
- Papers
Papers is Alpha. This content is part of an effort to make research more accessible, and (most likely) has lost some details from the original. You can find the original paper here.
Introduction
In April 2021 the European Commission (EC) proposed a set of rules to regulate Artificial Intelligence (AI) systems operating across Europe. This was an important step in a long-term process in which the European Union developed its approach towards AI, setting up policy agendasand ethics guidelinesamong others. During this period, the EC sought feedback from different stakeholders to ensure an inclusive policy development, such as the consultation run from February to June 2020 to gather opinions about the White Paper on AI. Usually, these consultations solicit reflection on specific actions or policy proposals and can reveal partial information, if anything, about what people think about AI and its related impact on society.
Knowing people’s views and perceptions is key to deploying effective governance mechanisms and integrating rules into society. In this paper, we aim to fill this gap and report the results of a survey investigating the knowledge and perception of AI in Europe. For this reason, we designed, developed, and validated a new questionnaire, the Perceptions on AI by the Citizens of Europe questionnaire (PAICE), structured around three dimensions: Awareness, attitude, and trust. Based on a computer-assisted web interview methodology (CAWI) we collected and analyzed the opinions of 4,006 European citizens from eight countries (France, Germany, Italy, Netherlands, Poland, Romania, Spain, and Sweden), stratified by age, gender, and geographic regions.
The collected responses show that respondents’ self-assessed knowledge about AI is low, while their attitude is very positive and slightly varies depending on the context of use (e.g. approval is lower when AI is applied to human resources management). The most important measures to increase trust in the AI ecosystem include the introduction of laws by national authorities, transparent communication by AI providers, and education activities. Among trusted entities that could ensure a beneficial use of AI, universities and research centers are ranked higher than other organizations (e.g. national governments and tech companies). The statistical analysis shows that the questionnaire has good internal consistency and that the validity is adequate.
We analyze the results of the survey and identify a few contrasting perceptions which may reflect three broader social trends: 1) approval of a hyped, but poorly known, technology; 2) disconnect from public AI policies; 3) poor engagement with AI education and training. We discuss how these trends may create friction in the creation of a Trustworthy AI culture and suggest a few recommendations. Our findings call for greater consideration of people’s views and participation in AI policy-making, especially if we consider the rapid transformations introduced by AI into society and the abundance of policy efforts by states and intergovernmental organizations.
Related work
AI and trust recall a vast academic literature investigating shared principles among ethics guidelines, as well as challenges and future directions. In this section, we focus on previous surveys analyzing citizen awareness, trust, and attitude towards AI from different perspectives.
In a global study surveying 10,000 citizens spanning eight countries across six continents, respondents reported a mix of positive and negative feelings about AI. In a similar study, the UK expressed a markedly negative view of AI, while showing a reasonable understanding and awareness of this technology. The US population has been surveyed on a key dimension of trust: the perception of governance. While most people (especially older segments) find the issue very important, they state that they have little trust in the actors who have the power to develop and manage AI (e.g. companies, universities, US agencies). Another US-related work investigated the ethical preferences of different groups of people and found that AI practitioners’ value priorities differ from those of the general public.
Studies focused on the perception of AI in Europe are not entirely new. In an EU-wide survey, the authors focused on a notion of AI centered around robotics, finding attitudes to be generally positive, with concerns related to job losses, later confirmed in a follow-up study. These are generic studies of EU public opinion about science and technology, with only a marginal focus on AI. A subsequent survey on opinion about AI highlighted discrimination and lack of accountability as key concerns for European citizens, and a belief that public policy intervention is needed, shared by a majority of respondents.
Recently,analyzed the positive and negative expectations of 164 individuals visiting a Science Gallery exhibition in Dublin. The study found that awareness of AI is relatively good, opportunities are related to economic growth and social progress (e.g. mentioning the positive impact on medicine, science, and environments) and concerns are connected to automation, followed by privacy and surveillance.examined awareness of AI, emotional responses to narratives, and the perceived likelihood of future scenarios in Italy. The authors pointed out a positive correlation between the level of digital expertise and general knowledge of AI and showed an important gender divide with respect to the emotional response to narratives with women more concerned than men across all scenarios.investigated how German people prioritize different ethical principles (transparency, fairness, non-maleficence, responsibility, beneficence, privacy, and machine autonomy) with regard to the application of AI to fraud detection. The study found that all ethical principles are equally important for the respondents but different preference profiles for ethically designed systems exist.
Research questions
The present work departs from the existing literature in two fundamental ways. First, it takes AI as its main target not as part of broader investigations in science and technology, connecting different perspectives (such as awareness and trust) with specific use cases. Second, it aims at reaching a large population involving more than one European country or demographics.
The questionnaire was developed in the context of an Horizon 2020 project by a multidisciplinary team of researchers. The research questions addressed by the team are the following:
- RQ1 : To what extent are EU citizens familiar with AI and the surrounding debate? This covers aspects concerning citizens’ awareness and competency such as: what people think they know about AI, where they think AI is applied, what is the perceived impact of AI, and which EU initiatives addressing ethical and legal concerns they are aware of.
- RQ2 : To what extent do EU citizens approve AI? This research question connects to citizens’ attitude towards AI and its use in some specific sectors or contexts of application (such as job recruitment).
- RQ3 : What could contribute to increasing citizens’ trust? This question investigates citizens’ priorities to promote the responsible development of AI in terms of actions, actors and ethical requirements. These questions guided the development of the questionnaire around the dimensions of awareness, attitude, and trust. The structure of the questionnaire was also explored in our analysis (i.e. validity and reliability). This allowed us to identify which items of the questionnaire can be used to validate the dimensions suggested by the team of experts who designed the research instrument.
The rest of the paper is organized as follows. First, we present the methodology guiding the survey design. Next, we report the results of the survey according to the dimensions of interest (i.e. awareness, attitude, and trust), and analyze the validity and reliability of the questionnaire. We discuss the results pointing out implicit tensions and discussing potential barriers to the development of inclusive AI policy processes, thereby making recommendations to improve current efforts, especially at the European level. Finally, we summarise our findings and suggest future research directions.
Methods and materials
Survey method
This survey was conducted by the market research agency Marketing Problem Solving (MPS) based in Italy. The survey was carried out through online interviews (CAWI) on the basis of a structured questionnaire. The average completion time was 20 minutes. MPS programmed the script of the questionnaire through the creation of a website hosted on the web server owned by MPS and managed the data collection process.
The invitation to fill out the questionnaire was sent by e-mail to members of an online panel who voluntarily agreed to share their opinions. To facilitate the task, panel members received the questionnaire in their own language. The respondents were free to drop out at any point and had the opportunity to go back to previous items and change their answers. Respondents’ information was recorded in compliance with the General Data Protection Regulation (GDPR) and the Italian legislation on data protection and privacy.
From the 1st to the 15th of June 2021 MPS, realized a total of 4,006 interviews in eight European countries: France, Germany, Italy, Netherlands, Poland, Romania, Spain, and Sweden. Countries were selected with a view to cover different European regions (southern, central/eastern, northern, and western). The survey was completed by individuals aged between 18 and 75 years. Quotas were imposed to ensure the representativeness of the sample with respect to gender, age group (18-34, 35-54, 55-75), and geographical area of residence.
Before undertaking the survey, MPS tested the questionnaire with a sample of panel members to assess the clarity of instructions and the average completion time. MPS monitored the whole interview process to ensure the quality of responses, e.g. by removing participants who completed the survey too quickly or provided contradictory answers.
The original version of the survey was developed and revised in English and then translations in other languages (Italian, Spanish, German, Polish, French, Romanian, Dutch, Swedish) were made by professional translators or mother tongue experts.
Population
To obtain a random stratified sample, members of the population were first divided into non-overlapping subgroups of units called strata (country), then, a sample was selected from each stratum based on geographic regions (unit of analysis), age groups and gender through a simple random sampling. The sample was made up of 4,006 individuals with equal representation for each country (12.5%).
The sample was composed of individuals in the age range 18-75 (mean age = 45, std = $\pm{14.83}$ ) where women were $49.3\%$ (mean age = 46, std = $\pm{14.92}$ ) and men $50.4\%$ (mean age = 45.5, std = $\pm{14.83}$ ). Note that in our analysis we considered only male and female groups since the respondents choosing the option “others” were only 0.3% of the whole population. The age groups were coded into three levels: young (18-34 years), middle age (35-54), and senior (55-75) people. In particular, 26.5% of respondents were young, 39.4% were middle age, and the remaining 33% were senior. We also investigated the population size of the place of residence and found that 25% of respondents lived in a city with a population up to 10K, about 40% lived in a city with 10-100K inhabitants, and the remaining 35% lived in a large city with more than 100K inhabitants. Information about gender, age groups, and city size related to respondents of each country is summarized in Table table1.
With reference to formal education, the descriptive analysis highlighted that 40% of the respondents had the highest level of formal education (bachelor, master, or doctoral degree). Note that this percentage is higher than the share of European citizens with tertiary education (i.e. also including trade schools and vocational education) which is estimated at 31%. The choice of the survey methodology, based on online interviews, possibly facilitated the participation of subjects with higher levels of education.
To investigate confidence with Information and Communication Technology domains we submitted to the respondents an item assessing their level of competence in digital skills on a five-point ordinal scale from almost no knowledge to advanced knowledge. It was observed that 44% of the respondents have an intermediate level of competence in digital skills. Among those who feel less competent in digital skills, we found French and German respondents who represent respectively 31.7% and 34.5% of the population surveyed in each country. The countries reporting the highest level of competency are Spain and Italy where respondents with intermediate or advanced knowledge are 82.9% and 79.8% respectively. For more details on digital skills and formal education see tables “digital skills” and “education” in the supplemental material (Digital skills).
Questionnaire design
The PAICE questionnaire was created by a group of researchers from different backgrounds (AI & Computer Science, Philosophy, Engineering, Psychology, and Communication) including the authors of the present work.
The design of the questionnaire took six months, from January to June 2021, during which the group met on a monthly basis. In the early stages of the design process, the group collected and analyzed the existing literature and previous surveys at a European and worldwide level. Based on the literature review, the group identified the research questions and subsequently defined the questions for the research instrument. After a refinement process, the group agreed on a total of 14 items including Likert scale, dichotomous, multi-response items, and ranking. The items were organized according to the three dimensions introduced above (awareness, attitude, and trust) with a view to address the starting research questions. An overview of the structure of the questionnaire with question types and the topics of each item is reported in Table tab-paice. Note that some questions, since they applied to different sectors, policy measures, or entities, were split into sub-items (e.g. Q7_1 to Q7_10).
In addition, the questionnaire presented: a control question about the perceived impact of AI, a question investigating the interest in attending a free course on AI, and seven questions on socio-demographic aspects (i.e. age group membership, gender, geographical area, population size, job sector, level of education, and digital expertise). The control question, which was a repetition of item Q3 (see Table tab-paice), was added to assess possible changes in opinions after the completion of the questionnaire. The English version of the full questionnaire is available in the supplemental material (Questionnaire).
Likert scale items ranged from 1 to 5 where 1 referred to negative or low values (e.g. “not at all”, “never”, “not important at all” and “strongly disapprove”) and 5 to positive or high values (e.g. “a lot”, “always”, “very important” and “strongly approve”). For item Q5 we also added the option “I don’t know” to accommodate respondents who did not have a clear opinion on the topic (awareness of interaction). We chose the 5-point Likert scale because this is largely used in social science research to study human attitudes and perceptions. Though the optimum number of choices in a Likert-type scale is a subject of dispute, we opted for a 5-point scale to ensure items’ simplicity andintelligibility.
To offer a common ground to all respondents we introduced the following definition of Artificial Intelligence at the beginning of the questionnaire: “Artificial intelligence (AI) refers to computer systems that can perform tasks that usually require intelligence (e.g. making decisions, achieving goals, planning, learning, reasoning, etc.). AI systems can perform these tasks based on objectives set by humans with a few explicit instructions.” Given the heterogeneity of the consulted population, we chose a simple definition that could be intelligible by a large audience.
Statistics
To explore the theoretical dimensions structuring the PAICE (awareness, attitude, and trust) an Exploratory Factor Analysis (EFA) and confirmatory factor analysis (CFA) were performed. The aim was to evaluate the robustness of items in the questionnaire. To do this we randomly split the sample (n=4,006) into two groups n=2,450 for EFA and n=1,051 for CFA. Note that only items measured on the Likert scale were included in this analysis. The EFA was performed to determine the number of fundamental (latent) constructs underlying the set of items and quantify the extent to which each item is associated with the construct. In this context, the EFA allows us to study the strength of relations between the dimensions identified by the team of experts who designed the questionnaire and the associated items. Before performing the EFA analysis, two criteria were tested to determine whether factor analysis was appropriate: the Kaiser-Meyer-Olkin (KMO) measure of sampling adequacy and Barlett’s test of sphericity assumptions. A KMO index $>0.7$ and a Barlett’s test of sphericity p-value$<0.05$ are considered appropriate values to conduct the EFA. The implementation of the EFA was based on a polychoric correlation matrix since the questionnaire is composed of ordinal items (i.e. Likert scale). The EFA was run by using principal axis factoring, because it does not assume normality of data, with oblique rotation. The parallel analysis was used to identify the optimum number of factors to be retained. We also assessed inter-factors correlation, in order to evaluate ifsome theoretical dimensions are correlated strongly with each other, i.e. $>0.7$ . To assess the internal consistency of the EFA solution, we calculated Cronbach’s $\alpha$ and ordinal $\alpha$ which is considered the most appropriate coefficient for ordinal-type scales. These indices take values in the range [0, 1], so the internal consistency is acceptable if the indices are greater than 0.80.
Finally, the validity of the factor structure derived from the EFA was evaluated by using the CFA. The implementation for the CFA was based on a polychoric matrix and the robust diagonally weighted least squares (RDWLS) extraction method which is more suitable for ordinal data than other extraction methods.
We assessed the fit of the model using the following criteria: root mean squared error of approximation (RMSEA$<0.08$ ), the comparative fit index (CFI) andthe Tucker-Lewis index (TLI) withvalues above 0.95 and 0.90, respectively, and the standardized root mean residual (SRMR$ <0.08$ ). All analyses were performed by using the statistical package for social science V.25.0.2 (SPSS) and R version 3.4.1 (The R Foundation for Statistical Computing, Vienna, Austria).
Limitations
This work, like any other, has some inherentlimitations. Though we tried to represent different European regions, the sample does not cover all European countries. Thus, our analysis may not be representative of the opinions of all EU citizens. As we suggest in the conclusion, extending the questionnaire to other countries will give a more complete picture of European society. Moreover, our questionnaire administration methodology (CAWI) assumes that the target population has access to the internet and is familiar with web navigation. This choice could have indirectly impacted on the selection of the population interviewed. The latter may be skewed towards people with higher education levels and/or wealthier socio-economic status.Another limitation concerns the measurement of awareness. In this study, we focus on self-reported awareness, which may suffer from subjective and contextual factors. Objective knowledge about AI is another important dimension of awareness; its rigorous measurement would require the development of a specific methodology going beyond the scope of this work.
Results
The responses to the questionnaire are presented with respect to the three dimensions: Awareness, attitude, and trust. Aggregated responses to all items are reported in tables “Likert-scale items” and “Non-Likert scales” with the descriptive statistics in the supplemental material (Responses). Responses were compared with respect to different groups by using Kruskal-Wallis test where a p-value $< 0.01$ is considered statistically significant. In our comparison, we considered the following groupings: Countries, age groups, and gender. With respect to countries, we found statistically significant differences among groups for all Likert scale items. As for age and gender groups, we found statistically significant differences for a subset of items. For the sake of brevity, in the subsequent sections, we will comment only most significant differences. The results of statistical tests are reported in tables “Awareness”, “Attitude”, and “Trust” in the supplemental material (Statistics by Groups).
Finally, we report the results of the analysis performed to assess the questionnaire’s validity and reliability.
Awareness
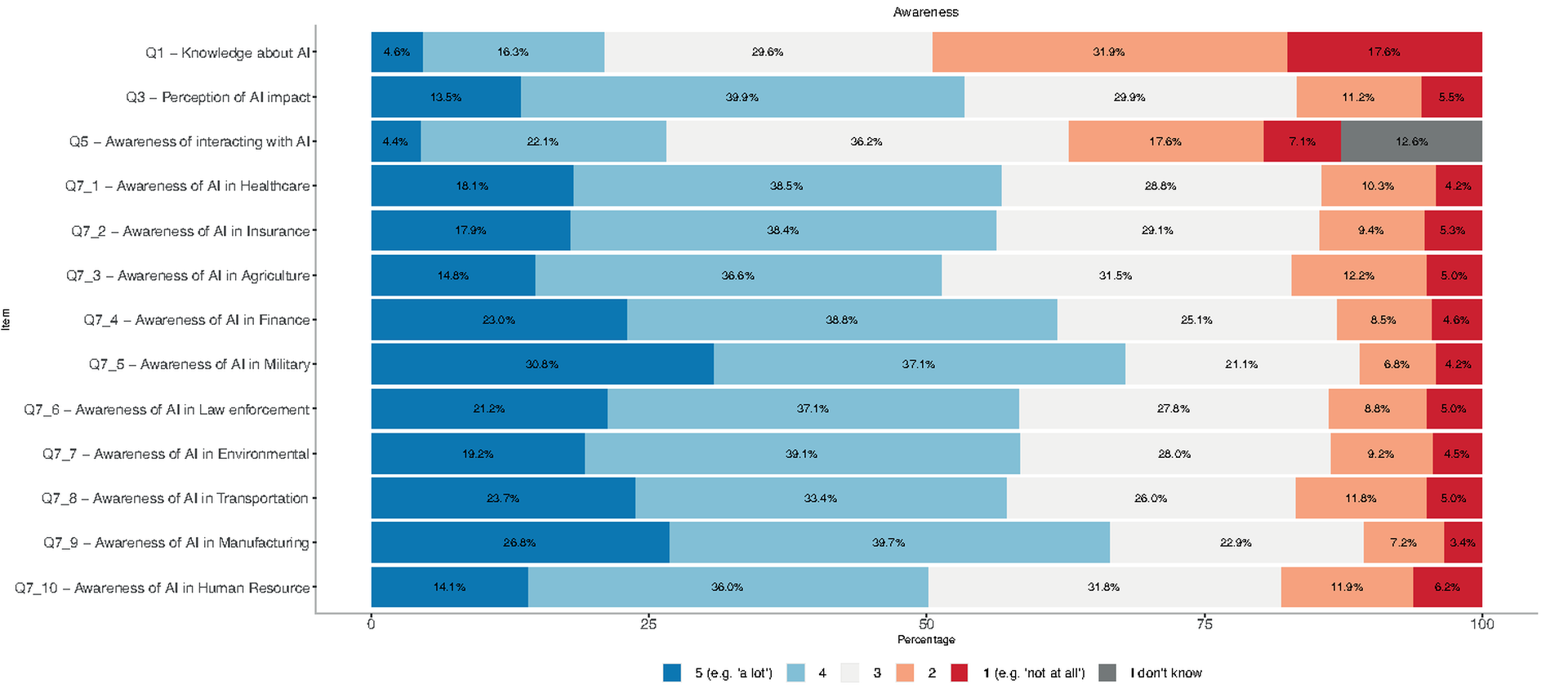
In Figure fig-1, we represented the percentages of responses to Likert scale items connected to awareness. Blue and red colored segments identify the two extreme positions: high and low levels of awareness respectively. The largest red segment, including the lowest scale values (i.e. 1 and 2), regards the self-assessed competency on AI (Q1). In this item, almost half of the respondents (49.5%) reported having low or no knowledge, while only 20.9% considered their knowledge to be advanced or expert-level. Analyzing the results by country, Germany and the Netherlands have the highest percentage of respondents who feel less knowledgeable, at 66% and 63% respectively. If we look at gender, the percentage of individuals who feel less competent is greater for males (55%) as compared to females (43%). With respect to age, the portion of individuals with low or no competency is higher for seniors (63%) and lower for young respondents (32%).
When asked about being aware of interacting with a product or service based on AI (Q5), only 26.5% reported being often or always aware, while 24.7% reported to be never or seldom aware, and 12.6% chose the “I don’t know” option. In Germany the fraction of people who feel never or seldom aware increases by 9 percentage points (32%). Male respondents declared a higher rate of low or no awareness of interaction (25%) as compared to females (23%). The group of senior respondents achieved the highest percentage of answers expressing unawareness during interaction (28%).
In relation to the impact of AI in their daily lives (Q3), half of the respondents (53.4%) felt like it has somewhat or a lot of impact, while 16.7% answered with “not so much” or “not at all”. The perception of (high) impact is greater in Spain (73%) and lower in Poland (33%) - the latter is also the country in which there is the highest fraction of answers reporting a low perceived impact of AI on their lives (29%).
Items from Q7_1 to Q7_10 assessed to what extent respondents feel AI is used in distinct sectors across Europe. Military (67.9%) and Manufacturing (66.5%) present a higher fraction of respondents perceiving AI as being somewhat or very present in such sectors. On the other hand, Human Resources (50.1%) and Agriculture (51.4%) present a lower perception of the presence of AI.
Regarding respondents’ familiarity with the normative and ethical European framework (Q4), two out of three respondents (65.6%) have heard about GDPR, while only one out of three were aware of the Trustworthy AI Guidelines or the AI Act (28.3% and 29.8% respectively).
Participants were also introduced to a list of applications and were asked about which ones may contain AI components (Q6). Facial recognition apps, content and product recommendations, search engines, traffic navigation apps, and car ride-sharing apps were the most identified applications, selected by half of the respondents. Other options with more limited AI applications, such as calculators or text editors, were included by 32.6% and 26.3% of participants respectively. Finally, 7.2% of respondents selected the option “none of the above”, hence did not identify any AI-based application.
Attitude
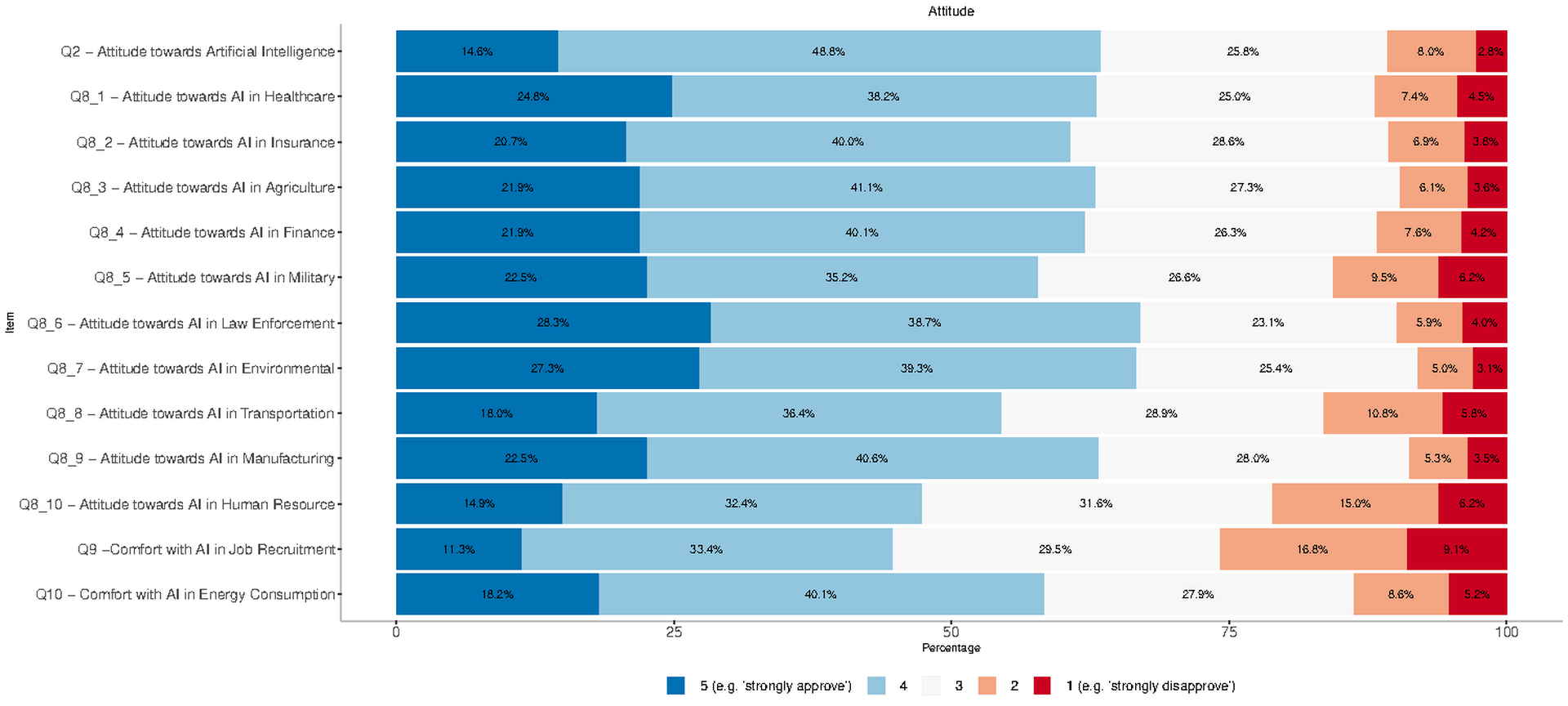
In Figure fig-2, we reported the percentages of responses to Likert scale items associated with attitude, where blue segments represent a (very) positive inclination and red segments indicate a (very) negative one.
Regarding their general attitude towards AI (Q2), 63.4% of the respondents report strongly approving or approving of AI. The most receptive countries were Romania and Spain with almost 80% approval, while in France fewer than 50% participants declared approval of AI. With respect to gender, females expressed to be more positive as compared to males, with approval or strong approval at 68% and 59% respectively. When considering age, the class of younger respondents reached the highest rate of approval (70%), while the group of seniors reported the lowest one (58%).
Items from Q8_1 to Q8_10 aimed to further understand how approval varies depending on the sector of application. Law Enforcement and Environment have the highest acceptance with an average of 67% of participants opting for approval or strong approval, followed by Manufacturing, Healthcare, and Agriculture. Human resources presents the lowest acceptance rate (47.3%) and the highest dissatisfaction rate with 21.2% of respondents disapproving or strongly disapproving.
We also considered two specific use case scenarios: Q9 presents an AI-based system that screens candidates’ resumes and selects those who can access the interviewing stage; Q10 introduces a smart meter to reduce energy consumption inspired by demand side managementthat leverages AI to recommend more efficient usage and provide personalized offers from energy providers. While the proportion of neutral positions is approximately the same for both scenarios, the approval is significantly higher for the smart meter with 58.3% of the respondents feeling fairly or very comfortable, as opposed to 44.7% for the resume screening system. Again, we observed statically significant differences among countries. Poland is the most receptive country with about 67% of respondents feeling fairly or very comfortable in both scenarios. The trend for gender and age groups is similar to that found for general attitude with a preference for the smart meter scenario.
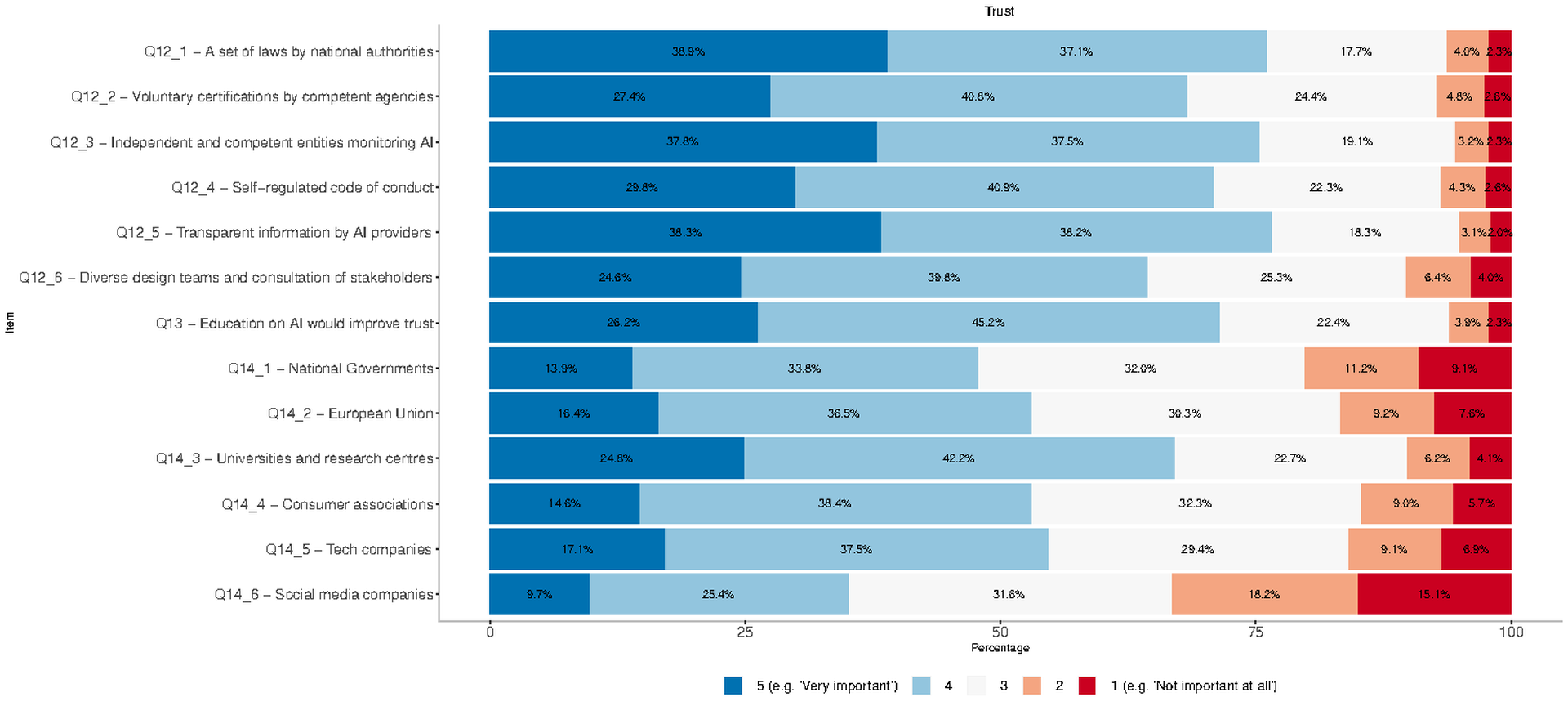
Trust
In Figure fig-3, we represented the responses to Likert scale items referred to trust. Similarly to previous dimensions, colors are indicative of respondents’ satisfaction with actions and entities aimed to ensure trust. When asked to assess the importance of a set of policy measures to increase trust (Q12), 76% of the respondents valued as important or very important the deployment of a set of laws by a national authority that guarantees ethical standards and social responsibility in the AI application. Romania and Germany are the countries in which this percentage is the largest, at 90% and 82% respectively. With regard to age, a large proportion of senior respondents consider this measure important (81%), followed by young (71%) and the middle age respondents (68%). The remaining measures were also highly supported (more than 50%); the least valued one was the creation of diverse design teams and the consultation of different stakeholders throughout the entire life cycle of the AI product (64.4%). Education as a remedy to improve citizens’ trust (Q13) was also largely approved with 71.4% of agreement or strong agreement. Note that this percentage increases significantly in Romania and Spain where agreement reaches 85% and 83% respectively, while it falls to 59% in France.
With respect to trusted entities ensuring a beneficial use of AI (Q14), two out of three participants (67%) rated universities and research centers as entities that could be trusted a lot or somewhat. Note that this percentage varies across countries with Romania reporting the highest value (77%) and France the lowest one (55%). Social media companies are the least trusted entity with only 35% of respondents trusting them. With respect to countries the percentage is higher in Italy (47%) and lower in the Netherlands (26%), while, if we consider age groups, trust in social media is lowest for senior respondents (24%) and highest for young respondents (46%). With Q11, we asked to select three out of the seven most important aspects that an organization should consider to developing or using AI in relation to the previous scenarios (Q9 and Q10). Interestingly, there is a clear preference towards technical aspects related to security, robustness and human oversight, with Privacy and Data Protection leading as a choice for 30.8% respondents. On the other hand, the Societal and Environmental impact of AI applications was only selected by the 5% of the respondents as a first or second choice.
Questionnaire validity and reliability
Among the 4,006 participants, 501 ticked the response option “I don’t know” for item Q5 (i.e. “How often are you aware of interacting with a product/service based on or including AI?”), corresponding to 12.6% of the sample. Therefore, these responses were excluded from the statistical analysis. A qualitative analysis was conducted to explore the content of each item and identify the ones with multicollinearity issues.
The Kaiser–Meyer–Olkin (KMO) test and the Bartlett’s test of sphericity showed that the data are appropriate to perform the EFA with a KMO index $=0.93$ and a Barlett’s test of sphericity p-value$<0.0001$ . Parallel analysis suggested three factors which are detailed in the supplemental material (Exploratory Factor Analysis: Figure). The three factors accounted for 62% of the total variance. In particular, we extracted the factors based on factor loading and the interpretability of the factors. Note that, the items with low factor loading ($<0.50$ ) were not considered while the remaining items were assigned to a single factor according to their highest loading (see supplemental material (Exploratory Factor Analysis: Table).
The items that load on the same factor suggested that factor 1 (26% of the total variance) refers to awareness and includes 7 items (Q7_2, Q7_4, Q7_5, Q7_6, Q7_7, Q7_9, Q7_10); factor 2 (25% of the total variance) refers to attitude and includes 6 items (Q8_1, Q8_2, Q8_3, Q8_4, Q8_6, Q8_7) and factor 3 (10% of the total variance) refers to trust and includes only 3 items (Q14_2, Q14_4, Q14_6).
We also assessed the factor correlation matrix of the final EFA to assess the discriminant validity. The correlations between all three factors were found positive. The largest positive correlation was between factor 1 and factor 2 (0.52), and the smallest correlation was between factor 2 and factor 3 (0.37).Hence, we did not find correlation coefficients greater than 0.7; therefore the factors derived from EFA revealed adequate discriminant validity among the factors.
For reliability, both Cronbach’s $\alpha$ and ordinal $\alpha$ were found to be large enough ($\alpha > 0.8$ ), indicating that the questionnaire had good internal consistency. Then, we used the CFA to examine the proposed factorial structure of the PAICE. Overall, our CFA results showed that the EFA model showedacceptable fit indices (RMSEA (90%CI = 0.011; CFI = 0.99; TLI = .99, SRMR = 0.03; p-value $<0.001$ ).
Discussion
The collected responses reveal some contrasts that are worthy of in-depth analysis. These tensions may signal friction in current efforts towards a Trustworthy AI innovation and, in particular, call for reflection on the EU context, where the AI strategy aims to build an ecosystem of trust and the development of an AI regulation is underway. Note that these contrasts reflect more implicit contradictions rather than disagreements openly expressed. Yet, pointing them out allows us to discuss critical social orientations that may constitute a barrier to the development of a trustworthy AI culture and, most importantly, an inclusive approach to AI governance.
Implicit contradictions
Knowledge about AI vs Approval of AI . The first remarkable result of this survey is that respondents’ (self-assessed) knowledge of AI is much lower as compared to their approval, which is, by contrast, quite high with respect to both AI generally considered and several domain applications. This confirms other studies that observed a gap between people’s limited competency and their perceptions and expectations, which might be influenced by the narratives about the future progress of emerging technologies such as AI.
AI for the environment vs The environmental impact of AI . AI approval is often dependent on the sector or context of application, such as education or healthcare. In this respect, the high acceptance rate of AI in law enforcement and the environment is rather striking. A plausible interpretation might be that people consider these as critical areas where the use of advanced technologies, like AI, could ensure greater progress as compared to other sectors. However, it is surprising that only a small portion of the respondents choose societal and environmental aspects as one of their ethical priorities. In other words, it seems that the intuition of the beneficial effect of AI on important environmental challenges ahead is not on par with the knowledge of possible negative impacts that AI may have on society and the environment. This intuition would be in line with previous studies showing that people tend to not care about the environmental impact of AI solutions and pay more attention to transparency and explainability.
Perceived AI impact vs Knowledge about EU measures on Trustworthy AI . While the perceived impact of AI is high across the interviewed population, the knowledge of recent measures put forward by the EC to safeguard the risks associated with the use of AI is significantly low. In particular, about 70% of the respondents claim no knowledge about two key recent actions by the EC, i.e. the ethics guidelines for Trustworthy AIand the proposal for an AI regulation, whereas most of them are familiar with the GDPR. Though this lack of knowledge can be partially explained by the novelty of these initiatives (April 2019 and April 2021 respectively), it seems that the public discussion of the AI impact in the EU is still remote from citizens’ experience. Also, the lack of knowledge about the proposal for an EU regulation on AI is somewhat in contrast with respondents’ policy preferences indicating the introduction of laws as a top priority.
Introduction of laws by national authorities vs Trust in national governments . As anticipated, the set up of laws by national authorities is acknowledged as (very) important by the largest portion of the respondents. However, national governments are the second last entity that can be trusted a lot or somewhat. This last opinion may reflect a larger discontent with democratic processes, challenged by global crises (e.g. climate, migration, economy etc) and more recently by the Covid-19 pandemic. The EU took a leading position in proposing global standards for the governance of AI and promoting a unified approach to AI across all member states. However, the implementation of these policy and regulatory efforts might be undermined by the fragile relations between citizens and democratic institutions and associated phenomena (e.g. anti-EU sentiments and populist movements).
AI Education as measure to improve citizens’ trust vs Interest in engaging with AI education . With respect to the role of education in fostering trust in AI, 71% respondents are highly positive and express a (strong) approval. The value of education and culture is also reflected by the choice of universities and research centers as the most trusted entities in ensuring the beneficial development of AI. To gain a better understating of the value of education we also asked participants if they would be interested in attending a free course on AI with a view to improve their knowledge (see the last question, Q16). Overall, 61% of participants answered positively, although compared to their strong support of education-related initiatives, even higher percentages could be expected. Moreover, only half of those who self-reported a low AI competence (Q1) said they would be interested in attending a free course (Q16). This limited interest in engaging with AI education might be indicative of a sort of hesitancy in joining the innovation process brought about by AI, in particular among individuals who feel less competent. A similar interpretation may also apply to the selection of inclusive design teams and consultation with stakeholders (Q12_6) as the least valued measures.
Potential barriers and recommendations
The combination of the implicit contradictions presented above suggests three interrelated social trends. These may affect the way in which AI innovations integrate into the fabric of social life and create a barrier to the human-centric approach that the EU wishes to achieve. For each trend, we discuss critical issues that policy makers could face and suggest a few recommendations. We recall that the European AI strategy pursues three fundamental goals: 1) boosting the AI uptake across the economy by private and public sectors; 2) preparing for socio-economic changes brought by AI transformations; 3) ensuring appropriate ethical and legal framework to promote trustworthy AI.
Approval of a hyped, but poorly known, tech .
The divide between knowledge and approval, regardless of its causes, calls for reflection on the meaning and implications of approving something which is not sufficiently known or understood. Over the last few years we have witnessed an explosion of fictional and non-fictional AI-related communication and narratives. This large availability of information sources can contribute to creating big expectations, on the one hand, but can also increase confusion or even resistance and aversion, on the other hand. For example,analyzed trends in beliefs, interests, and sentiment articles around AI in a 30-years period. Results show a significant increase in content with a generally optimistic perspective since 2009, although certain topics regarding ethical, technical, and social aspects of AI are also gaining relevance. Moreover, the language used to communicate is highly influential; when mixed with fictional, or utopian narratives, it can create confusion and lead the general public to overestimate the real capabilities and limitations of AI, augmenting the disconnect from the real progress of the technology.
A manifest example of the risk of this poorly informed approval is the attraction created by the latest language model ChatGPT. It seems plausible that, in the imagination of a non-specialist, an AI system of this kind, which creates poems, codes, and answers complex questions in a credible manner, is likely to be credited with advanced cognitive abilities. The problem is that systems like ChatGPT “can fool us into thinking that they understand more than they do”, and this limitation is probably unknown by the majority of users. The language and terminology used are fundamental to avoid inaccurate and biased messages that create overhype and misinformation about the real capabilities, limitations and associated risks of AI. Moreover, information needs to be clear and adapted to the audience. To improve media communication on AI and support more informed opinion we recommend: 1) increasing the study of media communication on AI and social dynamics created by AI-related content; 2) fostering training of science and tech journalists/communicators on AI applications, in particular, on new AI breakthrough; 3) distributing high-quality information through institutional channels (e.g. curating the terminology and translating material in national languages).
Disconnect from public AI policies .
In democratic societies, institutions play a crucial role in anticipating risks and taking preventive actions to protect citizens’ rights when innovation processes take place. This is particularly important in times of global crisis or rapid changes and when parts of the population lack the expertise to face complex challenges. However, the development and implementation of public policies and laws are more effective when citizens participate in the public discussion and gain a better understanding of the issues at stake. Indeed, increasing public awareness may impact people’s values and priorities. Not surprisingly, privacy and data protection, which turned out to be the most well-known EU action (i.e. the GDPR), is one of the highest-rated ethical requirements by the respondents of the survey. We recall that before the GDPR was released there were already a directive and respective national laws regarding data privacy. Moreover, the regulation was accompanied by a large campaign of information and awareness towards the topic, in addition to a two-year adoption period for companies (from 2016 to 2018).
The implicit contrasts observed in our results stress the need of supporting European citizens in gaining a greater understating of the risks associated with AI, including harms that might be invisible to them. In particular, more efforts should be made to raise awareness of AI’s environmental costs in the public discourse as suggested by. A poor understanding of societal harms associated with AI may contribute to exacerbating inequalities and eroding democratic processes. Moreover, if people have limited knowledge about the rules and the initiatives introduced to protect them from potential AI-related risks, they will not be aware of the rights they have and when these are violated. Overall, reflecting on the gap between citizens and the EU policy efforts on AI stresses the importance of building a culture of trust on top of laws and policies. Educational and dissemination resources are needed to promote the last key EU policy initiatives and to empower citizens to know their rights and exercise them. Greater attention should also be directed to the initiatives of inclusive governance to avoid the so-called paradox of participation, i.e. inclusion processes failing to achieve structural reforms. To improve participation and make society a relevant stakeholder in AI policy-making we recommend 1) analyzing the effectiveness of EU initiatives and platforms aimed atstakeholders’ participation, including the European AI alliance; 2) creating information material on the AI-related risks and associated EU measures targeted to different audiences (e.g. children and seniors); 3) increasing local initiatives (including physical events) on AI and the EU efforts aimed at reaching segments of society who are at the edge of current AI debates (e.g because lacking technology or other cultural resources).
Poor engagement with AI education and training .
Education and lifelong learning play a central role in the European AI policy. These strategies aim at boosting economic growth but also preparing the society as a whole, to ensure that “none is left behind in the digital transformation”. This preparation includes the introduction of AI from the early stages of education to increase skilled workers in AI-related tasks, but also the promotion of conditions that make Europe able to attract and retain talent for AI research and industry. These steps connect with the need to preserve democracy and core values in our society increasingly shaped by AI, big data, and behavioral economics. As well as the Digital Europe Programme (DIGITAL), the EU supports several projects to train AI experts and stimulate excellence (e.g. TAILOR, ELISE, HumanE-AI-Net). European countries are also making efforts to improve AI education at a national level as reported in their AI strategiesand the AI Watch investment dashboard - apparently the investments made in talent, skills, and lifelong learning represent about 60% of total investments by private and public organizations. While it is widely acknowledged that education and training are key in promoting citizens’ participation, what such an education should look like is open to discussion. This problem regards the type of knowledge and skills that we will value in the future. As the economy increasingly relies on AI, we expect that AI-related skills, such as algorithmic formalism, will take a greater role in education and culture. However, this change may favor critical processes such as the prioritization of algorithmic thinking over other forms of knowledgeand the subordination of education to business and economic interests. Note that the influence of economic drivers in the shaping of AI education could also damage the very field of AI by increasing the role of techniques and approaches with a higher economic and commercial impact and marginalizing the others. Another issue regards how to deliver AI education and training. Several resources are available online supporting self-education on AI, many offered for free. However, if this becomes the default option, some people might be excluded from AI education, such as workers who have a low level of formal education and digital skills. We should also consider to what extent people feel comfortable with the education offered, whether they experience anxiety or social pressure. Further concerns regard courses offered by big tech companies and how these can influence the public discourse on AI as well as AI research.
To address the issues connected to the shaping of AI education we recommend 1) assessing to what extent people feel conformable with existing educational resources on AI and identifying categories of the population that might be excluded; 2) increasing the integration of the humanities into computer science and AI curricula to help future tech people address broader socio-technical challenges; 3) reconsidering the incentives of research careers, now dictated by the dynamics and standards of individual disciplines, in light of multidisciplinary collaborations and societal challenges raised by techno-science.
Conclusions
This paper presents and discusses the results obtained from the PAICE questionnaire. The collected responses show that European citizens have low knowledge of AI capabilities in different applications and domains, as well as of the efforts aimed to build an ethical and regulatory framework for this technology. The analysis of our results suggests some tensions connected to broader social trends that lead to reflection on aspects that may interfere with policy efforts towards Trustworthy AI: 1) an uninformed approval recalls attention to the risks of misinformation and poor narratives about AI; 2) a disconnect from EU policy on AI brings attention to the need of high-quality communication campaigns on the AI-related harms and current EU policy and regulatory efforts; 3) a poor engagement with AI education and training strategies points to the risks of growing social and cultural inequalities.
Through the analysis of the validity and reliability of the questionnaire (PAICE) we assess the robustness of the theoretical structure identified by the working group during the design process and support the research community in the reuse of the PAICE. The validation of the questionnaire shows that for a subset of items, PAICE can be used to measure awareness, attitude, and trust towards the AI ecosystem. In addition, PAICE proves useful in providing respondents with new stimuli making them reflect upon their interaction with new technologies and its possible impact on society. At the end of the questionnaire, we repeated item Q3 investigating the perceived impact of AI, and found that 62.2% of respondents answered that AI has an impact on their daily life, an increase of 10 percentage points. In future work, we plan to extend the questionnaire to new regions and investigate country-specific differences with available data on the AI landscape.
Supplementary Material
In the following subsections, we provide the links to the supplemental material of the present research work.
Questionnaire
Text in full of the questionnaire on the Perceptions of AI by the Citizens of Europe(PAICE) translated in English: https://github.com/EU-Survey/Material/blob/main/S1_quest.pdf
Responses
Table with all aggregated responses to likert-scale / dichotomous / multi-response items and rankings: https://github.com/EU-Survey/Material/blob/main/S2_res.xlsx . For likert scale items, some descriptive statistics are also reported.
Digital skills
Table with aggregated responses related to digital skills, education and population size grouped by countries: https://github.com/EU-Survey/Material/blob/main/S3_dem.xlsx
Statistics by Groups
Table with all responses to likert scale items aggregated by countries / age groups / gender with p-values: https://github.com/EU-Survey/Material/blob/main/S4_comp.xlsx Responses are presented with respect to the dimension considered (awareness, attitude, and trust).
Exploratory Factor Analysis: Table
Table with the results of the Exploratory Factor Analysis: https://github.com/EU-Survey/Material/blob/main/S5_efa.xlsx . Exploratory factor analysis (EFA) is based on the polychoric matrix which uses principal axis factoring with oblique rotation
Exploratory Factor Analysis: Figure
Plot of Exploratory Factor Analysis: https://github.com/EU-Survey/Material/blob/main/S6_efa.pdf
Bibliography
1@article{luchs2023learning,
2 publisher = {SAGE Publications Sage UK: London, England},
3 year = {2023},
4 pages = {20539517231153806},
5 number = {1},
6 volume = {10},
7 journal = {Big Data \& Society},
8 author = {Luchs, Inga and Apprich, Clemens and Broersma, Marcel},
9 title = {Learning machine learning: On the political economy of big tech's online AI courses},
10}
11
12@article{konig2022consumers,
13 publisher = {SAGE Publications Sage UK: London, England},
14 year = {2022},
15 pages = {20539517211069632},
16 number = {1},
17 volume = {9},
18 journal = {Big Data \& Society},
19 author = {K{\"o}nig, Pascal D and Wurster, Stefan and Siewert, Markus B},
20 title = {Consumers are willing to pay a price for explainable, but not for green AI. Evidence from a choice-based conjoint analysis},
21}
22
23@article{brevini2020black,
24 publisher = {SAGE Publications Sage UK: London, England},
25 year = {2020},
26 pages = {2053951720935141},
27 number = {2},
28 volume = {7},
29 journal = {Big Data \& Society},
30 author = {Brevini, Benedetta},
31 title = {Black boxes, not green: Mythologizing artificial intelligence and omitting the environment},
32}
33
34@article{kerr2020expectations,
35 publisher = {Sage Publications Sage UK: London, England},
36 year = {2020},
37 pages = {2053951720915939},
38 number = {1},
39 volume = {7},
40 journal = {Big Data \& Society},
41 author = {Kerr, Aphra and Barry, Marguerite and Kelleher, John D},
42 title = {Expectations of artificial intelligence and the performativity of ethics: Implications for communication governance},
43}
44
45@article{kieslich2022artificial,
46 publisher = {SAGE Publications Sage UK: London, England},
47 year = {2022},
48 pages = {20539517221092956},
49 number = {1},
50 volume = {9},
51 journal = {Big Data \& Society},
52 author = {Kieslich, Kimon and Keller, Birte and Starke, Christopher},
53 title = {Artificial intelligence ethics by design. Evaluating public perception on the importance of ethical design principles of artificial intelligence},
54}
55
56@article{cleaver1999paradoxes,
57 publisher = {Wiley Online Library},
58 year = {1999},
59 pages = {597--612},
60 number = {4},
61 volume = {11},
62 journal = {Journal of International Development: The Journal of the Development Studies Association},
63 author = {Cleaver, Frances},
64 title = {Paradoxes of participation: questioning participatory approaches to development},
65}
66
67@inproceedings{simbeck2022facct,
68 year = {2022},
69 pages = {89--96},
70 booktitle = {2022 ACM Conference on Fairness, Accountability, and Transparency},
71 author = {Simbeck, Katharina},
72 title = {FAccT-Check on AI regulation: Systematic Evaluation of AI Regulation on the Example of the Legislation on the Use of AI in the Public Sector in the German Federal State of Schleswig-Holstein},
73}
74
75@inproceedings{png2022tensions,
76 year = {2022},
77 pages = {1434--1445},
78 booktitle = {2022 ACM Conference on Fairness, Accountability, and Transparency},
79 author = {Png, Marie-Therese},
80 title = {At the Tensions of South and North: Critical Roles of Global South Stakeholders in AI Governance},
81}
82
83@inproceedings{jakesch2022different,
84 year = {2022},
85 pages = {310--323},
86 booktitle = {2022 ACM Conference on Fairness, Accountability, and Transparency},
87 author = {Jakesch, Maurice and Bu{\c{c}}inca, Zana and Amershi, Saleema and Olteanu, Alexandra},
88 title = {How different groups prioritize ethical values for responsible AI},
89}
90
91@article{dietvorst2015algorithm,
92 publisher = {American Psychological Association},
93 year = {2015},
94 pages = {114},
95 number = {1},
96 volume = {144},
97 journal = {Journal of Experimental Psychology: General},
98 author = {Dietvorst, Berkeley J and Simmons, Joseph P and Massey, Cade},
99 title = {Algorithm aversion: people erroneously avoid algorithms after seeing them err.},
100}
101
102@article{longoni2019resistance,
103 publisher = {Oxford University Press},
104 year = {2019},
105 pages = {629--650},
106 number = {4},
107 volume = {46},
108 journal = {Journal of Consumer Research},
109 author = {Longoni, Chiara and Bonezzi, Andrea and Morewedge, Carey K},
110 title = {Resistance to medical artificial intelligence},
111}
112
113@article{boyd2012critical,
114 publisher = {Taylor \& Francis},
115 year = {2012},
116 pages = {662--679},
117 number = {5},
118 volume = {15},
119 journal = {Information, communication \& society},
120 author = {Boyd, Danah and Crawford, Kate},
121 title = {Critical questions for big data: Provocations for a cultural, technological, and scholarly phenomenon},
122}
123
124@inproceedings{green2020algorithmic,
125 year = {2020},
126 pages = {19--31},
127 booktitle = {Proceedings of the 2020 conference on fairness, accountability, and transparency},
128 author = {Green, Ben and Viljoen, Salom{\'e}},
129 title = {Algorithmic realism: expanding the boundaries of algorithmic thought},
130}
131
132@article{joshi2015,
133 publisher = {SCIENCEDOMAIN International},
134 year = {2015},
135 pages = {396},
136 number = {4},
137 volume = {7},
138 journal = {British journal of applied science \& technology},
139 author = {Joshi, Ankur and Kale, Saket and Chandel, Satish and Pal, D Kumar},
140 title = {Likert scale: Explored and explained},
141}
142
143@inproceedings{cave2019scary,
144 series = {AIES '19},
145 location = {Honolulu, HI, USA},
146 keywords = {AI ethics, AI policy, science communication, public perception},
147 numpages = {7},
148 pages = {331–337},
149 booktitle = {Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society},
150 doi = {10.1145/3306618.3314232},
151 url = {https://doi.org/10.1145/3306618.3314232},
152 address = {New York, NY, USA},
153 publisher = {Association for Computing Machinery},
154 isbn = {9781450363242},
155 year = {2019},
156 title = {"Scary Robots": Examining Public Responses to AI},
157 author = {Cave, Stephen and Coughlan, Kate and Dihal, Kanta},
158}
159
160@inproceedings{zhang2020us,
161 series = {AIES '20},
162 location = {New York, NY, USA},
163 keywords = {ai governance, public opinion, public trust},
164 numpages = {7},
165 pages = {187–193},
166 booktitle = {Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society},
167 abstract = {Artificial intelligence (AI) has widespread societal implications, yet social scientists
168are only beginning to study public attitudes toward the technology. Existing studies
169find that the public's trust in institutions can play a major role in shaping the
170regulation of emerging technologies. Using a large-scale survey (N=2000), we examined
171Americans' perceptions of 13 AI governance challenges as well as their trust in governmental,
172corporate, and multistakeholder institutions to responsibly develop and manage AI.
173While Americans perceive all of the AI governance issues to be important for tech
174companies and governments to manage, they have only low to moderate trust in these
175institutions to manage AI applications.},
176 doi = {10.1145/3375627.3375827},
177 url = {https://doi.org/10.1145/3375627.3375827},
178 address = {New York, NY, USA},
179 publisher = {Association for Computing Machinery},
180 isbn = {9781450371100},
181 year = {2020},
182 title = {U.S. Public Opinion on the Governance of Artificial Intelligence},
183 author = {Zhang, Baobao and Dafoe, Allan},
184}
185
186@inproceedings{kelley2021exciting,
187 series = {AIES '21},
188 location = {Virtual Event, USA},
189 keywords = {artificial intelligence, public perception},
190 numpages = {11},
191 pages = {627–637},
192 booktitle = {Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society},
193 abstract = {As the influence and use of artificial intelligence (AI) have grown and its transformative
194potential has become more apparent, many questions have been raised regarding the
195economic, political, social, and ethical implications of its use. Public opinion plays
196an important role in these discussions, influencing product adoption, commercial development,
197research funding, and regulation. In this paper we present results of an in-depth
198survey of public opinion of artificial intelligence conducted with 10,005 respondents
199spanning eight countries and six continents. We report widespread perception that
200AI will have significant impact on society, accompanied by strong support for the
201responsible development and use of AI, and also characterize the public's sentiment
202towards AI with four key themes (exciting, useful, worrying, and futuristic) whose
203prevalence distinguishes response to AI in different countries.},
204 doi = {10.1145/3461702.3462605},
205 url = {https://doi.org/10.1145/3461702.3462605},
206 address = {New York, NY, USA},
207 publisher = {Association for Computing Machinery},
208 isbn = {9781450384735},
209 year = {2021},
210 title = {Exciting, Useful, Worrying, Futuristic: Public Perception of Artificial Intelligence in 8 Countries},
211 author = {Kelley, Patrick Gage and Yang, Yongwei and Heldreth, Courtney and Moessner, Christopher and Sedley, Aaron and Kramm, Andreas and Newman, David T. and Woodruff, Allison},
212}
213
214@article{european2017special,
215 publisher = {Publications Office of the European Union Luxembourg},
216 year = {2017},
217 author = {{European Commission}},
218 title = {Special Eurobarometer 460-Attitudes Towards the Impact of Digitisation and Automation on Daily Life.},
219}
220
221@article{european2021special,
222 publisher = {Publications Office of the European Union Luxembourg},
223 year = {2021},
224 author = {{European Commission}},
225 title = {Special Eurobarometer 516-European citizens’ knowledge and attitudes towards science and technology.},
226}
227
228@article{european2019,
229 publisher = {Publications Office of the European Union Luxembourg},
230 year = {2019},
231 author = {{European Commission}},
232 title = {Standard Eurobarometer 92. Europeans and Artificial Intelligence},
233}
234
235@article{Gadermann2012,
236 year = {2012},
237 pages = {3},
238 number = {1},
239 volume = {17},
240 journal = {Practical Assessment, Research, and Evaluation},
241 author = {Gadermann, Anne M and Guhn, Martin and Zumbo, Bruno D},
242 title = {Estimating ordinal reliability for Likert-type and ordinal item response data: A conceptual, empirical, and practical guide},
243}
244
245@article{Zumbo2007,
246 year = {2007},
247 pages = {4},
248 number = {1},
249 volume = {6},
250 journal = {Journal of modern applied statistical methods},
251 author = {Zumbo, Bruno D and Gadermann, Anne M and Zeisser, Cornelia},
252 title = {Ordinal versions of coefficients alpha and theta for Likert rating scales},
253}
254
255@article{Taasoobshirazi2016,
256 publisher = {Association for Development through Science and Education, Romania (ADSER)},
257 year = {2016},
258 pages = {31--39},
259 number = {3},
260 volume = {11},
261 journal = {Journal of Applied Quantitative Methods},
262 author = {Taasoobshirazi, Gita and Wang, Shanshan},
263 title = {The performance of the SRMR, RMSEA, CFI, and TLI: An examination of sample size, path size, and degrees of freedom},
264}
265
266@article{Timmerman2011,
267 publisher = {American Psychological Association},
268 year = {2011},
269 pages = {209},
270 number = {2},
271 volume = {16},
272 journal = {Psychological methods},
273 author = {Timmerman, Marieke E and Lorenzo-Seva, Urbano},
274 title = {Dimensionality assessment of ordered polytomous items with parallel analysis.},
275}
276
277@article{schepman2020initial,
278 keywords = {Artificial intelligence, Psychometrics, Questionnaire, Index, Attitudes, Perception},
279 author = {Astrid Schepman and Paul Rodway},
280 url = {https://www.sciencedirect.com/science/article/pii/S2451958820300142},
281 doi = {https://doi.org/10.1016/j.chbr.2020.100014},
282 issn = {2451-9588},
283 year = {2020},
284 pages = {100014},
285 volume = {1},
286 journal = {Computers in Human Behavior Reports},
287 title = {Initial validation of the general attitudes towards Artificial Intelligence Scale},
288}
289
290@misc{Trustworthy_EU,
291 year = {2019},
292 date-modified = {2020-14-06 00:08:57 +0000},
293 date-added = {2020-14-06 00:08:57 +0000},
294 author = {{High-Level Expert Group on Artificial Intelligence}},
295 url = {https://ec.europa.eu/digital-single-market/en/news/ethics-guidelines-trustworthy-ai},
296 title = {Ethics {G}uidelines for {T}rustworthy {AI}},
297}
298
299@misc{Whitepaper_EU,
300 year = {2019},
301 date-modified = {2020-16-06 00:12:10 +0000},
302 date-added = {2020-16-06 00:12:12 +0000},
303 author = {{European Commission}},
304 url = {https://ec.europa.eu/info/sites/info/files/commission-white-paper-artificial-intelligence-feb2020_en.pdf},
305 title = {White {P}aper on {A}rtificial {I}ntelligence -
306{A} {E}uropean {A}pproach to {E}xcellence and {T}rust},
307}
308
309@misc{ai_act,
310 year = {2021},
311 date-added = {2021-21-04 00:12:12 +0000},
312 author = {{European Parliament}},
313 url = {https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=celex\%3A52021PC0206},
314 title = {Proposal for a regulation of the European Parliament and of the Council laying down harmonised rules on artificial intelligence (artificial intelligence act) and amending certain union legislative acts},
315}
316
317@misc{ec2019building,
318 year = {2019},
319 author = {{European Commission}},
320 url = {https://digital-strategy.ec.europa.eu/en/library/communication-building-trust-human-centric-artificial-intelligence},
321 title = {Building Trust in Human-Centric Artificial Intelligence},
322}
323
324@misc{ai_agenda,
325 year = {2018},
326 date-added = {2018-25-04 00:12:12 +0000},
327 author = {{European Commission}},
328 url = {https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=COM\%3A2018\%3A237\%3AFIN},
329 title = {Communication from the Commission to the European Parliament, the European Council, the Council, the European Economic and Social Committee and the Committee of the Regions. Artificial intelligence for Europe},
330}
331
332@book{nunnally1994,
333 publisher = {Tata McGraw-hill education},
334 year = {1994},
335 author = {Nunnally, Jum C},
336 title = {Psychometric theory 3E},
337}
338
339@techreport{TRS,
340 year = {2018},
341 title = {Portrayals and perceptions of {AI} and why they matter},
342 author = {The {R}oyal {S}ociety},
343}
344
345@inproceedings{10.5555/3298239.3298381,
346 series = {AAAI'17},
347 location = {San Francisco, California, USA},
348 numpages = {7},
349 pages = {963–969},
350 booktitle = {Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence},
351 publisher = {AAAI Press},
352 year = {2017},
353 title = {Long-Term Trends in the Public Perception of Artificial Intelligence},
354 author = {Fast, Ethan and Horvitz, Eric},
355}
356
357@article{Foffano22,
358 doi = {10.1007/s00146-022-01445-8},
359 journal = {AI \& Society},
360 title = {Investing in AI for Social Good: An Analysis of European National Strategies},
361 author = {Francesca Foffano and Teresa Scantamburlo and Atia Cort\'{e}s},
362 year = {2022},
363}
364
365@article{cristianini2020social,
366 publisher = {Springer},
367 year = {2020},
368 pages = {645--662},
369 volume = {35},
370 journal = {AI \& SOCIETY},
371 author = {Cristianini, Nello and Scantamburlo, Teresa},
372 title = {On social machines for algorithmic regulation},
373}
374
375@article{hongladarom23,
376 doi = {10.1007/s00146-023-01665-6},
377 journal = {AI \& Society},
378 title = {Non-western AI ethics guidelines: implications for intercultural ethics of technology},
379 author = {Soraj Hongladarom and Jerd Bandasak},
380 year = {2023},
381}
382
383@article{ch2016,
384 doi = {https://doi.org/10.3758/s13428-015-0619-7},
385 pages = {936-949},
386 volume = {48},
387 journal = {Behavior Research Methods volume},
388 title = {Confirmatory factor analysis with ordinal data: Comparing robust maximum likelihood and diagonally weighted least squares},
389 author = {Li, CH},
390 year = {2016},
391}
392
393@book{Tinsley2020,
394 publisher = {London: Academic Press},
395 year = {2020},
396 author = {Tinsley, H. E. and Brown, S. D.},
397 title = {Research Methods in Education 8 edition},
398}
399
400@book{Likert,
401 publisher = {New York: Columbia University Press},
402 year = {1932},
403 author = {Likert, Rensis},
404 title = {A Technique for the Measurement of Attitudes},
405}
406
407@article{Biasutti2017,
408 pages = {214–230},
409 volume = {23(2)},
410 journal = {Environmental Education Research},
411 title = {A validity and reliability study of the attitudes toward sustainable development scale.},
412 author = {Biasutti, Michele and Frate, Sara},
413 year = {2017},
414}
415
416@book{Brown2015,
417 publisher = {Guilford publications},
418 year = {2015},
419 author = {Brown, Timothy A},
420 title = {Confirmatory factor analysis for applied research},
421}
422
423@article{Fabrigar1999,
424 publisher = {American Psychological Association},
425 year = {1999},
426 pages = {272},
427 number = {3},
428 volume = {4},
429 journal = {Psychological methods},
430 author = {Fabrigar, Leandre R and Wegener, Duane T and MacCallum, Robert C and Strahan, Erin J},
431 title = {Evaluating the use of exploratory factor analysis in psychological research.},
432}
433
434@article{Kaiser1974,
435 publisher = {Springer},
436 year = {1974},
437 pages = {31--36},
438 number = {1},
439 volume = {39},
440 journal = {Psychometrika},
441 author = {Kaiser, Henry F},
442 title = {An index of factorial simplicity},
443}
444
445@article{Fabrigar,
446 publisher = {American Psychological Association},
447 year = {1999},
448 pages = {272},
449 number = {3},
450 volume = {4},
451 journal = {Psychological methods},
452 author = {Fabrigar, Leandre R and Wegener, Duane T and MacCallum, Robert C and Strahan, Erin J},
453 title = {Evaluating the use of exploratory factor analysis in psychological research.},
454}
455
456@article{joreskog1994,
457 doi = {https://doi.org/10.1007/BF02296131},
458 pages = {381-389},
459 volume = {59},
460 journal = {Psychometrika},
461 title = {On the estimation of polychoric correlations and their asymptotic covariance matrix},
462 author = {J{\"o}reskog, K.G},
463 year = {2016},
464}
465
466@book{cohen2017,
467 address = {Milton Park, AB, USA},
468 publisher = {Routledge},
469 year = {2017},
470 author = {Cohen, L. and Manion, L. and Morrison, K.},
471 title = {Research Methods in Education 8 edition},
472}
473
474@misc{eurostat2021educational,
475 year = {2021},
476 author = {Eurostat},
477 url = {https://ec.europa.eu/eurostat/statistics-explained/index.php?title=Educational_attainment_statistics#Level_of_educational_attainment_by_age},
478 title = {Educational attainment statistics},
479}
480
481@article{cheng2022shaping,
482 publisher = {Taylor \& Francis},
483 year = {2022},
484 pages = {1--17},
485 journal = {Journal of Contemporary China},
486 author = {Cheng, Jing and Zeng, Jinghan},
487 title = {Shaping AI’s Future? China in Global AI Governance},
488}
489
490@misc{AlgoAct,
491 author = {{US Congress}},
492 year = {2022},
493 url = {https://www.congress.gov/bill/117th-congress/house-bill/6580/text},
494 title = {Text - H.R.6580 - 117th Congress (2021-2022): Algorithmic Accountability Act of 2022},
495}
496
497@misc{AIwatch2021,
498 author = {{Joint Research Centre}},
499 year = {2022},
500 url = {https://ai-watch.ec.europa.eu/publications/ai-watch-index-2021_en},
501 title = {AI Watch Index 2021},
502}
503
504@article{sartori2022,
505 publisher = {Springer},
506 year = {2022},
507 pages = {1--16},
508 journal = {AI \& SOCIETY},
509 author = {Sartori, Laura and Bocca, Giulia},
510 title = {Minding the gap (s): public perceptions of AI and socio-technical imaginaries},
511}
512
513@article{lockey2021review,
514 year = {2021},
515 author = {Lockey, Steven and Gillespie, Nicole and Holm, Daniel and Someh, Ida Asadi},
516 title = {A review of trust in artificial intelligence: Challenges, vulnerabilities and future directions},
517}
518
519@article{hagendorff2020ethics,
520 publisher = {Springer},
521 year = {2020},
522 pages = {99--120},
523 number = {1},
524 volume = {30},
525 journal = {Minds and Machines},
526 author = {Hagendorff, Thilo},
527 title = {The ethics of AI ethics: An evaluation of guidelines},
528}
529
530@article{zhang2019artificial,
531 year = {2019},
532 journal = {Available at SSRN 3312874},
533 author = {Zhang, Baobao and Dafoe, Allan},
534 title = {Artificial intelligence: American attitudes and trends},
535}
536
537@article{siau2018building,
538 year = {2018},
539 pages = {47--53},
540 number = {2},
541 volume = {31},
542 journal = {Cutter business technology journal},
543 author = {Siau, Keng and Wang, Weiyu},
544 title = {Building trust in artificial intelligence, machine learning, and robotics},
545}
546
547@inproceedings{jacovi2021formalizing,
548 year = {2021},
549 pages = {624--635},
550 booktitle = {Proceedings of the 2021 ACM conference on fairness, accountability, and transparency},
551 author = {Jacovi, Alon and Marasovi{\'c}, Ana and Miller, Tim and Goldberg, Yoav},
552 title = {Formalizing trust in artificial intelligence: Prerequisites, causes and goals of human trust in AI},
553}
554
555@article{gille2020we,
556 publisher = {Elsevier},
557 year = {2020},
558 pages = {100001},
559 volume = {1},
560 journal = {Intelligence-Based Medicine},
561 author = {Gille, Felix and Jobin, Anna and Ienca, Marcello},
562 title = {What we talk about when we talk about trust: Theory of trust for AI in healthcare},
563}
564
565@article{glikson2020human,
566 publisher = {Briarcliff Manor, NY},
567 year = {2020},
568 pages = {627--660},
569 number = {2},
570 volume = {14},
571 journal = {Academy of Management Annals},
572 author = {Glikson, Ella and Woolley, Anita Williams},
573 title = {Human trust in artificial intelligence: Review of empirical research},
574}
575
576@article{lee2018understanding,
577 publisher = {SAGE Publications Sage UK: London, England},
578 year = {2018},
579 pages = {2053951718756684},
580 number = {1},
581 volume = {5},
582 journal = {Big Data \& Society},
583 author = {Lee, Min Kyung},
584 title = {Understanding perception of algorithmic decisions: Fairness, trust, and emotion in response to algorithmic management},
585}
586
587@techreport{bogen2018help,
588 year = {2018},
589 institution = {Upturn},
590 title = {Help Wanted: An Examination of Hiring Algorithms, Equity, and Bias},
591 author = {Bogen, Miranda and Rieke, Aaron},
592}
593
594@article{khan2019smart,
595 publisher = {IEEE},
596 year = {2019},
597 pages = {2631--2644},
598 volume = {8},
599 journal = {IEEE Access},
600 author = {Khan, Zafar A and Jayaweera, Dilan},
601 title = {Smart meter data based load forecasting and demand side management in distribution networks with embedded PV systems},
602}
603
604@article{funk2009public,
605 publisher = {HeinOnline},
606 year = {2009},
607 pages = {171},
608 volume = {61},
609 journal = {Admin. L. Rev.},
610 author = {Funk, William},
611 title = {Public participation and transparency in administrative law-Three examples as an object lesson},
612}
613
614@article{zwitter2012rule,
615 publisher = {JSTOR},
616 year = {2012},
617 pages = {95--111},
618 journal = {ARSP: Archiv F{\"u}r Rechts-Und Sozialphilosophie/Archives for Philosophy of Law and Social Philosophy},
619 author = {Zwitter, Andrej},
620 title = {The Rule of Law in Times of Crisis: A Legal Theory on the State of Emergency in the Liberal Democracy},
621}
622
623@inproceedings{kim2021and,
624 year = {2021},
625 pages = {15569--15576},
626 number = {17},
627 volume = {35},
628 booktitle = {proceedings of the AAAI Conference on Artificial Intelligence},
629 author = {Kim, Seonghun and Jang, Yeonju and Kim, Woojin and Choi, Seongyune and Jung, Heeseok and Kim, Soohwan and Kim, Hyeoncheol},
630 title = {Why and what to teach: AI curriculum for elementary school},
631}
632
633@book{helbing2019will,
634 publisher = {Springer},
635 year = {2019},
636 author = {Helbing, Dirk and Frey, Bruno S and Gigerenzer, Gerd and Hafen, Ernst and Hagner, Michael and Hofstetter, Yvonne and Van Den Hoven, Jeroen and Zicari, Roberto V and Zwitter, Andrej},
637 title = {Will democracy survive big data and artificial intelligence?},
638}
639
640@article{krarup2023european,
641 publisher = {SAGE Publications Sage UK: London, England},
642 year = {2023},
643 pages = {20539517231153811},
644 number = {1},
645 volume = {10},
646 journal = {Big Data \& Society},
647 author = {Krarup, Troels and Horst, Maja},
648 title = {European artificial intelligence policy as digital single market making},
649}Attribution
arXiv:2308.09979v1
[cs.CY]
License: cc-by-4.0


