168journal = {Personality and Individual Differences},
2169title = {Predicting compulsive buying from pathological personality traits, stressors, and purchasing behavior},
2170}
2171
2172@article{Rafieian2021,
2173abstract = { Mobile in-app advertising is now the dominant form of digital advertising. Although these ads have excellent user-tracking properties, they have raised concerns among privacy advocates. This has resulted in an ongoing debate on the value of different types of targeting information, the incentives of ad networks to engage in behavioral targeting, and the role of regulation. To answer these questions, we propose a unified modeling framework that consists of two components—a machine learning framework for targeting and an analytical auction model for examining market outcomes under counterfactual targeting regimes. We apply our framework to large-scale data from the leading in-app ad network of an Asian country. We find that an efficient targeting policy based on our machine learning framework improves the average click-through rate by 66.80\% over the current system. These gains mainly stem from behavioral information compared with contextual information. Theoretical and empirical counterfactuals show that although total surplus grows with more granular targeting, the ad network’s revenues are nonmonotonic; that is, the most efficient targeting does not maximize ad network revenues. Rather, it is maximized when the ad network does not allow advertisers to engage in behavioral targeting. Our results suggest that ad networks may have economic incentives to preserve users’ privacy without external regulation. },
2174eprint = {
2175
2176https://doi.org/10.1287/mksc.2020.1235
2177
2178},
2179url = {
2180
2181https://doi.org/10.1287/mksc.2020.1235
2182
2183},
2184doi = {10.1287/mksc.2020.1235},
2185year = {2021},
2186pages = {193-218},
2187number = {2},
2188volume = {40},
2189journal = {Marketing Science},
2190title = {Targeting and Privacy in Mobile Advertising},
2191author = {Rafieian, Omid and Yoganarasimhan, Hema},
2192}
2193
2194@misc{tappin2022,
2195month = {Nov},
2196year = {2022},
2197author = {Tappin, Ben M and Wittenberg, Chloe and Hewitt, Luke and berinsky, adam and Rand, David G},
2198publisher = {PsyArXiv},
2199doi = {10.31234/osf.io/dhg6k},
2200url = {psyarxiv.com/dhg6k},
2201title = {Quantifying the Persuasive Returns to Political Microtargeting},
2202}Attribution
arXiv:2301.04993v1
[cs.AI]
License: cc-by-4.0


