
- Papers
Papers is Alpha. This content is part of an effort to make research more accessible, and (most likely) has lost some details from the original. You can find the original paper here.
Introduction
With the rise of automation and digitization, the term “big data” has become ubiquitous across a wide range of industries. The rapid growth of cloud computing and tremendous progress in machine learning has attracted businesses to hire ML engineers to make the most value out of their data. ML has grown in popularity as a solution to various software engineering issues, including speech recognition, image processing, natural language processing etc. Nevertheless, The development of an ML model requires significant human expertise. It is necessary to use intuition based on prior knowledge and experience to determine the best ML algorithm/architecture for each dataset. This high demand of ML expertise coupled with the shortage of ML developers and the repetitive nature of many ML pipeline processes have inspired the adoption of low-code machine learning (i.e., AutoML) tools/platforms.
The primary goal of low-code AutoML services is to reduce the manual efforts of developing different ML pipelines, which thus helps in accelerating their development and deployment. This is necessary due to the fact that a business may have a specific business requirement and the domain experts/stakeholders in the business know it, but they lack the skills to develop an ML application. Indeed, for ML development, there are often primarily two key users as follows.
-
Domain Experts are knowledgeable about the problem domain (e.g., rain forecasting, cancer diagnosis, etc.) where the ML is applied. So that they have a deep understanding of the scope of the problem and the dataset.
-
ML Experts are experienced with the nuances of the ML model. They have a greater understanding and experience in selecting the appropriate ML algorithm/architecture, engineering features, training the model, and evaluating its performance.
Both of the domain and ML experts are equally important for the success of the ML-based solution development, and are often complementary to each other during the design and development of the solutions. AutoML aims to make ML more accessible to domain experts by providing end-to-end abstraction from data filtering to model designing & training to model deployment & monitoring. AutoML is becoming an essential topic for software engineering researchers as more and more AutoML applications are developed and deployed. AutoML research is progressing rapidly as academia and industry work collaboratively by making ML research their priority. For example, currently, in at least some experimental settings, AutoML tools yield better results than manually designed models by ML experts(c.f. background of AutoML in sec-background).
Machine learning practitioners face many challenges because of the interdisciplinary nature of the ML domain. They require not only the software engineering expertise to configure and set up new libraries but also in data visualization, linear algebra and statistics. There have been quite some studieson the challenges of deep learning and ML tools, but there are no formal studies on the challenges AutoML practitioners have asked about on public forums. There are also studies on developers’ discussion on machine learning domainand deep learning frameworks, but there are no studies on low-code, i.e., AutoML tools/platforms (c.f. related work in sec-related-work).
The online developer forum Stack Overflow (SO) is the most popular Q&A site with around 120 million posts and 12 million registered users. Several research has conducted by analyzing developers’ discussion of SO posts (e.g., traditional low-code practitioners discussion, IoT, big data, blockchain, docker developers challenges, concurrency, microservices) etc. The increasing popularity and distinctive character of low-code ML software development approaches (i.e., AutoML tools/frameworks) make it imperative for the SE research community to explore and analyze what practitioners shared publicly. To that end, in this paper, we present an empirical study of 14.3K SO posts (e.g., 10.5k Q + 3.3k Acc Ans) relating to AutoML-related discussion in SOto ascertain the interest and challenges of AutoML practitioners (c.f. study methodology in sec-methodology). We use SOTorrent datasetand Latent Dirichlet Allocation (LDA) to systematically analyze practitioners’ discussed topics similar to other studies. We explore the following four research questions by analyzing the dataset (c.f. results in sec-results).
RQ1. What topics do practitioners discuss regarding AutoML services on SO? As low-code machine learning (i.e., AutoML) is an emerging new paradigm, it is vital to study publicly shared queries by AutoML practitioners on a Q&A platform such as SO. We extract 14.3K AutoML related SO posts and apply the LDA topic modelling methodto our dataset. We find a total of 13 AutoML-related topics grouped into four categories: MLOps (43% Questions, 5 topics),Model (28% Questions, 4 topics), Data (27% Questions, 3 topics), and Documentation (2% Questions, topic). We find that around 40% of the questions are related to supported features of a specific AutoML solution providers, around 15% of questions are related to model design and development, and 20% of questions are related to data pre-processing and management. We find relatively fewer questions on programming, and details configuration on ML algorithm as AutoML aims to provide a higher level abstraction over data processing and model design and development pipeline. However, AutoML practitioners still struggle with development system configuration and model deployment.
RQ2. How AutoML topics are distributed across machine learning life cycle phases? AutoML aims to provide an end-to-end pipeline service to streamline ML development. The successful adoption of this technology largely depends on how effective this is on different machine learning life cycle (MLLC) phases. So, following related studies, we manually analyze and annotate 348 AutoML questions into one of six ML life cycle stages by taking statically significant questions from all the four topic categories. We find that Model training, i.e., the implementation phase is the most dominant (28.7% questions), followed by Data Preparation (24.7% questions) and Model Designing (18.7% questions).
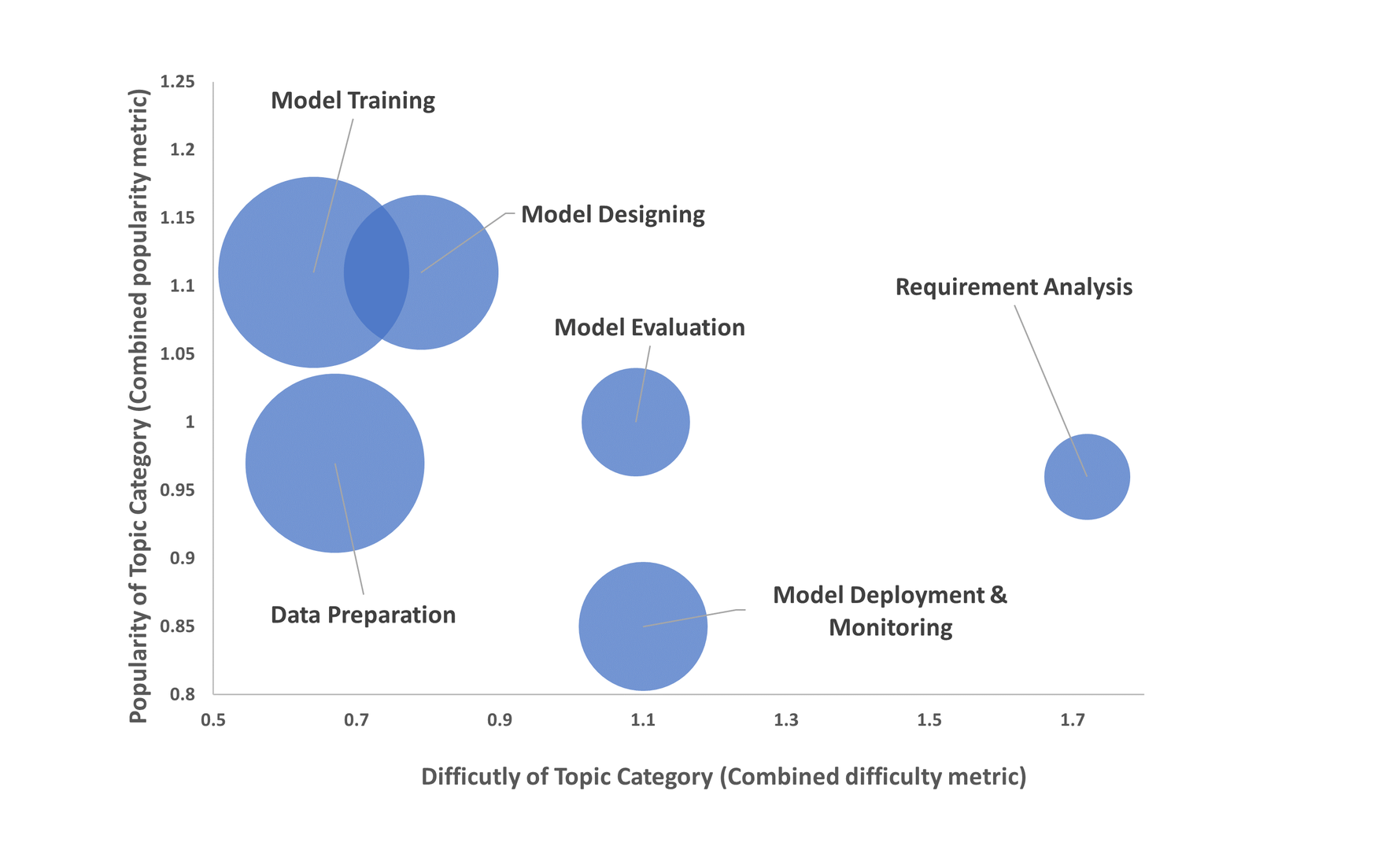
RQ3. What AutoML topics are most popular and difficult on SO? From our previous research questions, we find that AutoML practitioners discuss diverse topics in different stages of machine learning development. However, some of these questions are popular and have larger community support. We find that AutoML practitioners find the MLOps topic category most popular and challenging. AutoML practitioners find the Requirement Analysis phase the most challenging and popular, followed by the model deployment & monitoring MLLC phase. We find that AutoML practitioners find Model Deployment & Load topic to be most challenging regarding the percentage of questions without accepted answers and median hours required to get accepted answers. We also find that questions related to improving the performance of AutoML models are most popular among AutoML practitioners regarding average view count and average score.
RQ4. How does the topic distribution between cloud and non-cloud AutoML services differ? Our analyzed dataset contains both cloud-based and non-cloud-based AutoML services. Cloud-based solutions provides an end-to-end pipeline for data collecting to model operationalization, whereas non-cloud-based services offer greater customizability for data preparation and model development. We find that, in our dataset around 65% SO questionsbelong to cloud and 35% belong to non-cloud based AutoML solution. Cloud-based AutoML solution predominate over Model Deployment and Monitoring phase (82%) and non-cloud based AutoML solution predominate over Model Evaluation phase. MLOps topic category (i.e., 80%) is predominated over cloud-based AutoML solutions, while Model (i.e., 59%) topic category is predominated by non-cloud based AutoML solutions. Our study findings offer valuable insights to AutoML researchers, service providers, and educators regarding what aspect of AutoML requires improvement from the practitioners’ perspective (c.f. discussions and implications in sec-discussion). Specifically, our findings can enhance our understanding of the AutoML practitioners’ struggle and help the researchers and platform vendors better focus on the specific challenges. For example, AutoML solutions lack better support for deployment, and practitioners can prepare for potentially challenging areas. In addition, all stakeholders and practitioners of AutoML can collaborate to provide enhanced documentation and tutorials. The AutoML service vendors can better support model deployment, monitoring and fine-tuning.
Replication Package: The code and data are shared in https://github.com/disa-lab/automl-challenge-so
Background
AutoML as Low-code Tool/Platform for ML
Recent advancements in machine learning (ML) have yielded highly promising results for a variety of tasks, including regression, classification, clustering, etc., on diverse dataset types (e.g., texts, images, structured/unstructured data). The development of an ML model requires significant human expertise. Finding the optimal ML algorithm/architecture for each dataset necessitates intuition based on past experience. ML-expert and domain-expert collaboration is required for these laborious and arduous tasks. The shortage of ML engineers and the tedious nature of experimentation with different configuration values sparked the idea of a low-code approach for ML. This low-code machine learning solution seeks to solve this issue by automating some ML pipeline processes and offering a higher level of abstraction over the complexities of ML hyperparameter tuning, allowing domain experts to design ML applications without extensive ML expertise. It significantly increases productivity for machine learning practitioners, researchers, and data scientists. The primary goal of low-code AutoML tools is to reduce the manual efforts of different ML pipelines, thus accelerating their development and deployment.
In general terms, a machine learning program is a program that can learn from experience, i.e., data. In the traditional approach, a human expert analyses data and explores the search space to find the best model. AutoMLaims to democratize machine learning to domain experts by automating and abstracting machine learning-related complexities. It aims to solve the challenge of automating the Combined Algorithm Selection and Hyper-parameter tuning (CASH) problem. AutoML is a combination of automation and ML. It automates various tasks on the ML pipeline such as data prepossessing, model selection, hyper-parameter tuning, and model parameter optimization. They employ various types of techniques such as grid search, genetics, and Bayesian algorithms. Some AutoML services also help with data visualization, model interpretability, and deployment. It helps non-ML experts develop ML applications and provides opportunities for ML experts to engage in other tasks. The lack of ML experts and exponential growth in computational power make AutoML a hot topic for academia and the industry. Research on AutoML research is progressing rapidly; in some cases, at least in the experimental settings, AutoML tools are producing the best hand-designed models by ML experts.
AutoML Approaches


AutoML approach can be classified into two categories
-
AutoML for traditional machine learning algorithms. It focuses on data pre-processing, feature engineering (i.e., finding the best set of variables and data encoding technique for the input dataset), ML algorithm section, and hyperparameter tuning.
-
AutoML for deep learning algorithms: this includes Neural architecture search (NAS), which generates and assesses a large number of neural architectures to find the most fitting one by leveraging reinforcement learningand genetic algorithm.
Figure fig-automl-nas provides a high-level overview of AutoML for NAS and hyper-parameter optimization. The innermost circle represents the NAS exploration for the DL models, and the middle circle represents the hyper-parameter optimization search for both NAS and traditional ML applications.
AutoML Services
Depending on their mode of access/delivery, currently availalbe AutoML tools can be used over the cloud or via a stand-alone application in our desktop or internal server computers.
AutoML Cloud Service/Platforms. Large cloud providers and tech businesses started offering Machine Learning as a Service projects to make ML even more accessible to practitioners due to the rising popularity of AutoML tools. Some of these platforms specialize in various facets of AutoML, such as structured/unstructured data analysis, computer vision, natural language processing, and time series forecasting. In 2016, Microsoft released AzureMLruns on top of Azure cloud and assists ML researchers/engineers with data processing and model development. H2O Automlwas released in 2016, followed by H2O-DriverlessAIin 2017. It is a customizable data science platform with automatic feature engineering, model validation and selection, model deployment, and interpretability. In 2017 Google released Google Cloud AutoMLthat provides end-to-end support to train the custom model on the custom dataset with minimal effort. Some other notable cloud platforms are Darwin (2018)AutoML cloud platform for data science and business analytics, TransmogrifAI (2018)runs on top of Salesforce’s Apache Spark ML for structured data. This cloud-based AutoML platform enables end-to-end data analytics and AI solutions for nearly any sector.
AutoML Non-cloud Service (Tools/Library). The initial AutoML tools were developed in partnership with academic researchers and later by startups and large technology corporations. Researchers from the University of British Columbia and Freiburg Auto-Weka (2013), which is one of the first AutoML tools. Later, researchers from the University of Pennsylvania developed TPOT (2014), and researchers from the University of Freiburg released Auto-Sklearn (2014). These three AutoML tools provide a higher level abstraction over the popular ML library “SciKit-Learn” (2007). A similar research effort was followed to provide an automated ML pipeline over other popular ML libraries. University of Texas A&M University developed Auto-Keras (2017)that provides runs on top of Kerasand TensorFlow. Some of the other notable AutoML tools are MLJar (2018), DataRobot (2015), tool named “auto_ml” (2016). These AutoML tools provide a higher level of abstraction over traditional ML libraries such as TensorFlow, Keras, and Scikit-learn and essentially automate some ML pipeline steps (i.e., algorithm selection and hyper-parameter turning).
In Figure fig-automl-pipeline, we summarize the ML pipeline services offered by AutoML services. Traditional ML pipeline consists of various steps such as Model requirement, Data processing, feature engineering, model deigning, model evaluation, deployment, and monitoring. AutoML solutions aim to automate various stages of these pipelines, from data cleaning to Model deployment(Fig. fig-automl-pipeline). AutoML non-cloud solutions (i.e., tools/frameworks) mainly focus on automating different data filtering, model selection, and hyperparameter optimization. AutoML cloud platforms encapsulate the services of AutoML tools and provide model deployment and monitoring support. They usually provide the necessary tools for data exploration and visualization.
Study Data Collection and Topic Modeling
In this Section, we discuss our data collection process to find AutoML-related discussion, i.e., posts (Section sub-sec-data-collection). Then, we discuss in detail our data pre-processing and topic modeling steps on these posts (Section sub-sec-topic-modeling).
Data Collection
We collectAutoML related SO posts in the following three steps: [(1)]
-
Download SO data dump,
-
Identify AutoML-related tag list, and
-
Extract AutoML-related posts using our AutoML tag list. We describe the steps in detail below.
Step 1: Download SO data dump. For this study, we use the most popular Q&A site, Stack Overflow (SO), where practitioners from diverse backgrounds discuss various software and programming-related issues. First, we download the latest SO data dumpof June 2022, available during the start of this study. Following related studies, we use the contents of the “Post.xml” file, which contains information about each post like the post’s unique ID, title, body, associated tags, type (Question or Answer), creation date, favorite count, view-count, etc. Our data dump includes developers’ discussions of 14 years from July 2008 to June 2022 and contains around 56,264,787 posts. Out of them, 22,634,238 (i.e., 40.2%) are questions, 33,630,549 (i.e., 59.7%) are answers, and 11,587,787 questions (i.e., 51.19%) had accepted answers. Around 12 million users from all over the world participated in the discussions.
Each SO post contains 19 attributes, and some of the relevant attributes for this study are: [(1)]
-
Post’s unique Id, and creation time,
-
Post’s body with problem description and code snippets,
-
Post’s score, view, and favorite count,
-
Tags associated with a post,
-
Accepted answer Id.
Step 2: Identify AutoML tags. We need to identify AutoML related SO tags to extract AutoML-related posts, i.e., practitioners’ discussions. We followed a similar procedure used in prior workto find relevant SO tags. In Step 1, we identify the initial AutoML-related tags and call them $T_{init}$ . In Step 2, we finalize our AutoML tag list following approaches of related work. Our final tag list $T_{final}$ contains 41 tags from the top 18 AutoML service providers. We discuss each step in detail below.
(1) Identifying Initial AutoML tags. Following our related work, first, we compile a list of topAutoML services. First, we make a query in google with the following two search terms “top AutoML tools” and “top AutoML platforms”. We select the first five search results for each query that contain various websites ranked the best AutoML tools/platforms. The full list of these websites is available in our replication package. So, from these ten websites and the popular technological research website Gartner[https://www.gartner.com/reviews/market/data-science-machine-learning-platforms] we create a list of 38 top AutoML solutions. Then for each of these AutoML platforms, we search for SO tags. For example, We search for “AutoKeras” via the SO search engine. We find a list of SO posts discussing the AutoKeras tool. We compile a list of potential tags for this platform. For example, we notice most of these questions contain “keras” and “auto-keras” tags. Then, we manually examine the metadata of these tags [https://meta.stackexchange.com/tags]. For example, the metadata for the “auto-keras” tag says, “Auto-Keras is an open source software library for automated machine learning (AutoML), written in python. A question tagged auto-keras should be related to the Auto-Keras Python package.” The metadata for the “keras” tag says, “Keras is a neural network library providing a high-level API in Python and R. Use this tag for questions relating to how to use this API. Please also include the tag for the language/backend ([python], [r], [tensorflow], [theano], [cntk]) that you are using. If you are using tensorflow’s built-in keras, use the [tf.keras] tag.”. Therefore, we choose the “auto-keras” tag for the “AutoKeras” AutoML library. Not all AutoML platforms have associated SO tags; thus, they were excluded. For example, for AutoFolioAutoML library, there are no SO tags; thus, we exclude this from our list. This way, we find 18 SO tags for 18 AutoML services and call it $T_{init}$ . The final AutoML solutions and our initial tag list are available in our replication package.
(2) Finalizing AutoML-related tags. Intuitively, there might be variations to tags of 18 AutoML platforms other than those in $T_{init}$ . We use a heuristic technique from related previousworksto find the other relevant AutoML tags. First, we denote the entire SO data as $Q_{all}$ . Second, we extract all questions $Q$ that contain any tag from $T_{init}$ . Third, we create a candidate tag list $T_{candidate}$ using the relevant tags in the questions $Q$ . Fourth, we analyze and select significantly relevant tags from$T_{candidate}$ for ourAutoML discussions. Following related works, we compute relevance and significance for each tag $t$ in $T_{candidate}$ with respect to $Q$ (i.e., the extracted questions that have at least one tag in $T_{init}$ ) and $Q_{all}$ (i.e., our data dump) as follows,
\[ ( Significance) \ \ S_{tag} \ =\ \ \frac{\#\ of\ ques.\ with\ the\ tag\ t\ in\ Q}{\ \ \#\ of\ ques.\ with\ the\ tag\ t\ in\ Q_{all}} \]\[ ( Relevance) \ \ R_{tag} \ =\ \ \frac{\#\ of\ questions\ with\ tag\ t\ in\ Q}{\ \ \#\ of\ questions\ in\ Q} \] A tag $t$ is significantly relevant toAutoML if the $S_{tag}$ and$R_{tag}$ are higher than a threshold value. Similar to related study, we experimented with a wide range of values of $S_{tag}$ = {0.05, 0.10, 0.15, 0.20, 0.25, 0.30, 0.35} and$R_{tag}$ = {0.001, 0.005, 0.010, 0.015, 0.020, 0.025, 0.03}. From our analysis, we find that we increase $S_{tag}$ and$R_{tag}$ the total number of recommend tags decreases. For example, we find that for $S_{tag}$ = .05 and$R_{tag}$ = 0.001 the total number of recommended tags for AutoML is 30 which is highest. However, not all these recommended tags are AutoML-related. For example, “amazon-connect” tag’s $S_{tag}$ = 0.24 and $R_{tag}$ = 0.006 and this tag is quite often associated with questions related to other AutoML tags such as “aws-chatbot”, “amazon-machine-learning” but it mainly contains discussion related to AWS cloud based contact center solutions rather than AutoML related discussion. So, we remove this from our final tag list. Similarly, we find some other tags such as “splunk-formula”, “amazon-ground-truth” etc are frequently correlated with other AutoML platform tags, although they do not contain AutoML related discussions. After manually analysing these 31 tags we find that 23 new tags are relevant to AutoML-related discussions. So, after combining with out initial taglist, i.e., $T_{init}$ , our final tag list $T_{final}$ contains 41 significantly relevant AutoML-related tags which are:
- Final Tag List $T_{final}$
= {
amazon-machine-learning',automl’,aws-chatbot',aws-lex’,azure-machine-learning-studio',azure-machine-learning-workbench’,azureml',azureml-python-sdk’,azuremlsdk',driverless-ai’,ensemble-learning',gbm’,google-cloud-automl-nl',google-cloud-vertex-ai’,google-natural-language',h2o.ai’,h2o4gpu',mlops’,sparkling-water',splunk-calculation’,splunk-dashboard',splunk-query’,splunk-sdk',amazon-sagemaker’,tpot',auto-sklearn’,rapidminer',pycaret’,amazon-lex',auto-keras’,bigml',dataiku’,datarobot',google-cloud-automl’,h2o',mljar’,splunk',transmogrifai’,ludwig',azure-machine-learning-service’, `pycaret'}
Step 3: Extracting AutoML related posts. Hence, our final dataset $B$ contained 14,341posts containing 73.7% Questions (i.e., 10,549 Q) and 26.3% Accepted Answers (i.e., 3,792).
Topic Modeling
We produceAutoML topics from the extracted posts in three steps: [(1)]
-
Preprocess the posts,
-
Find the optimal number of topics, and
-
Generate topics. We discuss the steps in detail below.
Step 1. Preprocess the posts. For each post text, we remove noise using the technique in related works. First, we remove the code snippets from the post body, which is inside code/code tag, HTML tags such as (p/p, a/a, li/li etc.), and URLs. Then we remove the stop words such as “am”, “is”, “are”, “the”, punctuation marks, numbers, and non-alphabetical characters using the stop word list from MALLET, NLTK. After this, we use porter stemmerto get the stemmed representations of the words, e.g., “waiting”, “waits” - all of which are stemmed to the base form of the word “wait”.
Step 2. Finding the optimal number of topics. After the prepossessing, we use Latent Dirichlet Allocationand the MALLET toolto find out the AutoML-related topics in our SO discussions. We follow similar studies using topic modelingin SO dataset. Our goal is to find the optimal number of topics $K$ for our AutoML dataset $B$ so that the coherence score is high, i.e., encapsulation of underlying topics is more coherent. We use Gensim packageto determine the coherence score following previous research. We experiment with different values of $K$ that range from {5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70} and for each value, we runMALLET LDA on our dataset for 1000 iterations. Then we observe how the coherence score changes with respect to $K$ . As LDA topic modeling has some inherited randomness, we ran our experiment 3 times and found that we got the highest coherence score for $k$ = 15. Choosing the right value of $K$ is crucial because multiple real-world topics merge for smaller values of $K$ , and for a large value of $K$ , a topic breaks down. MALLET uses two hyper-parameters, $\alpha$ , and $\beta$ , to distribute words and posts across the generated topics. Following the previous works, in this study we use the standard values $50/K$ and 0.01 for hyper-parameters $\alpha$ and $\beta$ in our experiment.
Step 3. Generating topics. Topic modeling is a systematic approach to extracting a set of topics by analyzing a collection of documents without any predefined taxonomy. Each document, i.e., the post, has a probability distribution of topics, and every topic has a probability distribution of a set of related words. We generate 15 topics using the above LDA configuration on our AutoML dataset $B$ . Each topic model provides a list of the top $N$ words and a list of $M$ posts associated with the topic. A topic in our context comprises the 30 most commonly co-related terms, which indicate an AutoML development-related concept. Each post has a correlation score between 0 to 1, and following the previous work, we assign a document, i.e., a post with a topic that corresponds most.
Empirical Study
We answer the following four research questions by analyzing the topics we found in our 14.3K AutoML related posts in Stack Overflow (SO).
-
What topics do practitioners discuss regarding AutoML services on SO?
-
How are the AutoML topics distributed across machine learning life cycle phases?
-
What AutoML topics are most popular and difficult on SO?
-
How does the distribution of the topics differ between cloud and non-cloud AutoML services?
Discussions

Evolution of AutoML related discussion
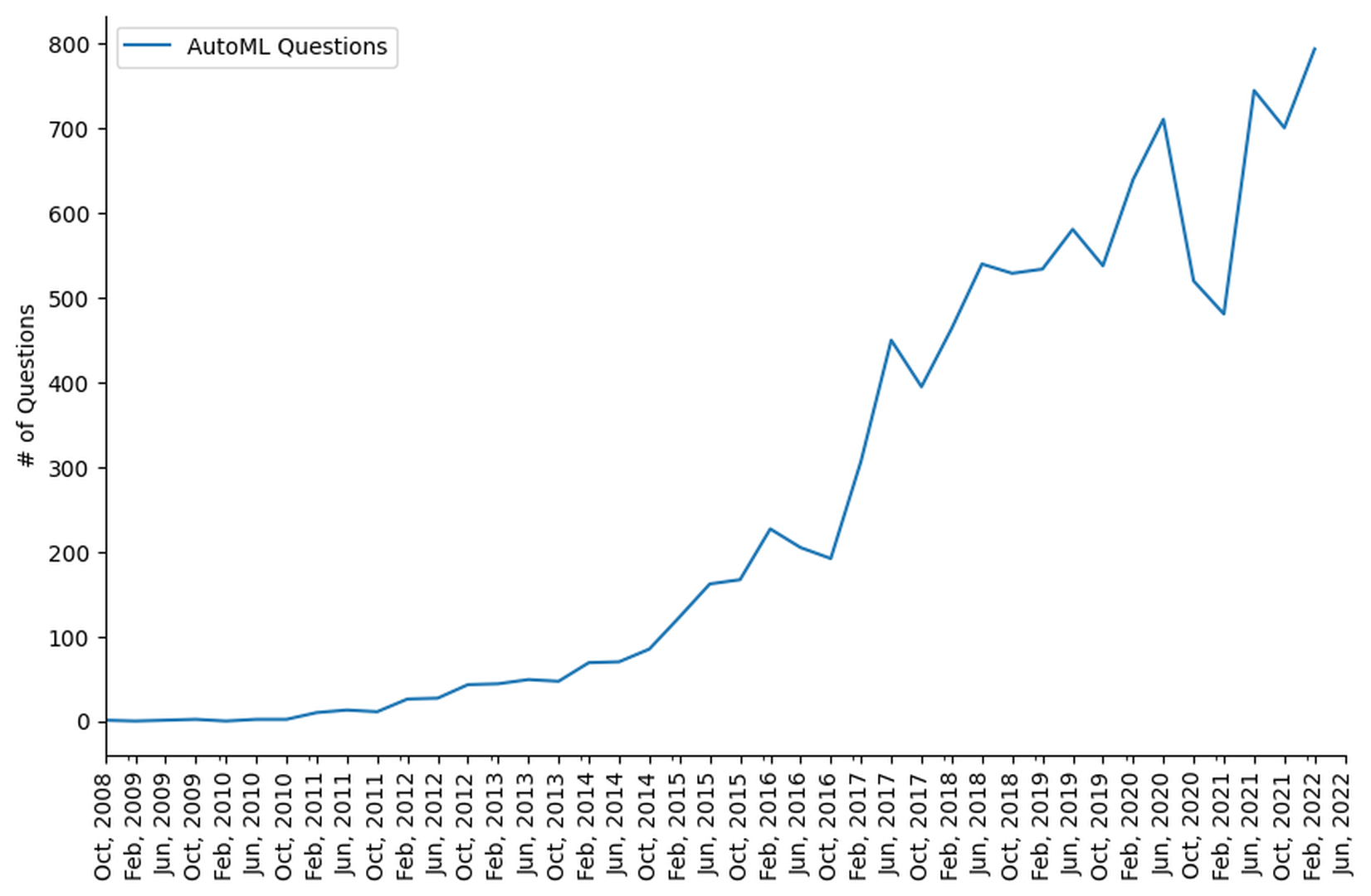

Figure fig-all-questions-evolution depicts the progression of overallAutoML-related discussion from our extracted dataset between 2008 to 2022. Additionally, it demonstrates that AutoML-related discussion is gaining popularity in mid-2016 (i.e., more than 200 questions per quarter). Figure fig-all-questions-evolution shows that during the first quarter of 2021, the total number of AutoML questions on Stack Overflow experiences a considerable decrease (i.e., about 25%), primarily due to the low number of queries in Splunk and Amazon Sagemaker during the pandemic. However, Amazon launches a suite of new AutoML services at the start of 2021, and the overall trend for AutoML-related discussion shows an upward trend. We provide a more detailed explanation for Figure fig-all-questions-evolution below.
MLOps This is the largest AutoML topic category, with around 43% of AutoML-related questions and five AutoML topics. From Figure fig-topic-cat-evolution, we can see this topic category began to gain popularity from the start of 2017, i.e., after big tech companies started to offer AutoML cloud platform services (sub-sec-automl). From 2017 to 2022, AutoML library and cloud platform management-related topics remain the most popular in this category (e.g., issues with installing the library in different platforms 61883115). From the beginning of 2017 to mid-2018 AutoML cloud platform’s bot development-related queries were quite popular (e.g., “Filling data in response cards with Amazon Lex” in47970307). Around that time, Amazon Lex (2017) was released, a fully managed solution to design, build, test and deploy conversational AI solutions. From our analysis, we can see the rise of Pipeline Automation-related discussion from the beginning of 2019 (e.g., issues related to the deployment pipeline in 55353889). We also notice a significant rise in the number of questions related to model load and deployment from 2019 to 2022 (e.g., “Custom Container deployment in vertex ai” in 69316032).
Model This is the second largest AutoML topic category, with around 28% of AutoML-related questions and four AutoML topics. From Figure fig-topic-cat-evolution, we can see that, similar to MLOps; the Model topic category began to gain popularity from the start of 2017. The dominant topic in this category is the Model performance improvement-related queries using AutoML services (e.g., “Grid Search builds models with different parameters (h2o in R) yields identical performance - why?” in 47475848, “How to understand the metrics of H2OModelMetrics Object through h2o.performance” in 43699454). From our analysis, we see around a 200% increase in the number of questions in Model training and monitoring topic from 2021 to mid-2021. So practitioners ask queries regarding training issues (e.g., “Training Google-Cloud-Automl Model on multiple datasets” in 68764644, 56048974)from practitioners in recent times. Other topics related to model design, model implementation, and debugging evolved homogeneously around this time.
Data This is the third largest AutoML topic category, with around 27% of AutoML-related questions and three AutoML topics. The Data Management topic is the most dominant topic in this category. From our analysis, we can see around a 60% increase in the number of queries on cloud data management, especially after Splunk cloud becomes available on the google cloud platform. So, we can see developers’ queries related to data transfer (e.g., in 63151824), REST API (e.g., in 63152602), API rate limitation (e.g., in 63292162) becomes popular. Other topics from this category evolve homogeneously over time.
Documentation This is the smallest AutoML topic category with around 2% of AutoML-related questions and one AutoML topic. We find that Since 2015 questions from this category shifted slightly from API-specific details (e.g., 35562896) to documentation-related limitations for cloud deployment (e.g., 59328925), containerization (e.g., 68888281).
Top AutoML service providers

In Figure fig-top-automl-platforms, we present the evolution of the top seven AutoML solutions in terms of the number of SO questions over the past decade. In our dataset, Amazon Sagemaker, is the largest AutoML platform containing around 20% of all the SO questions followed by Splunk (19%), H2O AI (17%), Azure Machine Learning, Amazon Lex, Google Cloud AutoML, and Rapid Miner. Among these AutoML service providers, H2O AI AI began in mid-2017 with the release of their H2O.ai driverless AI cloud platform, but since then, it has been steadily losing practitioners’ engagement in SO. We also observe that from its release in 2017 AWS SageMaker cloud platform remains dominating, with a notable surge occurring in the middle of 2021. Other AutoML platforms likewise demonstrate an overall upward trend.
AutoML service providers’ support on SO discussion.
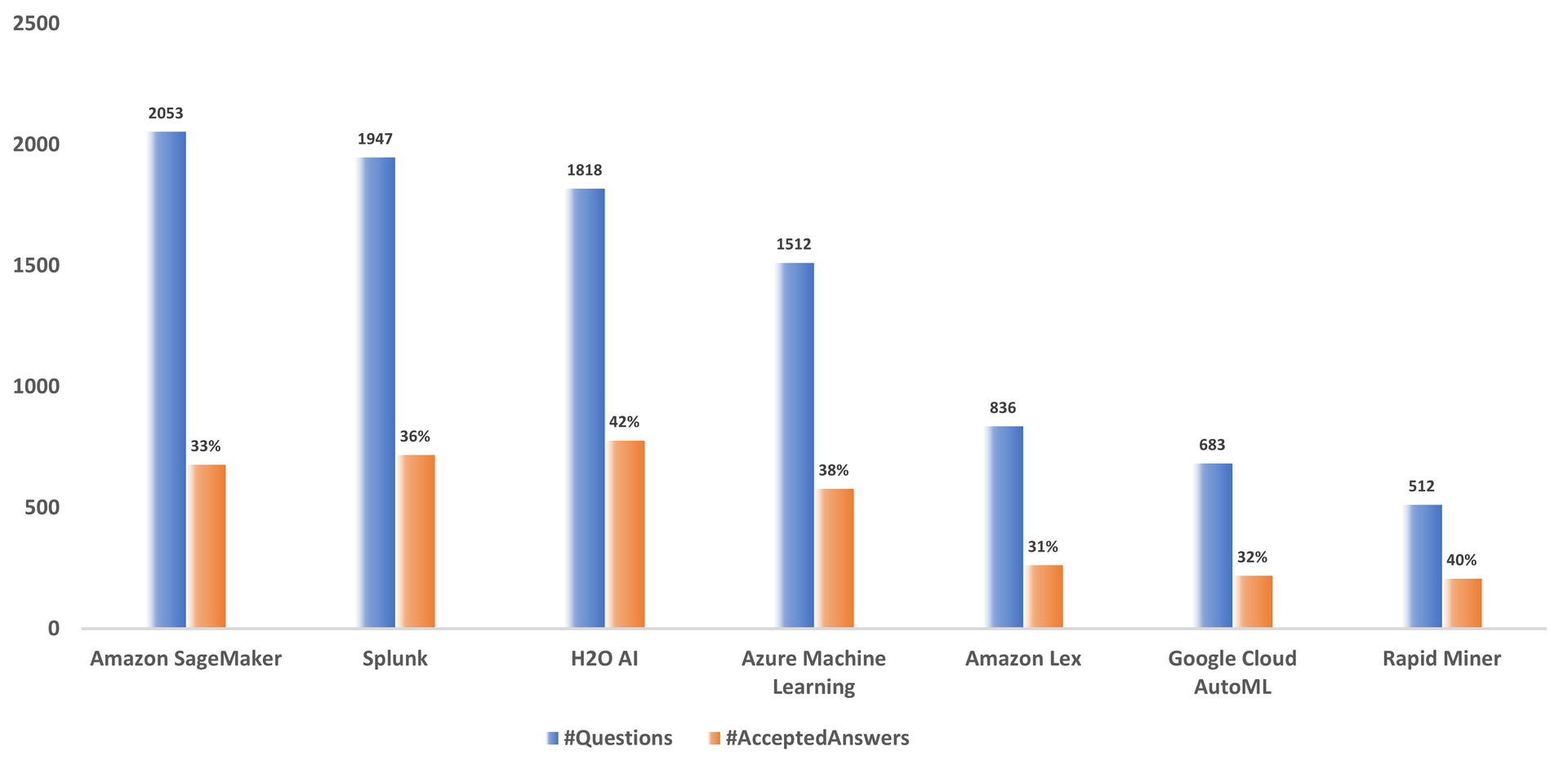


Our analysis shows that popular AutoML providers development actively follows SO discussion and provides solutions. For example, the H2O AutoML team officially provides support for practitioners’ queries in SO (e.g., 51527994), and thus they provide insights into our current limitations (e.g., 52486395) of the framework and plans for fixing the bugs in future releases (e.g., Fig. fig-h2o-support in 51683851). Similarly, we also find the development team from Amazon Sagemaker also actively participating in the SO discussion (Fig. fig-sagemaker-support in 55553190). In Figure fig-top-platform-acc-stat, we present a bar chart with the total number of questions vs. the percentage of questions with accepted answers for each of the top seven AutoML service providers. We can see that Amazon SageMaker has 2,053 questions, and only 33% of its questions have accepted answers. From Figure fig-top-platform-acc-stat, we see H2O AI has the highest percentage of questions with accepted answers (42%), followed by Rapid Miner (40%), Azure Machine Learning (38%), Splunk (36%), Amazon SageMaker (33%), Google Cloud AutoML (32%), Amazon Lex (31%).
Traditional ML vs AutoML challenges.
With with popularity of ML and its widespread adoption, there are several studies on the challenges of machine learning development, deep learning development, DL frameworks/libraries. However, none of this research addresses the challenges of the low-code machine learning approach, i.e., AutoML. In this section, we compare the conclusions of these past studies on the border ML domain with our findings regarding the AutoML challenges. As AutoML is a subset of the ML domain, we find that many issues are comparable while others are unique. This finding is intriguing in and of itself, given that AutoML was intended to mitigate some of the shortcomings of traditional ML development and make ML adoption more accessible. Our analysis shows that AutoML tools are successful in some circumstances but not all. For example, among AutoML practitioners, there is substantially less discussion about Model creation and fine-tuning than among all ML practitioners. However, deployment, library, and system configuration dominate both traditional ML and AutoML development. Future research from the SE domain can further ameliorate many of these challenges by providing a guideline on better documentation, API design, and MLOps. We present a detailed comparison of some of the most significant ML development challenges faced by traditional ML versus AutoML practitioners.
Requirement Analysis. This contains a discussion on formulating an ML solution for a specific problem/task. These questions are related to understanding available data and the support for existing ML frameworks/platforms. An empirical study on the machine learning challenges in SO discussion by Alshangiti et al.reports that ML developers have around 2.5% questions on these challenges in SO. Other studiesalso report similar challenges for ML developers. From our analysis (rq-result-mllc), we also find that AutoML practitioners have around 5.7% queries regarding the supported services from AutoML tools/platforms to meet their business requirements. Our analysis (Fig. fig-bubble-diff-pop-mllc) indicates that AutoML practitioners find these to be particularly hard(e.g., “Does AzureML RL support PyTorch?” in 64025308 or “Is there support for h2o4gpu for deeplearning in python?” in 67727907); therefore, AutoML providers should give more support in terms of available resources.
Data Processing & Management. This challenge relates to data loading, cleaning, splitting, formatting, labeling, handling missing values or imbalanced classes, etc. Previous studies report that ML developers find data pre-processing the second most challenging topicand even some popular ML libraries lack data cleaning features. Our analysis (rq-result-topics and rq-result-pop-diff, we find that this is quite a dominant topic for AutoML practitioners (i.e., 27% questions), but AutoML practitioners find these topics (Fig. fig-bubble-diff-pop-per-category) and MLLC phases (Fig. fig-bubble-diff-pop-mllc) less challenging. This finding suggests that AutoML service provide better abstraction and APIs for this data pre-processing and management pipeline.
Model Design. This contains some conceptual and implementation-related discussions on ML. This contains a discussion about ML algorithms/models, their internal implementation, parameters, etc. (e.g., Architecture of FCC, CNN, ResNet, etc., learning rate). Similar studies on ML challengesreport model creation-related questions as challenging. Questions regarding different ML algorithms are dominant in SO, and Neural network architecture is a popular topic among practitioners and gaining popularity. From our analysis, we find that this challenge is prevalent (4.2% questions) in AutoML practitioners (Fig. fig-taxonomy-tm) and moderately challenging (Table tab-topicdifficulty).
Training & Debugging. This contains a discussion related to the actual training of the model on a specific train dataset. This contains a discussion about use cases or troubleshooting for a specific library via documentation or prior experience. Similar studiesreport that coding error/exception topics– type mismatch, shape mismatch – are most dominant in SO, and resolving these issues requires more implementation knowledge than conceptual knowledge. Our analysis suggests that AutoML practitioners also find model training and debugging-related questions (i.e., around 10%) most popular (Fig. fig-bubble-diff-pop-topic). This suggests that both ML and AutoML practitioners require better support for bug detection.
Model Evaluation & Performance Improvement. This contains challenges related to evaluating the trained model via different metrics and improving the model’s performance via different techniques and multiple iterations. Similar studiesalso report that model-turning and prediction-related queries are less frequent in SO, even though significant ML research focuses on this step. More research is needed on practitioners’ challenges. We find that AutoML practitioners have many queries (i.e., around 10%) regarding improving the performance of the model with fewer resources (e.g., “H2O cluster uneven distribution of performance usage” in 46056853, 62408707). AutoML aims to abstract model architecture-related complexities, but better explainability of the model’s prediction may mitigate many of AutoML practitioners’ concerns (e.g., “RapidMiner: Explaining decision tree parameters” in 23362687).
Model deployment. This contains challenges while deploying the model, scaling up as necessary, and updating the model with a new dataset. Chen et al.report that ML developers face several challenges from Model export, environment configuration, model deployment via cloud APIs, and updating model. Guo et al.evaluated prediction accuracy and performance changes when DL models trained on PC platforms were deployed to mobile devices and browsers and found compatibility and dependability difficulties. Similar studieson developers’ discussion on SO on DL frameworks reported that developers find model deployment challenging. From our analysis, we also find that (Fig. fig-bubble-diff-pop-topic) AutoML practitioners find Model Load & Deployment (around 13% questions) to be one of the most difficult topics (e.g., “Azure ML Workbench Kubernetes Deployment Failed” in 46963846). This is particularly problematic as AutoML is expected to make model deployment and stability-related problems. Future research efforts from SE can help to mitigate these challenges.
Documentation. This challenge is related to incorrect and inadequate documentation, which is also quite prevalent in other software engineering tasks. Similar to empirical studieson the overall ML domain, we find that API misuse related to inadequate documentation or ML expertsis prevalent in all MLLC phases (e.g., In adequate documentation “API call for deploying and undeploying Google AutoML natural language model - documentation error?” in 67470364). This implies that researchers ML/AutoML should collaborate with the SE domain to improve these prevalent limitations.
Implications
In this Section, we summarize the findings can guide the following three stakeholders: [(1)]
-
AutoML Researchers & Educators to have a deeper understanding of the practical challenges/limitations of current AutoML tools and prioritize their future research effort,
-
AutoML platform/tool Providers to improve their services, learning resources, improve support for deployment, and maintenance,
-
AutoML Practitioners/Developers to gain a useful insights of current advantages and limitations to have a better understanding of the trade-offs between AutoML tools vs Tradition ML tools, We discuss the implications in details below.
AutoML Researchers & Educators. We find that the AutoML practitioners challenges are slightly different from traditional ML developers (sub-sec-autom-vs-traditionalml). Researchers can study how to improve the performance of AutoML core services, i.e., finding best ML algorithm configuration or Neural architecture search. AutoML tools/platforms aims to provide a reasonable good ML model at the cost of huge computational power (i.e., sometimes 100x) as it needs to explore a huge search space for potential solutions. Some recent search approach are showing promising results by reducing this cost by around ten fold. From our analysis (rq-diff-pop), we can see model performance improvement is a popular and difficult topic for AutoML practitioners (Table tab-topicpopularity). Future research on the explanability of the trained model can also provide more confidence to the practitioners.Researchers from SE can also help improve documentation, API design, and design intelligent tools to help AutoML practitioners to correctly tag SO questions so they reach the right experts.
AutoML Vendors. In this research, we present the AutoML practitioners discussed topics (Fig.fig-taxonomy-tm), popularity (Table tab-topicpopularity) and difficulty (Table tab-topicdifficulty) of these topics in details. From Figure fig-bubble-diff-pop-topic, we can see that Model load & deployment related topic is one of the most popular and difficult topic among the practitioners. We can also see that Model training & monitoring related question are the most challenging topic and model performance, library/platform management and data transformation related topics are most popular. AutoML vendors can prioritise their efforts based on the popularity and difficulty of these topics(Fig. fig-bubble-diff-pop-per-category). For example, expect for Model Load & Deployment (46 hours) and Model Training & Monitoring (32 hours) topics questions from other 11 topics have median average wait for for accepted answer is less than 20 hours. We also find that topics under data category are quite dominant and our analysis of AutoML tools and similar studies on other ML librariesreport the limitation of data processing APIs that require special attentions.
From Figure fig-bubble-diff-pop-mllc, We see that questions asked during model design and training related MLLC phase quite prevalent and popular among the AutoML community. We can also see that AutoML practitioners find requirement analysis phase (e.g., “How can I get elasticsearch data in h2o?” in 48397934) and Model deployment & monitoring phase quite challenging (e.g., “How to deploy machine learning model saved as pickle file on AWS SageMaker” in 68214823). We can also see popular development teams from popular AutoML providers such as H2O and Microsoft (Fig. fig-h2o-support, Fig. fig-sagemaker-support in sub-sec-top-automl) actively follow practitioners discussion on SO and take necessary actions or provide solutions. Other AutoML tool/platforms providers should also provide support to answer their platform feature specific queries. It shows that the smooth adoption of the AutoML tools/platforms depends on the improved and effective documentation, effective community support and tutorials.
AutoML Practitioners/Developers. The high demand and shortage of ML experts is making low-code, i.e., AutoML approach for ML development attractive for organizations. We can also see the the AutoML related discussion in SO a steady upward tread (Fig. fig-all-questions-evolution). AutoML tools/platforms provides a great support for different ML aspects such as data pre-processing and management but still lacks support for various tasks specially tasks related to model deployment and monitoring. Our analysis can provide project managers a comprehensive overview of current status of overall AutoML tools (sub-sec-top-automl and sub-sec-autom-vs-traditionalml). Our analysis provides invaluable insight on the current strength/limitations to project managers to adopt AutoML approach and better manage their resources. For example, even with AutoML approach setting up and configuring development environment and library management (e.g., “Need to install python packages in Azure ML studio” in 52925424), deployment trained models via cloud endpoint and updating model is still challenging. Our analysis also shows that average median wait time to get an accepted solution from SO is around 12 hours for data management and model implementation/debugging related tasks as development teams from some of these platforms also provide active support.
Threats to Validity
Internal validity threats in our study relate to the authors’ bias while analyzing the questions. We mitigate the bias in our manual labeling of topics andAutoML phases by following the annotation guideline. The first author participated in the labeling process, and in case of confusion, the first author consulted with the second author.
Construct Validity threats relate to the errors that may occur in our data collection process (e.g., identifying relevant AutoML tags). To mitigate this, first we created our initial list of tags, as stated in Section sec-methodology, by analyzing the posts in SO related to the leading AutoML platforms. Then we expanded our tag list using state-of-art approach. Another potential threat is the topic modeling technique, where we choose $K$ = 15 as the optimal number of topics for our dataset $B$ . This optimal number of topics directly impacts the output of LDA. We experimented with different values of $K$ following related works. We used the coherence score and our manual observation to find $K$ ’s optimal value that gives us the most relevant and generalized AutoML-related topics.
External Validity threats relate to the generalizability of our research findings. This study is based on data from developers’ discussions on SO. However, there are other forums that AutoML developers may use to discuss. We only considered questions and accepted answers in our topic modeling following other related works. The accepted and best answer (most scored) in SO may be different. The questioner approves the accepted answer, while all the viewers vote for the best answer. It is not easy to detect whether an answer is relevant to the question. Thus We chose the accepted answer in this study because we believe that the questioner is the best judge of whether the answer solves the problem. Even without the unaccepted answers, our dataset contains around 14.3K SO posts (12.5K questions + 3.7K accepted answers). Nevertheless, we believe using SO’s data provides us with generalizability because SO is a widely used Q&A platform for developers from diverse backgrounds. However, we also believe this study can be complemented by including discussions from other forums and surveying and interviewing AutoML practitioners.
Related Work
Research on AutoML
There are ongoing efforts to increase the performance of AutoML tools through better NAS approach, search for hyperparameters and loss methods, automating machine learning via keeping human in the loop. Truong et al.evaluated few popular AutoML tools on their abilities to automate ML pipeline. They report that at present different tools have different approaches for choosing the best model and optimizing hyperparameters. They report that the performance of these tools are reasonable against custom dataset but they still need improvement in terms of computational power, speed, flexibility etc. Karmaker et al.provides an overview of AutoML end-to-end pipeline. They highlight which ML pipeline requires future effort for the adoption of AutoML approach. There are other case studies on the use of AutoML technologies for autonomous vehicles, industry applicationanticipate bank collapses, predicting bank failureswhere the authors evaluate current strengths and limitations and make suggestions for future improvements. These studies focus on improving the AutoML paradigm from a theoretical perspective, and they do not address the challenges that AutoML practitioners have expressed in public forums such as SO.
Empirical Study on Challenges of ML Applications.
There has been quite some research effortsmostly by interviewing ML teams or surveys on the challenges of integrating ML in software engineering,explanability on the ML models. Bahrampour et al.conducted a comparative case of study on five popular deep learning frameworks – Caffe, Neon, TensorFlow, Theano, and Porch – on three different aspects such as their usability, execution speed and hardware utilization.
There are also quite some efforts on finding the challenges of Machine learning application by analysing developers discussion on stack overflow.
There are a few studies analyzing developer discussion on Stack Overflow regarding popular ML libraries. Islam et al.conduct a detailed examination of around 3.2K SO posts related to ten ML libraries and report the urgent need of SE research in this area. They report ML developers need support on finding errors earlier via static analyser, better support on debugging, better API design, better understanding of ML pipeline. Han et al.an empirical study on developers’ discussion three deep learning frameworks – Tensorflow, Pytorch, and Theano – on stack overflow and GitHub. They compare and report their challenges on these frameworks and provide useful insights to improve them. Zhang et al.analysed SO and GitHub projects on deep learning applications using TensorFlow and reported the characteristics and root causes of defects. Cummaudo et al.use Stack Overflow to mine developer dissatisfaction with computer vision services, classifying their inquiries against two taxonomies (i.e., documentation-related and general questions). They report that developers have a limited understanding of such systems’ underlying technology. Chen et al.conducts a comprehensive study on the challenges of deploying DL software by mining around 3K SO posts and report that DL deployment is more challenging than other topics in SE such as big data analysis and concurrency. They report a taxonomy of 72 challenges faced by the developers. These studies do not focus on the challenges of overall machine learning domain but rather on popular ML libraries, ML deployment, or a specific cloud-based ML service. Our study focuses entirely on overall AutoML related discussion on SO; hence, our analysed data, i.e., SO posts, are different.
There are also several empirical research on the challenges of machine learning, particularly deep learning, in the developers’ discussion on SO. Bangash et al.analyzes around 28K developers’ posts on SO and share their challenges. They report practitioners’ lack of basic understanding on Machine learning and not enough community feedback. Humbatova et al.manually analysed artefacts from GitHub commits and related SO discussion and report a report a variety of faults of while using DL frameworks and later validate their findings by surveying developers. Alshangiti et al.conduct a study on ML-related questions on SO and report developers’ challenges and report that ML related questions are more difficult than other domains and developers find data pre-processing, model deployment and environment setup related tasks most difficult. They also report although neural networks, and deep learning related frameworks are becoming popular, there is a shortage of experts in SO community. In contrast, our study focuses on AutoML tools/platforms rather than boarder machine learning domain in general. In this study, we aim to analyse the whole AutoML domains, i.e., AutoML-related discussion on SO rather than a few specific AutoML platforms. Our analyzed SO posts and SO users differ from theirs, and our findings provide insight focus on AutoML’s challenges.
Research on Topic Modeling & SO discussion
Our reason for employing topic modeling to understand LCSD discussions is rooted in current software engineering study demonstrates that concepts derived from The textual content can be a reasonable approximation of the underlying data. Topic modelling in SO dataset are used in a wide range of studies to understand software logging messagesand previously for diverse other tasks, such as concept and locating features, linking traceability (e.g., bug), to understand the evolution of software and source code history, to facilitate categorizing software code search, to refactor software code base, and for explaining software defects, and various software maintenance. The SO posts are used in several studies on various aspects of software development using topic modeling, such as what developers are discussing in generalor about a particular aspect, e.g., low-code software developers challenges, IoT developers discussion, docker development challenges, concurrency, big data, chatbot, machine learning challenges, challenges on deep learning libraries.
Conclusions
AutoML is a novel low-code approach for developing ML applications with minimal coding by utilizing higher-level end-to-end APIs. It automates various tasks in the ML pipeline, such as data prepossessing, model selection, hyperparameter tuning, etc. We present an empirical study that provides valuable insights into the types of discussions AutoML developers discuss in Stack Overflow (SO). We find 13 AutoML topics from our dataset of 14.3K extracted SO posts (question + acc. answers). We extracted these posts based on 41 SO tags belonging to the popular 18AutoML services. We categorize them into four high-level categories, namely the MLOps category (5 topics, 43.2% questions) with the highest number of SO questions, followed by Model (4 topics, 27.6% questions), Data (3 topics, 27% questions), Documentation (1 topic, 2.2% questions). Despite extensive support for data management, model design & deployment, we find that still, these topics are dominant in AutoML practitioners’ discussions across different MLLC phases. We find that many novice practitioners have platform feature-related queries without accepted answers. Our analysis suggests that better tutorial-based documentation can help mitigate most of these common issues. MLOps and Documentation topic categories predominate in cloud-based AutoML services. In contrast, the Model topic category and Model Evaluation phase are more predominant in non-cloud-based AutoML services. We hope these findings will help various AutoML stakeholders (e.g., AutoML/SE researchers, AutoML vendors, and practitioners) to take appropriate actions to mitigate these challenges. The research and developers’ popularity on AutoML indicates that this technology is likely widely adopted by various businesses for consumer-facing applications or business operational insight from their dataset. AutoML researchers and service providers should address the prevailing developers’ challenges for its fast adoption. Our future work will focus on [(1)]
-
getting AutoML developers’ feedback on our findings by interviews or surveys, and
-
developing tools to address the issues observed in the existing AutoML’s data processing and model designing pipeline.
Bibliography
1@inproceedings{abdellatif2020challenges,
2 series = {MSR '20},
3 location = {Seoul, Republic of Korea},
4 numpages = {12},
5 pages = {174–185},
6 booktitle = {Proceedings of the 17th International Conference on Mining
7Software Repositories},
8 doi = {10.1145/3379597.3387472},
9 url = {https://doi.org/10.1145/3379597.3387472},
10 address = {New York, NY, USA},
11 publisher = {Association for Computing Machinery},
12 isbn = {9781450375177},
13 year = {2020},
14 title = {Challenges in Chatbot Development: A Study of Stack
15Overflow Posts},
16 author = {Abdellatif, Ahmad and Costa, Diego and Badran, Khaled and
17Abdalkareem, Rabe and Shihab, Emad},
18}
19
20@inproceedings{adrian2020app,
21 organization = {Springer},
22 year = {2020},
23 pages = {45--51},
24 booktitle = {International Conference on Applied Human Factors and
25Ergonomics},
26 author = {Adrian, Benjamin and Hinrichsen, Sven and Nikolenko,
27Alexander},
28 title = {App Development via Low-Code Programming as Part of Modern
29Industrial Engineering Education},
30}
31
32@inproceedings{aghajani2020software,
33 organization = {IEEE},
34 year = {2020},
35 pages = {590--601},
36 booktitle = {2020 IEEE/ACM 42nd International Conference on Software
37Engineering (ICSE)},
38 author = {Aghajani, Emad and Nagy, Csaba and Linares-V{\'a}squez,
39Mario and Moreno, Laura and Bavota, Gabriele and Lanza,
40Michele and Shepherd, David C},
41 title = {Software documentation: the practitioners' perspective},
42}
43
44@article{agrapetidou2021automl,
45 publisher = {Taylor \& Francis},
46 year = {2021},
47 pages = {5--9},
48 number = {1},
49 volume = {28},
50 journal = {Applied Economics Letters},
51 author = {Agrapetidou, Anna and Charonyktakis, Paulos and Gogas,
52Periklis and Papadimitriou, Theophilos and Tsamardinos,
53Ioannis},
54 title = {An AutoML application to forecasting bank failures},
55}
56
57@article{agrawal2018wrong,
58 publisher = {Elsevier},
59 year = {2018},
60 pages = {74--88},
61 volume = {98},
62 journal = {Information and Software Technology},
63 author = {Agrawal, Amritanshu and Fu, Wei and Menzies, Tim},
64 title = {What is wrong with topic modeling? And how to fix it using
65search-based software engineering},
66}
67
68@inproceedings{ahmed2018concurrency,
69 series = {ESEM '18},
70 location = {Oulu, Finland},
71 keywords = {concurrency topics, concurrency topic difficulty,
72concurrency topic popularity, concurrency topic hierarchy,
73stack overflow},
74 numpages = {10},
75 articleno = {30},
76 booktitle = {Proceedings of the 12th ACM/IEEE International Symposium
77on Empirical Software Engineering and Measurement},
78 doi = {10.1145/3239235.3239524},
79 url = {https://doi.org/10.1145/3239235.3239524},
80 address = {New York, NY, USA},
81 publisher = {Association for Computing Machinery},
82 isbn = {9781450358231},
83 year = {2018},
84 title = {What Do Concurrency Developers Ask about? A Large-Scale
85Study Using Stack Overflow},
86 author = {Ahmed, Syed and Bagherzadeh, Mehdi},
87}
88
89@article{akiki2020eud,
90 publisher = {Elsevier},
91 year = {2020},
92 pages = {102534},
93 volume = {200},
94 journal = {Science of Computer Programming},
95 author = {Akiki, Pierre A and Akiki, Paul A and Bandara, Arosha K
96and Yu, Yijun},
97 title = {EUD-MARS: End-user development of model-driven adaptive
98robotics software systems},
99}
100
101@inproceedings{al2021quality,
102 organization = {IEEE},
103 year = {2021},
104 pages = {1--5},
105 booktitle = {2021 IEEE International Conference on Autonomous Systems
106(ICAS)},
107 author = {Al Alamin, Md Abdullah and Uddin, Gias},
108 title = {Quality assurance challenges for machine learning software
109applications during software development life cycle
110phases},
111}
112
113@inproceedings{alamin2021empirical,
114 pages = {46-57},
115 year = {2021},
116 organization = {IEEE},
117 booktitle = {2021 IEEE/ACM 18th International Conference on Mining
118Software Repositories (MSR)},
119 author = {Alamin, Md Abdullah Al and Malakar, Sanjay and Uddin, Gias
120and Afroz, Sadia and Haider, Tameem Bin and Iqbal,
121Anindya},
122 title = {An Empirical Study of Developer Discussions on Low-Code
123Software Development Challenges},
124}
125
126@article{alonso2020towards,
127 year = {2020},
128 journal = {arXiv preprint arXiv:2004.13495},
129 author = {Alonso, Ana Nunes and Abreu, Jo{\~a}o and Nunes, David and
130Vieira, Andr{\'e} and Santos, Luiz and Soares, T{\'e}rcio
131and Pereira, Jos{\'e}},
132 title = {Towards a polyglot data access layer for a low-code
133application development platform},
134}
135
136@article{alsaadi2021factors,
137 year = {2021},
138 pages = {123--140},
139 number = {3},
140 volume = {31},
141 journal = {Romanian Journal of Information Technology and Automatic
142Control},
143 author = {ALSAADI, Hana A and RADAIN, Dhefaf T and ALZAHRANI,
144Maysoon M and ALSHAMMARI, Wahj F and ALAHMADI, Dimah and
145FAKIEH, Bahjat},
146 title = {Factors that affect the utilization of low-code
147development platforms: survey study},
148}
149
150@inproceedings{alshangiti2019developing,
151 organization = {IEEE},
152 year = {2019},
153 pages = {1--11},
154 booktitle = {2019 ACM/IEEE International Symposium on Empirical
155Software Engineering and Measurement (ESEM)},
156 author = {Alshangiti, Moayad and Sapkota, Hitesh and Murukannaiah,
157Pradeep K and Liu, Xumin and Yu, Qi},
158 title = {Why is developing machine learning applications
159challenging? a study on stack overflow posts},
160}
161
162@inproceedings{amershi2019software,
163 organization = {IEEE},
164 year = {2019},
165 pages = {291--300},
166 booktitle = {2019 IEEE/ACM 41st International Conference on Software
167Engineering: Software Engineering in Practice (ICSE-SEIP)},
168 author = {Amershi, Saleema and Begel, Andrew and Bird, Christian and
169DeLine, Robert and Gall, Harald and Kamar, Ece and
170Nagappan, Nachiappan and Nushi, Besmira and Zimmermann,
171Thomas},
172 title = {Software engineering for machine learning: A case study},
173}
174
175@inproceedings{amershi_se_case_study_2019,
176 organization = {IEEE},
177 year = {2019},
178 pages = {291--300},
179 booktitle = {proc ICSE-SEIP},
180 author = {Amershi et al.},
181 title = {Software engineering for machine learning: A case study},
182}
183
184@misc{amplifystudio,
185 note = {[Online; accessed 5-November-2022]},
186 howpublished = {{Available: \url{https://aws.amazon.com/amplify/studio/}}},
187 title = {{AWS Amplify Studio overview}},
188 key = {amplifystudio},
189}
190
191@inproceedings{androutsopoulos2014analysis,
192 year = {2014},
193 pages = {573--583},
194 booktitle = {Proceedings of the 36th international conference on
195software engineering},
196 author = {Androutsopoulos et al.},
197 title = {An analysis of the relationship between conditional
198entropy and failed error propagation in software testing},
199}
200
201@article{annas2003hipaa,
202 publisher = {MEDICAL PUBLISHING GROUP-MASS MEDIC SOCIETY},
203 year = {2003},
204 pages = {1486--1490},
205 number = {15},
206 volume = {348},
207 journal = {New England Journal of Medicine},
208 author = {Annas et al.},
209 title = {HIPAA regulations-a new era of medical-record privacy?},
210}
211
212@misc{appengine,
213 note = {[Online; accessed 13-December-2021]},
214 howpublished = {{Available:
215\url{https://cloud.google.com/appengine/docs}}},
216 title = {{App Engine: a fully managed, serverless platform for
217developing and hosting web applications at scale.}},
218 key = {appengine},
219}
220
221@misc{appian,
222 note = {[Online; accessed 5-January-2021]},
223 howpublished = {{Available: \url{https://www.appian.com/}}},
224 title = {{Appian platform overview}},
225 key = {appian},
226}
227
228@inproceedings{arun2010finding,
229 organization = {Springer},
230 year = {2010},
231 pages = {391--402},
232 booktitle = {Pacific-Asia conference on knowledge discovery and data
233mining},
234 author = {Arun, Rajkumar and Suresh, Venkatasubramaniyan and
235Madhavan, CE Veni and Murthy, MN Narasimha},
236 title = {On finding the natural number of topics with latent
237dirichlet allocation: Some observations},
238}
239
240@inproceedings{asaduzzaman2013answering,
241 organization = {IEEE},
242 year = {2013},
243 pages = {97--100},
244 booktitle = {2013 10th Working Conference on Mining Software
245Repositories (MSR)},
246 author = {Asaduzzaman, Muhammad and Mashiyat, Ahmed Shah and Roy,
247Chanchal K and Schneider, Kevin A},
248 title = {Answering questions about unanswered questions of stack
249overflow},
250}
251
252@inproceedings{asuncion2010software,
253 organization = {IEEE},
254 year = {2010},
255 pages = {95--104},
256 volume = {1},
257 booktitle = {2010 ACM/IEEE 32nd International Conference on Software
258Engineering},
259 author = {Asuncion, Hazeline U and Asuncion, Arthur U and Taylor,
260Richard N},
261 title = {Software traceability with topic modeling},
262}
263
264@article{atkinson2003model,
265 publisher = {IEEE},
266 year = {2003},
267 pages = {36--41},
268 number = {5},
269 volume = {20},
270 journal = {IEEE software},
271 author = {Atkinson, Colin and Kuhne, Thomas},
272 title = {Model-driven development: a metamodeling foundation},
273}
274
275@inproceedings{attenberg2011beat,
276 year = {2011},
277 booktitle = {Workshops at the Twenty-Fifth AAAI Conference on
278Artificial Intelligence},
279 author = {Attenberg et al.},
280 title = {Beat the machine: Challenging workers to find the unknown
281unknowns},
282}
283
284@misc{auto_ml,
285 note = {[Online; accessed 5-November-2022]},
286 howpublished = {{Available: \url{https://github.com/ClimbsRocks/auto_ml}}},
287 title = {{Automated machine learning for analytics \& production}},
288 year = {2022},
289}
290
291@misc{autofolio,
292 note = {[Online; accessed 5-November-2022]},
293 howpublished = {{Available: \url{https://github.com/automl/AutoFolio}}},
294 title = {{AutoFolio Automated Algorithm Selection with
295Hyperparameter Optimization Library}},
296 year = {2022},
297}
298
299@misc{automl_nas,
300 note = {[Online; accessed 5-November-2022]},
301 howpublished = {{Available: \url{https://www.altexsoft.com/blog/automl/}}},
302 year = {2022},
303 title = {{AutoML: How to Automate Machine Learning With Google
304Vertex AI, Amazon SageMaker, H20.ai, and Other Providers}},
305}
306
307@misc{automl_pipeline_overview,
308 note = {[Online; accessed 5-November-2022]},
309 howpublished = {{Available:
310\url{https://gomerudo.github.io/auto-ml/nutshell.html}}},
311 title = {{AutoML in a nutshell}},
312 year = {2022},
313}
314
315@misc{automlcomputation,
316 note = {[Online; accessed 5-January-2021]},
317 howpublished = {{Available:
318\url{https://www.fast.ai/2018/07/23/auto-ml-3/}}},
319 title = {{Google's AutoML: Cutting Through the Hype }},
320 year = {2022},
321}
322
323@misc{aws_lex,
324 note = {[Online; accessed 5-November-2022]},
325 howpublished = {{Available: \url{https://aws.amazon.com/lex/}}},
326 title = {{Amazon Lex - Conversational AI and Chatbots}},
327 year = {2022},
328}
329
330@misc{aws_news,
331 note = {[Online; accessed 5-November-2022]},
332 howpublished = {{Available:
333\url{https://www.businesswire.com/news/home/20201208005335/en/AWS-Announces-Nine-New-Amazon-SageMaker-Capabilities}}},
334 title = {{AWS Announces Nine New Amazon SageMaker Capabilities}},
335 year = {2022},
336}
337
338@misc{aws_sagemaker,
339 note = {[Online; accessed 5-November-2022]},
340 howpublished = {{Available: \url{https://aws.amazon.com/sagemaker/}}},
341 title = {{Amazon SageMaker Overview}},
342 year = {2022},
343}
344
345@misc{azureml,
346 note = {[Online; accessed 5-November-2022]},
347 howpublished = {{Available:
348\url{https://azure.microsoft.com/en-us/services/machine-learning/}}},
349 title = {{Azure Machine Learning - ML as a Service}},
350 year = {2022},
351}
352
353@inproceedings{bagherzadeh2019going,
354 keywords = {Big data topic difficulty, Big data topic hierarchy, Big
355data topic popularity, Big data topics, Stackoverflow},
356 address = {New York, NY, USA},
357 publisher = {ACM},
358 pages = {432--442},
359 location = {Tallinn, Estonia},
360 year = {2019},
361 series = {ESEC/FSE 2019},
362 booktitle = {Proceedings of the 2019 27th ACM Joint Meeting on European
363Software Engineering Conference and Symposium on the
364Foundations of Software Engineering},
365 title = {Going Big: A Large-scale Study on What Big Data Developers
366Ask},
367 author = {Bagherzadeh, Mehdi and Khatchadourian, Raffi},
368}
369
370@article{bahrampour2015comparative,
371 year = {2015},
372 journal = {arXiv preprint arXiv:1511.06435},
373 author = {Bahrampour, Soheil and Ramakrishnan, Naveen and Schott,
374Lukas and Shah, Mohak},
375 title = {Comparative study of deep learning software frameworks},
376}
377
378@inproceedings{bajaj2014mining,
379 year = {2014},
380 pages = {112--121},
381 booktitle = {Proceedings of the 11th Working Conference on Mining
382Software Repositories},
383 author = {Bajaj, Kartik and Pattabiraman, Karthik and Mesbah, Ali},
384 title = {Mining questions asked by web developers},
385}
386
387@inproceedings{baltadzhieva2015predicting,
388 year = {2015},
389 pages = {32--40},
390 booktitle = {Proceedings of the international conference recent
391advances in natural language processing},
392 author = {Baltadzhieva, Antoaneta and Chrupa{\l}a, Grzegorz},
393 title = {Predicting the quality of questions on stackoverflow},
394}
395
396@inproceedings{bandeira2019we,
397 organization = {IEEE},
398 year = {2019},
399 pages = {255--259},
400 booktitle = {2019 IEEE/ACM 16th International Conference on Mining
401Software Repositories (MSR)},
402 author = {Bandeira, Alan and Medeiros, Carlos Alberto and Paixao,
403Matheus and Maia, Paulo Henrique},
404 title = {We need to talk about microservices: an analysis from the
405discussions on StackOverflow},
406}
407
408@inproceedings{bangash2019developers,
409 organization = {IEEE},
410 year = {2019},
411 pages = {260--264},
412 booktitle = {2019 IEEE/ACM 16th International Conference on Mining
413Software Repositories (MSR)},
414 author = {Bangash, Abdul Ali and Sahar, Hareem and Chowdhury,
415Shaiful and Wong, Alexander William and Hindle, Abram and
416Ali, Karim},
417 title = {What do developers know about machine learning: a study of
418ml discussions on stackoverflow},
419}
420
421@article{barr2014oracle,
422 publisher = {IEEE},
423 year = {2014},
424 pages = {507--525},
425 number = {5},
426 volume = {41},
427 journal = {IEEE transactions on software engineering},
428 author = {Barr et al.},
429 title = {The oracle problem in software testing: A survey},
430}
431
432@article{barua2014developers,
433 publisher = {Springer},
434 year = {2014},
435 pages = {619--654},
436 number = {3},
437 volume = {19},
438 journal = {Empirical Software Engineering},
439 author = {Barua, Anton and Thomas, Stephen W and Hassan, Ahmed E},
440 title = {What are developers talking about? an analysis of topics
441and trends in stack overflow},
442}
443
444@inproceedings{basciani2014mdeforge,
445 organization = {CEUR-WS},
446 year = {2014},
447 pages = {66--75},
448 volume = {1242},
449 booktitle = {2nd International Workshop on Model-Driven Engineering on
450and for the Cloud, CloudMDE 2014, Co-located with the 17th
451International Conference on Model Driven Engineering
452Languages and Systems, MoDELS 2014},
453 author = {Basciani, Francesco and Iovino, Ludovico and Pierantonio,
454Alfonso and others},
455 title = {MDEForge: an extensible web-based modeling platform},
456}
457
458@article{basil1975iterative,
459 publisher = {IEEE},
460 year = {1975},
461 pages = {390--396},
462 number = {4},
463 journal = {IEEE Transactions on Software Engineering},
464 author = {Basil, Victor R and Turner, Albert J},
465 title = {Iterative enhancement: A practical technique for software
466development},
467}
468
469@article{bassil2012simulation,
470 year = {2012},
471 journal = {arXiv preprint arXiv:1205.6904},
472 author = {Bassil, Youssef},
473 title = {A simulation model for the waterfall software development
474life cycle},
475}
476
477@article{bavota-refactoringtopic-tse2014,
478 year = {2014},
479 volume = {40},
480 title = {Methodbook: Recommending Move Method Refactorings via
481Relational Topic Models},
482 pages = {671-694},
483 number = {7},
484 journal = {IEEE Transactions on Software Engineering},
485 author = {Gabriele Bavota and Rocco Oliveto and Malcom Gethers and
486Denys Poshyvanyk and Andrea De Lucia},
487}
488
489@inproceedings{bayer2006view,
490 organization = {IEEE},
491 year = {2006},
492 pages = {10--pp},
493 booktitle = {13th Annual IEEE International Symposium and Workshop on
494Engineering of Computer-Based Systems (ECBS'06)},
495 author = {Bayer, Joachim and Muthig, Dirk},
496 title = {A view-based approach for improving software documentation
497practices},
498}
499
500@article{beck2001manifesto,
501 year = {2001},
502 author = {Beck, Kent and Beedle, Mike and Van Bennekum, Arie and
503Cockburn, Alistair and Cunningham, Ward and Fowler, Martin
504and Grenning, James and Highsmith, Jim and Hunt, Andrew and
505Jeffries, Ron and others},
506 title = {Manifesto for agile software development},
507}
508
509@inproceedings{beranic2020adoption,
510 organization = {Faculty of Organization and Informatics Varazdin},
511 year = {2020},
512 pages = {97--103},
513 booktitle = {Central European Conference on Information and Intelligent
514Systems},
515 author = {Beranic, Tina and Rek, Patrik and Heri{\v{c}}ko, Marjan},
516 title = {Adoption and Usability of Low-Code/No-Code Development
517Tools},
518}
519
520@article{beynon1999rapid,
521 publisher = {Taylor \& Francis},
522 year = {1999},
523 pages = {211--223},
524 number = {3},
525 volume = {8},
526 journal = {European Journal of Information Systems},
527 author = {Beynon-Davies, Paul and Carne, Chris and Mackay, Hugh and
528Tudhope, Douglas},
529 title = {Rapid application development (RAD): an empirical review},
530}
531
532@article{bhat2006overcoming,
533 publisher = {IEEE},
534 year = {2006},
535 pages = {38--44},
536 number = {5},
537 volume = {23},
538 journal = {IEEE software},
539 author = {Bhat, Jyoti M and Gupta, Mayank and Murthy, Santhosh N},
540 title = {Overcoming requirements engineering challenges: Lessons
541from offshore outsourcing},
542}
543
544@article{biggio2012poisoning,
545 year = {2012},
546 journal = {arXiv preprint arXiv:1206.6389},
547 author = {Biggio et al.},
548 title = {Poisoning attacks against support vector machines},
549}
550
551@article{blei2003latent,
552 year = {2003},
553 volume = {3},
554 title = {Latent Dirichlet Allocation},
555 pages = {993--1022},
556 number = {4-5},
557 journal = {Journal of Machine Learning Research},
558 author = {Blei, David M. and Ng, Andrew Y. and Jordan, Michael I.},
559}
560
561@article{bonawitz2019towards,
562 year = {2019},
563 journal = {arXiv preprint arXiv:1902.01046},
564 author = {Bonawitz et al.},
565 title = {Towards federated learning at scale: System design},
566}
567
568@inproceedings{borg2021aiq,
569 organization = {Springer},
570 year = {2021},
571 pages = {66--77},
572 booktitle = {International Conference on Software Quality},
573 author = {Borg, Markus},
574 title = {The AIQ meta-testbed: pragmatically bridging academic AI
575testing and industrial Q needs},
576}
577
578@inproceedings{botterweck2006model,
579 organization = {Springer},
580 year = {2006},
581 pages = {106--115},
582 booktitle = {International Conference on Model Driven Engineering
583Languages and Systems},
584 author = {Botterweck, Goetz},
585 title = {A model-driven approach to the engineering of multiple
586user interfaces},
587}
588
589@article{bourque1999guide,
590 publisher = {IEEE},
591 year = {1999},
592 pages = {35--44},
593 number = {6},
594 volume = {16},
595 journal = {IEEE software},
596 author = {Bourque et al.},
597 title = {The guide to the software engineering body of knowledge},
598}
599
600@article{brambilla2017model,
601 publisher = {Morgan \& Claypool Publishers},
602 year = {2017},
603 pages = {1--207},
604 number = {1},
605 volume = {3},
606 journal = {Synthesis lectures on software engineering},
607 author = {Brambilla, Marco and Cabot, Jordi and Wimmer, Manuel},
608 title = {Model-driven software engineering in practice},
609}
610
611@article{brambilla2017modelmdse,
612 publisher = {Morgan \& Claypool Publishers},
613 year = {2017},
614 pages = {1--207},
615 number = {1},
616 volume = {3},
617 journal = {Synthesis lectures on software engineering},
618 author = {Brambilla, Marco and Cabot, Jordi and Wimmer, Manuel},
619 title = {Model-driven software engineering in practice},
620}
621
622@article{brock2017smash,
623 year = {2017},
624 journal = {arXiv preprint arXiv:1708.05344},
625 author = {Brock, Andrew and Lim, Theodore and Ritchie, James M and
626Weston, Nick},
627 title = {Smash: one-shot model architecture search through
628hypernetworks},
629}
630
631@article{burnett1995visual,
632 publisher = {IEEE INSTITUTE OF ELECTRICAL AND ELECTRONICS},
633 year = {1995},
634 pages = {14--14},
635 volume = {28},
636 journal = {COMPUTER-LOS ALAMITOS-},
637 author = {Burnett, Margaret M and McIntyre, David W},
638 title = {Visual programming},
639}
640
641@inproceedings{carlini2017adversarial,
642 year = {2017},
643 organization = {ACM},
644 pages = {3--14},
645 booktitle = {proc ALSec},
646 author = {Carlini et al.},
647 title = {Adversarial examples are not easily detected: Bypassing
648ten detection methods},
649}
650
651@inproceedings{carlini2017towards,
652 organization = {IEEE},
653 year = {2017},
654 pages = {39--57},
655 booktitle = {symposium on security and privacy (sp)},
656 author = {Carlini et al.},
657 title = {Towards evaluating the robustness of neural networks},
658}
659
660@article{castelvecchi2016can,
661 year = {2016},
662 pages = {20},
663 number = {7623},
664 volume = {538},
665 journal = {Nature News},
666 author = {Castelvecchi, Davide},
667 title = {Can we open the black box of AI?},
668}
669
670@article{chakraborty-newlangsupportso-ist2021,
671 year = {2021},
672 volume = {},
673 title = {How Do Developers Discuss and Support New Programming
674Languages in Technical Q\&A Site? An Empirical Study of Go,
675Swift, and Rust in Stack Overflow},
676 pages = {19},
677 number = {},
678 journal = {Information and Software Technology (IST)},
679 author = {Partha Chakraborty and Rifat Shahriyar and Anindya Iqbal
680and Gias Uddin},
681}
682
683@inproceedings{chen-softwaredefecttopic-msr2012,
684 year = {2012},
685 title = {Explaining software defects using topic models},
686 pages = {189-198},
687 booktitle = {9th working conference on mining software repositories},
688 author = {Tse-Hsun Chen and Stephen W. Thomas and Meiyappan Nagappan
689and Ahmed E. Hassan},
690}
691
692@article{chen-surveytopicinse-emse2016,
693 year = {2016},
694 volume = {21},
695 title = {A survey on the use of topic models when mining software
696repositories},
697 pages = {1843-1919},
698 number = {5},
699 journal = {Empirical Software Engineering},
700 author = {Tse-Hsun (Peter) Chen and Stephen W. Thomas and Ahmed E
701Hassan},
702}
703
704@inproceedings{chen2015deepdriving,
705 year = {2015},
706 pages = {2722--2730},
707 booktitle = {proc ICCV},
708 author = {Chen et al.},
709 title = {Deepdriving: Learning affordance for direct perception in
710autonomous driving},
711}
712
713@inproceedings{chen2020comprehensive,
714 year = {2020},
715 pages = {750--762},
716 booktitle = {Proceedings of the 28th ACM Joint Meeting on European
717Software Engineering Conference and Symposium on the
718Foundations of Software Engineering},
719 author = {Chen, Zhenpeng and Cao, Yanbin and Liu, Yuanqiang and
720Wang, Haoyu and Xie, Tao and Liu, Xuanzhe},
721 title = {A comprehensive study on challenges in deploying deep
722learning based software},
723}
724
725@inproceedings{cheng2018manifesting,
726 organization = {IEEE},
727 year = {2018},
728 pages = {313--324},
729 booktitle = {proc in QRS},
730 author = {Cheng et al.},
731 title = {Manifesting bugs in machine learning code: An explorative
732study with mutation testing},
733}
734
735@article{chowdhury2003natural,
736 publisher = {Wiley Online Library},
737 year = {2003},
738 pages = {51--89},
739 number = {1},
740 volume = {37},
741 journal = {Annual review of information science and technology},
742 author = {Chowdhury, Gobinda G},
743 title = {Natural language processing},
744}
745
746@inproceedings{cisse2017parseval,
747 organization = {PMLR},
748 year = {2017},
749 pages = {854--863},
750 booktitle = {International Conference on Machine Learning},
751 author = {Cisse et al.},
752 title = {Parseval networks: Improving robustness to adversarial
753examples},
754}
755
756@article{cleary-conceptlocationtopic-emse2009,
757 year = {2009},
758 volume = {14},
759 title = {An empirical analysis of information retrieval based
760concept location techniques in software comprehension},
761 pages = {93-130},
762 number = {},
763 journal = {Empirical Software Engineering},
764 author = {Brendan Cleary and Chris Exton and Jim Buckley and Michael
765English },
766}
767
768@article{costabile2007visual,
769 publisher = {IEEE},
770 year = {2007},
771 pages = {1029--1046},
772 number = {6},
773 volume = {37},
774 journal = {IEEE transactions on systems, man, and cybernetics-part a:
775systems and humans},
776 author = {Costabile, Maria Francesca and Fogli, Daniela and Mussio,
777Piero and Piccinno, Antonio},
778 title = {Visual interactive systems for end-user development: a
779model-based design methodology},
780}
781
782@inproceedings{cummaudo2020beware,
783 year = {2020},
784 pages = {269--280},
785 booktitle = {Proceedings of the 28th ACM Joint Meeting on European
786Software Engineering Conference and Symposium on the
787Foundations of Software Engineering},
788 author = {Cummaudo, Alex and Barnett, Scott and Vasa, Rajesh and
789Grundy, John and Abdelrazek, Mohamed},
790 title = {Beware the evolving ‘intelligent’web service! An
791integration architecture tactic to guard AI-first
792components},
793}
794
795@inproceedings{cummaudo2020interpreting,
796 organization = {IEEE},
797 year = {2020},
798 pages = {1584--1596},
799 booktitle = {2020 IEEE/ACM 42nd International Conference on Software
800Engineering (ICSE)},
801 author = {Cummaudo, Alex and Vasa, Rajesh and Barnett, Scott and
802Grundy, John and Abdelrazek, Mohamed},
803 title = {Interpreting cloud computer vision pain-points: A mining
804study of Stack Overflow},
805}
806
807@misc{dahlberg2020developer,
808 year = {2020},
809 author = {Dahlberg, Daniel},
810 title = {Developer Experience of a Low-Code Platform: An
811exploratory study},
812}
813
814@misc{darwin,
815 note = {[Online; accessed 5-November-2022]},
816 howpublished = {{Available:
817\url{https://www.sparkcognition.com/product/darwin/}}},
818 title = {{Darwin - Automated Machine Learning Platform}},
819 year = {2022},
820}
821
822@article{das2017survey,
823 year = {2017},
824 pages = {1301--1309},
825 number = {2},
826 volume = {5},
827 journal = {International Journal of Innovative Research in Computer
828and Communication Engineering},
829 author = {Das, Kajaree and Behera, Rabi Narayan},
830 title = {A survey on machine learning: concept, algorithms and
831applications},
832}
833
834@misc{datarobot,
835 note = {[Online; accessed 5-November-2022]},
836 howpublished = {{Available: \url{https://www.datarobot.com/}}},
837 title = {{DataRobot AI Cloud - The Next Generation of AI}},
838 year = {2022},
839}
840
841@article{de2014labeling,
842 publisher = {Springer},
843 year = {2014},
844 pages = {1383--1420},
845 number = {5},
846 volume = {19},
847 journal = {Empirical Software Engineering},
848 author = {De Lucia, Andrea and Di Penta, Massimiliano and Oliveto,
849Rocco and Panichella, Annibale and Panichella, Sebastiano},
850 title = {Labeling source code with information retrieval methods:
851an empirical study},
852}
853
854@article{devanbu2020deep,
855 year = {2020},
856 journal = {arXiv preprint arXiv:2009.08525},
857 author = {Devanbu et al.},
858 title = {Deep Learning \& Software Engineering: State of Research
859and Future Directions},
860}
861
862@inproceedings{di2020democratizing,
863 year = {2020},
864 pages = {1--9},
865 booktitle = {Proceedings of the 23rd ACM/IEEE International Conference
866on Model Driven Engineering Languages and Systems:
867Companion Proceedings},
868 author = {Di Sipio, Claudio and Di Ruscio, Davide and Nguyen, Phuong
869T},
870 title = {Democratizing the development of recommender systems by
871means of low-code platforms},
872}
873
874@article{dlse_furute_2020,
875 year = {2020},
876 journal = {arXiv preprint arXiv:2009.08525},
877 author = {Devanbu et al.},
878 title = {Deep Learning \& Software Engineering: State of Research
879and Future Directions},
880}
881
882@inproceedings{dong2018boosting,
883 year = {2018},
884 pages = {9185--9193},
885 booktitle = {proc IEEE conference on computer vision and pattern
886recognition},
887 author = {Dong et al.},
888 title = {Boosting adversarial attacks with momentum},
889}
890
891@article{dziugaite2016study,
892 year = {2016},
893 journal = {arXiv preprint arXiv:1608.00853},
894 author = {Dziugaite et al.},
895 title = {A study of the effect of jpg compression on adversarial
896images},
897}
898
899@book{elsayed2020reliability,
900 publisher = {John Wiley \& Sons},
901 year = {2020},
902 author = {Elsayed, Elsayed A},
903 title = {Reliability engineering},
904}
905
906@article{elsken2019neural,
907 publisher = {JMLR. org},
908 year = {2019},
909 pages = {1997--2017},
910 number = {1},
911 volume = {20},
912 journal = {The Journal of Machine Learning Research},
913 author = {Elsken, Thomas and Metzen, Jan Hendrik and Hutter, Frank},
914 title = {Neural architecture search: A survey},
915}
916
917@article{felderer_qa_overview_challenges_2021,
918 year = {2021},
919 journal = {preprint arXiv:2102.05351},
920 author = {Felderer et al.},
921 title = {Quality Assurance for AI-based Systems: Overview and
922Challenges},
923}
924
925@inproceedings{feldt2018ways,
926 organization = {IEEE},
927 year = {2018},
928 pages = {35--41},
929 booktitle = {proc RAISE},
930 author = {Feldt et al.},
931 title = {Ways of applying artificial intelligence in software
932engineering},
933}
934
935@article{ferreira2021software,
936 year = {2021},
937 author = {Ferreira et al.},
938 title = {Software Engineering Meets Deep Learning: A Mapping
939Study},
940}
941
942@article{feurer2015efficient,
943 year = {2015},
944 volume = {28},
945 journal = {Advances in neural information processing systems},
946 author = {Feurer, Matthias and Klein, Aaron and Eggensperger,
947Katharina and Springenberg, Jost and Blum, Manuel and
948Hutter, Frank},
949 title = {Efficient and robust automated machine learning},
950}
951
952@article{feurer2020auto,
953 year = {2020},
954 journal = {arXiv preprint arXiv:2007.04074},
955 author = {Feurer, Matthias and Eggensperger, Katharina and Falkner,
956Stefan and Lindauer, Marius and Hutter, Frank},
957 title = {Auto-sklearn 2.0: The next generation},
958}
959
960@article{fincher2005making,
961 publisher = {Wiley Online Library},
962 year = {2005},
963 pages = {89--93},
964 number = {3},
965 volume = {22},
966 journal = {Expert Systems},
967 author = {Fincher, Sally and Tenenberg, Josh},
968 title = {Making sense of card sorting data},
969}
970
971@inproceedings{finkelstein2008fairness,
972 organization = {IEEE},
973 year = {2008},
974 pages = {115--124},
975 booktitle = {2008 16th IEEE International Requirements Engineering
976Conference},
977 author = {Finkelstein et al.},
978 title = {“Fairness analysis” in requirements assignments},
979}
980
981@article{fischer2004meta,
982 publisher = {ACM New York, NY, USA},
983 year = {2004},
984 pages = {33--37},
985 number = {9},
986 volume = {47},
987 journal = {Communications of the ACM},
988 author = {Fischer, Gerhard and Giaccardi, Elisa and Ye, Yunwen and
989Sutcliffe, Alistair G and Mehandjiev, Nikolay},
990 title = {Meta-design: a manifesto for end-user development},
991}
992
993@phdthesis{fors2016design,
994 school = {Lund University},
995 year = {2016},
996 author = {Fors, Niklas},
997 title = {The Design and Implementation of Bloqqi-A Feature-Based
998Diagram Programming Language},
999}
1000
1001@inproceedings{galhotra2017fairness,
1002 year = {2017},
1003 pages = {498--510},
1004 booktitle = {proc ESEC/FSE},
1005 author = {Galhotra et al.},
1006 title = {Fairness testing: testing software for discrimination},
1007}
1008
1009@misc{gartner,
1010 note = {[Online; accessed 5-November-2022]},
1011 howpublished = {{Available:
1012\url{https://www.gartner.com/reviews/market/enterprise-low-code-application-platform}}},
1013 title = {{Enterprise Low-Code Application Platforms (LCAP) Reviews
1014and Ratings}},
1015 key = {Gartner},
1016}
1017
1018@article{gijsbers2019open,
1019 year = {2019},
1020 journal = {arXiv preprint arXiv:1907.00909},
1021 author = {Gijsbers, Pieter and LeDell, Erin and Thomas, Janek and
1022Poirier, S{\'e}bastien and Bischl, Bernd and Vanschoren,
1023Joaquin},
1024 title = {An open source automl benchmark},
1025}
1026
1027@inproceedings{gil2019towards,
1028 year = {2019},
1029 pages = {614--624},
1030 booktitle = {Proceedings of the 24th International Conference on
1031Intelligent User Interfaces},
1032 author = {Gil, Yolanda and Honaker, James and Gupta, Shikhar and Ma,
1033Yibo and D'Orazio, Vito and Garijo, Daniel and Gadewar,
1034Shruti and Yang, Qifan and Jahanshad, Neda},
1035 title = {Towards human-guided machine learning},
1036}
1037
1038@book{gooden2015race,
1039 publisher = {Routledge},
1040 year = {2015},
1041 author = {Gooden, Susan T},
1042 title = {Race and social equity: A nervous area of government},
1043}
1044
1045@article{goodfellow2014explaining,
1046 year = {2014},
1047 journal = {arXiv preprint arXiv:1412.6572},
1048 author = {Goodfellow et al.},
1049 title = {Explaining and harnessing adversarial examples},
1050}
1051
1052@misc{google-disc,
1053 note = {[Online; accessed 5-January-2021]},
1054 howpublished = {\url{https://workspaceupdates.googleblog.com/2020/01/app-maker-update.html}},
1055 title = {{Google App Maker will be shut down on January 19, 2021}},
1056 key = {googledisc},
1057}
1058
1059@misc{google_automl,
1060 note = {[Online; accessed 5-November-2022]},
1061 howpublished = {{Available: \url{https://cloud.google.com/automl}}},
1062 title = {{Cloud AutoML Custom Machine Learning Models}},
1063 year = {2022},
1064}
1065
1066@misc{googleappmaker,
1067 note = {[Online; accessed 5-January-2021]},
1068 howpublished = {{Available: \url{https://developers.google.com/appmaker}}},
1069 title = {{Google App Maker platform overview}},
1070 year = {2022},
1071}
1072
1073@misc{googleappsheet,
1074 note = {[Online; accessed 13-December-2021]},
1075 howpublished = {{Available: \url{https://www.appsheet.com}}},
1076 title = {{AppSheet, Low-code application development}},
1077 year = {2022},
1078}
1079
1080@misc{googleautoml,
1081 note = {[Online; accessed 5-November-2022]},
1082 howpublished = {{Available: \url{https://www.cloud.google.com/automl/}}},
1083 title = {{Google cloud automl}},
1084 year = {2022},
1085}
1086
1087@article{gu2014towards,
1088 year = {2014},
1089 journal = {arXiv preprint arXiv:1412.5068},
1090 author = {Gu et al.},
1091 title = {Towards deep neural network architectures robust to
1092adversarial examples},
1093}
1094
1095@book{gulli2017deep,
1096 publisher = {Packt Publishing Ltd},
1097 year = {2017},
1098 author = {Gulli, Antonio and Pal, Sujit},
1099 title = {Deep learning with Keras},
1100}
1101
1102@inproceedings{guo2019empirical,
1103 organization = {IEEE},
1104 year = {2019},
1105 pages = {810--822},
1106 booktitle = {2019 34th IEEE/ACM International Conference on Automated
1107Software Engineering (ASE)},
1108 author = {Guo, Qianyu and Chen, Sen and Xie, Xiaofei and Ma, Lei and
1109Hu, Qiang and Liu, Hongtao and Liu, Yang and Zhao, Jianjun
1110and Li, Xiaohong},
1111 title = {An empirical study towards characterizing deep learning
1112development and deployment across different frameworks and
1113platforms},
1114}
1115
1116@misc{h2oai,
1117 note = {[Online; accessed 5-November-2022]},
1118 howpublished = {{Available: \url{https://h2o.ai/}}},
1119 title = {{H2O.ai: AI Cloud Platform}},
1120 year = {2022},
1121}
1122
1123@misc{h2odiverless,
1124 note = {[Online; accessed 5-November-2022]},
1125 howpublished = {{Available:
1126\url{https://h2o.ai/products/h2o-driverless-ai/}}},
1127 title = {{H2O Driverless AI}},
1128 year = {2022},
1129}
1130
1131@article{hailpern2006model,
1132 publisher = {IBM},
1133 year = {2006},
1134 pages = {451--461},
1135 number = {3},
1136 volume = {45},
1137 journal = {IBM systems journal},
1138 author = {Hailpern, Brent and Tarr, Peri},
1139 title = {Model-driven development: The good, the bad, and the
1140ugly},
1141}
1142
1143@phdthesis{halbert1984programming,
1144 school = {University of California, Berkeley},
1145 year = {1984},
1146 author = {Halbert, Daniel Conrad},
1147 title = {Programming by example},
1148}
1149
1150@incollection{hammer2015business,
1151 publisher = {Springer},
1152 year = {2015},
1153 pages = {3--16},
1154 booktitle = {Handbook on business process management 1},
1155 author = {Hammer, Michael},
1156 title = {What is business process management?},
1157}
1158
1159@article{han2020programmers,
1160 publisher = {Springer},
1161 year = {2020},
1162 pages = {2694--2747},
1163 number = {4},
1164 volume = {25},
1165 journal = {Empirical Software Engineering},
1166 author = {Han, Junxiao and Shihab, Emad and Wan, Zhiyuan and Deng,
1167Shuiguang and Xia, Xin},
1168 title = {What do programmers discuss about deep learning
1169frameworks},
1170}
1171
1172@inproceedings{haque2020challenges,
1173 year = {2020},
1174 pages = {1--11},
1175 booktitle = {Proceedings of the 14th ACM/IEEE International Symposium
1176on Empirical Software Engineering and Measurement (ESEM)},
1177 author = {Haque, Mubin Ul and Iwaya, Leonardo Horn and Babar, M
1178Ali},
1179 title = {Challenges in docker development: A large-scale study
1180using stack overflow},
1181}
1182
1183@article{hard2018federated,
1184 year = {2018},
1185 journal = {arXiv preprint arXiv:1811.03604},
1186 author = {Hard et al.},
1187 title = {Federated learning for mobile keyboard prediction},
1188}
1189
1190@inproceedings{he2017adversarial,
1191 year = {2017},
1192 booktitle = {11th $\{$USENIX$\}$ workshop on offensive technologies
1193($\{$WOOT$\}$ 17)},
1194 author = {He et al.},
1195 title = {Adversarial example defense: Ensembles of weak defenses
1196are not strong},
1197}
1198
1199@article{he2019towards,
1200 year = {2019},
1201 journal = {arXiv preprint arXiv:1911.12562},
1202 author = {He et al.},
1203 title = {Towards Security Threats of Deep Learning Systems: A
1204Survey},
1205}
1206
1207@article{he2021automl,
1208 publisher = {Elsevier},
1209 year = {2021},
1210 pages = {106622},
1211 volume = {212},
1212 journal = {Knowledge-Based Systems},
1213 author = {He, Xin and Zhao, Kaiyong and Chu, Xiaowen},
1214 title = {AutoML: A Survey of the State-of-the-Art},
1215}
1216
1217@article{hoffman2018metrics,
1218 year = {2018},
1219 journal = {arXiv preprint arXiv:1812.04608},
1220 author = {Hoffman, Robert R and Mueller, Shane T and Klein, Gary and
1221Litman, Jordan},
1222 title = {Metrics for explainable AI: Challenges and prospects},
1223}
1224
1225@misc{honeycode,
1226 note = {[Online; accessed 5-November-2022]},
1227 howpublished = {{Available: \url{https://www.honeycode.aws/}}},
1228 title = {{Amazon Honeycode platform overview}},
1229 year = {2022},
1230}
1231
1232@article{hosseini2017blocking,
1233 year = {2017},
1234 journal = {arXiv preprint arXiv:1703.04318},
1235 author = {Hosseini et al.},
1236 title = {Blocking transferability of adversarial examples in
1237black-box learning systems},
1238}
1239
1240@inproceedings{hu-evolutiondynamictopic-saner2015,
1241 year = {2015},
1242 title = {Modeling the evolution of development topics using Dynamic
1243Topic Models},
1244 pages = {3--12},
1245 booktitle = {IEEE 22nd International Conference on Software Analysis,
1246Evolution, and Reengineering},
1247 author = {Jiajun Hu and Xiaobing Sun and David Lo and Bin Li},
1248}
1249
1250@inproceedings{hu2020dsnas,
1251 year = {2020},
1252 pages = {12084--12092},
1253 booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision
1254and Pattern Recognition},
1255 author = {Hu, Shoukang and Xie, Sirui and Zheng, Hehui and Liu,
1256Chunxiao and Shi, Jianping and Liu, Xunying and Lin,
1257Dahua},
1258 title = {Dsnas: Direct neural architecture search without parameter
1259retraining},
1260}
1261
1262@article{huang2021robustness,
1263 year = {2021},
1264 journal = {arXiv preprint arXiv:2101.04401},
1265 author = {Huang et al.},
1266 title = {Robustness of on-device Models: Adversarial Attack to Deep
1267Learning Models on Android Apps},
1268}
1269
1270@inproceedings{humbatova2020taxonomy,
1271 year = {2020},
1272 pages = {1110--1121},
1273 booktitle = {Proceedings of the ACM/IEEE 42nd International Conference
1274on Software Engineering},
1275 author = {Humbatova, Nargiz and Jahangirova, Gunel and Bavota,
1276Gabriele and Riccio, Vincenzo and Stocco, Andrea and
1277Tonella, Paolo},
1278 title = {Taxonomy of real faults in deep learning systems},
1279}
1280
1281@inproceedings{ihirwe2020low,
1282 year = {2020},
1283 pages = {1--8},
1284 booktitle = {Proceedings of the 23rd ACM/IEEE International Conference
1285on Model Driven Engineering Languages and Systems:
1286Companion Proceedings},
1287 author = {Ihirwe, Felicien and Di Ruscio, Davide and Mazzini, Silvia
1288and Pierini, Pierluigi and Pierantonio, Alfonso},
1289 title = {Low-code Engineering for Internet of things: A state of
1290research},
1291}
1292
1293@article{iot21,
1294 doi = {10.1007/s10664-021-10021-5},
1295 journal = {Empirical Software Engineering},
1296 volume = {26},
1297 title = {An empirical study of IoT topics in IoT developer
1298discussions on Stack Overflow},
1299 pages = {},
1300 month = {11},
1301 year = {2021},
1302 author = {Uddin, Gias and Sabir, Fatima and Guéhéneuc, Yann-Gaël
1303and Alam, Omar and Khomh, Foutse},
1304}
1305
1306@article{islam2019developers,
1307 year = {2019},
1308 journal = {arXiv preprint arXiv:1906.11940},
1309 author = {Islam, Md Johirul and Nguyen, Hoan Anh and Pan, Rangeet
1310and Rajan, Hridesh},
1311 title = {What do developers ask about ml libraries? a large-scale
1312study using stack overflow},
1313}
1314
1315@inproceedings{jacinto2020test,
1316 year = {2020},
1317 pages = {1--5},
1318 booktitle = {Proceedings of the 23rd ACM/IEEE International Conference
1319on Model Driven Engineering Languages and Systems:
1320Companion Proceedings},
1321 author = {Jacinto, Alexandre and Louren{\c{c}}o, Miguel and
1322Ferreira, Carla},
1323 title = {Test mocks for low-code applications built with
1324OutSystems},
1325}
1326
1327@inproceedings{jia2008constructing,
1328 organization = {IEEE},
1329 year = {2008},
1330 pages = {249--258},
1331 booktitle = {2008 Eighth IEEE International Working Conference on
1332Source Code Analysis and Manipulation},
1333 author = {Jia et al.},
1334 title = {Constructing subtle faults using higher order mutation
1335testing},
1336}
1337
1338@inproceedings{jiang2018trust,
1339 year = {2018},
1340 pages = {5546--5557},
1341 booktitle = {proc NeurIPS},
1342 author = {Jiang et al.},
1343 title = {To Trust Or Not To Trust A Classifier.},
1344}
1345
1346@inproceedings{jin2019auto,
1347 year = {2019},
1348 pages = {1946--1956},
1349 booktitle = {Proceedings of the 25th ACM SIGKDD international
1350conference on knowledge discovery \& data mining},
1351 author = {Jin, Haifeng and Song, Qingquan and Hu, Xia},
1352 title = {Auto-keras: An efficient neural architecture search
1353system},
1354}
1355
1356@article{jones1995end,
1357 publisher = {IEEE},
1358 year = {1995},
1359 pages = {68--70},
1360 number = {9},
1361 volume = {28},
1362 journal = {Computer},
1363 author = {Jones, Capers},
1364 title = {End user programming},
1365}
1366
1367@article{karmaker2021automl,
1368 publisher = {ACM New York, NY},
1369 year = {2021},
1370 pages = {1--36},
1371 number = {8},
1372 volume = {54},
1373 journal = {ACM Computing Surveys (CSUR)},
1374 author = {Karmaker, Shubhra Kanti and Hassan, Md Mahadi and Smith,
1375Micah J and Xu, Lei and Zhai, Chengxiang and
1376Veeramachaneni, Kalyan},
1377 title = {Automl to date and beyond: Challenges and opportunities},
1378}
1379
1380@article{kendall-taumetric-biometrica1938,
1381 year = {1938},
1382 volume = {30},
1383 title = {A New Measure of Rank Correlation},
1384 pages = {81-93},
1385 number = {1},
1386 journal = {Biometrika},
1387 author = {M. G. Kendall},
1388}
1389
1390@inproceedings{khan-docsmell-saner2021,
1391 year = {2021},
1392 title = {Automatic Detection of Five API Documentation Smells:
1393Practitioners’ Perspectives},
1394 pages = {12},
1395 booktitle = {IEEE International Conference on Software Analysis,
1396Evolution and Reengineering (SANER)},
1397 author = {Junaed Younus Khan and Md. Tawkat Islam Khondaker and Gias
1398Uddin and Anindya Iqbal},
1399}
1400
1401@inproceedings{khan2021automatic,
1402 organization = {IEEE},
1403 year = {2021},
1404 pages = {318--329},
1405 booktitle = {2021 IEEE International Conference on Software Analysis,
1406Evolution and Reengineering (SANER)},
1407 author = {Khan, Junaed Younus and Khondaker, Md Tawkat Islam and
1408Uddin, Gias and Iqbal, Anindya},
1409 title = {Automatic detection of five api documentation smells:
1410Practitioners’ perspectives},
1411}
1412
1413@inproceedings{khorram2020challenges,
1414 year = {2020},
1415 pages = {1--10},
1416 booktitle = {Proceedings of the 23rd ACM/IEEE International Conference
1417on Model Driven Engineering Languages and Systems:
1418Companion Proceedings},
1419 author = {Khorram, Faezeh and Mottu, Jean-Marie and Suny{\'e},
1420Gerson},
1421 title = {Challenges \& opportunities in low-code testing},
1422}
1423
1424@article{kim2016examples,
1425 year = {2016},
1426 pages = {2280--2288},
1427 volume = {29},
1428 journal = {Advances in neural information processing systems},
1429 author = {Kim et al.},
1430 title = {Examples are not enough, learn to criticize! criticism for
1431interpretability},
1432}
1433
1434@incollection{kotthoff2019auto,
1435 publisher = {Springer, Cham},
1436 year = {2019},
1437 pages = {81--95},
1438 booktitle = {Automated machine learning},
1439 author = {Kotthoff, Lars and Thornton, Chris and Hoos, Holger H and
1440Hutter, Frank and Leyton-Brown, Kevin},
1441 title = {Auto-WEKA: Automatic model selection and hyperparameter
1442optimization in WEKA},
1443}
1444
1445@inproceedings{kourouklidis2020towards,
1446 year = {2020},
1447 pages = {1--8},
1448 booktitle = {Proceedings of the 23rd ACM/IEEE International Conference
1449on Model Driven Engineering Languages and Systems:
1450Companion Proceedings},
1451 author = {Kourouklidis, Panagiotis and Kolovos, Dimitris and
1452Matragkas, Nicholas and Noppen, Joost},
1453 title = {Towards a low-code solution for monitoring machine
1454learning model performance},
1455}
1456
1457@article{kruskal1957historical,
1458 publisher = {Taylor \& Francis},
1459 year = {1957},
1460 pages = {356--360},
1461 number = {279},
1462 volume = {52},
1463 journal = {Journal of the American Statistical Association},
1464 author = {Kruskal, William H},
1465 title = {Historical notes on the Wilcoxon unpaired two-sample
1466test},
1467}
1468
1469@inproceedings{kulesza2015principles,
1470 year = {2015},
1471 pages = {126--137},
1472 booktitle = {Proceedings of the 20th international conference on
1473intelligent user interfaces},
1474 author = {Kulesza et al.},
1475 title = {Principles of explanatory debugging to personalize
1476interactive machine learning},
1477}
1478
1479@article{kumar2017obamanet,
1480 year = {2017},
1481 journal = {arXiv preprint arXiv:1801.01442},
1482 author = {Kumar et al.},
1483 title = {Obamanet: Photo-realistic lip-sync from text},
1484}
1485
1486@inproceedings{ledell2020h2o,
1487 year = {2020},
1488 volume = {2020},
1489 booktitle = {Proceedings of the AutoML Workshop at ICML},
1490 author = {LeDell, Erin and Poirier, Sebastien},
1491 title = {H2o automl: Scalable automatic machine learning},
1492}
1493
1494@article{lee2019human,
1495 year = {2019},
1496 pages = {59--70},
1497 number = {2},
1498 volume = {42},
1499 journal = {IEEE Data Eng. Bull.},
1500 author = {Lee, Doris Jung Lin and Macke, Stephen and Xin, Doris and
1501Lee, Angela and Huang, Silu and Parameswaran, Aditya G},
1502 title = {A Human-in-the-loop Perspective on AutoML: Milestones and
1503the Road Ahead.},
1504}
1505
1506@article{lee2020human,
1507 year = {2020},
1508 journal = {IEEE Data Engineering Bulletin},
1509 author = {Lee, Doris Jung-Lin and Macke, Stephen},
1510 title = {A Human-in-the-loop Perspective on AutoML: Milestones and
1511the Road Ahead},
1512}
1513
1514@inproceedings{lenarduzzi2021software,
1515 organization = {Springer},
1516 year = {2021},
1517 pages = {43--53},
1518 booktitle = {International Conference on Software Quality},
1519 author = {Lenarduzzi et al.},
1520 title = {Software Quality for AI: Where We Are Now?},
1521}
1522
1523@inproceedings{lethbridge2021low,
1524 organization = {Springer},
1525 year = {2021},
1526 pages = {202--212},
1527 booktitle = {International Symposium on Leveraging Applications of
1528Formal Methods},
1529 author = {Lethbridge, Timothy C},
1530 title = {Low-code is often high-code, so we must design low-code
1531platforms to enable proper software engineering},
1532}
1533
1534@article{li-studysoftwareloggingusingtopic-emse2018,
1535 year = {2018},
1536 volume = {23},
1537 title = {Studying software logging using topic models},
1538 pages = {2655–2694},
1539 number = {},
1540 journal = {Empirical Software Engineering },
1541 author = {Heng Li and Tse-Hsun (Peter) Chen and Weiyi Shang and
1542Ahmed E. Hassan },
1543}
1544
1545@inproceedings{li2019lfs,
1546 year = {2019},
1547 pages = {8410--8419},
1548 booktitle = {Proceedings of the IEEE/CVF International Conference on
1549Computer Vision},
1550 author = {Li, Chuming and Yuan, Xin and Lin, Chen and Guo, Minghao
1551and Wu, Wei and Yan, Junjie and Ouyang, Wanli},
1552 title = {Am-lfs: Automl for loss function search},
1553}
1554
1555@article{li2020federated,
1556 publisher = {IEEE},
1557 year = {2020},
1558 pages = {50--60},
1559 number = {3},
1560 volume = {37},
1561 journal = {IEEE Signal Processing Magazine},
1562 author = {Li et al.},
1563 title = {Federated learning: Challenges, methods, and future
1564directions},
1565}
1566
1567@inproceedings{li2021automl,
1568 year = {2021},
1569 pages = {4853--4856},
1570 booktitle = {Proceedings of the 30th ACM International Conference on
1571Information \& Knowledge Management},
1572 author = {Li, Yaliang and Wang, Zhen and Xie, Yuexiang and Ding,
1573Bolin and Zeng, Kai and Zhang, Ce},
1574 title = {Automl: From methodology to application},
1575}
1576
1577@article{li2022volcanoml,
1578 publisher = {Springer},
1579 year = {2022},
1580 pages = {1--25},
1581 journal = {The VLDB Journal},
1582 author = {Li, Yang and Shen, Yu and Zhang, Wentao and Zhang, Ce and
1583Cui, Bin},
1584 title = {VolcanoML: speeding up end-to-end AutoML via scalable
1585search space decomposition},
1586}
1587
1588@incollection{lieberman2006end,
1589 publisher = {Springer},
1590 year = {2006},
1591 pages = {1--8},
1592 booktitle = {End user development},
1593 author = {Lieberman, Henry and Patern{\`o}, Fabio and Klann, Markus
1594and Wulf, Volker},
1595 title = {End-user development: An emerging paradigm},
1596}
1597
1598@article{lin2020software,
1599 publisher = {IEEE},
1600 year = {2020},
1601 pages = {1825--1848},
1602 number = {10},
1603 volume = {108},
1604 journal = {Proceedings of the IEEE},
1605 author = {Lin, Guanjun and Wen, Sheng and Han, Qing-Long and Zhang,
1606Jun and Xiang, Yang},
1607 title = {Software vulnerability detection using deep neural
1608networks: a survey},
1609}
1610
1611@inproceedings{linares2013exploratory,
1612 organization = {IEEE},
1613 year = {2013},
1614 pages = {93--96},
1615 booktitle = {2013 10th Working Conference on Mining Software
1616Repositories (MSR)},
1617 author = {Linares-V{\'a}squez, Mario and Dit, Bogdan and Poshyvanyk,
1618Denys},
1619 title = {An exploratory analysis of mobile development issues using
1620stack overflow},
1621}
1622
1623@article{lipton2018mythos,
1624 publisher = {ACM New York, NY, USA},
1625 year = {2018},
1626 pages = {31--57},
1627 number = {3},
1628 volume = {16},
1629 journal = {Queue},
1630 author = {Lipton, Zachary C},
1631 title = {The Mythos of Model Interpretability: In machine learning,
1632the concept of interpretability is both important and
1633slippery.},
1634}
1635
1636@article{loper2002nltk,
1637 year = {2002},
1638 journal = {arXiv preprint cs/0205028},
1639 author = {Loper, Edward and Bird, Steven},
1640 title = {NLTK: the natural language toolkit},
1641}
1642
1643@misc{lotus,
1644 note = {[Online; accessed 5-November-2022]},
1645 howpublished = {{Available: \url{https://help.hcltechsw.com/}}},
1646 title = {{IBM Lotus software}},
1647 year = {2022},
1648}
1649
1650@article{lowcodeapp,
1651 numpages = {1},
1652 pages = {119},
1653 month = {April},
1654 journal = {J. Comput. Sci. Coll.},
1655 issn = {1937-4771},
1656 number = {6},
1657 volume = {34},
1658 address = {Evansville, IN, USA},
1659 publisher = {Consortium for Computing Sciences in Colleges},
1660 issue_date = {April 2019},
1661 year = {2019},
1662 title = {Low Code App Development},
1663 author = {Fryling, Meg},
1664}
1665
1666@inproceedings{lowcodeiot,
1667 series = {MODELS '20},
1668 location = {Virtual Event, Canada},
1669 keywords = {low-code engineering, IoT, model driven engineering
1670(MDE)},
1671 numpages = {8},
1672 articleno = {74},
1673 booktitle = {Proceedings of the 23rd ACM/IEEE International Conference
1674on Model Driven Engineering Languages and Systems:
1675Companion Proceedings},
1676 doi = {10.1145/3417990.3420208},
1677 url = {https://doi.org/10.1145/3417990.3420208},
1678 address = {New York, NY, USA},
1679 publisher = {Association for Computing Machinery},
1680 isbn = {9781450381352},
1681 year = {2020},
1682 title = {Low-Code Engineering for Internet of Things: A State of
1683Research},
1684 author = {Ihirwe, Felicien and Di Ruscio, Davide and Mazzini, Silvia
1685and Pierini, Pierluigi and Pierantonio, Alfonso},
1686}
1687
1688@inproceedings{lowcodetesting,
1689 series = {MODELS '20},
1690 location = {Virtual Event, Canada},
1691 keywords = {low-code, citizen developer, low-code development
1692platform, testing},
1693 numpages = {10},
1694 articleno = {70},
1695 booktitle = {Proceedings of the 23rd ACM/IEEE International Conference
1696on Model Driven Engineering Languages and Systems:
1697Companion Proceedings},
1698 doi = {10.1145/3417990.3420204},
1699 url = {https://doi.org/10.1145/3417990.3420204},
1700 address = {New York, NY, USA},
1701 publisher = {Association for Computing Machinery},
1702 isbn = {9781450381352},
1703 year = {2020},
1704 title = {Challenges \& Opportunities in Low-Code Testing},
1705 author = {Khorram, Faezeh and Mottu, Jean-Marie and Suny\'{e},
1706Gerson},
1707}
1708
1709@misc{lowcodewiki,
1710 note = {[Online; accessed 5-January-2021]},
1711 howpublished = {{Available:
1712\url{https://en.wikipedia.org/wiki/Low-code_development_platform}}},
1713 title = {{Low-code development platform }},
1714 year = {2022},
1715}
1716
1717@misc{lowcodewiki2,
1718 note = {[Online; accessed 5-January-2021]},
1719 howpublished = {{Available:
1720\url{https://en.wikipedia.org/wiki/Low-code_development_platform}}},
1721 title = {{Low-code development platform }},
1722 year = {2022},
1723}
1724
1725@article{lundberg2017unified,
1726 year = {2017},
1727 journal = {arXiv preprint arXiv:1705.07874},
1728 author = {Lundberg et al.},
1729 title = {A unified approach to interpreting model predictions},
1730}
1731
1732@inproceedings{luo2021characteristics,
1733 year = {2021},
1734 pages = {1--11},
1735 booktitle = {Proceedings of the 15th ACM/IEEE International Symposium
1736on Empirical Software Engineering and Measurement (ESEM)},
1737 author = {Luo, Yajing and Liang, Peng and Wang, Chong and Shahin,
1738Mojtaba and Zhan, Jing},
1739 title = {Characteristics and Challenges of Low-Code Development:
1740The Practitioners' Perspective},
1741}
1742
1743@inproceedings{lwakatare2019taxonomy,
1744 organization = {Springer, Cham},
1745 year = {2019},
1746 pages = {227--243},
1747 booktitle = {International Conference on Agile Software Development},
1748 author = {Lwakatare, Lucy Ellen and Raj, Aiswarya and Bosch, Jan and
1749Olsson, Helena Holmstr{\"o}m and Crnkovic, Ivica},
1750 title = {A taxonomy of software engineering challenges for machine
1751learning systems: An empirical investigation},
1752}
1753
1754@inproceedings{ma2018mode,
1755 year = {2018},
1756 pages = {175--186},
1757 booktitle = {proc ESEC/FSE},
1758 author = {Ma et al.},
1759 title = {MODE: automated neural network model debugging via state
1760differential analysis and input selection},
1761}
1762
1763@article{madry2017towards,
1764 year = {2017},
1765 journal = {arXiv preprint arXiv:1706.06083},
1766 author = {Madry et al.},
1767 title = {Towards deep learning models resistant to adversarial
1768attacks},
1769}
1770
1771@inproceedings{mazzawi2019improvingks,
1772 year = {2019},
1773 booktitle = {INTERSPEECH},
1774 author = {Hanna Mazzawi and Xavi Gonzalvo and Aleksandar Kracun and
1775Prashant Sridhar and Niranjan A. Subrahmanya and Ignacio
1776Lopez-Moreno and Hyun-jin Park and Patrick Violette},
1777 title = {Improving Keyword Spotting and Language Identification via
1778Neural Architecture Search at Scale},
1779}
1780
1781@article{mccallum2002mallet,
1782 year = {2002},
1783 journal = {http://mallet. cs. umass. edu},
1784 author = {McCallum, Andrew Kachites},
1785 title = {Mallet: A machine learning for language toolkit},
1786}
1787
1788@article{mchugh2012interrater,
1789 publisher = {Medicinska naklada},
1790 year = {2012},
1791 pages = {276--282},
1792 number = {3},
1793 volume = {22},
1794 journal = {Biochemia medica},
1795 author = {McHugh, Mary L},
1796 title = {Interrater reliability: the kappa statistic},
1797}
1798
1799@inproceedings{mcmahan2017communication,
1800 organization = {PMLR},
1801 year = {2017},
1802 pages = {1273--1282},
1803 booktitle = {AISTATS},
1804 author = {McMahan et al.},
1805 title = {Communication-efficient learning of deep networks from
1806decentralized data},
1807}
1808
1809@article{mehrabi2019survey,
1810 year = {2019},
1811 journal = {arXiv preprint arXiv:1908.09635},
1812 author = {Mehrabi et al.},
1813 title = {A survey on bias and fairness in machine learning},
1814}
1815
1816@article{mehrabi_fairness_survey_2019,
1817 year = {2019},
1818 journal = {arXiv preprint arXiv:1908.09635},
1819 author = {Mehrabi et al.},
1820 title = {A survey on bias and fairness in machine learning},
1821}
1822
1823@inproceedings{mei2015using,
1824 year = {2015},
1825 number = {1},
1826 volume = {29},
1827 booktitle = {Proceedings of the AAAI Conference on Artificial
1828Intelligence},
1829 author = {Mei et al.},
1830 title = {Using machine teaching to identify optimal training-set
1831attacks on machine learners},
1832}
1833
1834@inproceedings{meldrum2017crowdsourced,
1835 year = {2017},
1836 pages = {180--185},
1837 booktitle = {Proceedings of the 21st International Conference on
1838Evaluation and Assessment in Software Engineering},
1839 author = {Meldrum, Sarah and Licorish, Sherlock A and Savarimuthu,
1840Bastin Tony Roy},
1841 title = {Crowdsourced knowledge on stack overflow: A systematic
1842mapping study},
1843}
1844
1845@inproceedings{mellor2021neural,
1846 organization = {PMLR},
1847 year = {2021},
1848 pages = {7588--7598},
1849 booktitle = {International Conference on Machine Learning},
1850 author = {Mellor, Joe and Turner, Jack and Storkey, Amos and
1851Crowley, Elliot J},
1852 title = {Neural architecture search without training},
1853}
1854
1855@misc{mendix,
1856 note = {[Online; accessed 5-January-2021]},
1857 howpublished = {{Available: \url{https://www.mendix.com/}}},
1858 title = {{Mendix platform overview}},
1859 year = {2022},
1860}
1861
1862@inproceedings{meng2017magnet,
1863 year = {2017},
1864 pages = {135--147},
1865 booktitle = {proc of ACM SIGSAC CCS},
1866 author = {Meng et al.},
1867 title = {Magnet: a two-pronged defense against adversarial
1868examples},
1869}
1870
1871@article{mernik2005and,
1872 publisher = {ACM New York, NY, USA},
1873 year = {2005},
1874 pages = {316--344},
1875 number = {4},
1876 volume = {37},
1877 journal = {ACM computing surveys (CSUR)},
1878 author = {Mernik, Marjan and Heering, Jan and Sloane, Anthony M},
1879 title = {When and how to develop domain-specific languages},
1880}
1881
1882@misc{microsoftpowerfx,
1883 note = {[Online; accessed 13-December-2021]},
1884 howpublished = {{Available:
1885\url{https://docs.microsoft.com/en-us/power-platform/power-fx/overview}}},
1886 title = {{Microsoft Power FX}},
1887 year = {2022},
1888}
1889
1890@incollection{mirjalili2019genetic,
1891 publisher = {Springer},
1892 year = {2019},
1893 pages = {43--55},
1894 booktitle = {Evolutionary algorithms and neural networks},
1895 author = {Mirjalili, Seyedali},
1896 title = {Genetic algorithm},
1897}
1898
1899@article{ml_practice_2019,
1900 publisher = {IEEE},
1901 year = {2019},
1902 journal = {In TSE},
1903 author = {Wan et al.},
1904 title = {How does machine learning change software development
1905practices?},
1906}
1907
1908@misc{mljar,
1909 url = {https://github.com/mljar/mljar-supervised},
1910 title = {MLJAR: State-of-the-art Automated Machine Learning
1911Framework for Tabular Data. Version 0.10.3},
1912 address = {\L{}apy, Poland},
1913 publisher = {MLJAR},
1914 year = {2021},
1915 author = {Aleksandra P\l{}o\'{n}ska and Piotr P\l{}o\'{n}ski},
1916}
1917
1918@misc{mlops,
1919 note = {[Online; accessed 5-November-2022]},
1920 howpublished = {{Available: \url{https://ml-ops.org/}}},
1921 title = {{MLOps Overview}},
1922 year = {2022},
1923}
1924
1925@inproceedings{morgenthaler2012searching,
1926 organization = {IEEE},
1927 year = {2012},
1928 pages = {1--6},
1929 booktitle = {Workshop on Managing Technical Debt (MTD)},
1930 author = {Morgenthaler et al.},
1931 title = {Searching for build debt: Experiences managing technical
1932debt at Google},
1933}
1934
1935@book{myers2004art,
1936 publisher = {Wiley Online Library},
1937 year = {2004},
1938 volume = {2},
1939 author = {Myers et al.},
1940 title = {The art of software testing},
1941}
1942
1943@inproceedings{myers2006invited,
1944 year = {2006},
1945 pages = {75--80},
1946 booktitle = {CHI'06 extended abstracts on Human factors in computing
1947systems},
1948 author = {Myers, Brad A and Ko, Amy J and Burnett, Margaret M},
1949 title = {Invited research overview: end-user programming},
1950}
1951
1952@inproceedings{nagarnaik2015survey,
1953 organization = {IEEE},
1954 year = {2015},
1955 pages = {1603--1608},
1956 booktitle = {2015 2nd International Conference on Electronics and
1957Communication Systems (ICECS)},
1958 author = {Nagarnaik, Paritosh and Thomas, A},
1959 title = {Survey on recommendation system methods},
1960}
1961
1962@mastersthesis{ness2019potential,
1963 year = {2019},
1964 author = {Ness, Cecilie and Hansen, Marita Eltvik},
1965 title = {Potential of low-code in the healthcare sector: an
1966exploratory study of the potential of low-code development
1967in the healthcare sector in Norway},
1968}
1969
1970@book{o2016weapons,
1971 publisher = {Crown},
1972 year = {2016},
1973 author = {O'neil, Cathy},
1974 title = {Weapons of math destruction: How big data increases
1975inequality and threatens democracy},
1976}
1977
1978@inproceedings{o2019deep,
1979 organization = {Springer},
1980 year = {2019},
1981 pages = {128--144},
1982 booktitle = {Science and Information Conference},
1983 author = {O’Mahony, Niall and Campbell, Sean and Carvalho,
1984Anderson and Harapanahalli, Suman and Hernandez, Gustavo
1985Velasco and Krpalkova, Lenka and Riordan, Daniel and Walsh,
1986Joseph},
1987 title = {Deep learning vs. traditional computer vision},
1988}
1989
1990@inproceedings{olson2016evaluation,
1991 year = {2016},
1992 pages = {485--492},
1993 booktitle = {Proceedings of the genetic and evolutionary computation
1994conference 2016},
1995 author = {Olson, Randal S and Bartley, Nathan and Urbanowicz, Ryan J
1996and Moore, Jason H},
1997 title = {Evaluation of a tree-based pipeline optimization tool for
1998automating data science},
1999}
2000
2001@misc{oneblink,
2002 note = {[Online; accessed 5-November-2022]},
2003 howpublished = {{Available: \url{https://www.oneblink.io/}}},
2004 title = {{OneBlink platform overview}},
2005 year = {2022},
2006}
2007
2008@misc{oracle_apex,
2009 note = {[Online; accessed 5-November-2022]},
2010 howpublished = {{Available: \url{https://apex.oracle.com/}}},
2011 title = {{Oracle Apex Platform}},
2012 year = {2022},
2013}
2014
2015@inproceedings{overeem2021proposing,
2016 organization = {IEEE},
2017 year = {2021},
2018 pages = {88--97},
2019 booktitle = {2021 ACM/IEEE International Conference on Model Driven
2020Engineering Languages and Systems Companion (MODELS-C)},
2021 author = {Overeem, Michiel and Jansen, Slinger},
2022 title = {Proposing a Framework for Impact Analysis for Low-Code
2023Development Platforms},
2024}
2025
2026@article{paleyes2020challenges,
2027 year = {2020},
2028 journal = {preprint arXiv:2011.09926},
2029 author = {Paleyes et al.},
2030 title = {Challenges in deploying machine learning: a survey of case
2031studies},
2032}
2033
2034@inproceedings{pan2020decomposing,
2035 year = {2020},
2036 pages = {889--900},
2037 booktitle = {proc ESEC/FSE},
2038 author = {Pan et al.},
2039 title = {On decomposing a deep neural network into modules},
2040}
2041
2042@misc{pandemic-low-code,
2043 note = {[Online; accessed 5-August-2022]},
2044 howpublished = {{Available:
2045\url{https://www.designnews.com/automation/programming-gains-speed-developers-turn-low-code-during-pandemic}}},
2046 title = {{Programming Gains Speed As Developers Turn to Low-Code
2047During the Pandemic}},
2048 year = {2022},
2049}
2050
2051@inbook{pane-morenatureeuse-springer2006,
2052 doi = {10.1007/1-4020-5386-X_3},
2053 isbn = {978-1-4020-4220-1},
2054 title = {More Natural Programming Languages and Environments},
2055 pages = {31-50},
2056 publisher = {Springer},
2057 month = {10},
2058 year = {2006},
2059 author = {Pane, John and Myers, Brad},
2060}
2061
2062@inproceedings{papernot2016distillation,
2063 organization = {IEEE},
2064 year = {2016},
2065 pages = {582--597},
2066 booktitle = { symposium on security and privacy (SP)},
2067 author = {Papernot et al.},
2068 title = {Distillation as a defense to adversarial perturbations
2069against deep neural networks},
2070}
2071
2072@inproceedings{patel2008examining,
2073 year = {2008},
2074 pages = {1563--1566},
2075 booktitle = {AAAI},
2076 author = {Patel, Kayur and Fogarty, James and Landay, James A and
2077Harrison, Beverly L},
2078 title = {Examining Difficulties Software Developers Encounter in
2079the Adoption of Statistical Machine Learning.},
2080}
2081
2082@article{paterno2013end,
2083 publisher = {Hindawi},
2084 year = {2013},
2085 volume = {2013},
2086 journal = {International Scholarly Research Notices},
2087 author = {Patern{\`o}, Fabio},
2088 title = {End user development: Survey of an emerging field for
2089empowering people},
2090}
2091
2092@misc{pcmag,
2093 note = {[Online; accessed 5-January-2021]},
2094 howpublished = {{Available:
2095\url{https://www.pcmag.com/picks/the-best-low-code-development-platforms}}},
2096 title = {{The Best Low-Code Development Platforms}},
2097 year = {2022},
2098}
2099
2100@article{pedregosa2011scikit,
2101 publisher = {JMLR. org},
2102 year = {2011},
2103 pages = {2825--2830},
2104 volume = {12},
2105 journal = {the Journal of machine Learning research},
2106 author = {Pedregosa, Fabian and Varoquaux, Ga{\"e}l and Gramfort,
2107Alexandre and Michel, Vincent and Thirion, Bertrand and
2108Grisel, Olivier and Blondel, Mathieu and Prettenhofer,
2109Peter and Weiss, Ron and Dubourg, Vincent and others},
2110 title = {Scikit-learn: Machine learning in Python},
2111}
2112
2113@inproceedings{pei2017deepxplore,
2114 year = {2017},
2115 pages = {1--18},
2116 booktitle = {proceedings of the 26th Symposium on Operating Systems
2117Principles},
2118 author = {Pei et al.},
2119 title = {Deepxplore: Automated whitebox testing of deep learning
2120systems},
2121}
2122
2123@article{peppard2000customer,
2124 publisher = {Elsevier},
2125 year = {2000},
2126 pages = {312--327},
2127 number = {3},
2128 volume = {18},
2129 journal = {European Management Journal},
2130 author = {Peppard, Joe},
2131 title = {Customer relationship management (CRM) in financial
2132services},
2133}
2134
2135@inproceedings{petersen2009waterfall,
2136 organization = {Springer},
2137 year = {2009},
2138 pages = {386--400},
2139 booktitle = {International Conference on Product-Focused Software
2140Process Improvement},
2141 author = {Petersen, Kai and Wohlin, Claes and Baca, Dejan},
2142 title = {The waterfall model in large-scale development},
2143}
2144
2145@incollection{phalake2021low,
2146 publisher = {Springer},
2147 year = {2021},
2148 pages = {689--697},
2149 booktitle = {Information and Communication Technology for Competitive
2150Strategies (ICTCS 2020)},
2151 author = {Phalake, Vaishali S and Joshi, Shashank D},
2152 title = {Low Code Development Platform for Digital Transformation},
2153}
2154
2155@inproceedings{pham2018efficient,
2156 organization = {PMLR},
2157 year = {2018},
2158 pages = {4095--4104},
2159 booktitle = {International conference on machine learning},
2160 author = {Pham, Hieu and Guan, Melody and Zoph, Barret and Le, Quoc
2161and Dean, Jeff},
2162 title = {Efficient neural architecture search via parameters
2163sharing},
2164}
2165
2166@inproceedings{pleuss2013model,
2167 year = {2013},
2168 pages = {13--22},
2169 booktitle = {Proceedings of the 5th ACM SIGCHI symposium on Engineering
2170interactive computing systems},
2171 author = {Pleuss, Andreas and Wollny, Stefan and Botterweck, Goetz},
2172 title = {Model-driven development and evolution of customized user
2173interfaces},
2174}
2175
2176@inproceedings{ponzanelli2014improving,
2177 organization = {IEEE},
2178 year = {2014},
2179 pages = {541--544},
2180 booktitle = {2014 IEEE international conference on software maintenance
2181and evolution},
2182 author = {Ponzanelli, Luca and Mocci, Andrea and Bacchelli, Alberto
2183and Lanza, Michele and Fullerton, David},
2184 title = {Improving low quality stack overflow post detection},
2185}
2186
2187@article{poshyvanyk-featurelocationtopic-tse2007,
2188 year = {2007},
2189 volume = {33},
2190 title = {Feature Location Using Probabilistic Ranking of Methods
2191Based on Execution Scenarios and Information Retrieval},
2192 pages = {420-432},
2193 number = {6},
2194 journal = {IEEE Transactions on Software Engineering},
2195 author = {Denys Poshyvanyk and Yann-Gaël Guéhéneuc and Andrian
2196Marcus and Giuliano Antoniol and Václav T Rajlich},
2197}
2198
2199@misc{powerapps,
2200 note = {[Online; accessed 5-January-2021]},
2201 howpublished = {{Available: \url{https://powerapps.microsoft.com/en-us/}}},
2202 title = {{Microsoft power apps platform overview}},
2203 year = {2022},
2204}
2205
2206@article{qiu2019review,
2207 publisher = {Multidisciplinary Digital Publishing Institute},
2208 year = {2019},
2209 pages = {909},
2210 number = {5},
2211 volume = {9},
2212 journal = {Applied Sciences},
2213 author = {Qiu et al.},
2214 title = {Review of artificial intelligence adversarial attack and
2215defense technologies},
2216}
2217
2218@misc{quickbase,
2219 note = {[Online; accessed 5-January-2021]},
2220 howpublished = {{Available:
2221\url{https://www.quickbase.com/product/product-overview}}},
2222 title = {{Quickbase platform overview}},
2223 year = {2022},
2224}
2225
2226@article{ramasubramanian2013effective,
2227 year = {2013},
2228 pages = {4536--4538},
2229 number = {12},
2230 volume = {2},
2231 journal = {International Journal of Advanced Research in Computer and
2232Communication Engineering},
2233 author = {Ramasubramanian, C and Ramya, R},
2234 title = {Effective pre-processing activities in text mining using
2235improved porter’s stemming algorithm},
2236}
2237
2238@inproceedings{rao-traceabilitybugtopic-msr2011,
2239 year = {2011},
2240 title = {Retrieval from software libraries for bug localization: a
2241comparative study of generic and composite text models},
2242 pages = {43–52},
2243 booktitle = {8th Working Conference on Mining Software Repositories},
2244 author = {Shivani Rao and Avinash C Kak},
2245}
2246
2247@misc{rapid_miner,
2248 note = {[Online; accessed 5-November-2022]},
2249 howpublished = {{Available: \url{https://rapidminer.com/}}},
2250 title = {{RapidMiner: Amplify the Impact of Your People,
2251Expertise.}},
2252 year = {2022},
2253}
2254
2255@inproceedings{real2017large,
2256 organization = {PMLR},
2257 year = {2017},
2258 pages = {2902--2911},
2259 booktitle = {International Conference on Machine Learning},
2260 author = {Real, Esteban and Moore, Sherry and Selle, Andrew and
2261Saxena, Saurabh and Suematsu, Yutaka Leon and Tan, Jie and
2262Le, Quoc V and Kurakin, Alexey},
2263 title = {Large-scale evolution of image classifiers},
2264}
2265
2266@inproceedings{real2020automl,
2267 organization = {PMLR},
2268 year = {2020},
2269 pages = {8007--8019},
2270 booktitle = {International Conference on Machine Learning},
2271 author = {Real, Esteban and Liang, Chen and So, David and Le, Quoc},
2272 title = {Automl-zero: Evolving machine learning algorithms from
2273scratch},
2274}
2275
2276@inproceedings{rehurek2010software,
2277 organization = {Citeseer},
2278 year = {2010},
2279 booktitle = {In Proceedings of the LREC 2010 Workshop on New Challenges
2280for NLP Frameworks},
2281 author = {Rehurek, Radim and Sojka, Petr},
2282 title = {Software framework for topic modelling with large
2283corpora},
2284}
2285
2286@inproceedings{ren2019discovering,
2287 organization = {IEEE},
2288 year = {2019},
2289 pages = {151--162},
2290 booktitle = {2019 34th IEEE/ACM International Conference on Automated
2291Software Engineering (ASE)},
2292 author = {Ren, Xiaoxue and Xing, Zhenchang and Xia, Xin and Li,
2293Guoqiang and Sun, Jianling},
2294 title = {Discovering, explaining and summarizing controversial
2295discussions in community q\&a sites},
2296}
2297
2298@article{resnick2009scratch,
2299 publisher = {ACM New York, NY, USA},
2300 year = {2009},
2301 pages = {60--67},
2302 number = {11},
2303 volume = {52},
2304 journal = {Communications of the ACM},
2305 author = {Resnick, Mitchel and Maloney, John and
2306Monroy-Hern{\'a}ndez, Andr{\'e}s and Rusk, Natalie and
2307Eastmond, Evelyn and Brennan, Karen and Millner, Amon and
2308Rosenbaum, Eric and Silver, Jay and Silverman, Brian and
2309others},
2310 title = {Scratch: programming for all},
2311}
2312
2313@inproceedings{ribeiro2016should,
2314 year = {2016},
2315 pages = {1135--1144},
2316 booktitle = {proc ACM KDD},
2317 author = {Ribeiro et al.},
2318 title = {Why should i trust you? Explaining the predictions of any
2319classifier},
2320}
2321
2322@inproceedings{rice2020overfitting,
2323 organization = {PMLR},
2324 year = {2020},
2325 pages = {8093--8104},
2326 booktitle = {International Conference on Machine Learning},
2327 author = {Rice et al.},
2328 title = {Overfitting in adversarially robust deep learning},
2329}
2330
2331@article{robillard-apiproperty-ieeetse2012,
2332 year = {2012},
2333 title = {Automated {API} Property Inference Techniques},
2334 pages = {28},
2335 journal = {IEEE Transactions on Software Engineering},
2336 author = {Martin P. Robillard and Eric Bodden and David Kawrykow and
2337Mira Mezini and Tristan Ratchford},
2338}
2339
2340@inproceedings{roder2015exploring,
2341 year = {2015},
2342 pages = {399--408},
2343 booktitle = {Proceedings of the eighth ACM international conference on
2344Web search and data mining},
2345 author = {R{\"o}der, Michael and Both, Andreas and Hinneburg,
2346Alexander},
2347 title = {Exploring the space of topic coherence measures},
2348}
2349
2350@article{roscher2020explainable,
2351 publisher = {IEEE},
2352 year = {2020},
2353 pages = {42200--42216},
2354 volume = {8},
2355 journal = {IEEE Access},
2356 author = {Roscher et al.},
2357 title = {Explainable machine learning for scientific insights and
2358discoveries},
2359}
2360
2361@article{rosen-mobiledeveloperso-ese2015,
2362 year = {2015},
2363 volume = {},
2364 title = {What are mobile developers asking about? A large scale
2365study using stack overflow},
2366 pages = {33},
2367 number = {},
2368 journal = {Empirical Software Engineering},
2369 author = {Christoffer Rosen and Emad Shihab},
2370}
2371
2372@article{rosen2016mobile,
2373 publisher = {Springer},
2374 year = {2016},
2375 pages = {1192--1223},
2376 number = {3},
2377 volume = {21},
2378 journal = {Empirical Software Engineering},
2379 author = {Rosen, Christoffer and Shihab, Emad},
2380 title = {What are mobile developers asking about? a large scale
2381study using stack overflow},
2382}
2383
2384@article{rymer2019forrester,
2385 publisher = {Forrester Research},
2386 year = {2019},
2387 author = {Rymer, John R and Koplowitz, Rob and Leaders, Salesforce
2388Are},
2389 title = {The forrester wave(tm) Low-code development platforms for
2390ad\&d professionals, q1 2019},
2391}
2392
2393@inproceedings{sahay2020supporting,
2394 organization = {IEEE},
2395 year = {2020},
2396 pages = {171--178},
2397 booktitle = {2020 46th Euromicro Conference on Software Engineering and
2398Advanced Applications (SEAA)},
2399 author = {Sahay, Apurvanand and Indamutsa, Arsene and Di Ruscio,
2400Davide and Pierantonio, Alfonso},
2401 title = {Supporting the understanding and comparison of low-code
2402development platforms},
2403}
2404
2405@misc{salesforce,
2406 note = {[Online; accessed 5-November-2022]},
2407 howpublished = {{Available: \url{https://www.salesforce.com/in/?ir=1}}},
2408 title = {{Salesforce platform overview}},
2409 key = {salesforce},
2410}
2411
2412@article{samangouei2018defense,
2413 year = {2018},
2414 journal = {arXiv preprint arXiv:1805.06605},
2415 author = {Samangouei et al.},
2416 title = {Defense-gan: Protecting classifiers against adversarial
2417attacks using generative models},
2418}
2419
2420@article{santhanam2019engineering,
2421 year = {2019},
2422 journal = {arXiv preprint arXiv:1910.12582},
2423 author = {Santhanam et al.r},
2424 title = {Engineering reliable deep learning systems},
2425}
2426
2427@article{saria_safe_reliable_2019,
2428 year = {2019},
2429 journal = {arXiv preprint arXiv:1904.07204},
2430 author = {Saria et al.},
2431 title = {Tutorial: safe and reliable machine learning},
2432}
2433
2434@article{schelter2018challenges,
2435 year = {2018},
2436 author = {Schelter et al.},
2437 title = {On challenges in machine learning model management},
2438}
2439
2440@inproceedings{schulam2019can,
2441 organization = {PMLR},
2442 year = {2019},
2443 pages = {1022--1031},
2444 booktitle = {proc of Artificial Intelligence and Statistics},
2445 author = {Schulam et al.},
2446 title = {Can you trust this prediction? Auditing pointwise
2447reliability after learning},
2448}
2449
2450@article{sculley2014machine,
2451 year = {2014},
2452 author = {Sculley et al.},
2453 title = {Machine learning: The high interest credit card of
2454technical debt},
2455}
2456
2457@article{sculley2015hidden,
2458 year = {2015},
2459 volume = {28},
2460 journal = {Advances in neural information processing systems},
2461 author = {Sculley, David and Holt, Gary and Golovin, Daniel and
2462Davydov, Eugene and Phillips, Todd and Ebner, Dietmar and
2463Chaudhary, Vinay and Young, Michael and Crespo,
2464Jean-Francois and Dennison, Dan},
2465 title = {Hidden technical debt in machine learning systems},
2466}
2467
2468@inproceedings{sculley_hiddent_debt_2015,
2469 year = {2015},
2470 pages = {2503--2511},
2471 booktitle = {Advances in neural information processing systems},
2472 author = {Sculley et al.},
2473 title = {Hidden technical debt in machine learning systems},
2474}
2475
2476@inproceedings{se_dl18,
2477 organization = {IEEE},
2478 year = {2018},
2479 pages = {50--59},
2480 booktitle = {proc of Software Engineering and Advanced Applications
2481(SEAA)},
2482 author = {Arpteg et al.},
2483 title = {Software engineering challenges of deep learning},
2484}
2485
2486@article{selic2003pragmatics,
2487 publisher = {IEEE},
2488 year = {2003},
2489 pages = {19--25},
2490 number = {5},
2491 volume = {20},
2492 journal = {IEEE software},
2493 author = {Selic, Bran},
2494 title = {The pragmatics of model-driven development},
2495}
2496
2497@inproceedings{selic2007systematic,
2498 organization = {IEEE},
2499 year = {2007},
2500 pages = {2--9},
2501 booktitle = {10th IEEE International Symposium on Object and
2502Component-Oriented Real-Time Distributed Computing
2503(ISORC'07)},
2504 author = {Selic, Bran},
2505 title = {A systematic approach to domain-specific language design
2506using UML},
2507}
2508
2509@article{semlahead18,
2510 publisher = {IEEE},
2511 year = {2018},
2512 pages = {81--84},
2513 number = {5},
2514 volume = {35},
2515 journal = {IEEE Software},
2516 author = {Khomh et al.},
2517 title = {Software engineering for machine-learning applications:
2518The road ahead},
2519}
2520
2521@article{shafiq2020machine,
2522 year = {2020},
2523 journal = {arXiv preprint arXiv:2005.13299},
2524 author = {Shafiq et al.},
2525 title = {Machine Learning for Software Engineering: A Systematic
2526Mapping},
2527}
2528
2529@article{shi2020automated,
2530 publisher = {IEEE},
2531 year = {2020},
2532 pages = {7145--7154},
2533 number = {11},
2534 volume = {22},
2535 journal = {IEEE Transactions on Intelligent Transportation Systems},
2536 author = {Shi, Xiupeng and Wong, Yiik Diew and Chai, Chen and Li,
2537Michael Zhi-Feng},
2538 title = {An automated machine learning (AutoML) method of risk
2539prediction for decision-making of autonomous vehicles},
2540}
2541
2542@incollection{singh2020introduction,
2543 publisher = {Springer},
2544 year = {2020},
2545 pages = {1--24},
2546 booktitle = {Learn TensorFlow 2.0},
2547 author = {Singh, Pramod and Manure, Avinash},
2548 title = {Introduction to tensorflow 2.0},
2549}
2550
2551@inproceedings{sinha2010human,
2552 organization = {IEEE},
2553 year = {2010},
2554 pages = {1--4},
2555 booktitle = {2010 3rd International Conference on Emerging Trends in
2556Engineering and Technology},
2557 author = {Sinha, Gaurav and Shahi, Rahul and Shankar, Mani},
2558 title = {Human computer interaction},
2559}
2560
2561@misc{sodump,
2562 note = {[Online; accessed 5-November-2022]},
2563 howpublished = {{Available:
2564\url{https://archive.org/details/stackexchange}}},
2565 year = {2020},
2566 title = {{ Stack exchange data dump }},
2567 author = {Stack Exchange},
2568}
2569
2570@article{sokolova2009,
2571 publisher = {Elsevier},
2572 year = {2009},
2573 pages = {427--437},
2574 number = {4},
2575 volume = {45},
2576 journal = {Information processing \& management},
2577 author = {Sokolova, Marina and Lapalme, Guy},
2578 title = {A systematic analysis of performance measures for
2579classification tasks},
2580}
2581
2582@misc{splunk,
2583 note = {[Online; accessed 5-November-2022]},
2584 howpublished = {{Available: \url{https://www.splunk.com/}}},
2585 title = {{Splunk: The Data Platform for the Hybrid World}},
2586 year = {2022},
2587}
2588
2589@inproceedings{sun-exploretopicmodelsurvey-snpd2016,
2590 year = {2016},
2591 title = {Exploring topic models in software engineering data
2592analysis: A survey},
2593 pages = {357-362},
2594 booktitle = {17th IEEE/ACIS International Conference on Software
2595Engineering, Artificial Intelligence, Networking and
2596Parallel/Distributed Computing},
2597 author = {Xiaobing Sun and Xiangyue Liu and Bin Li and Yucong Duan
2598and Hui Yang and Jiajun Hu},
2599}
2600
2601@article{sun-softwaremaintenancehistorytopic-cis2015,
2602 year = {2015},
2603 volume = {},
2604 title = {What Information in Software Historical Repositories Do We
2605Need to Support Software Maintenance Tasks? An Approach
2606Based on Topic Model},
2607 pages = {22-37},
2608 number = {},
2609 journal = {Computer and Information Science },
2610 author = {Xiaobing Sun and Bin Li and Yun Li and Ying Chen},
2611}
2612
2613@article{sun-softwaremaintenancetopic-ist2015,
2614 year = {2015},
2615 volume = {66},
2616 title = {MSR4SM: Using topic models to effectively mining software
2617repositories for software maintenance tasks},
2618 pages = {671-694},
2619 number = {},
2620 journal = {Information and Software Technology},
2621 author = {Xiaobing Sun and Bixin Li and Hareton Leung and Bin Li and
2622Yun Li},
2623}
2624
2625@article{survey_transfer_learning_2009,
2626 publisher = {IEEE},
2627 year = {2009},
2628 pages = {1345--1359},
2629 number = {10},
2630 volume = {22},
2631 journal = {In TKDE},
2632 author = {Pan et al.},
2633 title = {A survey on transfer learning},
2634}
2635
2636@book{sutton2018reinforcement,
2637 publisher = {MIT press},
2638 year = {2018},
2639 author = {Sutton, Richard S and Barto, Andrew G},
2640 title = {Reinforcement learning: An introduction},
2641}
2642
2643@article{szegedy2013intriguing,
2644 year = {2013},
2645 journal = {arXiv preprint arXiv:1312.6199},
2646 author = {Szegedy et al.},
2647 title = {Intriguing properties of neural networks},
2648}
2649
2650@inproceedings{tata2017quick,
2651 year = {2017},
2652 pages = {1643--1651},
2653 booktitle = {Proceedings of the 23rd ACM SIGKDD International
2654Conference on Knowledge Discovery and Data Mining},
2655 author = {Tata et al.},
2656 title = {Quick access: building a smart experience for Google
2657drive},
2658}
2659
2660@inproceedings{team2016azureml,
2661 organization = {PMLR},
2662 year = {2016},
2663 pages = {1--13},
2664 booktitle = {Conference on Predictive APIs and Apps},
2665 author = {Team, AzureML},
2666 title = {AzureML: Anatomy of a machine learning service},
2667}
2668
2669@inproceedings{thomas-evolutionsourcecodehistorytopic-msr2011,
2670 year = {2011},
2671 title = {Modeling the evolution of topics in source code
2672histories},
2673 pages = {173--182},
2674 booktitle = {8th working conference on mining software repositories},
2675 author = {Stephen W. Thomas and Bram Adams and Ahmed E Hassan and
2676Dorothea Blostein},
2677}
2678
2679@article{thomas-softwareevolutionusingtopic-scp2014,
2680 year = {2014},
2681 volume = {80},
2682 title = {Studying software evolution using topic models},
2683 pages = {457-479},
2684 number = {B},
2685 journal = {Science of Computer Programming},
2686 author = {Stephen W. Thomas and Bram Adams and Ahmed E Hassan and
2687Dorothea Blostein},
2688}
2689
2690@inproceedings{tian-softwarecategorizetopic-msr2009,
2691 year = {2009},
2692 title = {Using Latent Dirichlet Allocation for automatic
2693categorization of software},
2694 pages = {163--166},
2695 booktitle = {6th international working conference on mining software
2696repositories},
2697 author = {Kai Tian and Meghan Revelle and Denys Poshyvanyk},
2698}
2699
2700@inproceedings{tisi2019lowcomote,
2701 year = {2019},
2702 booktitle = {STAF 2019 Co-Located Events Joint Proceedings: 1st Junior
2703Researcher Community Event, 2nd International Workshop on
2704Model-Driven Engineering for Design-Runtime Interaction in
2705Complex Systems, and 1st Research Project Showcase Workshop
2706co-located with Software Technologies: Applications and
2707Foundations (STAF 2019)},
2708 author = {Tisi, Massimo and Mottu, Jean-Marie and Kolovos, Dimitrios
2709and De Lara, Juan and Guerra, Esther and Di Ruscio, Davide
2710and Pierantonio, Alfonso and Wimmer, Manuel},
2711 title = {Lowcomote: Training the next generation of experts in
2712scalable low-code engineering platforms},
2713}
2714
2715@article{torres2018demand,
2716 year = {2018},
2717 journal = {Bloomberg. Com},
2718 author = {Torres, Craig},
2719 title = {Demand for programmers hits full boil as US job market
2720simmers},
2721}
2722
2723@misc{total_low_code,
2724 note = {[Online; accessed 5-August-2022]},
2725 howpublished = {{Available:
2726\url{https://www.spreadsheetweb.com/how-many-low-code-no-code-platforms-are-out-there/}}},
2727 title = {{How many Low-Code/No-Code platforms are out there?}},
2728 year = {2022},
2729}
2730
2731@article{tramer2017ensemble,
2732 year = {2017},
2733 journal = {arXiv preprint arXiv:1705.07204},
2734 author = {Tram{\`e}r et al.},
2735 title = {Ensemble adversarial training: Attacks and defenses},
2736}
2737
2738@misc{transmogrifai,
2739 note = {[Online; accessed 5-November-2022]},
2740 howpublished = {{Available: \url{https://transmogrif.ai/}}},
2741 title = {{TransmogrifAI - AutoML library for building modular,
2742reusable system}},
2743 year = {2022},
2744}
2745
2746@inproceedings{treude2011programmers,
2747 year = {2011},
2748 pages = {804--807},
2749 booktitle = {Proceedings of the 33rd international conference on
2750software engineering},
2751 author = {Treude, Christoph and Barzilay, Ohad and Storey,
2752Margaret-Anne},
2753 title = {How do programmers ask and answer questions on the
2754web?(nier track)},
2755}
2756
2757@inproceedings{truong2019towards,
2758 organization = {IEEE},
2759 year = {2019},
2760 pages = {1471--1479},
2761 booktitle = {2019 IEEE 31st international conference on tools with
2762artificial intelligence (ICTAI)},
2763 author = {Truong, Anh and Walters, Austin and Goodsitt, Jeremy and
2764Hines, Keegan and Bruss, C Bayan and Farivar, Reza},
2765 title = {Towards automated machine learning: Evaluation and
2766comparison of AutoML approaches and tools},
2767}
2768
2769@techreport{uddin-apiaspectmining-techreport2017,
2770 year = {2017},
2771 institution = {\url{https://swat.polymtl.ca/data/opinionvalue-technical-report.pdf}},
2772 title = {Mining API aspects in API reviews},
2773 author = {Gias Uddin and Foutse Khomh},
2774}
2775
2776@article{uddin-howapidocumentationfails-ieeesw2015,
2777 year = {2015},
2778 volume = {32},
2779 title = {How API Documentation Fails},
2780 pages = {76-83},
2781 number = {4},
2782 journal = {IEEE Softawre},
2783 author = {Gias Uddin and Martin P. Robillard},
2784}
2785
2786@article{uddin-opinerapiusagescenario-ist2020,
2787 year = {2020},
2788 volume = {},
2789 title = {Automatic Mining of API Usage Scenarios from Stack
2790Overflow},
2791 pages = {16},
2792 number = {},
2793 journal = {Information and Software Technology (IST)},
2794 author = {Gias Uddin and Foutse Khomh and Chanchal K Roy},
2795}
2796
2797@article{uddin-opinerapiusagescenario-tosem2020,
2798 year = {2020},
2799 volume = {},
2800 title = { Automatic API Usage Scenario Documentation from Technical
2801Q\&A Sites},
2802 pages = {43},
2803 number = {},
2804 journal = {ACM Transactions on Software Engineering and Methodology},
2805 author = {Gias Uddin and Foutse Khomh and Chanchal K Roy},
2806}
2807
2808@inproceedings{uddin-opinerreviewalgo-ase2017,
2809 year = {2017},
2810 title = {Automatic Summarization of {API} Reviews},
2811 pages = {12},
2812 booktitle = {Proc. 32nd IEEE/ACM International Conference on Automated
2813Software Engineering},
2814 author = {Gias Uddin and Foutse Khomh},
2815}
2816
2817@inproceedings{uddin-opinerreviewtooldemo-ase2017,
2818 year = {2017},
2819 title = {Opiner: A Search and Summarization Engine for {API}
2820Reviews},
2821 pages = {6},
2822 booktitle = {Proc. 32nd IEEE/ACM International Conference on Automated
2823Software Engineering},
2824 author = {Gias Uddin and Foutse Khomh},
2825}
2826
2827@article{uddin-opinionsurvey-tse2019,
2828 year = {2019},
2829 volume = {},
2830 title = {Understanding How and Why Developers Seek and Analyze API
2831Related Opinions},
2832 pages = {40},
2833 number = {},
2834 journal = {IEEE Transactions on Software Engineering},
2835 author = {Gias Uddin and Olga Baysal and Latifa Guerroj and Foutse
2836Khomh},
2837}
2838
2839@article{uddin-opinionvalue-tse2019,
2840 year = {2019},
2841 volume = {},
2842 title = {Automatic Opinion Mining from {API} Reviews from Stack
2843Overflow},
2844 pages = {35},
2845 number = {},
2846 journal = {IEEE Transactions on Software Engineering},
2847 author = {Gias Uddin and Foutse Khomh},
2848}
2849
2850@inproceedings{uddin-temporalapiusage-ase2011,
2851 year = {2011},
2852 title = {Analyzing Temporal {API} Usage Patterns},
2853 pages = {456--459},
2854 booktitle = {Proc. 26th IEEE/ACM Intl. Conf. on Automated Software
2855Engineering},
2856 author = {Gias Uddin and Barth{\'{e}}l{\'{e}}my Dagenais and Martin
2857P. Robillard},
2858}
2859
2860@inproceedings{uddin-temporalapiusage-icse2012,
2861 year = {2012},
2862 title = {Temporal Analysis of {API} Usage Concepts},
2863 pages = {804--814},
2864 booktitle = {Proc. 34th IEEE/ACM Intl. Conf. on Software Engineering},
2865 author = {Gias Uddin and Barth{\'{e}}l{\'{e}}my Dagenais and Martin
2866P. Robillard},
2867}
2868
2869@article{uddin2015api,
2870 publisher = {IEEE},
2871 year = {2015},
2872 pages = {68--75},
2873 number = {4},
2874 volume = {32},
2875 journal = {Ieee software},
2876 author = {Uddin, Gias and Robillard, Martin P},
2877 title = {How API documentation fails},
2878}
2879
2880@inproceedings{uddin2017automatic,
2881 organization = {IEEE},
2882 year = {2017},
2883 pages = {159--170},
2884 booktitle = {2017 32nd IEEE/ACM International Conference on Automated
2885Software Engineering (ASE)},
2886 author = {Uddin, Gias and Khomh, Foutse},
2887 title = {Automatic summarization of API reviews},
2888}
2889
2890@inproceedings{uddin2019towards,
2891 organization = {IEEE},
2892 year = {2019},
2893 pages = {310--311},
2894 booktitle = {2019 IEEE/ACM 41st International Conference on Software
2895Engineering: Companion Proceedings (ICSE-Companion)},
2896 author = {Uddin, Gias and Khomh, Foutse and Roy, Chanchal K},
2897 title = {Towards crowd-sourced API documentation},
2898}
2899
2900@article{uddin2021automatic,
2901 publisher = {ACM New York, NY, USA},
2902 year = {2021},
2903 pages = {1--45},
2904 number = {3},
2905 volume = {30},
2906 journal = {ACM Transactions on Software Engineering and Methodology
2907(TOSEM)},
2908 author = {Uddin, Gias and Khomh, Foutse and Roy, Chanchal K},
2909 title = {Automatic api usage scenario documentation from technical
2910q\&a sites},
2911}
2912
2913@article{umble2003enterprise,
2914 publisher = {Elsevier},
2915 year = {2003},
2916 pages = {241--257},
2917 number = {2},
2918 volume = {146},
2919 journal = {European journal of operational research},
2920 author = {Umble, Elisabeth J and Haft, Ronald R and Umble, M
2921Michael},
2922 title = {Enterprise resource planning: Implementation procedures
2923and critical success factors},
2924}
2925
2926@inproceedings{ur2014practical,
2927 year = {2014},
2928 pages = {803--812},
2929 booktitle = {Proceedings of the SIGCHI Conference on Human Factors in
2930Computing Systems},
2931 author = {Ur, Blase and McManus, Elyse and Pak Yong Ho, Melwyn and
2932Littman, Michael L},
2933 title = {Practical trigger-action programming in the smart home},
2934}
2935
2936@article{van2000domain,
2937 publisher = {ACM New York, NY, USA},
2938 year = {2000},
2939 pages = {26--36},
2940 number = {6},
2941 volume = {35},
2942 journal = {ACM Sigplan Notices},
2943 author = {Van Deursen, Arie and Klint, Paul and Visser, Joost},
2944 title = {Domain-specific languages: An annotated bibliography},
2945}
2946
2947@article{vincent2019magic,
2948 year = {2019},
2949 journal = {Gartner report},
2950 author = {Vincent, Paul and Iijima, Kimihiko and Driver, Mark and
2951Wong, Jason and Natis, Yefim},
2952 title = {Magic quadrant for enterprise low-code application
2953platforms},
2954}
2955
2956@misc{vinyl,
2957 note = {[Online; accessed 5-January-2021]},
2958 howpublished = {{Available: \url{https://zudy.com/}}},
2959 title = {{Vinyl platform overview}},
2960 key = {vinyl},
2961}
2962
2963@inproceedings{vogelsang2019requirements,
2964 organization = {IEEE},
2965 year = {2019},
2966 pages = {245--251},
2967 booktitle = {International Requirements Engineering Conference
2968Workshops (REW)},
2969 author = {Vogelsang et al.},
2970 title = {Requirements engineering for machine learning:
2971Perspectives from data scientists},
2972}
2973
2974@article{voigt2017eu,
2975 publisher = {Springer},
2976 year = {2017},
2977 pages = {3152676},
2978 volume = {10},
2979 journal = {A Practical Guide, 1st Ed., Cham: Springer International
2980Publishing},
2981 author = {Voigt et al.},
2982 title = {The eu general data protection regulation (gdpr)},
2983}
2984
2985@article{von2003open,
2986 publisher = {Massachusetts Institute of Technology, Cambridge, MA},
2987 year = {2003},
2988 pages = {14--18},
2989 number = {3},
2990 volume = {44},
2991 journal = {MIT Sloan Management Review},
2992 author = {Von Krogh, Georg},
2993 title = {Open-source software development},
2994}
2995
2996@article{wan2019discussed,
2997 publisher = {IEEE},
2998 year = {2019},
2999 journal = {IEEE Transactions on Software Engineering},
3000 author = {Wan, Zhiyuan and Xia, Xin and Hassan, Ahmed E},
3001 title = {What is Discussed about Blockchain? A Case Study on the
3002Use of Balanced LDA and the Reference Architecture of a
3003Domain to Capture Online Discussions about Blockchain
3004platforms across the Stack Exchange Communities},
3005}
3006
3007@inproceedings{wang2019atmseer,
3008 year = {2019},
3009 pages = {1--12},
3010 booktitle = {Proceedings of the 2019 CHI Conference on Human Factors in
3011Computing Systems},
3012 author = {Wang, Qianwen and Ming, Yao and Jin, Zhihua and Shen,
3013Qiaomu and Liu, Dongyu and Smith, Micah J and
3014Veeramachaneni, Kalyan and Qu, Huamin},
3015 title = {Atmseer: Increasing transparency and controllability in
3016automated machine learning},
3017}
3018
3019@article{wang2019human,
3020 publisher = {ACM New York, NY, USA},
3021 year = {2019},
3022 pages = {1--24},
3023 number = {CSCW},
3024 volume = {3},
3025 journal = {Proceedings of the ACM on Human-Computer Interaction},
3026 author = {Wang, Dakuo and Weisz, Justin D and Muller, Michael and
3027Ram, Parikshit and Geyer, Werner and Dugan, Casey and
3028Tausczik, Yla and Samulowitz, Horst and Gray, Alexander},
3029 title = {Human-ai collaboration in data science: Exploring data
3030scientists' perceptions of automated ai},
3031}
3032
3033@inproceedings{wardat2022deepdiagnosis,
3034 year = {2022},
3035 pages = {561--572},
3036 booktitle = {Proceedings of the 44th International Conference on
3037Software Engineering},
3038 author = {Wardat, Mohammad and Cruz, Breno Dantas and Le, Wei and
3039Rajan, Hridesh},
3040 title = {DeepDiagnosis: automatically diagnosing faults and
3041recommending actionable fixes in deep learning programs},
3042}
3043
3044@article{waszkowski2019low,
3045 publisher = {Elsevier},
3046 year = {2019},
3047 pages = {376--381},
3048 number = {10},
3049 volume = {52},
3050 journal = {IFAC-PapersOnLine},
3051 author = {Waszkowski, Robert},
3052 title = {Low-code platform for automating business processes in
3053manufacturing},
3054}
3055
3056@article{waszkowski2019low-automating,
3057 doi = {10.1016/j.ifacol.2019.10.060},
3058 journal = {IFAC-PapersOnLine},
3059 volume = {52},
3060 title = {Low-code platform for automating business processes in
3061manufacturing},
3062 pages = {376-381},
3063 month = {01},
3064 year = {2019},
3065 author = {Waszkowski, Robert},
3066}
3067
3068@manual{website:stackoverflow,
3069 note = {Last accessed on 14 November 2020},
3070 year = {2020},
3071 title = {Stack Overflow Questions},
3072 author = {Stack Overflow},
3073 address = {\url{https://stackoverflow.com/questions/}},
3074}
3075
3076@inproceedings{weidele2020autoaiviz,
3077 year = {2020},
3078 pages = {308--312},
3079 booktitle = {Proceedings of the 25th International Conference on
3080Intelligent User Interfaces},
3081 author = {Weidele, Daniel Karl I and Weisz, Justin D and Oduor,
3082Erick and Muller, Michael and Andres, Josh and Gray,
3083Alexander and Wang, Dakuo},
3084 title = {AutoAIViz: opening the blackbox of automated artificial
3085intelligence with conditional parallel coordinates},
3086}
3087
3088@inproceedings{willers2020safety,
3089 organization = {Springer},
3090 year = {2020},
3091 pages = {336--350},
3092 booktitle = {International Conference on Computer Safety, Reliability,
3093and Security},
3094 author = {Willers et al.},
3095 title = {Safety concerns and mitigation approaches regarding the
3096use of deep learning in safety-critical perception tasks},
3097}
3098
3099@book{wohlin2012experimentation,
3100 publisher = {Springer Science \& Business Media},
3101 year = {2012},
3102 author = {Wohlin, Claes and Runeson, Per and H{\"o}st, Martin and
3103Ohlsson, Magnus C and Regnell, Bj{\"o}rn and Wessl{\'e}n,
3104Anders},
3105 title = {Experimentation in software engineering},
3106}
3107
3108@inproceedings{wolber2011app,
3109 year = {2011},
3110 pages = {601--606},
3111 booktitle = {Proceedings of the 42nd ACM technical symposium on
3112Computer science education},
3113 author = {Wolber, David},
3114 title = {App inventor and real-world motivation},
3115}
3116
3117@misc{wong2019low,
3118 year = {2019},
3119 author = {Wong, Jason and Driver, Mark and Vincent, Paul},
3120 title = {Low-Code Development Technologies Evaluation Guide},
3121}
3122
3123@article{woo2020rise,
3124 publisher = {Elsevier},
3125 year = {2020},
3126 pages = {960},
3127 number = {9},
3128 volume = {6},
3129 journal = {Engineering (Beijing, China)},
3130 author = {Woo, Marcus},
3131 title = {The rise of no/low code software development—No
3132experience needed?},
3133}
3134
3135@article{wuest2016machine,
3136 publisher = {Taylor \& Francis},
3137 year = {2016},
3138 pages = {23--45},
3139 number = {1},
3140 volume = {4},
3141 journal = {Production \& Manufacturing Research},
3142 author = {Wuest, Thorsten and Weimer, Daniel and Irgens, Christopher
3143and Thoben, Klaus-Dieter},
3144 title = {Machine learning in manufacturing: advantages, challenges,
3145and applications},
3146}
3147
3148@inproceedings{xie2017adversarial,
3149 year = {2017},
3150 pages = {1369--1378},
3151 booktitle = {IEEE International Conference on Computer Vision},
3152 author = {Xie et al.},
3153 title = {Adversarial examples for semantic segmentation and object
3154detection},
3155}
3156
3157@inproceedings{xie_2019,
3158 doi = {10.1109/CVPR.2019.00059},
3159 pages = {501-509},
3160 number = {},
3161 volume = {},
3162 year = {2019},
3163 title = {Feature Denoising for Improving Adversarial Robustness},
3164 booktitle = {2019 IEEE/CVF Conference on Computer Vision and Pattern
3165Recognition (CVPR)},
3166 author = {C. {Xie} et al.},
3167}
3168
3169@inproceedings{xu2019explainable,
3170 organization = {Springer},
3171 year = {2019},
3172 pages = {563--574},
3173 booktitle = {CCF international conference on natural language
3174processing and Chinese computing},
3175 author = {Xu, Feiyu and Uszkoreit, Hans and Du, Yangzhou and Fan,
3176Wei and Zhao, Dongyan and Zhu, Jun},
3177 title = {Explainable AI: A brief survey on history, research areas,
3178approaches and challenges},
3179}
3180
3181@article{yan2018deep,
3182 year = {2018},
3183 journal = {arXiv preprint arXiv:1803.00404},
3184 author = {Yan et al.},
3185 title = {Deep defense: Training dnns with improved adversarial
3186robustness},
3187}
3188
3189@inproceedings{yang2016query,
3190 organization = {IEEE},
3191 year = {2016},
3192 pages = {391--401},
3193 booktitle = {2016 IEEE/ACM 13th Working Conference on Mining Software
3194Repositories (MSR)},
3195 author = {Yang, Di and Hussain, Aftab and Lopes, Cristina Videira},
3196 title = {From query to usable code: an analysis of stack overflow
3197code snippets},
3198}
3199
3200@article{yang2016security,
3201 publisher = {Springer},
3202 year = {2016},
3203 pages = {910--924},
3204 number = {5},
3205 volume = {31},
3206 journal = {Journal of Computer Science and Technology},
3207 author = {Yang, Xin-Li and Lo, David and Xia, Xin and Wan, Zhi-Yuan
3208and Sun, Jian-Ling},
3209 title = {What security questions do developers ask? a large-scale
3210study of stack overflow posts},
3211}
3212
3213@article{yang2019evaluation,
3214 year = {2019},
3215 journal = {arXiv preprint arXiv:1912.12522},
3216 author = {Yang, Antoine and Esperan{\c{c}}a, Pedro M and Carlucci,
3217Fabio M},
3218 title = {NAS evaluation is frustratingly hard},
3219}
3220
3221@inproceedings{zhang2018empirical,
3222 year = {2018},
3223 pages = {129--140},
3224 booktitle = {Proceedings of the 27th ACM SIGSOFT International
3225Symposium on Software Testing and Analysis},
3226 author = {Zhang, Yuhao and Chen, Yifan and Cheung, Shing-Chi and
3227Xiong, Yingfei and Zhang, Lu},
3228 title = {An empirical study on TensorFlow program bugs},
3229}
3230
3231@article{zhang2019defense,
3232 year = {2019},
3233 journal = {preprint arXiv:1907.10764},
3234 author = {Zhang et al.},
3235 title = {Defense against adversarial attacks using feature
3236scattering-based adversarial training},
3237}
3238
3239@inproceedings{zhang2020empirical,
3240 organization = {IEEE},
3241 year = {2020},
3242 pages = {1159--1170},
3243 booktitle = {2020 IEEE/ACM 42nd International Conference on Software
3244Engineering (ICSE)},
3245 author = {Zhang, Ru and Xiao, Wencong and Zhang, Hongyu and Liu, Yu
3246and Lin, Haoxiang and Yang, Mao},
3247 title = {An empirical study on program failures of deep learning
3248jobs},
3249}
3250
3251@article{zhang_ml_testing_survey_horizons_2020,
3252 publisher = {IEEE},
3253 year = {2020},
3254 journal = {In TSE},
3255 author = {Zhang et al.},
3256 title = {Machine learning testing: Survey, landscapes and
3257horizons},
3258}
3259
3260@article{zhu2016devops,
3261 publisher = {IEEE},
3262 year = {2016},
3263 pages = {32--34},
3264 number = {3},
3265 volume = {33},
3266 journal = {IEEE Software},
3267 author = {Zhu, Liming and Bass, Len and Champlin-Scharff, George},
3268 title = {DevOps and its practices},
3269}
3270
3271@article{zhu2019model,
3272 publisher = {ACM New York, NY, USA},
3273 year = {2019},
3274 pages = {1--32},
3275 number = {6},
3276 volume = {52},
3277 journal = {ACM Computing Surveys (CSUR)},
3278 author = {Zhu, Meng and Wang, Alf Inge},
3279 title = {Model-driven game development: A literature review},
3280}
3281
3282@article{zhuang2021easyfl,
3283 year = {2021},
3284 journal = {arXiv preprint arXiv:2105.07603},
3285 author = {Zhuang, Weiming and Gan, Xin and Wen, Yonggang and Zhang,
3286Shuai},
3287 title = {EasyFL: A Low-code Federated Learning Platform For
3288Dummies},
3289}
3290
3291@misc{zohocreator,
3292 note = {[Online; accessed 5-January-2021]},
3293 howpublished = {{Available: \url{https://www.zoho.com/creator/}}},
3294 title = {{Zoho Creator platform overview}},
3295 key = {zohocreator},
3296}
3297
3298@misc{software_dev,
3299 note = {[Online; accessed 5-January-2021]},
3300 howpublished = {{Available: \url{https://en.wikipedia.org/wiki/Software_development}}},
3301 title = {{Software development overview}},
3302 key = {software_dev},
3303}
3304
3305@misc{github_copilot,
3306 note = {[Online; accessed 5-January-2021]},
3307 howpublished = {{Available: \url{https://github.com/features/copilot}}},
3308 title = {{Your AI pair programmer}},
3309 key = {github_copilot},
3310}
3311
3312@misc{microsoft_nlp,
3313 note = {[Online; accessed 5-January-2021]},
3314 howpublished = {{Available: \url{https://blogs.microsoft.com/ai/from-conversation-to-code-microsoft-introduces-its-first-product-features-powered-by-gpt-3/}}},
3315 title = {{From conversation to code: Microsoft introduces its first product features powered by GPT-3}},
3316 key = {microsoft_nlp},
3317}
3318
3319@article{devlin2018bert,
3320 year = {2018},
3321 journal = {arXiv preprint arXiv:1810.04805},
3322 author = {Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
3323 title = {Bert: Pre-training of deep bidirectional transformers for language understanding},
3324}
3325
3326@inproceedings{mihalcea2006nlp,
3327 organization = {Springer},
3328 year = {2006},
3329 pages = {319--330},
3330 booktitle = {International Conference on intelligent text processing and computational linguistics},
3331 author = {Mihalcea, Rada and Liu, Hugo and Lieberman, Henry},
3332 title = {NLP (natural language processing) for NLP (natural language programming)},
3333}
3334
3335@article{austin2021program,
3336 year = {2021},
3337 journal = {arXiv preprint arXiv:2108.07732},
3338 author = {Austin, Jacob and Odena, Augustus and Nye, Maxwell and Bosma, Maarten and Michalewski, Henryk and Dohan, David and Jiang, Ellen and Cai, Carrie and Terry, Michael and Le, Quoc and others},
3339 title = {Program synthesis with large language models},
3340}
3341
3342@article{lieber2021jurassic,
3343 year = {2021},
3344 journal = {White Paper. AI21 Labs},
3345 author = {Lieber, Opher and Sharir, Or and Lenz, Barak and Shoham, Yoav},
3346 title = {Jurassic-1: Technical details and evaluation},
3347}
3348
3349@article{hammond2021empirical,
3350 year = {2021},
3351 journal = {arXiv preprint arXiv:2108.09293},
3352 author = {Hammond Pearce, Baleegh Ahmad and Tan, Benjamin and Dolan-Gavitt, Brendan and Karri, Ramesh},
3353 title = {An empirical cybersecurity evaluation of github copilot’s code contributions},
3354}
3355
3356@inproceedings{hartmann2010would,
3357 year = {2010},
3358 pages = {1019--1028},
3359 booktitle = {Proceedings of the SIGCHI Conference on Human Factors in Computing Systems},
3360 author = {Hartmann, Bj{\"o}rn and MacDougall, Daniel and Brandt, Joel and Klemmer, Scott R},
3361 title = {What would other programmers do: suggesting solutions to error messages},
3362}
3363
3364@article{brown2020language_GPT,
3365 year = {2020},
3366 pages = {1877--1901},
3367 volume = {33},
3368 journal = {Advances in neural information processing systems},
3369 author = {Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and others},
3370 title = {Language models are few-shot learners},
3371}
3372
3373@article{chen2021evaluating_codex,
3374 year = {2021},
3375 journal = {arXiv preprint arXiv:2107.03374},
3376 author = {Chen, Mark and Tworek, Jerry and Jun, Heewoo and Yuan, Qiming and Pinto, Henrique Ponde de Oliveira and Kaplan, Jared and Edwards, Harri and Burda, Yuri and Joseph, Nicholas and Brockman, Greg and others},
3377 title = {Evaluating large language models trained on code},
3378}
3379
3380@book{boshernitsan2004visual,
3381 publisher = {Citeseer},
3382 year = {2004},
3383 author = {Boshernitsan, Marat and Downes, Michael Sean},
3384 title = {Visual programming languages: A survey},
3385}
3386
3387@misc{rintagi,
3388 note = {[Online; accessed 5-January-2021]},
3389 howpublished = {{Available: \url{https://github.com/Rintagi/Low-Code-Development-Platform}}},
3390 title = {{Rintagi low-code platform}},
3391 key = {rintagi},
3392}
3393
3394@misc{joget,
3395 note = {[Online; accessed 5-January-2021]},
3396 howpublished = {{Available: \url{https://github.com/jogetworkflow/jw-community}}},
3397 title = {{joget low-code platform}},
3398 key = {joget},
3399}
3400
3401@misc{skyve,
3402 note = {[Online; accessed 5-January-2021]},
3403 howpublished = {{Available: \url{https://skyve.org/}}},
3404 title = {{Skyve low-code platform overview}},
3405 key = {skyve},
3406}
3407
3408@misc{gartner_intro,
3409 note = {[Online; accessed 5-November-2022]},
3410 howpublished = {{Available:
3411\url{https://www.gartner.com}}},
3412 title = {{Garner overview}},
3413 key = {gartner_intro},
3414}
3415
3416@misc{G2_intro,
3417 note = {[Online; accessed 5-November-2022]},
3418 howpublished = {{Available: \url{https://www.g2.com/}}},
3419 title = {{G2 overview}},
3420 key = {G2_intro},
3421}
3422
3423@misc{autovibrationML,
3424 note = {[Online; accessed 5-November-2022]},
3425 howpublished = {{Available: \url{https://github.com/al-alamin/XGeoML/tree/main/vibration_prediction}}},
3426 title = {{AutoVibrationML overview}},
3427 key = {autovibrationML},
3428}
3429
3430@misc{xojo,
3431 note = {[Online; accessed 5-November-2022]},
3432 howpublished = {{Available: \url{https://www.xojo.com/products/mobile.php}}},
3433 title = {{Xojo platform overview}},
3434 key = {xojo},
3435}
3436
3437@misc{mlbox,
3438 note = {[Online; accessed 5-November-2022]},
3439 howpublished = {{Available: \url{https://bigml.com/}}},
3440 title = {{MLBox platform overview}},
3441 key = {mlbox},
3442}
3443
3444@misc{lianja_app_builder,
3445 note = {[Online; accessed 5-November-2022]},
3446 howpublished = {{Available: \url{https://www.lianja.com/overview/lianja-app-builder}}},
3447 title = {{Lianja App Builder platform overview}},
3448 key = {lianja_app_builder},
3449}
3450
3451@misc{appery,
3452 note = {[Online; accessed 5-November-2022]},
3453 howpublished = {{Available: \url{https://appery.io/}}},
3454 title = {{Appery platform overview}},
3455 key = {appery},
3456}
3457
3458@misc{gamemaker,
3459 note = {[Online; accessed 5-November-2022]},
3460 howpublished = {{Available: \url{https://gamemaker.io/en/gamemaker}}},
3461 title = {{GameMaker platform overview}},
3462 key = {gamemaker},
3463}
3464
3465@misc{struct,
3466 note = {[Online; accessed 5-November-2022]},
3467 howpublished = {{Available: \url{https://structr.com/}}},
3468 title = {{Struct platform overview}},
3469 key = {struct},
3470}
3471
3472@misc{labor_shortage,
3473 note = {[Online; accessed 5-November-2022]},
3474 howpublished = {{Available: \url{https://www.revelo.com/blog/software-developer-shortage-us}}},
3475 title = {{Software Developers and Engineers Shortage in the US: The case for Global Talent}},
3476 key = {labor_shortage},
3477}
3478
3479@inproceedings{guan2021autogl,
3480 url = {https://openreview.net/forum?id=0yHwpLeInDn},
3481 year = {2021},
3482 booktitle = {ICLR 2021 Workshop on Geometrical and Topological Representation Learning},
3483 author = {Chaoyu Guan and Ziwei Zhang and Haoyang Li and Heng Chang and Zeyang Zhang and Yijian Qin and Jiyan Jiang and Xin Wang and Wenwu Zhu},
3484 title = {Auto{GL}: A Library for Automated Graph Learning},
3485}
3486
3487@article{agtabular,
3488 year = {2020},
3489 journal = {arXiv preprint arXiv:2003.06505},
3490 author = {Erickson, Nick and Mueller, Jonas and Shirkov, Alexander and Zhang, Hang and Larroy, Pedro and Li, Mu and Smola, Alexander},
3491 title = {AutoGluon-Tabular: Robust and Accurate AutoML for Structured Data},
3492}
3493
3494@misc{automl_forecast,
3495 note = {[Online; accessed 5-November-2022]},
3496 howpublished = {{Available: \url{https://www.researchandmarkets.com/reports/5010695/automated-machine-learning-market-research-report}}},
3497 title = {{Automated Machine Learning Market Research Report - Global Industry Analysis and Growth Forecast to 2030}},
3498 key = {automl_forecast},
3499}
3500
3501@inproceedings{shah2021towards,
3502 year = {2021},
3503 pages = {1584--1596},
3504 booktitle = {Proceedings of the 2021 International Conference on Management of Data},
3505 author = {Shah, Vraj and Lacanlale, Jonathan and Kumar, Premanand and Yang, Kevin and Kumar, Arun},
3506 title = {Towards benchmarking feature type inference for automl platforms},
3507}
3508
3509@incollection{bisong2019google,
3510 publisher = {Springer},
3511 year = {2019},
3512 pages = {581--598},
3513 booktitle = {Building Machine Learning and Deep Learning Models on Google Cloud Platform},
3514 author = {Bisong, Ekaba},
3515 title = {Google AutoML: cloud vision},
3516}
3517
3518@article{feurer-arxiv20a,
3519 year = {2020},
3520 booktitle = {arXiv:2007.04074 [cs.LG]},
3521 author = {Feurer, Matthias and Eggensperger, Katharina and Falkner, Stefan and Lindauer, Marius and Hutter, Frank},
3522 title = {Auto-Sklearn 2.0: Hands-free AutoML via Meta-Learning},
3523}
3524
3525@misc{bpmn_notation_example,
3526 note = {[Online; accessed 5-November-2022]},
3527 howpublished = {{Available: \url{https://www.appmixer.com/blog/workflow-automation-software-explained}}},
3528 title = {{Workflow Automation Software Explained, and How to Provide a Visual Integration Builder to Your Clients}},
3529 key = {bpmn_notation_example},
3530}
3531
3532@misc{WYSIWYG,
3533 note = {[Online; accessed 5-November-2022]},
3534 howpublished = {{Available: \url{https://docs.infinable.io/platform/infinable-quickstart/what-can-i-do-with-infinable}}},
3535 title = {{Infinable platform documentation}},
3536 key = {WYSIWYG},
3537}
3538
3539@misc{joget_IDE,
3540 note = {[Online; accessed 5-November-2022]},
3541 howpublished = {{Available: \url{https://www.joget.org/product/}}},
3542 title = {{What is Joget?}},
3543 key = {joget_IDE},
3544}
3545
3546@misc{sklearn,
3547 note = {[Online; accessed 5-November-2022]},
3548 howpublished = {{Available: \url{https://scikit-learn.org/stable/}}},
3549 title = {{SKLearn ML library.}},
3550 key = {sklearn},
3551}
3552
3553@incollection{cleophas2018bayesian,
3554 publisher = {Springer},
3555 year = {2018},
3556 pages = {111--118},
3557 booktitle = {Modern Bayesian Statistics in Clinical Research},
3558 author = {Cleophas, Ton J and Zwinderman, Aeilko H},
3559 title = {Bayesian Pearson correlation analysis},
3560}
3561
3562@article{bonett2000sample,
3563 publisher = {Springer},
3564 year = {2000},
3565 pages = {23--28},
3566 number = {1},
3567 volume = {65},
3568 journal = {Psychometrika},
3569 author = {Bonett, Douglas G and Wright, Thomas A},
3570 title = {Sample size requirements for estimating Pearson, Kendall and Spearman correlations},
3571}
3572
3573@book{oliphant2006guide,
3574 publisher = {Trelgol Publishing USA},
3575 year = {2006},
3576 volume = {1},
3577 author = {Oliphant, Travis E},
3578 title = {A guide to NumPy},
3579}
3580
3581@inproceedings{okoli2019estimating,
3582 organization = {OnePetro},
3583 year = {2019},
3584 booktitle = {SPE Western Regional Meeting},
3585 author = {Okoli, Prince and Cruz Vega, Juan and Shor, Roman},
3586 title = {Estimating Downhole Vibration via Machine Learning Techniques Using Only Surface Drilling Parameters},
3587}
3588
3589@incollection{zha2018monitoring,
3590 publisher = {Society of Exploration Geophysicists},
3591 year = {2018},
3592 pages = {2101--2105},
3593 booktitle = {SEG Technical Program Expanded Abstracts 2018},
3594 author = {Zha, Yang and Pham, Son},
3595 title = {Monitoring downhole drilling vibrations using surface data through deep learning},
3596}
3597
3598@inproceedings{xin2021whither,
3599 year = {2021},
3600 pages = {1--16},
3601 booktitle = {Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems},
3602 author = {Xin, Doris and Wu, Eva Yiwei and Lee, Doris Jung-Lin and Salehi, Niloufar and Parameswaran, Aditya},
3603 title = {Whither automl? understanding the role of automation in machine learning workflows},
3604}
3605
3606@article{dudley2018review,
3607 publisher = {ACM New York, NY, USA},
3608 year = {2018},
3609 pages = {1--37},
3610 number = {2},
3611 volume = {8},
3612 journal = {ACM Transactions on Interactive Intelligent Systems (TiiS)},
3613 author = {Dudley, John J and Kristensson, Per Ola},
3614 title = {A review of user interface design for interactive machine learning},
3615}
3616
3617@article{amershi2014power,
3618 year = {2014},
3619 pages = {105--120},
3620 number = {4},
3621 volume = {35},
3622 journal = {Ai Magazine},
3623 author = {Amershi, Saleema and Cakmak, Maya and Knox, William Bradley and Kulesza, Todd},
3624 title = {Power to the people: The role of humans in interactive machine learning},
3625}
3626
3627@inproceedings{fiebrink2011human,
3628 year = {2011},
3629 pages = {147--156},
3630 booktitle = {Proceedings of the SIGCHI conference on human factors in computing systems},
3631 author = {Fiebrink, Rebecca and Cook, Perry R and Trueman, Dan},
3632 title = {Human model evaluation in interactive supervised learning},
3633}
3634
3635@inproceedings{fails2003interactive,
3636 year = {2003},
3637 pages = {39--45},
3638 booktitle = {Proceedings of the 8th international conference on Intelligent user interfaces},
3639 author = {Fails, Jerry Alan and Olsen Jr, Dan R},
3640 title = {Interactive machine learning},
3641}
3642
3643@article{wexler2017facets,
3644 year = {2017},
3645 journal = {Google Open Source Blog},
3646 author = {Wexler, James},
3647 title = {Facets: An open source visualization tool for machine learning training data},
3648}
3649
3650@article{wongsuphasawat2017visualizing,
3651 publisher = {IEEE},
3652 year = {2017},
3653 pages = {1--12},
3654 number = {1},
3655 volume = {24},
3656 journal = {IEEE transactions on visualization and computer graphics},
3657 author = {Wongsuphasawat, Kanit and Smilkov, Daniel and Wexler, James and Wilson, Jimbo and Mane, Dandelion and Fritz, Doug and Krishnan, Dilip and Vi{\'e}gas, Fernanda B and Wattenberg, Martin},
3658 title = {Visualizing dataflow graphs of deep learning models in tensorflow},
3659}
3660
3661@article{ono2020pipelineprofiler,
3662 publisher = {IEEE},
3663 year = {2020},
3664 pages = {390--400},
3665 number = {2},
3666 volume = {27},
3667 journal = {IEEE Transactions on Visualization and Computer Graphics},
3668 author = {Ono, Jorge Piazentin and Castelo, Sonia and Lopez, Roque and Bertini, Enrico and Freire, Juliana and Silva, Claudio},
3669 title = {PipelineProfiler: A visual analytics tool for the exploration of AutoML pipelines},
3670}
3671
3672@inproceedings{yang2018grounding,
3673 year = {2018},
3674 pages = {573--584},
3675 booktitle = {Proceedings of the 2018 designing interactive systems conference},
3676 author = {Yang, Qian and Suh, Jina and Chen, Nan-Chen and Ramos, Gonzalo},
3677 title = {Grounding interactive machine learning tool design in how non-experts actually build models},
3678}
3679
3680@article{wu2022survey,
3681 publisher = {Elsevier},
3682 year = {2022},
3683 journal = {Future Generation Computer Systems},
3684 author = {Wu, Xingjiao and Xiao, Luwei and Sun, Yixuan and Zhang, Junhang and Ma, Tianlong and He, Liang},
3685 title = {A survey of human-in-the-loop for machine learning},
3686}
3687
3688@article{dieber2020model,
3689 year = {2020},
3690 journal = {arXiv preprint arXiv:2012.00093},
3691 author = {Dieber, J{\"u}rgen and Kirrane, Sabrina},
3692 title = {Why model why? Assessing the strengths and limitations of LIME},
3693}
3694
3695@article{alamin_LCSD_EMSE,
3696 doi = {10.1007/s10664-022-10244-0},
3697 journal = {Empirical Software Engineering},
3698 volume = {},
3699 title = {Developer discussion topics on the adoption and barriers of low code software development platforms},
3700 pages = {},
3701 year = {2022},
3702 author = {Alamin, Md Abdullah Al and Uddin, Gias and Malakar, Sanjay and
3703and Afroz, Sadia and Haider, Tameem Bin and Iqbal, Anindya},
3704}Attribution
arXiv:2211.04661v1
[cs.SE]
License: cc-by-4.0


