
- Papers
Papers is Alpha. This content is part of an effort to make research more accessible, and (most likely) has lost some details from the original. You can find the original paper here.
Introduction
In this position paper, we share our insights about AI Governance in companies, which enables new connections between various aspects and properties of trustworthy and socially responsible Machine Learning: security, robustness, privacy, fairness, ethics, interpretability, transparency, etc.
For a long time Artificial intelligence (AI) was something enterprise organizations adopted due to the huge amounts of resources they have at their fingertips. Today, smaller companies are able to take advantage of AI due to newer technologies, e.g. cloud software, which are significantly more affordable than what was available in the past. AI has been on an upward trajectory in recent years and it will increase significantly over the next several years. However, every investment has its pros and cons. Unfortunately, the cons associated with AI adoption are caused by its inherent uncertainties, and the builders of such AI systems who do not take the necessary steps to avoid problems down the road. Note that, in this work, AI comprises modern Machine Learning (ML) and Deep Learning (DL) systems, yet not their software around them - which represents other threats and vulnerabilities by itself-.
Problems within Industry
Some popular applications of AI are: anomaly detection and forecasting, recommender systems, medical diagnosis, natural sciences, and search engines.
However, these applications of AI in industry is still in its infancy. With that said, many problems have arisen since its adoption, which can be attributed to several factors:
Lack of risk awareness and management: Too much attention is given to applications of AI and its potential success and not enough attention is given to its potential pitfalls and risks.
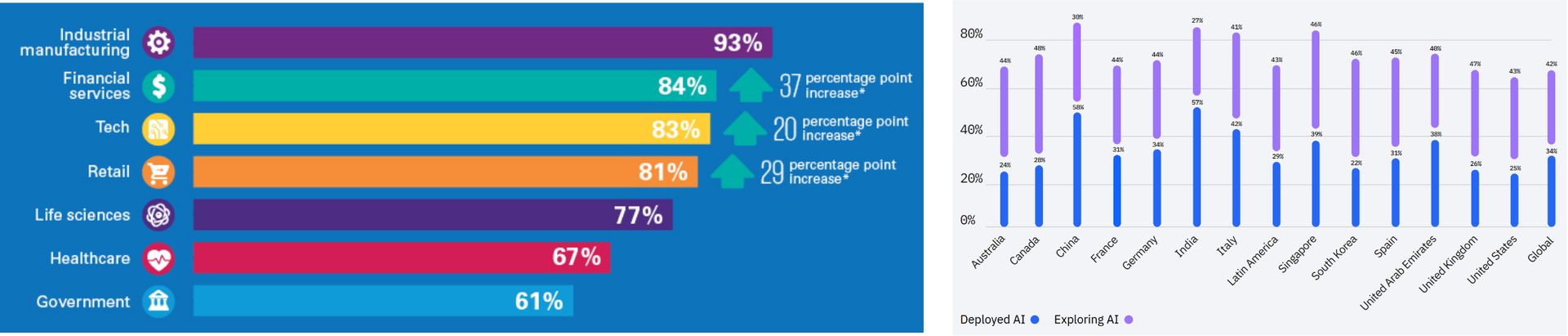
AI adoption is moving too fast: According to a survey by KPMG in 2021, many respondents noted that AI technology is moving too fast for their comfort in industrial manufacturing (55%), technology (49%), financial services (37%), government (37%), and health care (35%) sectors.
AI adoption needs government intervention: According to the same survey by KPMG,(see Figure fig-surveys), an overwhelming percentage of respondents agreed that governments should be involved in regulating AI technology in the industrial manufacturing (94%), retail (87%), financial services (86%), life sciences (86%), technology (86%), health care (84%), and government (82%) sectors.
Companies are still immature when it comes to adopting AI: Some companies are not prepared for business conditions to change once a ML model is deployed into the real world.
Many of these problems can be avoided with proper governance mechanisms. AI without such mechanisms is a dangerous game with detrimental outcomes due its inherent uncertainty. With that said, adding governance into applications of AI is imperative to ensure safety in production.
AI Governance
What is AI Governance (AIG)?
AI Governance is a framework to operationalize responsible artificial intelligence at organizations. This framework encourages organizations to curate and use bias-free data, consider societal and end-user impact, and produce unbiased models; the framework also enforces controls on model progression through deployment stages. The potential risks associated with AI need to be considered when designing models, before they affect the quality of models and algorithms. If left unmonitored, AI may not only produce undesirable results, but can also have a significant adverse impact on the organization.
In order for organizations to realize the maximum value out of AI projects and develop consistency for organization-wide adoption of AI, while managing significant risks to their business, they must implement AI governance; this enables organizations to not only develop AI projects in a responsible way, but also ensure that there is consistency across the entire organization and the business objective is front and center. With the AI governance implemented (as illustrated in Figure fig-teaser), the following benefits can be realized:
Alignment and Clarity: teams would be aware and aligned on what the industry, international, regional, local, and organizational policies are that need to be adhered to.
Thoughtfulness and Accountability: teams would put deliberate effort into justifying the business case for AI projects, and put conscious effort into thinking about end-user experience, adversarial impacts, public safety & privacy. This also places greater accountability on the teams developing their respective AI projects.
Consistency and Organizational Adoption: teams would have a more consistent way of developing and collaborating on their AI projects, leading to increased tracking and transparency for their projects. This also provides an overarching view of all AI projects going on within the organization, leading to increased visibility and overall adoption.
Process, Communication, and Tools: teams would have complete understanding of what the steps are in order to move the AI project to production to start realizing business value. They would also be able to leverage tools that take them through the defined process, while being able to communicate with the right stakeholders through the tool.
Trust and Public Perception: as teams build out their AI projects more thoughtfully, this will inherently build trust amongst customers and end users, and therefore a positive public perception.
AI governance requires the following:
-
A structured organization that gives AIG leaders the correct information they need to establish policies and accountability for AI efforts across their entire organization. For smaller organizations, this might require a more phased approach in which they will work towards the desired structural framework of AIG. For larger organizations, this process might be more attainable due to resources alone, e.g. people, IT infrastructure, larger budgets.
-
A concrete and specific AI workflow that collects information needed by AIG leaders will help enforce the constructed policies. This provides information to various parties in a consumable manner. Having such information can be used to minimize mistakes, errors, and bias, amongst other things.
The requirements for AI governance manifest into a framework that an organization must work towards developing. The components of this framework need to be transparent and comprehensive to achieve a successful implementation of AIG. Specifically, this should focus on organizational and use case planning, AI development, and AI “operationalization”, which come together to make a 4 stage AI life cycle approach.
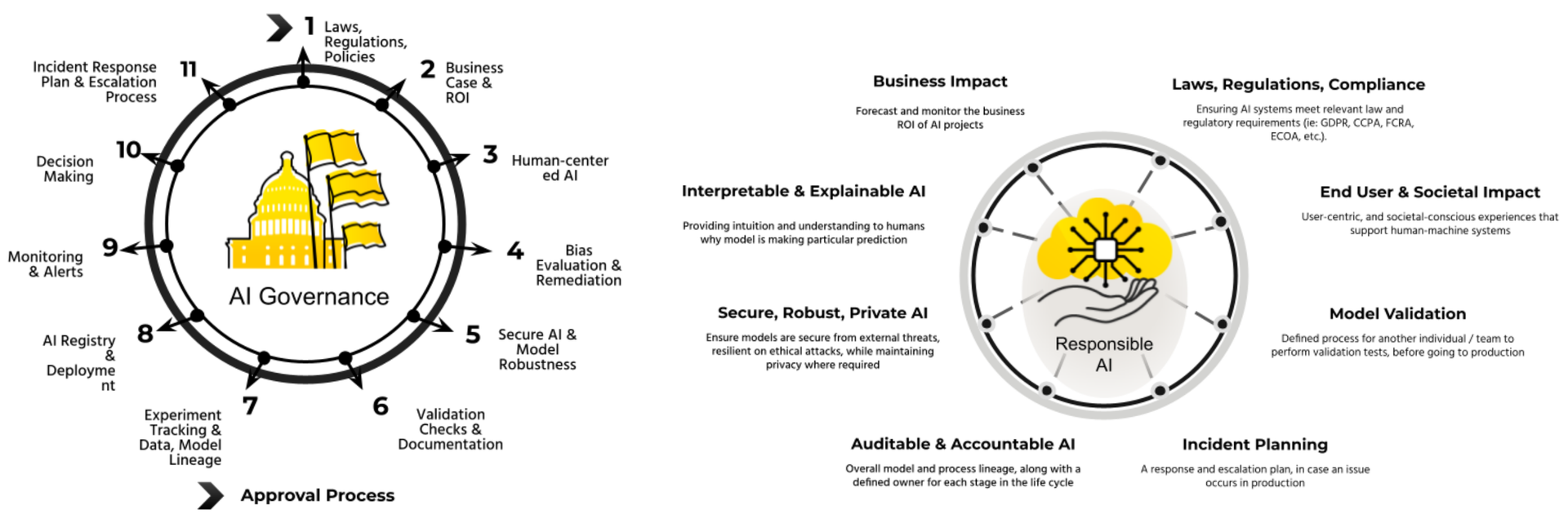
Stages of a Governed AI Life cycle
Organizational Planning
An AI Governance Programshould be organized in such a way that (a) there is comprehensive understanding of regulations, laws, and policies amongst all team members (b) resources and help available for team members who encounter challenges (c) there is a light weight, yet clear process to assist team members.
- Regulations, Laws, Policies
Laws and regulations that apply to a specific entity should be identified, documented, and available for others to review and audit. These regulations, laws, and policies vary across industry and sometimes by geographical location. Organizations should, if applicable, develop policies for themselves, which reflect their values and ethical views; this enables teams to be more autonomous and make decisions with confidence.
- Organization (Center of Competency)
Establishing groups within an organization that provide support to teams with AI projects can prove to be quite beneficial. This includes a group that is knowledgeable with regulations, laws, and policies and can answer any questions that AI teams may have; a group that is able to share best practices across different AI teams within the organization; a group that is able to audit the data, model, process, etc. to ensure there isn’t a breach or non-compliance. For more information, we refer the reader to to the survey by Floridi et al..
- Process
Developing a light-weight process that provides guidelines to AI teams can help with their efficiency, rather than hinder their progress and velocity. This involves identifying what the approval process and incident response would be for data, model, deployments, etc.
Use Case Planning
Building use cases involves establishing business value, technology stack, and model usage. The group of people involved in this process can include: subject matter experts, data scientists/analysts/annotators and ML engineers, IT professionals, and finance departments.
Business Value Framework. The AI team should ensure that the motivation for the AI use case is documented and communicated amongst all stakeholders. This should also include the original hypothesis, and the metrics that would be used for evaluating the experiments.
Tools, Technology, Products. The AI team should either select from a set of pre-approved tools and products from the organization or get a set of tools and products approved before using in an AI user case. If tools for AI development are not governed, it not only leads to high costs and inability to manage the tools (as existing IT teams are aware), it also leads to not being able to create repeatability and traceability into AI models.
Model Usage. Once a sense of value is attached to the use case, then the next step would be to break down the use case to its sub-components which include, but are not limited to, identifying the consumer of the model, the model’s limitations, and potential bias that may exist within the model, along with its implications. Also, one would want to ensure inclusiveness of the target, public safety/user privacy, and identification of the model interface needed for their intended use case.
AI Development
Development of a machine learning model, including data handling and analysis, modeling, generating explanations, bias detection, accuracy and efficacy analysis, security and robustness checks, model lineage, validation, and documentation.
- Data Handling, Analysis and Modeling
The first technical step to any AI project is the procurement and analysis of data, which is critical as it lays the foundation for all work going forward. Once data is analyzed, then one must decipher if modeling is needed for the use case at hand. If modeling is needed, then the application of AI can take place. Such an application is an iterative process spanned across many different types of people.
- Explanations and Bias
The goal of model explanations is to relate feature values to model predictions in a human-friendly manner. What one does with these explanations breaks down to 3 personas: modeler, intermediary user, and the end user. The modeler would use explanations for model debugging and gaining understanding of the model they just built. The intermediary user would use what the modeler made for actionable insights. And finally, the end user is the person the model affects directly. For these reasons, Explainable Artificial Intelligence (XAI) is a very active research topic.
Bias, whether intentional (disparate treatment) or unintentional (disparate impact), is a cause for concern in many applications of AI. Common things to investigate when it comes to preventing bias include the data source used for the modeling process, performance issues amongst different demographics, disparate impact, identifying known limitations & potential adverse implications, and the models impact on public safety. We refer the reader to the survey by Mehrabi *et al.*for more details about bias and fairness in AI.
- Accuracy, Efficacy, & Robustness
Accuracy of a machine learning model is critical for any business application in which predictions drive potential actions. However, it is not the most important metric to optimize. One must also consider the efficacy of a model, i.e. is the model making the intended business impact?
When a model is serving predictions in a production setting, the data can be a little or significantly different from the data that the project team had access to. Although model drift and feature drift can capture this discrepancy, it is a lagging indicator, and by that time, the model has already made predictions. This is where Robustness comes in: project teams can proactively test for model robustness, using “out of scope” data, to understand whether the model perturbs. The out of scope data can be a combination of manual generation (toggle with feature values) and automatic generation (system toggles feature values).
- Security
ML systems today are subject to general attacks that can affect any public facing IT system,; specialized attacks that exploit insider access to data and ML code; external access to ML prediction APIs and endpoints,; and trojans that can hide in third-party ML artifacts. Such attacks must be accounted for and tested against before sending a machine learning model out into the real world.
- Documentation & Validation
An overall lineage of the entire AI project life-cycle should be documented to ensure transparency and understanding,, which will be useful for the AI team working on the project and also future teams who must reference this project for their own application.
Model validationis the set of processes and activities that are carried out by a third party, with the intent to verify that models are robust and performing as expected, in line with the business use case. It also identifies the impact of potential limitations and assumptions. From a technical standpoint, the following should be considered: (i) Sensitivity Analysis. (ii) In-sample vs. Out-of-sample performance. (iii) Replication of results from model development team. (iv) Stability analysis. Model “validators” should document all of their findings and share with relevant stakeholders.
AI Operationalization
Deploying a machine learning model into production (i.e. MLOps) is the first step to potentially receiving value out of it. The steps that go into the deployment process should include the following:
Review-Approval Flow: Model building in an AI project will go through various stages: experimentation, model registration, deployment, and decommissioning. Moving from one stage to the next would require “external” reviewer(s) who will vet and provide feedback.
Monitoring & Alerts: Once a model is deployed, it must be monitored for various metrics to ensure there is not any degradation in the model. The cause for a model degrading when deployed can include the following: feature and/or target drift, lack of data integrity, and outliers, amongst other things. In terms of monitoring, accuracy, fairness, and explanations of predictions are of interest.
Decision Making: The output of a machine learning model is a prediction, but that output must be turned into a decision. How to decide? Will it be autonomous? Will it involve a human in the loop? The answers to these questions vary across different applications, but the idea remains the same, ensuring decisions are made in the proper way to decrease risk for everyone involved.
Incident Response and Escalation Process: With AI models being used in production, there is always going to be a chance for issues to arise. Organizations should have an incident response plan and escalation process documented and known to all project teams.
Companies who successfully implement AI governance for AI applications will result in a highly impactful use of artificial intelligence. While those who fail to do so, risk catastrophic outcomes and an arduous road to recovery as shown in the following use-case.
AIG Use Case
In this section we describe a recent use case where - we believe - AI Governance could have avoided a terrible outcome.
In 2021, the online real estate technology giant, Zillow, shut down its AI-powered house-flipping business. At it’s core, this line of business relied heavily on forecasting from their machine learning models. Zillow found itself overpaying for homes due to overestimating the price of a property. Such overestimation of property values led to a loss of $569 million, and 28% of their valuation. The monetary loss and laying off of 2,000 employees also came with a reputational cost.
This AI failure begs the question “What mistakes did Zillow make?” and “Could this have been prevented?”. The answer to the second question is a firm “yes”. However, the answer to the first question has many facets, but we try to break down the key mistakes below:
- Removing “Human in the Loop”
In its early days, this company hired local real estate agents and property experts to verify the output of their home price prediction ML algorithm; however, as the business scaled, the human verification process around the algorithms was minimizedand the offer-making process was automated, which helped to cut expenses and increase acquisitions. However, removing human verification in such a volatile domain led to predictions taken at face value without any verification, which played a big role in overpricing of properties.
Keeping the human in the loop can help companies from relying on overestimated and biased predictions. Considering a ML ecosystem for decision-making in organizations, having a human in the loop is a safety harness and should be used in any high stake decision making.
- Not Accounting for Concept Drift and Lack of Model Monitoring
Taking a look back at the timeline of events, it appears that the ML algorithms were not adjusted accordingly to the real market status. The algorithms continued to assume that the market was still “hot” and overestimated home prices.
To avoid problems of drift, specifically concept drift, companies should leverage tools for monitoring and maintaining the quality of AI models. Ideally, in this example, they should have set up an infrastructure that automatically alerts data science teams when there is drift or performance degradation, support root cause analysis, and inform model updates with humans-in-the-loop.
- Lack of Model Validation
Before organizations deploy any of their algorithms, they should have enact a set of processes and activities intended to verify that their models are performing as expected and that they are in line with the business use case. Effective validation ensures that models are robust. It also identifies potential limitations and assumptions, and it assesses their possible impact. A lack of model validation played a crucial role in this case, and led to the overestimation of home prices. It should be noted that -ideally- model validation needs to be carried out by a third party that did not take part in the model building process.
- Lack of Incident Response
It is not clear when this company started to realize that their model’s were degrading and producing erroneous results. The lack of having such an incident response plan can cost businesses an exuberant amount of money, time, and human resources. In retrospect, if proper AI Governance would had been implemented, the company could have started an incident response i.e. incident identification and documentation, human review, and redirection of model traffic. These three steps alone could have prevented a lot of damage to their business.
This industry use case is an example of what can happen without proper AI governance. The mistakes that were made could have been avoided if proper AI governance principles were taken into account from the inception of their use case. Specifically, if this company continued to rely on their subject matter experts, accounted for various types of drift, added model validation, and implemented concrete model monitoring with proper incident response planning, then this whole situation could have been avoided or the damage could have been at a much lower magnitude.
Conclusion
AI systems are used today to make life-altering decisions about employment, bail, parole, and lending, and the scope of decisions delegated by AI systems seems likely to expand in the future. The pervasiveness of AI across many fields is something that will not slowdown anytime soon and organizations will want to keep up with such applications. However, they must be cognisant of the risks that come with AI and have guidelines around how they approach applications of AI to avoid such risks. By establishing a framework for AI Governance, organizations will be able to harness AI for their use cases while at the same time avoiding risks and having plans in place for risk mitigation, which is paramount.
Social Impact
As we discuss in this paper, governance and certain control over AI applications in organizations should be mandatory. AI Governance aims to enable and facilitate connections between various aspects of trustworthy and socially responsible machine learning systems, and therefore it accounts for security, robustness, privacy, fairness, ethics, and transparency. We believe the implementation of these ideas should have a positive impact in the society.
Acknowledgements We thank the Trustworthy and Socially Responsible Machine Learning (TSRML) Workshop at NeurIPS 2022. This work was supported by H2O.ai.
Bibliography
1@misc{IBM,
2 year = {2022},
3 author = {IBM},
4 note = {URL: \url{https://www.ibm.com/downloads/cas/GVAGA3JP}},
5 title = {{IBM} {G}lobal {AI} {A}doption {I}ndex},
6}
7
8@misc{PwC,
9year = {2022},
10author = {PwC (PriceWaterhouseCoopers)},
11note = {URL: \url{https://www.pwc.com/us/en/tech-effect/ai-analytics/ai-business-survey.html}},
12title = {{PwC} 2022 {AI} {B}usiness {S}urvey},
13}
14
15@misc{KPMG,
16year = {2021},
17author = {KPMG},
18note = {URL: \url{https://info.kpmg.us/news-perspectives/technology-innovation/thriving-in-an-ai-world/ai-adoption-accelerated-during-pandemic.html}},
19title = {{AI} adoption accelerated during the pandemic but many say it’s moving too fast: {KPMG} survey},
20}
21
22@article{hbr,
23year = {2021},
24note = {URL: \url{https://hbr.org/2021/09/ai-adoption-skyrocketed-over-the-last-18-months}},
25title = {{AI} {A}doption {S}kyrocketed {O}ver {t}he {L}ast 18 {M}onths.},
26journal = {Harvard Business Review},
27author = {Joe McKendrick},
28}
29
30@misc{ai_incidents,
31note = {URL: \url{https://incidentdatabase.ai/}},
32year = {2022},
33author = {Artificial Intelligence Incident Database},
34title = {{AI} {I}ncident {D}atabase},
35}
36
37@article{security_of_ml,
38note = {URL: \url{https://people.eecs.berkeley.edu/~adj/publications/paper-files/SecML-MLJ2010.pdf}},
39publisher = {Springer},
40year = {2010},
41pages = {121--148},
42number = {2},
43volume = {81},
44journal = {Machine Learning},
45author = {Barreno, Marco and Nelson, Blaine and Joseph, Anthony D and Tygar, J Doug},
46title = {The {S}ecurity of {M}achine {L}earning},
47}
48
49@inproceedings{papernot2018marauder,
50note = {URL: \url{https://arxiv.org/pdf/1811.01134.pdf}},
51organization = {ACM},
52year = {2018},
53booktitle = {Proceedings of the 11th ACM Workshop on Artificial Intelligence and Security},
54author = {Papernot, Nicolas},
55title = {A {M}arauder's {M}ap of {S}ecurity and {P}rivacy in {M}achine {L}earning: {A}n overview of current and future research directions for making machine learning secure and private},
56}
57
58@inproceedings{membership_inference,
59note = {URL: \url{https://arxiv.org/pdf/1610.05820.pdf}},
60organization = {IEEE},
61year = {2017},
62pages = {3--18},
63booktitle = {2017 IEEE Symposium on Security and Privacy (SP)},
64author = {Shokri, Reza and Stronati, Marco and Song, Congzheng and Shmatikov, Vitaly},
65title = {Membership {I}nference {A}ttacks {A}gainst {M}achine {L}earning {M}odels},
66}
67
68@inproceedings{model_stealing,
69note = {URL: \url{https://www.usenix.org/system/files/conference/usenixsecurity16/sec16_paper_tramer.pdf}},
70year = {2016},
71pages = {601--618},
72booktitle = {25th $\{$USENIX$\}$ Security Symposium ($\{$USENIX$\}$ Security 16)},
73author = {Tram{\`e}r, Florian and Zhang, Fan and Juels, Ari and Reiter, Michael K and Ristenpart, Thomas},
74title = {Stealing {M}achine {L}earning {M}odels via {P}rediction {A}{P}{I}s},
75}
76
77@book{molnar,
78note = {URL: \url{https://christophm.github.io/interpretable-ml-book/}},
79year = {2022},
80author = {Christopher Molnar},
81title = {{I}nterpretable {M}achine {L}earning},
82}
83
84@article{gunning2019xai,
85publisher = {American Association for the Advancement of Science},
86year = {2019},
87pages = {eaay7120},
88number = {37},
89volume = {4},
90journal = {Science robotics},
91author = {Gunning, David and Stefik, Mark and Choi, Jaesik and Miller, Timothy and Stumpf, Simone and Yang, Guang-Zhong},
92title = {XAI—Explainable artificial intelligence},
93}
94
95@article{arrieta2020explainable,
96publisher = {Elsevier},
97year = {2020},
98pages = {82--115},
99volume = {58},
100journal = {Information fusion},
101author = {Arrieta, Alejandro Barredo and D{\'\i}az-Rodr{\'\i}guez, Natalia and Del Ser, Javier and Bennetot, Adrien and Tabik, Siham and Barbado, Alberto and Garc{\'\i}a, Salvador and Gil-L{\'o}pez, Sergio and Molina, Daniel and Benjamins, Richard and others},
102title = {Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI},
103}
104
105@misc{bias,
106note = {URL: \url{https://fairmlbook.org/pdf/fairmlbook.pdf}},
107year = {2022},
108author = {Barocas, S. and Hardt, M. and Narayanan, A.},
109title = {{F}airness and {M}achine {L}earning: {L}imitaions and {O}pportunities},
110}
111
112@misc{bias_nist,
113language = {en},
114doi = {https://doi.org/10.6028/NIST.SP.1270},
115url = {https://tsapps.nist.gov/publication/get_pdf.cfm?pub_id=934464},
116publisher = {Special Publication (NIST SP), National Institute of Standards and Technology, Gaithersburg, MD},
117month = {2022-03-15 04:03:00},
118year = {2022},
119title = {Towards a Standard for Identifying and Managing Bias in Artificial Intelligence},
120author = {Reva Schwartz and Apostol Vassilev and Kristen Greene and Lori Perine and Andrew Burt and Patrick Hall},
121}
122
123@article{mehrabi2021survey,
124publisher = {ACM New York, NY, USA},
125year = {2021},
126pages = {1--35},
127number = {6},
128volume = {54},
129journal = {ACM Computing Surveys (CSUR)},
130author = {Mehrabi, Ninareh and Morstatter, Fred and Saxena, Nripsuta and Lerman, Kristina and Galstyan, Aram},
131title = {A survey on bias and fairness in machine learning},
132}
133
134@misc{SR117,
135author = {Board of Governors of the Federal Reserve System Office of the Comptroller of the Currency},
136pages = {6--16},
137url = {https://www.federalreserve.gov/supervisionreg/srletters/sr1107a1.pdf},
138year = {2011},
139title = {{S}upervisory {G}uidance on {M}odel {R}isk {M}anagement, {SR} {L}etter 11-7},
140}
141
142@article{landry1983model,
143publisher = {Elsevier},
144year = {1983},
145pages = {207--220},
146number = {3},
147volume = {14},
148journal = {European journal of operational research},
149author = {Landry, Maurice and Malouin, Jean-Louis and Oral, Muhittin},
150title = {Model validation in operations research},
151}
152
153@inproceedings{Mitchell_2019,
154booktitle = {Proceedings of the Conference on Fairness, Accountability, and Transparency},
155title = {Model Cards for Model Reporting},
156author = {Margaret Mitchell and Simone Wu and Andrew Zaldivar and Parker Barnes and Lucy Vasserman and Ben Hutchinson and Elena Spitzer and Inioluwa Deborah Raji and Timnit Gebru},
157publisher = {{ACM}},
158year = {2019},
159url = {https://doi.org/10.1145%2F3287560.3287596},
160doi = {10.1145/3287560.3287596},
161}
162
163@misc{data_cards,
164copyright = {Creative Commons Attribution 4.0 International},
165year = {2022},
166publisher = {arXiv},
167title = {Data Cards: Purposeful and Transparent Dataset Documentation for Responsible AI},
168keywords = {Human-Computer Interaction (cs.HC), Artificial Intelligence (cs.AI), Databases (cs.DB), Machine Learning (cs.LG), FOS: Computer and information sciences, FOS: Computer and information sciences},
169author = {Pushkarna, Mahima and Zaldivar, Andrew and Kjartansson, Oddur},
170url = {https://arxiv.org/abs/2204.01075},
171doi = {10.48550/ARXIV.2204.01075},
172}
173
174@article{alsheibani2018artificial,
175journal = {PACIS 2018 Proceedings},
176year = {2018},
177author = {AlSheibani, Sulaiman and Cheung, Yen and Messom, Chris},
178title = {Artificial intelligence adoption: AI-readiness at firm-level},
179}
180
181@article{cubric2020drivers,
182publisher = {Elsevier},
183year = {2020},
184pages = {101257},
185volume = {62},
186journal = {Technology in Society},
187author = {Cubric, Marija},
188title = {Drivers, barriers and social considerations for AI adoption in business and management: A tertiary study},
189}
190
191@article{duan2019artificial,
192publisher = {Elsevier},
193year = {2019},
194pages = {63--71},
195volume = {48},
196journal = {International journal of information management},
197author = {Duan, Yanqing and Edwards, John S and Dwivedi, Yogesh K},
198title = {Artificial intelligence for decision making in the era of Big Data--evolution, challenges and research agenda},
199}
200
201@article{floridi2018ai4people,
202publisher = {Springer},
203year = {2018},
204pages = {689--707},
205number = {4},
206volume = {28},
207journal = {Minds and machines},
208author = {Floridi, Luciano and Cowls, Josh and Beltrametti, Monica and Chatila, Raja and Chazerand, Patrice and Dignum, Virginia and Luetge, Christoph and Madelin, Robert and Pagallo, Ugo and Rossi, Francesca and others},
209title = {AI4People—An ethical framework for a good AI society: Opportunities, risks, principles, and recommendations},
210}
211
212@article{marr2018artificial,
213year = {2018},
214journal = {Forbes},
215author = {Marr, Bernard},
216title = {Is Artificial Intelligence dangerous? 6 AI risks everyone should know about},
217}
218
219@article{wang2018artificial,
220year = {2018},
221volume = {40},
222journal = {MWAIS 2018 proceedings},
223author = {Wang, Weiyu and Siau, Keng},
224title = {Artificial intelligence: A study on governance, policies, and regulations},
225}
226
227@article{reddy2020governance,
228publisher = {Oxford University Press},
229year = {2020},
230pages = {491--497},
231number = {3},
232volume = {27},
233journal = {Journal of the American Medical Informatics Association},
234author = {Reddy, Sandeep and Allan, Sonia and Coghlan, Simon and Cooper, Paul},
235title = {A governance model for the application of AI in health care},
236}
237
238@article{dafoe2018ai,
239year = {2018},
240pages = {1443},
241volume = {1442},
242journal = {Governance of AI Program, Future of Humanity Institute, University of Oxford: Oxford, UK},
243author = {Dafoe, Allan},
244title = {AI governance: a research agenda},
245}
246
247@article{gasser2017layered,
248publisher = {IEEE},
249year = {2017},
250pages = {58--62},
251number = {6},
252volume = {21},
253journal = {IEEE Internet Computing},
254author = {Gasser, Urs and Almeida, Virgilio AF},
255title = {A layered model for AI governance},
256}
257
258@article{kuziemski2020ai,
259publisher = {Elsevier},
260year = {2020},
261pages = {101976},
262number = {6},
263volume = {44},
264journal = {Telecommunications policy},
265author = {Kuziemski, Maciej and Misuraca, Gianluca},
266title = {AI governance in the public sector: Three tales from the frontiers of automated decision-making in democratic settings},
267}
268
269@article{vaishya2020artificial,
270publisher = {Elsevier},
271year = {2020},
272pages = {337--339},
273number = {4},
274volume = {14},
275journal = {Diabetes \& Metabolic Syndrome: Clinical Research \& Reviews},
276author = {Vaishya, Raju and Javaid, Mohd and Khan, Ibrahim Haleem and Haleem, Abid},
277title = {Artificial Intelligence (AI) applications for COVID-19 pandemic},
278}
279
280@article{bresina2012planning,
281year = {2012},
282journal = {arXiv preprint arXiv:1301.0559},
283author = {Bresina, John and Dearden, Richard and Meuleau, Nicolas and Ramkrishnan, Sailesh and Smith, David and Washington, Richard},
284title = {Planning under continuous time and resource uncertainty: A challenge for AI},
285}
286
287@incollection{zadeh1986probability,
288publisher = {Elsevier},
289year = {1986},
290pages = {103--116},
291volume = {4},
292booktitle = {Machine intelligence and pattern recognition},
293author = {Zadeh, Lotfi A},
294title = {Is probability theory sufficient for dealing with uncertainty in AI: A negative view},
295}
296
297@incollection{zhu2022ai,
298publisher = {Springer},
299year = {2022},
300pages = {15--33},
301booktitle = {Humanity Driven AI},
302author = {Zhu, Liming and Xu, Xiwei and Lu, Qinghua and Governatori, Guido and Whittle, Jon},
303title = {AI and Ethics—Operationalizing Responsible AI},
304}
305
306@inproceedings{ehsan2021operationalizing,
307year = {2021},
308pages = {1--6},
309booktitle = {Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems},
310author = {Ehsan, Upol and Wintersberger, Philipp and Liao, Q Vera and Mara, Martina and Streit, Marc and Wachter, Sandra and Riener, Andreas and Riedl, Mark O},
311title = {Operationalizing human-centered perspectives in explainable AI},
312}
313
314@article{amodei2016concrete,
315year = {2016},
316journal = {arXiv preprint arXiv:1606.06565},
317author = {Amodei, Dario and Olah, Chris and Steinhardt, Jacob and Christiano, Paul and Schulman, John and Man{\'e}, Dan},
318title = {Concrete problems in AI safety},
319}
320
321@article{leike2017ai,
322year = {2017},
323journal = {arXiv preprint arXiv:1711.09883},
324author = {Leike, Jan and Martic, Miljan and Krakovna, Victoria and Ortega, Pedro A and Everitt, Tom and Lefrancq, Andrew and Orseau, Laurent and Legg, Shane},
325title = {AI safety gridworlds},
326}
327
328@book{treveil2020introducing,
329publisher = {O'Reilly Media},
330year = {2020},
331author = {Treveil, Mark and Omont, Nicolas and Stenac, Cl{\'e}ment and Lefevre, Kenji and Phan, Du and Zentici, Joachim and Lavoillotte, Adrien and Miyazaki, Makoto and Heidmann, Lynn},
332title = {Introducing MLOps},
333}
334
335@incollection{alla2021mlops,
336publisher = {Springer},
337year = {2021},
338pages = {79--124},
339booktitle = {Beginning MLOps with MLFlow},
340author = {Alla, Sridhar and Adari, Suman Kalyan},
341title = {What is mlops?},
342}
343
344@article{mittelstadt2019principles,
345publisher = {Nature Publishing Group},
346year = {2019},
347pages = {501--507},
348number = {11},
349volume = {1},
350journal = {Nature Machine Intelligence},
351author = {Mittelstadt, Brent},
352title = {Principles alone cannot guarantee ethical AI},
353}
354
355@article{bloomberg,
356year = {2021},
357note = {URL: \url{https://www.bloomberg.com/news/articles/2021-11-08/zillow-z-home-flipping-experiment-doomed-by-tech-algorithms}},
358title = {Zillow’s Algorithm-Fueled Buying Spree Doomed Its Home-Flipping Experiment},
359journal = {Bloomberg},
360author = {Patrick Clark},
361}
362
363@article{bloomberg2,
364year = {2021},
365note = {URL: \url{https://www.bloomberg.com/news/articles/2021-11-01/zillow-selling-7-000-homes-for-2-8-billion-after-flipping-halt}},
366title = {Zillow Seeks to Sell 7,000 Homes for \$2.8 Billion After Flipping Halt},
367journal = {Bloomberg},
368author = {Patrick Clark, Sridhar Natarajan, Heather Perlberg},
369}
370
371@article{sr711,
372year = {2011},
373note = {URL: https://www.federalreserve.gov/supervisionreg/srletters/sr1107a1.pdf},
374title = {SR 11-7 attachment: Supervisory Guidance on Model Risk Management},
375author = {Board of Governors of the Federal Reserve System},
376}
377
378@article{alhazmi2007measuring,
379publisher = {Elsevier},
380year = {2007},
381pages = {219--228},
382number = {3},
383volume = {26},
384journal = {computers \& security},
385author = {Alhazmi, Omar Hussain and Malaiya, Yashwant K and Ray, Indrajit},
386title = {Measuring, analyzing and predicting security vulnerabilities in software systems},
387}
388
389@book{dowd2006art,
390publisher = {Pearson Education},
391year = {2006},
392author = {Dowd, Mark and McDonald, John and Schuh, Justin},
393title = {The art of software security assessment: Identifying and preventing software vulnerabilities},
394}
395
396@article{mcgraw2004software,
397publisher = {IEEE},
398year = {2004},
399pages = {80--83},
400number = {2},
401volume = {2},
402journal = {IEEE Security \& Privacy},
403author = {McGraw, Gary},
404title = {Software security},
405}
406
407@article{conde2022general,
408year = {2022},
409journal = {arXiv preprint arXiv:2210.11141},
410author = {Conde, Marcos V and Aerlic, Ivan and J{\'e}gou, Simon},
411title = {General Image Descriptors for Open World Image Retrieval using ViT CLIP},
412}
413
414@article{conde2021weakly,
415year = {2021},
416journal = {arXiv preprint arXiv:2107.04878},
417author = {Conde, Marcos V and Shubham, Kumar and Agnihotri, Prateek and Movva, Nitin D and Bessenyei, Szilard},
418title = {Weakly-Supervised Classification and Detection of Bird Sounds in the Wild. A BirdCLEF 2021 Solution},
419}
420
421@article{conde2022few,
422year = {2022},
423journal = {arXiv preprint arXiv:2206.11260},
424author = {Conde, Marcos V and Choi, Ui-Jin},
425title = {Few-shot Long-Tailed Bird Audio Recognition},
426}
427
428@inproceedings{sultani2018real,
429year = {2018},
430pages = {6479--6488},
431booktitle = {Proceedings of the IEEE conference on computer vision and pattern recognition},
432author = {Sultani, Waqas and Chen, Chen and Shah, Mubarak},
433title = {Real-world anomaly detection in surveillance videos},
434}
435
436@article{portugal2018use,
437publisher = {Elsevier},
438year = {2018},
439pages = {205--227},
440volume = {97},
441journal = {Expert Systems with Applications},
442author = {Portugal, Ivens and Alencar, Paulo and Cowan, Donald},
443title = {The use of machine learning algorithms in recommender systems: A systematic review},
444}
445
446@article{gordeev2020backtesting,
447year = {2020},
448journal = {arXiv preprint arXiv:2007.11411},
449author = {Gordeev, Dmitry and Singer, Philipp and Michailidis, Marios and M{\"u}ller, Mathias and Ambati, SriSatish},
450title = {Backtesting the predictability of COVID-19},
451}
452
453@article{henkel2021recognizing,
454year = {2021},
455journal = {arXiv preprint arXiv:2107.07728},
456author = {Henkel, Christof and Pfeiffer, Pascal and Singer, Philipp},
457title = {Recognizing bird species in diverse soundscapes under weak supervision},
458}
459
460@article{makridakis2018statistical,
461publisher = {Public Library of Science San Francisco, CA USA},
462year = {2018},
463pages = {e0194889},
464number = {3},
465volume = {13},
466journal = {PloS one},
467author = {Makridakis, Spyros and Spiliotis, Evangelos and Assimakopoulos, Vassilios},
468title = {Statistical and Machine Learning forecasting methods: Concerns and ways forward},
469}
470
471@article{esteva2021deep,
472publisher = {Nature Publishing Group},
473year = {2021},
474pages = {1--9},
475number = {1},
476volume = {4},
477journal = {NPJ digital medicine},
478author = {Esteva, Andre and Chou, Katherine and Yeung, Serena and Naik, Nikhil and Madani, Ali and Mottaghi, Ali and Liu, Yun and Topol, Eric and Dean, Jeff and Socher, Richard},
479title = {Deep learning-enabled medical computer vision},
480}
481
482@inproceedings{conde2021clip,
483year = {2021},
484pages = {3956--3960},
485booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
486author = {Conde, Marcos V and Turgutlu, Kerem},
487title = {CLIP-Art: contrastive pre-training for fine-grained art classification},
488}
489
490@article{suzuki2017overview,
491publisher = {Springer},
492year = {2017},
493pages = {257--273},
494number = {3},
495volume = {10},
496journal = {Radiological physics and technology},
497author = {Suzuki, Kenji},
498title = {Overview of deep learning in medical imaging},
499}Attribution
arXiv:2211.13130v1
[cs.CY]
License: cc-by-sa-4.0


