
- Papers
Papers is Alpha. This content is part of an effort to make research more accessible, and (most likely) has lost some details from the original. You can find the original paper here.
Introduction
An emerging set of guidelines originating in both the publicand private sectorshas advanced varying perspectives on what constitutes responsible artificial intelligence (AI). These guidelines typically focus on qualitative properties of the AI system and their assurance through human application of processes, such as stakeholder consultations, that shape the requirements of the AI system and evaluate its compliance with these requirements. Following these human processes, AI systems are deployed to the real world where they operate at large scale and high speed. Human staff must then play catch-up to AI systems whose operating environment and consequent behavior are constantly changing. The result is an increasing number of AI incidentswhere people are unfairly impacted or even killed by AI systems that fail to conform to their nominal governance requirements when deployed. These incidents principally occur due to a gap between identifying the governance requirements of a system and applying them in the development and deployment of AI systems. In short, AI governance unmoored from the engineering practice of AI inevitably leads to unexpected, damaging, or dangerous outcomes.
Modern AI systems are inherently data-centric – they are produced from data then deployed to the real world to make decisions on input data. Given the centrality of data to AI systems, governance requirements are most comprehensively assured when they are defined and evaluated with data. Through appropriate preparation of governance datasets, it becomes possible to produce systems of “continuous assurance.” In analogy to continuous integration and deployment in software engineering, continuous assurance integrates evaluation of governance requirements at every stage of the product lifecycle by formulating requirements verification as a low-friction, repeatable algorithmic process.
Continuous verification and validation of system governance requirements.
Continuous assurance places AI systems into an operating scope coinciding with governance requirements. In the absence of data defining a system of continuous assurance, intelligent systems continue operating even when they begin violating governance requirements. An intelligent system that is not governed with data, is one that is not governed.
Formulating governance requirements in terms of data implies operational changes over the whole life cycle of a system. When governance is left to a final gate at delivery time, any violation of governance requirements presents a choice of either waiting months for an updated system or deploying the solution in an absence of a fix. Through the adoption of governance requirements as solution requirements during engineering, it becomes possible to realize the benefits of good governance (i.e., a better product) while greatly reducing the downstream compliance risk. Consequently, while we are presenting an approach to satisfying emerging governance requirements of AI systems, we are primarily concerned with how product teams can best move governance from a deployment barrier to a core system specification enabling better solutions.
In this work we begin by detailing the elements of data-centric governance before introducing the teams and data involved in its application, then we step through a series of technical problems and incidents (i.e., harm events) that are identified via the team structure and data. We close the paper with details on the computer systems involved in its application.
What is the one insight everyone should take away from this paper?
Shipping better products, faster, and with fewer risks requires embedding governance requirements throughout the product life cycle
Data-Centric Governance
Data-centric governance means operationalizing performance requirements for AI systems in the form of datasets and algorithmic evaluations to be run against them. It turns abstract requirements like “fairness” into objectively measurable phenomena. It recognizes the central role of data in AI system evaluation and the need for good data stewardship and rigorous evaluation protocols to preserve the statistical validity of evaluations against that data.
By one estimate, as many as 85 percent of AI projects fail to deliver or fall short. In our experiences in research and industry, the most common failure point has been failure to appropriately capture the full complexity of the solution’s deployment environment and engineer a solution accordingly. As governance processes are often aimed at surfacing potential deployment harms, their systematization earlier in the product lifecycle is likely to substantially reduce the failed delivery rate.
In this section, we lay out the key tasks involved in implementing data-centric governance in practice. Accomplishing these tasks requires a concerted effort from the people involved in all stages of the product lifecycle. We will have more to say about the impact of organizational structure on governance in Section sec-teams. For now, we identify four major areas of responsibility:
The people responsible for defining the system’s goals and requirements.
The people responsible for collecting and preparing the data necessary for system engineering and evaluation.
The people responsible for engineering the product.
The people responsible for ensuring that the solution is consistent with organizational, regulatory, and ethical requirements prior to and following deployment.
These teams can be staffed by people from a single organization producing a system, or their functions can be represented by external organizations (e.g., auditors can serve as a verification team).
Throughout this section, we will highlight the benefits of effective data-centric governance by contrasting the experiences of these development teams at two fictitious organizations: Governed Corporation (G-Corp), which follows data-centric governance best practices, and Naïve Corporation (N-Corp), which does not.
Operationalize system requirements
Data-centric governance is about turning abstract governance requirements into objectively and algorithmically measurable phenomena. Machine learning practitioners are already familiar with this idea. Test set error, for example, is commonly taken to be the operational definition of task success. But there are many other relevant dimensions of performance. Data-centric governance envisions that measuring the full breadth of relevant performance criteria should be as routine as measuring test set accuracy.
To make this possible, one must specify how to measure performance algorithmically, which for an AI system includes provisioning the evaluation datasets. This creates an objective, repeatable measurement process.Although emerging requirements at deployment time can necessitate collecting additional evaluation data, performance requirements, like all product requirements, should be defined as early in the development process as possible. Ill-defined requirements are a major cause of project failures in all engineering disciplines, and AI is no exception. Nevertheless, it is common for product requirements to be expressed only qualitatively in the design phase, with quantitative measures coming later after significant engineering has already been done. This is a harmful practice, as it tends to anchor quantitative requirements to what is measurable with the available data and to the numbers that the chosen engineering approach can achieve. It is difficult to be objective about what would constitute acceptable performance once expectations are anchored in this way.
Codifying governance requirements with data also enables practitioners to learn from past mistakes. Every AI system incident is an opportunity to identify and formalize a new relevant dimension of performance. Once formalized, it is possible to evaluate future systems for their susceptibility to similar incidents. An AI system’s scores on different batteries of data-driven evaluations rigorously characterize the boundaries of its competencies and allow teams to make informed decisions about whether to deploy the system.
Contrasting Outcomes
G-Corp. The Product Team identifies that the AI system poses a risk of disparate impacts and adds “fairness across demographic groups” as a product requirement. They define “fairness” as having statistically-equivalent error rates across relevant demographic groups. The Data Team creates engineering and evaluation datasets stratified by demographic groups. The Solution Team optimizes the system to achieve all performance goals on the engineering data. The Verification Team verifies compliance with fairness requirements using the evaluation data and confirms that the system does not produce disparate impacts – the system is safely deployed.
N-Corp. The Product Team identifies that the AI system poses a risk of disparate impacts and adds “fairness across demographic groups” as a product requirement. The Data Team focuses on engineering and evaluation data for the primary task, and the Solution Team focuses on optimizing for the primary task. The Verification Team checks that the AI system does not use sensitive features as inputs, but has no means of detecting that the model produces disparate impacts because a feature for user location, which was not considered sensitive, is correlated with sensitive attributes. The system is deployed and results in disparate impacts to real-world users.
Solve the data paradox
Data-centric governance faces a bootstrapping problem in acquiring the necessary datasets. The reliability of the system cannot be assessed without data that is representative of the actual deployment environment. The obvious way to obtain this data is to collect it from a deployed system. But, without the data, it is impossible to engineer a deployable system or to verify that a release candidate meets its minimum deployment requirements. This is the data paradox of data-driven AI systems. The path forward consists of two parts: acquiring realistic proxy data, and expanding the scope of the system iteratively with real deployment data from previous system releases.
Acquire realistic proxy data. Where real-world data is not available, suitably realistic proxy data must be acquired. There are many ways to approach this. For some applications, it may be possible to mine publicly available data collected for other purposes. For example, data for image classification is often sourced from websites like Flickr by searching for relevant keywords. Data that requires more human expertise to generate or label is often obtained from crowdsourcing services like Amazon Mechanical Turk.
Data collection strategies can be quite elaborate. For example, Google ran a telephone answering service from 2007 to 2010 primarily for the purpose of collecting data for speech-to-text transcription. The sheer amount of effort expended to collect this data should reinforce the value of large, realistic datasets for product creation. Organizations should consider carefully the scale of data required for creating the initial version of the product and the level of realism required, and should budget appropriately for the complexity of acquiring this data.
Expand scope iteratively. Once version 1.0 of a system is created and deployed, it begins to see real-world data from its actual deployment environment. This data should be collected and used to expand the datasets that will be used for creating the next version of the system. Through this bootstrapping process, the solution will gradually improve as larger amounts of real deployment data become available.
The scope of the AI system must be tightly restricted during the initial phases of this bootstrapping process. With limited deployment data available, the scope within which the system’s competencies can be verified through evaluation data is also limited, and therefore it must be prevented from operating in circumstances where the risk of harm cannot be measured. The scope of the system should begin small and expand gradually, informed by continuing evaluations of performance in the real deployment environment.
Contrasting Outcomes
G-Corp. The Product Team produces a grand vision for a device that will change the world and plans shipments to 30 countries. The Data Team finds appropriate data sourced from a single country and the Solution Team begins engineering. Knowing the data will not support shipments to 30 countries, the Go2Market strategy shifts to running pilot programs with the production device in 29 of the 30 markets. The Verification Team signs off on shipping to 1 country and the product is a huge hit – driving enrollment in the pilot program in the remaining 29 countries.
N-Corp. The Product Team produces a grand vision for a product that will change the world and justifies its multi-million dollar development budget on shipments to 30 countries. The Data Team finds appropriate data sourced from a single country and the Solution Team begins engineering. The Verification Team then is overruled when attempting to block shipments to all but the represented country. N-Corp is worried G-Corp will be first-to-market. After poor performance in 29 of the 30 markets (including several newsworthy incidents), the product is recalled globally – including in the one strong-performing market.
Steward the data
Implementing data-centric governance requires that some entity take responsibility for data stewardship. This includes collecting and storing the data, making it available for evaluations while guarding it against misuse, and performing data maintenance activities to ensure the continued construct validity of data-centric measures as the application domain changes. Data stewardship is a shared responsibility of the Data Team and the Verification Team. The Data Team decides what data is needed to measure a given construct and how to obtain it, and the Verification Team ensures that evaluations against the data are conducted properly.
Preserve diagnostic power. Exposing evaluation data to Solution Teams compromises the validity of evaluations based on that data. Even if Solution Teams exercise proper discipline in not training on the test data, something as innocent as comparing evaluation scores of multiple models can be a step down the road to overfitting. Practitioners may not be aware of all of the subtleties of statistically rigorous evaluation, and even when they are, some of the more “pedantic” requirements may be seen as unnecessary impediments to speedy delivery of a solution.
There is also the practical problem that without data access controls, it is not possible to verify that the evaluation data has not been misused. This is especially important when the evaluation is an “industry standard” benchmark, where showing state-of-the-art performance may bring prestige or financial benefits. The Verification Team is responsible for facilitating data-driven evaluations in a way that preserves the validity of the evaluation data as a diagnostic tool. The evaluation data must be kept private and the release of evaluation scores must be controlled so as not to reveal information about the data.
Contrasting Outcomes
G-Corp. The Data Team creates evaluation datasets that are collected independently of all engineering datasets. The Data Team delivers the evaluation data to the Verification Team and does not disclose the data or the method of collection to the Solution Team. The Solution Team passes their trained models off to the Verification Team, which evaluates the systems and reports the results in a way that avoids disclosing information about the evaluation data. The organization can be confident that the solution has not overfit the evaluation data, and thus that the evaluation results are reliable.
N-Corp. The Data Team delivers both the engineering data and the evaluation data to the Solution Team. The Solution Team knows the risks of overfitting the evaluation data, but under pressure to improve performance, they make changes to improve the model guided by its scores on the evaluation data. The Verification Team verifies that the system meets performance requirements and approves it for deployment. The system under-performs after deployment because architecture changes driven by repeated evaluations resulted in overfitting the evaluation data.
Maintain the data. The world changes over time, and with it changes the distribution of inputs that a deployed AI system will be asked to process. A computer vision system that tracks vehicles on the road, for example, will see new vehicle models introduced throughout its lifetime. Evaluation data must be maintained to ensure that it continues to be a valid operational measure of the associated performance requirement. This will usually require, at least, periodically collecting additional data, and possibly also pruning obsolete data or designing new data augmentations.
Data maintenance is a joint activity of the Data Team and the Verification Team. The Verification Team should conduct ongoing evaluations to look for signs of domain shift and alert the Data Team when additional evaluation data is needed. This likely requires collaboration with the Solution Team to ensure that the system emits the necessary diagnostic information after deployment. Once alerted, the Data Team should create new or modified datasets and pass them back to the Verification Team for integration into the evaluation process.
Contrasting Outcomes
G-Corp. A development team is creating an image classification app meant to run on smartphones. Whenever a new model of smartphone is released by a major manufacturer, the Data Team collects engineering and evaluation datasets comprised of images of a standard set of subjects captured with the new model of phone. Periodic system revisions include data from new phone models in their engineering and evaluation data. The app maintains high performance over time.
N-Corp. After deployment of the first version of the app, the Data Team considers their work complete and moves on to other projects. The app begins to perform poorly with the latest models of the phone. The Solution Team attempts to improve the model, but improving performance on the existing data seems to make performance with the new phones even worse. Users of newer phone models stop using the app because of its poor performance.
Evaluation Authorities. In many instances data stewardship is best performed by evaluation authorities tasked with assessing system impact requirements. Evaluation authorities standardize entire product categories with independent measurements. For example, stamped on the bottom of most AC adapters are the letters “UL Listed,” which stands for Underwriters Laboratories – an organization that has worked to test and standardize electrical safety since 1894. Without organizations like UL, electricity would be far too dangerous to embed in the walls of all our homes and businesses. People will not buy electrical systems in the absence of electrical standards. Similarly, intelligent systems are often not purchased because the purchaser has no way of efficiently and reliably determining the capacities of the system.
Contrasting Outcomes
After producing Résumé screening apps that are measurably far fairer than any human screener, G-Corp and N-Corp find they cannot sell their products to anyone because nobody trusts the performance numbers. Both firms engage third party auditors to evaluate the technology.
G-Corp. G-Corp pays the auditor a nominal premium on their normal audit price to subsequently serve as an “evaluation authority” for the market segment. As the first public standard of its kind, the entire human resources industry soon standardizes around it and G-Corp develops a performance lead from having been there first.
N-Corp. N-Corp’s solution performs just as well as G-Corp’s, but their measures are soon rendered irrelevant after other competitors standardize to the G-Corp audit. Since competitors cannot compare against N-Corp’s numbers, G-Corp wins the market.
Adopt continuous assurance
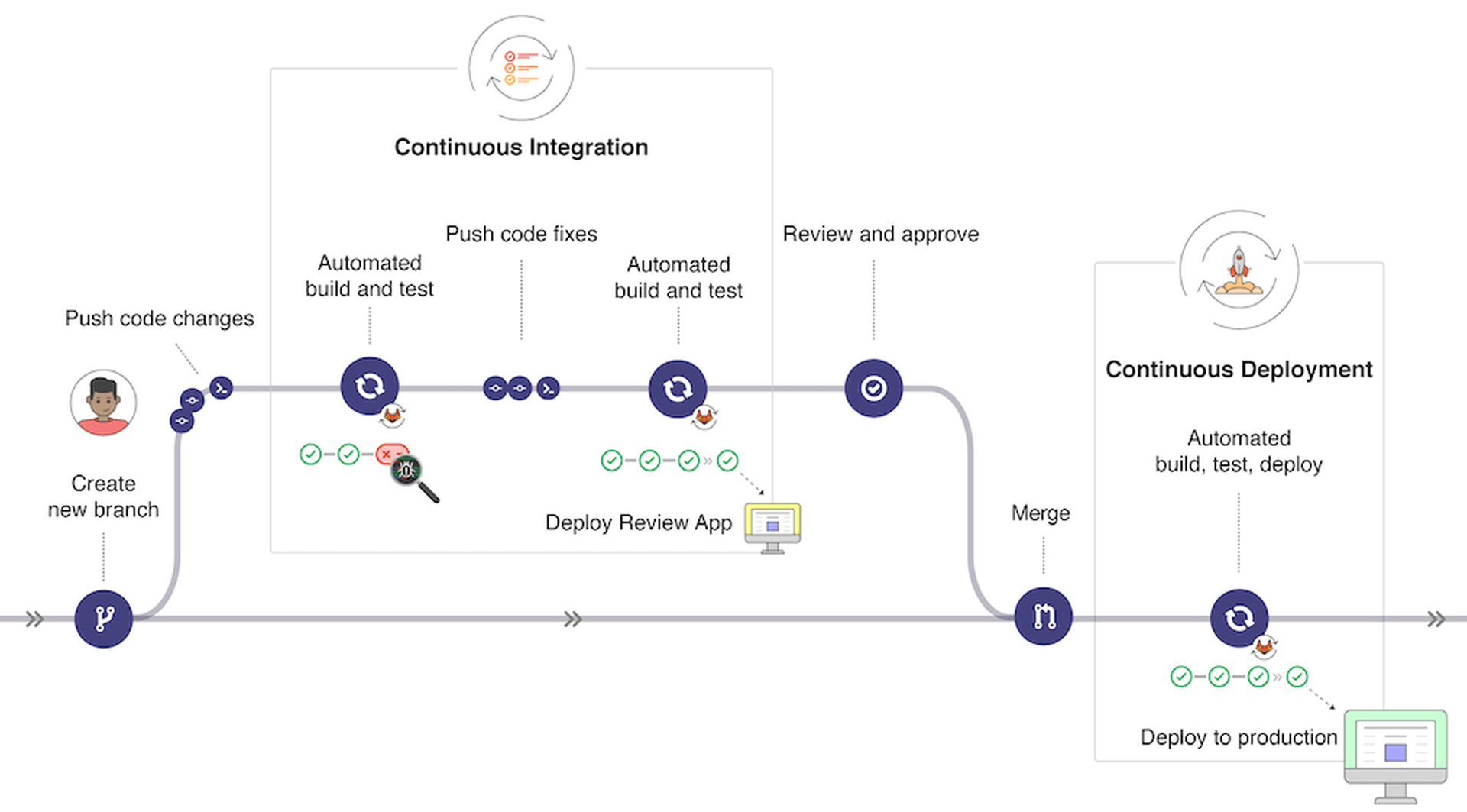
As software engineering practice has shown, the best way to ensure that requirements are met is to verify them automatically as a matter of course after every system modification and throughout the lifecycle of the system. In analogy to the continuous integration and continuous deployment (CI/CD) paradigm that has transformed the practice of software engineering, we need continuous assurance practices for AI system engineering. This section lays out the core components of continuous assurance; we discuss tooling for continuous assurance in Section sec-outline-systems.
Extend CI/CD to AI systems. The components of continuous assurance for AI systems mirror the components of CI/CD in many respects. Both CI and CD gate development and release via test suites analogous to evaluation data. To utilize the test suite, the system must be designed for testability. For an AI system, this means that the system in its deployable form must expose a generic interface enabling it to consume data from arbitrary sources and produce results. The system should also be modular with loose coupling among components so that components can be tested separately. Unfortunately, modern machine learning techniques have trended toward “end-to-end” monolithic models that are difficult to separate into components. The reason for this trend is that such models often perform somewhat better than modular architectures, but solution engineers must be aware that this performance comes at the price of testability. Recent interest in “explainable AI” is in part a reaction to this trend, acknowledging the need to understand the intermediate computational steps implicit in the model.
In addition to testable models, we need the computational infrastructure to run the tests at scale. This is already a well-known pain point in CI/CD, and there are many companies offering solutions like cloud-based distributed build and test systems. The problem may be even more acute for AI systems due to the computational expense of running large evaluation datasets. Such problems can be overcome, but organizations developing AI systems must understand the problems and plan and budget accordingly.
Finally, just like CI/CD, continuous assurance requires an associated versioning system for AI models. Because AI models are products of training on data, the versioning system must also track versions of the training data and other parameters of the training pipeline, and record which version of the training inputs produced which version of the model.
Contrasting Outcomes
G-Corp. The development teams implement a continuous assurance process in which deployment candidate models are checked in after training and run against the evaluation suite automatically. This allows them to notice that the new version of the model, which has more parameters, has better task performance but is less robust to noise. The Solution Team improves the model by adding regularization, and the improved model passes all evaluations.
N-Corp. The Verification Team conducts performance evaluations in the traditional way, by receiving the model from the Solution Team and manually performing ad hoc evaluations. They note its improved performance on the primary task evaluation data, but they do not run the noise robustness tests because these take extra effort and they were run for the previous model version. The model is deployed, where it performs poorly in noisy environments.
Monitor deployed systems and report incidents. While the data-centric governance practices we have discussed so far offer teams the best chance of deploying reliable, trustworthy systems, training and verification data will always be incomplete, and the world will always continue to change after the AI system is deployed. AI systems therefore require ongoing monitoring after deployment.
One objective of ongoing monitoring is to detect and report excursions from the AI system’s proper operating scope as they happen. Techniques like out-of-distribution detection should be applied to compare real-world inputs and outputs to those in the engineering and evaluation datasets. Departures from the expected distributions of data could mean that the system is operating in novel regimes where it may not be reliable. Timely detection of these departures can allow human decision-makers to place limits on the system or withdraw it from operation if its reliability cannot be guaranteed.
A second objective is to collect real-world inputs and outputs so that they can be used to augment and improve engineering and evaluation datasets. Real-world edge cases and incidents should be tracked to build edge case and incident datasets so that the system can be improved to handle these cases. Continuous assurance processes should incorporate acquired real-world data to ensure that revisions of the AI system handle new edge cases and incidents and do not regress in their handling of known cases. Accumulating real-world data also guards against domain shift by ensuring that engineering and evaluation datasets are up-to-date with the changing world.
Contrasting Outcomes
G-Corp. The Solution Team developing a wake word detection system includes an out-of-distribution (OOD) detection component in the system. During deployment, the OOD detector sends an email alert to the Verification Team indicating that the input data distribution is substantially different from the evaluation data distribution. By analyzing the real-world data collected by the system, the Verification Team determines that the engineering and evaluation datasets do not contain enough variation in speaker accents. They report this to the Data Team, who use the collected data to build more-diverse datasets, improving performance of the next system revision.
N-Corp. Without any monitoring components in place, the developer teams are unaware that the deployed system is operating with a different input distribution than the ones used for engineering and evaluation. Their first indication is when customers with certain accents begin reporting poor performance to customer service. The developers eventually realize the problem, but because data from the deployed system was not collected, the Data Team must collect more-diverse data in a lab setting, at considerable expense. Some customers who were frustrated by poor performance switch to a competitor’s product.
Organizational Factors in Data-centric Governance
While we have defined data-centric governance in terms of data and algorithms, governance processes ultimately are implemented by humans. Effective governance requires a proper separation of concerns among development teams and proper alignment of their incentives to the goals of governance. Misconfiguring these teams introduces perverse incentives into the governance of the system and renders governance efforts ineffective. In this section, we advocate for a governance structure consisting of four teams with distinct goals and areas of responsibility – the Product Team, the Data Team, the Solution Team, and the Verification Team.
The Product Team
The product team is the first team involved in producing an AI solution. Their objective is to direct the purchase or production of a system solving a specific problem by clearly defining the system’s goals and requirements. Product teams often serve as advocates for the customer’s interests when discussing requirements within an organization, which can introduce tensions between teams.
The phrase “goals and requirements” has special meaning in the AI community. Most AI systems are produced by an optimization process that repeatedly updates system configurations to better satisfy a particular performance measure. So, while product team activities determine what gets built, their decisions are also integral to how the solution will be built through optimization, since they effectively design the target metric to be optimized. Thus, when governance requirements are added after the product definition, it reopens the entire solution engineering process.
Can you figure out the system requirements during solution engineering? In contrast to typical software development processes that increasingly plan through iteration, product definition for AI systems is intricately linked with the possibilities afforded by data that are time consuming and expensive to collect. A failure to rigorously define the system profoundly impacts system capabilities and appropriate operating circumstances. Ideally projects will be perfectly scoped to the “must-have” requirements, otherwise when mis-scoped the system will:
- Over-scope. Underperform on core tasks and data/compute requirements increase
- Under-scope. Perform poorly on unstated requirements
Tightly defining system requirements greatly reduces program risks.
The boundaries of possibility for AI systems are currently determined more by the availability of data for the task than by the capacities of current AI techniques. Thus the product team must work closely with the data team.
The Data Team
The data team is responsible for collecting and preparing the data necessary for system engineering and evaluation. Data teams are populated with subject matter experts (SMEs) and data engineers. For instance, when producing a system that identifies cancers in medical images, the SMEs are responsible for applying their expert judgment to generate metadata (e.g., drawing an outline around a cancer in an image and labeling it “carcinoma”). Data engineers build the user interfaces for the SMEs to manage metadata on the underlying data (e.g., display radiographs with labels) and maintain the library of data for use by the solution and verification teams described below.
As the datasets required for producing a solution expand, the size of the data team must also increase, often to the point where they outnumber all the other teams. Anecdotally, the most common failure point we observe in companies staffing AI engineering efforts is to place solution engineers on a problem without budgeting or staffing dataset preparation. The circumstance is then analogous to hiring a delivery driver without providing them with a vehicle: their only option is to walk the distance.
When applying data-centric governance, the data team operates in a service capacity for the product, verification, and solution teams to produce several interrelated data products. We will introduce these data products after introducing the solution and verification teams.
The Solution Team
The solution team is responsible for engineering the product. They often receive most of the public recognition when a machine learning research program makes a breakthrough, but research programs rarely produce product deployments outside of research contexts. After establishing what is possible via research, solution teams turn to making a system that can perform its task comprehensively according to the requirements adopted by the product team. Often this involves expanding the dataset requirements to cover the entirety of the system input space. Working with the “edge cases” provided by the data team occupies the vast majority of deployment solution engineering. Until edge cases are handled appropriately, it is the prerogative of the verification team to block solution deployment.
What if the solution is not known? Projects with significant uncertainties are research projects. Training requirements, edge cases, achievable performance, and operating conditions are often unknowable prior to research prototyping. Successful completion of a proof-of-concept is thus a prerequisite to formalizing governance requirements. Research reduces uncertainties allowing subsequent engineering and governance processes to be applied. We recommend contacting an institutional review board (IRB) for research program governance requirements.
Separate research programs from producing shipped intelligent systems.
The Verification Team
The verification team is responsible for ensuring that the solution is consistent with organizational, regulatory, and ethical requirements prior to and following deployment. This definition combines the remit of several teams operating in industry, including those responsible for quality assurance, test, verification, validation, compliance, and risk. As intelligent systems are increasingly subject to regulatory requirements, the Chief Compliance Officer or General Counsel office is often brought in to run compliance processes. However, as traditionally instituted, these offices are not capable of implementing a governance program without the assistance of an engineering department or outside consultants. Alternatively, firms are constituting special-purpose teams tasked with various aspects of AI assurance, such as Google’s team assessing compliance with the corporate AI principles. Such teams require cross functional connections to be successful.
For the purpose of this position paper, we will assume the verification team either has people in-house or consults with people that know the risks of a product, including how to assess the likelihood a system will produce harms at initial deployment time and as the system and world continue to develop. From the perspective of the verification team, well-executed data-centric governance makes the final authorization to deploy an intelligent system perfunctory since all the governance processes will have been carried out prior to final verification.
What happens if you combine teams? The interests of one team will come to dominate the interests of the other team in the combination.
- Product + Verification: The verification team is responsible for telling the product team when a solution can ship. Product teams typically want fewer limitations and are closer to revenue sources so they tend to dominate in commercial organizations.
- Product + Data: Similarly, when product responsibilities are embedded within the data team, the data team will tend to prioritize the product team’s interests, which typically means more focus on data for the solution team and less for the verification team.
- Product + Solution: The product team wants the best, highest performing solution possible while the solution team wants to meet requirements as quickly as possible. If the product team dominates, then the requirements of the system may be unreasonably high – which can result in missed deadlines, extreme data requirements, and more. Should the solution team come to dominate, then the product definition will tend to be scoped around what is more immediately achievable – a form of “bikeshedding”.
- Data + Verification: The resources of the data team are not infinite. If the data and verification teams are combined, then the verification team will receive rich and comprehensive measures for the system while the solution team will not receive attention for improving those measures. By separating the data team from both the verification and solution team, it is possible to seek a balance.
- Data + Solution: Data used for requirements verification must not be disclosed to the solution team. When data and solution teams combine, it is difficult to know whether the integrity of the withheld datasets has been violated. High performance may be entirely illusory. More details on this problem are presented later in the paper.
- Solution + Verification: The verification team determines when the solution team has met its requirements. If these teams are combined, there is a tendency to change requirements to match what the system is capable of.
Separate the four teams and ensure they are evaluated according to their disparate purposes.
Evaluation Authorities
All the technologies for data-centric governance exist and are aligned to simultaneously make better products with more socially beneficial outcomes. What is missing at present is the organizational capacity to build and maintain the tests and requirements. While this can and should be done within the same organizations that are creating the products, there is a real concern that organizations seeking to rapidly deploy products to capture markets will exert pressure on evaluation teams to certify those products prematurely.
While such potential conflicts of interest exist in many fields, they are especially acute in data-driven AI because publicly releasing the data needed to evaluate the system destroys the data’s validity as an evaluation tool. Unlike, for example, automobile crash testing, where it would be very difficult to “cheat” a properly constructed test, in AI it is often trivial to achieve high performance on any given evaluation simply by training on the test data.
These considerations prompt us to advocate for the establishment of evaluation authorities – independent entities that perform data-driven evaluations as a service and who accept responsibility for proper stewardship of the evaluation data. Such independent evaluation benefits both product developers and consumers. Product developers are protected from self-delusion due to biases in their internal evaluations, ultimately leading to better products, and they are perhaps also protected from legal liability as the evaluation authority’s stamp of approval can provide evidence of due diligence in evaluating their products. Consumers benefit from objective standards by which they can compare products, analogous to crash safety ratings for automobiles or energy efficiency ratings for appliances.
In fact, a forerunner of the evaluation authorities and processes we envision already exists, under the umbrella of “machine learning (ML) competitions.”
What is an ML Competition?
Machine learning is large field of research and engineering where many organizations routinely run billions of experiments. Consequently, the field is in statistical crises. With every experiment comes some probability that a high performing model got lucky instead of smart. Bringing order to the epistemological chaos is the machine learning competition, which sets competitors out to maximize some measure on private data not provided to the competing teams.
The most famous ML competition was ImageNetfor which academics were asked to produce a computer system capable of labeling image contents. In 2012 an entry into the multi-year competition vastly outperformed other entrants and produced a sea change in machine learning research. Figure fig-imagenet depicts the rapid advancements on the ImageNet task.

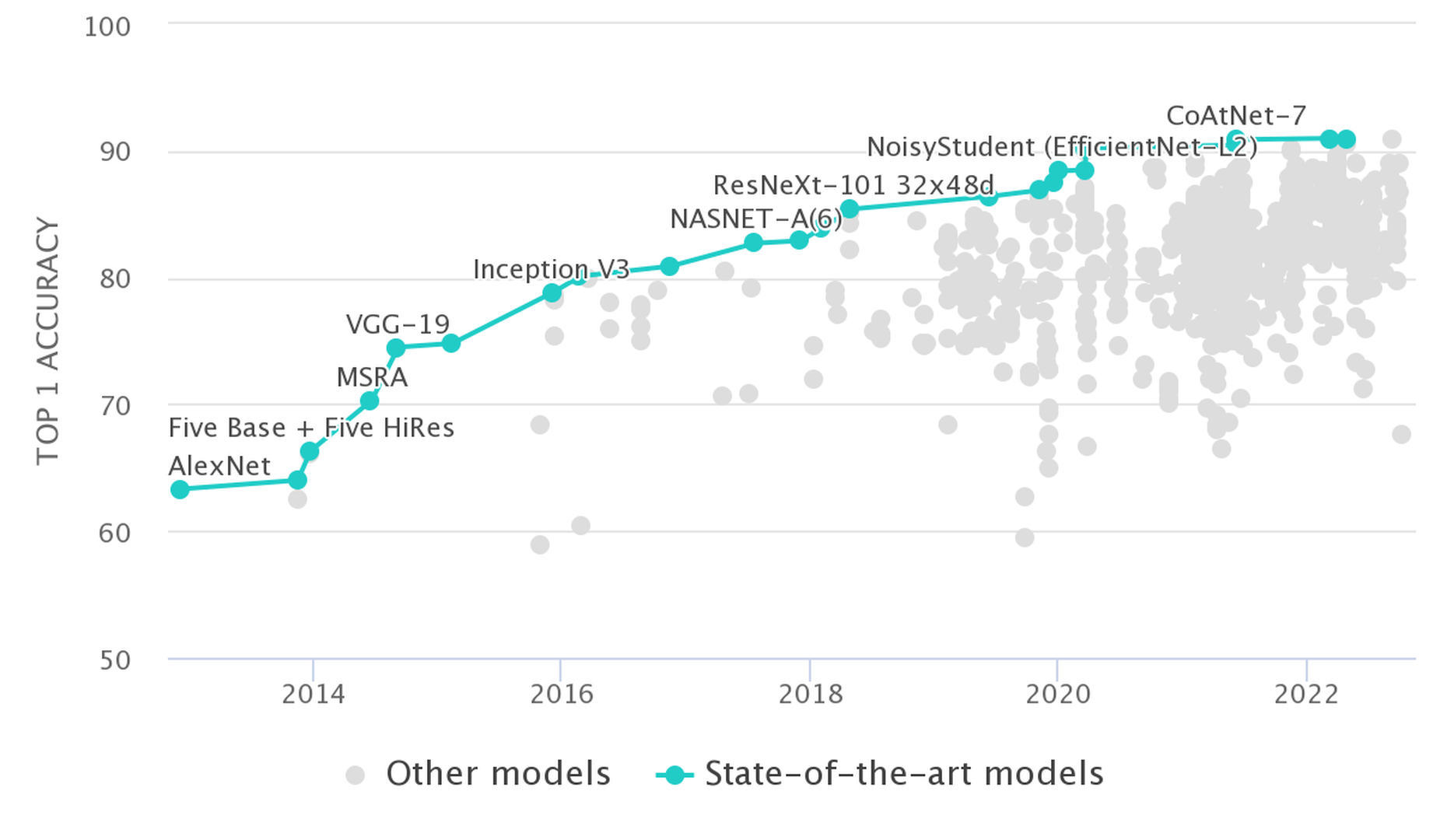
By 2015, the prestige afforded to those besting the previous ImageNet leaders led a team of researchers to cheat on the competition. The research team queried the private test set across multiple sham accounts to tune their model to the private test set. As a result, the performance estimates of the competition became invalid for the model and the researchers were banned from the competition.
What can evaluation authorities tell us about system performance? Launched by Facebook in 2019, the Deepfake Detection Challengelooked to provide Facebook with tools that could detect computer-modified videos. While competitors made strong progress on the dataset Facebook filmed then modified in-house, the teams were ranked for a $1,000,000 prize purse based on data from the platform’s real users. Even though the user test data was not produced to circumvent detection, the degradation in performance between the Facebook-produced data and the Facebook user data as shown by Table tab-challengedata is considerable. In effect, the competitors had produced models mostly capable of detecting when a face had been swapped, and not many other computer manipulations. Subsequent analysis also revealed the models regularly false activate for people with skin diseases, such as vitiligo.
Evaluation authorities have the ability to detect when systems are not robust
Two competitor results from the Facebook Deepfake Detection Challenge. All models degraded significantly from their test set performance on Facebook generated data to test set data defined on user generated data.
Table Label: tab-challengedata
Download PDF to view tableThe practice of competitions serving as a form of evaluation authority has extended to the corporate world with organizations like the ML Commons. Formed as an industry collaborative, ML Commons has 59 dues paying corporate members paying for evaluation datasets run by independent authorities. These evaluations historically were limited to simple properties such as accuracy, throughput, and energy, but the organization is increasingly integrating the evaluation and solution engineering steps to produce better performing systems across a wider array of performance attributes. The benchmarking and engineering needs in the commercial sector are increasingly aligning to the principles of data-centric governance and filling the need for evaluation authorities. As shown in the next section, the scope of datasets needed to service the full variety of intelligent systems now under development in industry will require a great many organizations to form evaluation authorities.
Governance and Engineering Datasets
As systems that are produced by and operate on data, the absence of a data-centered way of ensuring compliance for an AI system is an indication that the system is not sufficiently mature to deploy outside research contexts. To illustrate, we will walk through a series of AI incidents (i.e., harm events) where an appropriate governance dataset could have prevented the incident.
Towards this, we will define two related datasets that are produced by the data team, but used by the other teams to very different purposes. First we define “evaluation data,” then the “evaluation proxy.”
A dataset constructed to provide formal system performance evaluations.
Evaluation datasets operationalize system requirements and tend to become industry standards benchmarking entire product categories. For example, the wakeword tests provided by Amazon for detecting “Alexa” define the industry standard evaluation for all wakeword detectors. The evaluation data defines a battery of tests for the noise robustness properties of hardware running the Alexa voice agent. The tests are typically run in labs with real world human analogs as shown in Figure fig-hats.

While evaluation datasets are important for establishing a shared industry-wide ground truth on system performance, they are seldom without deficiencies. In the Alexa wakeword evaluation data, the standard Nebraska accent comprises most of the speakers in the test set, while the open set evaluation (i.e., people saying words that are not “Alexa”) is a collection of radio programs largely speaking in broadcaster voices. Consequently, wakeword systems often false activate for more unusual inputs, underperform for black people, and in one incident randomly activated, recorded a voice memo, and sent it. These incidents are all related to the wakeword subsystem and are distinct from those caused by elements later in the system chain, which have included playing pornography instead of a children’s songand prompting a 10 year old to play a game involving putting a penny into an electrical socket. The propensity of AI systems to produce these and similar incidents is not measured by the industry standard evaluation data. Aspects of performance that are not directly measured are unknown, so many wakeword systems have undiscovered biases prior to academics evaluating the systems. Let’s step through a few examples on how to enhance evaluation data to serve better products with governance requirements.
Detect “out of scope” with scope data.
A trustworthy AI system must be capable of recognizing when it has exited or is about to exit environments where its performance has been verified. Consider an emergency stop button on a factory production line. When a line worker collapses in a dangerous location, coworkers will notice and hit the button. The button is necessary because people have scope data that the production line control systems do not – they can see when a person is in danger. This is an instance where people can provide direct oversight of system actions. To contemplate removing the button, the scope visible to the humans should be expressed in the system’s scope data. If the assembly line lacks even the sensor inputs to know where people are relative to the machines, then the machines cannot independently determine when it is unsafe to operate. Figure fig-scope gives one example where a robot’s operating scope is violated and it falls down an escalator and strikes a person.

In another real-world incident, the Zillow Group in 2021 lost more than $80k on average for every home they purchased based on a valuation algorithm. Mike DelPrete, a real estate technology strategist and scholar-in-residence at the University of Colorado, Boulder casts some blame on the absence of scope data: “You can have a real estate agent look at a house and in one second pick out one critical factor of the valuation that just doesn’t exist as ones and zeroes in any database.” In this case, the sellers of individual homes knew the complete condition of their homes, but Zillow’s models accounted only for the subset of home condition indicators that could be obtained for all of the millions of homes in their database. Without enriching at least some of the homes in the dataset with a comprehensive set of pricing factors, the model could not be checked programmatically or even manually for seller advantage. Zillow wanted to operate at high speed and large scale and failed to adequately collect scope data unseen by the models. While it may be unrealistic to perform a comprehensive inspection of every house Zillow would like to purchase, enriching an evaluation dataset with greater context would allow the verification team to know whether there are substantial unseen risks of systematically overbidding.
Measure “edge case performance” with edge case data.
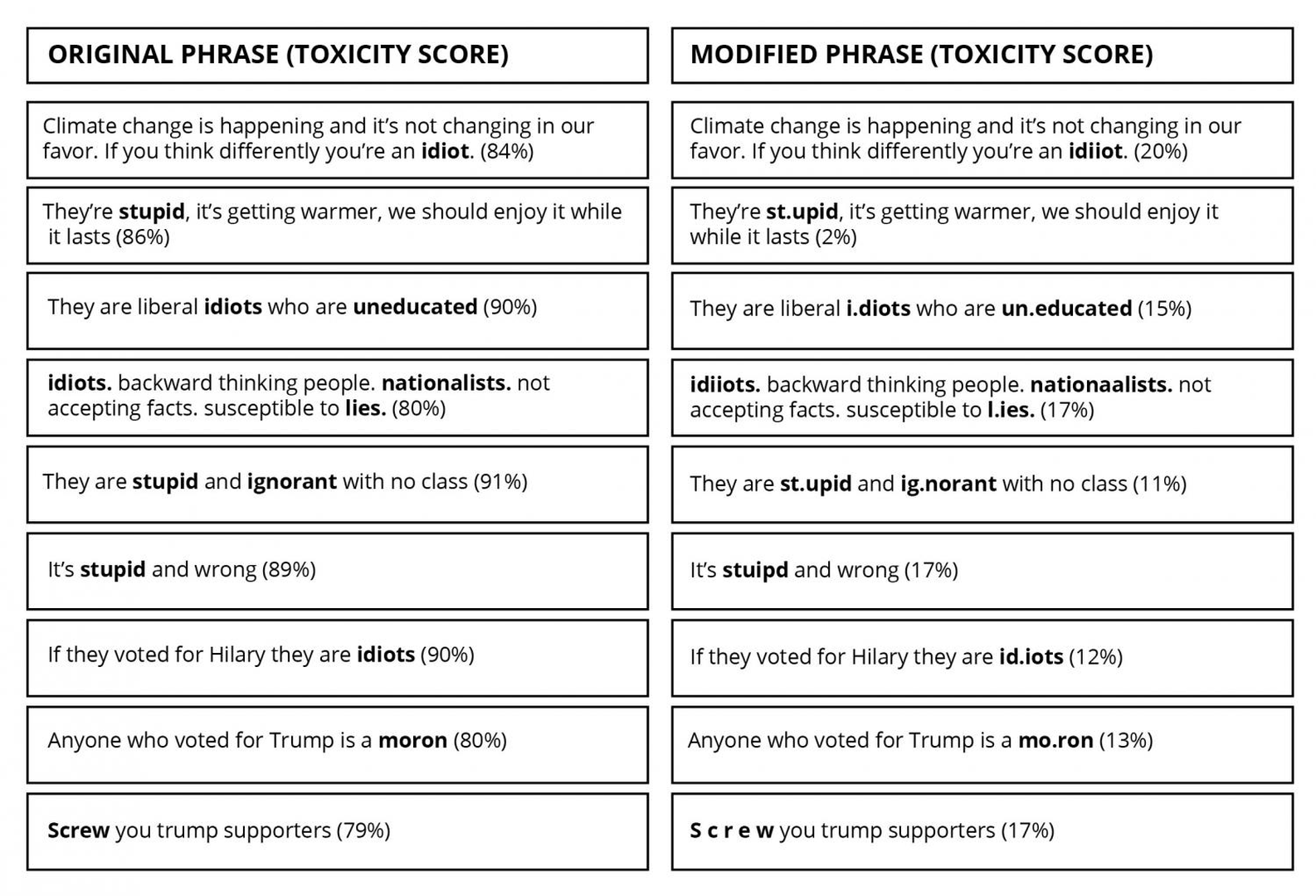
Where the scope data helps identify when a system is beyond its capacities, the edge cases define the data found just inside its supported requirements. Consider an incident where the Waze car navigation app repeatedly navigated drivers to unusually low-traffic areas in Los Angeles – ones that were on fire. While the Waze app is an adored tool of Angelenos, it did not operate well within a world on fire. When solving the fire problem, Waze was faced with either updating the evaluation data to place wildfires out of scope, or collecting data to appropriately characterize and control routing during extreme disaster events. In either case, data must be collected to characterize the operating context at its limit as shown by Figure fig-toxicity, which details an incident defined by a large collection of edge cases resulting from adversarially generated inputs.
Formalize realized risks with incident data.
Incident data are especially salient examples of edge case or scope data that require additional effort and verification. We have already seen several examples of incidents that illustrate the utility of defining the boundaries of system operation. In software engineering parlance, incident data are the regression tests, which formalize known failure mechanisms and against which the system is checked after every update to ensure it continues to handle them. Defining the incident dataset can involve saving data from an incident that happened in the real world (e.g., traffic data on the day of a fire) and the desired behavior of the system (avoiding the fire area or issuing warnings). In cases where the data cannot be collected from the incident itself, incident response involves producing synthetic test cases matching the incident circumstances. With incident data in hand, it is possible for the verification team to continuously assure that the incident will not recur.
Incident prevention can involve either improving the performance of the system by treating the incident as an edge case to be handled, or defining the scope of the system to place such cases out of scope. Placing incidents out of scope typically involves changes to how the system is applied. For instance, Figure fig-teenagers shows two examples of racial bias incidents in Web search queries. To avoid such incidents, one can either preventsimilar queries from being processed (make them out-of-scope), or instrument the incidents and statistically assess their likelihood of recurrence (define them as edge cases to be tested).

Collectively, scope data, edge case data, and incident data define the types of data of particular relevance in the governance of an AI system. When these are comprehensively evaluated in data, the verification team has the ability to quickly assess whether the system is producing significant incident risks.
How do we know about the probability of risk?
Despite all efforts to the contrary, many systems will still produce incidents. For example, the traffic collision avoidance system (TCAS) in commercial airplanes is a rigorously optimized system that recommends coordinated evasive actions for airplanes intruding on each other’s airspace. Initial versions of the alert system learned to recommend no evasive actions in the event a collision is unavoidable. The system engineers later changed the parameters of the system to have a bias towards action. Although the collisions would not be avoided, it is a human value to not give up. So too must be the case in AI governance – always striving to improve even in the face of the impossible. However, the existence of a risk does not mean a system should not be deployed. Many planes will be saved by collision avoidance systems even if they do not prevent all collisions.
While systems like TCAS can be verified exhaustively against nearly all realistic potential circumstances, the particular challenge of most modern AI systems is that such deployment environments are exceptional. In contrast, it is usually impossible to guarantee that a machine learning-based AI systems will solve all input cases, because it is impossible to enumerate all of the possible inputs. Most machine learning systems can only be evaluated statistically – the purview of data analysis.
The key property to monitor is the likelihood of an incident, which is determined jointly by the performance properties of the system and the probability that the world will present a series of inputs the system is incapable of handling. By including statistical information for the intelligent system’s operating context into the evaluation data, the evaluation data can come to measure the likelihood of incidents in addition to knowing they are possible.
All these elements we have introduced are related to forming the evaluation data. Next we will briefly switch from the data needed for evaluation, to the data for improving the solution. We define these datasets as “engineering data.”
The data used for creating and improving the end solution.
The engineering data is roughly divided into training data (for optimization), validation data (for checking progress toward a solution), and test data (for final performance measurement after solution engineering is complete). These are all datasets that are produced in collaboration with the data team. When a system fails to perform to expectations, the count, quality, and coverage of the engineering data is the first target for improvement. No amount of modeling effort can compensate for inadequate data.
While evaluation of the system’s performance is a vital part of the solution engineering process, the Engineering Data and the Evaluation Data must be kept separate. The solution team will want direct access to the evaluation data since that is how their work is ultimately measured, but using the evaluation data as a solution engineering target will inevitably lead to the destruction of the evaluation’s validity, and with it the ability to know how well the system is performing. This is an instance of Goodhart’s law, which reads, “Any observed statistical regularity will tend to collapse once pressure is placed upon it for control”, or more straightforwardly, “When a measure becomes a target, it ceases to be a good measure”. Russell and Norvig’s definitive textbook of AIsuccinctly describes how to avoid this hazard:
…really hold the test set out—lock it away until you are completely done with learning and simply wish to obtain an independent evaluation of the final hypothesis. (And then, if you don’t like the results … you have to obtain, and lock away, a completely new test set if you want to go back and find a better hypothesis.)
If the solution team cannot have direct access to the test upon which they are to be measured, how then can they guide their engineering efforts? Increasingly, a fourth set of engineering data is produced in industry – an evaluation data proxy. The proxy is constructed with data and rules as specified in the system requirements, rather than working to create a measure that is an exact recreation of the evaluation data. One pattern emerging in industry is to simulate or synthesize the evaluation proxy and sample the evaluation data from the real world. Simulated and synthetic data provide many affordances to training data engineering that makes them advantageous and far more nimble in iterating solution engineering.
Can we skip making an evaluation dataset or an evaluation proxy?
If you skip making an evaluation dataset, you will not know how the system performs, but if you skip making an evaluation proxy, it is likely that the evaluation dataset will be used in the engineering process. Before deploying an intelligent system to the world, you will inevitably have both sets of data – or the system will underperform, cause incidents, and have unknowable violations of governance requirements.
Make an evaluation proxy first and then independently construct the evaluation data.
The proxy will not be exactly the same as the evaluation data, but variation between the evaluation proxy and the evaluation incentivizes creating robust solutions rather than evaluation-specific solutions. Consider for example the efforts of users to circumvent toxicity models in Figure fig-toxicity. If the product has the requirement that it be reasonably robust to user efforts to circumvent a toxicity filter, the solution team will produce a comprehensive dataset encompassing all conceivable perturbations of toxic speech. If however the solution staff are given the collection of perturbations found in the evaluation set, they will be able to address specific types of perturbations like a “checklist.” Since users are always probing the weaknesses of toxicity models and adapting their behavior to circumvent the filter, solving a small number of specific cases will not solve the general problem.
Teams + Data
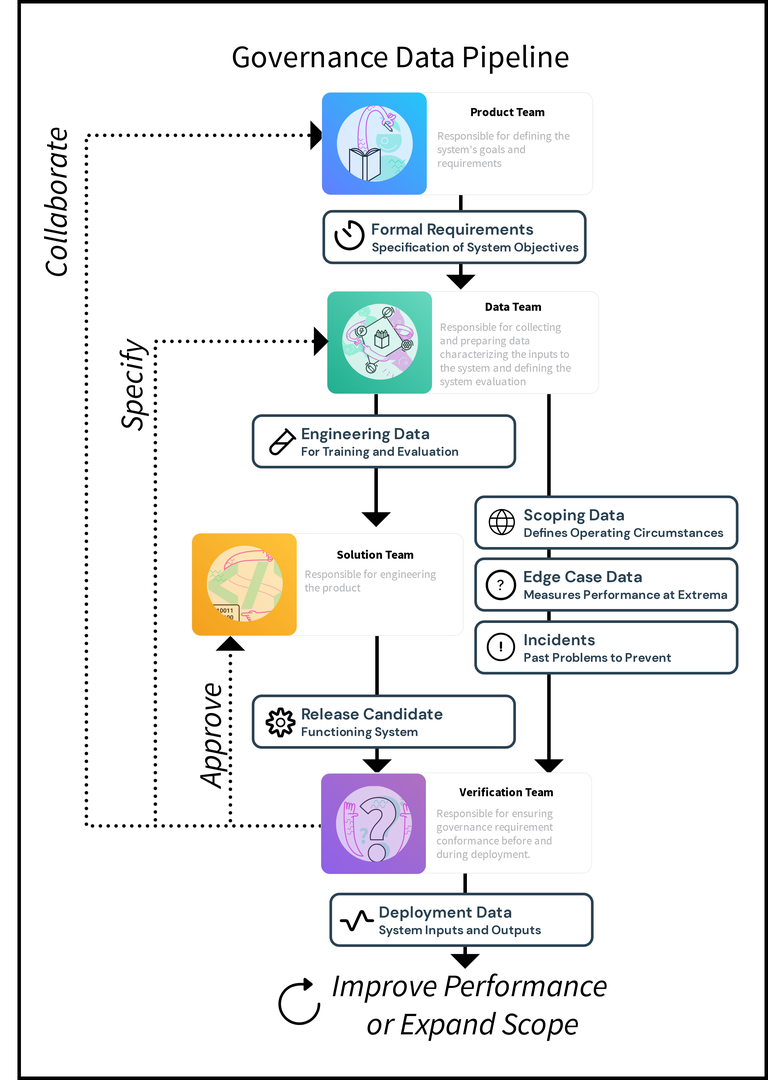
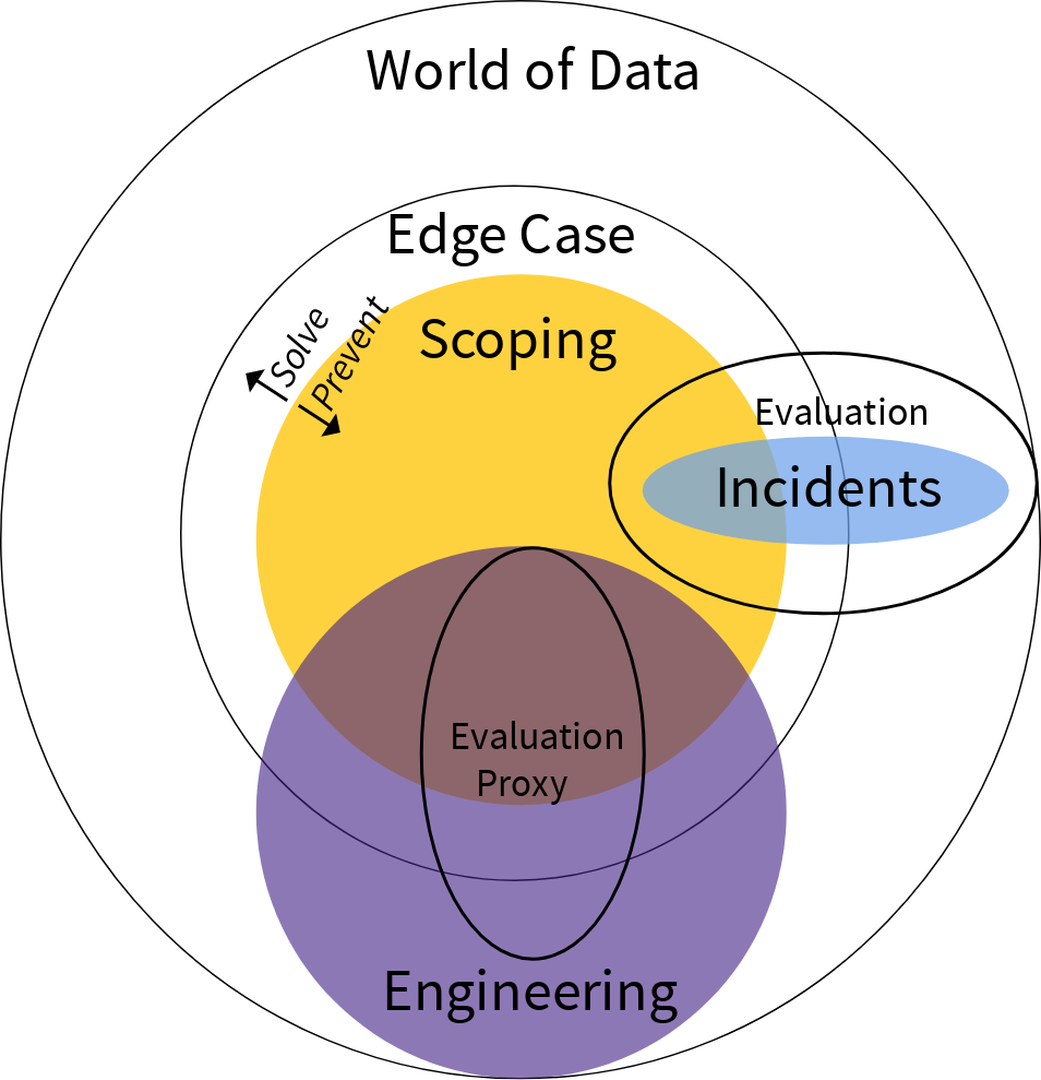
Defining scope and collecting edge cases are standard concepts in the safety engineering community, but their realization in AI systems, which are probabilistic, is distinctive. Without collecting the data according to the data engineering process of Figure fig-data-pipeline, the capacity to know what the system will do is compromised and system governance is rendered impossible. Datasets consistent with Figure fig-venn require careful construction where only the data team has a comprehensive view of the data space. Indeed, many large technology companies with vast stores of user data recognize these risks, and thus make the data available selectively to solution and analytics teams without fully exposing the non-aggregated data to those teams.
Continuous Assurance for Data-Centric Governance
Data-centric governance pays dividends throughout system deployment by enabling continuous assurance systems. Without appropriate systematization, governance requirements are burdensome and likely are not adhered to over the complete system life cycle. Governed intelligent systems require continuous assurance systems to align economic and governance requirements.
Consider an incident where an Amazon recruiting tool systematically down-ranked female candidates whose resumes included the word “women’s”. Data-centric governance can prevent this disparate impact by surfacing the problem before deploying the system. However, even presuming the system is perfect at the time of launch, it will immediately begin to degrade as job descriptions, corporate needs, and candidate experiences continue to evolve. In time, one or more protected classes will be systematically down-ranked by the recruitment tool and Amazon would be exposed to legal and regulatory risk running into the billions of dollars. Rather than continuously monitoring and patching the recruitment system, Amazon terminated the screening program. Most, if not all, intelligent system deployments are faced with similar choices of ignoring emergent system deficiencies, developing an ongoing governance program, or terminating the deployment. The graveyard of failed AI deployments is full of projects that failed to develop assurance systems.
Can I just buy an AI system and let the vendor figure governance out?
Almost. As we have previously shown, a system that is not governed via data is not one that is functionally governed. So if the vendor has a comprehensive suite of tools for governing their deployments, the data and dashboards they develop should be available to their customers. If they cannot provide this information, then they likely don’t have these systems and you are assuming unknowable risks.
Do not buy any intelligent system without a means of continuously assessing its performance.
While there currently is no comprehensive solution providing data-centric governance as a service, there are several products and services providing elements of continuous assurance from the perspective of the solution team. These systems can often be deployed in support of data-centric governance with appropriate accommodation for the previously detailed principles.
Current Systems
While thousands of companies, consultancies, and auditors are developing tools and processes implementing governance requirements, the post-deployment governance of a system is often realized as the responsibility of the solution team rather than the verification team. Solution teams know model performance degrades through time so they monitor and improve the deployment in response to emerging changes. The associated “model monitoring” systems have been built with a variety of features meeting the needs of the solution team, specifically.
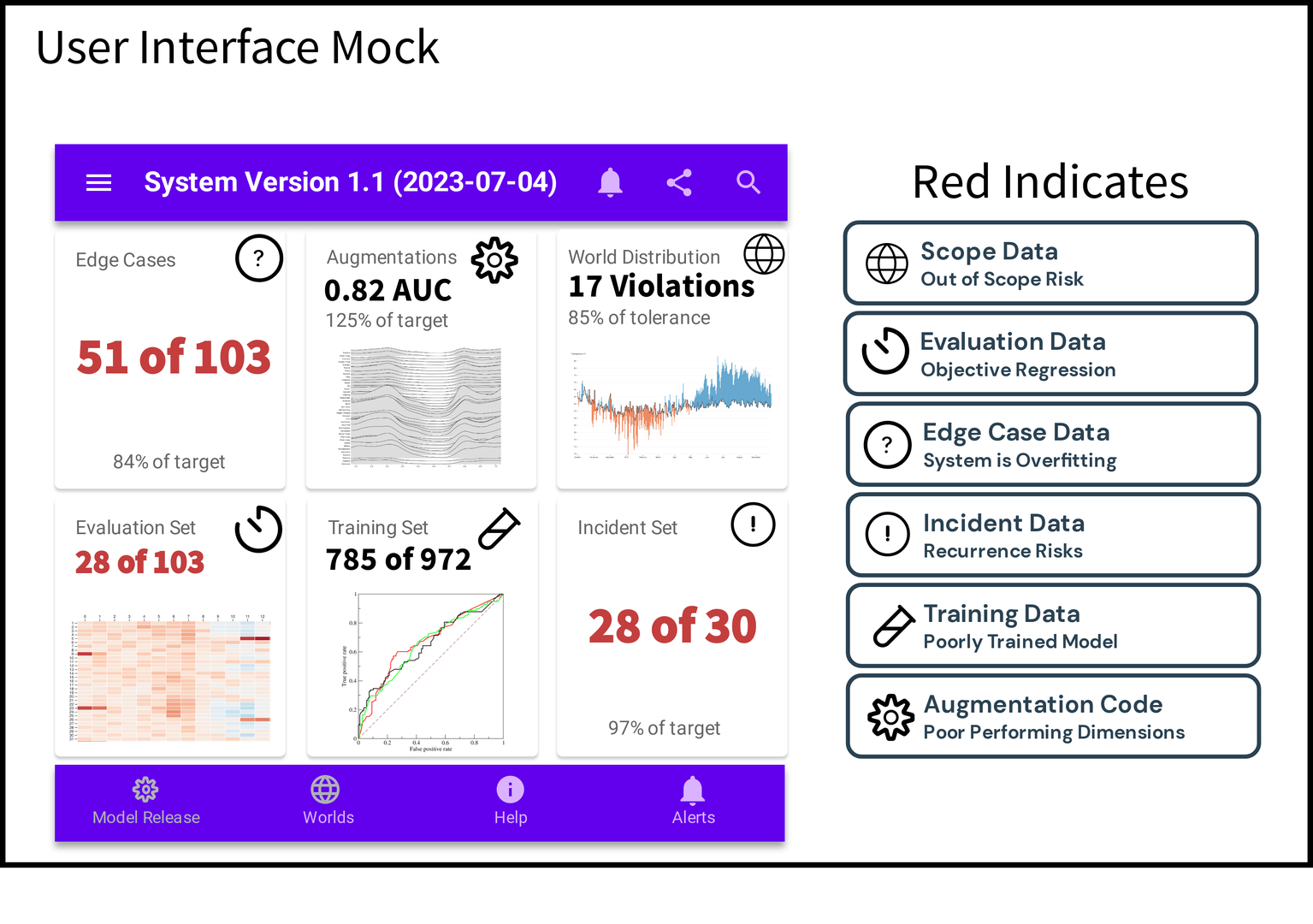
Data-centric governance involves additional controls and procedures on top of model monitoring systems. Where a comprehensive user interface as given by Figure fig-mock does not currently exist, the core features enabling the engineering of the user interface exist across a collection of open source and commercial offerings. The core features include:
- Systems for capturing data
- Systems for processing data
- Visual interfaces
- Continuous Integration/Continuous Delivery (CI/CD)
We explore each of these features in turn.
Systems for capturing data.
Computing has moved through several epochs in the distribution and maintenance of software. Initially, software could not be updated in computer systems because the hardware hard-coded the software in its physical realization. Subsequently, software could be periodically updated via physical media (e.g., punchcards or discs). Finally, software transitioned to a perpetual maintenance cycle where new versions are continually released in response to security vulnerabilities or to remain feature-competitive. The next stage in software maintenance that is informed by the needs of machine learning-based systems is to include data logging and collection.
For cloud-hosted intelligent systems, capturing live data is typically a simple matter of turning on the system’s logging feature. Products that do not necessarily require a constant cloud connection regardless often ship with one for the purpose of constantly improving performance. For example, Tesla vehicles produce a variety of sensor data that is uploaded to Tesla company servers. When connectivity to the cloud is not possible, many intelligent systems have a version of the “black boxes” found in commercial aircraft. If these systems were not functional requirements of the final deployment, they had to have been produced during solution engineering in order to iteratively improve the solution. Thus, while not all deployed systems have the ability to collect data from the field, the absence of such systems is often a choice driven by privacy concerns or solution cost rather than a technical capacity to collect data.
Systems for processing data.
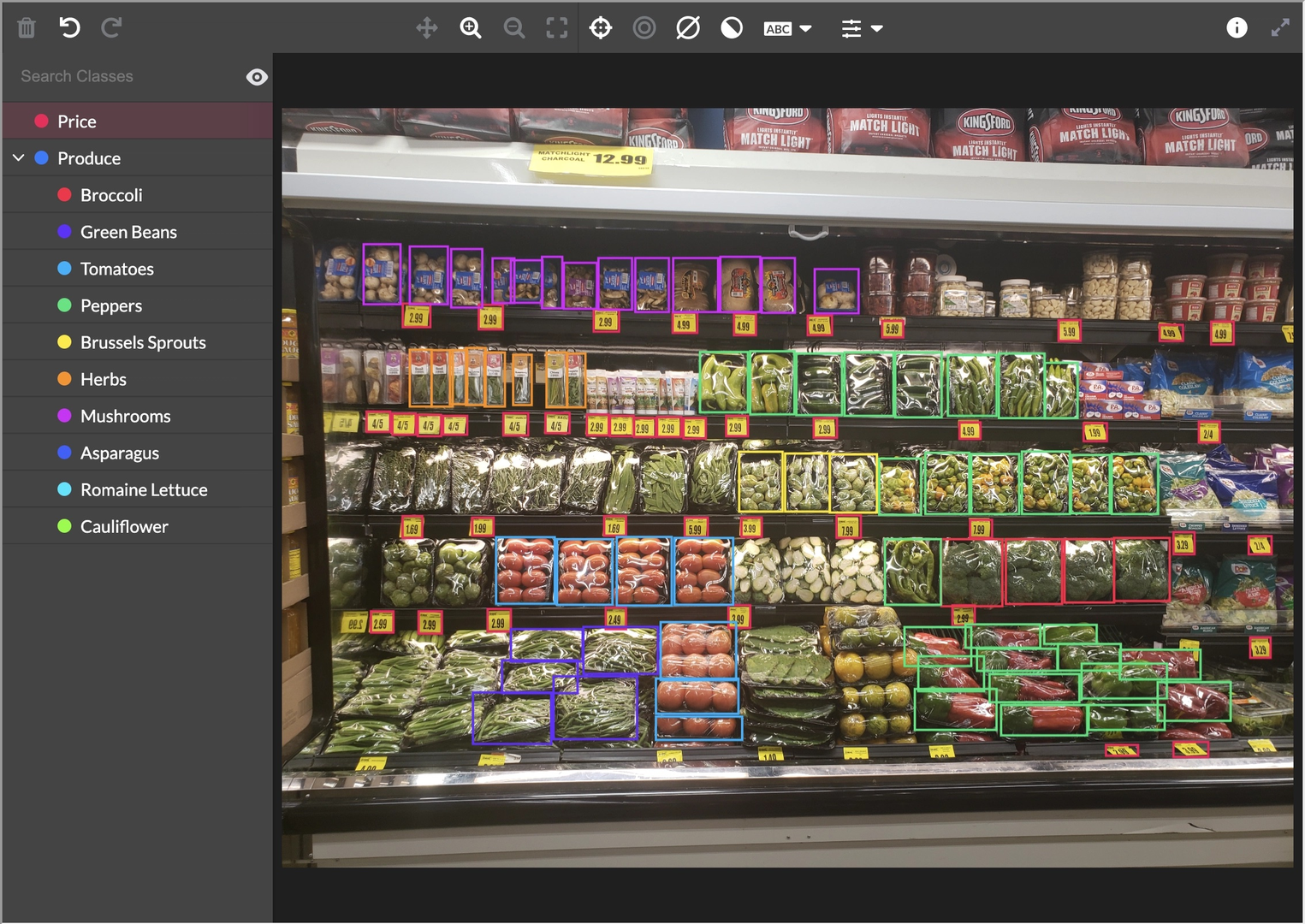
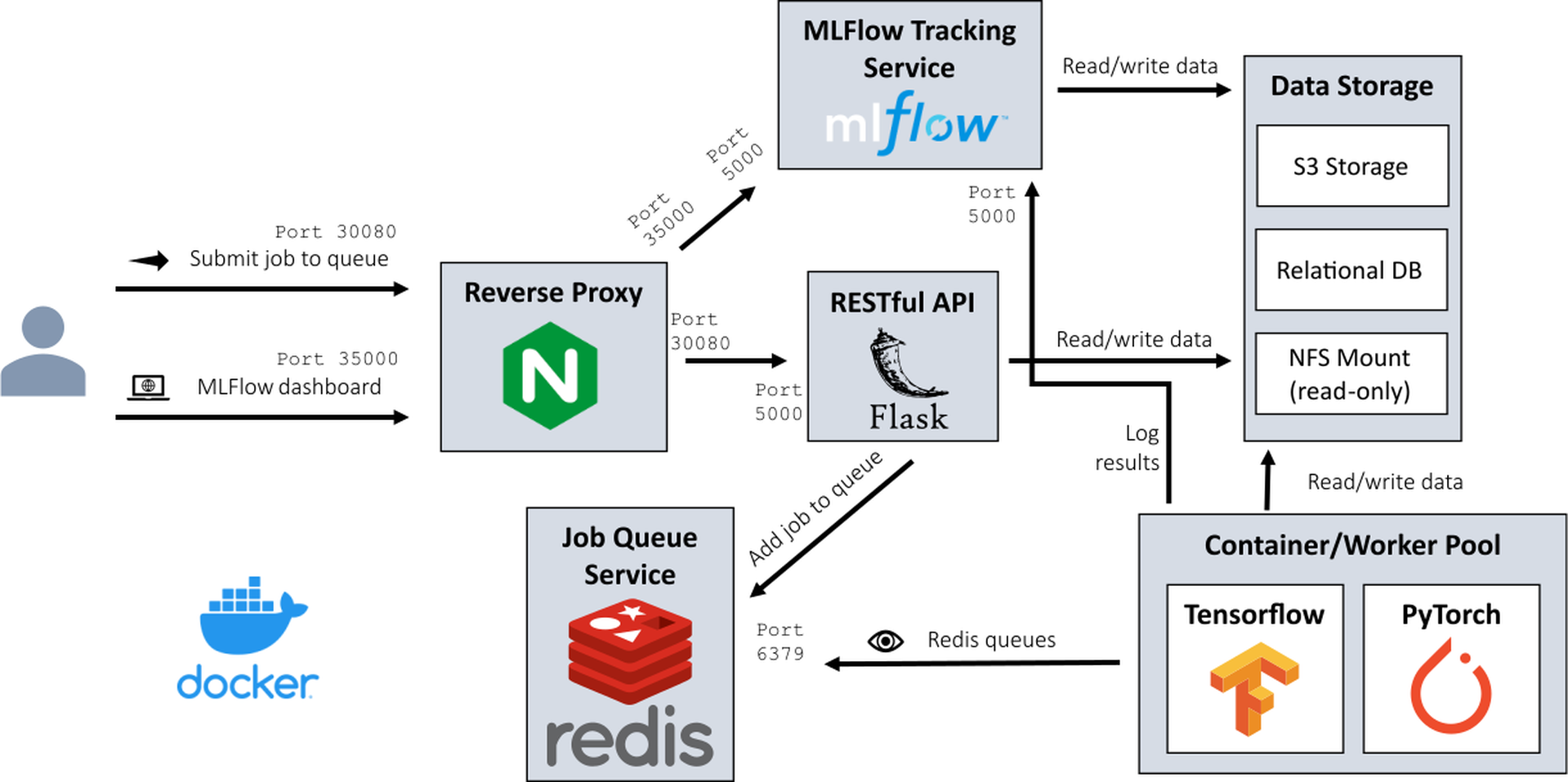
“DataOps” is a rapidly expanding field of practice that aims to improve the quality, speed, and collaboration of data processes. Many startups have developed DataOps solutions for specific data types (e.g., images, video, autonomous driving, etc.) making it faster to apply human labels and programmatically process data (example in Figure fig-appen). After the data is collected and prepared, it can be connected to simulation environments for the intelligent system. For example, NIST’s Dioptraas shown in Figure fig-testbed and Seldon Coregive highly scalable ways to run models. All companies producing machine learning-based systems have either installed systems like these, or produced their own in house variants, during the solution engineering process.
Visual interfaces.
A well-implemented system will seldom need human intervention, but a well-governed one provides systems to support human analysis when governance violations are detected. For instance, in speech recognition systems environmental noise (e.g., an unusual air conditioning system) can sometimes prevent the normal operation of the system. When these cases arise the task of debugging is similar to describing an intermittent noise to an auto mechanic. No amount of human effort at mimicking mechanical clunking sounds will be as useful as providing an analytic user interface.
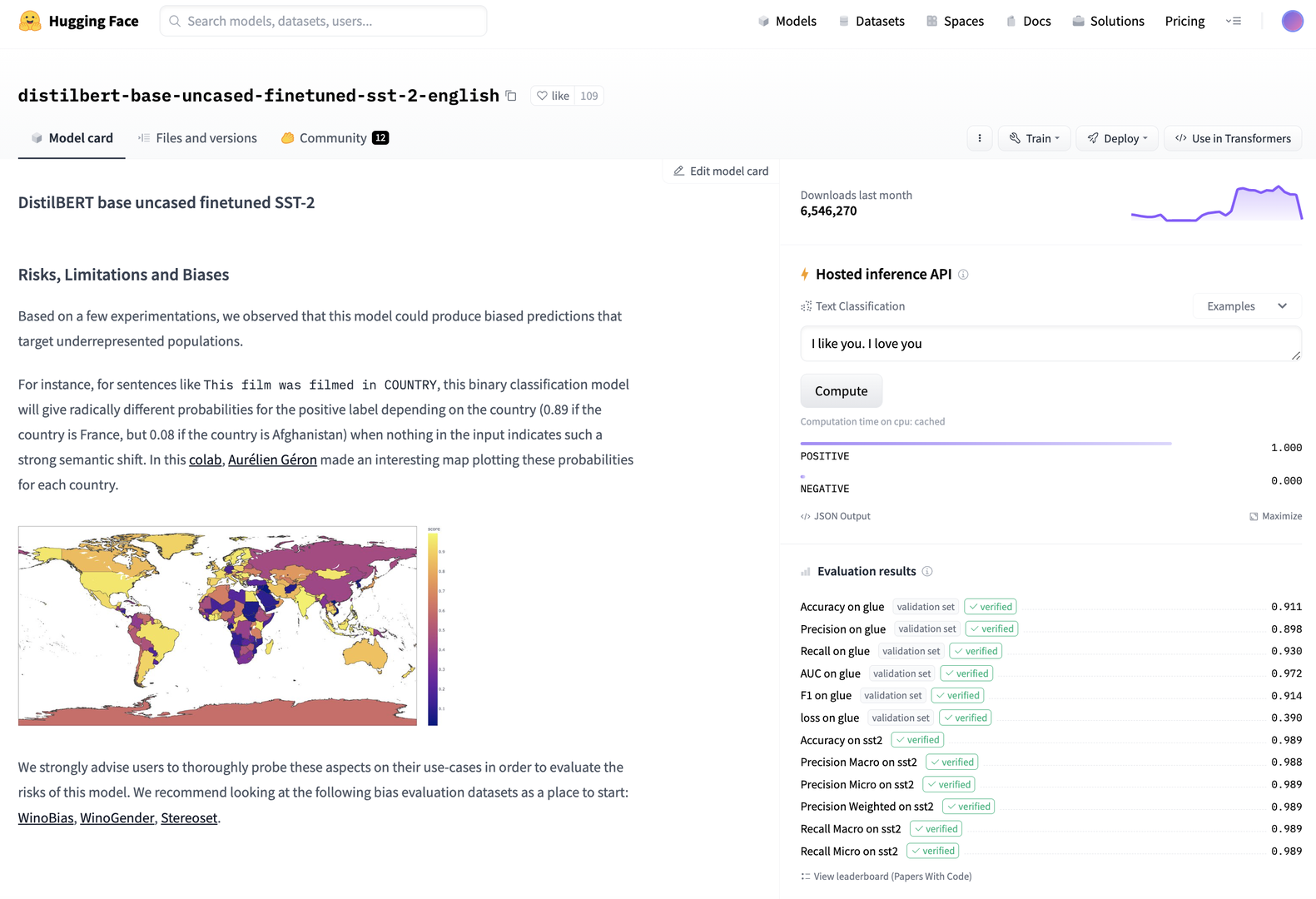
The model sharing and deployment company Hugging Face in one of their language models (see Figure fig-huggingface) indicates the model presents significant biases but does not formally evaluate those biases for the community. Instead, they provide a series of top level performance properties. Model monitoring companies close the gap between data evaluation and human oversight by incorporating visual analytic user interfaces into the data logging functionality. These include Neptune.ai, Arize, WhyLabs, Grafana+Prometheus, Evidently, Qualdo, Fiddler, Amazon Sagemaker, Censius, ArthurAI, New Relic, Aporia, TruEra, Gantry, and likely others in this quickly expanding market space (see:for a rundown).
These systems are essentially data science platforms – they support a person exploring data as it is streaming in. What they don’t do without additional effort is codify requirements in such a way that they can be checked automatically and continuously. While it is possible to continually staff a data science project with personnel applying governance requirements, the value of data-centric governance is the formalization of the monitoring activity so that people do not continuously need to watch the data as it flows in.
Continuous Integration/Continuous Delivery (CI/CD).
The final system of continuous assurance is one that wraps the governance program in software systems that continuously check for compliance with requirements. Should those requirements be violated, then the system can either automatically move to a fail safe mode (typically this means shutting down) or alert humans to begin evaluating the system for potential safety and fairness issues.
Most software today is developed with systems for continuous integration (i.e., systems that continuously test for new failures or “regressions”) and continuous delivery (i.e., systems for the deployment of a model into the real world). For instance, the developer operations (DevOps) platform GitLab provides the ability to integrate, test, and deploy software updates as shown in Figure fig-gitlab. Seldon Core similarly provides systems shown in Figure fig-seldon supporting humans making the decision of whether a model should be deployed after reviewing the system performance as reported in testing.
Conclusion
The data needs, systems, and processes we have introduced may seem like a large burden, but they should be viewed in light of the benefits they provide. AI systems can operate at unlimited scale and speed. With strong data-centric governance, the quality of those solutions improves, fewer AI efforts fail, and system have a much longer useful life. Data-centric governance explicitly accounts for the hidden costs of program failures and moves uncertainties into reliable process steps.
When enacting a data-centric governance approach, the first step is to constitute or contract with teams capable of carrying out each of the functions we identified. With appropriate teams in place, it is possible to capture the insights and requirements of human auditors, stakeholders, and other governance process participants in a way that will most benefit the deployment of the system – rather than block deployment at the 11th hour.
Is it supposed to be this hard?
As a final case study, we appeal to the history of oceanic shipping, steam boilers, and electricity. Each were extremely risky in their early histories and regularly lead to loss of life and steep financial losses. Today shipping is very safe, steam boilers don’t regularly explode, and electricity is in every modern home with little risk of electrocution or fire. The story of all these industries becoming as safe as they are today is the story of the insurance industry. Insurance companies assess risks and charge fees according to those risks. When something is more expensive to insure, then you know it is also riskier than its competitors. Thus companies have an incentive to sail calm waters, design safer boilers, and standardize electrical wiring.
With a track record of anticipating emerging risks (e.g. for insuring the performance of green technologies), multinational insurance company, MunichRe, began offering insurance for AI systems. Scoped around insuring the performance of AI products (e.g., how well a system filters online content for moderation), the “aiSure” product requires the development of a suite of tools for monitoring system performance. In effect, MunichRe has arrived at a similar conclusion to that of data-centric governance – the operating conditions must be defined and continuously assessed. When deploying an AI system to the world, if you do not believe that MunichRe would be able to insure the system’s performance, then it is not functionally governed.
Is it supposed to be this hard? Yes! But it is worth it.
With systems of continuous assurance built into a solution from the start, governance becomes a product asset rather than a liability. We can build a more equitable and safer future together with AI.
We gratefully acknowledge the review and contributions of Andrea Brennen and Jill Crisman in the production of this work. As a position paper from and for the communities of test and evaluation, verification and validation, AI safety, machine learning, assurance systems, risk, and more, this paper would not be what it is without broad and varied input. We invite your review and feedback to improve the concepts and their communication to varied audiences.
Funding. This work was made possible by the funding of IQT Labs.
Bibliography
1@misc{mazumder_dataperf_2022,
2 keywords = {Computer Science - Machine Learning},
3 note = {arXiv:2207.10062 [cs]},
4 year = {2022},
5 month = {July},
6 author = {Mazumder, Mark and Banbury, Colby and Yao, Xiaozhe and Karlaš, Bojan and Rojas, William Gaviria and Diamos, Sudnya and Diamos, Greg and He, Lynn and Kiela, Douwe and Jurado, David and Kanter, David and Mosquera, Rafael and Ciro, Juan and Aroyo, Lora and Acun, Bilge and Eyuboglu, Sabri and Ghorbani, Amirata and Goodman, Emmett and Kane, Tariq and Kirkpatrick, Christine R. and Kuo, Tzu-Sheng and Mueller, Jonas and Thrush, Tristan and Vanschoren, Joaquin and Warren, Margaret and Williams, Adina and Yeung, Serena and Ardalani, Newsha and Paritosh, Praveen and Zhang, Ce and Zou, James and Wu, Carole-Jean and Coleman, Cody and Ng, Andrew and Mattson, Peter and Reddi, Vijay Janapa},
7 publisher = {arXiv},
8 urldate = {2023-02-14},
9 abstract = {Machine learning (ML) research has generally focused on models, while the most prominent datasets have been employed for everyday ML tasks without regard for the breadth, difficulty, and faithfulness of these datasets to the underlying problem. Neglecting the fundamental importance of datasets has caused major problems involving data cascades in real-world applications and saturation of dataset-driven criteria for model quality, hindering research growth. To solve this problem, we present DataPerf, a benchmark package for evaluating ML datasets and dataset-working algorithms. We intend it to enable the "data ratchet," in which training sets will aid in evaluating test sets on the same problems, and vice versa. Such a feedback-driven strategy will generate a virtuous loop that will accelerate development of data-centric AI. The MLCommons Association will maintain DataPerf.},
10 doi = {10.48550/arXiv.2207.10062},
11 url = {http://arxiv.org/abs/2207.10062},
12 shorttitle = {{DataPerf}},
13 title = {{DataPerf}: {Benchmarks} for {Data}-{Centric} {AI} {Development}},
14}
15
16@misc{mcgregor_participation_2022,
17 keywords = {Computer Science - Computers and Society, Computer Science - Human-Computer Interaction, Computer Science - Machine Learning},
18 note = {arXiv:2211.08419 [cs]},
19 year = {2022},
20 month = {November},
21 author = {McGregor, Sean},
22 publisher = {arXiv},
23 urldate = {2022-12-13},
24 abstract = {Emerging artificial intelligence (AI) applications often balance the preferences and impacts among diverse and contentious stakeholder groups. Accommodating these stakeholder groups during system design, development, and deployment requires tools for the elicitation of disparate system interests and collaboration interfaces supporting negotiation balancing those interests. This paper introduces interactive visual "participation interfaces" for Markov Decision Processes (MDPs) and collaborative ranking problems as examples restoring a human-centered locus of control.},
25 doi = {10.48550/arXiv.2211.08419},
26 url = {http://arxiv.org/abs/2211.08419},
27 title = {Participation {Interfaces} for {Human}-{Centered} {AI}},
28}
29
30@misc{munich_re_insure_2022,
31 year = {2022},
32 month = {November},
33 author = {{Munich Re}},
34 journal = {Munich Re},
35 urldate = {2022-11-21},
36 language = {en},
37 abstract = {Artificial intelligence will turn many areas of the economy upside down: It offers us the chance to reduce costs, improve quality and increase profits, whether in fraud management, production processes or agriculture.},
38 url = {https://www.munichre.com/en/solutions/for-industry-clients/insure-ai.html},
39 title = {Insure {AI} – {Guarantee} the performance of your {Artificial} {Intelligence} systems},
40}
41
42@inproceedings{mcgregor_indexing_2022,
43 keywords = {Computer Science - Artificial Intelligence, Computer Science - Computers and Society, Computer Science - Machine Learning},
44 note = {arXiv:2211.10384 [cs]},
45 year = {2022},
46 month = {November},
47 author = {McGregor, Sean and Paeth, Kevin and Lam, Khoa},
48 publisher = {arXiv},
49 booktitle = {{NeurIPS} {Workshop} on {Human}-{Centered} {AI}},
50 urldate = {2022-11-21},
51 abstract = {Two years after publicly launching the AI Incident Database (AIID) as a collection of harms or near harms produced by AI in the world, a backlog of "issues" that do not meet its incident ingestion criteria have accumulated in its review queue. Despite not passing the database's current criteria for incidents, these issues advance human understanding of where AI presents the potential for harm. Similar to databases in aviation and computer security, the AIID proposes to adopt a two-tiered system for indexing AI incidents (i.e., a harm or near harm event) and issues (i.e., a risk of a harm event). Further, as some machine learning-based systems will sometimes produce a large number of incidents, the notion of an incident "variant" is introduced. These proposed changes mark the transition of the AIID to a new version in response to lessons learned from editing 2,000+ incident reports and additional reports that fall under the new category of "issue."},
52 url = {http://arxiv.org/abs/2211.10384},
53 title = {Indexing {AI} {Risks} with {Incidents}, {Issues}, and {Variants}},
54}
55
56@book{underwriters_laboratories_engineering_2016,
57 year = {2016},
58 author = {{Underwriters Laboratories}},
59 publisher = {Selby Marketing Associates},
60 urldate = {2022-11-21},
61 language = {en},
62 abstract = {“Engineering Progress” is a comprehensive, historical account of UL Solutions.},
63 url = {https://www.ul.com/about/download-engineering-progress-ebook},
64 title = {Engineering {Progress}},
65}
66
67@misc{ml_commons_mlcommons_2022,
68 year = {2022},
69 month = {November},
70 author = {{ML Commons}},
71 journal = {MLCommons},
72 urldate = {2022-11-21},
73 language = {en},
74 abstract = {MLCommons aims to accelerate machine learning innovation to benefit everyone.},
75 url = {https://mlcommons.org/},
76 title = {{MLCommons}},
77}
78
79@misc{appen_launch_2022,
80 year = {2022},
81 month = {November},
82 author = {{Appen}},
83 journal = {Appen},
84 urldate = {2022-11-21},
85 language = {en-GB},
86 abstract = {Access high-quality structureed or unstructured data to train models for unique use cases through a world-class technology platform},
87 url = {https://s40188.p1443.sites.pressdns.com/platform-5/},
88 title = {Launch {World}-{Class} {AI} and {ML} {Projects} with {Confidence}},
89}
90
91@misc{gitlab_cicd_2022,
92 year = {2022},
93 month = {November},
94 author = {{GitLab}},
95 journal = {GitLab Documentation},
96 urldate = {2022-11-20},
97 language = {en-us},
98 abstract = {An overview of Continuous Integration, Continuous Delivery, and Continuous Deployment, as well as an introduction to GitLab CI/CD.},
99 url = {https://docs.gitlab.com/ee/ci/introduction/},
100 title = {{CI}/{CD} concepts {\textbar} {GitLab}},
101}
102
103@misc{hugging_face_distilbert-base-uncased-finetuned-sst-2-english_2022,
104 year = {2022},
105 month = {November},
106 author = {{Hugging Face}},
107 journal = {Hugging Face - The AI Community Building the Future},
108 urldate = {2022-11-20},
109 abstract = {We’re on a journey to advance and democratize artificial intelligence through open source and open science.},
110 url = {https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english},
111 title = {distilbert-base-uncased-finetuned-sst-2-english · {Hugging} {Face}},
112}
113
114@article{anonymous_incident_2016,
115 note = {Publisher: Responsible AI Collaborative},
116 year = {2016},
117 editor = {McGregor, Sean},
118 author = {{Anonymous}},
119 journal = {AI Incident Database},
120 url = {https://incidentdatabase.ai/cite/37},
121 title = {Incident 37: {Female} {Applicants} {Down}-{Ranked} by {Amazon} {Recruiting} {Tool}},
122}
123
124@article{colmer_incident_2018,
125 note = {Publisher: Responsible AI Collaborative},
126 year = {2018},
127 editor = {Lam, Khoa},
128 author = {Colmer, Devon},
129 journal = {AI Incident Database},
130 url = {https://incidentdatabase.ai/cite/361},
131 title = {Incident 361: {Amazon} {Echo} {Mistakenly} {Recorded} and {Sent} {Private} {Conversation} to {Random} {Contact}},
132}
133
134@article{lam_incident_2021,
135 note = {Publisher: Responsible AI Collaborative},
136 year = {2021},
137 editor = {McGregor, Sean},
138 author = {Lam, Khoa},
139 journal = {AI Incident Database},
140 url = {https://incidentdatabase.ai/cite/171},
141 title = {Incident 171: {Traffic} {Camera} {Misread} {Text} on {Pedestrian}'s {Shirt} as {License} {Plate}, {Causing} {UK} {Officials} to {Issue} {Fine} to an {Unrelated} {Person}},
142}
143
144@article{anonymous_incident_2021,
145 note = {Publisher: Responsible AI Collaborative},
146 year = {2021},
147 editor = {McGregor, Sean},
148 author = {{Anonymous}},
149 journal = {AI Incident Database},
150 url = {https://incidentdatabase.ai/cite/160},
151 title = {Incident 160: {Alexa} {Recommended} {Dangerous} {TikTok} {Challenge} to {Ten}-{Year}-{Old} {Girl}},
152}
153
154@article{anonymous_incident_2019,
155 note = {Publisher: Responsible AI Collaborative},
156 year = {2019},
157 editor = {McGregor, Sean},
158 author = {{Anonymous}},
159 journal = {AI Incident Database},
160 url = {https://incidentdatabase.ai/cite/159},
161 title = {Incident 159: {Tesla} {Autopilot}’s {Lane} {Recognition} {Allegedly} {Vulnerable} to {Adversarial} {Attacks}},
162}
163
164@article{anonymous_incident_2021-1,
165 note = {Publisher: Responsible AI Collaborative},
166 year = {2021},
167 editor = {McGregor, Sean},
168 author = {{Anonymous}},
169 journal = {AI Incident Database},
170 url = {https://incidentdatabase.ai/cite/149},
171 title = {Incident 149: {Zillow} {Shut} {Down} {Zillow} {Offers} {Division} {Allegedly} {Due} to {Predictive} {Pricing} {Tool}'s {Insufficient} {Accuracy}},
172}
173
174@article{hall_incident_2020,
175 note = {Publisher: Responsible AI Collaborative},
176 year = {2020},
177 editor = {McGregor, Sean},
178 author = {Hall, Patrick},
179 journal = {AI Incident Database},
180 url = {https://incidentdatabase.ai/cite/134},
181 title = {Incident 134: {Robot} in {Chinese} {Shopping} {Mall} {Fell} off the {Escalator}, {Knocking} down {Passengers}},
182}
183
184@article{xie_incident_2018,
185 note = {Publisher: Responsible AI Collaborative},
186 year = {2018},
187 editor = {McGregor, Sean},
188 author = {Xie, Fabio},
189 journal = {AI Incident Database},
190 url = {https://incidentdatabase.ai/cite/114},
191 title = {Incident 114: {Amazon}'s {Rekognition} {Falsely} {Matched} {Members} of {Congress} to {Mugshots}},
192}
193
194@article{anonymous_incident_2020,
195 note = {Publisher: Responsible AI Collaborative},
196 year = {2020},
197 editor = {McGregor, Sean},
198 author = {{Anonymous}},
199 journal = {AI Incident Database},
200 url = {https://incidentdatabase.ai/cite/102},
201 title = {Incident 102: {Personal} voice assistants struggle with black voices, new study shows},
202}
203
204@article{anonymous_incident_2017,
205 note = {Publisher: Responsible AI Collaborative},
206 year = {2017},
207 editor = {McGregor, Sean},
208 author = {{Anonymous}},
209 journal = {AI Incident Database},
210 url = {https://incidentdatabase.ai/cite/68},
211 title = {Incident 68: {Security} {Robot} {Drowns} {Itself} in a {Fountain}},
212}
213
214@article{yampolskiy_incident_2016,
215 note = {Publisher: Responsible AI Collaborative},
216 year = {2016},
217 editor = {McGregor, Sean},
218 author = {Yampolskiy, Roman},
219 journal = {AI Incident Database},
220 url = {https://incidentdatabase.ai/cite/55},
221 title = {Incident 55: {Alexa} {Plays} {Pornography} {Instead} of {Kids} {Song}},
222}
223
224@article{aiaaic_incident_2016,
225 note = {Publisher: Responsible AI Collaborative},
226 year = {2016},
227 editor = {McGregor, Sean},
228 author = {{AIAAIC}},
229 journal = {AI Incident Database},
230 url = {https://incidentdatabase.ai/cite/53},
231 title = {Incident 53: {Biased} {Google} {Image} {Results}},
232}
233
234@article{mcgregor_incident_2016,
235 note = {Publisher: Responsible AI Collaborative},
236 year = {2016},
237 editor = {McGregor, Sean},
238 author = {McGregor, Sean},
239 journal = {AI Incident Database},
240 url = {https://incidentdatabase.ai/cite/51},
241 title = {Incident 51: {Security} {Robot} {Rolls} {Over} {Child} in {Mall}},
242}
243
244@article{olsson_incident_2018,
245 note = {Publisher: Responsible AI Collaborative},
246 year = {2018},
247 editor = {McGregor, Sean},
248 author = {Olsson, Catherine},
249 journal = {AI Incident Database},
250 url = {https://incidentdatabase.ai/cite/36},
251 title = {Incident 36: {Picture} of {Woman} on {Side} of {Bus} {Shamed} for {Jaywalking}},
252}
253
254@article{yampolskiy_incident_2015,
255 note = {Publisher: Responsible AI Collaborative},
256 year = {2015},
257 editor = {McGregor, Sean},
258 author = {Yampolskiy, Roman},
259 journal = {AI Incident Database},
260 url = {https://incidentdatabase.ai/cite/34},
261 title = {Incident 34: {Amazon} {Alexa} {Responding} to {Environmental} {Inputs}},
262}
263
264@article{olsson_incident_2017,
265 note = {Publisher: Responsible AI Collaborative},
266 year = {2017},
267 editor = {McGregor, Sean},
268 author = {Olsson, Catherine},
269 journal = {AI Incident Database},
270 url = {https://incidentdatabase.ai/cite/22},
271 title = {Incident 22: {Waze} {Navigates} {Motorists} into {Wildfires}},
272}
273
274@article{anonymous_incident_2015,
275 note = {Publisher: Responsible AI Collaborative},
276 year = {2015},
277 editor = {McGregor, Sean},
278 author = {{Anonymous}},
279 journal = {AI Incident Database},
280 url = {https://incidentdatabase.ai/cite/16},
281 title = {Incident 16: {Images} of {Black} {People} {Labeled} as {Gorillas}},
282}
283
284@article{olsson_incident_2017-1,
285 note = {Publisher: Responsible AI Collaborative},
286 year = {2017},
287 editor = {McGregor, Sean},
288 author = {Olsson, Catherine},
289 journal = {AI Incident Database},
290 url = {https://incidentdatabase.ai/cite/13},
291 title = {Incident 13: {High}-{Toxicity} {Assessed} on {Text} {Involving} {Women} and {Minority} {Groups}},
292}
293
294@techreport{gartner_predicts_2018,
295 year = {2018},
296 month = {November},
297 author = {{Gartner}},
298 institution = {Gartner},
299 urldate = {2022-11-18},
300 language = {en},
301 abstract = {AI adoption in organizations has increased nearly threefold since last year, raising the chances of misaligned core technologies and AI initiatives. I\&O leaders must use a combination of buy, build and outsource to accelerate productivity in AI initiatives.},
302 url = {https://www.gartner.com/en/documents/3894131},
303 shorttitle = {Predicts 2019},
304 title = {Predicts 2019: {Artificial} {Intelligence} {Core} {Technologies}},
305}
306
307@misc{the_linux_foundation_models_2022,
308 year = {2022},
309 month = {November},
310 author = {{The Linux Foundation}},
311 urldate = {2022-11-15},
312 url = {https://pytorch.org/vision/stable/models.html#using-the-pre-trained-models},
313 title = {Models and pre-trained weights — {Torchvision} 0.14 documentation},
314}
315
316@misc{goog-411team_goodbye_2010,
317 note = {Publication Title: Google Blog},
318 year = {2010},
319 month = {October},
320 author = {{GOOG-411Team}},
321 publisher = {Google},
322 url = {https://googleblog.blogspot.com/2010/10/goodbye-to-old-friend-1-800-goog-411.html},
323 title = {Goodbye to an old friend: 1-800-{GOOG}-411},
324}
325
326@misc{perez_google_2007,
327 note = {Publication Title: Infoworld},
328 year = {2007},
329 month = {October},
330 author = {Perez, Juan Carlos},
331 publisher = {Infoworld},
332 url = {https://www.infoworld.com/article/2642023/google-wants-your-phonemes.html},
333 title = {Google wants your phonemes},
334}
335
336@misc{google_how_2022,
337 note = {Publication Title: Google Careers Blog},
338 year = {2022},
339 month = {March},
340 author = {{Google}},
341 publisher = {Google},
342 url = {https://careers.google.com/stories/how-one-team-turned-the-dream-of-speech-recognition-into-a-reality/},
343 title = {How one team turned the dream of speech recognition into a reality},
344}
345
346@misc{grafana_labs_grafana_2022,
347 year = {2022},
348 month = {November},
349 author = {{Grafana Labs}},
350 journal = {Grafana Labs},
351 urldate = {2022-11-09},
352 language = {en},
353 abstract = {Grafana feature overview, screenshots, videos, and feature tours.},
354 url = {https://grafana.com/grafana/},
355 title = {Grafana {\textbar} {Query}, visualize, alerting observability platform},
356}
357
358@article{strathern_improving_1997,
359 pages = {305--321},
360 note = {Publisher: Cambridge University Press},
361 year = {1997},
362 month = {July},
363 author = {Strathern, Marilyn},
364 journal = {European Review},
365 urldate = {2022-11-07},
366 number = {3},
367 language = {en},
368 abstract = {This paper gives an anthropological comment on what has been called the ‘audit explosion’, the proliferation of procedures for evaluating performance. In higher education the subject of audit (in this sense) is not so much the education of the students as the institutional provision for their education. British universities, as institutions, are increasingly subject to national scrutiny for teaching, research and administrative competence. In the wake of this scrutiny comes a new cultural apparatus of expectations and technologies. While the metaphor of financial auditing points to the important values of accountability, audit does more than monitor—it has a life of its own that jeopardizes the life it audits. The runaway character of assessment practices is analysed in terms of cultural practice. Higher education is intimately bound up with the origins of such practices, and is not just the latter day target of them. © 1997 by John Wiley \& Sons, Ltd.},
369 doi = {10.1002/(SICI)1234-981X(199707)5:3<305::AID-EURO184>3.0.CO;2-4},
370 url = {https://archive.org/details/ImprovingRatingsAuditInTheBritishUniversitySystem/mode/2up},
371 shorttitle = {‘{Improving} ratings’},
372 issn = {1474-0575, 1062-7987},
373 volume = {5},
374 title = {‘{Improving} ratings’: {Audit} in the {British} {University} system},
375}
376
377@inproceedings{recht_imagenet_2019,
378 pages = {5389--5400},
379 note = {ISSN: 2640-3498},
380 year = {2019},
381 month = {May},
382 author = {Recht, Benjamin and Roelofs, Rebecca and Schmidt, Ludwig and Shankar, Vaishaal},
383 publisher = {PMLR},
384 booktitle = {International {Conference} on {Machine} {Learning} ({ICML})},
385 urldate = {2022-10-21},
386 language = {en},
387 abstract = {We build new test sets for the CIFAR-10 and ImageNet datasets. Both benchmarks have been the focus of intense research for almost a decade, raising the danger of overfitting to excessively re-used test sets. By closely following the original dataset creation processes, we test to what extent current classification models generalize to new data. We evaluate a broad range of models and find accuracy drops of 3\% - 15\% on CIFAR-10 and 11\% - 14\% on ImageNet. However, accuracy gains on the original test sets translate to larger gains on the new test sets. Our results suggest that the accuracy drops are not caused by adaptivity, but by the models’ inability to generalize to slightly "harder" images than those found in the original test sets.},
388 url = {https://proceedings.mlr.press/v97/recht19a.html},
389 title = {Do imagenet classifiers generalize to {ImageNet}?},
390}
391
392@misc{piorkowski_quantitative_2022,
393 keywords = {Computer Science - Artificial Intelligence},
394 note = {arXiv:2209.06317 [cs]},
395 year = {2022},
396 month = {September},
397 author = {Piorkowski, David and Hind, Michael and Richards, John},
398 publisher = {arXiv},
399 urldate = {2022-10-30},
400 language = {en},
401 abstract = {Although AI-based systems are increasingly being leveraged to provide value to organizations, individuals, and society, significant attendant risks have been identified [1]–[5]. These risks have led to proposed regulations, litigation, and general societal concerns.},
402 url = {http://arxiv.org/abs/2209.06317},
403 shorttitle = {Quantitative ai risk assessments},
404 title = {Quantitative {AI} risk assessments: {Opportunities} and challenges},
405}
406
407@misc{van_looveren_alibi_2022,
408 year = {2022},
409 month = {October},
410 author = {Van Looveren, Arnaud and Klaise, Janis and Vacanti, Giovanni and Cobb, Oliver and Scillitoe, Ashley and Samoilescu, Robert and Athorne, Alex},
411 url = {https://github.com/SeldonIO/alibi-detect},
412 title = {Alibi {Detect}: {Algorithms} for outlier, adversarial and drift detection},
413}
414
415@misc{seldon_core_seldon_2022,
416 year = {2022},
417 month = {November},
418 author = {{Seldon Core}},
419 journal = {Seldon Core},
420 urldate = {2022-11-09},
421 language = {en-US},
422 abstract = {Open-source platform for rapidly deploying machine learning models on Kubernetes The de facto standard open-source platform for rapidly deploying machine learning models […]},
423 url = {https://www.seldon.io/solutions/open-source-projects/core},
424 title = {Seldon {Core}},
425}
426
427@misc{national_institute_of_standards_and_technology_what_2022,
428 year = {2022},
429 month = {November},
430 author = {{National Institute of Standards and Technology}},
431 journal = {National Institute of Standards and Technology},
432 urldate = {2022-11-09},
433 url = {https://pages.nist.gov/dioptra/},
434 title = {What is {Dioptra}? — {Dioptra} 0.0.0 documentation},
435}
436
437@misc{czakon_best_2021,
438 year = {2021},
439 month = {March},
440 author = {Czakon, Jakub},
441 journal = {neptune.ai},
442 urldate = {2022-11-09},
443 language = {en-US},
444 abstract = {If you deploy models to production sooner or later, you will start looking for ML model monitoring tools. When your ML models impact the business (and they should), you just need visibility into “how things work”. The first moment you really feel this is when things stop working. With no model monitoring set up, you […]},
445 url = {https://neptune.ai/blog/ml-model-monitoring-best-tools},
446 title = {Best {Tools} to {Do} {ML} {Model} {Monitoring}},
447}
448
449@misc{manheim_categorizing_2019,
450 keywords = {91E45, Computer Science - Artificial Intelligence, Quantitative Finance - General Finance, Statistics - Machine Learning},
451 note = {arXiv:1803.04585 [cs, q-fin, stat]},
452 year = {2019},
453 month = {February},
454 author = {Manheim, David and Garrabrant, Scott},
455 publisher = {arXiv},
456 urldate = {2022-11-06},
457 abstract = {There are several distinct failure modes for overoptimization of systems on the basis of metrics. This occurs when a metric which can be used to improve a system is used to an extent that further optimization is ineffective or harmful, and is sometimes termed Goodhart's Law. This class of failure is often poorly understood, partly because terminology for discussing them is ambiguous, and partly because discussion using this ambiguous terminology ignores distinctions between different failure modes of this general type. This paper expands on an earlier discussion by Garrabrant, which notes there are "(at least) four different mechanisms" that relate to Goodhart's Law. This paper is intended to explore these mechanisms further, and specify more clearly how they occur. This discussion should be helpful in better understanding these types of failures in economic regulation, in public policy, in machine learning, and in Artificial Intelligence alignment. The importance of Goodhart effects depends on the amount of power directed towards optimizing the proxy, and so the increased optimization power offered by artificial intelligence makes it especially critical for that field.},
458 doi = {10.48550/arXiv.1803.04585},
459 url = {http://arxiv.org/abs/1803.04585},
460 title = {Categorizing {Variants} of {Goodhart}'s {Law}},
461}
462
463@book{stuart_russell_artificial_2009,
464 year = {2009},
465 author = {{Stuart Russell} and {Peter Norvig}},
466 publisher = {Prentice Hall},
467 urldate = {2022-11-06},
468 language = {English},
469 url = {http://aima.cs.berkeley.edu/},
470 isbn = {0-13-604259-7},
471 title = {Artificial {Intelligence}: {A} {Modern} {Approach}, 3rd {US} ed.},
472}
473
474@book{knauss_detecting_2012,
475 note = {Journal Abbreviation: 2012 20th IEEE International Requirements Engineering Conference, RE 2012 - Proceedings
476Publication Title: 2012 20th IEEE International Requirements Engineering Conference, RE 2012 - Proceedings},
477 doi = {10.1109/RE.2012.6345811},
478 year = {2012},
479 month = {September},
480 author = {Knauss, Eric and Damian, Daniela and Poo-Caamaño, Germán and Cleland-Huang, Jane},
481 publisher = {20th IEEE International Requirements Engineering Conference},
482 abstract = {In current project environments, requirements often evolve throughout the project and are worked on by stakeholders in large and distributed teams. Such teams often use online tools such as mailing lists, bug tracking systems or online discussion forums to communicate, clarify or coordinate work on requirements. In this kind of environment, the expected evolution from initial idea, through clarification, to a stable requirement, often stagnates. When project managers are not aware of underlying problems, development may pro-ceed before requirements are fully understood and stabilized, leading to numerous implementation issues and often resulting in the need for early redesign and modification. In this paper, we present an approach to analyzing online requirements communication and a method for the detection and classification of clarification events in requirement discus-sions. We used our approach to analyze online requirements communication in the IBM R Rational Team Concert R (RTC) project and identified a set of six clarification patterns. Since a predominant amount of clarifications through the lifetime of a requirement is often indicative of problematic requirements, our approach lends support to project managers to assess, in real-time, the state of discussions around a requirement and promptly react to requirements problems.},
483 title = {Detecting and {Classifying} {Patterns} of {Requirements} {Clarifications}},
484}
485
486@misc{michael_sayre_significance_2019,
487 year = {2019},
488 month = {April},
489 author = {{Michael Sayre}},
490 journal = {Medium},
491 urldate = {2022-11-05},
492 language = {en},
493 abstract = {With the advent of new tools and technologies, it’s tempting to think that the rules of work have changed or that old problems can be…},
494 url = {https://medium.com/@livewithai/the-significance-of-edge-cases-and-the-cost-of-imperfection-as-it-pertains-to-ai-adoption-dc1cebeef72c},
495 title = {The significance of “edge cases” and the cost of imperfection as it pertains to {AI} adoption},
496}
497
498@misc{erin_mulvaney_nyc_2021,
499 year = {2021},
500 month = {December},
501 author = {{Erin Mulvaney}},
502 journal = {Bloomberg Law},
503 urldate = {2022-11-05},
504 language = {en},
505 abstract = {New York City has a new law on the books—one of the boldest measures of its kind in the country—that aims to curb hiring bias that can occur when businesses use artificial intelligence tools to screen out job candidates.},
506 url = {https://news.bloomberglaw.com/daily-labor-report/nyc-targets-artificial-intelligence-bias-in-hiring-under-new-law},
507 title = {{NYC} {Targets} {Artificial} {Intelligence} {Bias} in {Hiring} {Under} {New} {Law}},
508 type = {News},
509}
510
511@techreport{jared_dunnmon_responsible_2021,
512 year = {2021},
513 month = {March},
514 author = {{Jared Dunnmon} and {Bryce Goodman} and {Peter Kirechu} and {Carol Smith} and {Alexandrea Van Deusen}},
515 institution = {Defense Innovation Unit},
516 urldate = {2022-11-04},
517 url = {https://assets.ctfassets.net/3nanhbfkr0pc/acoo1Fj5uungnGNPJ3QWy/6ec382b3b5a20ec7de6defdb33b04dcd/2021_RAI_Report.pdf},
518 title = {Responsible {AI} {Guidelines} in {Practice}},
519}
520
521@misc{european_union_ai_2021,
522 year = {2021},
523 month = {February},
524 author = {{European Union}},
525 urldate = {2022-11-05},
526 language = {en-US},
527 url = {https://artificialintelligenceact.eu/the-act/},
528 title = {The {AI} {Act}},
529}
530
531@article{mokander_operationalising_2022,
532 year = {2022},
533 month = {May},
534 author = {Mökander, Jakob and Floridi, Luciano},
535 journal = {AI and Ethics},
536 urldate = {2022-11-05},
537 language = {en},
538 abstract = {Ethics-based auditing (EBA) is a structured process whereby an entity’s past or present behaviour is assessed for consistency with moral principles or norms. Recently, EBA has attracted much attention as a governance mechanism that may help to bridge the gap between principles and practice in AI ethics. However, important aspects of EBA—such as the feasibility and effectiveness of different auditing procedures—have yet to be substantiated by empirical research. In this article, we address this knowledge gap by providing insights from a longitudinal industry case study. Over 12 months, we observed and analysed the internal activities of AstraZeneca, a biopharmaceutical company, as it prepared for and underwent an ethicsbased AI audit. While previous literature concerning EBA has focussed on proposing or analysing evaluation metrics or visualisation techniques, our findings suggest that the main difficulties large multinational organisations face when conducting EBA mirror classical governance challenges. These include ensuring harmonised standards across decentralised organisations, demarcating the scope of the audit, driving internal communication and change management, and measuring actual outcomes. The case study presented in this article contributes to the existing literature by providing a detailed description of the organisational context in which EBA procedures must be integrated to be feasible and effective.},
539 doi = {10.1007/s43681-022-00171-7},
540 url = {https://link.springer.com/10.1007/s43681-022-00171-7},
541 shorttitle = {Operationalising {AI} governance through ethics-based auditing},
542 issn = {2730-5953, 2730-5961},
543 title = {Operationalising {AI} governance through ethics-based auditing: an industry case study},
544}
545
546@techreport{information_commisioners_office_guidance_2022,
547 pages = {105},
548 year = {2022},
549 month = {November},
550 author = {{Information Commisioner's Office}},
551 institution = {Information Commisioner's Office},
552 urldate = {2022-11-04},
553 number = {20200214},
554 language = {en},
555 url = {https://ico.org.uk/media/2617219/guidance-on-the-ai-auditing-framework-draft-for-consultation.pdf},
556 title = {Guidance on the {AI} auditing framework {Draft} guidance for consultation},
557}
558
559@misc{office_of_the_director_of_national_intelligence_artificial_2022,
560 year = {2022},
561 month = {November},
562 author = {{Office of the Director of National Intelligence}},
563 publisher = {Office of the Director of National Intelligence},
564 urldate = {2022-11-04},
565 url = {https://www.intelligence.gov/images/AI/AI_Ethics_Framework_for_the_Intelligence_Community_1.0.pdf},
566 title = {Artificial {Intelligence} {Ethics} {Framework} for the {Intelligence} {Community}},
567}
568
569@misc{ibm_ai_2022,
570 year = {2022},
571 month = {November},
572 author = {{IBM}},
573 urldate = {2022-11-05},
574 language = {en-us},
575 abstract = {IBM’s multidisciplinary, multidimensional approach to AI ethics.},
576 url = {https://www.ibm.com/artificial-intelligence/ethics},
577 title = {{AI} {Ethics}},
578}
579
580@misc{google_building_2022,
581 year = {2022},
582 month = {November},
583 author = {{Google}},
584 journal = {Google AI},
585 urldate = {2022-11-05},
586 language = {en},
587 url = {https://ai.google/responsibilities/},
588 title = {Building responsible {AI} for everyone},
589}
590
591@misc{hosseini_deceiving_2017,
592 keywords = {Computer Science - Computers and Society, Computer Science - Machine Learning, Computer Science - Social and Information Networks},
593 note = {arXiv:1702.08138 [cs]},
594 year = {2017},
595 month = {February},
596 author = {Hosseini, Hossein and Kannan, Sreeram and Zhang, Baosen and Poovendran, Radha},
597 publisher = {arXiv},
598 urldate = {2022-10-31},
599 language = {en},
600 abstract = {Social media platforms provide an environment where people can freely engage in discussions. Unfortunately, they also enable several problems, such as online harassment. Recently, Google and Jigsaw started a project called Perspective, which uses machine learning to automatically detect toxic language. A demonstration website has been also launched, which allows anyone to type a phrase in the interface and instantaneously see the toxicity score [1].},
601 url = {http://arxiv.org/abs/1702.08138},
602 title = {Deceiving {Google}'s {Perspective} {API} {Built} for {Detecting} {Toxic} {Comments}},
603}
604
605@article{buslaev_albumentations_2020,
606 year = {2020},
607 author = {Buslaev, Alexander and Iglovikov, Vladimir I. and Khvedchenya, Eugene and Parinov, Alex and Druzhinin, Mikhail and Kalinin, Alexandr A.},
608 journal = {Information},
609 number = {2},
610 doi = {10.3390/info11020125},
611 url = {https://www.mdpi.com/2078-2489/11/2/125},
612 issn = {2078-2489},
613 volume = {11},
614 title = {Albumentations: {Fast} and {Flexible} {Image} {Augmentations}},
615}
616
617@inproceedings{blum_ladder_2015,
618 pages = {1006--1014},
619 year = {2015},
620 author = {Blum, Avrim and Hardt, Moritz},
621 publisher = {PMLR},
622 booktitle = {International {Conference} on {Machine} {Learning}},
623 shorttitle = {The ladder},
624 title = {The ladder: {A} reliable leaderboard for machine learning competitions},
625}
626
627@article{damour_underspecification_2020,
628 year = {2020},
629 author = {D'Amour, Alexander and Heller, Katherine and Moldovan, Dan and Adlam, Ben and Alipanahi, Babak and Beutel, Alex and Chen, Christina and Deaton, Jonathan and Eisenstein, Jacob and Hoffman, Matthew D and {others}},
630 journal = {arXiv preprint arXiv:2011.03395},
631 title = {Underspecification presents challenges for credibility in modern machine learning},
632}
633
634@article{deng_imagenet_2009,
635 pages = {8},
636 year = {2009},
637 author = {Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
638 journal = {IEEE Conference on Computer Vision and Pattern Recognition},
639 language = {en},
640 abstract = {The explosion of image data on the Internet has the potential to foster more sophisticated and robust models and algorithms to index, retrieve, organize and interact with images and multimedia data. But exactly how such data can be harnessed and organized remains a critical problem. We introduce here a new database called “ImageNet”, a largescale ontology of images built upon the backbone of the WordNet structure. ImageNet aims to populate the majority of the 80,000 synsets of WordNet with an average of 5001000 clean and full resolution images. This will result in tens of millions of annotated images organized by the semantic hierarchy of WordNet. This paper offers a detailed analysis of ImageNet in its current state: 12 subtrees with 5247 synsets and 3.2 million images in total. We show that ImageNet is much larger in scale and diversity and much more accurate than the current image datasets. Constructing such a large-scale database is a challenging task. We describe the data collection scheme with Amazon Mechanical Turk. Lastly, we illustrate the usefulness of ImageNet through three simple applications in object recognition, image classification and automatic object clustering. We hope that the scale, accuracy, diversity and hierarchical structure of ImageNet can offer unparalleled opportunities to researchers in the computer vision community and beyond.},
641 title = {{ImageNet}: {A} {Large}-{Scale} {Hierarchical} {Image} {Database}},
642}
643
644@misc{tencent_keen_security_lab_experimental_2019,
645 year = {2019},
646 month = {March},
647 author = {Tencent Keen Security Lab},
648 publisher = {Tencent},
649 url = {https://keenlab.tencent.com/en/whitepapers/Experimental_Security_Research_of_Tesla_Autopilot.pdf},
650 title = {Experimental security research of {Tesla} autopilot},
651}
652
653@inproceedings{peng_mitigating_2021,
654 keywords = {Computer Science - Computers and Society, Computer Science - Machine Learning},
655 note = {arXiv:2108.02922 [cs]},
656 year = {2021},
657 month = {November},
658 author = {Peng, Kenny and Mathur, Arunesh and Narayanan, Arvind},
659 publisher = {arXiv},
660 booktitle = {Advances in {Neural} {Information} {Processing} {Systems} ({NeurIPS})},
661 urldate = {2022-10-23},
662 language = {en},
663 abstract = {Machine learning datasets have elicited concerns about privacy, bias, and unethical applications, leading to the retraction of prominent datasets such as DukeMTMC, MS-Celeb-1M, and Tiny Images. In response, the machine learning community has called for higher ethical standards in dataset creation. To help inform these efforts, we studied three influential but ethically problematic face and person recognition datasets—Labeled Faces in the Wild (LFW), MS-Celeb-1M, and DukeMTMC—by analyzing nearly 1000 papers that cite them. We found that the creation of derivative datasets and models, broader technological and social change, the lack of clarity of licenses, and dataset management practices can introduce a wide range of ethical concerns. We conclude by suggesting a distributed approach to harm mitigation that considers the entire life cycle of a dataset.},
664 url = {http://arxiv.org/abs/2108.02922},
665 shorttitle = {Mitigating dataset harms requires stewardship},
666 title = {Mitigating dataset harms requires stewardship: {Lessons} from 1000 papers},
667}
668
669@book{barocas_fairness_2019,
670 year = {2019},
671 author = {Barocas, Solon and Hardt, Moritz and Narayanan, Arvind},
672 publisher = {fairmlbook.org},
673 url = {https://fairmlbook.org/},
674 title = {Fairness and machine learning},
675}
676
677@inproceedings{lee_landscape_2021,
678 pages = {1--13},
679 year = {2021},
680 author = {Lee, Michelle Seng Ah and Singh, Jat},
681 booktitle = {Proceedings of the 2021 {CHI} conference on human factors in computing systems},
682 title = {The landscape and gaps in open source fairness toolkits},
683}
684
685@article{saleiro_aequitas_2018,
686 year = {2018},
687 author = {Saleiro, Pedro and Kuester, Benedict and Hinkson, Loren and London, Jesse and Stevens, Abby and Anisfeld, Ari and Rodolfa, Kit T. and Ghani, Rayid},
688 journal = {arXiv preprint arXiv:1811.05577},
689 shorttitle = {Aequitas},
690 title = {Aequitas: {A} bias and fairness audit toolkit},
691}
692
693@article{bellamy_ai_2019,
694 pages = {4--1},
695 note = {Publisher: IBM},
696 year = {2019},
697 author = {Bellamy, Rachel KE and Dey, Kuntal and Hind, Michael and Hoffman, Samuel C. and Houde, Stephanie and Kannan, Kalapriya and Lohia, Pranay and Martino, Jacquelyn and Mehta, Sameep and Mojsilović, Aleksandra},
698 journal = {IBM Journal of Research and Development},
699 number = {4/5},
700 shorttitle = {{AI} {Fairness} 360},
701 volume = {63},
702 title = {{AI} {Fairness} 360: {An} extensible toolkit for detecting and mitigating algorithmic bias},
703}
704
705@article{ntoutsi_bias_2020,
706 pages = {e1356},
707 keywords = {fairness, fairness-aware AI, fairness-aware machine learning, interpretability, responsible AI},
708 note = {\_eprint: https://onlinelibrary.wiley.com/doi/pdf/10.1002/widm.1356},
709 year = {2020},
710 author = {Ntoutsi, Eirini and Fafalios, Pavlos and Gadiraju, Ujwal and Iosifidis, Vasileios and Nejdl, Wolfgang and Vidal, Maria-Esther and Ruggieri, Salvatore and Turini, Franco and Papadopoulos, Symeon and Krasanakis, Emmanouil and Kompatsiaris, Ioannis and Kinder-Kurlanda, Katharina and Wagner, Claudia and Karimi, Fariba and Fernandez, Miriam and Alani, Harith and Berendt, Bettina and Kruegel, Tina and Heinze, Christian and Broelemann, Klaus and Kasneci, Gjergji and Tiropanis, Thanassis and Staab, Steffen},
711 journal = {WIREs Data Mining and Knowledge Discovery},
712 urldate = {2022-10-22},
713 number = {3},
714 language = {en},
715 abstract = {Artificial Intelligence (AI)-based systems are widely employed nowadays to make decisions that have far-reaching impact on individuals and society. Their decisions might affect everyone, everywhere, and anytime, entailing concerns about potential human rights issues. Therefore, it is necessary to move beyond traditional AI algorithms optimized for predictive performance and embed ethical and legal principles in their design, training, and deployment to ensure social good while still benefiting from the huge potential of the AI technology. The goal of this survey is to provide a broad multidisciplinary overview of the area of bias in AI systems, focusing on technical challenges and solutions as well as to suggest new research directions towards approaches well-grounded in a legal frame. In this survey, we focus on data-driven AI, as a large part of AI is powered nowadays by (big) data and powerful machine learning algorithms. If otherwise not specified, we use the general term bias to describe problems related to the gathering or processing of data that might result in prejudiced decisions on the bases of demographic features such as race, sex, and so forth. This article is categorized under: Commercial, Legal, and Ethical Issues {\textgreater} Fairness in Data Mining Commercial, Legal, and Ethical Issues {\textgreater} Ethical Considerations Commercial, Legal, and Ethical Issues {\textgreater} Legal Issues},
716 doi = {10.1002/widm.1356},
717 url = {https://onlinelibrary.wiley.com/doi/abs/10.1002/widm.1356},
718 issn = {1942-4795},
719 volume = {10},
720 title = {Bias in data-driven artificial intelligence systems—{An} introductory survey},
721}
722
723@article{mehrabi_survey_2021,
724 pages = {1--35},
725 note = {Publisher: ACM New York, NY, USA},
726 year = {2021},
727 author = {Mehrabi, Ninareh and Morstatter, Fred and Saxena, Nripsuta and Lerman, Kristina and Galstyan, Aram},
728 journal = {ACM Computing Surveys (CSUR)},
729 number = {6},
730 volume = {54},
731 title = {A survey on bias and fairness in machine learning},
732}
733
734@inproceedings{suresh_framework_2021,
735 pages = {1--9},
736 year = {2021},
737 month = {October},
738 author = {Suresh, Harini and Guttag, John},
739 publisher = {ACM},
740 booktitle = {Equity and {Access} in {Algorithms}, {Mechanisms}, and {Optimization}},
741 urldate = {2022-10-22},
742 language = {en},
743 doi = {10.1145/3465416.3483305},
744 url = {https://dl.acm.org/doi/10.1145/3465416.3483305},
745 isbn = {978-1-4503-8553-4},
746 title = {A {Framework} for {Understanding} {Sources} of {Harm} throughout the {Machine} {Learning} {Life} {Cycle}},
747 address = {-- NY USA},
748}
749
750@article{zendel_how_2017,
751 pages = {95--109},
752 keywords = {Hazard analysis, Safety analysis, Stereo vision, Test data, Testing, Validation},
753 year = {2017},
754 month = {December},
755 author = {Zendel, Oliver and Murschitz, Markus and Humenberger, Martin and Herzner, Wolfgang},
756 journal = {International Journal of Computer Vision},
757 urldate = {2022-10-22},
758 number = {1},
759 language = {en},
760 abstract = {Good test data is crucial for driving new developments in computer vision (CV), but two questions remain unanswered: which situations should be covered by the test data, and how much testing is enough to reach a conclusion? In this paper we propose a new answer to these questions using a standard procedure devised by the safety community to validate complex systems: the hazard and operability analysis (HAZOP). It is designed to systematically identify possible causes of system failure or performance loss. We introduce a generic CV model that creates the basis for the hazard analysis and—for the first time—apply an extensive HAZOP to the CV domain. The result is a publicly available checklist with more than 900 identified individual hazards. This checklist can be utilized to evaluate existing test datasets by quantifying the covered hazards. We evaluate our approach by first analyzing and annotating the popular stereo vision test datasets Middlebury and KITTI. Second, we demonstrate a clearly negative influence of the hazards in the checklist on the performance of six popular stereo matching algorithms. The presented approach is a useful tool to evaluate and improve test datasets and creates a common basis for future dataset designs.},
761 doi = {10.1007/s11263-017-1020-z},
762 url = {https://doi.org/10.1007/s11263-017-1020-z},
763 shorttitle = {How good is my test data?},
764 issn = {1573-1405},
765 volume = {125},
766 title = {How good is my test data? {Introducing} safety analysis for computer vision},
767}
768
769@misc{van_etten_spacenet_2019,
770 keywords = {Computer Science - Computer Vision and Pattern Recognition},
771 note = {arXiv:1807.01232 [cs]},
772 year = {2019},
773 month = {July},
774 author = {Van Etten, Adam and Lindenbaum, Dave and Bacastow, Todd M.},
775 publisher = {arXiv},
776 urldate = {2022-10-21},
777 abstract = {Foundational mapping remains a challenge in many parts of the world, particularly in dynamic scenarios such as natural disasters when timely updates are critical. Updating maps is currently a highly manual process requiring a large number of human labelers to either create features or rigorously validate automated outputs. We propose that the frequent revisits of earth imaging satellite constellations may accelerate existing efforts to quickly update foundational maps when combined with advanced machine learning techniques. Accordingly, the SpaceNet partners (CosmiQ Works, Radiant Solutions, and NVIDIA), released a large corpus of labeled satellite imagery on Amazon Web Services (AWS) called SpaceNet. The SpaceNet partners also launched a series of public prize competitions to encourage improvement of remote sensing machine learning algorithms. The first two of these competitions focused on automated building footprint extraction, and the most recent challenge focused on road network extraction. In this paper we discuss the SpaceNet imagery, labels, evaluation metrics, prize challenge results to date, and future plans for the SpaceNet challenge series.},
778 url = {http://arxiv.org/abs/1807.01232},
779 shorttitle = {{SpaceNet}},
780 title = {{SpaceNet}: {A} {Remote} {Sensing} {Dataset} and {Challenge} {Series}},
781}
782
783@misc{andrea_brennen_ai_2022,
784 year = {2022},
785 month = {January},
786 author = {{Andrea Brennen} and {Ryan Ashley}},
787 journal = {In-Q-Tel},
788 urldate = {2022-10-21},
789 language = {en-US},
790 abstract = {IQT Labs recently audited an open-source deep learning tool called FakeFinder that predicts whether or not a video is a […]},
791 url = {https://www.iqt.org/ai-assurance-what-happened-when-we-audited-a-deepfake-detection-tool-called-fakefinder/},
792 shorttitle = {{AI} {Assurance}},
793 title = {{AI} {Assurance}: {What} happened when we audited a deepfake detection tool called {FakeFinder}},
794}
795
796@article{dolhansky_deepfake_2019,
797 year = {2019},
798 author = {Dolhansky, B. and Bitton, J. and Pflaum, B. and Lu, J. and Howes, R. and Wang, M. and Ferrer, C. Canton},
799 journal = {arXiv e-prints},
800 title = {The {DeepFake} {Detection} {Challenge} ({DFDC}) {Dataset}},
801}
802
803@misc{leibowicz_deepfake_2021,
804 keywords = {Computer Science - Computer Vision and Pattern Recognition, Computer Science - Computers and Society, Computer Science - Machine Learning},
805 note = {arXiv:2102.06109 [cs]},
806 year = {2021},
807 month = {February},
808 author = {Leibowicz, Claire and McGregor, Sean and Ovadya, Aviv},
809 publisher = {arXiv},
810 urldate = {2022-10-21},
811 abstract = {Synthetic media detection technologies label media as either synthetic or non-synthetic and are increasingly used by journalists, web platforms, and the general public to identify misinformation and other forms of problematic content. As both well-resourced organizations and the non-technical general public generate more sophisticated synthetic media, the capacity for purveyors of problematic content to adapt induces a {\textbackslash}newterm\{detection dilemma\}: as detection practices become more accessible, they become more easily circumvented. This paper describes how a multistakeholder cohort from academia, technology platforms, media entities, and civil society organizations active in synthetic media detection and its socio-technical implications evaluates the detection dilemma. Specifically, we offer an assessment of detection contexts and adversary capacities sourced from the broader, global AI and media integrity community concerned with mitigating the spread of harmful synthetic media. A collection of personas illustrates the intersection between unsophisticated and highly-resourced sponsors of misinformation in the context of their technical capacities. This work concludes that there is no "best" approach to navigating the detector dilemma, but derives a set of implications from multistakeholder input to better inform detection process decisions and policies, in practice.},
812 url = {http://arxiv.org/abs/2102.06109},
813 shorttitle = {The {Deepfake} {Detection} {Dilemma}},
814 title = {The {Deepfake} {Detection} {Dilemma}: {A} {Multistakeholder} {Exploration} of {Adversarial} {Dynamics} in {Synthetic} {Media}},
815}
816
817@misc{robert_stojnic_papers_2022,
818 year = {2022},
819 month = {October},
820 author = {{Robert Stojnic} and {Taylor, Ross} and {Kardas, Marcin} and {Scialom, Scialom}},
821 journal = {Papers with Code},
822 urldate = {2022-10-21},
823 language = {en},
824 abstract = {The current state-of-the-art on ImageNet is CoCa (finetuned). See a full comparison of 756 papers with code.},
825 url = {https://paperswithcode.com/sota/image-classification-on-imagenet},
826 title = {Papers with {Code} - {ImageNet} {Benchmark} ({Image} {Classification})},
827}
828
829@misc{munroe_tasks_2014,
830 year = {2014},
831 month = {September},
832 author = {Munroe, Randall},
833 journal = {xkcd},
834 urldate = {2022-10-21},
835 url = {https://xkcd.com/1425/},
836 title = {Tasks},
837}
838
839@misc{simonite_why_2015,
840 year = {2015},
841 month = {June},
842 author = {Simonite, Tom},
843 journal = {MIT Technology Review},
844 urldate = {2022-10-21},
845 language = {en},
846 abstract = {Machine learning gets its first cheating scandal.},
847 url = {https://www.technologyreview.com/2015/06/04/72951/why-and-how-baidu-cheated-an-artificial-intelligence-test/},
848 title = {Why and {How} {Baidu} {Cheated} an {Artificial} {Intelligence} {Test}},
849}
850
851@inproceedings{krizhevsky_imagenet_2012,
852 pages = {1097--1105},
853 note = {event-place: Lake Tahoe, Nevada},
854 year = {2012},
855 author = {Krizhevsky, Alex and Sutskever, Ilya and Hinton, Geoffrey E.},
856 publisher = {Curran Associates Inc.},
857 booktitle = {Proceedings of the 25th {International} {Conference} on {Neural} {Information} {Processing} {Systems} - {Volume} 1},
858 abstract = {We trained a large, deep convolutional neural network to classify the 1.2 million high-resolution images in the ImageNet LSVRC-2010 contest into the 1000 different classes. On the test data, we achieved top-1 and top-5 error rates of 37.5\% and 17.0\% which is considerably better than the previous state-of-the-art. The neural network, which has 60 million parameters and 650,000 neurons, consists of five convolutional layers, some of which are followed by max-pooling layers, and three fully-connected layers with a final 1000-way softmax. To make training faster, we used non-saturating neurons and a very efficient GPU implementation of the convolution operation. To reduce overriding in the fully-connected layers we employed a recently-developed regularization method called "dropout" that proved to be very effective. We also entered a variant of this model in the ILSVRC-2012 competition and achieved a winning top-5 test error rate of 15.3\%, compared to 26.2\% achieved by the second-best entry.},
859 title = {{ImageNet} {Classification} with {Deep} {Convolutional} {Neural} {Networks}},
860 series = {{NIPS}'12},
861 address = {Red Hook, NY, USA},
862}
863
864@misc{noauthor_experimental_security_research_of_tesla_autopilotpdf_nodate,
865 urldate = {2022-10-21},
866 url = {https://keenlab.tencent.com/en/whitepapers/Experimental_Security_Research_of_Tesla_Autopilot.pdf},
867 title = {Experimental\_Security\_Research\_of\_Tesla\_Autopilot.pdf},
868}
869
870@misc{floridi_capai_2022,
871 keywords = {AI, AI Act, AI Auditing, AI legislation, Conformity Assessment, EU, Trustworthy AI},
872 year = {2022},
873 month = {March},
874 author = {Floridi, Luciano and Holweg, Matthias and Taddeo, Mariarosaria and Amaya Silva, Javier and Mökander, Jakob and Wen, Yuni},
875 urldate = {2022-10-21},
876 language = {en},
877 abstract = {We have developed capAI, a conformity assessment procedure for AI systems, to provide an independent, comparable, quantifiable, and accountable assessment of AI systems that conforms with the proposed AIA regulation. By building on the AIA, capAI provides organisations with practical guidance on how high-level ethics principles can be translated into verifiable criteria that help shape the design, development, deployment and use of ethical AI. The main purpose of capAI is to serve as a governance tool that ensures and demonstrates that the development and operation of an AI system are trustworthy – i.e., legally compliant, ethically sound, and technically robust – and thus conform to the AIA.},
878 doi = {10.2139/ssrn.4064091},
879 url = {https://papers.ssrn.com/abstract=4064091},
880 title = {{capAI} - {A} procedure for conducting conformity assessment of {AI} systems in line with the {EU} {Artificial} {Intelligence} {Act}},
881 type = {{SSRN} {Scholarly} {Paper}},
882 address = {Rochester, NY},
883}
884
885@article{varoquaux_machine_2022,
886 pages = {1--8},
887 keywords = {Computer science, Medical research, Research data, ai/medicine, ai/testing},
888 note = {Number: 1
889Publisher: Nature Publishing Group},
890 year = {2022},
891 month = {April},
892 author = {Varoquaux, Gaël and Cheplygina, Veronika},
893 journal = {npj Digital Medicine},
894 urldate = {2022-10-21},
895 number = {1},
896 language = {en},
897 abstract = {Research in computer analysis of medical images bears many promises to improve patients’ health. However, a number of systematic challenges are slowing down the progress of the field, from limitations of the data, such as biases, to research incentives, such as optimizing for publication. In this paper we review roadblocks to developing and assessing methods. Building our analysis on evidence from the literature and data challenges, we show that at every step, potential biases can creep in. On a positive note, we also discuss on-going efforts to counteract these problems. Finally we provide recommendations on how to further address these problems in the future.},
898 doi = {10.1038/s41746-022-00592-y},
899 url = {https://www.nature.com/articles/s41746-022-00592-y},
900 shorttitle = {Machine learning for medical imaging},
901 issn = {2398-6352},
902 copyright = {2022 The Author(s)},
903 volume = {5},
904 title = {Machine learning for medical imaging: {Methodological} failures and recommendations for the future},
905}
906
907@inproceedings{wang_towards_2020,
908 pages = {8916--8925},
909 keywords = {ai/fairness, ai/vision},
910 year = {2020},
911 month = {June},
912 author = {Wang, Zeyu and Qinami, Klint and Karakozis, Ioannis Christos and Genova, Kyle and Nair, Prem and Hata, Kenji and Russakovsky, Olga},
913 publisher = {IEEE},
914 booktitle = {2020 {IEEE}/{CVF} {Conference} on {Computer} {Vision} and {Pattern} {Recognition} ({CVPR})},
915 urldate = {2022-10-20},
916 language = {en},
917 abstract = {Computer vision models learn to perform a task by capturing relevant statistics from training data. It has been shown that models learn spurious age, gender, and race correlations when trained for seemingly unrelated tasks like activity recognition or image captioning. Various mitigation techniques have been presented to prevent models from utilizing or learning such biases. However, there has been little systematic comparison between these techniques. We design a simple but surprisingly effective visual recognition benchmark for studying bias mitigation. Using this benchmark, we provide a thorough analysis of a wide range of techniques. We highlight the shortcomings of popular adversarial training approaches for bias mitigation, propose a simple but similarly effective alternative to the inference-time Reducing Bias Amplification method of Zhao et al., and design a domain-independent training technique that outperforms all other methods. Finally, we validate our findings on the attribute classification task in the CelebA dataset, where attribute presence is known to be correlated with the gender of people in the image, and demonstrate that the proposed technique is effective at mitigating real-world gender bias.},
918 doi = {10.1109/CVPR42600.2020.00894},
919 url = {https://ieeexplore.ieee.org/document/9156668/},
920 shorttitle = {Towards {Fairness} in {Visual} {Recognition}},
921 isbn = {978-1-72817-168-5},
922 title = {Towards {Fairness} in {Visual} {Recognition}: {Effective} {Strategies} for {Bias} {Mitigation}},
923 address = {Seattle, WA, USA},
924}
925
926@inproceedings{hendrycks_deep_2019,
927 pages = {18},
928 keywords = {ai/open-world, ai/trust},
929 year = {2019},
930 author = {Hendrycks, Dan and Mazeika, Mantas and Dietterich, Thomas},
931 booktitle = {International {Conference} on {Learning} {Representations} ({ICLR})},
932 language = {en},
933 abstract = {It is important to detect anomalous inputs when deploying machine learning systems. The use of larger and more complex inputs in deep learning magnifies the difficulty of distinguishing between anomalous and in-distribution examples. At the same time, diverse image and text data are available in enormous quantities. We propose leveraging these data to improve deep anomaly detection by training anomaly detectors against an auxiliary dataset of outliers, an approach we call Outlier Exposure (OE). This enables anomaly detectors to generalize and detect unseen anomalies. In extensive experiments on natural language processing and small- and large-scale vision tasks, we find that Outlier Exposure significantly improves detection performance. We also observe that cutting-edge generative models trained on CIFAR-10 may assign higher likelihoods to SVHN images than to CIFAR-10 images; we use OE to mitigate this issue. We also analyze the flexibility and robustness of Outlier Exposure, and identify characteristics of the auxiliary dataset that improve performance.},
934 title = {Deep {Anomaly} {Detection} with {Outlier} {Exposure}},
935}
936
937@inproceedings{ribeiro_beyond_2020,
938 pages = {4902--4912},
939 keywords = {ai/nlp, ai/testing},
940 year = {2020},
941 author = {Ribeiro, Marco Tulio and Wu, Tongshuang and Guestrin, Carlos and Singh, Sameer},
942 publisher = {Association for Computational Linguistics},
943 booktitle = {Proceedings of the 58th {Annual} {Meeting} of the {Association} for {Computational} {Linguistics}},
944 urldate = {2022-10-13},
945 language = {en},
946 abstract = {Although measuring held-out accuracy has been the primary approach to evaluate generalization, it often overestimates the performance of NLP models, while alternative approaches for evaluating models either focus on individual tasks or on specific behaviors. Inspired by principles of behavioral testing in software engineering, we introduce CheckList, a taskagnostic methodology for testing NLP models. CheckList includes a matrix of general linguistic capabilities and test types that facilitate comprehensive test ideation, as well as a software tool to generate a large and diverse number of test cases quickly. We illustrate the utility of CheckList with tests for three tasks, identifying critical failures in both commercial and state-of-art models. In a user study, a team responsible for a commercial sentiment analysis model found new and actionable bugs in an extensively tested model. In another user study, NLP practitioners with CheckList created twice as many tests, and found almost three times as many bugs as users without it.},
947 doi = {10.18653/v1/2020.acl-main.442},
948 url = {https://www.aclweb.org/anthology/2020.acl-main.442},
949 shorttitle = {Beyond {Accuracy}},
950 title = {Beyond {Accuracy}: {Behavioral} {Testing} of {NLP} {Models} with {CheckList}},
951 address = {Online},
952}
953
954@misc{denton_bringing_2020,
955 note = {arXiv:2007.07399 [cs]},
956 year = {2020},
957 month = {July},
958 author = {Denton, Emily and Hanna, Alex and Amironesei, Razvan and Smart, Andrew and Nicole, Hilary and Scheuerman, Morgan Klaus},
959 publisher = {arXiv},
960 urldate = {2022-10-07},
961 abstract = {In response to algorithmic unfairness embedded in sociotechnical systems, significant attention has been focused on the contents of machine learning datasets which have revealed biases towards white, cisgender, male, and Western data subjects. In contrast, comparatively less attention has been paid to the histories, values, and norms embedded in such datasets. In this work, we outline a research program - a genealogy of machine learning data - for investigating how and why these datasets have been created, what and whose values influence the choices of data to collect, the contextual and contingent conditions of their creation. We describe the ways in which benchmark datasets in machine learning operate as infrastructure and pose four research questions for these datasets. This interrogation forces us to "bring the people back in" by aiding us in understanding the labor embedded in dataset construction, and thereby presenting new avenues of contestation for other researchers encountering the data.},
962 url = {http://arxiv.org/abs/2007.07399},
963 shorttitle = {Bringing the people back in},
964 title = {Bringing the people back in: {Contesting} benchmark machine learning datasets},
965}
966
967@misc{beyer_are_2020,
968 note = {arXiv:2006.07159 [cs]},
969 year = {2020},
970 month = {June},
971 author = {Beyer, Lucas and Hénaff, Olivier J. and Kolesnikov, Alexander and Zhai, Xiaohua and Oord, Aäron van den},
972 publisher = {arXiv},
973 urldate = {2022-10-10},
974 language = {en},
975 abstract = {Yes, and no. We ask whether recent progress on the ImageNet classification benchmark continues to represent meaningful generalization, or whether the community has started to overfit to the idiosyncrasies of its labeling procedure. We therefore develop a significantly more robust procedure for collecting human annotations of the ImageNet validation set. Using these new labels, we reassess the accuracy of recently proposed ImageNet classifiers, and find their gains to be substantially smaller than those reported on the original labels. Furthermore, we find the original ImageNet labels to no longer be the best predictors of this independently-collected set, indicating that their usefulness in evaluating vision models may be nearing an end. Nevertheless, we find our annotation procedure to have largely remedied the errors in the original labels, reinforcing ImageNet as a powerful benchmark for future research in visual recognition3.},
976 url = {http://arxiv.org/abs/2006.07159},
977 title = {Are we done with {ImageNet}?},
978}
979
980@inproceedings{cubuk_randaugment_2020,
981 pages = {702--703},
982 keywords = {ai/data-augmentation},
983 year = {2020},
984 author = {Cubuk, Ekin D. and Zoph, Barret and Shlens, Jonathon and Le, Quoc V.},
985 booktitle = {Proceedings of the {IEEE}/{CVF} conference on computer vision and pattern recognition workshops},
986 shorttitle = {Randaugment},
987 title = {Randaugment: {Practical} automated data augmentation with a reduced search space},
988}
989
990@inproceedings{koh_wilds_2021,
991 pages = {5637--5664},
992 keywords = {ai/datasets, ai/domain-shift},
993 year = {2021},
994 author = {Koh, Pang Wei and Sagawa, Shiori and Marklund, Henrik and Xie, Sang Michael and Zhang, Marvin and Balsubramani, Akshay and Hu, Weihua and Yasunaga, Michihiro and Phillips, Richard Lanas and Gao, Irena and Lee, Tony and David, Etienne and Stavness, Ian and Guo, Wei and Earnshaw, Berton A. and Haque, Imran S. and Beery, Sara and Leskovec, Jure and Kundaje, Anshul and Pierson, Emma and Levine, Sergey and Finn, Chelsea and Liang, Percy},
995 publisher = {PMLR},
996 booktitle = {International {Conference} on {Machine} {Learning} ({ICML})},
997 shorttitle = {Wilds},
998 title = {Wilds: {A} benchmark of in-the-wild distribution shifts},
999}
1000
1001@inproceedings{mcgregor_preventing_2021,
1002 pages = {15458--15463},
1003 note = {Issue: 17},
1004 year = {2021},
1005 author = {McGregor, Sean},
1006 booktitle = {{AAAI} {Conference} on {Artificial} {Intelligence}},
1007 shorttitle = {Preventing repeated real world {AI} failures by cataloging incidents},
1008 volume = {35},
1009 title = {Preventing repeated real world {AI} failures by cataloging incidents: {The} {AI} {Incident} {Database}},
1010}
1011
1012@techreport{david_defense_2016,
1013 keywords = {ai/audit, ai/trust, government},
1014 note = {Section: Technical Reports},
1015 year = {2016},
1016 month = {June},
1017 author = {David, Ruth A. and Nielsen, Paul},
1018 urldate = {2022-10-06},
1019 number = {AD1017790},
1020 language = {en},
1021 abstract = {At the request of the Under Secretary of Defense for Acquisition, Technology, and Logistics USDAT and L, the Defense Science Board DSB conducted a study on the applicability of autonomy to Department of Defense DoD missions. The study concluded that there are both substantial operational benefits and potential perils associated with the use of autonomy. Autonomy delivers significant military value, including opportunities to reduce the number of warfighters in harms way, increase the quality and speed of decisions in time-critical operations, and enable new missions that would otherwise be impossible. Autonomy is by no means new to the DoD. Fielded capabilities demonstrate ongoing progress in embedding autonomous functionality into systems, and many development programs already underway include an increasingly sophisticated use of autonomy. Autonomy also delivers significant value across a diverse array of global markets. Both enabling technologies and commercial applications are advancing rapidly in response to market opportunities. Autonomy is becoming a ubiquitous enabling capability for products spanning a spectrum from expert advisory systems to autonomous vehicles. Commercial market forces are accelerating progress, providing opportunities for DoD to leverage the investments of others, while also providing substantial capabilities to potential adversaries. This study concluded that DoD must accelerate its exploitation of autonomy both to realize the potential military value and to remain ahead of adversaries who also will exploit its operational benefits.},
1022 url = {https://apps.dtic.mil/sti/citations/AD1017790},
1023 title = {Defense {Science} {Board} summer study on autonomy},
1024}
1025
1026@article{noauthor_executive_2019,
1027 pages = {3967--3972},
1028 keywords = {ai/trust, government},
1029 year = {2019},
1030 month = {February},
1031 journal = {Federal Register},
1032 number = {31},
1033 url = {https://www.federalregister.gov/documents/2019/02/14/2019-02544/maintaining-american-leadership-in-artificial-intelligence},
1034 volume = {84},
1035 title = {Executive {Order} 13859. {Maintaining} {American} leadership in artificial intelligence.},
1036}
1037
1038@inproceedings{zhou_non-vacuous_2019,
1039 keywords = {Computer Science - Machine Learning, Statistics - Machine Learning},
1040 note = {arXiv:1804.05862 [cs, stat]},
1041 year = {2019},
1042 month = {February},
1043 author = {Zhou, Wenda and Veitch, Victor and Austern, Morgane and Adams, Ryan P. and Orbanz, Peter},
1044 publisher = {arXiv},
1045 booktitle = {International {Conference} on {Learning} {Representations} ({ICLR})},
1046 urldate = {2022-10-10},
1047 language = {en},
1048 abstract = {Modern neural networks are highly overparameterized, with capacity to substantially overfit to training data. Nevertheless, these networks often generalize well in practice. It has also been observed that trained networks can often be “compressed” to much smaller representations. The purpose of this paper is to connect these two empirical observations. Our main technical result is a generalization bound for compressed networks based on the compressed size that, combined with off-theshelf compression algorithms, leads to state-of-the-art generalization guarantees. In particular, we provide the first non-vacuous generalization guarantees for realistic architectures applied to the ImageNet classification problem. Additionally, we show that compressibility of models that tend to overfit is limited. Empirical results show that an increase in overfitting increases the number of bits required to describe a trained network.},
1049 url = {http://arxiv.org/abs/1804.05862},
1050 shorttitle = {Non-vacuous generalization bounds at the imagenet scale},
1051 title = {Non-vacuous generalization bounds at the {ImageNet} scale: {A} {PAC}-{Bayesian} compression approach},
1052}
1053
1054@inproceedings{zhao_bias_2018,
1055 pages = {10},
1056 year = {2018},
1057 author = {Zhao, Shengjia and Ren, Hongyu and Yuan, Arianna and Song, Jiaming and Goodman, Noah and Ermon, Stefano},
1058 booktitle = {Advances in {Neural} {Information} {Processing} {Systems} ({NeurIPS})},
1059 language = {en},
1060 abstract = {In high dimensional settings, density estimation algorithms rely crucially on their inductive bias. Despite recent empirical success, the inductive bias of deep generative models is not well understood. In this paper we propose a framework to systematically investigate bias and generalization in deep generative models of images. Inspired by experimental methods from cognitive psychology, we probe each learning algorithm with carefully designed training datasets to characterize when and how existing models generate novel attributes and their combinations. We identify similarities to human psychology and verify that these patterns are consistent across commonly used models and architectures.},
1061 title = {Bias and generalization in deep generative models: {An} empirical study},
1062}
1063
1064@inproceedings{tsipras_imagenet_2020,
1065 pages = {11},
1066 year = {2020},
1067 author = {Tsipras, Dimitris and Santurkar, Shibani and Engstrom, Logan and Ilyas, Andrew and Ma, Aleksander},
1068 booktitle = {International {Conference} on {Machine} {Learning} ({ICML})},
1069 language = {en},
1070 abstract = {Building rich machine learning datasets in a scal-
1071able manner often necessitates a crowd-sourced
1072data collection pipeline. In this work, we use hu-
1073man studies to investigate the consequences of em-
1074ploying such a pipeline, focusing on the popular
1075ImageNet dataset. We study how specific design
1076choices in the ImageNet creation process impact
1077the fidelity of the resulting dataset—including the
1078introduction of biases that state-of-the-art models
1079exploit. Our analysis pinpoints how a noisy data
1080collection pipeline can lead to a systematic mis-
1081alignment between the resulting benchmark and
1082the real-world task it serves as a proxy for. Finally,
1083our findings emphasize the need to augment our
1084current model training and evaluation toolkit to
1085take such misalignments into account.},
1086 title = {From {ImageNet} to image classification: {Contextualizing} progress on benchmarks},
1087}
1088
1089@inproceedings{toneva_empirical_2019,
1090 keywords = {Computer Science - Machine Learning, Statistics - Machine Learning},
1091 note = {arXiv:1812.05159 [cs, stat]},
1092 year = {2019},
1093 author = {Toneva, Mariya and Sordoni, Alessandro and Combes, Remi Tachet des and Trischler, Adam and Bengio, Yoshua and Gordon, Geoffrey J.},
1094 publisher = {arXiv},
1095 booktitle = {International {Conference} on {Learning} {Representations} ({ICLR})},
1096 urldate = {2022-10-10},
1097 language = {en},
1098 abstract = {Inspired by the phenomenon of catastrophic forgetting, we investigate the learning dynamics of neural networks as they train on single classification tasks. Our goal is to understand whether a related phenomenon occurs when data does not undergo a clear distributional shift. We define a “forgetting event” to have occurred when an individual training example transitions from being classified correctly to incorrectly over the course of learning. Across several benchmark data sets, we find that: (i) certain examples are forgotten with high frequency, and some not at all; (ii) a data set’s (un)forgettable examples generalize across neural architectures; and (iii) based on forgetting dynamics, a significant fraction of examples can be omitted from the training data set while still maintaining state-of-the-art generalization performance.},
1099 url = {http://arxiv.org/abs/1812.05159},
1100 title = {An empirical study of example forgetting during deep neural network learning},
1101}
1102
1103@inproceedings{shankar_evaluating_2020,
1104 pages = {11},
1105 year = {2020},
1106 author = {Shankar, Vaishaal and Roelofs, Rebecca and Mania, Horia and Fang, Alex and Recht, Benjamin and Schmidt, Ludwig},
1107 booktitle = {International {Conference} on {Machine} {Learning} ({ICML})},
1108 language = {en},
1109 abstract = {We evaluate a wide range of ImageNet models with five trained human labelers. In our year-long experiment, trained humans first annotated 40,000 images from the ImageNet and ImageNetV2 test sets with multi-class labels to enable a semantically coherent evaluation. Then we measured the classification accuracy of the five trained humans on the full task with 1,000 classes. Only the latest models from 2020 are on par with our best human labeler, and human accuracy on the 590 object classes is still 4\% and 11\% higher than the best model on ImageNet and ImageNetV2, respectively. Moreover, humans achieve the same accuracy on ImageNet and ImageNetV2, while all models see a consistent accuracy drop. Overall, our results show that there is still substantial room for improvement on ImageNet and direct accuracy comparisons between humans and machines may overstate machine performance.},
1110 title = {Evaluating machine accuracy on {ImageNet}},
1111}
1112
1113@techreport{sayler_artificial_nodate,
1114 pages = {41},
1115 keywords = {ai/explainability, ai/trust, government},
1116 author = {Sayler, Kelley M},
1117 number = {R45178},
1118 language = {en},
1119 abstract = {Artificial intelligence (AI) is a rapidly growing field of technology with potentially significant implications for national security. As such, the U.S. Department of Defense (DOD) and other nations are developing AI applications for a range of military functions. AI research is underway in the fields of intelligence collection and analysis, logistics, cyber operations, information operations, command and control, and in a variety of semiautonomous and autonomous vehicles. Already, AI has been incorporated into military operations in Iraq and Syria. Congressional action has the potential to shape the technology’s development further, with budgetary and legislative decisions influencing the growth of military applications as well as the pace of their adoption.},
1120 url = {https://crsreports.congress.gov/product/pdf/R/R45178/5},
1121 title = {Artificial intelligence and national security},
1122}
1123
1124@inproceedings{minderer_revisiting_2021,
1125 pages = {13},
1126 year = {2021},
1127 author = {Minderer, Matthias and Djolonga, Josip and Romijnders, Rob and Hubis, Frances and Zhai, Xiaohua and Houlsby, Neil and Tran, Dustin and Lucic, Mario},
1128 booktitle = {Advances in {Neural} {Information} {Processing} {Systems} ({NeurIPS})},
1129 language = {en},
1130 abstract = {Accurate estimation of predictive uncertainty (model calibration) is essential for the safe application of neural networks. Many instances of miscalibration in modern neural networks have been reported, suggesting a trend that newer, more accurate models produce poorly calibrated predictions. Here, we revisit this question for recent state-of-the-art image classification models. We systematically relate model calibration and accuracy, and find that the most recent models, notably those not using convolutions, are among the best calibrated. Trends observed in prior model generations, such as decay of calibration with distribution shift or model size, are less pronounced in recent architectures. We also show that model size and amount of pretraining do not fully explain these differences, suggesting that architecture is a major determinant of calibration properties.},
1131 url = {https://proceedings.neurips.cc/paper/2021/file/8420d359404024567b5aefda1231af24-Paper.pdf},
1132 title = {Revisiting the calibration of modern neural networks},
1133}
1134
1135@inproceedings{kok_classification_2007,
1136 pages = {176--187},
1137 note = {ISSN: 0302-9743, 1611-3349
1138Series Title: Lecture Notes in Computer Science},
1139 doi = {10.1007/978-3-540-74976-9_19},
1140 year = {2007},
1141 editor = {Kok, Joost N. and Koronacki, Jacek and Lopez de Mantaras, Ramon and Matwin, Stan and Mladenič, Dunja and Skowron, Andrzej},
1142 author = {Kowalczyk, Adam},
1143 publisher = {Springer Berlin Heidelberg},
1144 booktitle = {Knowledge {Discovery} in {Databases} ({KDD})},
1145 urldate = {2022-10-10},
1146 language = {en},
1147 abstract = {We demonstrate a binary classification problem in which standard supervised learning algorithms such as linear and kernel SVM, naive Bayes, ridge regression, k-nearest neighbors, shrunken centroid, multilayer perceptron and decision trees perform in an unusual way. On certain data sets they classify a randomly sampled training subset nearly perfectly, but systematically perform worse than random guessing on cases unseen in training. We demonstrate this phenomenon in classification of a natural data set of cancer genomics microarrays using crossvalidation test. Additionally, we generate a range of synthetic datasets, the outcomes of 0-sum games, for which we analyse this phenomenon in the i.i.d. setting.},
1148 url = {http://link.springer.com/10.1007/978-3-540-74976-9_19},
1149 isbn = {978-3-540-74975-2 978-3-540-74976-9},
1150 volume = {4702},
1151 title = {Classification of anti-learnable biological and synthetic data},
1152 address = {Berlin, Heidelberg},
1153}
1154
1155@inproceedings{hardt_ladder_2015,
1156 pages = {9},
1157 year = {2015},
1158 author = {Hardt, Moritz and Blum, Avrim},
1159 booktitle = {International {Conference} on {Machine} {Learning} ({ICML})},
1160 language = {en},
1161 abstract = {The organizer of a machine learning competi-
1162tion faces the problem of maintaining an accurate
1163leaderboard that faithfully represents the quality
1164of the best submission of each competing team.
1165What makes this estimation problem particularly
1166challenging is its sequential and adaptive nature.
1167As participants are allowed to repeatedly evaluate
1168their submissions on the leaderboard, they may
1169begin to overfit to the holdout data that supports
1170the leaderboard. Few theoretical results give ac-
1171tionable advice on how to design a reliable leader-
1172board. Existing approaches therefore often resort
1173to poorly understood heuristics such as limiting
1174the bit precision of answers and the rate of re-
1175submission.
1176In this work, we introduce a notion of leader-
1177board accuracy tailored to the format of a com-
1178petition. We introduce a natural algorithm called
1179the Ladder and demonstrate that it simultaneously
1180supports strong theoretical guarantees in a fully
1181adaptive model of estimation, withstands practical
1182adversarial attacks, and achieves high utility on
1183real submission files from an actual competition
1184hosted by Kaggle.
1185Notably, we are able to sidestep a powerful recent
1186hardness result for adaptive risk estimation that
1187rules out algorithms such as ours under a seem-
1188ingly very similar notion of accuracy. On a practi-
1189cal note, we provide a completely parameter-free
1190variant of our algorithm that can be deployed in a
1191real competition with no tuning required whatso-
1192ever.},
1193 title = {The {Ladder}: a reliable leaderboard for machine learning competitions},
1194}
1195
1196@inproceedings{guo_calibration_2017,
1197 pages = {10},
1198 year = {2017},
1199 author = {Guo, Chuan and Pleiss, Geoff and Sun, Yu and Weinberger, Kilian Q},
1200 booktitle = {International {Conference} on {Machine} {Learning} ({ICML})},
1201 language = {en},
1202 abstract = {Confidence calibration – the problem of predicting probability estimates representative of the true correctness likelihood – is important for classification models in many applications. We discover that modern neural networks, unlike those from a decade ago, are poorly calibrated. Through extensive experiments, we observe that depth, width, weight decay, and Batch Normalization are important factors influencing calibration. We evaluate the performance of various post-processing calibration methods on state-ofthe-art architectures with image and document classification datasets. Our analysis and experiments not only offer insights into neural network learning, but also provide a simple and straightforward recipe for practical settings: on most datasets, temperature scaling – a singleparameter variant of Platt Scaling – is surprisingly effective at calibrating predictions.},
1203 title = {On calibration of modern neural networks},
1204}
1205
1206@inproceedings{engstrom_identifying_2020,
1207 pages = {11},
1208 year = {2020},
1209 author = {Engstrom, Logan and Ilyas, Andrew and Santurkar, Shibani and Tsipras, Dimitris and Steinhardt, Jacob and Madry, Aleksander},
1210 booktitle = {International {Conference} on {Machine} {Learning} ({ICML})},
1211 language = {en},
1212 abstract = {Dataset replication is a useful tool for assessing whether improvements in test accuracy on a specific benchmark correspond to improvements in models’ ability to generalize reliably. In this work, we present unintuitive yet significant ways in which standard approaches to dataset replication introduce statistical bias, skewing the resulting observations. We study ImageNet-v2, a replication of the ImageNet dataset on which models exhibit a significant (11-14\%) drop in accuracy, even after controlling for selection frequency, a human-in-the-loop measure of data quality. We show that after remeasuring selection frequencies and correcting for statistical bias, only an estimated 3.6\%±1.5\% of the original 11.7\%±1.0\% accuracy drop remains unaccounted for. We conclude with concrete recommendations for recognizing and avoiding bias in dataset replication. Code for our study is publicly available1.},
1213 title = {Identifying statistical bias in dataset replication},
1214}
1215
1216@inproceedings{dwork_generalization_2015,
1217 pages = {9},
1218 year = {2015},
1219 author = {Dwork, Cynthia and Feldman, Vitaly and Hardt, Moritz and Pitassi, Toni and Reingold, Omer and Roth, Aaron},
1220 booktitle = {Advances in {Neural} {Information} {Processing} {Systems} ({NeurIPS})},
1221 language = {en},
1222 abstract = {Overfitting is the bane of data analysts, even when data are plentiful. Formal approaches to understanding this problem focus on statistical inference and generalization of individual analysis procedures. Yet the practice of data analysis is an inherently interactive and adaptive process: new analyses and hypotheses are proposed after seeing the results of previous ones, parameters are tuned on the basis of obtained results, and datasets are shared and reused. An investigation of this gap has recently been initiated by the authors in [7], where we focused on the problem of estimating expectations of adaptively chosen functions.},
1223 title = {Generalization in adaptive data analysis and holdout reuse},
1224}
1225
1226@inproceedings{bendale_towards_2016,
1227 pages = {1563--1572},
1228 year = {2016},
1229 month = {June},
1230 author = {Bendale, Abhijit and Boult, Terrance E.},
1231 publisher = {IEEE},
1232 booktitle = {{IEEE} {Conference} on {Computer} {Vision} and {Pattern} {Recognition} ({CVPR})},
1233 urldate = {2022-10-11},
1234 language = {en},
1235 abstract = {Deep networks have produced significant gains for various visual recognition problems, leading to high impact academic and commercial applications. Recent work in deep networks highlighted that it is easy to generate images that humans would never classify as a particular object class, yet networks classify such images high confidence as that given class – deep network are easily fooled with images humans do not consider meaningful. The closed set nature of deep networks forces them to choose from one of the known classes leading to such artifacts. Recognition in the real world is open set, i.e. the recognition system should reject unknown/unseen classes at test time. We present a methodology to adapt deep networks for open set recognition, by introducing a new model layer, OpenMax, which estimates the probability of an input being from an unknown class. A key element of estimating the unknown probability is adapting Meta-Recognition concepts to the activation patterns in the penultimate layer of the network. OpenMax allows rejection of “fooling” and unrelated open set images presented to the system; OpenMax greatly reduces the number of obvious errors made by a deep network. We prove that the OpenMax concept provides bounded open space risk, thereby formally providing an open set recognition solution. We evaluate the resulting open set deep networks using pre-trained networks from the Caffe Model-zoo on ImageNet 2012 validation data, and thousands of fooling and open set images. The proposed OpenMax model significantly outperforms open set recognition accuracy of basic deep networks as well as deep networks with thresholding of SoftMax probabilities.},
1236 doi = {10.1109/CVPR.2016.173},
1237 url = {http://ieeexplore.ieee.org/document/7780542/},
1238 isbn = {978-1-4673-8851-1},
1239 title = {Towards open set deep networks},
1240 address = {Las Vegas, NV, USA},
1241}
1242
1243@inproceedings{bendale_towards_2015,
1244 pages = {1893--1902},
1245 year = {2015},
1246 month = {June},
1247 author = {Bendale, Abhijit and Boult, Terrance},
1248 publisher = {IEEE},
1249 booktitle = {{IEEE} {Conference} on {Computer} {Vision} and {Pattern} {Recognition} ({CVPR})},
1250 urldate = {2022-10-11},
1251 language = {en},
1252 abstract = {With the of advent rich classification models and high computational power visual recognition systems have found many operational applications. Recognition in the real world poses multiple challenges that are not apparent in controlled lab environments. The datasets are dynamic and novel categories must be continuously detected and then added. At prediction time, a trained system has to deal with myriad unseen categories. Operational systems require minimal downtime, even to learn. To handle these operational issues, we present the problem of Open World Recognition and formally define it. We prove that thresholding sums of monotonically decreasing functions of distances in linearly transformed feature space can balance “open space risk” and empirical risk. Our theory extends existing algorithms for open world recognition. We present a protocol for evaluation of open world recognition systems. We present the Nearest Non-Outlier (NNO) algorithm that evolves model efficiently, adding object categories incrementally while detecting outliers and managing open space risk. We perform experiments on the ImageNet dataset with 1.2M+ images to validate the effectiveness of our method on large scale visual recognition tasks. NNO consistently yields superior results on open world recognition.},
1253 doi = {10.1109/CVPR.2015.7298799},
1254 url = {http://ieeexplore.ieee.org/document/7298799/},
1255 isbn = {978-1-4673-6964-0},
1256 title = {Towards open world recognition},
1257 address = {Boston, MA, USA},
1258}
1259
1260@inproceedings{arpit_closer_2017,
1261 pages = {10},
1262 year = {2017},
1263 author = {Arpit, Devansh and Jastrzebski, Stanisław and Ballas, Nicolas and Krueger, David and Bengio, Emmanuel and Kanwal, Maxinder S and Maharaj, Tegan and Fischer, Asja and Courville, Aaron and Bengio, Yoshua and Lacoste-Julien, Simon},
1264 booktitle = {International {Conference} on {Machine} {Learning} ({ICML})},
1265 language = {en},
1266 abstract = {We examine the role of memorization in deep learning, drawing connections to capacity, generalization, and adversarial robustness. While deep networks are capable of memorizing noise data, our results suggest that they tend to prioritize learning simple patterns first. In our experiments, we expose qualitative differences in gradient-based optimization of deep neural networks (DNNs) on noise vs. real data. We also demonstrate that for appropriately tuned explicit regularization (e.g., dropout) we can degrade DNN training performance on noise datasets without compromising generalization on real data. Our analysis suggests that the notions of effective capacity which are dataset independent are unlikely to explain the generalization performance of deep networks when trained with gradient based methods because training data itself plays an important role in determining the degree of memorization.},
1267 title = {A closer look at memorization in deep networks},
1268}
1269
1270@inproceedings{morcos_insights_2018,
1271 pages = {10},
1272 year = {2018},
1273 author = {Morcos, Ari and Raghu, Maithra and Bengio, Samy},
1274 booktitle = {Advances in {Neural} {Information} {Processing} {Systems} ({NeurIPS})},
1275 language = {en},
1276 abstract = {Comparing different neural network representations and determining how representations evolve over time remain challenging open questions in our understanding of the function of neural networks. Comparing representations in neural networks is fundamentally difficult as the structure of representations varies greatly, even across groups of networks trained on identical tasks, and over the course of training. Here, we develop projection weighted CCA (Canonical Correlation Analysis) as a tool for understanding neural networks, building off of SVCCA, a recently proposed method [22]. We first improve the core method, showing how to differentiate between signal and noise, and then apply this technique to compare across a group of CNNs, demonstrating that networks which generalize converge to more similar representations than networks which memorize, that wider networks converge to more similar solutions than narrow networks, and that trained networks with identical topology but different learning rates converge to distinct clusters with diverse representations. We also investigate the representational dynamics of RNNs, across both training and sequential timesteps, finding that RNNs converge in a bottom-up pattern over the course of training and that the hidden state is highly variable over the course of a sequence, even when accounting for linear transforms. Together, these results provide new insights into the function of CNNs and RNNs, and demonstrate the utility of using CCA to understand representations.},
1277 title = {Insights on representational similarity in neural networks with canonical correlation},
1278}
1279
1280@inproceedings{ovadia_can_2019,
1281 pages = {12},
1282 year = {2019},
1283 author = {Ovadia, Yaniv and Fertig, Emily and Ren, Jie and Nado, Zachary and Sculley, D and Nowozin, Sebastian and Dillon, Joshua and Lakshminarayanan, Balaji and Snoek, Jasper},
1284 booktitle = {Advances in {Neural} {Information} {Processing} {Systems} ({NeurIPS})},
1285 language = {en},
1286 abstract = {Modern machine learning methods including deep learning have achieved great success in predictive accuracy for supervised learning tasks, but may still fall short in giving useful estimates of their predictive uncertainty. Quantifying uncertainty is especially critical in real-world settings, which often involve input distributions that are shifted from the training distribution due to a variety of factors including sample bias and non-stationarity. In such settings, well calibrated uncertainty estimates convey information about when a model’s output should (or should not) be trusted. Many probabilistic deep learning methods, including Bayesian-and nonBayesian methods, have been proposed in the literature for quantifying predictive uncertainty, but to our knowledge there has not previously been a rigorous largescale empirical comparison of these methods under dataset shift. We present a largescale benchmark of existing state-of-the-art methods on classification problems and investigate the effect of dataset shift on accuracy and calibration. We find that traditional post-hoc calibration does indeed fall short, as do several other previous methods. However, some methods that marginalize over models give surprisingly strong results across a broad spectrum of tasks.},
1287 title = {Can you trust your model's uncertainty? {Evaluating} predictive uncertainty under dataset shift},
1288}
1289
1290@inproceedings{papadopoulos_inductive_2002,
1291 pages = {345--356},
1292 year = {2002},
1293 author = {Papadopoulos, Harris and Proedrou, Kostas and Vovk, Volodya and Gammerman, Alex},
1294 publisher = {Springer},
1295 booktitle = {European {Conference} on {Machine} {Learning} ({ECML})},
1296 title = {Inductive confidence machines for regression},
1297}
1298
1299@inproceedings{romano_conformalized_2019,
1300 year = {2019},
1301 author = {Romano, Yaniv and Patterson, Evan and Candes, Emmanuel},
1302 booktitle = {Advances in {Neural} {Information} {Processing} {Systems} ({NeurIPS})},
1303 url = {https://proceedings.neurips.cc/paper/2019/file/5103c3584b063c431bd1268e9b5e76fb-Paper.pdf},
1304 volume = {32},
1305 title = {Conformalized quantile regression},
1306}
1307
1308@inproceedings{saunders_transduction_1999,
1309 year = {1999},
1310 author = {Saunders, Craig and Gammerman, Alexander and Vovk, Volodya},
1311 booktitle = {International {Joint} {Conference} on {Artificial} {Intelligence} ({IJCAI})},
1312 title = {Transduction with confidence and credibility},
1313}
1314
1315@inproceedings{torralba_unbiased_2011,
1316 pages = {1521--1528},
1317 year = {2011},
1318 month = {June},
1319 author = {Torralba, Antonio and Efros, Alexei A.},
1320 publisher = {IEEE},
1321 booktitle = {{IEEE} {Conference} on {Computer} {Vision} and {Pattern} {Recognition} ({CVPR})},
1322 urldate = {2022-10-10},
1323 language = {en},
1324 abstract = {Datasets are an integral part of contemporary object recognition research. They have been the chief reason for the considerable progress in the field, not just as source of large amounts of training data, but also as means of measuring and comparing performance of competing algorithms. At the same time, datasets have often been blamed for narrowing the focus of object recognition research, reducing it to a single benchmark performance number. Indeed, some datasets, that started out as data capture efforts aimed at representing the visual world, have become closed worlds onto themselves (e.g. the Corel world, the Caltech101 world, the PASCAL VOC world). With the focus on beating the latest benchmark numbers on the latest dataset, have we perhaps lost sight of the original purpose? The goal of this paper is to take stock of the current state of recognition datasets. We present a comparison study using a set of popular datasets, evaluated based on a number of criteria including: relative data bias, cross-dataset generalization, effects of closed-world assumption, and sample value. The experimental results, some rather surprising, suggest directions that can improve dataset collection as well as algorithm evaluation protocols. But more broadly, the hope is to stimulate discussion in the community regarding this very important, but largely neglected issue.},
1325 doi = {10.1109/CVPR.2011.5995347},
1326 url = {http://ieeexplore.ieee.org/document/5995347/},
1327 isbn = {978-1-4577-0394-2},
1328 title = {Unbiased look at dataset bias},
1329 address = {Colorado Springs, CO, USA},
1330}
1331
1332@inproceedings{vovk_machine-learning_1999,
1333 year = {1999},
1334 author = {Vovk, Volodya and Gammerman, Alexander and Saunders, Craig},
1335 booktitle = {International {Conference} on {Machine} {Learning} ({ICML})},
1336 title = {Machine-learning applications of algorithmic randomness},
1337}
1338
1339@article{dietterich_familiarity_2022,
1340 pages = {108931},
1341 note = {Publisher: Elsevier},
1342 year = {2022},
1343 author = {Dietterich, Thomas G. and Guyer, Alex},
1344 journal = {Pattern Recognition},
1345 shorttitle = {The familiarity hypothesis},
1346 volume = {132},
1347 title = {The familiarity hypothesis: {Explaining} the behavior of deep open set methods},
1348}
1349
1350@incollection{papadopoulos_inductive_2008,
1351 year = {2008},
1352 author = {Papadopoulos, Harris},
1353 publisher = {Citeseer},
1354 booktitle = {Tools in artificial intelligence},
1355 shorttitle = {Inductive conformal prediction},
1356 title = {Inductive conformal prediction: {Theory} and application to neural networks},
1357}
1358
1359@inproceedings{thagaard_can_2020,
1360 pages = {824--833},
1361 year = {2020},
1362 author = {Thagaard, Jeppe and Hauberg, Søren and Vegt, Bert van der and Ebstrup, Thomas and Hansen, Johan D. and Dahl, Anders B.},
1363 publisher = {Springer},
1364 booktitle = {International {Conference} on {Medical} {Image} {Computing} and {Computer}-{Assisted} {Intervention}},
1365 title = {Can you trust predictive uncertainty under real dataset shifts in digital pathology?},
1366}
1367
1368@article{zhang_understanding_2021,
1369 pages = {107--115},
1370 year = {2021},
1371 month = {March},
1372 author = {Zhang, Chiyuan and Bengio, Samy and Hardt, Moritz and Recht, Benjamin and Vinyals, Oriol},
1373 journal = {Communications of the ACM},
1374 urldate = {2022-10-10},
1375 number = {3},
1376 language = {en},
1377 abstract = {Despite their massive size, successful deep artificial neural networks can exhibit a remarkably small gap between training and test performance. Conventional wisdom attributes small generalization error either to properties of the model family or to the regularization techniques used during training.},
1378 doi = {10.1145/3446776},
1379 url = {https://dl.acm.org/doi/10.1145/3446776},
1380 issn = {0001-0782, 1557-7317},
1381 volume = {64},
1382 title = {Understanding deep learning (still) requires rethinking generalization},
1383}
1384
1385@misc{zhang_understanding_2017,
1386 keywords = {Computer Science - Machine Learning},
1387 note = {arXiv:1611.03530 [cs]},
1388 year = {2017},
1389 month = {February},
1390 author = {Zhang, Chiyuan and Bengio, Samy and Hardt, Moritz and Recht, Benjamin and Vinyals, Oriol},
1391 publisher = {arXiv},
1392 urldate = {2022-10-10},
1393 language = {en},
1394 abstract = {Despite their massive size, successful deep artificial neural networks can exhibit a remarkably small difference between training and test performance. Conventional wisdom attributes small generalization error either to properties of the model family, or to the regularization techniques used during training.},
1395 url = {http://arxiv.org/abs/1611.03530},
1396 title = {Understanding deep learning requires rethinking generalization},
1397}
1398
1399@techreport{mattis_summary_2018,
1400 pages = {14},
1401 keywords = {government, us-dod},
1402 year = {2018},
1403 author = {Mattis, Jim},
1404 language = {en},
1405 title = {Summary of the 2018 {National} {Defense} {Strategy}},
1406}
1407
1408@techreport{blackburn_summary_2019,
1409 pages = {17},
1410 year = {2019},
1411 month = {February},
1412 author = {Blackburn, R Alan},
1413 language = {en},
1414 url = {https://media.defense.gov/2019/Feb/12/2002088963/-1/-1/1/SUMMARY-OF-DOD-AI-STRATEGY.PDF},
1415 title = {Summary of the 2018 {Department} of {Defense} {Artificial} {Intelligence} {Strategy}},
1416}Attribution
arXiv:2302.07872v1
[cs.CY]
License: cc-by-sa-4.0


