
- Papers
Papers is Alpha. This content is part of an effort to make research more accessible, and (most likely) has lost some details from the original. You can find the original paper here.
Introduction
There is a growing community of researchers focused on ensuring that advances in AI are safe and beneficial for humanity (which we call the AI ethics and society community, or AI E&S for short.) The AI E&S research space is very broad, encompassing many different questions: from how AI is likely to impact society in practice to what ethical issues that might raise, and what technical and governance solutions might be needed. These questions are approached from many different perspectives and disciplines: philosophy, computer science, political science, sociology, law, economics, and international relations to name just a few. This research space is fast growing, with new initiatives, workshops, and research centres emerging every year.
Finding ways to break down this broad and evolving research space is important, as it helps researchers to clearly formulate and communicate problems and research agendas, collaborate effectively with others, and to identify gaps in current research. Natural ways to break down the AI E&S research space include by themes or sectors (such as the impact of AI on medicine, the military, or issues of social justice) or in relation to pre-existing disciplines (distinguishing research on ethics from technical approaches from governance and policy, for example).
Due to the cross-cutting nature of AI’s impacts, and the need for deep interdisciplinary collaboration in this space, it may be useful to have ways of carving up the research space that relate to more fundamental priorities and assumptions rather than being tied to specific domains or disciplines. One such way of carving up the research space which has emerged in recent years is to distinguish between those who focus on near-term' and long-term’ issues.
However, the distinction between near-term' and long-term’ is being over-emphasised as a way of characterising differences in the research space. On closer inspection, the distinction is poorly defined, and is used differently across people and contexts: sometimes to refer to issues on different timescales; sometimes to issues related to different types of AI capabilities, and other times masks deeper normative and empirical disagreements. Highlighting inconsistencies in how the near/long-term distinction is used, we argue that it fails to adequately capture the complexity and nuance of different approaches and priorities in the AI E&S research space, and risks causing confusion and fuelling conflict.
By unpacking the distinction between near- and long-term into four different dimensions, we propose some ways to more clearly conceptualise different priorities and disagreements within the AI E&S research space. First, we distinguish between research which focuses on near/long-term capabilities as opposed to near/long-term impacts, and argue that in both cases near/long-term is a spectrum rather than a binary distinction. We show how this way of thinking about different approaches could both improve collaboration and communication between researchers as well as helping to identify important areas of research which are currently neglected. Second, we analyse some of the beliefs and disagreements which seem to underpin differing research priorities, and suggest that clarifying these beliefs could aid mutual understanding between different researchers and groups.
The near/long-term distinction in practice
The distinction between near- and long-term in AI E&S is used both to distinguish different types of issues one might be concerned about, as well as to highlight a divide or disagreement between two research communities. In this section, we briefly review how the distinction is made in the literature.
`Near-term’ issues
As the phrase near-term' suggests, those who have written about the distinction tend to characterise near-term issues as those issues that society is already facing or likely to face very soon: Brundagedefines near-term issues as those society is “grappling with today” and Cave and ÓhÉigeartaightalk in terms of “immediate or imminent challenges” (p.5). Examples include concerns about data privacy, algorithmic bias, self-driving car accidents, and ethical issues associated with autonomous weapons. It is worth noting two things about these examples. First, they tend to be relatively concrete and specific, and an important feature of near-term’ issues is the fact that they are already fairly well-understood. Second, these examples tend to be directly related to recent progress in machine learning which have enabled increasing real-world applications of narrow and specialised AI systems: for example in medical diagnosis and predictive policing.
`Long-term’ issues
Long-term' issues are often characterised as those arising from advanced AI systems, or simply as issues that will arise far into the future. Brundagedefines long-term issues as those that “either only arise at all or arise to a much greater extent when AI is much more advanced than it is today”, while Cave and ÓhH́igeartaighpoint to “longer-term concerns and opportunities that are less certain” (p.5). Examples of long-term issues often centre around the implications of very advanced future AI with broad capabilities (artificial general intelligence’, or AGI), which achieve human or superhuman intelligence (human-level AI' or superintelligence’), or are in some other way radically transformative. For example, the White House Report on Preparing for the Future of Artificial Intelligence talks about “long-term concerns of AGI”, implicitly equating the two. While thinking about long-term' concerns of AI may have begun with concerns about superintelligence and related notions, the notion has since broadened to include challenges that are likely to have long-term consequences, as opposed to merely arising far into the future. Examples include the effects of advanced, transformative AI’ oninternational security, race dynamics and power relations.
The divide between near-term' and long-term’ communities
Baumnot only distinguishes between near and long-term issues, but also points to a divide between two different communities: presentists', who claim that “attention should go to existing and near-term AI”, and futurists’, who argue for focusing on “the potential for radically transformative AI”. Cave and ÓhÉigeartaighalso point to “two seemingly separate communities of researchers and technologists” focused on near and long-term issues.
Baum suggests these two groups disagree quite fundamentally about what issues are most important to work on. This has provoked hostility between the two sides: the near-term' camp suggesting that long-term concerns are overblown and a distraction from real problems, while some in the long-term’ camp suggest that the problems they focus on dwarf any near-term concerns in importance. This adversarial dynamic seems to be at the core of proposals to reconcile' or bridge’ the two sides.
The problem with the near/long-term distinction
Near-term' and long-term’ are often used in ways that combine and conflate multiple different dimensions, including: when issues arise; what kinds of technological capabilities issues relate to; how well-understood or speculative issues are; how high-stakes issues are and how many people they affect; and how long-lasting the consequences of an issue are likely to be. As table table1 shows, even a single definition or paper sometimes associates near-term' with one of these dimensions and long-term’ with another: Brundage, for example, defines near-term' based on when issues arise and long-term’ in terms of technological capabilities.
Rather than describing a single dimension, we suggest that the distinction between near- and long-term as currently used is better understood as describing clusters of issues, incorporating multiple dimensions:
- [] Issues considered `near-term’ tend to be those arising in the present/near future as a result of current/foreseeable AI systems and capabilities, on varying levels of scale/severity, which mostly have immediate consequences for people and society.
- []Issues considered `long-term’ tend to be those arising far into the future as a result of large advances in AI capabilities (with a particular focus on notions of transformative AI or AGI), and those that are likely to pose risks that are severe/large in scale with very long-term consequences.
We believe that carving up the AI E&S research space according to these clusters is problematic in two key ways. First, important and nuanced information gets lost if we give too much prominence to only two clusters. Many beliefs, values and assumptions will vary within each of these clusters. For example, among those who believe we should prioritise risks from advanced AI systems, there seems to be substantial disagreement about why exactly those risks are most important to work on, and what work should be done today to prevent those risks. Similarly, there are many different reasons a group may choose to focus on issues arising from current applications of AI in society: because they believe we should prioritise helping people alive today, because they believe advanced AI systems are very far off or hard to predict, or because they believe today’s problems are as high-stakes as anything we might face in the future. As we will discuss later, a binary distinction may have led the research community to neglect impacts which fall somewhere between immediate' and very long-term'.
Second, giving too much prominence to the near-term' and long-term’ clusters without examining underlying beliefs can lead researchers who identify with either side to end up misunderstanding each other. For example, Etzioniargues against the idea that superhuman AI could pose an existential threat to humanity (most prominently argued by Bostrom,) by drawing on survey data to suggest that experts do not believe superhuman AI systems will arrive any time soon. But as Dafoe and Russellpoint out in response, Bostrom’s argument does not actually rely on any assumptions about superintelligence being imminent. In practice, Etzioni and Bostrom’s disagreement turns more on how important and tractable they think it is to work on the potential risks from superhuman AI today. The idea that there are two `camps’ of AI E&S researchers, with very opposing perspectives, may lead researchers like Etzioni and Bostrom to make unfounded assumptions about the others’ perspective, and prevent them from engaging in more substantive and productive debate.
At its core, the distinction between near and long-term in AI E&S aims to capture the idea that different researchers and groups will sometimes have quite different priorities which guide what they work on, underpinned by some quite fundamental disagreements. We believe that acknowledging these differences is useful, but suggest that we need a clearer way to think and communicate about what they are. In the following section, we propose exactly that - some clearer ways to communicate about different research priorities and underlying disagreements.
A clearer account of research priorities and disagreements
Unpacking the near/long-term distinction
As commonly used, the terms near-term' and long-term’ in fact appear to capture four different dimensions of differing priorities within the AI E&S research community:
- [] Capabilities: whether to focus on the impacts and challenges of current AI systems, or those relating to much more advanced AI systems
- [] Impacts: whether to focus mostly on the immediate impacts of AI for society, or whether to consider possible impacts much further into the future.
- [] Certainty: whether to focus on impacts and issues that are relatively certain and well-understood, or those that are more uncertain and speculative.
- [] Extremity: whether to focus on impacts at all scales, or to prioritise focusing on those that may be particularly large in scale.
None of these four dimensions are binary: one can choose research questions that focus on AI systems that are more or less advanced, exploring impacts on varying time horizons, with varying degrees of certainty and extremity. Table table1 shows how these four dimensions in definitions of near-term' and long-term’ by different authors.
Dimensions underlying the ’near-term’ and ’long-term’ distinction in the literature.
Table Label: table1
Download PDF to view tableOf course, these dimensions are not entirely independent of one another: for example, if one wants to focus on particularly large-scale impacts of AI, one may have to be willing to consider more speculative questions. However, it is still useful to unpack these different dimensions, particularly because there are many possible views and research questions which are not easily captured by the near/long-term distinction as commonly used.
Looking at these four dimensions, we can identify some differences in what they refer to. Capabilities' and impacts’ both refer in some sense to time horizons; to whether research focuses on the present (either in terms of AI capabilities or impacts) or whether it looks further into the future. Both these dimensions therefore seem to capture different interpretations of what it might mean to say an issue is near-term' or long-term’. Certainty' and extremity’, by contrast, do not relate so explicitly to time horizons: instead they relate to the nature of impacts that different researchers might focus on, and our ability to predict and understandthese impacts. Although these dimensions do appear in how near and long-term are described, we suggest that they better characterised as capturing the kinds of motivations researchers may have for choosing to work on different areas.
Distinguishing capabilities and impacts
Near-term' and long-term’ are often modifiers applied to the state of technological capabilities themselves, with near-term issues being those arising from the AI systems we have today, and long-term issues being those we might expect to arise from certain kinds of much more advanced AI systems. At other times, near-term' and long-term’ refer rather to the impacts of the technology: with near-term issues being the impacts of AI that society already faces or will face in the immediate future, and long-term issues being the impacts of AI that society might face very far into the future.
Of course the timescale of technological advances and their impacts on society will be related. However, conflating long-term capabilities and impacts may mean the research community neglect important questions about the potential long-term impacts of current AI systems and their applications in society. For example, in what ways could injustices perpetuated by increased use of current algorithmic systems have very long-lasting and irreversible consequences for inequality in society? What are the possible longer-term implications of how data-intensive AI applications are beginning to change norms around privacy and personal data?Furthermore, it is important to recognise that both capabilities and impacts lie on a spectrum between near- and long-term. Understanding the potential medium-term' impacts of AI on society - for example, exploring what different sectors and domains might look like in 5-10 years as a result of current trends in AI development and deployment - is likely to be important both for thinking about what we can do today to protect against future harms, and for preparing for longer-term impacts and scenarios. Similarly, there are many ways in which AI systems could become more advanced over the coming years, before reaching anything close to superintelligence’ or `AGI’. We need to consider what issues these intermediate advances might raise, and what kinds of intermediate advances in capabilities are mostly likely to be of harm or benefit for society.
Figure fig-1 shows how considering these two dimensions of capabilities and impacts, each sitting on a spectrum, allows for more nuanced categorisation of different types of issues.
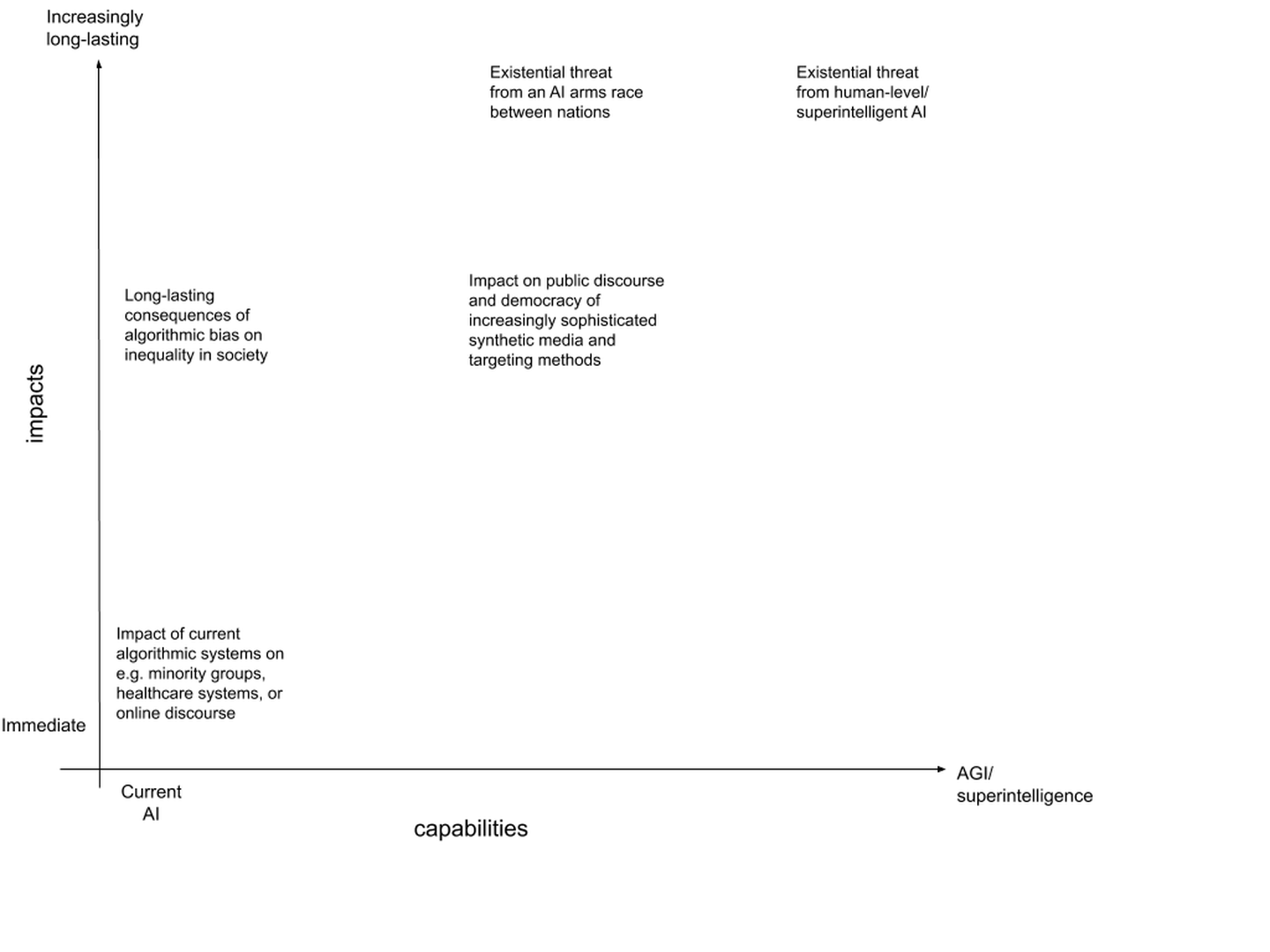
This way of conceptualising the research space could also be used to situate different research groups or research agendas. For example, AI Now’s research seems to sit pretty squarely in the bottom left-hand corner; the Centre for the Governance of AI at Oxford focuses mostly on issues at the top of the plot but spanning left to right; and the Centre for the Future of Intelligence at Cambridge works on issues across a much wider range of the plot. Both authors of this paper see their research as mostly focusing in the upper-left quadrant - i.e. considering the medium-to-long-term impacts of near-to-medium-term AI capabilities, primarily because these issues have thus far been more neglected in discourse and research around AI E&S impacts.
Of course, this still contains considerable ambiguity and room for disagreement, and placing different issues on these axes requires making assumptions about questions we don’t necessarily have good answers to. Is there really good reason to think that advanced AI systems will pose an existential threat to humanity, or that advances in AI capabilities might pose a threat to democracy with long-lasting consequences? We believe that provoking productive debate and discussion on questions like these could in fact be a valuable consequence of this way of conceptualising the research space. However, we also recognise that any two-dimensional plot is limited in its ability to capture more fundamental reasons why people have those different priorities. We therefore next turn to a discussion of some of the beliefs and motivations underpinning different approaches in the AI E&S research space.
Underlying beliefs and motivations
One question that has not been explored in existing discussions of the near/long-term distinction is why different researchers and groups have different priorities. The idea of focusing on impacts that are more or less certain and more or less extreme are present in some definitions of near and long-term (see table table1); we suggest that these dimensions may be best understood as capturing some of the underlying motivations people have for focusing on certain types of research questions.
One reason to focus on researching the longer-term impacts of AI, and/or the impacts of more advanced capabilities, is that those impacts might be more extreme and so particularly important to manage. Indeed, groups like the Open Philanthropy Project who explicitly prioritise risks from advanced AI state that “all else equal, we’re more interested in artificial developments that would affect more people and more deeply”. Similarly, a research agenda published by the Future of Humanity Institute in Oxford, typically thought of as an institution with a `long-term’ focus, explicitly highlights its “focus on extreme risks”.
The idea that immediate impacts of AI and/or those relating to current AI systems are more certain and well-understood is also sometimes invoked as a reason to work on those issues (or as an argument against focusing on advanced capabilities and long-term impacts.) For example, Andrew Ng explains that the reason he is not concerned about advanced AI is “the same reason I don’t worry about overpopulation on Mars… we’ve never set foot on the planet so how can we productively worry about this problem now?”. Relatedly, criticisms of those who focus on potential existential risks from AI often make the argument that these worries are too speculative, and are “a distraction from the very real problems with artificial intelligence today”.
Working on problems that may have very extreme impacts on humanity, and working on problems that are certain and well-understood today are somewhat in tension with one another, and this tension is perhaps a central driver of the divide between long-term' and near-term’ communities in AI E&S. Of course, in line with the main message of this paper, our view is that there is not a simple binary choice between focusing on extreme' impacts of AI and focusing on certain’ impacts - both exist on a spectrum, and there may be many ways for the AI E&S community to identify areas for research which have relatively high-stakes implications while also being grounded enough in current AI and societal trends to make progress on.
Further dimensions of disagreement may help explain why the AI E&S community has divided in certain ways. Disagreement on normative issues may be relevant here, such as around whether we have a special moral obligation to help those who are alive today over those who will live in future, or to prioritise helping those worst off in society. Someone who holds the more fundamental philosophical belief that we should prioritise helping the worst off in society, for example, is likely to choose to work on the implications of AI for global fairness or social justice, regardless of their position on the certainty/extremity tension as outlined above.
Other disagreements underpinning different priorities may be empirical: disagreements about the nature of problems, or our ability to solve them. Whether one believes it is more important to focus on challenges relating to current or advanced AI systems is likely to depend at least in part on beliefs about AI progress. If you believe we are likely to see very fast and/or discontinuous progress in AI capabilities over the next few years, preparing for the potential impacts of these advances seems much more urgent than if you believe progress will be slow and gradual, giving us time to solve today’s problems before we have to deal with anything more advanced. Indeed, much of the disagreement about whether we should be concerned about advanced AI seems to turn on disagreement about whether large advances in AI capabilities are possible any time soon. Which specific impacts one chooses to focus on may also depend on empirical beliefs about the severity of different issues: how damaging to society threats to privacy might be in the long-term, and/or how likely advanced AI systems are to pose an existential threat, for example.
Beliefs about our ability to forecast and/or influence the future are also relevant - often scepticism about research on advanced AI systems seems to stem from doubts about our ability to productively work on these problems. Andrew Ng’s statement quoted earlierappears to express this kind of scepticism: that we can’t `productively’ work on the impacts of advanced AI systems.
Recommendations and conclusion
The field of research concerned with the impact of AI on society and humanity is fast growing. Due to the cross-cutting and interdisciplinary nature of these issues, it is useful to be able to carve up the research space in ways that go beyond traditional disciplinary or thematic boundaries in academia, and capture different underlying assumptions about what the most important problems in this space are. We propose more nuanced ways to do this that better capture this rich and complex research space, breaking down the binary distinction between near-term' and long-term’ into four different dimensions: capabilities, impacts, certainty and extremity, and emphasising that all of these sit on a spectrum.
Based on this analysis, we have a few concrete recommendations for how the AI E&S research community can encourage more nuanced and productive discussion about different priorities and assumptions:
- Be specific about what you mean when using
near-term' orlong-term’ to refer to research priorities or projects. As outlined in the previous section, we think it would be particularly useful if there was a clearer distinction between (a) immediate vs. long-term impacts on society, and (b) current vs. much more advanced AI capabilities, and if there were greater acknowledgement that in both cases `near to long-term’ is a spectrum, not a binary distinction. - Communicate clearly and explicitly about the assumptions and beliefs underlying your projects and priorities, especially around some of the questions highlighted above. A good example of this is the preface to Dafoe’sresearch agenda, which explicitly states its focus on extreme risks from advanced AI (though they could go even further to explain the reasoning behind this decision.) Another good example is Parson et al.who clearly state that their project focuses on the “intermediate scale of AI impacts, time horizons, and implications” since this is where their expertise is most relevant, and where areas of potential importance are receiving relatively less attention.
- Make an effort to understand the underlying motivations and assumptions of others with different research priorities, again using some of the questions outlined in the previous section as a starting point. Conferences, workshops and journals could potentially help support this by providing fora for researchers to debate such fundamental questions and disagreements, improving mutual understanding.
By taking these steps, we hope the AI E&S research community can: (a) establish new opportunities for collaboration and reduce adversarial dynamics, while allowing for differences of opinion and approach; (b) develop more consistent and coherent research agendas by helping researchers to think more clearly about what they prioritise; and (c) identify neglected research areas which may have been overlooked due to not fitting neatly into existing ways of characterising the research space.
Bibliography
1@article{newellmarabelli2015,
2 publisher = {Elsevier},
3 year = {2015},
4 pages = {3--14},
5 number = {1},
6 volume = {24},
7 journal = {The Journal of Strategic Information Systems},
8 author = {Newell, Sue and Marabelli, Marco},
9 title = {Strategic opportunities (and challenges) of algorithmic decision-making: A call for action on the long-term societal effects of `datification'},
10}
11
12@book{brockman2019,
13publisher = {Penguin Press},
14year = {2019},
15author = {Brockman, John},
16title = {{Possible} {Minds}: {Twenty}-{Five} {Ways} of {Looking} at {AI}},
17}
18
19@article{tucker2018privacy,
20publisher = {University of Chicago Press},
21year = {2018},
22journal = {The Economics of Artificial Intelligence: An Agenda},
23author = {Tucker, Catherine},
24title = {Privacy, algorithms, and artificial intelligence},
25}
26
27@book{zuboff2019age,
28publisher = {Profile Books},
29year = {2019},
30author = {Zuboff, Shoshana},
31title = {The age of surveillance capitalism: The fight for a human future at the new frontier of power},
32}
33
34@inproceedings{hajian2016algorithmic,
35organization = {ACM},
36year = {2016},
37pages = {2125--2126},
38booktitle = {Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining},
39author = {Hajian, Sara and Bonchi, Francesco and Castillo, Carlos},
40title = {Algorithmic bias: From discrimination discovery to fairness-aware data mining},
41}
42
43@article{goodall2016can,
44publisher = {IEEE},
45year = {2016},
46pages = {28--58},
47number = {6},
48volume = {53},
49journal = {IEEE Spectrum},
50author = {Goodall, Noah J},
51title = {Can you program ethics into a self-driving car?},
52}
53
54@article{koene2017algorithmic,
55publisher = {IEEE},
56year = {2017},
57pages = {31--32},
58number = {2},
59volume = {36},
60journal = {IEEE Technology and Society Magazine},
61author = {Koene, Ansgar},
62title = {Algorithmic Bias: Addressing Growing Concerns [Leading Edge]},
63}
64
65@article{bonnefon2016social,
66publisher = {American Association for the Advancement of Science},
67year = {2016},
68pages = {1573--1576},
69number = {6293},
70volume = {352},
71journal = {Science},
72author = {Bonnefon, Jean-Fran{\c{c}}ois and Shariff, Azim and Rahwan, Iyad},
73title = {The social dilemma of autonomous vehicles},
74}
75
76@article{asaro2012banning,
77publisher = {Cambridge University Press},
78year = {2012},
79pages = {687--709},
80number = {886},
81volume = {94},
82journal = {International Review of the Red Cross},
83author = {Asaro, Peter},
84title = {On banning autonomous weapon systems: human rights, automation, and the dehumanization of lethal decision-making},
85}
86
87@article{anderson2013law,
88publisher = {Stanford University, The Hoover Institution},
89year = {2013},
90author = {Anderson, Kenneth and Waxman, Matthew C},
91title = {Law and ethics for autonomous weapon systems: Why a ban won't work and how the laws of war can},
92}
93
94@book{ford2019,
95publisher = {Packt Publishing},
96year = {2019},
97author = {Martin Ford},
98title = {{Architects} of {Intelligence}: {The} truth abut {AI} from the people building it},
99}
100
101@misc{sittler2019,
102howpublished = {https://fragile-credences.github.io/prioritising-ai/},
103year = {2019},
104author = {Sittler, Tom},
105title = {A shift in arguments for {AI} risk},
106}
107
108@misc{ngo2019,
109howpublished = {https://thinkingcomplete.blogspot.com/2019/01/disentangling-arguments-for-importance.html},
110year = {2019},
111author = {Ngo, Richard},
112title = {Disentangling arguments for the importance of {AI} safety},
113}
114
115@book{tegmark2017,
116publisher = {Knopf},
117year = {2017},
118author = {Tegmark, Max},
119title = {Life 3.0: Being human in the age of artificial intelligence},
120}
121
122@article{crawfordcalo2016,
123year = {2016},
124pages = {311},
125number = {7625},
126volume = {538},
127journal = {Nature News},
128author = {Crawford, Kate and Calo, Ryan},
129title = {There is a blind spot in {AI} research},
130}
131
132@article{gruetzemacher_2019,
133year = {2019},
134journal = {Effective Altruism Global, London 2019},
135author = {Gruetzemacher, Ross and Whittlestone, Jess},
136title = {{Defining} and {Unpacking} {Transformative} {AI}},
137}
138
139@misc{whitehouse_2016,
140author = {National Science and Technology Council (Obama White House)},
141year = {2016},
142title = {{Preparing} {For} {The} {Future} {Of} {Artificial} {Intelligence}},
143}
144
145@article{dafoe_ai_2018,
146year = {2018},
147author = {Dafoe, Allan},
148journal = {Center for the Governance of AI, Future of Humanity Institute, University of Oxford},
149title = {{AI} {Governance}: {A} {Research} {Agenda}},
150}
151
152@article{garling_why_2015,
153year = {2015},
154author = {Garling, Caleb},
155journal = {Wired},
156title = {{Andrew} {Ng}: {Why} `{Deep} {Learning}' is a mandate for humans, not just machines.},
157}
158
159@book{parfit_equality_1991,
160publisher = {University of Kansas, Department of Philosophy},
161year = {1991},
162author = {Parfit, Derek},
163title = {Equality or priority},
164}
165
166@article{parfit_future_2017,
167publisher = {Wiley Online Library},
168year = {2017},
169pages = {118--157},
170number = {2},
171volume = {45},
172journal = {Philosophy \& Public Affairs},
173author = {Parfit, Derek},
174title = {Future people, the non-identity problem, and person-affecting principles},
175}
176
177@article{crawford_artificial_2016,
178year = {2016},
179author = {Crawford, Kate},
180journal = {The {New} {York} {Times}},
181title = {Artifical {I}ntelligence's {W}hite {G}uy {P}roblem.},
182}
183
184@article{etzioni_no_2016,
185year = {2016},
186month = {September},
187author = {Etzioni, Oren},
188journal = {{MIT} {T}echnology {R}eview},
189 title = {No, the {Experts} {Don't} {Think} {Superintelligent} {AI} is a {Threat} to {Humanity}},
190}
191
192@article{dafoe_yes_2016,
193year = {2016},
194month = {November},
195author = {Dafoe, Allan and Russel, Stuart},
196journal = {{MIT} {T}echnology {R}eview},
197 title = {Yes, {We} {Are} {Worried} {About} the {Existential} {Risk} of {Artificial} {Intelligence}},
198}
199
200@book{whittaker_ai_2018,
201publisher = {AI Now Institute at New York University},
202year = {2018},
203author = {Whittaker, Meredith and Crawford, Kate and Dobbe, Roel and Fried, Genevieve and Kaziunas, Elizabeth and Mathur, Varoon and West, Sarah Mysers and Richardson, Rashida and Schultz, Jason and Schwartz, Oscar},
204title = {AI now report 2018},
205}
206
207@book{bostrom_superintelligence_2014,
208year = {2014},
209author = {Bostrom, Nick},
210publisher = {OUP Oxford},
211language = {English},
212title = {Superintelligence: {Paths}, {Dangers}, {Strategies}},
213address = {Oxford},
214}
215
216@misc{karnofsky_potential_2016,
217year = {2016},
218month = {May},
219author = {Karnofsky, Holden},
220journal = {Open Philanthropy Project},
221howpublished = {https://www.openphilanthropy.org/blog/potential-risks-advanced-artificial-intelligence-philanthropic-opportunity},
222title = {Potential {Risks} from {Advanced} {Artificial} {Intelligence}: {The} {Philanthropic} {Opportunity}},
223}
224
225@article{buch_artificial_2018,
226pages = {143--144},
227pmid = {29472224},
228year = {2018},
229month = {March},
230author = {Buch, Varun H. and Ahmed, Irfan and Maruthappu, Mahiben},
231journal = {British Journal of General Practice},
232urldate = {2019-10-31},
233number = {668},
234language = {en},
235doi = {10.3399/bjgp18X695213},
236url = {https://bjgp.org/content/68/668/143},
237shorttitle = {Artificial intelligence in medicine},
238issn = {0960-1643, 1478-5242},
239copyright = {© British Journal of General Practice 2018},
240volume = {68},
241title = {Artificial intelligence in medicine: current trends and future possibilities},
242}
243
244@techreport{richardson_dirty_2019,
245keywords = {AI, Bias, Civil Rights, Data, Justice, Machine Learning, Policing, Predictive Policing},
246year = {2019},
247month = {February},
248author = {Richardson, Rashida and Schultz, Jason and Crawford, Kate},
249institution = {Social Science Research Network},
250urldate = {2019-10-31},
251number = {ID 3333423},
252language = {en},
253abstract = {Law enforcement agencies are increasingly using predictive policing systems to forecast criminal activity and allocate police resources. Yet in numerous jurisdictions, these systems are built on data produced during documented periods of flawed, racially biased, and sometimes unlawful practices and policies (“dirty policing”). These policing practices and policies shape the environment and the methodology by which data is created, which raises the risk of creating inaccurate, skewed, or systemically biased data (“dirty data”). If predictive policing systems are informed by such data, they cannot escape the legacies of the unlawful or biased policing practices that they are built on. Nor do current claims by predictive policing vendors provide sufficient assurances that their systems adequately mitigate or segregate this data.In our research, we analyze thirteen jurisdictions that have used or developed predictive policing tools while under government commission investigations or federal court monitored settlements, consent decrees, or memoranda of agreement stemming from corrupt, racially biased, or otherwise illegal policing practices. In particular, we examine the link between unlawful and biased police practices and the data available to train or implement these systems. We highlight three case studies: (1) Chicago, an example of where dirty data was ingested directly into the city’s predictive system; (2) New Orleans, an example where the extensive evidence of dirty policing practices and recent litigation suggests an extremely high risk that dirty data was or could be used in predictive policing; and (3) Maricopa County, where despite extensive evidence of dirty policing practices, a lack of public transparency about the details of various predictive policing systems restricts a proper assessment of the risks. The implications of these findings have widespread ramifications for predictive policing writ large. Deploying predictive policing systems in jurisdictions with extensive histories of unlawful police practices presents elevated risks that dirty data will lead to flawed or unlawful predictions, which in turn risk perpetuating additional harm via feedback loops throughout the criminal justice system. The use of predictive policing must be treated with high levels of caution and mechanisms for the public to know, assess, and reject such systems are imperative.},
254url = {https://papers.ssrn.com/abstract=3333423},
255shorttitle = {Dirty {Data}, {Bad} {Predictions}},
256title = {Dirty {Data}, {Bad} {Predictions}: {How} {Civil} {Rights} {Violations} {Impact} {Police} {Data}, {Predictive} {Policing} {Systems}, and {Justice}},
257type = {{SSRN} {Scholarly} {Paper}},
258address = {Rochester, NY},
259}
260
261@article{baum2018,
262publisher = {Springer},
263year = {2018},
264pages = {565--572},
265number = {4},
266volume = {33},
267journal = {AI \& SOCIETY},
268author = {Baum, Seth D},
269title = {Reconciliation between factions focused on near-term and long-term artificial intelligence},
270}
271
272@article{krakovna_is_2018,
273year = {2018},
274author = {Krakovna, Viktoriya},
275journal = {Future of Life Institute News},
276url = {https://futureoflife.org/2018/01/29/trade-off-immediate-longer-term-ai-safety-efforts/},
277title = {Is {There} a {Trade}-{Off} {Between} {Immediate} and {Longer}-term {AI} {Safety} {Efforts}?},
278}
279
280@article{parson_artificial_2019,
281year = {2019},
282howpublished = {aipulse.org/artificial-intelligence-in-strategic-context-an-introduction/},
283author = {Parson, Edward and Re, Richard and Solow-Niederman, Alicia and Zeide, Elana},
284title = {Artificial {Intelligence} in {Strategic} {Context}: {An} {Introduction}},
285}
286
287@techreport{brundage_guide_2017,
288year = {2017},
289author = {Brundage, Miles},
290url = {https://80000hours.org/articles/ai-policy-guide/},
291title = {Guide to working in {AI} policy and strategy},
292}
293
294@article{cave_bridging_2019,
295pages = {5--6},
296year = {2019},
297month = {January},
298author = {Cave, Stephen and ÓhÉigeartaigh, Seán S.},
299journal = {Nature Machine Intelligence},
300urldate = {2019-10-30},
301number = {1},
302language = {en},
303abstract = {Debate about the impacts of AI is often split into two camps, one associated with the near term and the other with the long term. This divide is a mistake — the connections between the two perspectives deserve more attention, say Stephen Cave and Seán S. ÓhÉigeartaigh.},
304doi = {10.1038/s42256-018-0003-2},
305url = {https://www.nature.com/articles/s42256-018-0003-2},
306issn = {2522-5839},
307copyright = {2019 Springer Nature Limited},
308volume = {1},
309title = {Bridging near- and long-term concerns about {AI}},
310}Attribution
arXiv:2001.04335v2
[cs.CY]
License: cc-by-4.0


