
- Papers
Papers is Alpha. This content is part of an effort to make research more accessible, and (most likely) has lost some details from the original. You can find the original paper here.
Introduction
In the past decade, there has been widespread proliferation of artificial intelligence (AI) systems into the private and public sectors. These systems have been implemented in a broad range of contexts, including employment, healthcare, lending, criminal justice, and more. The rapid development and implementation of AI technologies has greatly outpaced public oversight, creating a “wild-west”-style regulatory environment. As policy makers struggle to catch up, the issues of unregulated AI have become glaringly obvious, especially for underprivileged and marginalized communities. Famously, ProPublica revealed that the AI-driven system COMPAS used to assess the likelihood of a prisoner recidivating was highly discriminatory against black individuals. In another example, Amazonbuilt and implemented an automated resume screening and hiring AI system–only to later find out that the system was biased against hiring women. In an effort to address these issues, countries around the world have begun regulating the use of AI systems. Over 50 nations and intergovernmental organizations have published AI strategies, actions plans, policy papers or directives. A survey of existing and proposed regulation around AI transparency is given in Section sec-laws.
Unfortunately, most strategies, directives and laws to date lack specificity on how AI regulation should be carried out in practice by technologists. Where there is specificity, there is a lack of mechanisms for enforcing laws and holding institutions using AI accountable.Documents on AI governance have focused on what to do (or what not to do) with respect to AI, but leave the brunt of the work to practitioners to figure out how things should be done. This tension plays out heavily in regulations governing the transparency of AI systems (called “explainability” by AI practitioners). The most prominent example of this is the “right to explanation” of data use that is included in the EU’s General Data Protection Regulation (GDPR). Despite being passed into law in 2016, the meaning and scope of the right is still being debated by legal scholars, with little of the discussion resulting in concrete benefits for citizens.
While regulation can help weigh the benefits of new technology against the risks, developingeffective regulation is difficult, as is establishing effective mechanisms to comply with existing regulation. This paper aims to fill a gap in the existing literature by writing to technologists and AI practitioners about the existing AI regulatory landscape, and speaks to their role in designing complaint systems. We make a case for why AI practitioners should be leading efforts to ensure the transparency of AI systems, and to this end, we propose a novel framework for implementing regulatory-compliant explanations for stakeholders. We also consider an instantiation of our stakeholder-first approach in the context of a real-world example using work done by a national employment agency.
We make the following three contributions: (1) provide a survey of existing and proposed regulations on the transparency and explainability of AI systems; (2) propose a novel framework for a stakeholder-first approach to designing transparent AI systems; and (3) present a case-study that illustrates how this stakeholder-first approach could be used in practice.
Existing and Emerging Regulations
In recent years, countries around the world have increasingly been drafting strategies, action plans, and policy directives to govern the use of AI systems. To some extent, regulatory approaches vary by country and region. For example, policy strategies in the US and the EU reflect their respective strengths: free-market ideas for the former, and citizen voice for the latter. Yet, despite country-level variation, many AI policies contain similar themes and ideas. A meta-analysis of over 80 AI ethics guidelines and soft-laws found that 87% mention transparency, and include an effort to increase the explainability of AI systems. Unfortunately, all documents to date have one major limitation: they are filled with uncertainty on how transparency and explainability should actually be implemented in a way that is compliant with the evolving regulatory landscape. This limitation has 3 main causes: (1) it is difficult to design transparency regulations that can easily be standardized across different fields of AI, such as self-driving cars, robotics, and predictive modeling; (2) when it comes to transparency, there is a strong information asymmetry between technologists and policymakers, and, ultimately, the individuals who are impacted by AI systems; (3) there is no normative consensus around AI transparency, and most policy debates are focused on the risks of AI rather than the opportunities. For the purposes of scope, we will focus on regulations in the United States and Europe. However, its important noting that there is meaningful AI regulation emerging in Latin and South America, Asia, Africa, and beyond, and summarizing those regulations is an avenue for future work. For example, in 2021, Chile presented it’s first national action plan on AI policy [https://www.gob.cl/en/news/chile-presents-first-national-policy-artificial-intelligence/ ].
United States
In 2019 the US took two major steps in the direction of AI regulation. First, Executive Order 13859 was issued with the purpose of establishing federal principles for AI systems, and to promote AI research, economic competitiveness, and national security. Importantly, the order mandates that AI algorithms implemented for use by public bodies must be “understandable”, “transparent”, “responsible”, and “accountable.” Second, the Algorithmic Accountability Act of 2019 was introduced to the House of Representatives, and more recently reintroduced under the name Algorithmic Accountability Act of 2022. If passed into law, the Algorithmic Accountability Act would be a landmark legalisation for AI regulation in the US. The purpose of the bill is to create transparency and prevent disparate outcomes for AI systems, and it would require companies to assess the impacts of the AI systems they use and sell. The bill describes the impact assessment in detail — which must be submitted to an oversight committee— and states that the assessment must address “the transparency and explainability of [an AI system] and the degree to which a consumer may contest, correct, or appeal a decision or opt out of such system or process”, which speaks directly to what AI practitioners refer to as “recourse”, or the ability of an individual to understand the outcome of an AI system and what they could do to change that outcome.
In 2019 the OPEN Government Data Act was passed into law, requiring that federal agencies maintain and publish their information online as open data. The data also must be cataloged on Data.gov, a public data repository created by the the US government. While this law only applies to public data, it demonstrates how policy can address transparency within the whole pipeline of an AI system, from the data to the algorithm to the system outcome.
There are also some industry-specific standards for transparency that could act as a model for future cross-industry regulations. Under the Equal Credit Opportunity Act, creditors who deny loan applicants must provide a specific reason for the denial. This includes denials made by AI systems. The explanations for a denial come from a standardized list of numeric reason codes, such as: “U4: Too many recently opened accounts with balances[https://www.fico.com/en/latest-thinking/solution-sheet/us-fico-score-reason-codes ].”
European Union
In 2019 the EU published a white paper titled “Ethics Guidelines for Trustworthy AI,” containing a legal framework that outlines ethical principles and legal obligations for EU member states to follow when deploying AI[https://ec.europa.eu/digital-single-market/en/news/ethics-guidelines-trustworthy-ai ]. While the white paper is non-binding, it lays out expectations on how member-states should regulate the transparency of AI systems: “… data, system and AI business models should be transparent. Traceability mechanisms can help achieving this. Moreover, AI systems and their decisions should be explained in a manner adapted to the stakeholder concerned. Humans need to be aware that they are interacting with an AI system, and must be informed of the system’s capabilities and limitations.”
Currently, the European Commission is reviewing the Artificial Intelligence Act[https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A52021PC0206 ], which would create a common legal framework for governing all types of AI used in all non-military sectors in Europe. The directive takes the position that AI systems pose a significant risk to the health, safety and fundamental rights of persons, and governs from that perspective. With respect to transparency, the directive delineates between non-high-risk and high-risk AI systems (neither of which are rigorously defined at this time). It states that for “non-high-risk AI systems, only very limited transparency obligations are imposed, for example in terms of the provision of information to flag the use of an AI system when interacting with humans.” Yet, for high-risk systems, “the requirements of high quality data, documentation and traceability, transparency, human oversight, accuracy and robustness, are strictly necessary to mitigate the risks to fundamental rights and safety posed by AI and that are not covered by other existing legal frameworks.” Notably, as in the Algorithmic Accountability Act in the United States, the document contains explicit text mentioning recourse (referred to as “redress”) for persons affected by AI systems.
The EU has also passed Regulation (EU) 2019/1150 that sets guidelines for the transparency of rankings for online search.[https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A32019R1150 ] In practice, this means that online stores and search engines should be required to disclose the algorithmic parameters used to rank goods and services on their site. The regulation also states that explanations about rankings should contain redress mechanisms for individuals and businesses affected by the rankings.
Right to Explanation.
The Right to Explanation is a proposed fundamental human right that would guarantee individuals access to an explanation for any AI system decision that affects them. The Right to Explanation was written into the EU’s 2016 GDPR regulations, and reads as follows: “[the data subject should have] the right … to obtain an explanation of the decision reached.”[https://www.privacy-regulation.eu/en/r71.htm ] The legal meaning and obligation of the text has been debated heavily by legal scholars, who are unsure under which circumstances it applies, what constitutes an explanation, and how the right is applicable to different AI systems. The Right to Explanation is an example of how emerging AI technologies may “reveal” additional rights that need to be considered by lawmakers and legal experts.
The EU’s recently proposed Artificial Intelligence Act simultaneously reinforces the idea that explanations about AI systems are a human right, while slightly rolling back the Right to Explanation by acknowledging that there are both non-high-risk and high-risk AI systems. Discussions about the Right are likely to continue, and will be a central part of debates on regulating AI transparency. In fact, some local governing bodies have already taken steps to adopt the Right to Explanation. France passed the Digital Republic Act in 2016, which gives the Right to Explanation for individuals affected by an AI system in the public sector. Hungary also has a similar law.
Local
There has been significant movement on the regulation of specific forms of AI systems at local levels of government. In response to the well-documented biases of facial recognition software when identifying people of different races and ethnicities, Washington State signed Senate Bill 6820 into law in 2020, which prohibits the use of facial recognition software in surveillance and limits its use in criminal investigation.[<https://app.leg.wa.gov/billsummary?BillNumber=6280 Initiative=false Year=2019>] Detroit has also reacted to concerns about facial recognition, and its City Council approved legislation that mandates transparency and accountability for the procurement process of video and camera surveillance contracts used in the city.[https://www.detroitnews.com/story/news/local/detroit-city/2021/05/25/detroit-council-approves-ordinance-boost-transparency-surveillance-camera-contracts/7433185002/ ] The New York City Council recently regulated the use of AI systems in relation to employment decisions (Local Law 144 of 2021).[<https://legistar.council.nyc.gov/LegislationDetail.aspx?ID=4344524 GUID=B051915D-A9AC-451E-81F8-6596032FA3F9 Options=Advanced Search>] The bill requires that AI tools for hiring employees be subject to yearly bias audits. An additional requirement is to notify job seekers that they were screened by a tool, and to disclose to them what “qualifications or characteristics” were used by the tool as basis of decisions. Finally, in the Netherlands, the municipality of Rotterdam has created a Data-Driven Working program which has been critical of transparency surrounding the algorithms used for fraud detection.[https://nos.nl/artikel/2376810-rekenkamer-rotterdam-risico-op-vooringenomen-uitkomsten-door-gebruik-algoritmes ]
The Role of Technologists
The continuously evolving regulatory landscape of AI, combined with the limitations of existing regulation in providing clarity on how transparency should be implemented into AI systems, has left open questions concerning responsibilities for AI design and implementation. We argue that (1) practitioners should bear the bulk of the responsibility for designing and implementing compliant, transparent AI systems (2) it is in the best interest of practitioners to bear this responsibility. Researchers have also shown that there may be risks of only partially complying with AI regulations, and that fusll compliance is the best way forward. Technologists include AI practitioners, researchers, designers, programmers, and developers.
Practitioners have the right technical expertise. Transparency has been a central topic of AI research for the past decade, and is motivated beyond just regulatory compliance by ideas like making systems more efficient, debugging systems, and giving decision making agency to the data subjects (i.e., those affected by AI-assisted decisions) or to the users of AI systems (i.e., those making decisions with the help of AI). New technologies in transparent AI are being created at a fast pace, and there is no indication that the rapid innovation of explainable AI will slow any time soon, meaning that of all the stakeholders involved in the socio-technical environment of AI systems, technologists are the most likely to be aware of available tools for creating transparent AI systems. Furthermore, there are currently no objective measures for the quality of transparency in AI systems, and so technologists are necessary to discern the difference between a “good explanation” and a “bad explanation” about a system.
Practitioners are the least-cost avoiders. This idea is based on the principle of the least-cost avoider, which states that obligations and liabilities should be allocated entirely to the party with the lowest cost of care. AI practitioners are the least-cost avoiders because they are already equipped with the technical know-how for building and implementing transparency tools into AI systems, especially when compared to policymakers and the individuals affected by the outcome of the system. Notably, given the wide range of existing transparency tools, implementing the “bare minimum” is trivially easy for most technologists.
One argument practitioners give against building transparent systems is that they may be less accurate than highly complex, black-box systems. However, there has been a growing amount of evidence suggesting that building transparent systems actually results into little to no trade-off in the accuracy of AI systems. In other words: building transparent systems is not a Pareto-reducing constraint for practitioners.
Practitioners already bear the responsibility for implementing transparency into AI systems. A study interviewing AI practitioners found that using AI responsibly in their work is viewed as the practitioner’s burden, not the institutions for which they work. Practitioners noted that existing structures within institutions are often antithetical to the goals of responsible AI, and that it is up to them to push for structural change within that institution. Section sec-laws shows that AI regulation is converging on requiring transparent AI systems that offer meaningful explanations to stakeholders. Therefore, it is in the best interest of practitioners to continue the bottom-up approach of building transparent AI systems in the face of looming regulations.
A Stakeholder-First Approach to Designing Transparent ADS
Definitions
Technologists and AI researchers have not agreed on a definition of transparency for AI systems. Instead, a number of terms have been used, including explainability, interpretability, intelligibility, understandability, and comprehensibility. There is no consensus on the meaning of these terms and they are often defined differently by different authors or used interchangeably. Furthermore, transparency and its related terms cannot trivially be quantified or measured, and transparency for one stakeholder does not automatically imply the same for different stakeholders.
While having multiple definitions of transparency has been useful for distinguishing nuance in a research setting, it also poses a challenge for policy making. In contrast to technologists, policymakers favor definitions of transparency that are about human thought and behavior such as accountability or legibility. Table terms outlines terms related to transparency commonly used by policymakers versus those used by technologists.
Transparency. For the purposes of this paper, we choose to use only the term “transparency,” in the broadest possible sense, so that it encompasses all the definitions above. This is most similar to the way “explainability” is used by technologists.Here we use the definition adapted from work by Christoph Molnar and define transparency as “the degree to which a human can understand an AI system.”
Explanation. We use the term “explanation” to refer to an instantiation of transparency. For example, to ensure transparency for a system, a technologist may create an explanation about the data it uses.
Automated Decision Systems. The approach described in this paper applies to all Automated Decision Systems (ADS), which is any system that processes data to make decisions about people. This means that AI systems are a subset of ADS, but there are two key distinctions: (1) an ADS is underpinned by any algorithm and not just AI or machine learning, and (2) an ADS implies a context of use and some kind of impact. For a formal definition of ADS, see. Henceforth, we will use the term ADS.
Notably, while many regulations are written to specifically mention “AI systems”, all the ideas they contain about transparency could be applied to all ADS. It is likely that future regulations will focus broadly on ADS, as seen in NYC Local Law 144 of 2021 and France’s Digital Republic Act.
Running Example: Predicting Unemployment in Portugal
To make the discussion concrete, we use a running example of an ADS implemented in Portugal to try and prevent long-term unemployment (being unemployed for 12 months or more). The long-term unemployed are particularly vulnerable persons, and tend to earn less once they find new jobs, have poorer health and have children with worse academic performance as compared to those who had continuous employment. The Portuguese national employment agency, the Institute for Employment and Vocational Training (IEFP), uses an ADS to allocate unemployment resources to at-risk unemployed persons. The system is based on demographic data about the individual, including their age, unemployment length, and profession, along with other data on macroeconomic trends in Portugal.
The ADS is used by job counselors who work at the IEFP unemployment centers spread across Portugal. This interaction model, where an ML system makes a prediction and a human ultimately makes a final determination informed by the system’s predictions, is referred to as having a “human-in-the-loop” (HITL). Having a HITL is an increasingly common practice for implementing ADS. The ADS assigns unemployed persons as low, medium, or high risk for remaining unemployed, and then job counselors have the responsibility of assigning them to interventions such as re-skilling, resume building, or job search training.
This is a useful case study for three reasons: (1) people’s access to economic opportunity is at stake, and as a result, systems for predicting long-term unemployment are used widely around the world; (2) the ADS exists in a dynamic setting which includes several stakeholders, like unemployed persons, job counselors who act as the human-in-the-loop, policymakers who oversee the implementation of the tool, and the technologists who developed the tool; (3) lessons from this case about designing stakeholder-first transparent systems generalize well to other real-world uses cases of ADS.
The Approach
There are many purposes, goals, use-cases and methods for the transparency of ADS, which have been categorized in a number of taxonomies and frameworks. Theapproach we propose here has three subtle — yet important — differences from much of the existing work in this area: (1) our approach is stakeholder-first, capturing an emerging trend among researchers in this field to reject existing method or use-case driven approaches; (2) our approach is focused on improving the design of transparent ADS, rather than attempting to categorize the entire field of transparency; (3) our approach is aimed at designing ADS that comply with transparency regulations.
Our approach can be seen in Figure fig-taxonomy and is made up of the following components: stakeholders, goals, purpose, and methods. We describe each component in the remainder of this section, and explain how they apply to the running example.
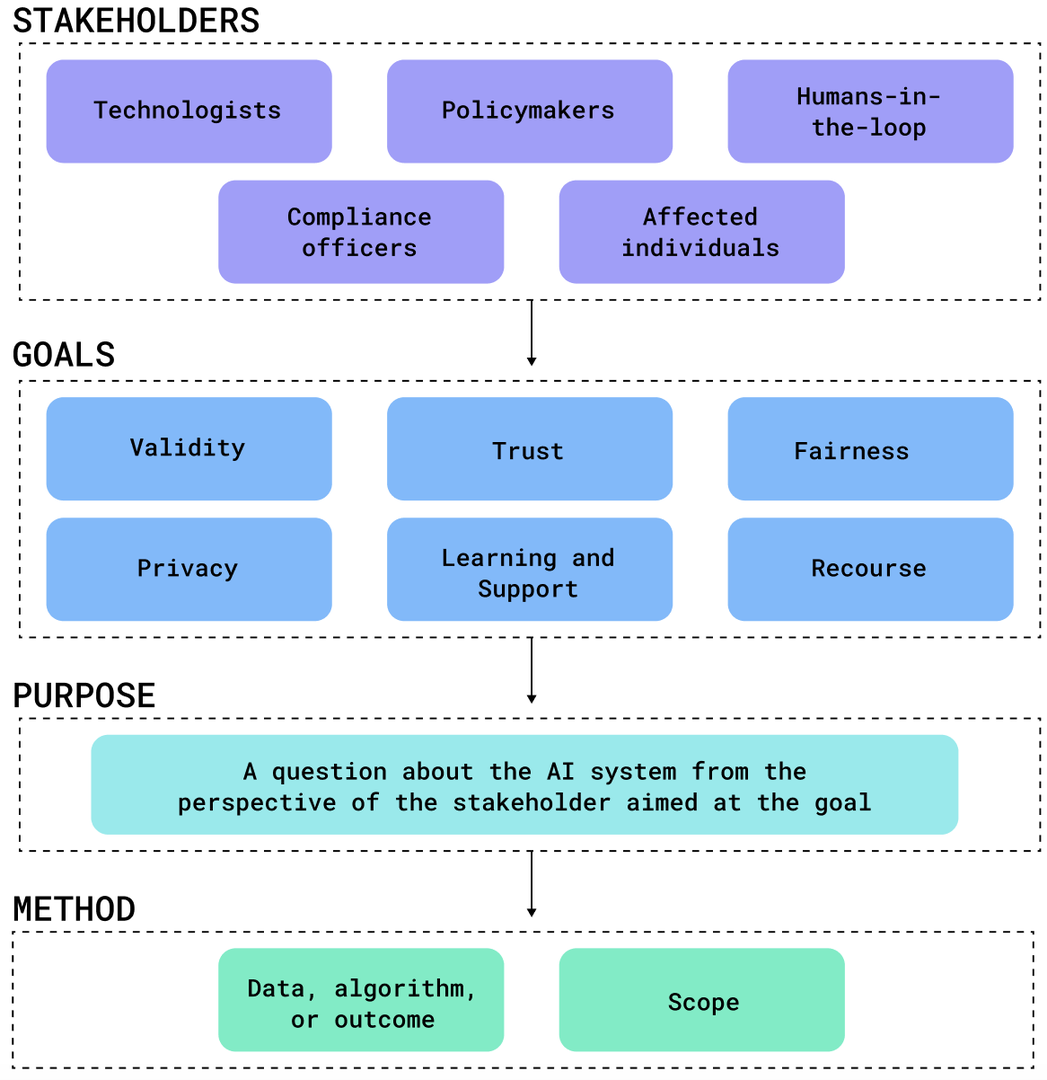
Definitions and examples of stakeholder goals for the 6 categories of ADS transparency goals.
Table Label: tab-goals
Download PDF to view tableStakeholders
Much of ADS transparency research is focused on creating novel and innovative transparency methods for algorithms, and then later trying to understand how these methods can be used to meet stakeholders needs. Counter to this rationale, we propose a starting point that focuses on ADS stakeholders: assuming algorithmic transparency is intended to improve the understanding of a human stakeholder, technologists designing transparent ADS must first consider the stakeholders of the system, before thinking about the system’s goals or the technical methods for creating transparency.
The existing literature and taxonomies on ADS transparency have identified a number of important stakeholders, which include technologists, policymakers, auditors, regulators, humans-in-the-loop, and those individuals affected by the output of the ADS.While there is some overlap in how these stakeholders may think about transparency, in general, there is no single approach to designing transparent systems for these disparate stakeholder groups, and each of them has their own goals and purposes for wanting to understand an ADS.In fact, even within a stakeholder group there may be variations on how they define meaningful transparency. Designers of ADS may also want to weight the needs of separate stakeholders differently. For example, it may be more meaningful to meet the transparency needs of affected individuals over AI managers or auditors.
Importantly, by staking transparency on the needs of stakeholders, technologists will be compliant with citizen-aware regulations like the Right to Explanation, and those that require audits of ADS.
Running example. In the ADS used by IEFP in Portugal, there are four main stakeholders: the technologists who developed the ADS, the policymakers who reviewed the ADS and passed laws for its implementation, the job counselors who use the system, and the affected individuals who are assessed for long-term unemployment.In the development of the AI, explanations were created to meet the varying goals of many of these stakeholders including practitioners, policymakers, and the job counselors.Unfortunately, and significantly, affected individuals were not considered.Had the practitioners adopted a robust stakeholder-first approach to designing transparent systems they could have better considered how to meet the goals of this key stakeholder group. For example, a person may want to appeal being predicted low risk because they feel they are high risk for long-term unemployment and need access to better interventions.
Goals.
There has been little consensus in the literature on how ADS goals should be classified. Some researchers have focused broadly, classifying the goals of ADS as evaluating, justifying, managing, improving, or learning about the outcome of an ADS.Others have defined goals more closely to what can be accomplished by known transparency methods, including building trust, establishing causality, and achieving reliability, fairness, and privacy.Amarasinghe et al. identified five main goals (designated as use-cases) of transparency specifically in a policy setting:model-debugging, trust and adoption, whether or not to intervene, improving intervention assignments, and for recourse. In this context, the term intervention refers to a policy action associated with the outcome of an ADS.
Notably, the goals of transparency are distinct from the purpose. The purpose addresses a context-specific aim of the ADS. For example, if an explanation is created for an ADS with the purpose of explaining to an individual why their loan was rejected, the goal may be to offer individual recourse against the rejection. This distinction is made clear in purpose.
For our stakeholder-first approach we make two changes to the existing body of research work. First, we require that the goal of transparent design must start with a stakeholder. Since all transparency elements of an ADS are intended for a human audience, defining a stakeholder is implicit in defining goals. Second, we have established 6 goal categories, which encompass those found in literature.These categories are validity, trust, learning and support, recourse, fairness and privacy, and are defined in Table tab-goals alongside concrete examples of how these goals may be implemented.
- Validity.Validity refers to making sure that an AI is constructed correctly and is reasonable.It encompasses ideas like making sure the AI is reliable and robust.
- Trust. In the context of an AI, trust refers knowing “how often a model is right” and “for which examples it is right”.Importantly, trust is related to the adoption of an ADS.
- Learning and Support.Learning and support refers to when the goal of transparency in an ADS is to satisfy human curiosity, or increase understanding about how an AI is supporting a real-world recommendation.
- Recourse.Recourse refers to allowing a stakeholder to take some action against the outcome of an AI.
- Fairness.Fairness refers to making sure that an AI is fair based on some metric, and transparency can be used to find bias within a model.
- Privacy.Privacy refers to making sure that an AI respects the data privacy of an individual.Transparency may be used to understand if privacy is being respected in an AI.
An important discussion surrounding goals are the justifications for pursuing them.For example, fairness and privacy goals may be justified for humanitarian reasons (they are perceived by the stakeholders as the “right thing to do”).Other justifications may be to prevent harm, like offering recourse to stakeholders against an outcome of an ADS, or for a reward, like an explanation that supports a doctor’s correct diagnosis.For reasons of scope we will not delve into the issue of goal justification in this paper.
Running example. In our case study, transparency is built into the ADS with the goal of offering learning and support to job counselors. The ADS generates explanations about what factors contribute to an individual being classified as low, medium, or high risk for long-term unemployment, which job counselors use to help make better treatment decision.Furthermore, the job counselor may also use the explanation to offer recommendations for recourse against a high risk score.
Purpose
Miller proposed that the purpose of transparency is to answer a “why” question, and gives the following example: In the context where a system is predicting if a credit loan is accepted or rejected, one may ask, “why was a particular loan rejected?” Liao et al. expanded on this significantly by creating a “question bank” which is a mapping from a taxonomy of technical transparency methodology to different types of user questions.Instead of just answering why questions, the works shows that transparency can be used to answer 10 categories of questions:questions about the input, output, and performance of the system, how, why, why not, what if, how to be that, how to still be this, and others. These questions have two important characteristics. First, they are context-specific and should address a direct transparency goal of the stakeholder. Second, and importantly for technologists, these questions can be mapped onto known methods for creating explanations, meaning that a well-defined purpose for transparency acts a bridge between the goals and methods.
Thoughtfully defining the goals and purpose of transparency in ADS is critical for technologists to be compliant with regulators. It is not sufficient to try and apply general, one-size-fits-all design like simply showing the features that were used by an ADS. For instance, both the proposed Algorithmic Accountability Act in the United States and the Artificial Intelligence Act in the European Union specifically mention that ADS should have transparency mechanisms that allow individuals to have recourse against a system outcome. Researchers have noted that feature-highlighting transparency lacks utility when there is a disconnect between the explanation and real-world actions. For instance, if someone is rejected for a loan and the reason for that decision is the person’s age, there is no action that they can effectively take for recourse against that decision.
Running example. In the long-term unemployment use case, there were two main purposes of transparency: to understand why an individual was assigned to a particular risk category, and to understand what could be done to help high risk individuals lower their chances of remaining long-term unemployed.
Methods.
Once the stakeholders, goals, and purposes for algorithmic transparency have been established, it is time for the technologist to pick the appropriate transparency method (somtimes called explainablity method). Over the past decade there has been significant work in transparent ADS research (sometimes called “explainable AI” research or XAI) on developing new methods for understanding opaque ADS.There are several existing taxonomies of these methods, which show that explanations can be classified on a number of attributes like the scope (local or global), intrinsic or post-hoc, data or model, model-agnostic or model-specific, surrogate or model behavior, and static or interactive. Furthermore, researchers have created a number of different tools to accomplish transparency in ADS.
In contrast to the complex classification of transparency methods by technologists, regulations have focused on two elements of ADS: (1) what aspect of the ADS pipeline is being explained (the data, algorithm, or outcome)?, and (2) what is the scope of the explanation (for one individual or the entire system)? Table tab-laws shows how different regulations speak to different combinations of pipeline and scope. In our stakeholder first-approach to transparency, we focus on these two main attributes. We will not discuss specific methods in detail, but for the convenience of technologists we have underlined them throughout this discussion.
How different laws regulate the aspects the ADS pipeline (the data, algorithm or outcome), and within what scope (local or global).
Table Label: tab-laws
Download PDF to view tableData, algorithm, or outcome. Transparency methods have focused on generating explanations for three different “points in time” in an ADS pipeline:the data (pre-processing), the model/algorithm (in-processing, intrinsic), or the outcome (post-processing, post-hoc).Importantly, transparency is relevant for each part of the machine learning pipeline because issues likes bias can arise within each component.
Transparency techniques that focus on the pre-processing component of the pipeline, that is, on the data used to create an ADS, typically include descriptive statistics or data visualizations.
Data visualizations have proved useful for informing users and making complex information more accessible and digestible, and have even been found to have a powerful persuasive effect. Therefore, it is advisable to use data visualization if it can easilyaddress the purpose of an explanation. However, visualizations should be deployed thoughtfully, as they have the ability to be abused and can successfully misrepresent a message through techniques like exaggeration or understatement.
Techniques for creating in-processing or post-processing explanations call into question the important consideration of using explainable versus black-box algorithms when designing AI. The machine learning community accepts two classifications of models:those that are intrinsically transparent by their nature (sometimes called directly interpretable or white-box models), and those that are not (called black box models). Interpretable models, like linear regression, decision trees, or rules-based models, have intrinsic transparency mechanisms that offer algorithmic transparency, like the linear formula, the tree diagram, and the set of rules, respectively. There are also methods like select-regress-round that simplify black-box models into interpretable models that use a similar set of features.
As an important design consideration for technologists, researchers have studied the effect of the complexity of a model and how it impacts its ability to be understood by a stakeholder. A user study found that the understanding of a machine learning model is negatively correlated with it’s complexity, and found decision trees to be among the model types most understood by users. An additional, lower-level design consideration is that model complexity is not fixed to a particular model type, but rather to the way that the model is constructed. For example, a decision tree with 1,000 nodes will be understood far less well than a tree with only 3 or 5 nodes.
In contrast to in-process transparency, which is intrinsically built into a model or algorithm, post-hoc transparency aims to answer questions about a model or algorithm after is has already been created.Some of the most popular post-hoc methods are LIME, SHAP, SAGE, and QII. These methods are considered model-agnostic because they can be used to create explanations for any model, from linear models to random forests to neural networks. Some methods create a transparent surrogate model that mimics the behavior of a black-box model. For example, LIME creates a linear regression to approximate an underlying black-box model. More work needs to be done in this direction, but one promising study has shown that post-hoc explanations can actually improve the perceived trust in the outcome of an algorithm. However, post-hoc transparency methods have been shown to have two weaknesses that technologists should be aware of: (1) in many cases, these methods are at-best approximations of the black-box they are trying to explain, and (2) these methods may be vulnerable to adversarial attacks and exploitation.Some researchers have also called into question the utility of black-box models and post-hoc explanation methods altogether, and have cautioned against their use in real-world contexts like clinical settings.
Scope
. There are two levels at which a transparent explanation about an ADS can operate:it either explains its underlying algorithm fully, called a “global” explanation; or it explains how the algorithm operates on one specific instance, called a “local” explanation. Molnar further subdivides each of these levels into two sub-levels: global explanations can either be holistic (applying to an entire algorithm, which includes all of its features, and in the case of an ensemble algorithm, all of the component algorithms) or modular, meaning they explain on part of the holistic explanation and local explanations can either be applied to a single individual, or aggregated to provide local explanations for an entire group.
The scope of an explanation is highly relevant to the stakeholder and goals of an explanation, and is related to whether the stakeholder operates at a system or individual level. Researchers found that the scope of explanation can influence whether or not an individual thinks a model is fair. Policymakers and ADS compliance officers are more apt to be concerned with system level goals, like ensuring that the ADS is fair, respects privacy, and is valid overall, while humans-in-the-loop and those individuals affected by the outcome of an ADS are likely more interested in seeing local explanations to pertain to their specific cases. Technologists should consider both.
Naturally, there is considerable overlap between stakeholders’ scope needs (for example, an auditor may want to inspect a model globally and look at local cases), but generally, it is important which scope an explanation has.Therefore designers of ADS explanations should be thoughtful of how they select the scope of an explanation based on a stakeholder and their goals.
Running-example. In the IEFP use case, SHAP factors were given to job counselors to show the top factors influencing the score of a candidate both positively and negatively. The transparency provided by SHAP provided a local explanation about the outcome of the model. A bias audit was also conducted on the entire algorithm, and presented to policy officials within IEFP.
Overall, researchers found that the explanations improved the confidence of the decisions, but counter-intuitively, had a somewhat negative effect on the quality of those decisions.
Putting the Approach into Practice
The stakeholder-first approach describe in Section sec-approach is meant to act as a guide for technologists creating regulatory-compliant ADS. Putting this approach into practice is simple: starting at the first component in Figure fig-taxonomy (stakeholders), one should consider each bubble, before moving onto the next component and again considering each bubble. By the time one has finished worked their way through the figure, they should have considered all the possible stakeholders, goals, purposes, and methods of an ADS. An instantiation of the approach can be found throughout Section sec-approach in the running example of building an ADS that predicts the risk of long-term unemployment in Portugal.
It’s important to note that our proposed stakeholder-first approach is only a high-level tool for thinking about ADS transparency through the perspective of stakeholders and their needs. Beyond this approach, there are meaningful low-level steps that can be taken by technologists when it comes to actually implement transparency into ADS. One such step is the use of participatory design, where stakeholders are included directly in design conversations. In one promising study researchers used participatory design to successfully create better algorithmic explanations for users in the field of communal energy accounting.
Concluding Remarks
If there is to be a positive, ethical future for the use of AI systems, there needs to be stakeholder-driven design for creating transparency algorithms — and who better to lead this effort than technologists. Here we proposed a stakeholder-first approach that technologists can use to guide their design of transparent AI systems that are compliant with existing and proposed AI regulations. While there is still significant research that needs to be done in understanding how the transparency of AI systems can be most useful for stakeholders, and in the policy design of AI regulation, this paper aims to be a step in the right direction.
There are several important research steps that could be taken to extend this work. First, the stakeholder-first approach described here lays the foundation for creating a complete playbook to designing transparent systems. This playbook would be useful to a number of audiences including technologists, humans-in-the-loop, and policymakers. Second, a repository of examples and use cases of regulatory-compliant systems derived from this approach could be created, to act as a reference to technologists.
Bibliography
1@article{rakova2020responsible,
2 year = {2020},
3 journal = {arXiv preprint arXiv:2006.12358},
4 author = {Rakova, Bogdana and Yang, Jingying and Cramer, Henriette and Chowdhury, Rumman},
5 title = {Where Responsible AI meets Reality: Practitioner Perspectives on Enablers for shifting Organizational Practices},
6}
7
8@article{DBLP:journals/corr/abs-1906-11668,
9 bibsource = {dblp computer science bibliography, https://dblp.org},
10 biburl = {https://dblp.org/rec/journals/corr/abs-1906-11668.bib},
11 timestamp = {Mon, 01 Jul 2019 13:00:07 +0200},
12 eprint = {1906.11668},
13 archiveprefix = {arXiv},
14 url = {http://arxiv.org/abs/1906.11668},
15 year = {2019},
16 volume = {abs/1906.11668},
17 journal = {CoRR},
18 title = {Artificial Intelligence: the global landscape of ethics guidelines},
19 author = {Anna Jobin and
20Marcello Ienca and
21Effy Vayena},
22}
23
24@inproceedings{DBLP:conf/fat/BuolamwiniG18,
25 bibsource = {dblp computer science bibliography, https://dblp.org},
26 biburl = {https://dblp.org/rec/conf/fat/BuolamwiniG18.bib},
27 timestamp = {Wed, 03 Apr 2019 18:17:20 +0200},
28 url = {http://proceedings.mlr.press/v81/buolamwini18a.html},
29 year = {2018},
30 publisher = {{PMLR}},
31 pages = {77--91},
32 volume = {81},
33 series = {Proceedings of Machine Learning Research},
34 booktitle = {Conference on Fairness, Accountability and Transparency, {FAT} 2018,
3523-24 February 2018, New York, NY, {USA}},
36 title = {Gender Shades: Intersectional Accuracy Disparities in Commercial Gender
37Classification},
38 editor = {Sorelle A. Friedler and
39Christo Wilson},
40 author = {Joy Buolamwini and
41Timnit Gebru},
42}
43
44@article{angwin2016machine,
45 year = {2016},
46 journal = {See https://www. propublica. org/article/machine-bias-risk-assessments-in-criminal-sentencing},
47 author = {Angwin, Julia and Larson, Jeff and Mattu, Surya and Kirchner, Lauren},
48 title = {Machine bias. ProPublica},
49}
50
51@article{KUZIEMSKI2020101976,
52 abstract = {The rush to understand new socio-economic contexts created by the wide adoption of AI is justified by its far-ranging consequences, spanning almost every walk of life. Yet, the public sector's predicament is a tragic double bind: its obligations to protect citizens from potential algorithmic harms are at odds with the temptation to increase its own efficiency - or in other words - to govern algorithms, while governing by algorithms. Whether such dual role is even possible, has been a matter of debate, the challenge stemming from algorithms' intrinsic properties, that make them distinct from other digital solutions, long embraced by the governments, create externalities that rule-based programming lacks. As the pressures to deploy automated decision making systems in the public sector become prevalent, this paper aims to examine how the use of AI in the public sector in relation to existing data governance regimes and national regulatory practices can be intensifying existing power asymmetries. To this end, investigating the legal and policy instruments associated with the use of AI for strenghtening the immigration process control system in Canada; “optimising” the employment services” in Poland, and personalising the digital service experience in Finland, the paper advocates for the need of a common framework to evaluate the potential impact of the use of AI in the public sector. In this regard, it discusses the specific effects of automated decision support systems on public services and the growing expectations for governments to play a more prevalent role in the digital society and to ensure that the potential of technology is harnessed, while negative effects are controlled and possibly avoided. This is of particular importance in light of the current COVID-19 emergency crisis where AI and the underpinning regulatory framework of data ecosystems, have become crucial policy issues as more and more innovations are based on large scale data collections from digital devices, and the real-time accessibility of information and services, contact and relationships between institutions and citizens could strengthen – or undermine - trust in governance systems and democracy.},
53 keywords = {Artificial intelligence, Public sector innovation, Automated decision making, Algorithmic accountability},
54 author = {Maciej Kuziemski and Gianluca Misuraca},
55 url = {http://www.sciencedirect.com/science/article/pii/S0308596120300689},
56 doi = {https://doi.org/10.1016/j.telpol.2020.101976},
57 issn = {0308-5961},
58 note = {Artificial intelligence, economy and society},
59 year = {2020},
60 pages = {101976},
61 number = {6},
62 volume = {44},
63 journal = {Telecommunications Policy},
64 title = {AI governance in the public sector: Three tales from the frontiers of automated decision-making in democratic settings},
65}
66
67@article{DBLP:journals/corr/abs-2001-09734,
68 bibsource = {dblp computer science bibliography, https://dblp.org},
69 biburl = {https://dblp.org/rec/journals/corr/abs-2001-09734.bib},
70 timestamp = {Thu, 30 Jan 2020 18:46:36 +0100},
71 eprint = {2001.09734},
72 archiveprefix = {arXiv},
73 url = {https://arxiv.org/abs/2001.09734},
74 year = {2020},
75 volume = {abs/2001.09734},
76 journal = {CoRR},
77 title = {One Explanation Does Not Fit All: The Promise of Interactive Explanations
78for Machine Learning Transparency},
79 author = {Kacper Sokol and
80Peter A. Flach},
81}
82
83@inproceedings{DBLP:conf/fat/SelbstP18,
84 bibsource = {dblp computer science bibliography, https://dblp.org},
85 biburl = {https://dblp.org/rec/conf/fat/SelbstP18.bib},
86 timestamp = {Wed, 03 Apr 2019 18:17:20 +0200},
87 url = {http://proceedings.mlr.press/v81/selbst18a.html},
88 year = {2018},
89 publisher = {{PMLR}},
90 pages = {48},
91 volume = {81},
92 series = {Proceedings of Machine Learning Research},
93 booktitle = {Conference on Fairness, Accountability and Transparency, {FAT} 2018,
9423-24 February 2018, New York, NY, {USA}},
95 title = {"Meaningful Information" and the Right to Explanation},
96 editor = {Sorelle A. Friedler and
97Christo Wilson},
98 author = {Andrew Selbst and
99Julia Powles},
100}
101
102@article{reed2018,
103 url = {http://dx.doi.org/10.1098/rsta.2017.0360},
104 year = {2018},
105 volume = {376},
106 journal = {Trans. R. Soc. A},
107 title = {How should we regulate artificial intelligence?},
108 author = {C. Reed},
109}
110
111@article{1894_showreel,
112 author+an = {1=self},
113 keywords = {public},
114 day = {12},
115 month = {11},
116 year = {2020},
117 url = {https://dataresponsibly.github.io/documents/Bill1894Showreel.pdf},
118 journal = {NYU Center for Responsible AI},
119 title = {Public Engagement Showreel, Int 1894},
120 author = {Julia Stoyanovich and Steven Kuyan and Meghan McDermott and Maria Grillo and Mona Sloane},
121}
122
123@article{DBLP:journals/pvldb/StoyanovichHJ20,
124 addendum = {paper accompanying keynote presentation at the 46th International Conference on Very Large Data Bases, {VLDB}},
125 author+an = {1=self},
126 keywords = {invited,selected},
127 doi = {10.14778/3415478.3415570},
128 pages = {3474-3489},
129 number = {12},
130 volume = {13},
131 year = {2020},
132 journal = {PVLDB},
133 title = {Responsible Data Management},
134 author = {Julia Stoyanovich and Bill Howe and H.V. Jagadish},
135}
136
137@inproceedings{DBLP:conf/aies/KrafftYKHB20,
138 bibsource = {dblp computer science bibliography, https://dblp.org},
139 biburl = {https://dblp.org/rec/conf/aies/KrafftYKHB20.bib},
140 timestamp = {Fri, 08 Jan 2021 08:52:12 +0100},
141 doi = {10.1145/3375627.3375835},
142 url = {https://doi.org/10.1145/3375627.3375835},
143 year = {2020},
144 publisher = {{ACM}},
145 pages = {72--78},
146 booktitle = {{AIES} '20: {AAAI/ACM} Conference on AI, Ethics, and Society, New
147York, NY, USA, February 7-8, 2020},
148 title = {Defining {AI} in Policy versus Practice},
149 editor = {Annette N. Markham and
150Julia Powles and
151Toby Walsh and
152Anne L. Washington},
153 author = {P. M. Krafft and
154Meg Young and
155Michael A. Katell and
156Karen Huang and
157Ghislain Bugingo},
158}
159
160@book{molnar2019,
161 subtitle = {A Guide for Making Black Box Models Explainable},
162 year = {2019},
163 note = {\url{https://christophm.github.io/interpretable-ml-book/}},
164 author = {Christoph Molnar},
165 title = {Interpretable Machine Learning},
166}
167
168@article{DBLP:journals/corr/abs-2010-14374,
169 bibsource = {dblp computer science bibliography, https://dblp.org},
170 biburl = {https://dblp.org/rec/journals/corr/abs-2010-14374.bib},
171 timestamp = {Mon, 02 Nov 2020 18:17:09 +0100},
172 eprint = {2010.14374},
173 archiveprefix = {arXiv},
174 url = {https://arxiv.org/abs/2010.14374},
175 year = {2020},
176 volume = {abs/2010.14374},
177 journal = {CoRR},
178 title = {Explainable Machine Learning for Public Policy: Use Cases, Gaps, and
179Research Directions},
180 author = {Kasun Amarasinghe and
181Kit T. Rodolfa and
182Hemank Lamba and
183Rayid Ghani},
184}
185
186@article{meske,
187 doi = {10.1080/10580530.2020.1849465},
188 journal = {Information Systems Management},
189 title = {Explainable Artificial Intelligence: Objectives, Stakeholders and Future Research Opportunities},
190 pages = {},
191 month = {12},
192 year = {2020},
193 author = {Meske, Christian and Bunde, Enrico and Schneider, Johannes and Gersch, Martin},
194}
195
196@inproceedings{DBLP:conf/chi/LiaoGM20,
197 bibsource = {dblp computer science bibliography, https://dblp.org},
198 biburl = {https://dblp.org/rec/conf/chi/LiaoGM20.bib},
199 timestamp = {Fri, 25 Dec 2020 01:14:19 +0100},
200 doi = {10.1145/3313831.3376590},
201 url = {https://doi.org/10.1145/3313831.3376590},
202 year = {2020},
203 publisher = {{ACM}},
204 pages = {1--15},
205 booktitle = {{CHI} '20: {CHI} Conference on Human Factors in Computing Systems,
206Honolulu, HI, USA, April 25-30, 2020},
207 title = {Questioning the {AI:} Informing Design Practices for Explainable {AI}
208User Experiences},
209 editor = {Regina Bernhaupt and
210Florian 'Floyd' Mueller and
211David Verweij and
212Josh Andres and
213Joanna McGrenere and
214Andy Cockburn and
215Ignacio Avellino and
216Alix Goguey and
217Pernille Bj{\o}n and
218Shengdong Zhao and
219Briane Paul Samson and
220Rafal Kocielnik},
221 author = {Q. Vera Liao and
222Daniel M. Gruen and
223Sarah Miller},
224}
225
226@article{DBLP:journals/corr/Miller17a,
227 bibsource = {dblp computer science bibliography, https://dblp.org},
228 biburl = {https://dblp.org/rec/journals/corr/Miller17a.bib},
229 timestamp = {Mon, 13 Aug 2018 16:47:22 +0200},
230 eprint = {1706.07269},
231 archiveprefix = {arXiv},
232 url = {http://arxiv.org/abs/1706.07269},
233 year = {2017},
234 volume = {abs/1706.07269},
235 journal = {CoRR},
236 title = {Explanation in Artificial Intelligence: Insights from the Social Sciences},
237 author = {Tim Miller},
238}
239
240@article{DBLP:journals/jmlr/AryaBCDHHHLLMMP20,
241 bibsource = {dblp computer science bibliography, https://dblp.org},
242 biburl = {https://dblp.org/rec/journals/jmlr/AryaBCDHHHLLMMP20.bib},
243 timestamp = {Wed, 18 Nov 2020 15:58:12 +0100},
244 url = {http://jmlr.org/papers/v21/19-1035.html},
245 year = {2020},
246 pages = {130:1--130:6},
247 volume = {21},
248 journal = {J. Mach. Learn. Res.},
249 title = {{AI} Explainability 360: An Extensible Toolkit for Understanding Data
250and Machine Learning Models},
251 author = {Vijay Arya and
252Rachel K. E. Bellamy and
253Pin{-}Yu Chen and
254Amit Dhurandhar and
255Michael Hind and
256Samuel C. Hoffman and
257Stephanie Houde and
258Q. Vera Liao and
259Ronny Luss and
260Aleksandra Mojsilovic and
261Sami Mourad and
262Pablo Pedemonte and
263Ramya Raghavendra and
264John T. Richards and
265Prasanna Sattigeri and
266Karthikeyan Shanmugam and
267Moninder Singh and
268Kush R. Varshney and
269Dennis Wei and
270Yunfeng Zhang},
271}
272
273@inproceedings{yang2020fairness,
274 year = {2020},
275 booktitle = {HILDA workshop at SIGMOD},
276 author = {Yang, Ke and Huang, Biao and Stoyanovich, Julia and Schelter, Sebastian},
277 title = {Fairness-aware instrumentation of preprocessing pipelines for machine learning},
278}
279
280@article{zhang2019should,
281 year = {2019},
282 journal = {arXiv preprint arXiv:1904.12991},
283 author = {Zhang, Yujia and Song, Kuangyan and Sun, Yiming and Tan, Sarah and Udell, Madeleine},
284 title = {" Why Should You Trust My Explanation?" Understanding Uncertainty in LIME Explanations},
285}
286
287@inproceedings{DBLP:conf/aies/SlackHJSL20,
288 bibsource = {dblp computer science bibliography, https://dblp.org},
289 biburl = {https://dblp.org/rec/conf/aies/SlackHJSL20.bib},
290 timestamp = {Mon, 24 Feb 2020 12:40:26 +0100},
291 doi = {10.1145/3375627.3375830},
292 url = {https://doi.org/10.1145/3375627.3375830},
293 year = {2020},
294 publisher = {{ACM}},
295 pages = {180--186},
296 booktitle = {{AIES} '20: {AAAI/ACM} Conference on AI, Ethics, and Society, New
297York, NY, USA, February 7-8, 2020},
298 title = {Fooling {LIME} and {SHAP:} Adversarial Attacks on Post hoc Explanation
299Methods},
300 editor = {Annette N. Markham and
301Julia Powles and
302Toby Walsh and
303Anne L. Washington},
304 author = {Dylan Slack and
305Sophie Hilgard and
306Emily Jia and
307Sameer Singh and
308Himabindu Lakkaraju},
309}
310
311@article{platform2018tackling,
312 year = {2018},
313 author = {Anette Scoppetta and Arthur Buckenleib.},
314 title = {Tackling Long-Term Unemployment through Risk Profiling and Outreach},
315}
316
317@article{loxha2014profiling,
318 publisher = {World Bank Group, Washington, DC},
319 year = {2014},
320 author = {Loxha, Artan and Morgandi, Matteo},
321 title = {Profiling the Unemployed: a review of OECD experiences and implications for emerging economies},
322}
323
324@inproceedings{riipinen2011risk,
325 year = {2011},
326 pages = {8--9},
327 booktitle = {Power Point presentation at the European Commission’s “PES to PES Dialogue Dissemination Conference,” Brussels, September},
328 author = {Riipinen, T},
329 title = {Risk profiling of long-term unemployment in Finland},
330}
331
332@article{caswell2010unemployed,
333 publisher = {Sage Publications Sage UK: London, England},
334 year = {2010},
335 pages = {384--404},
336 number = {3},
337 volume = {30},
338 journal = {Critical Social Policy},
339 author = {Caswell, Dorte and Marston, Greg and Larsen, J{\o}rgen Elm},
340 title = {Unemployed citizen or ‘at risk’client? Classification systems and employment services in Denmark and Australia},
341}
342
343@book{matty2013predicting,
344 publisher = {Corporate Document Services},
345 year = {2013},
346 author = {Matty, Simon},
347 title = {Predicting Likelihood of Long-term Unemployment: The Development of a UK Jobseekers' Classification Instrument},
348}
349
350@article{sztandar2018changing,
351 year = {2018},
352 number = {2},
353 volume = {16},
354 journal = {Social Work \& Society},
355 author = {Sztandar-Sztanderska, Karolina and Zielenska, Marianna},
356 title = {Changing social citizenship through information technology},
357}
358
359@article{raso2017displacement,
360 publisher = {Cambridge University Press},
361 year = {2017},
362 pages = {75--95},
363 number = {1},
364 volume = {32},
365 journal = {Canadian Journal of Law and Society},
366 author = {Raso, Jennifer},
367 title = {Displacement as regulation: New regulatory technologies and front-line decision-making in Ontario works},
368}
369
370@article{wagner2019liable,
371 publisher = {Wiley Online Library},
372 year = {2019},
373 pages = {104--122},
374 number = {1},
375 volume = {11},
376 journal = {Policy \& Internet},
377 author = {Wagner, Ben},
378 title = {Liable, but not in control? Ensuring meaningful human agency in automated decision-making systems},
379}
380
381@article{gillingham2019can,
382 publisher = {Wiley Online Library},
383 year = {2019},
384 pages = {114--126},
385 number = {2},
386 volume = {28},
387 journal = {Child abuse review},
388 author = {Gillingham, Philip},
389 title = {Can predictive algorithms assist decision-making in social work with children and families?},
390}
391
392@article{gill2020policy,
393 publisher = {Duke Global Working Paper Series},
394 year = {2020},
395 author = {Gill, Indermit S},
396 title = {Policy Approaches to Artificial Intelligence Based Technologies in China, European Union and the United States},
397}
398
399@article{narayanan2018humans,
400 year = {2018},
401 journal = {arXiv preprint arXiv:1802.00682},
402 author = {Narayanan, Menaka and Chen, Emily and He, Jeffrey and Kim, Been and Gershman, Sam and Doshi-Velez, Finale},
403 title = {How do humans understand explanations from machine learning systems? an evaluation of the human-interpretability of explanation},
404}
405
406@article{unicri,
407 url = {http://www.unicri.it/index.php/topics/ai_robotics},
408 year = {2020},
409 author = {UNICRI},
410 title = {Towards Responsible Artificial Intelligence Innovation},
411}
412
413@article{DBLP:journals/corr/abs-1909-03567,
414 bibsource = {dblp computer science bibliography, https://dblp.org},
415 biburl = {https://dblp.org/rec/journals/corr/abs-1909-03567.bib},
416 timestamp = {Tue, 17 Sep 2019 11:23:44 +0200},
417 eprint = {1909.03567},
418 archiveprefix = {arXiv},
419 url = {http://arxiv.org/abs/1909.03567},
420 year = {2019},
421 volume = {abs/1909.03567},
422 journal = {CoRR},
423 title = {What You See Is What You Get? The Impact of Representation Criteria
424on Human Bias in Hiring},
425 author = {Andi Peng and
426Besmira Nushi and
427Emre Kiciman and
428Kori Inkpen and
429Siddharth Suri and
430Ece Kamar},
431}
432
433@inproceedings{DBLP:conf/softcomp/BekriKH19,
434 bibsource = {dblp computer science bibliography, https://dblp.org},
435 biburl = {https://dblp.org/rec/conf/softcomp/BekriKH19.bib},
436 timestamp = {Tue, 29 Dec 2020 18:31:06 +0100},
437 doi = {10.1007/978-3-030-20055-8\_4},
438 url = {https://doi.org/10.1007/978-3-030-20055-8\_4},
439 year = {2019},
440 publisher = {Springer},
441 pages = {35--46},
442 volume = {950},
443 series = {Advances in Intelligent Systems and Computing},
444 booktitle = {14th International Conference on Soft Computing Models in Industrial
445and Environmental Applications {(SOCO} 2019) - Seville, Spain, May
44613-15, 2019, Proceedings},
447 title = {A Study on Trust in Black Box Models and Post-hoc Explanations},
448 editor = {Francisco Mart{\'{\i}}nez{-}{\'{A}}lvarez and
449Alicia Troncoso Lora and
450Jos{\'{e}} Ant{\'{o}}nio S{\'{a}}ez Mu{\~{n}}oz and
451H{\'{e}}ctor Quinti{\'{a}}n and
452Emilio Corchado},
453 author = {Nadia El Bekri and
454Jasmin Kling and
455Marco F. Huber},
456}
457
458@article{lipton2018mythos,
459 publisher = {ACM New York, NY, USA},
460 year = {2018},
461 pages = {31--57},
462 number = {3},
463 volume = {16},
464 journal = {Queue},
465 author = {Lipton, Zachary C},
466 title = {The Mythos of Model Interpretability: In machine learning, the concept of interpretability is both important and slippery.},
467}
468
469@article{doshi2017towards,
470 year = {2017},
471 journal = {arXiv preprint arXiv:1702.08608},
472 author = {Doshi-Velez, Finale and Kim, Been},
473 title = {Towards a rigorous science of interpretable machine learning},
474}
475
476@inproceedings{ventocilla2018towards,
477 year = {2018},
478 pages = {151--157},
479 booktitle = {XAI Workshop on Explainable Artificial Intelligence},
480 author = {Ventocilla, Elio and Helldin, Tove and Riveiro, Maria and Bae, Juhee and Boeva, Veselka and Falkman, G{\"o}ran and Lavesson, Niklas},
481 title = {Towards a taxonomy for interpretable and interactive machine learning},
482}
483
484@article{stoyanovich2016revealing,
485 year = {2016},
486 journal = {Freedom to Tinker (August 5 2016)},
487 author = {Stoyanovich, Julia and Goodman, Ellen P},
488 title = {Revealing algorithmic rankers},
489}
490
491@article{DBLP:journals/internet/GasserA17,
492 bibsource = {dblp computer science bibliography, https://dblp.org},
493 biburl = {https://dblp.org/rec/journals/internet/GasserA17.bib},
494 timestamp = {Mon, 26 Oct 2020 09:03:54 +0100},
495 doi = {10.1109/MIC.2017.4180835},
496 url = {https://doi.org/10.1109/MIC.2017.4180835},
497 year = {2017},
498 pages = {58--62},
499 number = {6},
500 volume = {21},
501 journal = {{IEEE} Internet Comput.},
502 title = {A Layered Model for {AI} Governance},
503 author = {Urs Gasser and
504Virg{\'{\i}}lio A. F. Almeida},
505}
506
507@article{wachter2017transparent,
508 year = {2017},
509 author = {Wachter, Sandra and Mittelstadt, Brent and Floridi, Luciano},
510 title = {Transparent, explainable, and accountable AI for robotics},
511}
512
513@article{gosiewska2019not,
514 year = {2019},
515 journal = {arXiv preprint arXiv:1903.11420},
516 author = {Gosiewska, Alicja and Biecek, Przemyslaw},
517 title = {Do not trust additive explanations},
518}
519
520@article{rudin2019stop,
521 publisher = {Nature Publishing Group},
522 year = {2019},
523 pages = {206--215},
524 number = {5},
525 volume = {1},
526 journal = {Nature Machine Intelligence},
527 author = {Rudin, Cynthia},
528 title = {Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead},
529}
530
531@article{DBLP:journals/corr/abs-2101-09429,
532 bibsource = {dblp computer science bibliography, https://dblp.org},
533 biburl = {https://dblp.org/rec/journals/corr/abs-2101-09429.bib},
534 timestamp = {Sat, 30 Jan 2021 18:02:51 +0100},
535 eprint = {2101.09429},
536 archiveprefix = {arXiv},
537 url = {https://arxiv.org/abs/2101.09429},
538 year = {2021},
539 volume = {abs/2101.09429},
540 journal = {CoRR},
541 title = {Explainable Artificial Intelligence Approaches: {A} Survey},
542 author = {Sheikh Rabiul Islam and
543William Eberle and
544Sheikh Khaled Ghafoor and
545Mohiuddin Ahmed},
546}
547
548@inproceedings{DBLP:conf/scai/AllahyariL11,
549 bibsource = {dblp computer science bibliography, https://dblp.org},
550 biburl = {https://dblp.org/rec/conf/scai/AllahyariL11.bib},
551 timestamp = {Fri, 19 May 2017 01:25:16 +0200},
552 doi = {10.3233/978-1-60750-754-3-11},
553 url = {https://doi.org/10.3233/978-1-60750-754-3-11},
554 year = {2011},
555 publisher = {{IOS} Press},
556 pages = {11--19},
557 volume = {227},
558 series = {Frontiers in Artificial Intelligence and Applications},
559 booktitle = {Eleventh Scandinavian Conference on Artificial Intelligence, {SCAI}
5602011, Trondheim, Norway, May 24th - 26th, 2011},
561 title = {User-oriented Assessment of Classification Model Understandability},
562 editor = {Anders Kofod{-}Petersen and
563Fredrik Heintz and
564Helge Langseth},
565 author = {Hiva Allahyari and
566Niklas Lavesson},
567}
568
569@misc{rodolfa2020machine,
570 primaryclass = {cs.LG},
571 archiveprefix = {arXiv},
572 eprint = {2012.02972},
573 year = {2020},
574 author = {Kit T. Rodolfa and Hemank Lamba and Rayid Ghani},
575 title = {Machine learning for public policy: Do we need to sacrifice accuracy to make models fair?},
576}
577
578@article{DBLP:journals/debu/StoyanovichH19,
579 bibsource = {dblp computer science bibliography, https://dblp.org},
580 biburl = {https://dblp.org/rec/journals/debu/StoyanovichH19.bib},
581 timestamp = {Tue, 10 Mar 2020 16:23:50 +0100},
582 url = {http://sites.computer.org/debull/A19sept/p13.pdf},
583 year = {2019},
584 pages = {13--23},
585 number = {3},
586 volume = {42},
587 journal = {{IEEE} Data Eng. Bull.},
588 title = {Nutritional Labels for Data and Models},
589 author = {Julia Stoyanovich and
590Bill Howe},
591}
592
593@article{campos2011nutrition,
594 publisher = {Cambridge University Press},
595 year = {2011},
596 pages = {1496--1506},
597 number = {8},
598 volume = {14},
599 journal = {Public health nutrition},
600 author = {Campos, Sarah and Doxey, Juliana and Hammond, David},
601 title = {Nutrition labels on pre-packaged foods: a systematic review},
602}
603
604@inproceedings{ribeiro2016should,
605 year = {2016},
606 pages = {1135--1144},
607 booktitle = {Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining},
608 author = {Ribeiro, Marco Tulio and Singh, Sameer and Guestrin, Carlos},
609 title = {" Why should i trust you?" Explaining the predictions of any classifier},
610}
611
612@inproceedings{datta2016algorithmic,
613 organization = {IEEE},
614 year = {2016},
615 pages = {598--617},
616 booktitle = {2016 IEEE symposium on security and privacy (SP)},
617 author = {Datta, Anupam and Sen, Shayak and Zick, Yair},
618 title = {Algorithmic transparency via quantitative input influence: Theory and experiments with learning systems},
619}
620
621@inproceedings{DBLP:conf/nips/LundbergL17,
622 bibsource = {dblp computer science bibliography, https://dblp.org},
623 biburl = {https://dblp.org/rec/conf/nips/LundbergL17.bib},
624 timestamp = {Thu, 21 Jan 2021 15:15:21 +0100},
625 url = {https://proceedings.neurips.cc/paper/2017/hash/8a20a8621978632d76c43dfd28b67767-Abstract.html},
626 year = {2017},
627 pages = {4765--4774},
628 booktitle = {Advances in Neural Information Processing Systems 30: Annual Conference
629on Neural Information Processing Systems 2017, December 4-9, 2017,
630Long Beach, CA, {USA}},
631 title = {A Unified Approach to Interpreting Model Predictions},
632 editor = {Isabelle Guyon and
633Ulrike von Luxburg and
634Samy Bengio and
635Hanna M. Wallach and
636Rob Fergus and
637S. V. N. Vishwanathan and
638Roman Garnett},
639 author = {Scott M. Lundberg and
640Su{-}In Lee},
641}
642
643@inproceedings{DBLP:conf/fat/SokolF20,
644 bibsource = {dblp computer science bibliography, https://dblp.org},
645 biburl = {https://dblp.org/rec/conf/fat/SokolF20.bib},
646 timestamp = {Fri, 24 Jan 2020 19:41:57 +0100},
647 doi = {10.1145/3351095.3372870},
648 url = {https://doi.org/10.1145/3351095.3372870},
649 year = {2020},
650 publisher = {{ACM}},
651 pages = {56--67},
652 booktitle = {FAT* '20: Conference on Fairness, Accountability, and Transparency,
653Barcelona, Spain, January 27-30, 2020},
654 title = {Explainability fact sheets: a framework for systematic assessment
655of explainable approaches},
656 editor = {Mireille Hildebrandt and
657Carlos Castillo and
658Elisa Celis and
659Salvatore Ruggieri and
660Linnet Taylor and
661Gabriela Zanfir{-}Fortuna},
662 author = {Kacper Sokol and
663Peter A. Flach},
664}
665
666@inproceedings{DBLP:conf/chi/HohmanHCDD19,
667 bibsource = {dblp computer science bibliography, https://dblp.org},
668 biburl = {https://dblp.org/rec/conf/chi/HohmanHCDD19.bib},
669 timestamp = {Fri, 24 Jan 2020 16:59:38 +0100},
670 doi = {10.1145/3290605.3300809},
671 url = {https://doi.org/10.1145/3290605.3300809},
672 year = {2019},
673 publisher = {{ACM}},
674 pages = {579},
675 booktitle = {Proceedings of the 2019 {CHI} Conference on Human Factors in Computing
676Systems, {CHI} 2019, Glasgow, Scotland, UK, May 04-09, 2019},
677 title = {Gamut: {A} Design Probe to Understand How Data Scientists Understand
678Machine Learning Models},
679 editor = {Stephen A. Brewster and
680Geraldine Fitzpatrick and
681Anna L. Cox and
682Vassilis Kostakos},
683 author = {Fred Hohman and
684Andrew Head and
685Rich Caruana and
686Robert DeLine and
687Steven Mark Drucker},
688}
689
690@article{gunaratne2017using,
691 publisher = {Wiley Online Library},
692 year = {2017},
693 pages = {1836--1849},
694 number = {8},
695 volume = {68},
696 journal = {Journal of the Association for Information Science and Technology},
697 author = {Gunaratne, Junius and Nov, Oded},
698 title = {Using interactive “Nutrition labels” for financial products to assist decision making under uncertainty},
699}
700
701@article{zejnilovic2020machine,
702 year = {2020},
703 journal = {Available at SSRN 3715529},
704 author = {Zejnilovic, Leid and Lavado, Susana and Soares, Carlos and Rituerto de Troya, {\'I}{\~n}igo and Bell, Andrew and Ghani, Rayid},
705 title = {Machine Learning Informed Decision-Making: A Field Intervention in Public Employment Service},
706}
707
708@article{zejnilovic2020algorithmic,
709 publisher = {University of California Press},
710 year = {2020},
711 number = {1},
712 volume = {1},
713 journal = {Global Perspectives},
714 author = {Zejnilovi{\'c}, Leid and Lavado, Susana and Mart{\'\i}nez de Rituerto de Troya, {\'I}{\~n}igo and Sim, Samantha and Bell, Andrew},
715 title = {Algorithmic Long-Term Unemployment Risk Assessment in Use: Counselors’ Perceptions and Use Practices},
716}
717
718@article{doshi2017accountability,
719 year = {2017},
720 journal = {arXiv preprint arXiv:1711.01134},
721 author = {Doshi-Velez, Finale and Kortz, Mason and Budish, Ryan and Bavitz, Chris and Gershman, Sam and O'Brien, David and Scott, Kate and Schieber, Stuart and Waldo, James and Weinberger, David and others},
722 title = {Accountability of AI under the law: The role of explanation},
723}
724
725@article{DBLP:journals/corr/abs-2012-01805,
726 bibsource = {dblp computer science bibliography, https://dblp.org},
727 biburl = {https://dblp.org/rec/journals/corr/abs-2012-01805.bib},
728 timestamp = {Fri, 04 Dec 2020 12:07:23 +0100},
729 eprint = {2012.01805},
730 archiveprefix = {arXiv},
731 url = {https://arxiv.org/abs/2012.01805},
732 year = {2020},
733 volume = {abs/2012.01805},
734 journal = {CoRR},
735 title = {Interpretability and Explainability: {A} Machine Learning Zoo Mini-tour},
736 author = {Ricards Marcinkevics and
737Julia E. Vogt},
738}
739
740@article{wilson2021building,
741 year = {2021},
742 author = {Wilson, Christo and Ghosh, Avijit and Jiang, Shan and Mislove, Alan and Baker, Lewis and Szary, Janelle and Trindel, Kelly and Polli, Frida},
743 title = {Building and Auditing Fair Algorithms: A Case Study in Candidate Screening},
744}
745
746@article{meyers2007street,
747 publisher = {sage Publications London, UK},
748 year = {2007},
749 pages = {153--163},
750 journal = {The handbook of public administration},
751 author = {Meyers, Marcia K and Vorsanger, Susan and Peters, B Guy and Pierre, Jon},
752 title = {Street-level bureaucrats and the implementation of public policy},
753}
754
755@article{tal2016blinded,
756 publisher = {SAGE Publications Sage UK: London, England},
757 year = {2016},
758 pages = {117--125},
759 number = {1},
760 volume = {25},
761 journal = {Public Understanding of Science},
762 author = {Tal, Aner and Wansink, Brian},
763 title = {Blinded with science: Trivial graphs and formulas increase ad persuasiveness and belief in product efficacy},
764}
765
766@inproceedings{pandey2015deceptive,
767 year = {2015},
768 pages = {1469--1478},
769 booktitle = {Proceedings of the 33rd annual acm conference on human factors in computing systems},
770 author = {Pandey, Anshul Vikram and Rall, Katharina and Satterthwaite, Margaret L and Nov, Oded and Bertini, Enrico},
771 title = {How deceptive are deceptive visualizations? An empirical analysis of common distortion techniques},
772}
773
774@article{DBLP:journals/tvcg/PandeyMNSB14,
775 bibsource = {dblp computer science bibliography, https://dblp.org},
776 biburl = {https://dblp.org/rec/journals/tvcg/PandeyMNSB14.bib},
777 timestamp = {Wed, 14 Nov 2018 10:22:06 +0100},
778 doi = {10.1109/TVCG.2014.2346419},
779 url = {https://doi.org/10.1109/TVCG.2014.2346419},
780 year = {2014},
781 pages = {2211--2220},
782 number = {12},
783 volume = {20},
784 journal = {{IEEE} Trans. Vis. Comput. Graph.},
785 title = {The Persuasive Power of Data Visualization},
786 author = {Anshul Vikram Pandey and
787Anjali Manivannan and
788Oded Nov and
789Margaret Satterthwaite and
790Enrico Bertini},
791}
792
793@article{wachter2017counterfactual,
794 publisher = {HeinOnline},
795 year = {2017},
796 pages = {841},
797 volume = {31},
798 journal = {Harv. JL \& Tech.},
799 author = {Wachter, Sandra and Mittelstadt, Brent and Russell, Chris},
800 title = {Counterfactual explanations without opening the black box: Automated decisions and the GDPR},
801}
802
803@inproceedings{ustun2019actionable,
804 year = {2019},
805 pages = {10--19},
806 booktitle = {Proceedings of the conference on fairness, accountability, and transparency},
807 author = {Ustun, Berk and Spangher, Alexander and Liu, Yang},
808 title = {Actionable recourse in linear classification},
809}
810
811@article{edwards2018enslaving,
812 publisher = {IEEE},
813 year = {2018},
814 pages = {46--54},
815 number = {3},
816 volume = {16},
817 journal = {IEEE Security \& Privacy},
818 author = {Edwards, Lilian and Veale, Michael},
819 title = {Enslaving the algorithm: From a “Right to an Explanation” to a “Right to Better Decisions”?},
820}
821
822@article{malgieri2019automated,
823 publisher = {Elsevier},
824 year = {2019},
825 pages = {105327},
826 number = {5},
827 volume = {35},
828 journal = {Computer law \& security review},
829 author = {Malgieri, Gianclaudio},
830 title = {Automated decision-making in the EU Member States: The right to explanation and other “suitable safeguards” in the national legislations},
831}
832
833@misc{bhatt2020explainable,
834 primaryclass = {cs.LG},
835 archiveprefix = {arXiv},
836 eprint = {1909.06342},
837 year = {2020},
838 author = {Umang Bhatt and Alice Xiang and Shubham Sharma and Adrian Weller and Ankur Taly and Yunhan Jia and Joydeep Ghosh and Ruchir Puri and José M. F. Moura and Peter Eckersley},
839 title = {Explainable Machine Learning in Deployment},
840}
841
842@misc{slack2020fooling,
843 primaryclass = {cs.LG},
844 archiveprefix = {arXiv},
845 eprint = {1911.02508},
846 year = {2020},
847 author = {Dylan Slack and Sophie Hilgard and Emily Jia and Sameer Singh and Himabindu Lakkaraju},
848 title = {Fooling LIME and SHAP: Adversarial Attacks on Post hoc Explanation Methods},
849}
850
851@article{guidotti2018survey,
852 bibsource = {dblp computer science bibliography, https://dblp.org},
853 biburl = {https://dblp.org/rec/journals/csur/GuidottiMRTGP19.bib},
854 timestamp = {Sat, 08 Jan 2022 02:23:15 +0100},
855 doi = {10.1145/3236009},
856 url = {https://doi.org/10.1145/3236009},
857 year = {2019},
858 pages = {93:1--93:42},
859 number = {5},
860 volume = {51},
861 journal = {{ACM} Comput. Surv.},
862 title = {A Survey of Methods for Explaining Black Box Models},
863 author = {Riccardo Guidotti and
864Anna Monreale and
865Salvatore Ruggieri and
866Franco Turini and
867Fosca Giannotti and
868Dino Pedreschi},
869}
870
871@article{DBLP:journals/corr/abs-2004-00668,
872 bibsource = {dblp computer science bibliography, https://dblp.org},
873 biburl = {https://dblp.org/rec/journals/corr/abs-2004-00668.bib},
874 timestamp = {Fri, 26 Nov 2021 16:33:35 +0100},
875 eprint = {2004.00668},
876 eprinttype = {arXiv},
877 url = {https://arxiv.org/abs/2004.00668},
878 year = {2020},
879 volume = {abs/2004.00668},
880 journal = {CoRR},
881 title = {DBLP:journals/corr/abs-2004-00668 Feature Contributions Through Additive Importance
882Measures},
883 author = {Ian Covert and
884Scott M. Lundberg and
885Su{-}In Lee},
886}
887
888@article{Black_2020,
889 month = {Jan},
890 year = {2020},
891 author = {Black, Emily and Yeom, Samuel and Fredrikson, Matt},
892 publisher = {ACM},
893 journal = {Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency},
894 doi = {10.1145/3351095.3372845},
895 url = {http://dx.doi.org/10.1145/3351095.3372845},
896 isbn = {9781450369367},
897 title = {FlipTest},
898}
899
900@article{osti_10182459,
901 author = {Yang, Ke and Huang, Biao and Stoyanovich, Julia and Schelter, Sebastian},
902 journal = {Workshop on Human-In-the-Loop Data Analytics (HILDA'20)},
903 abstractnote = {Surfacing and mitigating bias in ML pipelines is a complex topic, with a dire need to provide system-level support to data scientists. Humans should be empowered to debug these pipelines, in order to control for bias and to improve data quality and representativeness. We propose fairDAGs, an open-source library that extracts directed acyclic graph (DAG) representations of the data flow in preprocessing pipelines for ML. The library subsequently instruments the pipelines with tracing and visualization code to capture changes in data distributions and identify distortions with respect to protected group membership as the data travels through the pipeline. We illustrate the utility of fairDAGs, with experiments on publicly available ML pipelines.},
904 doi = {10.1145/3398730.3399194},
905 url = {https://par.nsf.gov/biblio/10182459},
906 title = {Fairness-Aware Instrumentation of Preprocessing~Pipelines for Machine Learning},
907 place = {Country unknown/Code not available},
908}
909
910@misc{marcinkevics2020interpretability,
911 primaryclass = {cs.LG},
912 archiveprefix = {arXiv},
913 eprint = {2012.01805},
914 year = {2020},
915 author = {Ričards Marcinkevičs and Julia E. Vogt},
916 title = {Interpretability and Explainability: A Machine Learning Zoo Mini-tour},
917}
918
919@misc{saha2020measuring,
920 primaryclass = {cs.CY},
921 archiveprefix = {arXiv},
922 eprint = {2001.00089},
923 year = {2020},
924 author = {Debjani Saha and Candice Schumann and Duncan C. McElfresh and John P. Dickerson and Michelle L. Mazurek and Michael Carl Tschantz},
925 title = {Measuring Non-Expert Comprehension of Machine Learning Fairness Metrics},
926}
927
928@article{STUMPF2009639,
929 abstract = {Although machine learning is becoming commonly used in today's software, there has been little research into how end users might interact with machine learning systems, beyond communicating simple “right/wrong” judgments. If the users themselves could work hand-in-hand with machine learning systems, the users’ understanding and trust of the system could improve and the accuracy of learning systems could be improved as well. We conducted three experiments to understand the potential for rich interactions between users and machine learning systems. The first experiment was a think-aloud study that investigated users’ willingness to interact with machine learning reasoning, and what kinds of feedback users might give to machine learning systems. We then investigated the viability of introducing such feedback into machine learning systems, specifically, how to incorporate some of these types of user feedback into machine learning systems, and what their impact was on the accuracy of the system. Taken together, the results of our experiments show that supporting rich interactions between users and machine learning systems is feasible for both user and machine. This shows the potential of rich human–computer collaboration via on-the-spot interactions as a promising direction for machine learning systems and users to collaboratively share intelligence.},
930 keywords = {Intelligent user interfaces, Rich feedback, Explanations, Machine learning},
931 author = {Simone Stumpf and Vidya Rajaram and Lida Li and Weng-Keen Wong and Margaret Burnett and Thomas Dietterich and Erin Sullivan and Jonathan Herlocker},
932 url = {https://www.sciencedirect.com/science/article/pii/S1071581909000457},
933 doi = {https://doi.org/10.1016/j.ijhcs.2009.03.004},
934 issn = {1071-5819},
935 year = {2009},
936 pages = {639-662},
937 number = {8},
938 volume = {67},
939 journal = {International Journal of Human-Computer Studies},
940 title = {Interacting meaningfully with machine learning systems: Three experiments},
941}
942
943@article{Obermeyer447,
944 journal = {Science},
945 eprint = {https://science.sciencemag.org/content/366/6464/447.full.pdf},
946 url = {https://science.sciencemag.org/content/366/6464/447},
947 issn = {0036-8075},
948 abstract = {The U.S. health care system uses commercial algorithms to guide health decisions. Obermeyer et al. find evidence of racial bias in one widely used algorithm, such that Black patients assigned the same level of risk by the algorithm are sicker than White patients (see the Perspective by Benjamin). The authors estimated that this racial bias reduces the number of Black patients identified for extra care by more than half. Bias occurs because the algorithm uses health costs as a proxy for health needs. Less money is spent on Black patients who have the same level of need, and the algorithm thus falsely concludes that Black patients are healthier than equally sick White patients. Reformulating the algorithm so that it no longer uses costs as a proxy for needs eliminates the racial bias in predicting who needs extra care.Science, this issue p. 447; see also p. 421Health systems rely on commercial prediction algorithms to identify and help patients with complex health needs. We show that a widely used algorithm, typical of this industry-wide approach and affecting millions of patients, exhibits significant racial bias: At a given risk score, Black patients are considerably sicker than White patients, as evidenced by signs of uncontrolled illnesses. Remedying this disparity would increase the percentage of Black patients receiving additional help from 17.7 to 46.5\%. The bias arises because the algorithm predicts health care costs rather than illness, but unequal access to care means that we spend less money caring for Black patients than for White patients. Thus, despite health care cost appearing to be an effective proxy for health by some measures of predictive accuracy, large racial biases arise. We suggest that the choice of convenient, seemingly effective proxies for ground truth can be an important source of algorithmic bias in many contexts.},
949 publisher = {American Association for the Advancement of Science},
950 doi = {10.1126/science.aax2342},
951 year = {2019},
952 pages = {447--453},
953 number = {6464},
954 volume = {366},
955 title = {Dissecting racial bias in an algorithm used to manage the health of populations},
956 author = {Obermeyer, Ziad and Powers, Brian and Vogeli, Christine and Mullainathan, Sendhil},
957}
958
959@article{BARTLETT2021,
960 abstract = {U.S. fair-lending law prohibits lenders from making credit determinations that disparately affect minority borrowers if those determinations are based on characteristics unrelated to creditworthiness. Using an identification under this rule, we show risk-equivalent Latinx/Black borrowers pay significantly higher interest rates on GSE-securitized and FHA-insured loans, particularly in high-minority-share neighborhoods. We estimate these rate differences cost minority borrowers over $450 million yearly. FinTech lenders’ rate disparities were similar to those of non-Fintech lenders for GSE mortgages, but lower for FHA mortgages issued in 2009–2015 and for FHA refi mortgages issued in 2018–2019.},
961 keywords = {Discrimination, FinTech, GSE mortgages, Credit scoring, Algorithmic underwriting, Big-data lending, Platform loans, Statistical discrimination, Legitimate business necessity},
962 author = {Robert Bartlett and Adair Morse and Richard Stanton and Nancy Wallace},
963 url = {https://www.sciencedirect.com/science/article/pii/S0304405X21002403},
964 doi = {https://doi.org/10.1016/j.jfineco.2021.05.047},
965 issn = {0304-405X},
966 year = {2021},
967 journal = {Journal of Financial Economics},
968 title = {Consumer-lending discrimination in the FinTech Era},
969}
970
971@misc{holstein2021equity,
972 primaryclass = {cs.HC},
973 archiveprefix = {arXiv},
974 eprint = {2104.12920},
975 year = {2021},
976 author = {Kenneth Holstein and Shayan Doroudi},
977 title = {Equity and Artificial Intelligence in Education: Will "AIEd" Amplify or Alleviate Inequities in Education?},
978}
979
980@misc{baker_hawn_2021,
981 month = {Mar},
982 year = {2021},
983 author = {Baker, Ryan S and Hawn, Aaron},
984 publisher = {EdArXiv},
985 doi = {10.35542/osf.io/pbmvz},
986 url = {edarxiv.org/pbmvz},
987 title = {Algorithmic Bias in Education},
988}
989
990@misc{hu_2020,
991 month = {Jun},
992 year = {2020},
993 author = {Hu, Qian|Rangwala},
994 publisher = {International Educational Data Mining Society. e-mail: [email protected]; Web site: http://www.educationaldatamining.org},
995 journal = {International Educational Data Mining Society},
996 url = {https://eric.ed.gov/?id=ED608050},
997 title = {Towards Fair Educational Data Mining: A Case Study on Detecting At-Risk Students.},
998}
999
1000@inproceedings{Sapiezynski2017AcademicPP,
1001 year = {2017},
1002 author = {Piotr Sapiezynski and Valentin Kassarnig and Christo Wilson},
1003 title = {Academic performance prediction in a gender-imbalanced environment},
1004}
1005
1006@misc{lundberg2017unified,
1007 primaryclass = {cs.AI},
1008 archiveprefix = {arXiv},
1009 eprint = {1705.07874},
1010 year = {2017},
1011 author = {Scott Lundberg and Su-In Lee},
1012 title = {A Unified Approach to Interpreting Model Predictions},
1013}
1014
1015@misc{ribeiro2016why,
1016 primaryclass = {cs.LG},
1017 archiveprefix = {arXiv},
1018 eprint = {1602.04938},
1019 year = {2016},
1020 author = {Marco Tulio Ribeiro and Sameer Singh and Carlos Guestrin},
1021 title = {"Why Should I Trust You?": Explaining the Predictions of Any Classifier},
1022}
1023
1024@article{ECOA1994,
1025 url = {https://www.fdic.gov/resources/supervision-and-examinations/consumer-compliance-examination-manual/documents/4/iv-1-1.pdf},
1026 year = {1994},
1027 title = {IV. Fair Lending — Fair Lending Laws and Regulations},
1028 author = {FDIC: Federal Deposit Insurance Corporation},
1029}
1030
1031@article{lee2018detecting,
1032 publisher = {Emerald Publishing Limited},
1033 year = {2018},
1034 journal = {Journal of Information, Communication and Ethics in Society},
1035 author = {Lee, Nicol Turner},
1036 title = {Detecting racial bias in algorithms and machine learning},
1037}
1038
1039@article{decamp2020latent,
1040 publisher = {Oxford University Press},
1041 year = {2020},
1042 pages = {2020--2023},
1043 number = {12},
1044 volume = {27},
1045 journal = {Journal of the American Medical Informatics Association},
1046 author = {DeCamp, Matthew and Lindvall, Charlotta},
1047 title = {Latent bias and the implementation of artificial intelligence in medicine},
1048}
1049
1050@article{DBLP:journals/corr/abs-2102-03054,
1051 bibsource = {dblp computer science bibliography, https://dblp.org},
1052 biburl = {https://dblp.org/rec/journals/corr/abs-2102-03054.bib},
1053 timestamp = {Wed, 10 Feb 2021 15:24:31 +0100},
1054 eprint = {2102.03054},
1055 eprinttype = {arXiv},
1056 url = {https://arxiv.org/abs/2102.03054},
1057 year = {2021},
1058 volume = {abs/2102.03054},
1059 journal = {CoRR},
1060 title = {Removing biased data to improve fairness and accuracy},
1061 author = {Sahil Verma and
1062Michael D. Ernst and
1063Ren{\'{e}} Just},
1064}
1065
1066@article{FHA1968,
1067 url = {https://www.fdic.gov/regulations/laws/rules/6000-1400.html},
1068 year = {1968},
1069 title = {Civil Rights Act of 1968},
1070 author = {FDIC: Federal Deposit Insurance Corporation},
1071}
1072
1073@article{gunning2019xai,
1074 publisher = {Science Robotics},
1075 year = {2019},
1076 number = {37},
1077 volume = {4},
1078 journal = {Science Robotics},
1079 author = {Gunning, David and Stefik, Mark and Choi, Jaesik and Miller, Timothy and Stumpf, Simone and Yang, Guang-Zhong},
1080 title = {XAI—Explainable artificial intelligence},
1081}
1082
1083@article{doshivelez2017rigorous,
1084 primaryclass = {stat.ML},
1085 archiveprefix = {arXiv},
1086 eprint = {1702.08608},
1087 year = {2017},
1088 author = {Finale Doshi-Velez and Been Kim},
1089 title = {Towards A Rigorous Science of Interpretable Machine Learning},
1090}
1091
1092@inproceedings{NIPS2016_5680522b,
1093 year = {2016},
1094 volume = {29},
1095 url = {https://proceedings.neurips.cc/paper/2016/file/5680522b8e2bb01943234bce7bf84534-Paper.pdf},
1096 title = {Examples are not enough, learn to criticize! Criticism for Interpretability},
1097 publisher = {Curran Associates, Inc.},
1098 pages = {},
1099 editor = {D. Lee and M. Sugiyama and U. Luxburg and I. Guyon and R. Garnett},
1100 booktitle = {Advances in Neural Information Processing Systems},
1101 author = {Kim, Been and Khanna, Rajiv and Koyejo, Oluwasanmi O},
1102}
1103
1104@misc{hara2016making,
1105 primaryclass = {stat.ML},
1106 archiveprefix = {arXiv},
1107 eprint = {1606.05390},
1108 year = {2016},
1109 author = {Satoshi Hara and Kohei Hayashi},
1110 title = {Making Tree Ensembles Interpretable},
1111}
1112
1113@misc{julia_angwin_2016,
1114 month = {May},
1115 year = {2016},
1116 author = {Julia Angwin, Jeff Larson},
1117 journal = {ProPublica},
1118 url = {https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing},
1119 title = {Machine Bias},
1120}
1121
1122@article{Hong_2020,
1123 pages = {1–26},
1124 month = {May},
1125 year = {2020},
1126 author = {Hong, Sungsoo Ray and Hullman, Jessica and Bertini, Enrico},
1127 publisher = {Association for Computing Machinery (ACM)},
1128 journal = {Proceedings of the ACM on Human-Computer Interaction},
1129 number = {CSCW1},
1130 doi = {10.1145/3392878},
1131 url = {http://dx.doi.org/10.1145/3392878},
1132 issn = {2573-0142},
1133 volume = {4},
1134 title = {Human Factors in Model Interpretability: Industry Practices, Challenges, and Needs},
1135}
1136
1137@article{narayanan2018humans,
1138 year = {2018},
1139 journal = {arXiv preprint arXiv:1802.00682},
1140 author = {Narayanan, Menaka and Chen, Emily and He, Jeffrey and Kim, Been and Gershman, Sam and Doshi-Velez, Finale},
1141 title = {How do humans understand explanations from machine learning systems? an evaluation of the human-interpretability of explanation},
1142}
1143
1144@inproceedings{zejnilovic2021machine,
1145 organization = {Academy of Management Briarcliff Manor, NY 10510},
1146 year = {2021},
1147 pages = {15424},
1148 number = {1},
1149 volume = {2021},
1150 booktitle = {Academy of Management Proceedings},
1151 author = {Zejnilovic, Leid and Lavado, Susana and Soares, Carlos and Mart{\'\i}nez De Rituerto De Troya, {\'I}{\~n}igo and Bell, Andrew and Ghani, Rayid},
1152 title = {Machine Learning Informed Decision-Making with Interpreted Model’s Outputs: A Field Intervention},
1153}
1154
1155@article{10.1525/gp.2020.12908,
1156 eprint = {https://online.ucpress.edu/gp/article-pdf/1/1/12908/462946/12908.pdf},
1157 note = {12908},
1158 url = {https://doi.org/10.1525/gp.2020.12908},
1159 doi = {10.1525/gp.2020.12908},
1160 issn = {2575-7350},
1161 abstract = {{The recent surge of interest in algorithmic decision-making among scholars across disciplines is associated with its potential to resolve the challenges common to administrative decision-making in the public sector, such as greater fairness and equal treatment of each individual, among others. However, algorithmic decision-making combined with human judgment may introduce new complexities with unclear consequences. This article offers evidence that contributes to the ongoing discussion about algorithmic decision-making and governance, contextualizing it within a public employment service. In particular, we discuss the use of a decision support system that employs an algorithm to assess individual risk of becoming long-term unemployed and that informs counselors to assign interventions accordingly. We study the human interaction with algorithms in this context using the lenses of human detachment from and attachment to decision-making. Employing a mixed-method research approach, we show the complexity of enacting the potentials of the data-driven decision-making in the context of a public agency.}},
1162 month = {06},
1163 year = {2020},
1164 number = {1},
1165 volume = {1},
1166 journal = {Global Perspectives},
1167 title = {{Algorithmic Long-Term Unemployment Risk Assessment in Use: Counselors’ Perceptions and Use Practices}},
1168 author = {Zejnilović, Leid and Lavado, Susana and Martínez de Rituerto de Troya, Íñigo and Sim, Samantha and Bell, Andrew},
1169}
1170
1171@article{huysmans2006using,
1172 publisher = {KU Leuven KBI Working Paper},
1173 year = {2006},
1174 author = {Huysmans, Johan and Baesens, Bart and Vanthienen, Jan},
1175 title = {Using rule extraction to improve the comprehensibility of predictive models},
1176}
1177
1178@inproceedings{bell2019proactive,
1179 organization = {IEEE},
1180 year = {2019},
1181 pages = {1--6},
1182 booktitle = {2019 IEEE International Conference on Healthcare Informatics (ICHI)},
1183 author = {Bell, Andrew and Rich, Alexander and Teng, Melisande and Ore{\v{s}}kovi{\'c}, Tin and Bras, Nuno B and Mestrinho, L{\'e}nia and Golubovic, Srdan and Pristas, Ivan and Zejnilovic, Leid},
1184 title = {Proactive advising: a machine learning driven approach to vaccine hesitancy},
1185}
1186
1187@article{stiglic2015comprehensible,
1188 publisher = {Public Library of Science San Francisco, CA USA},
1189 year = {2015},
1190 pages = {e0144439},
1191 number = {12},
1192 volume = {10},
1193 journal = {PloS one},
1194 author = {Stiglic, Gregor and Povalej Brzan, Petra and Fijacko, Nino and Wang, Fei and Delibasic, Boris and Kalousis, Alexandros and Obradovic, Zoran},
1195 title = {Comprehensible predictive modeling using regularized logistic regression and comorbidity based features},
1196}
1197
1198@inproceedings{de2018predicting,
1199 year = {2018},
1200 booktitle = {NeurIPS Workshop on AI for Social Good},
1201 author = {de Troya, Inigo Martinez and Chen, Ruqian and Moraes, Laura O and Bajaj, Pranjal and Kupersmith, Jordan and Ghani, Rayid and Br{\'a}s, Nuno B and Zejnilovic, Leid},
1202 title = {Predicting, explaining, and understanding risk of long-term unemployment},
1203}
1204
1205@article{lamba2021empirical,
1206 publisher = {ACM New York, NY, USA},
1207 year = {2021},
1208 pages = {69--85},
1209 number = {1},
1210 volume = {23},
1211 journal = {ACM SIGKDD Explorations Newsletter},
1212 author = {Lamba, Hemank and Rodolfa, Kit T and Ghani, Rayid},
1213 title = {An Empirical Comparison of Bias Reduction Methods on Real-World Problems in High-Stakes Policy Settings},
1214}
1215
1216@article{gleicher2016framework,
1217 publisher = {Mary Ann Liebert, Inc. 140 Huguenot Street, 3rd Floor New Rochelle, NY 10801 USA},
1218 year = {2016},
1219 pages = {75--88},
1220 number = {2},
1221 volume = {4},
1222 journal = {Big data},
1223 author = {Gleicher, Michael},
1224 title = {A framework for considering comprehensibility in modeling},
1225}
1226
1227@article{wilde_2021,
1228 pages = {e2},
1229 year = {2021},
1230 author = {Wilde, Harrison and Chen, Lucia L. and Nguyen, Austin and Kimpel, Zoe and Sidgwick, Joshua and De Unanue, Adolfo and Veronese, Davide and Mateen, Bilal and Ghani, Rayid and Vollmer, Sebastian and et al.},
1231 publisher = {Cambridge University Press},
1232 journal = {Data and Policy},
1233 doi = {10.1017/dap.2020.23},
1234 volume = {3},
1235 title = {A recommendation and risk classification system for connecting rough sleepers to essential outreach services},
1236}
1237
1238@inproceedings{carton2016identifying,
1239 year = {2016},
1240 pages = {67--76},
1241 booktitle = {Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining},
1242 author = {Carton, Samuel and Helsby, Jennifer and Joseph, Kenneth and Mahmud, Ayesha and Park, Youngsoo and Walsh, Joe and Cody, Crystal and Patterson, CPT Estella and Haynes, Lauren and Ghani, Rayid},
1243 title = {Identifying police officers at risk of adverse events},
1244}
1245
1246@inproceedings{aguiar2015and,
1247 year = {2015},
1248 pages = {93--102},
1249 booktitle = {Proceedings of the Fifth International Conference on Learning Analytics And Knowledge},
1250 author = {Aguiar, Everaldo and Lakkaraju, Himabindu and Bhanpuri, Nasir and Miller, David and Yuhas, Ben and Addison, Kecia L},
1251 title = {Who, when, and why: A machine learning approach to prioritizing students at risk of not graduating high school on time},
1252}
1253
1254@article{holzinger2020measuring,
1255 publisher = {Springer},
1256 year = {2020},
1257 pages = {1--6},
1258 journal = {KI-K{\"u}nstliche Intelligenz},
1259 author = {Holzinger, Andreas and Carrington, Andr{\'e} and M{\"u}ller, Heimo},
1260 title = {Measuring the quality of explanations: the system causability scale (SCS)},
1261}
1262
1263@article{aha1988instance,
1264 year = {1988},
1265 pages = {3--2},
1266 number = {1},
1267 volume = {3},
1268 journal = {University of California},
1269 author = {Aha, D and Kibler, Dennis},
1270 title = {Instance-based prediction of heart-disease presence with the Cleveland database},
1271}
1272
1273@misc{das2020opportunities,
1274 primaryclass = {cs.CV},
1275 archiveprefix = {arXiv},
1276 eprint = {2006.11371},
1277 year = {2020},
1278 author = {Arun Das and Paul Rad},
1279 title = {Opportunities and Challenges in Explainable Artificial Intelligence (XAI): A Survey},
1280}
1281
1282@article{10.1093/jamia/ocz229,
1283 eprint = {https://academic.oup.com/jamia/article-pdf/27/4/592/34153285/ocz229.pdf},
1284 url = {https://doi.org/10.1093/jamia/ocz229},
1285 doi = {10.1093/jamia/ocz229},
1286 issn = {1527-974X},
1287 abstract = {{Implementation of machine learning (ML) may be limited by patients’ right to “meaningful information about the logic involved” when ML influences healthcare decisions. Given the complexity of healthcare decisions, it is likely that ML outputs will need to be understood and trusted by physicians, and then explained to patients. We therefore investigated the association between physician understanding of ML outputs, their ability to explain these to patients, and their willingness to trust the ML outputs, using various ML explainability methods.We designed a survey for physicians with a diagnostic dilemma that could be resolved by an ML risk calculator. Physicians were asked to rate their understanding, explainability, and trust in response to 3 different ML outputs. One ML output had no explanation of its logic (the control) and 2 ML outputs used different model-agnostic explainability methods. The relationships among understanding, explainability, and trust were assessed using Cochran-Mantel-Haenszel tests of association.The survey was sent to 1315 physicians, and 170 (13\\%) provided completed surveys. There were significant associations between physician understanding and explainability (P \\< .001), between physician understanding and trust (P \\< .001), and between explainability and trust (P \\< .001). ML outputs that used model-agnostic explainability methods were preferred by 88\\% of physicians when compared with the control condition; however, no particular ML explainability method had a greater influence on intended physician behavior.Physician understanding, explainability, and trust in ML risk calculators are related. Physicians preferred ML outputs accompanied by model-agnostic explanations but the explainability method did not alter intended physician behavior.}},
1288 month = {02},
1289 year = {2020},
1290 pages = {592-600},
1291 number = {4},
1292 volume = {27},
1293 journal = {Journal of the American Medical Informatics Association},
1294 title = {{Physician understanding, explainability, and trust in a hypothetical machine learning risk calculator}},
1295 author = {Diprose, William K and Buist, Nicholas and Hua, Ning and Thurier, Quentin and Shand, George and Robinson, Reece},
1296}
1297
1298@article{10.1002/isaf.1422,
1299 year = {2018},
1300 abstract = {Summary Recent rapid progress in machine learning (ML), particularly so-called ‘deep learning’, has led to a resurgence in interest in explainability of artificial intelligence (AI) systems, reviving an area of research dating back to the 1970s. The aim of this article is to view current issues concerning ML-based AI systems from the perspective of classical AI, showing that the fundamental problems are far from new, and arguing that elements of that earlier work offer routes to making progress towards explainable AI today.},
1301 eprint = {https://onlinelibrary.wiley.com/doi/pdf/10.1002/isaf.1422},
1302 url = {https://onlinelibrary.wiley.com/doi/abs/10.1002/isaf.1422},
1303 doi = {https://doi.org/10.1002/isaf.1422},
1304 keywords = {artificial intelligence, explainability, interpretability, machine learning},
1305 pages = {63-72},
1306 number = {2},
1307 volume = {25},
1308 journal = {Intelligent Systems in Accounting, Finance and Management},
1309 title = {Asking ‘Why’ in AI: Explainability of intelligent systems – perspectives and challenges},
1310 author = {Preece, Alun},
1311}
1312
1313@article{Ehsan_2021,
1314 month = {May},
1315 year = {2021},
1316 author = {Ehsan, Upol and Liao, Q. Vera and Muller, Michael and Riedl, Mark O. and Weisz, Justin D.},
1317 publisher = {ACM},
1318 journal = {Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems},
1319 doi = {10.1145/3411764.3445188},
1320 url = {http://dx.doi.org/10.1145/3411764.3445188},
1321 isbn = {9781450380966},
1322 title = {Expanding Explainability: Towards Social Transparency in AI systems},
1323}
1324
1325@inproceedings{abdul2020cogam,
1326 year = {2020},
1327 pages = {1--14},
1328 booktitle = {Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems},
1329 author = {Abdul, Ashraf and von der Weth, Christian and Kankanhalli, Mohan and Lim, Brian Y},
1330 title = {COGAM: Measuring and Moderating Cognitive Load in Machine Learning Model Explanations},
1331}
1332
1333@inproceedings{10.1145/1620545.1620576,
1334 series = {UbiComp '09},
1335 location = {Orlando, Florida, USA},
1336 keywords = {explanations, context-aware, satisfaction, intelligibility},
1337 numpages = {10},
1338 pages = {195–204},
1339 booktitle = {Proceedings of the 11th International Conference on Ubiquitous Computing},
1340 abstract = {Intelligibility can help expose the inner workings and inputs of context-aware applications
1341that tend to be opaque to users due to their implicit sensing and actions. However,
1342users may not be interested in all the information that the applications can produce.
1343Using scenarios of four real-world applications that span the design space of context-aware
1344computing, we conducted two experiments to discover what information users are interested
1345in. In the first experiment, we elicit types of information demands that users have
1346and under what moderating circumstances they have them. In the second experiment,
1347we verify the findings by soliciting users about which types they would want to know
1348and establish whether receiving such information would satisfy them. We discuss why
1349users demand certain types of information, and provide design implications on how
1350to provide different intelligibility types to make context-aware applications intelligible
1351and acceptable to users.},
1352 doi = {10.1145/1620545.1620576},
1353 url = {https://doi.org/10.1145/1620545.1620576},
1354 address = {New York, NY, USA},
1355 publisher = {Association for Computing Machinery},
1356 isbn = {9781605584317},
1357 year = {2009},
1358 title = {Assessing Demand for Intelligibility in Context-Aware Applications},
1359 author = {Lim, Brian Y. and Dey, Anind K.},
1360}
1361
1362@inbook{10.1145/1518701.1519023,
1363 numpages = {10},
1364 pages = {2119–2128},
1365 booktitle = {Proceedings of the SIGCHI Conference on Human Factors in Computing Systems},
1366 abstract = {Context-aware intelligent systems employ implicit inputs, and make decisions based
1367on complex rules and machine learning models that are rarely clear to users. Such
1368lack of system intelligibility can lead to loss of user trust, satisfaction and acceptance
1369of these systems. However, automatically providing explanations about a system's decision
1370process can help mitigate this problem. In this paper we present results from a controlled
1371study with over 200 participants in which the effectiveness of different types of
1372explanations was examined. Participants were shown examples of a system's operation
1373along with various automatically generated explanations, and then tested on their
1374understanding of the system. We show, for example, that explanations describing why
1375the system behaved a certain way resulted in better understanding and stronger feelings
1376of trust. Explanations describing why the system did not behave a certain way, resulted
1377in lower understanding yet adequate performance. We discuss implications for the use
1378of our findings in real-world context-aware applications.},
1379 url = {https://doi.org/10.1145/1518701.1519023},
1380 address = {New York, NY, USA},
1381 publisher = {Association for Computing Machinery},
1382 isbn = {9781605582467},
1383 year = {2009},
1384 title = {Why and Why Not Explanations Improve the Intelligibility of Context-Aware Intelligent Systems},
1385 author = {Lim, Brian Y. and Dey, Anind K. and Avrahami, Daniel},
1386}
1387
1388@book{10.5555/3208509,
1389 abstract = {Naomi Klein: "This book is downright scary."Ethan Zuckerman, MIT: "Should be required
1390reading."Dorothy Roberts, author of Killing the Black Body: "A must-read."Astra Taylor,
1391author of The People's Platform: "The single most important book about technology
1392you will read this year."Cory Doctorow: "Indispensable."A powerful investigative look
1393at data-based discriminationand how technology affects civil and human rights and
1394economic equity The State of Indiana denies one million applications for healthcare,
1395foodstamps and cash benefits in three yearsbecause a new computer system interprets
1396any mistake as failure to cooperate. In Los Angeles, an algorithm calculates the comparative
1397vulnerability of tens of thousands of homeless people in order to prioritize them
1398for an inadequate pool of housing resources. In Pittsburgh, a child welfare agency
1399uses a statistical model to try to predict which children might be future victims
1400of abuse or neglect. Since the dawn of the digital age, decision-making in finance,
1401employment, politics, health and human services has undergone revolutionary change.
1402Today, automated systemsrather than humanscontrol which neighborhoods get policed,
1403which families attain needed resources, and who is investigated for fraud. While we
1404all live under this new regime of data, the most invasive and punitive systems are
1405aimed at the poor. In Automating Inequality, Virginia Eubanks systematically investigates
1406the impacts of data mining, policy algorithms, and predictive risk models on poor
1407and working-class people in America. The book is full of heart-wrenching and eye-opening
1408stories, from a woman in Indiana whose benefits are literally cut off as she lays
1409dying to a family in Pennsylvania in daily fear of losing their daughter because they
1410fit a certain statistical profile. The U.S. has always used its most cutting-edge
1411science and technology to contain, investigate, discipline and punish the destitute.
1412Like the county poorhouse and scientific charity before them, digital tracking and
1413automated decision-making hide poverty from the middle-class public and give the nation
1414the ethical distance it needs to make inhumane choices: which families get food and
1415which starve, who has housing and who remains homeless, and which families are broken
1416up by the state. In the process, they weaken democracy and betray our most cherished
1417national values. This deeply researched and passionate book could not be more timely.},
1418 address = {USA},
1419 publisher = {St. Martin's Press, Inc.},
1420 isbn = {1250074312},
1421 year = {2018},
1422 title = {Automating Inequality: How High-Tech Tools Profile, Police, and Punish the Poor},
1423 author = {Eubanks, Virginia},
1424}
1425
1426@book{10.5555/3002861,
1427 abstract = {A former Wall Street quant sounds an alarm on the mathematical models that pervade
1428modern life and threaten to rip apart our social fabricWe live in the age of the algorithm.
1429Increasingly, the decisions that affect our liveswhere we go to school, whether we
1430get a car loan, how much we pay for health insuranceare being made not by humans,
1431but by mathematical models. In theory, this should lead to greater fairness: Everyone
1432is judged according to the same rules, and bias is eliminated. But as Cathy ONeil
1433reveals in this urgent and necessary book, the opposite is true. The models being
1434used today are opaque, unregulated, and uncontestable, even when theyre wrong. Most
1435troubling, they reinforce discrimination: If a poor student cant get a loan because
1436a lending model deems him too risky (by virtue of his zip code), hes then cut off
1437from the kind of education that could pull him out of poverty, and a vicious spiral
1438ensues. Models are propping up the lucky and punishing the downtrodden, creating a
1439toxic cocktail for democracy. Welcome to the dark side of Big Data. Tracing the arc
1440of a persons life, ONeil exposes the black box models that shape our future, both
1441as individuals and as a society. These weapons of math destruction score teachers
1442and students, sort rsums, grant (or deny) loans, evaluate workers, target voters,
1443set parole, and monitor our health. ONeil calls on modelers to take more responsibility
1444for their algorithms and on policy makers to regulate their use. But in the end, its
1445up to us to become more savvy about the models that govern our lives. This important
1446book empowers us to ask the tough questions, uncover the truth, and demand change.},
1447 address = {USA},
1448 publisher = {Crown Publishing Group},
1449 isbn = {0553418815},
1450 year = {2016},
1451 title = {Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy},
1452 author = {O'Neil, Cathy},
1453}
1454
1455@misc{chouldechova2016fair,
1456 primaryclass = {stat.AP},
1457 archiveprefix = {arXiv},
1458 eprint = {1610.07524},
1459 year = {2016},
1460 author = {Alexandra Chouldechova},
1461 title = {Fair prediction with disparate impact: A study of bias in recidivism prediction instruments},
1462}
1463
1464@article{Goodman_2017,
1465 pages = {50–57},
1466 month = {Oct},
1467 year = {2017},
1468 author = {Goodman, Bryce and Flaxman, Seth},
1469 publisher = {Association for the Advancement of Artificial Intelligence (AAAI)},
1470 journal = {AI Magazine},
1471 number = {3},
1472 doi = {10.1609/aimag.v38i3.2741},
1473 url = {http://dx.doi.org/10.1609/aimag.v38i3.2741},
1474 issn = {0738-4602},
1475 volume = {38},
1476 title = {European Union Regulations on Algorithmic Decision-Making and a “Right to Explanation”},
1477}
1478
1479@inproceedings{Cortez2008UsingDM,
1480 year = {2008},
1481 author = {P. Cortez and A. M. G. Silva},
1482 title = {Using data mining to predict secondary school student performance},
1483}
1484
1485@article{OpenML2013,
1486 address = {New York, NY, USA},
1487 publisher = {ACM},
1488 doi = {10.1145/2641190.2641198},
1489 url = {http://doi.acm.org/10.1145/2641190.2641198},
1490 pages = {49--60},
1491 year = {2013},
1492 number = {2},
1493 volume = {15},
1494 journal = {SIGKDD Explorations},
1495 title = {OpenML: Networked Science in Machine Learning},
1496 author = {Vanschoren, Joaquin and van Rijn, Jan N. and Bischl, Bernd and Torgo, Luis},
1497}
1498
1499@article{miller2019explanation,
1500 publisher = {Elsevier},
1501 year = {2019},
1502 pages = {1--38},
1503 volume = {267},
1504 journal = {Artificial intelligence},
1505 author = {Miller, Tim},
1506 title = {Explanation in artificial intelligence: Insights from the social sciences},
1507}
1508
1509@book{molnar2020interpretable,
1510 publisher = {Lulu. com},
1511 year = {2020},
1512 author = {Molnar, Christoph},
1513 title = {Interpretable machine learning},
1514}
1515
1516@inproceedings{yang2019study,
1517 year = {2019},
1518 booktitle = {IUI Workshops},
1519 author = {Yang, Yiwei and Kandogan, Eser and Li, Yunyao and Sen, Prithviraj and Lasecki, Walter S},
1520 title = {A study on interaction in human-in-the-loop machine learning for text analytics},
1521}
1522
1523@article{ross2017impact,
1524 year = {2017},
1525 journal = {Univerity of Chicago, Harris School of Public Policy Working Paper},
1526 author = {Ross, Robert},
1527 title = {The impact of property tax appeals on vertical equity in Cook County, IL},
1528}
1529
1530@article{amarasinghe2020explainable,
1531 year = {2020},
1532 journal = {arXiv preprint arXiv:2010.14374},
1533 author = {Amarasinghe, Kasun and Rodolfa, Kit and Lamba, Hemank and Ghani, Rayid},
1534 title = {Explainable machine learning for public policy: Use cases, gaps, and research directions},
1535}
1536
1537@inproceedings{jesus2021can,
1538 year = {2021},
1539 pages = {805--815},
1540 booktitle = {Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency},
1541 author = {Jesus, S{\'e}rgio and Bel{\'e}m, Catarina and Balayan, Vladimir and Bento, Jo{\~a}o and Saleiro, Pedro and Bizarro, Pedro and Gama, Jo{\~a}o},
1542 title = {How can I choose an explainer? An Application-grounded Evaluation of Post-hoc Explanations},
1543}
1544
1545@article{fuster2020predictably,
1546 year = {2020},
1547 journal = {The Effects of Machine Learning on Credit Markets (October 1, 2020)},
1548 author = {Fuster, Andreas and Goldsmith-Pinkham, Paul and Ramadorai, Tarun and Walther, Ansgar},
1549 title = {Predictably unequal? the effects of machine learning on credit markets},
1550}
1551
1552@article{dziugaite2020enforcing,
1553 year = {2020},
1554 journal = {arXiv preprint arXiv:2010.13764},
1555 author = {Dziugaite, Gintare Karolina and Ben-David, Shai and Roy, Daniel M},
1556 title = {Enforcing Interpretability and its Statistical Impacts: Trade-offs between Accuracy and Interpretability},
1557}
1558
1559@inproceedings{barocas2020hidden,
1560 year = {2020},
1561 pages = {80--89},
1562 booktitle = {Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency},
1563 author = {Barocas, Solon and Selbst, Andrew D and Raghavan, Manish},
1564 title = {The hidden assumptions behind counterfactual explanations and principal reasons},
1565}
1566
1567@inproceedings{dai2021fair,
1568 year = {2021},
1569 pages = {55--65},
1570 booktitle = {Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society},
1571 author = {Dai, Jessica and Fazelpour, Sina and Lipton, Zachary},
1572 title = {Fair machine learning under partial compliance},
1573}
1574
1575@inproceedings{loi2021towards,
1576 year = {2021},
1577 pages = {757--766},
1578 booktitle = {Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society},
1579 author = {Loi, Michele and Spielkamp, Matthias},
1580 title = {Towards accountability in the use of artificial intelligence for public administrations},
1581}
1582
1583@article{lu2019good,
1584 year = {2019},
1585 journal = {Available at SSRN 3503603},
1586 author = {Lu, Joy and Lee, Dokyun and Kim, Tae Wan and Danks, David},
1587 title = {Good explanation for algorithmic transparency},
1588}
1589
1590@article{jung2017simple,
1591 year = {2017},
1592 journal = {arXiv preprint arXiv:1702.04690},
1593 author = {Jung, Jongbin and Concannon, Connor and Shroff, Ravi and Goel, Sharad and Goldstein, Daniel G},
1594 title = {Simple rules for complex decisions},
1595}
1596
1597@inproceedings{10.1145/3306618.3314274,
1598 series = {AIES '19},
1599 location = {Honolulu, HI, USA},
1600 keywords = {rights, interest theory, right to be forgotten, right to disconnect},
1601 numpages = {1},
1602 pages = {201},
1603 booktitle = {Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society},
1604 abstract = {Over recent decades, technological development has been accompanied by the proposal of new rights by various groups and individuals: the right to public anonymity, the right to be forgotten, and the right to disconnect, for example. Although there is widespread acknowledgment of the motivation behind these proposed rights, there is little agreement about their actual normative status. One potential challenge is that the claims only arise in contingent social-technical contexts, which may affect how we conceive of them ethically (albeit, not necessarily in terms of policy). What sort of morally legitimate rights claims depend on such contingencies? Our paper investigates the grounds on which such proposals might be considered "actual" rights. The full paper can be found at http://www.andrew.cmu.edu/user/cgparker/Parker_Danks_RevealedRights.pdf. We propose the notion of a revealed right, a right that only imposes duties -- and thus is only meaningfully revealed -- in certain technological contexts. Our framework is based on an interest theory approach to rights, which understands rights in terms of a justificatory role: morally important aspects of a person's well-being (interests) ground rights, which then justify holding someone to a duty that promotes or protects that interest. Our framework uses this approach to interpret the conflicts that lead to revealed rights in terms of how technological developments cause shifts in the balance of power to promote particular interests. Different parties can have competing or conflicting interests. It is also generally accepted that some interests are more normatively important than others (even if only within a particular framework). We can refer to this difference in importance by saying that the former interest has less "moral weight" than the latter interest (in that context). The moral weight of an interest is connected to its contribution to the interest-holder's overall well-being, and thereby determines the strength of the reason that a corresponding right provides to justify a duty. Improved technology can offer resources that grant one party increased causal power to realize its interests to the detriment of another's capacity to do so, even while the relative moral weight of their interests remain the same. Such changes in circumstance can make the importance of protecting a particular interest newly salient. If that interest's moral weight justifies establishing a duty to protect it, thereby limiting the threat posed by the new socio-technical context, then a right is revealed. Revealed rights justify realignment between the moral weight and causal power orderings so that people with weightier interests have greater power to protect those interests. In the extended paper, we show how this account can be applied to the interpretation of two recently proposed "rights": the right to be forgotten, and the right to disconnect. Since we are focused on making sense of revealed rights, not any particular substantive theory of interests or well-being, the characterization of 'weights' is a free parameter in this account. Our framework alone cannot provide means to resolve the question of whether specific rights exist, but it can be used to identify empirical questions that need to be answered to decide the existence or non-existence of such rights. The emergence of a revealed right depends on a number of factors, including: whether the plausible uses of the technology could potentially impede another's well-being or interests; whether the technology is sufficiently common to have a wider, social impact; and whether the technology has actually changed the balance of power sufficiently to yield a frequent possibility for misalignment between causal power and moral weight. This approach confronts the question of how, in principle, such rights could be justified, without requiring specific commitments on the ontology of rights. Our account explains why the rhetoric of "new rights" is both accurate (since the rights were not previously recognized) and inaccurate (since the rights were present all along, but without corresponding duties). Further, it explains the rights without grounding their normative status in considerations related to right-holders' capacities to rationally waive or assert claims. This is especially important given that many of the relevant disruptive technological developments pose challenges to understanding by affected parties for the same reasons they pose threats to those parties' well-being. In the course of our discussion, we confront a number of potential objections to the account. We argue that our framework's ability to accommodate highly specific or derivative-seeming rights is un-problematic. We also head off worries that our use of interest theory makes the account likely to recognize absurd rights claims.},
1605 doi = {10.1145/3306618.3314274},
1606 url = {https://doi.org/10.1145/3306618.3314274},
1607 address = {New York, NY, USA},
1608 publisher = {Association for Computing Machinery},
1609 isbn = {9781450363242},
1610 year = {2019},
1611 title = {How Technological Advances Can Reveal Rights},
1612 author = {Parker, Jack and Danks, David},
1613}
1614
1615@article{schmidt2020transparency,
1616 publisher = {Taylor \& Francis},
1617 year = {2020},
1618 pages = {260--278},
1619 number = {4},
1620 volume = {29},
1621 journal = {Journal of Decision Systems},
1622 author = {Schmidt, Philipp and Biessmann, Felix and Teubner, Timm},
1623 title = {Transparency and trust in artificial intelligence systems},
1624}
1625
1626@article{nichols2013consequences,
1627 year = {2013},
1628 journal = {Washington, DC: The Urban Institute},
1629 author = {Nichols, Austin and Mitchell, Josh and Lindner, Stephan},
1630 title = {Consequences of long-term unemployment},
1631}
1632
1633@inproceedings{cech2021tackling,
1634 year = {2021},
1635 pages = {258--268},
1636 booktitle = {C\&T'21: Proceedings of the 10th International Conference on Communities \& Technologies-Wicked Problems in the Age of Tech},
1637 author = {Cech, Florian},
1638 title = {Tackling Algorithmic Transparency in Communal Energy Accounting through Participatory Design},
1639}
1640
1641@inproceedings{eiband2018bringing,
1642 year = {2018},
1643 pages = {211--223},
1644 booktitle = {23rd international conference on intelligent user interfaces},
1645 author = {Eiband, Malin and Schneider, Hanna and Bilandzic, Mark and Fazekas-Con, Julian and Haug, Mareike and Hussmann, Heinrich},
1646 title = {Bringing transparency design into practice},
1647}
1648
1649@article{aizenberg2020designing,
1650 publisher = {SAGE Publications Sage UK: London, England},
1651 year = {2020},
1652 pages = {2053951720949566},
1653 number = {2},
1654 volume = {7},
1655 journal = {Big Data \& Society},
1656 author = {Aizenberg, Evgeni and Van Den Hoven, Jeroen},
1657 title = {Designing for human rights in AI},
1658}
1659
1660@article{gupta2020participatory,
1661 year = {2020},
1662 journal = {arXiv preprint arXiv:2006.00432},
1663 author = {Gupta, Abhishek and De Gasperis, Tania},
1664 title = {Participatory Design to build better contact-and proximity-tracing apps},
1665}
1666
1667@article{preece2018stakeholders,
1668 year = {2018},
1669 journal = {arXiv preprint arXiv:1810.00184},
1670 author = {Preece, Alun and Harborne, Dan and Braines, Dave and Tomsett, Richard and Chakraborty, Supriyo},
1671 title = {Stakeholders in explainable AI},
1672}
1673
1674@article{richards2021human,
1675 year = {2021},
1676 pages = {47--58},
1677 number = {4},
1678 volume = {44},
1679 journal = {IEEE Data Eng. Bull.},
1680 author = {Richards, John T and Piorkowski, David and Hind, Michael and Houde, Stephanie and Mojsilovic, Aleksandra and Varshney, Kush R},
1681 title = {A Human-Centered Methodology for Creating AI FactSheets.},
1682}
1683
1684@article{hind2019explaining,
1685 publisher = {ACM New York, NY, USA},
1686 year = {2019},
1687 pages = {16--19},
1688 number = {3},
1689 volume = {25},
1690 journal = {XRDS: Crossroads, The ACM Magazine for Students},
1691 author = {Hind, Michael},
1692 title = {Explaining explainable AI},
1693}Attribution
arXiv:2207.01482v1
[cs.CY]
License: cc-by-4.0


