
- Papers
Papers is Alpha. This content is part of an effort to make research more accessible, and (most likely) has lost some details from the original. You can find the original paper here.
Introduction
Increasing adoption of artificial intelligence in public life has sparked tremendous interest in the fields of AI ethics, algorithmic fairness and bias, and model explainability and interpretability. These ideas did not spring out of thin air, but rather are a response to difficult questions about when, where, and how it is appropriate to use artificial intelligence to perform tasks. Much of the extant literature has aimed to provide constructive movement in the direction of ensuring the principles of fairness, accountability, and transparency are upheld by machine learning algorithms. For practitioners, there are three dominant approaches in AI ethics:
Fairness metrics
Interpretability
Explainability
Throughout this work, we use the term “AI system” to mean products and services that leverages artificial intelligence as a decision making component. The term “Responsible AI” then is an AI system that is built with a notion of minimizing the potential harm. The term “harm”, used throughout the paper, we use in accordance with Crawford’suse of the term to mean both allocative and representational harms. Allocative harms are harms which result in an improper distribution of resources on the basis of group membership. Representational harms are more difficult to quantify than allocative harms and result in the reinforcement of subordination of some group on the basis of identify, e.g. race, gender, class, etc.
The topics of fairness, interpretability, and explainability are not merely of interest to the academic world. The European Union has begun work on their “AI Act”, a law that seeks to legislate and harmonize regulations of technologies and products that leverage artificial intelligence. In the United States, the National Institute of Standards and Technology has begun work on a risk management framework for artificial intelligence, and a number of states have passed legislation regulating uses of artificial intelligence. Consequently, all at once, we are developing methods for determining and achieving fairness and explainability, implementing these methods in industry, and seeing regulation of the technologies that encourage or require those same methods. Unfortunately, standardization of these topics is ongoing, there are no one-size-fits-all solutions, and there are significant methodological and computational hurdles to overcome.
We look to the field of information security as one potential model for success due to similarities between the two fields. In particular, information security deals with a number of competing theoriesand standardsthat make it challenging to harmonize controls. Moreover, information security, like ethical AI, aims to find heuristics, stopgaps, and proxies for computationally intractable problemswith important human impacts. In information security, it is widely accepted that even in the best case for mitigation, vulnerabilities and compromises cannot be avoided entirely. To this end, information security seeks to optimize mitigation, detection, and response. In this work, we demonstrate how practitioners in ethical AI can use the framework of mitigation, detection, and response to operationalize fairness, interpretability, and explainabiltiy frameworks.
Background and Related Works
This work builds on research in economics, AI ethics, software engineering, and information security, drawing inspiration from Howard and Lipner’s Security Development Lifecycleand from the many ways that their work has been refined, implemented, and evolved in the software industry. In this section, we provide background on fairness, interpretability, and explainability with an eye towards the insufficiency of existing methods. Crucially, in the realm of interpretability and explainability, the presence of explanations increases user confidence in the predictions of the model, even when the explanations are incorrect.
Fairness
In the economics literature, there are a variety of fairness metrics that have been established. For many fairness metrics in the continuous case, the problems are rarely able to be solved efficientlyand for indivisible goods, envy-free allocation – allocation where nobody would rather have someone else’s good – is NP-hard. Kleinberg _et al._explore the COMPAS risk tool and show that for integer values, risk assignment is NP-Complete; although for non-integer values, the problem of fair risk assignment in polynomial-time remains open. Fairness in classification was examined by Dwork et al., who developed fairness constraints in a classification context, identifying statistical parity as one way to determine fairness in classifiers. Yona and Rothblumtackle the issue of generalization from training to test sets in machine learning by relaxing the notion of fairness to an approximation and demonstrating generalization of metric-fairness. Like the aforementioned works, much of the literature focuses on the fairness of a single algorithm making classifications on groups of agents.
In the multi-agent setting, where motivations of individual agents may worsen the outcomes of other agents, the problem becomes even more difficult. The work of Zhang and Shahattempts to resolve fairness in this multi-agent setting via linear programming and game theoretic approaches. The game theoretic approach used tries to find a Nash equilibrium for the two-player zero-sum setting, a problem which is known to be PPAD-Completeand conjectured not to be in P unless P = NP. This suggests that in general, any attempt at algorithmic fairness is a substantial computational problem on top of whatever problem we are aiming to solve.
In addition to computational difficulties, the work of Fazelpour and Liptonaddresses shortcomings in the ideological foundations of formalizing fairness metrics by connecting the existing work to the political philosophy of ideal and non-ideal approaches. As in much of the fair machine learning literature, ideal models in political theory imagine a world that is perfectly just. By using this as a target, we aim to measure – and correct for – the deviation from this ideal. However, developing this fairness ideal in algorithmic settings necessitates comparison to other groups and consequently, a “fair” approach may actually be worse for all groups and yield new groups that need to be protected. Further work by Dai _et al._shows that fairness allocations with narrow desiderata can lead to worse outcomes overall when issues like the intrinsic value of diversityare not accounted for. This suggests that because the term “fairness” is not well-defined, collaboration between developers of AI systems and social scientists or ethicists is important to ensure any metric for measuring fairness captures a problem-specific definition of the term.
Interpretability
Recent work on model interpretability has indicated that users find simpler models more trustworthy. This is built on the definition of Liptonthat presumes users are able to comprehend the entire model at once. However, the ability to interpret high-dimensional models is limited, even when those models are linear. This initially suggests that model interpretability limits the available models to low-dimensional linear models and short, individual decision trees.
Spurred by these notions, Generalized Linear Models and Generalized Additive Models have been developed and seek to be sufficiently robust to be useful in practice while retaining strong notions of human-interpretability. These methods allow for linear and non-linear models that are inherently interpretable. However, as Molnar notes, high-dimensional models are inherently less interpretable even when those models are linear. Moreover, even the most interpretable models rely on assumptions about the stability of the data generation process and any violation of those assumptions renders interpretation of those weights invalid.
Explainability
Post-hoc explanations have proven very popular due to their intelligibility and their ability to be used with complex machine learning models, particularly neural networks. Explainablity methods tend to be model agnostic and are more flexible than model-specific interpretation methods. We refer readers interested in the technical details of these methods to other resources, such as the book by Molnaror appropriate survey literature. In practice, explainability methods manifest in a variety of ways:
Partial Dependence Plots
Individual Conditional Explanations
Accumulated Local Effects
Feature Interaction
Feature Importance
Global Surrogates
Local Surrogates
Shapley values
Counterfactual Explanations
Adversarial Examples
Attention Layer Visualization
The above methods can be broadly grouped into two buckets: global explanations and local explanations. Global explanations seek to provide overall model interpretability for models that are otherwise difficult to understand. These methods will demonstrate, for example, how certain features are weighted more heavily than others or show how correlation between variables can cause a particular prediction. Local methods, on the other hand, purport to provide explanations for individual predictions. The most popular among these are LIME, GradCAM, and SHAP, which leverage local surrogate models, gradient-based localization, and Shapley values respectively to foster explanations. In response to their popularity, the robustness of these methods have been investigated. Slack _et al._demonstrated that these methods do not work well in an adversarial setting – that is, they can be fooled by a modeler who wishes to provide convincing explanations that appear innocuous while maintaining a biased classifier. Further work by Agarwal _et al._attempts to establish foundations for robustness in explanation methods, finding that there are some robustness guarantees for some methods, but those guarantees are subject to variance in the perturbations and gradients. Beyond these issues, substantial critiques have been leveraged against the use of Shapley values for feature importancebased on their inconsistency across distributions and the lack of a normative human evaluation for the values.
Counterfactual explanations offer a particularly useful line of explanation, effectively answering the question: “what would need to be different to get a different outcome?” Humans desire counterfactual explanations, since they provide a direction to create a different outcome in the future. As an example, when a person applies for a bank loan and is denied on the basis of their credit score, they expect a counterfactual explanation that says what factors, specifically, contributed to the denial and would need to improve in order to approve the loan. Though metacognition – thinking about thinking – has been studied in computer science, and particularly in cognitive architectures, recent attempts have been madetoward a metacognition for explaining difficult to interpret models, largely in the mold of providing counterfactual explanations. However, to date, counterfactal explanations and artificial metacognition have not developed sufficiently to allow for their use.
Attacks on AI systems
There is a deep connection between security and fairness in machine learning systems. Aside from clear connections like the link between differential privacy and fairness in classification, techniques like adversarial examples– inputs to models that are similar to humans but are perturbed to cause misclassification – can be used to evaluate the robustness of model fairness, interpretability, and explainability. Adjacent to our taxonomy of allocative and representational harms, we also have a taxonomy of harms that our model can perpetrate against users and third parties: one, the harms caused by the system itself, including the aforementioned allocative and representational harms; two, the harms caused to users by other users of the system. The first case is well-studied, though strategies for renumerating and redressing uncovered harms outside of calibration primarily prescribe putting human-in-the-loop or mandating explanations for a human gatekeeper. The harms caused to users by other users of the system tend to align more closely with attacks on AI systems, which we provide a high-level overview of below and refer readers to surveys on attacks in machine learningand threats to privacy in machine learningfor additional details. These user-on-user harms largely align with four overarching categories:
Classification-level attacks
Model-level attacks
System-level attacks
Privacy attacks
Classification-level attacks are those attacks which seek to cause misclassification. These attacks include adversarial examples in images, but also distinct techniques like “Bad Characters”that use imperceptible characters to bypass text content filters. Essentially, these attacks allow one user to harm another by causing an input to be misclassified without altering the model, data, or anything else. These attacks would also include attacks like the one used against Tesla’s Traffic Aware Cruise Controlwhere a malicious individual could easily modify a 35 mph speed limit sign with a small piece of black tape and cause the model to incorrectly classify the sign as an 85 mph speed limit sign.
Model-level attacks differ from classification-level attacks in that they alter the model itself. The most common example of this is a poisoning attack – an attack in which the training data of the model are altered to cause consistent misclassification. This often requires access to the model or the data itself, making the attack challenging. However, in the online setting, a number of online data poisoning attackshave been demonstrated to great effect. A malicious user then, could poison the model and cause problems for all users.
System-level attacks are intend not to simply affect the predictions of the model, but rather damage the system itself. An example here is that of sponge examples, model inputs that are generated to maximize energy consumption and inference time to degrade the functionality of the system. This can also include exploitation of conventional vulnerabilities which could allow for tampering with model inputs or outputs to harm users.
Privacy attacks include membership inferenceand model inversion. Membership inference attacks seek to identify whether or not individuals are present in the training data of a model, potentially damaging user privacy. Model inversion then, is a step further. Rather than ask whether or not a user’s data is present in the training data of the model, model inversion seeks to extract training data directly from the model – a phenomenon that has been observed in generative models. Both of these attacks can facilitate harms to users and are within the purview of responsible AI to limit.
Adapting the Secure Software Development Lifecycle to Artificial Intelligence
As discussed, attempts to satisfy fairness criteria can be limiting from a computational perspective. Within information security, there is a notion of formal verification, a computationally intensive process of ensuring that under any input, the program behaves as expected. This leads to more reliable software that is less prone to exploitable bugs. Note however, that the mission statement of formal verification – designing a program that halts when a bug is detected – is undecidable because it is exactly the halting problem. This has led to extensive work in both automated and interactive verification to overcome this theoretical barrier by solving subproblems, approximations of the problem, or writing domain-specific automation. In many cases, formal verification for software is a larger engineering effort than the software project itself and as a result, most software is not formally verified. How then, do we ensure that software is not riddled with exploitable bugs? In general, the presence of exploitable bugs in softwareis reduced through a number of steps in the secure software development lifecycle. For our purposes, we identify analogies between ethical AI development and the following:
Design Review
Threat Modeling
Penetration Testing
These principles reduce risk that may be introduced in software development and produce more robust code without the overhead of formal verification methods. In ethical artificial intelligence, we also seek to reduce the risk of negative outcomes and discrimination. As such, we adapt these secure software development lifecycle principles to ethical AI. One point of disagreement in the security community that may be reflected here is whether to perform threat modeling ahead of design review. The idea of performing threat modeling first is to provide a thorough view of the threats so that the risks uncovered in design review are threat-centric. We follow the convention of performing design review ahead of threat modeling based on the rationale that defining the threats for a system that has not yet been designed makes the scope too broad to be useful. We note that both approaches are valid and can be tailored to fit the maturity and preferences of the organization.
Design Review
In information security, a design review looks at the system under development and assesses the architecture, design, operations, and their associated risksallowing for implementation of systems-level security controls such as authentication, encryption, logging, and validation. When developing AI systems, a similar sort of design review should be conducted, with a view toward AI risks. This means that during the design review process, we should explore questions like:
- How can we check for distribution drift?
- Are we logging model queries in a way that allows us to find reported bad behaviors?
- What features do we input to the model, and do they introduce potential issues?
- Are there other data sources we should be incorporating into this model?
- What actions, if any, are taken automatically as a result of model predictions?
This step provides a system-level view of how data goes into and predictions come out of the system and is ideally conducted before the system is deployed. The idea, at the design review step, is to identify data flows and consider how the system could be refactored or rearchitected to avoid potential risks. Things like data pre-processing or calibrationshould be discussed at this step, and if they are not needed or not sufficient, there should be documentation as to why they are omitted. This goes beyond the actual model and training pipeline to include where data is derived from, what additional data is collected, where predictions and logs are stored, and other system-level issues.
An important part of the design review process is a discussion of how data related to the system is generated, processed, and stored. This is an important part of the system that is often viewed through a lens of privacy and policy, but not always with a view of how to responsibly manage data. While data management and mismanagement can cause one to run afoul of data privacy legislation, there are a variety of personal data misusesthat can cause harm. This means that the privacy of data per se is not the entirety of the discussion, but how the data moves through the system to become a classification needs to be uncovered. An investigation into this requires analysis of all data used in predictions, whether these are raw data, proxy features that stand in for data that is not directly available, or transformed features like those yielded from principle component analysis.
Threat Modeling
Threat modeling is the phase of the development process that aims to predict the threats that a system may face. Akin to how one might imagine ways to secure a home by evaluating the locks, windows, and entrances to their home, threat modeling seeks to evaluate how attackers may gain entry to a system. Since AI systems are software, the security threat modeling conducted should incorporate those systems. By analogy, we want to think not only of threats to our system, but how our system could pose a risk to users. This comes in two forms: malicious users of our system harming other users, and harms that our system could hypothetically cause.
When it comes to harming other users, we look to AI security and data privacy for potential harms. Essentially, we must assess if users are fully independent and if not, the ways in which one user could potentially harm another. As an example, malicious users could extract training data from trained models or infer individuals membership in the training datawhich could then be used to harm those individuals privacy. Another example is malicious users conducting data poisoning attacks, particularly for online machine learning systemsthat might lead to bad outcomes for other users. This is one way that AI security directly influences AI ethics.
On the other hand, enumerating ways in which a system using AI could harm users is also critical. Some harms may be expected: a self-driving car that does not recognize a pedestrian, a discriminatory bail-setting algorithm, an image cropping algorithm suffering from the “male gaze”. However, other harms could rear their head. For example, the EMBER malware (malicious software) datasetincludes a large number of features for Windows Portable Executable files, including the language of the system the malware was compiled on. One could conclude, based on the command and control infrastructure and the compilation language of the malware, that the presence of Chinese language is indicative of maliciousness and correspondingly restrict access to Chinese language websites. One harm this could introduce, however, is inadvertent discrimination against Chinese-speaking users who may wish to visit legitimate webpages or run legitimate software. Ultimately, we may conclude that the benefit of deploying the system outweighs the risk – but identifying this possible harm is still an important part of the threat modeling process that we will revisit in our section on Incident Response.
Penetration Testing
The concept of a penetration test is simple – a trusted individual or team with adversarial skills seeks to find weaknesses in a system in accordance with the same techniques an attacker would use. In the context of developing ethical AI systems, a “penetration test” then approaches our AI system with the same tools and intent as a malicious actor. This test should evaluate an attacker’s ability to harm the system, harm the users of a system, and also uncover harms latent in the system. Much like the Twitter Algorithmic Bias Bug Bounty, we can and should directly evaluate our algorithms from an adversarial perspective, even if only internally. Though the term penetration testing has a particular meaning in the information security context, we use it here to refer to the use of adversarial techniques to uncover potential harms in AI systems. Additionally, we eschew the phrase “algorithmic bias assessment” since bias is only one potential cause for harm and we seek to use a more task-oriented term.
Conducting these sort of assessments require both AI security skills and sociotechnical knowledge. As of 2021, only 3 out of 28 organizations surveyed conducted security assessments on their machine learning systems, suggesting that many organizations are not currently well-equipped to evaluate these vulnerabilities and would need to cultivate teams capable of performing algorithmic harm assessments. Utilities like Counterfitand PrivacyRavenhave lowered the barrier to entry for security professionals to use adversarial examples and membership inference attacks on machine learning models, but many organizations still do not assess their machine learning security. These same utilities are critical to conducting these assessments against models. Additionally, simple tactics like using so-called beauty filters can also demonstrate bias in machine learning systems. In order to devise new tactics to target these algorithms, AI assessors need to understand both the technical and social factors included in these systems. Importantly, the act of testing these systems assists us not only in identifying potential harms but also in assessing the robustness of our system.
Another key to penetration testing is the need to test the full system as deployed. Since the algorithm is not deployed in a vacuum, there may be feature engineering, allow and block-listing, preprocessing, post-processing, and other steps that could allow problems to creep into the system. Many so-called “AI systems” are not single algorithms deployed behind an API, but are instead a tapestry of data engineering, multiple algorithms, and post-processing systems. In some cases, an algorithm may be biased against a particular group, but some calibrationin a post-processing system corrects for the identified issue. In other cases, the added complexity of the overall system may actually amplify small changes to inputs and cause a larger effect that one might observe on the individual algorithm.
Incident Response
An often overlooked discussion is how to deal with a harm perpetrated by an AI system once it is identified. In the field of information security, there is the concept of a breach – a successful intrusion by an attacker into our system – and when this occurs, we begin the incident response process. Typically an incident response process occurs alongside execution of a business continuity plan, a predefined plan for how to continue execution when there is a security event or natural disaster. The incident response process involves eliminating the attacker’s access to systems, patching vulnerabilities that were exploited, and taking steps to ensure that the attacker does not get back in. Similarly, we should be prepared in the field of AI to respond to events where our system creates or perpetuates harm.
There are a number of ways harms can be identified even after design review, threat modeling, and penetration testing such as through a bias bounty, a news report, or a user reporting that they have been harmed. Once the existence of a harm is identified, the work of incident response begins with identifying what the actual harm is. This can be an acute damage or harm to an individual, a systemic bias problem, or the potential for a third-party to harm other users of the system. A self-driving car that strikes a pedestrian is a commonly-used example because the harm is clear: there exists a configuration of vehicles, pedestrians, and other distractions such that the vehicle does not stop before a pedestrian is struck. Other harms, such as bias against racial and gender minorities as observed in the cases of COMPASand Amazon’s hiring algorithmare less obvious until we conduct research into exactly what harms occurred. Whether the harm identified is an acute damage to an individual or an ongoing systemic harm, we must take immediate action to:
Continue operations if possible
Perform root cause analysis
Remediate the harms caused
Continuity Planning
Once a harm is established, all reasonable efforts to prevent another incident should be taken. In many cases, this means removing a system from production for a period of time while the remainder of the incident response process is executed. Some sort of procedure should be established to allow for continuity of operations during this period that is contingent on the severity of the harm. For example, a self driving car that strikes a pedestrian may require temporarily suspending self-driving across a fleet or limiting where it can be used. In the case of something like a discriminatory sentencing algorithm, we may simply allow judges to operate as they did before the tool was available, suspending its use. Other cases, such as Twitter’s image cropping algorithm’s “male gaze” bias or its aversion to non-Latin text may not rise to the need for continuity response and can remain in production.
In many cases, the scale of these harms – bad user experience, emotional pain and suffering, loss of life – can be anticipated, even if the specific harm cannot. This provides the ability to set up risk-based continuity planning. Essentially, we seek to answer the question: “if we have to remove this system from production, what will we do instead?” to ensure that those who depend in some way on these systems are still able to leverage them, even with limited functionality.
Root Cause Analysis
In security, root cause analysis is used to ask and answer questions about the series of events which led to a security incident, often with a particular focus on the vulnerabilities exploited and why they were not patched. Even in so-called blameless post-mortems, the root cause analysis seeks to determine what was the weak link in the chain and how said weak link could have been avoided. In the case of algorithmic harms, a root cause analysis is likely to be much more involved, due to the large number of pieces at play.
The first place to look when a harm occurs is what, if anything, has changed in the system since it most recently functioned at an acceptable level. If there was an update the morning before an incident, it is prudent to investigate whether or not the previous version of the system would have caused the harm. If not, an ablation study should be conducted across the pipeline to identify what components, if any, could be changed to mitigate the harm. This root cause analysis then informs future penetration tests and threat models to ensure that another incident is not caused by the same cause.
Remediating Harms
After a root cause is identified, it is prudent to remediate both the harms themselves and the causes of said harms. Remediating a harm depends a lot on the particulars of the harms caused and is currently an issue being openly discussed. For the teenagers harmed by the promotion of eating disorders on social media, it is unlikely that they will be directly compensated by the organization perpetuating the harm. Remediating the harm itself is a difficult task that asks much larger questions about who is responsible for these incidents, how the costs are handled, and who, if anyone, owes harmed parties reparations for said harms. For harms at the scale of COMPAS, the questions grow even larger. However, as governments like the EU consider revising their product liability regimes to incorporate AI, developers and purveyors of these systems should develop a plan for how to address potential claims against their systems.
Remediating the cause of the harm then, is the more straightforward task – though by no means is the task simple. Remediating the harm extends the work of root cause analysis and opens the question of how to fix the root cause. In the case of bias, this could be a matter of finding a new dataset, calibrating according to sensitive attributes, leveraging multicalibration, decision calibration, or some other method. In other cases, the cause of the harm may necessitate pre- or post-processing of data and decisions to create guardrails. Yet other cases may require a fundamental reconsideration of the system in use and whether or not it is feasible to have a safe, fair system. These harms and remediations must be documented to ensure that future projects do not fall into the same trap and can be evaluated using similar methods.
A Responsible AI Development Lifecycle
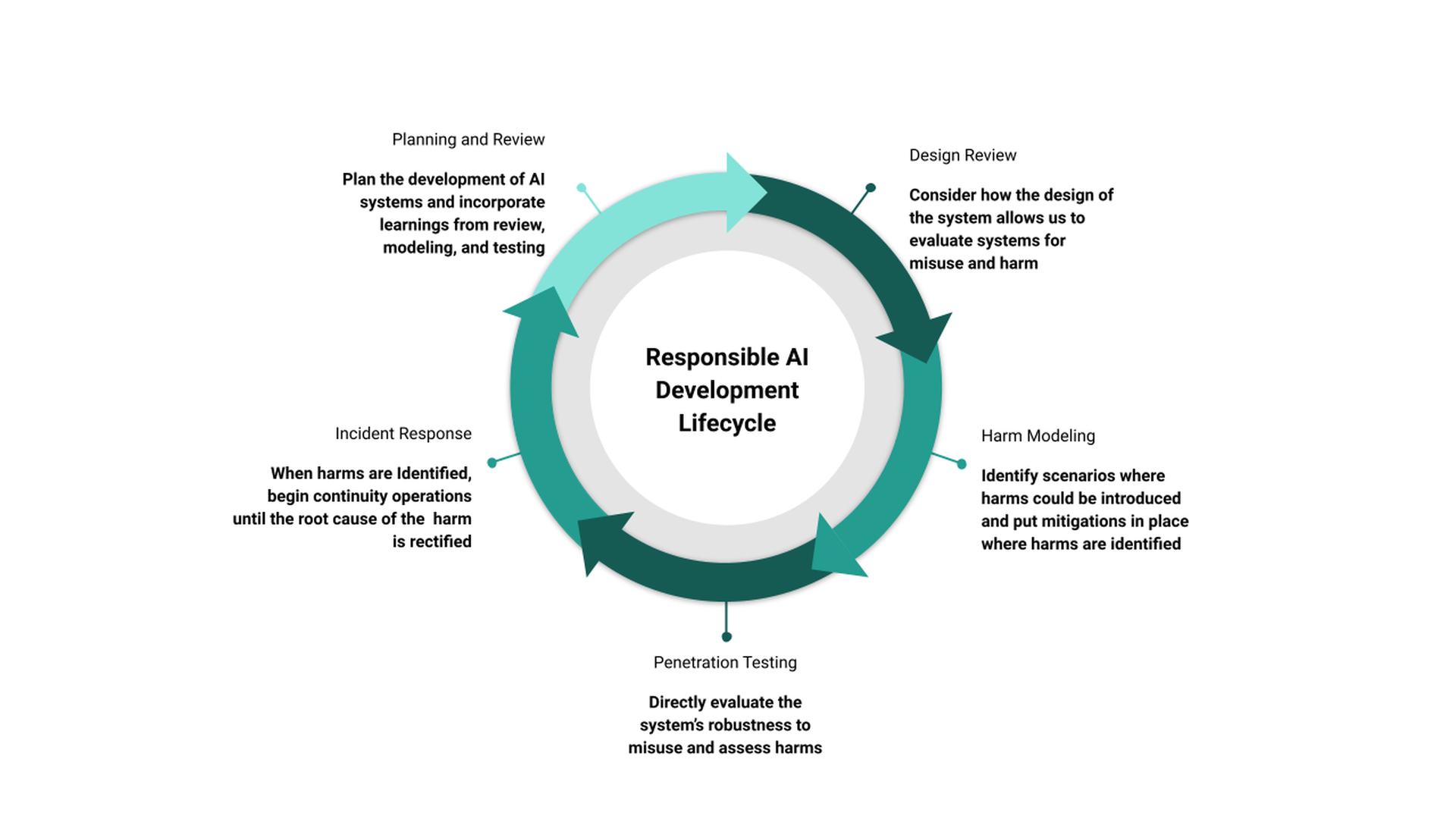
Given the analogies between security and ethical artificial intelligence in Sections sec-adapting and sec-incident, we propose a framework for a responsible AI development lifecycle, illustrated in Figure fig-lifecycle. Organizations working with artificial intelligence and machine learning have existing processes for design, development, training, testing, and deployment of AI systems. Though we do not detail those processes here, the proposed framework aims not to replace any part of that process, but rather to augment existing processes with ethical principles. The responsible AI development lifecycle consists of five steps:
Planning and Review
Design Review
Harm Modeling
Penetration Testing
Incident Response
Planning and review, as both the first and last step in the process, is intended to revise existing systems and inform the development of new systems. This step should occur before any new code is written, whether that is in the process of remediating harms or designing a new system. The planning and review process should look back at prior findings in this system and other systems and set forth the steps that need to be taken in developing this new system. Additionally, this step is where business continuity planning as outlined in Section sec-continuity should occur. One critical part of planning and review is the process of documentation – this involves documenting plans and findings, capturing learnings from incidents, and identifying structures that should be in place ahead of development.
This process leads into the design review step where the overall design of the system is set out. The intent of the system should be clear, the algorithmic components should be well understood, and data sources should be documented. In a more mature organization, a design review should include datasheetsor model cardsto nail down specific places where there are known issues. As discussed in Section sec-design-review, the design review should consider not only the artificial intelligence component, but the scaffolding around it and the system as a whole to include logging and auditing, pre-processing, post-processing, and in-processing.
Coming out of the design review step, training and tuning models, deployment, and testing can occur in parallel with harm modeling. As discussed in Section sec-threat-modeling, this is a good place for counterfactual reasoning – asking all of the “what if” scenarios to understand what can go wrong. This process should involve stakeholders from throughout the organization to identify potential harms to users of the system and to external parties. Where possible, this process should also identify mitigations that can be put in place before the system goes live. The reason to put mitigations in place ahead of time is twofold: first, having mitigations in place ahead of deployment reduces the likelihood that an individual experiences an identified harm; second, it reduces the cost of putting the mitigation in place since there is no downtime needed to implement it.
When the system is deployed or ready for deployment, we can conduct penetration testing of the system, as in Section sec-pen-test. This penetration test differs from a traditional penetration test in a number of respects, but is not entirely divorced from the original notion. Specifically, we are still concerned with discovering security bugs since many of those can be leveraged to cause harm. Where this approach differs is in taking a broader view of what is in-scope for a penetration test, since we are concerned not only with the possibility of attacks on our models, but also with potential representational harms that are difficult to uncover in security testing.
Assuming that we have established a continuity plan and done our job in the design review phase, there should be good feedback mechanisms for uncovering harms in our systems. These can be monitored and spot-corrected over time to ensure that the system is functioning as intended and is not perpetrating harms. When something goes out of wack or a user or third-party reports a problem, we should initiate our incident response. As mentioned in Section sec-incident, we should begin by identifying the scope and scale of the harm, then proceed to initiate our business continuity plan if necessary. Once we have determined the root cause of the harm, we develop a plan to alleviate the problem and proceed back to the top of the process – reviewing our findings and planning our fixes.
As teams cycle through this process for a particular system, each trip through the cycle should be shorter and easier. In some cases, the cycle may terminate entirely if the outcome of the review and planning step is a decision not to use an AI system. When evaluating the risks and benefits of deploying an AI system, it is important to always consider the reference point of simply not using artificial intelligence
Conclusion
This work establishes a framework for developing AI systems responsibly. We identify two parallel taxonomies of harm: allocative harm versus representational harm and system-on-user harm versus user-on-user harm. These two taxonomies allow us to develop methods of uncovering, identifying, and classifying harms to users. Since AI development occurs not in a vacuum but rather as part of a broader development cycle, we view the proposed framework as something that can easily work alongside existing AI system production methods.
The proposed system consists of 5 steps that mirror the standard lifecycle of a software system – design, development, training, testing, and deployment. As development proceeds, our framework helps AI developers and stakeholders evaluate their system for potential harms and address them. This framework differs from existing prescriptions of fairness metrics, explainability methods, and interpretable models due to the shortcomings of those methods computationally, epistemologically, and practically. Since nearly all systems inevitably change, fail, or prove insufficient, this framework offers an opportunity for iterative ethical improvements without sacrificing practicality. We achieve this by analogy with information security, and our framework built on the foundations of the secure software development lifecycle.
This framework makes a number of strong assumptions by necessity. Specifically, we assume that a “harm” can be identified and that given sufficient care, can be resolved. Crucially, we also assume that organizations actually want to identify and remediate harms to users and are willing to expend effort to improve their systems to that end. Finally, we assume that the skills to evaluate these models is present in organizations that wish to adopt these principles – something that we know is untrue for the majority of organizations.
In future work, we aim to address the feasibility of automating parts of this process to reduce the need for specially-skilled individuals. Today, the creation of documentation around bias, robustness, and other important features of responsible AI is cumbersome and manual. By offering opportunities to automate and operationalize some of this work, adoption of these processes is eased.
Bibliography
1@inproceedings{fazelpour2020algorithmic,
2 year = {2020},
3 pages = {57--63},
4 booktitle = {Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society},
5 author = {Fazelpour, Sina and Lipton, Zachary C},
6 title = {Algorithmic fairness from a non-ideal perspective},
7}
8
9@inproceedings{slack2020fooling,
10 year = {2020},
11 pages = {180--186},
12 booktitle = {Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society},
13 author = {Slack, Dylan and Hilgard, Sophie and Jia, Emily and Singh, Sameer and Lakkaraju, Himabindu},
14 title = {Fooling lime and shap: Adversarial attacks on post hoc explanation methods},
15}
16
17@inproceedings{shokri2021privacy,
18 year = {2021},
19 pages = {231--241},
20 booktitle = {Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society},
21 author = {Shokri, Reza and Strobel, Martin and Zick, Yair},
22 title = {On the privacy risks of model explanations},
23}
24
25@inproceedings{kumar2021meta,
26 organization = {IEEE},
27 year = {2021},
28 pages = {3795--3799},
29 booktitle = {ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
30 author = {Kumar, Sannidhi P and Gautam, Chandan and Sundaram, Suresh},
31 title = {Meta-Cognition-Based Simple And Effective Approach To Object Detection},
32}
33
34@article{babu2012meta,
35 publisher = {Elsevier},
36 year = {2012},
37 pages = {86--96},
38 volume = {81},
39 journal = {Neurocomputing},
40 author = {Babu, G Sateesh and Suresh, Sundaram},
41 title = {Meta-cognitive neural network for classification problems in a sequential learning framework},
42}
43
44@article{vilone2021notions,
45 publisher = {Elsevier},
46 year = {2021},
47 journal = {Information Fusion},
48 author = {Vilone, Giulia and Longo, Luca},
49 title = {Notions of explainability and evaluation approaches for explainable artificial intelligence},
50}
51
52@book{marshall1999metacat,
53 publisher = {Indiana University},
54 year = {1999},
55 author = {Marshall, James B},
56 title = {Metacat: A self-watching cognitive architecture for analogy-making and high-level perception},
57}
58
59@misc{ncsl2021legislation,
60 note = {[Online; accessed 10-January-2022]},
61 year = {2021},
62 howpublished = {\url{https://www.ncsl.org/research/telecommunications-and-information-technology/2020-legislation-related-to-artificial-intelligence.aspx}},
63 author = {National Conference of State Legislatures},
64 title = {Legislation Related to Artificial Intelligence},
65}
66
67@misc{nist2021rmf,
68 note = {[Online; accessed 10-January-2022]},
69 year = {2021},
70 howpublished = {\url{https://www.nist.gov/itl/ai-risk-management-framework}},
71 author = {National Institute of Standards and Technology},
72 title = {AI Risk Management Framework Concept Paper},
73}
74
75@article{eu2021proposal,
76 year = {2021},
77 volume = {206},
78 journal = {COM (2021)},
79 author = {EU Commission and others},
80 title = {Proposal for a regulation of the European Parliament and of the Council laying down harmonised rules on artificial intelligence (Artificial Intelligence Act) and amending certain Union legislative acts},
81}
82
83@inproceedings{lipton2004approximately,
84 year = {2004},
85 pages = {125--131},
86 booktitle = {Proceedings of the 5th ACM Conference on Electronic Commerce},
87 author = {Lipton, Richard J and Markakis, Evangelos and Mossel, Elchanan and Saberi, Amin},
88 title = {On approximately fair allocations of indivisible goods},
89}
90
91@book{robertson1998cake,
92 publisher = {CRC Press},
93 year = {1998},
94 author = {Robertson, Jack and Webb, William},
95 title = {Cake-cutting algorithms: Be fair if you can},
96}
97
98@inproceedings{zhang2014fairness,
99 year = {2014},
100 pages = {2636--2644},
101 booktitle = {Advances in Neural Information Processing Systems},
102 author = {Zhang, Chongjie and Shah, Julie A},
103 title = {Fairness in multi-agent sequential decision-making},
104}
105
106@inproceedings{dwork2012fairness,
107 year = {2012},
108 pages = {214--226},
109 booktitle = {Proceedings of the 3rd innovations in theoretical computer science conference},
110 author = {Dwork, Cynthia and Hardt, Moritz and Pitassi, Toniann and Reingold, Omer and Zemel, Richard},
111 title = {Fairness through awareness},
112}
113
114@inproceedings{yona2018probably,
115 organization = {PMLR},
116 year = {2018},
117 pages = {5680--5688},
118 booktitle = {International Conference on Machine Learning},
119 author = {Yona, Gal and Rothblum, Guy},
120 title = {Probably approximately metric-fair learning},
121}
122
123@inproceedings{chen2006settling,
124 organization = {IEEE},
125 year = {2006},
126 pages = {261--272},
127 booktitle = {2006 47th Annual IEEE Symposium on Foundations of Computer Science (FOCS'06)},
128 author = {Chen, Xi and Deng, Xiaotie},
129 title = {Settling the complexity of two-player Nash equilibrium},
130}
131
132@inproceedings{kleinberg2017inherent,
133 organization = {Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik},
134 year = {2017},
135 booktitle = {8th Innovations in Theoretical Computer Science Conference (ITCS 2017)},
136 author = {Kleinberg, Jon and Mullainathan, Sendhil and Raghavan, Manish},
137 title = {Inherent Trade-Offs in the Fair Determination of Risk Scores},
138}
139
140@inproceedings{dai2021fair,
141 year = {2021},
142 pages = {55--65},
143 booktitle = {Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society},
144 author = {Dai, Jessica and Fazelpour, Sina and Lipton, Zachary},
145 title = {Fair machine learning under partial compliance},
146}
147
148@article{steel2021information,
149 publisher = {Springer},
150 year = {2021},
151 pages = {1287--1307},
152 number = {2},
153 volume = {198},
154 journal = {Synthese},
155 author = {Steel, Daniel and Fazelpour, Sina and Crewe, Bianca and Gillette, Kinley},
156 title = {Information elaboration and epistemic effects of diversity},
157}
158
159@inproceedings{weidman2020nothing,
160 organization = {Springer},
161 year = {2020},
162 pages = {263--282},
163 booktitle = {European Symposium on Research in Computer Security},
164 author = {Weidman, Jake and Bilogrevic, Igor and Grossklags, Jens},
165 title = {Nothing Standard About It: An Analysis of Minimum Security Standards in Organizations},
166}
167
168@article{moody2018toward,
169 year = {2018},
170 number = {1},
171 volume = {42},
172 journal = {MIS quarterly},
173 author = {Moody, Gregory D and Siponen, Mikko and Pahnila, Seppo},
174 title = {Toward a unified model of information security policy compliance.},
175}
176
177@article{sulistyowati2020comparative,
178 year = {2020},
179 pages = {225--230},
180 number = {4},
181 volume = {4},
182 journal = {JOIV: International Journal on Informatics Visualization},
183 author = {Sulistyowati, Diah and Handayani, Fitri and Suryanto, Yohan},
184 title = {Comparative Analysis and Design of Cybersecurity Maturity Assessment Methodology Using NIST CSF, COBIT, ISO/IEC 27002 and PCI DSS},
185}
186
187@inproceedings{roy2020high,
188 organization = {IEEE},
189 year = {2020},
190 pages = {1--3},
191 booktitle = {2020 National Conference on Emerging Trends on Sustainable Technology and Engineering Applications (NCETSTEA)},
192 author = {Roy, Prameet P},
193 title = {A High-Level Comparison between the NIST Cyber Security Framework and the ISO 27001 Information Security Standard},
194}
195
196@article{cohen1987computer,
197 publisher = {Elsevier},
198 year = {1987},
199 pages = {22--35},
200 number = {1},
201 volume = {6},
202 journal = {Computers \& security},
203 author = {Cohen, Fred},
204 title = {Computer viruses: theory and experiments},
205}
206
207@article{chess2004static,
208 publisher = {IEEE},
209 year = {2004},
210 pages = {76--79},
211 number = {6},
212 volume = {2},
213 journal = {IEEE security \& privacy},
214 author = {Chess, Brian and McGraw, Gary},
215 title = {Static analysis for security},
216}
217
218@article{schmidt2019quantifying,
219 year = {2019},
220 journal = {AAAI-19 Workshop on Network Interpretability for Deep learning},
221 author = {Schmidt, Philipp and Biessmann, Felix},
222 title = {Quantifying interpretability and trust in machine learning systems},
223}
224
225@article{doshi2017towards,
226 journal = {arXiv},
227 url = {https://arxiv.org/abs/1702.08608},
228 year = {2017},
229 author = {Finale Doshi-Velez and Been Kim},
230 title = {Towards A Rigorous Science of Interpretable Machine Learning},
231}
232
233@article{lipton2018mythos,
234 publisher = {ACM New York, NY, USA},
235 year = {2018},
236 pages = {31--57},
237 number = {3},
238 volume = {16},
239 journal = {Queue},
240 author = {Lipton, Zachary C},
241 title = {The Mythos of Model Interpretability: In machine learning, the concept of interpretability is both important and slippery.},
242}
243
244@book{molnar2020interpretable,
245 publisher = {Lulu. com},
246 year = {2020},
247 author = {Molnar, Christoph},
248 title = {Interpretable machine learning},
249}
250
251@article{carvalho2019machine,
252 publisher = {Multidisciplinary Digital Publishing Institute},
253 year = {2019},
254 pages = {832},
255 number = {8},
256 volume = {8},
257 journal = {Electronics},
258 author = {Carvalho, Diogo V and Pereira, Eduardo M and Cardoso, Jaime S},
259 title = {Machine learning interpretability: A survey on methods and metrics},
260}
261
262@inproceedings{ribeiro2016should,
263 year = {2016},
264 pages = {1135--1144},
265 booktitle = {Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining},
266 author = {Ribeiro, Marco Tulio and Singh, Sameer and Guestrin, Carlos},
267 title = {" Why should i trust you?" Explaining the predictions of any classifier},
268}
269
270@inproceedings{lundberg2017unified,
271 year = {2017},
272 pages = {4768--4777},
273 booktitle = {Proceedings of the 31st international conference on neural information processing systems},
274 author = {Lundberg, Scott M and Lee, Su-In},
275 title = {A unified approach to interpreting model predictions},
276}
277
278@article{wachter2017counterfactual,
279 publisher = {HeinOnline},
280 year = {2017},
281 pages = {841},
282 volume = {31},
283 journal = {Harv. JL \& Tech.},
284 author = {Wachter, Sandra and Mittelstadt, Brent and Russell, Chris},
285 title = {Counterfactual explanations without opening the black box: Automated decisions and the GDPR},
286}
287
288@book{pearl2018book,
289 publisher = {Basic books},
290 year = {2018},
291 author = {Pearl, Judea and Mackenzie, Dana},
292 title = {The book of why: the new science of cause and effect},
293}
294
295@inproceedings{agarwal2021towards,
296 year = {2021},
297 journal = {International Conference on Machine Learning},
298 author = {Agarwal, Sushant and Jabbari, Shahin and Agarwal, Chirag and Upadhyay, Sohini and Wu, Zhiwei Steven and Lakkaraju, Himabindu},
299 title = {Towards the Unification and Robustness of Perturbation and Gradient Based Explanations},
300}
301
302@article{ringer2020qed,
303 year = {2020},
304 journal = {arXiv preprint arXiv:2003.06458},
305 author = {Ringer, Talia and Palmskog, Karl and Sergey, Ilya and Gligoric, Milos and Tatlock, Zachary},
306 title = {QED at large: A survey of engineering of formally verified software},
307}
308
309@book{dowd2006art,
310 publisher = {Pearson Education},
311 year = {2006},
312 author = {Dowd, Mark and McDonald, John and Schuh, Justin},
313 title = {The art of software security assessment: Identifying and preventing software vulnerabilities},
314}
315
316@book{wysopal2006art,
317 publisher = {Pearson Education},
318 year = {2006},
319 author = {Wysopal, Chris and Nelson, Lucas and Dustin, Elfriede and Dai Zovi, Dino},
320 title = {The art of software security testing: identifying software security flaws},
321}
322
323@article{barocas2017fairness,
324 year = {2017},
325 pages = {2017},
326 volume = {1},
327 journal = {Nips tutorial},
328 author = {Barocas, Solon and Hardt, Moritz and Narayanan, Arvind},
329 title = {Fairness in machine learning},
330}
331
332@book{shostack2014threat,
333 publisher = {John Wiley \& Sons},
334 year = {2014},
335 author = {Shostack, Adam},
336 title = {Threat modeling: Designing for security},
337}
338
339@inproceedings{carlini2021extracting,
340 year = {2021},
341 pages = {2633--2650},
342 booktitle = {30th USENIX Security Symposium (USENIX Security 21)},
343 author = {Carlini, Nicholas and Tramer, Florian and Wallace, Eric and Jagielski, Matthew and Herbert-Voss, Ariel and Lee, Katherine and Roberts, Adam and Brown, Tom and Song, Dawn and Erlingsson, Ulfar and others},
344 title = {Extracting training data from large language models},
345}
346
347@inproceedings{choquette2021label,
348 organization = {PMLR},
349 year = {2021},
350 pages = {1964--1974},
351 booktitle = {International Conference on Machine Learning},
352 author = {Choquette-Choo, Christopher A and Tramer, Florian and Carlini, Nicholas and Papernot, Nicolas},
353 title = {Label-only membership inference attacks},
354}
355
356@article{kroger2021data,
357 year = {2021},
358 journal = {Available at SSRN 3887097},
359 author = {Kr{\"o}ger, Jacob Leon and Miceli, Milagros and M{\"u}ller, Florian},
360 title = {How Data Can Be Used Against People: A Classification of Personal Data Misuses},
361}
362
363@inproceedings{ahmed2021threats,
364 organization = {Springer},
365 year = {2021},
366 pages = {586--600},
367 booktitle = {International Conference on Advances in Cyber Security},
368 author = {Ahmed, Ibrahim M and Kashmoola, Manar Younis},
369 title = {Threats on Machine Learning Technique by Data Poisoning Attack: A Survey},
370}
371
372@inproceedings{zhang2020online,
373 organization = {PMLR},
374 year = {2020},
375 pages = {201--210},
376 booktitle = {Learning for Dynamics and Control},
377 author = {Zhang, Xuezhou and Zhu, Xiaojin and Lessard, Laurent},
378 title = {Online data poisoning attacks},
379}
380
381@inproceedings{birhane2022auditing,
382 year = {2022},
383 pages = {4051--4059},
384 booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision},
385 author = {Birhane, Abeba and Prabhu, Vinay Uday and Whaley, John},
386 title = {Auditing Saliency Cropping Algorithms},
387}
388
389@article{shepardson2021us,
390 journal = {Reuters},
391 note = {[Online; accessed 17-January-2022]},
392 author = {Shepardson, David and Jin, Hyunjoo},
393 year = {2021},
394 howpublished = {\url{https://www.reuters.com/business/autos-transportation/us-probing-fatal-tesla-crash-that-killed-pedestrian-2021-09-03/}},
395 title = {U.S. probing fatal Tesla crash that killed pedestrian},
396}
397
398@article{angwin2016machine,
399 year = {2016},
400 pages = {23},
401 journal = {Google Scholar},
402 author = {Angwin, Julia and Larson, Jeff and Mattu, Surya and Kirchner, Lauren},
403 title = {Machine bias: There’s software used across the country to predict future criminals. And it’s biased against blacks. ProPublica (2016)},
404}
405
406@article{anderson2018ember,
407 year = {2018},
408 journal = {arXiv preprint arXiv:1804.04637},
409 author = {Anderson, Hyrum S and Roth, Phil},
410 title = {Ember: an open dataset for training static pe malware machine learning models},
411}
412
413@misc{chowdhury2021introducing,
414 note = {[Online; accessed 17-January-2022]},
415 year = {2021},
416 howpublished = {\url{https://blog.twitter.com/engineering/en_us/topics/insights/2021/algorithmic-bias-bounty-challenge}},
417 author = {Chowdhury, Rumman and Williams, Jutta},
418 title = {Introducing Twitter's first algorithmic bias bounty challenge},
419}
420
421@inproceedings{kumar2020adversarial,
422 organization = {IEEE},
423 year = {2020},
424 pages = {69--75},
425 booktitle = {2020 IEEE Security and Privacy Workshops (SPW)},
426 author = {Kumar, Ram Shankar Siva and Nystr{\"o}m, Magnus and Lambert, John and Marshall, Andrew and Goertzel, Mario and Comissoneru, Andi and Swann, Matt and Xia, Sharon},
427 title = {Adversarial machine learning-industry perspectives},
428}
429
430@misc{pearce2021ai,
431 note = {[Online; accessed 19-January-2022]},
432 year = {2021},
433 howpublished = {\url{https://www.microsoft.com/security/blog/2021/05/03/ai-security-risk-assessment-using-counterfit/}},
434 author = {Pearce, Will and Kumar, Ram Shankar Siva},
435 title = {AI Security Risk Assessment Using Counterfit},
436}
437
438@misc{hussain2020privacyraven,
439 note = {[Online; accessed 19-January-2022]},
440 year = {2020},
441 howpublished = {\url{https://blog.trailofbits.com/2020/10/08/privacyraven-has-left-the-nest/}},
442 author = {Hussain, Suha},
443 title = {PrivacyRaven Has Left the Nest},
444}
445
446@misc{fingas2021twitter,
447 note = {[Online; accessed 19-January-2022]},
448 year = {2021},
449 howpublished = {\url{https://www.engadget.com/twitter-ai-bias-beauty-filters-133210055.html}},
450 author = {Fingas, Jon},
451 title = {Twitter's AI bounty program reveals bias toward young, pretty white people},
452}
453
454@misc{dastin2018amazon,
455 publisher = {Reuters London},
456 year = {2018},
457 author = {Dastin, Jeffrey},
458 title = {Amazon scraps secret AI recruiting tool that showed bias against women},
459}
460
461@misc{osullivan2021instagram,
462 note = {[Online; accessed 27-January-2022]},
463 publisher = {CNN Business},
464 howpublished = {\url{https://www.cnn.com/2021/10/04/tech/instagram-facebook-eating-disorders/index.html}},
465 year = {2021},
466 author = {O'Sullivan, Donie and Duffy, Clare and Jorgensen, Sarah},
467 title = {Instagram promoted pages glorifying eating disorders to teen accounts},
468}
469
470@article{eu2021civil,
471 note = {[Online; accessed 3-February-2022]},
472 howpublished = {\url{https://ec.europa.eu/info/law/better-regulation/have-your-say/initiatives/12979-Civil-liability-adapting-liability-rules-to-the-digital-age-and-artificial-intelligence/public-consultation_en}},
473 year = {2021},
474 author = {EU Commission and others},
475 title = {Civil liability – adapting liability rules to the digital age and artificial intelligence},
476}
477
478@inproceedings{hebert2018multicalibration,
479 organization = {PMLR},
480 year = {2018},
481 pages = {1939--1948},
482 booktitle = {International Conference on Machine Learning},
483 author = {H{\'e}bert-Johnson, Ursula and Kim, Michael and Reingold, Omer and Rothblum, Guy},
484 title = {Multicalibration: Calibration for the (computationally-identifiable) masses},
485}
486
487@article{zhao2021calibrating,
488 year = {2021},
489 volume = {34},
490 journal = {Advances in Neural Information Processing Systems},
491 author = {Zhao, Shengjia and Kim, Michael and Sahoo, Roshni and Ma, Tengyu and Ermon, Stefano},
492 title = {Calibrating Predictions to Decisions: A Novel Approach to Multi-Class Calibration},
493}
494
495@inproceedings{bansal2021does,
496 year = {2021},
497 pages = {1--16},
498 booktitle = {Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems},
499 author = {Bansal, Gagan and Wu, Tongshuang and Zhou, Joyce and Fok, Raymond and Nushi, Besmira and Kamar, Ece and Ribeiro, Marco Tulio and Weld, Daniel},
500 title = {Does the whole exceed its parts? the effect of ai explanations on complementary team performance},
501}
502
503@book{howard2006security,
504 publisher = {Microsoft Press Redmond},
505 year = {2006},
506 volume = {8},
507 author = {Howard, Michael and Lipner, Steve},
508 title = {The security development lifecycle},
509}
510
511@misc{crawford2017trouble,
512 url = {https://nips.cc/Conferences/2017/Schedule?showEvent=8742},
513 note = {Thirty-first Conference on Neural Information Processing Systems Keynote Presentation},
514 year = {2017},
515 author = {Crawford, Kate},
516 title = {The Trouble With Bias},
517}
518
519@article{gebru2021datasheets,
520 publisher = {ACM New York, NY, USA},
521 year = {2021},
522 pages = {86--92},
523 number = {12},
524 volume = {64},
525 journal = {Communications of the ACM},
526 author = {Gebru, Timnit and Morgenstern, Jamie and Vecchione, Briana and Vaughan, Jennifer Wortman and Wallach, Hanna and Iii, Hal Daum{\'e} and Crawford, Kate},
527 title = {Datasheets for datasets},
528}
529
530@inproceedings{mitchell2019model,
531 year = {2019},
532 pages = {220--229},
533 booktitle = {Proceedings of the conference on fairness, accountability, and transparency},
534 author = {Mitchell, Margaret and Wu, Simone and Zaldivar, Andrew and Barnes, Parker and Vasserman, Lucy and Hutchinson, Ben and Spitzer, Elena and Raji, Inioluwa Deborah and Gebru, Timnit},
535 title = {Model cards for model reporting},
536}
537
538@article{pitropakis2019taxonomy,
539 publisher = {Elsevier},
540 year = {2019},
541 pages = {100199},
542 volume = {34},
543 journal = {Computer Science Review},
544 author = {Pitropakis, Nikolaos and Panaousis, Emmanouil and Giannetsos, Thanassis and Anastasiadis, Eleftherios and Loukas, George},
545 title = {A taxonomy and survey of attacks against machine learning},
546}
547
548@article{al2019privacy,
549 publisher = {IEEE},
550 year = {2019},
551 pages = {49--58},
552 number = {2},
553 volume = {17},
554 journal = {IEEE Security \& Privacy},
555 author = {Al-Rubaie, Mohammad and Chang, J Morris},
556 title = {Privacy-preserving machine learning: Threats and solutions},
557}
558
559@inproceedings{selvaraju2017grad,
560 year = {2017},
561 pages = {618--626},
562 booktitle = {Proceedings of the IEEE international conference on computer vision},
563 author = {Selvaraju, Ramprasaath R and Cogswell, Michael and Das, Abhishek and Vedantam, Ramakrishna and Parikh, Devi and Batra, Dhruv},
564 title = {Grad-cam: Visual explanations from deep networks via gradient-based localization},
565}
566
567@article{szegedy2013intriguing,
568 year = {2013},
569 journal = {arXiv preprint arXiv:1312.6199},
570 author = {Szegedy, Christian and Zaremba, Wojciech and Sutskever, Ilya and Bruna, Joan and Erhan, Dumitru and Goodfellow, Ian and Fergus, Rob},
571 title = {Intriguing properties of neural networks},
572}
573
574@article{boucher2022bad,
575 year = {2022},
576 journal = {43rd IEEE Symposium on Security and Privacy},
577 author = {Boucher, Nicholas and Shumailov, Ilia and Anderson, Ross and Papernot, Nicolas},
578 title = {Bad characters: Imperceptible nlp attacks},
579}
580
581@article{povolny2020model,
582 year = {2020},
583 journal = {McAfee Advanced Threat Research},
584 author = {Povolny, Steve and Trivedi, Shivangee},
585 title = {Model hacking ADAS to pave safer roads for autonomous vehicles},
586}
587
588@inproceedings{kloft2007poisoning,
589 organization = {Citeseer},
590 year = {2007},
591 volume = {19},
592 booktitle = {NIPS Workshop on Machine Learning in Adversarial Environments for Computer Security},
593 author = {Kloft, Marius and Laskov, Pavel},
594 title = {A poisoning attack against online anomaly detection},
595}
596
597@inproceedings{shumailov2021sponge,
598 organization = {IEEE},
599 year = {2021},
600 pages = {212--231},
601 booktitle = {2021 IEEE European Symposium on Security and Privacy (EuroS\&P)},
602 author = {Shumailov, Ilia and Zhao, Yiren and Bates, Daniel and Papernot, Nicolas and Mullins, Robert and Anderson, Ross},
603 title = {Sponge examples: Energy-latency attacks on neural networks},
604}
605
606@inproceedings{shokri2017membership,
607 organization = {IEEE},
608 year = {2017},
609 pages = {3--18},
610 booktitle = {2017 IEEE symposium on security and privacy (SP)},
611 author = {Shokri, Reza and Stronati, Marco and Song, Congzheng and Shmatikov, Vitaly},
612 title = {Membership inference attacks against machine learning models},
613}
614
615@inproceedings{fredrikson2015model,
616 year = {2015},
617 pages = {1322--1333},
618 booktitle = {Proceedings of the 22nd ACM SIGSAC conference on computer and communications security},
619 author = {Fredrikson, Matt and Jha, Somesh and Ristenpart, Thomas},
620 title = {Model inversion attacks that exploit confidence information and basic countermeasures},
621}
622
623@inproceedings{kumar2020problems,
624 organization = {PMLR},
625 year = {2020},
626 pages = {5491--5500},
627 booktitle = {International Conference on Machine Learning},
628 author = {Kumar, I Elizabeth and Venkatasubramanian, Suresh and Scheidegger, Carlos and Friedler, Sorelle},
629 title = {Problems with Shapley-value-based explanations as feature importance measures},
630}
631
632@inproceedings{kaur2020interpreting,
633 year = {2020},
634 pages = {1--14},
635 booktitle = {Proceedings of the 2020 CHI conference on human factors in computing systems},
636 author = {Kaur, Harmanpreet and Nori, Harsha and Jenkins, Samuel and Caruana, Rich and Wallach, Hanna and Wortman Vaughan, Jennifer},
637 title = {Interpreting interpretability: understanding data scientists' use of interpretability tools for machine learning},
638}Attribution
arXiv:2203.02958v1
[cs.AI]
License: cc-by-4.0


