
- Papers
Papers is Alpha. This content is part of an effort to make research more accessible, and (most likely) has lost some details from the original. You can find the original paper here.
Introduction
This work is still in progress. Foundation models . The success of high-quality AI Generated Content (AIGC) is strongly correlated with the emergence and rapid advancement of large foundation models. These models, with their vast capacity, enable the rapid development of domain-specific models, which are commonly employed for the production of various types of content, including images, texts, audio, and video.
For instance, many text generators are built on the Generative Pre-trained Transformer (GPT)or its derivatives, such as GPT-2and GPT-3. Similarly, numerous text-to-image generators rely on vision-language models such as CLIPand OpenCLIP.
AIGC models . In recent years, generative modeling has made rapid advances and tremendous progress. OpenAI’s DALL·Ewas one of the first text-to-image models to capture widespread public attention. It is trained to generate digital images from text descriptions, referred to as “prompts”, using a dataset of text–image pairs. Its successor, DALL·E 2, which can generate more complex and realistic images, was unveiled in April 2022, followed by Stable Diffusion, which was publicly released in August 2022. Google, as a rival to OpenAI, presented two text-to-image models that can generate photorealistic images: the diffusion-based model Imagen, and the Pathways Autoregressive Text-to-Image model (Parti).
Diffusion models have been used not only for text-to-image tasks, but also for image-to-imageand text-to-video models, such as Runway, Make-A-Video, Imagen Video, and Phenaki. Stable Diffusion has been adapted for various applications, from medical imagingto music generation.

In addition to image and video generation, text generation is a popular generative domain, and OpenAI’s GPT-3is a notable example of a large language model (LLM). With a simple text prompt, GPT-3 can produce a piece of writing or an entire essay. It can also assist programmers in writing code. OpenAI has further developed GPT-3.5, an improved version which is better at generating complex text and poetry. Additionally, OpenAI launched ChatGPT, a 175 billion parameter natural language processing (NLP) model that can produce responses in a conversational style. This model combines two popular AI topics: chatbots and GPT-3.5. ChatGPT is a specific chatbot use case wherein the chatbot interacts with a GPT information source.
AIGC dispute . Despite its popularity, AIGC has raised concerns regarding privacy, bias, toxicity, misinformation, intellectual property (IP), and potential misuse of technology.
The recent release of ChatGPT has sparked much conversation surrounding its capabilities and potential risks, such as its ability to debug code or compose essays for university students. It is important to consider whether AIGC models result in unique creative works or simply replicate content from their training sets. Ideally, AIGC should produce original and distinct outputs, but the source and intellectual property rights of the training data are often unknown due to the use of uncurated web-scale data. Furthermore, the powerful memorization of large AIGC modelsposes a risk of reproducing data directly from the training data, which potentially violates privacy rights and raises legal concerns around copyright infringement and ownership. Most AIGC models rely on text encoders that are trained using large amounts of data from the internet, which may contain social biases, toxicity, and other limitations that are inherent in large language models.
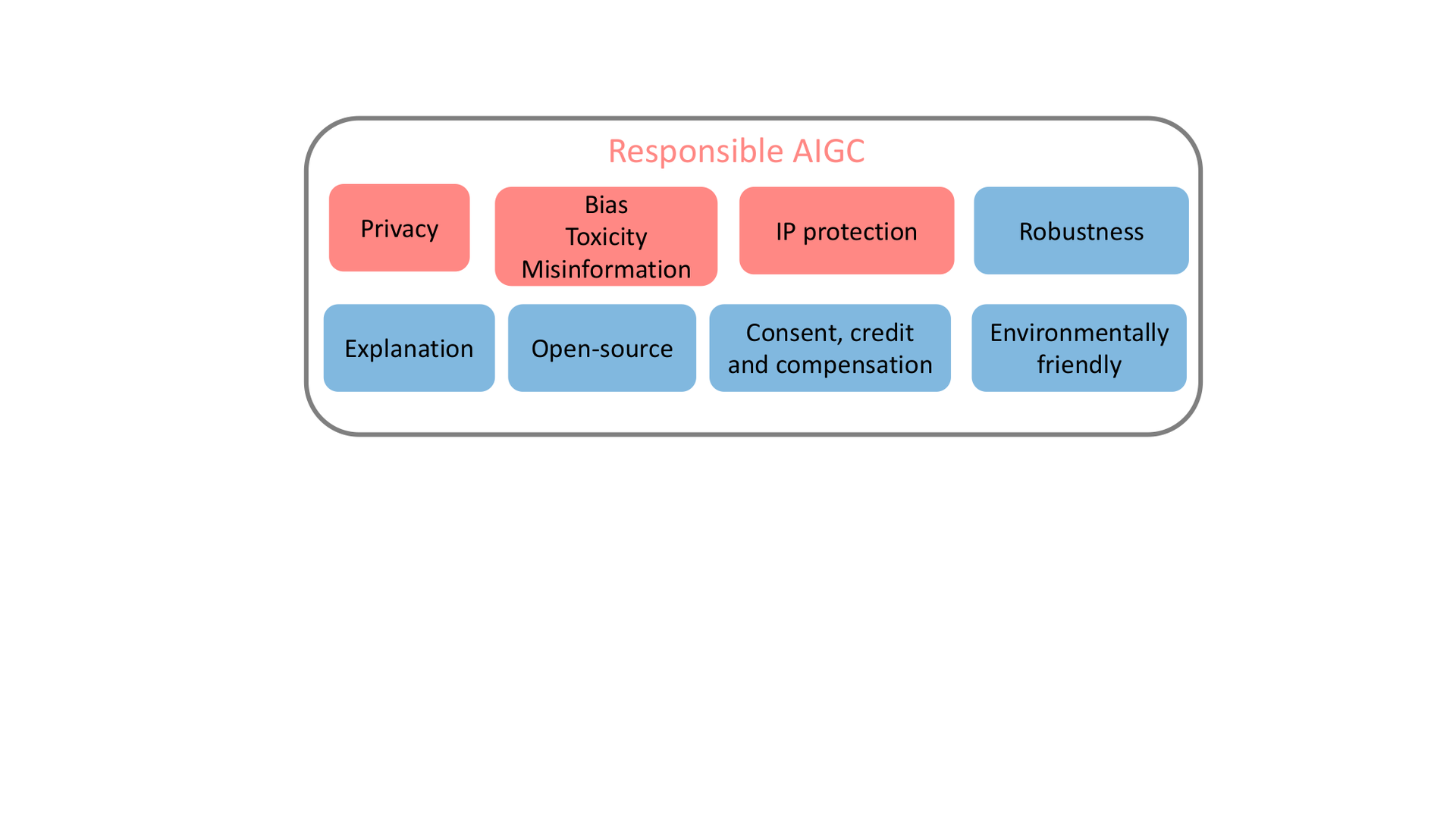
The essential components of responsible AIGC are summarized in Figure fig-responsible-aigc, with particular focus given to the first three parts (e.g., privacy, bias, toxicity, misinformation, and intellectual property), which are highlighted in black. The remaining risks associated with responsible AIGC are discussed in Section sec-discussion, and other underlying issues may require further investigation. Table tbl-aigc-models lists recent AIGC models and their associated issues related to privacy, bias, toxicity, misinformation, and IP, noting which models have taken proactive actions.
A summary of recent AIGC models and associated issues.
We use dots with different colors to indicate different modalities involved in the models: Text, Image, Video.
Table Label: tbl-aigc-models
Download PDF to view tablePrivacy
Privacy leakage in foundation models
Large foundation models are known to be vulnerable to privacy risks, and it is possible that AIGC models that build upon these models could also be subject to privacy leakage. Previous research has demonstrated that large language models such as GPT-2 can be vulnerable to privacy attacks, as attackers can generate sequences from the trained model and identify those memorized from the training set. Kandpalhave attributed the success of these privacy attacks to the presence of duplicated data in commonly used web-scraped training sets. It has been demonstrated that a sequence that appears multiple times in the training data is more likely to be generated than a sequence that occurred only once. This suggests that deduplication could be used as a potential countermeasure in privacy-sensitive applications.
Privacy leakage in generative models
The replication behavior in Generative Adversarial Networks (GANs) has been studied extensively. Due to the fact that AIGC models are trained on large-scale web-scraped data, the issue of overfitting and privacy leakage becomes especially relevant. For instance, Stable Diffusion memorized duplicate images in the training data. Somepallidemonstrated that Stable Diffusion blatantly copies images from its training data, and the generated images are simple combinations of the foreground and background objects of the training dataset (as shown in Figure fig-aigc-privacy). Moreover, the system occasionally displays the ability to reconstruct memories, producing objects that are semantically equivalent to the original without being identical in pixel form. The existence of such images raises concerns about data memorization and the ownership of diffusion images.
Similarly, recent research has shown that Google’s Imagen can leak photos of real people and copyrighted images. In Matthew Butterick’s recent litigation, he pointed out that because all visual information in the system is derived from copyrighted training images, the images produced are necessarily works derived from those training images, regardless of their outward appearance.
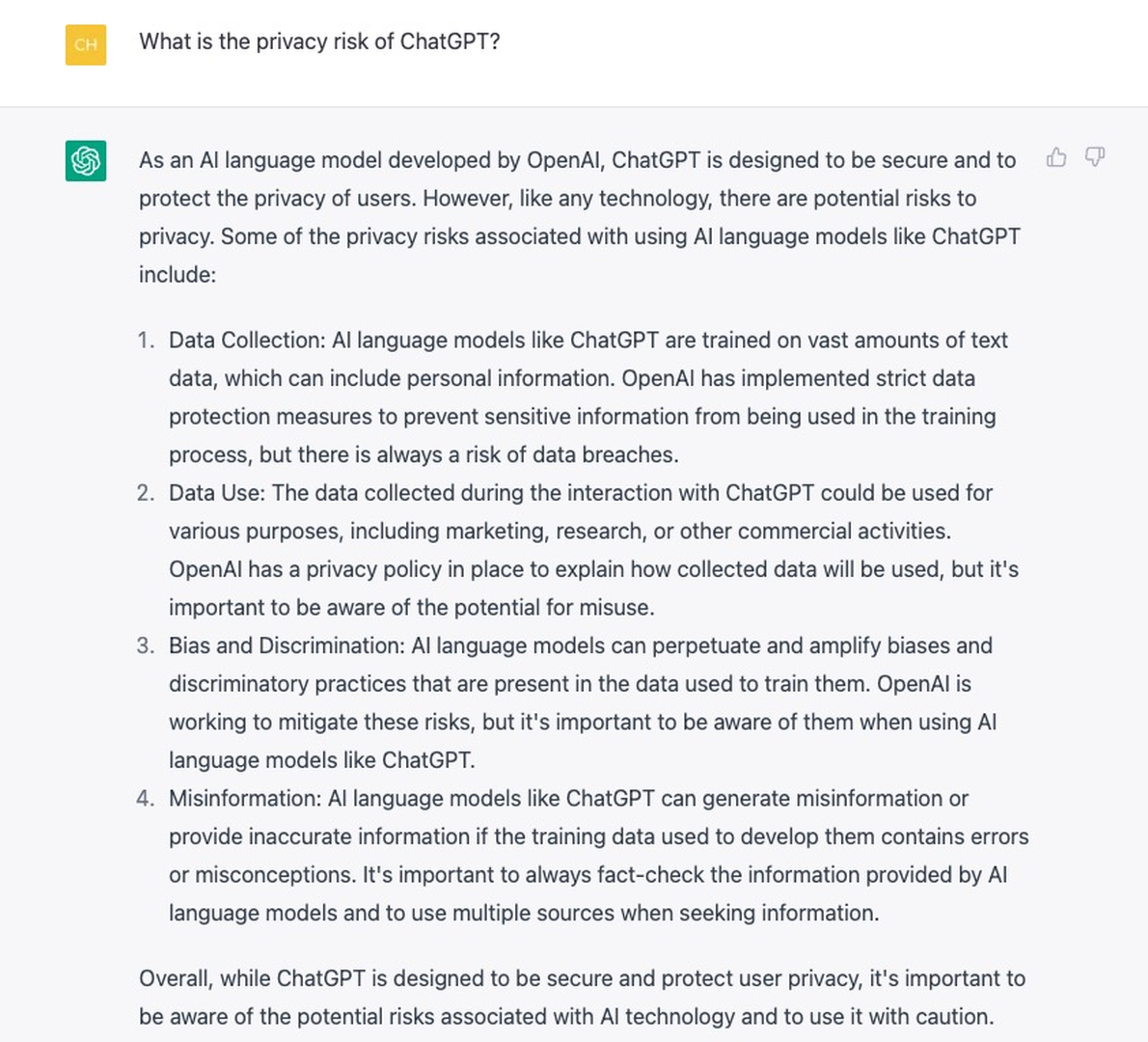
DALL·E 2 has also encountered similar problems. It can sometimes reproduce images from its training data rather than creating new ones. OpenAI found that this image regurgitation occurs due to images being replicated many times in the dataset. Similarly, ChatGPT itself recognizes its privacy leakage in its response, as illustrated by an example shown in Figure fig-chatgpt.
Privacy actions
Although a complete resolution to the privacy issues mentioned above has not been achieved, companies and researchers have taken proactive steps to address these issues, such as introducing warning messages and detecting replicated content.
At the industry level, Stability AI has recognized the limitations of Stable Diffusion, such as the potential for memorization of replicated images in the training data. To address this, they provide a websiteto support the identification of such memorized images. In addition, art company Spawning AI has created a website called “Have I Been Trained"to assist users in determining whether their photos or works have been used as AI training materials. OpenAI has taken steps to address privacy concerns by reducing data duplication through deduplication. Furthermore, companies such as Microsoft and Amazon have implemented measures to prevent employee breaches of confidentiality by banning the sharing of sensitive data with ChatGPT, given that this information could be utilized for training data for future versions of ChatGPT.
Academic researchers, such as Somepalli, have studied image retrieval frameworks to identify content duplication, while Dockhornhave proposed differentially private diffusion models to guarantee privacy in generative models.
Existing privacy measures are inadequate to meet the demands of privacy. It is essential to explore more reliable detection systems for data replication in generative models, and to further investigate memorization and generalization in deep learning systems.
Bias, toxicity, misinformation
Problematic datasets
Since the training data used in AI models are collected in the real world, they can unintentionally reinforce harmful stereotypes, exclude or marginalize certain groups, and contain toxic data sources, which can incite hate or violence and offend individuals. For example, the LAION dataset, which is used to train diffusion models, has been criticized for containing problematic content related to social stereotyping, pornography, racist slurs, and violence.
Although some AIGC models like Imagentry to filter out undesirable data, such as pornographic imagery and toxic language, the filtered data can still contain sexually explicit or violent content. Moreover, recent researchhas pointed out that these unfiltered datasets utilized for training frequently encompass social biases, repressive perspectives, and derogatory connections towards underrepresented communities. Google’s Imagen Videois trained on a combination of the LAION-400M image-text dataset and their internal dataset, and Google is concerned that its Imagen tool could be used to generate harmful content. However, the dataset still inherits social biases and stereotypes that are difficult to remove.
Problematic AIGC models
Models trained, learned, or fine-tuned on the aforementioned problematic datasets without mitigation strategies can inherit harmful stereotypes, social biases, and toxicity, leading to unfair discrimination and harm to certain social groups. Furthermore, there is a risk of misinformation when models provide inaccurate or false answers.
Stable Diffusion v1 was trained primarily on the LAION-2B data set, which only contains images with English descriptions. As a result, the model was biased towards white, Western cultures, and prompts in other languages may not be adequately represented. Follow-up versions of the Stable Diffusion model were fine-tuned on filtered versions of the LAION dataset, but the bias issue still occurs. Similarly, DALLA·E and DALLA·E 2 have been found to exhibit negative stereotypes against minoritized groups. Google’s Imagenalso encodes several social biases and stereotypes, such as generating images of people with lighter skin tones and aligning with Western gender stereotypes. These biases can lead to unfair discrimination and harm to certain social groups. Furthermore, even when generating non-human images, Imagen has been shown to encode social and cultural biases. Due to these issues, most companies decided not to make their AIGC models available to the public. Beyond above issues, there is also a risk of misinformation when AIGC models provide inaccurate or false answers. For example, the content generated by GPT and its derivatives may appear to be accurate and authoritative, but it could be completely inaccurate. Therefore, it can be used for misleading purposes in schools, laws, medical domains, weather forecasting, or anywhere else. For example, the answer on medical dosages that ChatGPT provides could be inaccurate or incomplete, potentially leading to the user taking dangerous or even life-threatening actions. Prompted misinformation on traffic laws could cause accidents and even death if drivers follow the false traffic rules. ChatGPT also exhibits verbosity and overuse of certain phrases. For instance, it repeatedly states that it is a language model trained by OpenAI. These issues are due to biases inherent in training data, as trainers tend to prefer longer answers that appear more comprehensive.
To illustrate the inherent bias in AIGC models, we tested a toy example on Stable Diffusion v2.1. As shown in Figure fig-unfair, images generated with the prompt “Three engineers running on the grassland” were all male and none of them belong to the neglected racial minorities, indicating a lack of diversity in the generated images.









Bias, toxicity, misinformation mitigation
The quality of the content generated by language models is inextricably linked to the quality of the training corpora. OpenAI took extra measures to ensure that any violent or sexual content was removed from the training data for DALLA·E 2 by carefully filtering the original training dataset. However, filtering can introduce biases into the training data that can then be propagated to the downstream models. To address this issue, OpenAI developed pre-training techniques to mitigate the consequent filter-induced biases.
To ensure that AI-driven models reflect the current state of society, it is essential to regularly update the training corpora used in AIGC models with the most recent information. This will help prevent information lag and ensure that the models remain updated, relevant, and beneficial to society. Recent researchhas shown that transformer models cannot accurately predict data that did not fall into training data period. This is because test data and training data come from different periods, and increasing model size does not improve performance. It is thus essential to collect new training data and update the model regularly.
One noticeable point is that while biases and stereotypes can be reduced in the source datasets, they can still be propagated or even exacerbated during the training and development of AIGC models. Therefore, it is crucial to evaluate the existence of bias, toxicity, and misinformation throughout the entire lifecycle of model training and development, rather than staying solely at the data source level. Additionally, there is a challenge in defining a truly fair and non-toxic dataset. The extent and nature of these issues within AIGC models have not yet been comprehensively investigated.
IP Protection
As AIGC continues to advance in sophistication and popularity, it raises questions about the origin of content for copyright purposes and whether AI-generated content should be entitled to the same intellectual property protections as content created by humans.
Difficulty of IP infringement detection
Traditional understanding of copyright. Copyright law generally protects original works of authorship that are created by human authors and are fixed in a tangible form. For a work to be eligible for copyright protection, it needs to be expressed in a tangible form, either physical or digital, such as a book, painting, or computer file.
Difficulty of copyright definition in AIGC. The ownership and protection of generated content have raised a significant amount of concern and debate. It remains unclear whether such generated content should be considered original works eligible for copyright protection under current laws.
There are many different notions of replication from AIGC. Somepalligave an (informal) definition as follows: An image is considered to contain replicated content if it includes an object that is identical to an object in a training image, regardless of minor variations in appearance resulting from data augmentation, whether the object is in the foreground or background .
In fact, addressing AI copyright issues is a complex task that involves several factors, including: (1) unclear regulations on data collection, usage, rights confirmation, and commercial use of data; (2) the need for a fair benefit distribution mechanism for contributors; (3) the lack of a unified legal understanding of AIGC copyright worldwide, with disputes over ownership still unresolved; and (4) difficulties in identifying all original works used to train AIGC models, as these models can generate an unlimited amount of content, making it impossible to test all of it.
IP infringement examples
There is a risk of copyright infringement with the generated content if it copies existing works, whether intentionally or not, raising legal questions about IP infringement.
In November 2022, Matthew Butterick filed a class action lawsuit against Microsoft’s subsidiary GitHub, accusing that their product Copilot, a code-generating service, violated copyright law. The lawsuit centers around Copilot’s illegal use of licensed code sections from the internet without attribution. Texas A&M professor Tim Davis also provided examples of his code being copied verbatim by Copilot. Although Microsoft and OpenAI have acknowledged that Copilot is trained on open-source software in public GitHub repositories, Microsoft claims that the output of Copilot is merely a series of code “suggestions" and does not claim any rights in these suggestions. Microsoft also does not make any guarantees regarding the correctness, security, or copyright of the generated code.
For text-to-image models, several generative models have faced accusations of infringing on the creative work of artists. Somepallipresented evidence suggesting that art-generating AI systems, such as Stable Diffusion, may copy from the data on which they were trained. While Stable Diffusion disclaims any ownership of generated images and allows users to use them freely as long as the image content is legal and non-harmful, this freedom raises questions about ownership ethics. Generative models like Stable Diffusion are trained on billions of images from the Internet without the approval of the IP holders, which some argue is a violation of their rights.
IP problem mitigation
To mitigate IP concerns, many AIGC companies have started implementing measures to accommodate content creators. Midjourney, for instance, has added a DMCA takedown policy to its terms of service, allowing artists to request the removal of their work from the dataset if they suspect copyright infringement. Similarly, Stability AI plans to offer artists the option of excluding themselves from future versions of Stable Diffusion.
Furthermore, text watermarks, which have previously been used to protect the IP of language generation APIs, can also be used to identify if these AIGC tools have utilized samples from other sources without permission. This is evident in Stable Diffusion, which has generated images with the Getty Images’ watermark on them. In light of the growing popularity of AIGC, the need for watermarking is becoming increasingly pressing. OpenAI is developing a watermark to identify text generated by its GPT model. It could be a valuable tool for educators and professors to detect plagiarism in assignments generated with such tools. Google has already applied a Parti watermark to all images it releases. John Kirchenbauerproposed a watermark to detect whether the text is generated by an AI model. Still, they only tested it on the smaller open-source language model OPT-6.7B from Meta, leaving its performance on the larger and more widely used ChatGPT model unknown.
In addition to watermarking, OpenAI has released a classifier that can distinguish between text generated by AI and that written by humans. This tool has the potential to be extremely useful. However, it should not be relied exclusively on for critical decisions.
In general, the emergence of AIGC presents significant IP concerns and challenges that demand immediate attention. It is essential for technologists, lawyers, and policymakers to recognize these issues and work together to ensure that the intellectual property rights of human creators are protected.
Discussion
Concerns on misuse . Evaluating and mitigating risks associated with AIGC models and their potential harms is a complex and interdisciplinary challenge. In addition, it is important to tackle the problematic aspects of data encoded and propagated through these models, including hidden, harmful, and violent content. In fact, with the ability to generate highly realistic images and text that are difficult to distinguish from human-generated content, these models can be used for malicious purposes such as spreading fake news, hoaxes, and harassment. The foundation models that power AIGC have made it easier and cheaper to create deepfakes that are close to the original, posing additional risks and concerns.
In fact, many AIGC models are still far from satisfactory. Some models have gained negative reputations for producing useless, biased, or harmful information. For example, on the 4chan online forum, there are numerous discussions about images of naked celebrities and other forms of fake pornographic content generated by Stable Diffusion. The misuse of these technologies could lead to the spread of misinformation, harm the reputations of individuals, or even break the law.
The potential negative impact of ChatGPT on education is significant, as students could use it to write homework or solve math problems, thus compromising the integrity of their work. Moreover, as ChatGPT is a chatbot, it lacks the necessary emotional connection that a human teacher can provide, which could lead to a diminished learning experience. In light of these concerns, New York City public schools have recently banned the use of ChatGPT. Stack Overflow, a Q&A platform for coders and programmers, temporarily prohibited the sharing of ChatGPT information, acknowledging its potential to cause significant harm to the site and users who rely on it for accurate answers. Writing and editing tools that rely on ChatGPT also face the risk of losing customers if they inadvertently introduce errors into the output.
Overall, the potential misuse of AIGC poses a threat to the creative industries. Therefore, it is crucial to use AIGC only in situations where the risk can be managed or corrected. To mitigate risks, it is also necessary to include governance mechanisms for AIGC models as soon as possible, such as establishing legal regulations.
Vulnerability to poisoning attack . AIGC models have made it easier to generate synthetic data, but it would be a disaster if the foundational model is compromised. For example, a diffusion model with a hidden “backdoor" could carry out malicious actions when it encounters a specific trigger pattern during data generation. This Trojan effect could cause catastrophic damage to downstream applications that depend on the compromised diffusion model. Unfortunately, research on the robustness of foundational and fine-tuned AIGC models is still limited.
What about commercial usage: a vicious competition? Will AIGC replace humans and become a roadblock to human creativity?
Many AIGC models are being utilized for commercial art and graphic design. For example, PromptBaseis an early marketplace for DALL·E, Midjourney, Stable Diffusion & GPT-3 prompts.
Microsoft is using DALL-E 2 to power a generative art feature that will be available in Microsoft Edge. Microsoft and OpenAI are collaborating on ChatGPT-Powered Bing. Moreover, Microsoft is planning to integrate OpenAI’s AIGC models into Word, PowerPoint, Outlook, and other applications to allow users to automatically generate text using simple prompts. While using the generated works for profit or commercial purposes is not recommended, there are no mandatory legal restrictions at this stage.
The use of AIGC has faced criticism from those who fear that it will replace human jobs. Insider has listed several jobs that could potentially be replaced by ChatGPT, including coders, data analysts, journalists, legal assistants, traders, accountants, etc. Some artists worry that the wide use of image generation tools such as Stable Diffusion could eventually make human artists, photographers, models, cinematographers, and actors commercially uncompetitive. For example, the images generated by Stable Diffusion can be sold on the market. This creates direct competition and poses a significant threat to creators, such as writers, artists, and programmers, who could suffer permanent damage to their businesses. Since Stable Diffusion can produce an unlimited number of infringing images, this threat is even more significant. However, David Holz, the founder of Midjourney, views artists as customers rather than competitors. Artists can use Midjourney to quickly prototype artistic concepts to show to clients before starting work themselves.
As AIGC models become more widespread, people may become too dependent on instant answers and less willing to think critically on their own, which could ultimately destroy human creativity and increase the risk of AI exerting control over humans. Overreliance on AIGC models could create opportunities for malicious attackers to exploit user trust and access their private information.
Explainable AIGC . The black-box nature of foundation models can lead to unsatisfactory results. It is frequently challenging to determine the information used to generate a model’s output, which makes biases occur within datasets. An explanation is a critical element in comprehending how and why AIGC creates these problems.
For example, social and cultural bias is introduced and potentially amplified at many stages of system development and deployment. However, how the biases are propagated through these models remain unclear. While deduplication can be an effective method of preventing memorization, it does not completely explain why or how models like DALL·E 2 memorize training data.
To address these issues, comprehensive explanations are necessary to trade-off between risks and benefits for specific use cases of AIGC.
Responsible Open-sourcing . The responsible open-sourcing of code is a matter of great concern due to the aforementioned risks. Most companies chose not to release their models or source code before solving these risks. OpenAI has been criticized for not sharing more about how the most recent GPT-4 was created. Stable Diffusion is the only AI art generator that provides its source code and pretrained model (weights) available. The risk is that anyone can use Stable Diffusionfor free, even for commercial or malicious purposes.
As the code and models behind AIGC are not transparent to the public, and their downstream applications are diverse and may have complex societal impacts, it is challenging to determine the potential harms they may cause. Therefore, the need for responsible open-sourcing becomes critical in determining whether the benefits of AIGC outweigh its potential risks in specific use cases.
User feedback. Gathering user feedback is also an essential element of responsible AIGC. Companies such as OpenAI actively seek feedback from users to identify harmful outputs that could arise in real-world scenarios, as well as to uncover and mitigate novel risks. Actually, GPT-4 had incorporated an additional safety reward signal during Reinforcement Learning from Human Feedback (RLHF) training to reduce harmful outputs by training the model to refuse requests for such content. By involving users in the feedback loop, AIGC developers can better understand the potential consequences of their models and take corrective actions to minimize any negative impacts.
Consent, credit, and compensation . Many AIGC models are trained on datasets without obtaining consent or providing credit or compensation to the original data contributors. For example, Simon Willison and Andy Baio found that a large number of images in LAION were copied from DeviantArt and used to train Stable Diffusion. This results in data contributors’ works being learned by AI models and recreated by other users for profit, without their knowledge or permission. This practice damages the interests of the original data contributors. To avoid negative impacts, AIGC companies should obtain consent from data contributors and take proactive measures before training their models on original or augmented works. Failure to do so could result in lawsuits against AIGC. Therefore, AIGC companies must ensure that data collection and model training are conducted in an ethical and responsible manner.
A potential solution to the issue of using creators’ works for AI training is to notify them from the beginning and give them the option to benefit from subsequent creations based on their works generated by the model. Additionally, creators who give their consent for their data to be used can be rewarded based on how their creations contribute to AIGC each time the tool is queried. By incentivizing creators, companies can encourage creators to contribute more and accelerate the development of AIGC. For example, a more user-friendly version of Copilot could allow voluntary participation or compensate coders for contributing to the training corpus.
Environment impact. The massive size of AIGC models, which can have billions or trillions of parameters, results in high environmental costs for both model training and operation. For example, GPT-3 has 175 billion parameters and requires significant computing resources to train. Narayananestimated that training GPT-3 with A100s would require 1,024 GPUs, 34 days, and cost 4.6 million dollars, with an expected energy consumption of 936 MWh. This raises important questions about how to reduce the energy consumption and carbon emission of AIGC models.
The upcoming GPT-4, with even more parameters than its predecessor, is expected to leave a more significant carbon emission. Failing to take appropriate steps to mitigate the substantial energy costs of AIGC could lead to irreparable damage to our planet. It is crucial to address these concerns and explore sustainable alternatives.
Fairness of benefits. It is important to recognize that AIGC models may have varying impacts on different groups of people depending on their environmental and individual abilities, which could further exacerbate global inequities. Addressing the issue of how to fairly distribute the benefits of AIGC models is an area that requires further exploration and attention.
Conflict among multiple goals . It is critical to ensure that the mitigation of one risk does not exacerbate another. For example, approaches to mitigate the use of toxic language in language models can introduce biases in model predictions against marginalized communities. Therefore, it is essential to explore effective mitigation strategies that can simultaneously address multiple risks.
Conclusion
Although AIGC is still in its infancy, it is rapidly expanding and will remain active for the foreseeable future. Current AIGC technologies only scratch the surface of what AI can create in the field of art. While AIGC offers many opportunities, it also carries significant risks. To acquire a thorough comprehension of these risks, we provide a synopsis of both current and potential threats in recent AIGC models, so that both the users and companies can be well aware of these risks, and make the appropriate actions to mitigate them.
In order to promote responsible usage of AIGC tools and mitigate associated risks, we propose several steps that companies and users can take. It is important for companies to incorporate responsible AI practices throughout all AIGC-related projects. Additionally, proactive measures should be taken to mitigate potential risks in data sources, models, and pre/post-processing steps. Without proper safeguards, AIGC development may face significant challenges and regulatory hurdles. Note that this vision paper is not exhaustive, and it is essential for the wider community to contribute to the understanding and implementation of responsible AIGC. To facilitate this, it is necessary to build comprehensive benchmarks for measuring and evaluating the risks associated with different AIGC models.
Bibliography
1@inproceedings{ramesh2021zero,
2 organization = {PMLR},
3 year = {2021},
4 pages = {8821--8831},
5 booktitle = {International Conference on Machine Learning},
6 author = {Ramesh, Aditya and Pavlov, Mikhail and Goh, Gabriel and Gray, Scott and Voss, Chelsea and Radford, Alec and Chen, Mark and Sutskever, Ilya},
7 title = {Zero-shot text-to-image generation},
8}
9
10@article{somepalli2022diffusion,
11 year = {2022},
12 journal = {arXiv preprint arXiv:2212.03860},
13 author = {Somepalli, Gowthami and Singla, Vasu and Goldblum, Micah and Geiping, Jonas and Goldstein, Tom},
14 title = {Diffusion Art or Digital Forgery? Investigating Data Replication in Diffusion Models},
15}
16
17@article{agostinelli2023musiclm,
18 journal = {arXiv preprint arXiv: Arxiv-2301.11325},
19 year = {2023},
20 author = {Andrea Agostinelli and Timo I. Denk and Zalán Borsos and Jesse Engel and Mauro Verzetti and Antoine Caillon and Qingqing Huang and Aren Jansen and Adam Roberts and Marco Tagliasacchi and Matt Sharifi and Neil Zeghidour and Christian Frank},
21 title = {MusicLM: Generating Music From Text},
22}
23
24@article{ramesh2022hierarchical,
25 year = {2022},
26 journal = {arXiv preprint arXiv:2204.06125},
27 author = {Ramesh, Aditya and Dhariwal, Prafulla and Nichol, Alex and Chu, Casey and Chen, Mark},
28 title = {Hierarchical text-conditional image generation with clip latents},
29}
30
31@inproceedings{rombach2022high,
32 year = {2022},
33 pages = {10684--10695},
34 booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
35 author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj{\"o}rn},
36 title = {High-resolution image synthesis with latent diffusion models},
37}
38
39@article{birhane2021multimodal,
40 year = {2021},
41 journal = {arXiv preprint arXiv:2110.01963},
42 author = {Birhane, Abeba and Prabhu, Vinay Uday and Kahembwe, Emmanuel},
43 title = {Multimodal datasets: misogyny, pornography, and malignant stereotypes},
44}
45
46@article{brown2020language,
47 year = {2020},
48 pages = {1877--1901},
49 volume = {33},
50 journal = {Advances in neural information processing systems},
51 author = {Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and others},
52 title = {Language models are few-shot learners},
53}
54
55@article{lyu2022privacy,
56 publisher = {IEEE},
57 year = {2022},
58 journal = {IEEE transactions on neural networks and learning systems},
59 author = {Lyu, Lingjuan and Yu, Han and Ma, Xingjun and Chen, Chen and Sun, Lichao and Zhao, Jun and Yang, Qiang and Philip, S Yu},
60 title = {Privacy and robustness in federated learning: Attacks and defenses},
61}
62
63@article{carlini2022quantifying,
64 year = {2022},
65 journal = {arXiv preprint arXiv:2202.07646},
66 author = {Carlini, Nicholas and Ippolito, Daphne and Jagielski, Matthew and Lee, Katherine and Tramer, Florian and Zhang, Chiyuan},
67 title = {Quantifying memorization across neural language models},
68}
69
70@inproceedings{carlini2021extracting,
71 year = {2021},
72 pages = {2633--2650},
73 booktitle = {30th USENIX Security Symposium (USENIX Security 21)},
74 author = {Carlini, Nicholas and Tramer, Florian and Wallace, Eric and Jagielski, Matthew and Herbert-Voss, Ariel and Lee, Katherine and Roberts, Adam and Brown, Tom and Song, Dawn and Erlingsson, Ulfar and others},
75 title = {Extracting training data from large language models},
76}
77
78@inproceedings{he2022protecting,
79 organization = {AAAI},
80 year = {2022},
81 author = {He, Xuanli and Xu, Qiongkai and Lyu, Lingjuan and Wu, Fangzhao and Wang, Chenguang},
82 title = {Protecting intellectual property of language generation apis with lexical watermark},
83}
84
85@inproceedings{he2022cater,
86 year = {2022},
87 organization = {Advances in Neural Information Processing Systems},
88 author = {He, Xuanli and Xu, Qiongkai and Zeng, Yi and Lyu, Lingjuan and Wu, Fangzhao and Li, Jiwei and Jia, Ruoxi},
89 title = {CATER: Intellectual Property Protection on Text Generation APIs via Conditional Watermarks},
90}
91
92@inproceedings{meehan2020non,
93 year = {2020},
94 booktitle = {International Conference on Artificial Intelligence and Statistics},
95 author = {Meehan, Casey and Chaudhuri, Kamalika and Dasgupta, Sanjoy},
96 title = {A non-parametric test to detect data-copying in generative models},
97}
98
99@inproceedings{feng2021gans,
100 year = {2021},
101 pages = {6701--6710},
102 booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision},
103 author = {Feng, Qianli and Guo, Chenqi and Benitez-Quiroz, Fabian and Martinez, Aleix M},
104 title = {When do GANs replicate? On the choice of dataset size},
105}
106
107@article{webster2021person,
108 year = {2021},
109 journal = {arXiv preprint arXiv:2107.06018},
110 author = {Webster, Ryan and Rabin, Julien and Simon, Loic and Jurie, Frederic},
111 title = {This person (probably) exists. identity membership attacks against gan generated faces},
112}
113
114@inproceedings{wortsman2022robust,
115 year = {2022},
116 pages = {7959--7971},
117 booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
118 author = {Wortsman, Mitchell and Ilharco, Gabriel and Kim, Jong Wook and Li, Mike and Kornblith, Simon and Roelofs, Rebecca and Lopes, Raphael Gontijo and Hajishirzi, Hannaneh and Farhadi, Ali and Namkoong, Hongseok and others},
119 title = {Robust fine-tuning of zero-shot models},
120}
121
122@article{schuhmann2021laion,
123 year = {2021},
124 journal = {arXiv preprint arXiv:2111.02114},
125 author = {Schuhmann, Christoph and Vencu, Richard and Beaumont, Romain and Kaczmarczyk, Robert and Mullis, Clayton and Katta, Aarush and Coombes, Theo and Jitsev, Jenia and Komatsuzaki, Aran},
126 title = {Laion-400m: Open dataset of clip-filtered 400 million image-text pairs},
127}
128
129@article{kandpal2022deduplicating,
130 year = {2022},
131 journal = {arXiv preprint arXiv:2202.06539},
132 author = {Kandpal, Nikhil and Wallace, Eric and Raffel, Colin},
133 title = {Deduplicating training data mitigates privacy risks in language models},
134}
135
136@article{chou2022backdoor,
137 year = {2022},
138 journal = {arXiv preprint arXiv:2212.05400},
139 author = {Chou, Sheng-Yen and Chen, Pin-Yu and Ho, Tsung-Yi},
140 title = {How to Backdoor Diffusion Models?},
141}
142
143@article{saharia2022photorealistic,
144 year = {2022},
145 journal = {arXiv preprint arXiv:2205.11487},
146 author = {Saharia, Chitwan and Chan, William and Saxena, Saurabh and Li, Lala and Whang, Jay and Denton, Emily and Ghasemipour, Seyed Kamyar Seyed and Ayan, Burcu Karagol and Mahdavi, S Sara and Lopes, Rapha Gontijo and others},
147 title = {Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding},
148}
149
150@misc{An-AI-url,
151 howpublished = {\url{https://www.vice.com/en/article/bvmvqm/an-ai-generated-artwork-won-first-place-at-a-state-fair-fine-arts-competition-and-artists-are-pissed}},
152 title = {An AI-Generated Artwork Won First Place at a State Fair Fine Arts Competition, and Artists Are Pissed},
153 author = {Gault, Matthew},
154}
155
156@article{dockhorn2022differentially,
157 year = {2022},
158 journal = {arXiv preprint arXiv:2210.09929},
159 author = {Dockhorn, Tim and Cao, Tianshi and Vahdat, Arash and Kreis, Karsten},
160 title = {Differentially private diffusion models},
161}
162
163@article{chambon2022adapting,
164 year = {2022},
165 journal = {arXiv preprint arXiv:2210.04133},
166 author = {Chambon, Pierre and Bluethgen, Christian and Langlotz, Curtis P and Chaudhari, Akshay},
167 title = {Adapting pretrained vision-language foundational models to medical imaging domains},
168}
169
170@misc{this-artist-url,
171 year = {2022},
172 howpublished = {\url{https://www.technologyreview.com/2022/09/16/1059598/this-artist-is-dominating-ai-generated-art-and-hes-not-happy-about-it/}},
173 title = {This artist is dominating AI-generated art. And he’s not happy about it.},
174 author = {Heikkilä, Melissa},
175}
176
177@article{singer2022make,
178 year = {2022},
179 journal = {arXiv preprint arXiv:2209.14792},
180 author = {Singer, Uriel and Polyak, Adam and Hayes, Thomas and Yin, Xi and An, Jie and Zhang, Songyang and Hu, Qiyuan and Yang, Harry and Ashual, Oron and Gafni, Oran and others},
181 title = {Make-a-video: Text-to-video generation without text-video data},
182}
183
184@article{ho2022imagen,
185 year = {2022},
186 journal = {arXiv preprint arXiv:2210.02303},
187 author = {Ho, Jonathan and Chan, William and Saharia, Chitwan and Whang, Jay and Gao, Ruiqi and Gritsenko, Alexey and Kingma, Diederik P and Poole, Ben and Norouzi, Mohammad and Fleet, David J and others},
188 title = {Imagen video: High definition video generation with diffusion models},
189}
190
191@article{yu2022scaling,
192 year = {2022},
193 journal = {arXiv preprint arXiv:2206.10789},
194 author = {Yu, Jiahui and Xu, Yuanzhong and Koh, Jing Yu and Luong, Thang and Baid, Gunjan and Wang, Zirui and Vasudevan, Vijay and Ku, Alexander and Yang, Yinfei and Ayan, Burcu Karagol and others},
195 title = {Scaling autoregressive models for content-rich text-to-image generation},
196}
197
198@article{ding2021cogview,
199 year = {2021},
200 pages = {19822--19835},
201 volume = {34},
202 journal = {Advances in Neural Information Processing Systems},
203 author = {Ding, Ming and Yang, Zhuoyi and Hong, Wenyi and Zheng, Wendi and Zhou, Chang and Yin, Da and Lin, Junyang and Zou, Xu and Shao, Zhou and Yang, Hongxia and others},
204 title = {Cogview: Mastering text-to-image generation via transformers},
205}
206
207@inproceedings{sohl2015deep,
208 organization = {PMLR},
209 year = {2015},
210 pages = {2256--2265},
211 booktitle = {International Conference on Machine Learning},
212 author = {Sohl-Dickstein, Jascha and Weiss, Eric and Maheswaranathan, Niru and Ganguli, Surya},
213 title = {Deep unsupervised learning using nonequilibrium thermodynamics},
214}
215
216@article{ho2020denoising,
217 year = {2020},
218 pages = {6840--6851},
219 volume = {33},
220 journal = {Advances in Neural Information Processing Systems},
221 author = {Ho, Jonathan and Jain, Ajay and Abbeel, Pieter},
222 title = {Denoising diffusion probabilistic models},
223}
224
225@inproceedings{nichol2021improved,
226 organization = {PMLR},
227 year = {2021},
228 pages = {8162--8171},
229 booktitle = {International Conference on Machine Learning},
230 author = {Nichol, Alexander Quinn and Dhariwal, Prafulla},
231 title = {Improved denoising diffusion probabilistic models},
232}
233
234@article{dhariwal2021diffusion,
235 year = {2021},
236 pages = {8780--8794},
237 volume = {34},
238 journal = {Advances in Neural Information Processing Systems},
239 author = {Dhariwal, Prafulla and Nichol, Alexander},
240 title = {Diffusion models beat gans on image synthesis},
241}
242
243@article{saharia2022image,
244 publisher = {IEEE},
245 year = {2022},
246 journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence},
247 author = {Saharia, Chitwan and Ho, Jonathan and Chan, William and Salimans, Tim and Fleet, David J and Norouzi, Mohammad},
248 title = {Image super-resolution via iterative refinement},
249}
250
251@inproceedings{whang2022deblurring,
252 year = {2022},
253 pages = {16293--16303},
254 booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
255 author = {Whang, Jay and Delbracio, Mauricio and Talebi, Hossein and Saharia, Chitwan and Dimakis, Alexandros G and Milanfar, Peyman},
256 title = {Deblurring via stochastic refinement},
257}
258
259@article{nichol2021glide,
260 year = {2021},
261 journal = {arXiv preprint arXiv:2112.10741},
262 author = {Nichol, Alex and Dhariwal, Prafulla and Ramesh, Aditya and Shyam, Pranav and Mishkin, Pamela and McGrew, Bob and Sutskever, Ilya and Chen, Mark},
263 title = {Glide: Towards photorealistic image generation and editing with text-guided diffusion models},
264}
265
266@article{chen2020wavegrad,
267 year = {2020},
268 journal = {arXiv preprint arXiv:2009.00713},
269 author = {Chen, Nanxin and Zhang, Yu and Zen, Heiga and Weiss, Ron J and Norouzi, Mohammad and Chan, William},
270 title = {WaveGrad: Estimating gradients for waveform generation},
271}
272
273@article{chen2021wavegrad,
274 year = {2021},
275 journal = {arXiv preprint arXiv:2106.09660},
276 author = {Chen, Nanxin and Zhang, Yu and Zen, Heiga and Weiss, Ron J and Norouzi, Mohammad and Dehak, Najim and Chan, William},
277 title = {WaveGrad 2: Iterative refinement for text-to-speech synthesis},
278}
279
280@article{kong2020diffwave,
281 year = {2020},
282 journal = {arXiv preprint arXiv:2009.09761},
283 author = {Kong, Zhifeng and Ping, Wei and Huang, Jiaji and Zhao, Kexin and Catanzaro, Bryan},
284 title = {Diffwave: A versatile diffusion model for audio synthesis},
285}
286
287@article{ho2022video,
288 year = {2022},
289 journal = {arXiv preprint arXiv:2204.03458},
290 author = {Ho, Jonathan and Salimans, Tim and Gritsenko, Alexey and Chan, William and Norouzi, Mohammad and Fleet, David J},
291 title = {Video diffusion models},
292}
293
294@inproceedings{kim2022guided,
295 organization = {PMLR},
296 year = {2022},
297 pages = {11119--11133},
298 booktitle = {International Conference on Machine Learning},
299 author = {Kim, Heeseung and Kim, Sungwon and Yoon, Sungroh},
300 title = {Guided-tts: A diffusion model for text-to-speech via classifier guidance},
301}
302
303@inproceedings{popov2021grad,
304 organization = {PMLR},
305 year = {2021},
306 pages = {8599--8608},
307 booktitle = {International Conference on Machine Learning},
308 author = {Popov, Vadim and Vovk, Ivan and Gogoryan, Vladimir and Sadekova, Tasnima and Kudinov, Mikhail},
309 title = {Grad-tts: A diffusion probabilistic model for text-to-speech},
310}
311
312@article{xu2022geodiff,
313 year = {2022},
314 journal = {arXiv preprint arXiv:2203.02923},
315 author = {Xu, Minkai and Yu, Lantao and Song, Yang and Shi, Chence and Ermon, Stefano and Tang, Jian},
316 title = {Geodiff: A geometric diffusion model for molecular conformation generation},
317}
318
319@article{li2022diffusion,
320 year = {2022},
321 journal = {arXiv preprint arXiv:2205.14217},
322 author = {Li, Xiang Lisa and Thickstun, John and Gulrajani, Ishaan and Liang, Percy and Hashimoto, Tatsunori B},
323 title = {Diffusion-LM Improves Controllable Text Generation},
324}
325
326@article{villegas2022phenaki,
327 year = {2022},
328 journal = {arXiv preprint arXiv:2210.02399},
329 author = {Villegas, Ruben and Babaeizadeh, Mohammad and Kindermans, Pieter-Jan and Moraldo, Hernan and Zhang, Han and Saffar, Mohammad Taghi and Castro, Santiago and Kunze, Julius and Erhan, Dumitru},
330 title = {Phenaki: Variable length video generation from open domain textual description},
331}
332
333@article{raffel2020exploring,
334 year = {2020},
335 pages = {1--67},
336 number = {140},
337 volume = {21},
338 journal = {J. Mach. Learn. Res.},
339 author = {Raffel, Colin and Shazeer, Noam and Roberts, Adam and Lee, Katherine and Narang, Sharan and Matena, Michael and Zhou, Yanqi and Li, Wei and Liu, Peter J and others},
340 title = {Exploring the limits of transfer learning with a unified text-to-text transformer.},
341}
342
343@article{kirchenbauer2023watermark,
344 year = {2023},
345 journal = {arXiv preprint arXiv:2301.10226},
346 author = {Kirchenbauer, John and Geiping, Jonas and Wen, Yuxin and Katz, Jonathan and Miers, Ian and Goldstein, Tom},
347 title = {A Watermark for Large Language Models},
348}
349
350@article{devlin2018bert,
351 year = {2018},
352 journal = {arXiv preprint arXiv:1810.04805},
353 author = {Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
354 title = {Bert: Pre-training of deep bidirectional transformers for language understanding},
355}
356
357@article{prabhu2020large,
358 year = {2020},
359 journal = {arXiv preprint arXiv:2006.16923},
360 author = {Prabhu, Vinay Uday and Birhane, Abeba},
361 title = {Large image datasets: A pyrrhic win for computer vision?},
362}
363
364@article{radford2019language,
365 year = {2019},
366 pages = {9},
367 number = {8},
368 volume = {1},
369 journal = {OpenAI blog},
370 author = {Radford, Alec and Wu, Jeffrey and Child, Rewon and Luan, David and Amodei, Dario and Sutskever, Ilya and others},
371 title = {Language models are unsupervised multitask learners},
372}
373
374@article{radford2018improving,
375 publisher = {OpenAI},
376 year = {2018},
377 author = {Radford, Alec and Narasimhan, Karthik and Salimans, Tim and Sutskever, Ilya and others},
378 title = {Improving language understanding by generative pre-training},
379}
380
381@inproceedings{radford2021learning,
382 organization = {PMLR},
383 year = {2021},
384 pages = {8748--8763},
385 booktitle = {International Conference on Machine Learning},
386 author = {Radford, Alec and Kim, Jong Wook and Hallacy, Chris and Ramesh, Aditya and Goh, Gabriel and Agarwal, Sandhini and Sastry, Girish and Askell, Amanda and Mishkin, Pamela and Clark, Jack and others},
387 title = {Learning transferable visual models from natural language supervision},
388}
389
390@inproceedings{narayanan2021efficient,
391 year = {2021},
392 pages = {1--15},
393 booktitle = {Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis},
394 author = {Narayanan, Deepak and Shoeybi, Mohammad and Casper, Jared and LeGresley, Patrick and Patwary, Mostofa and Korthikanti, Vijay and Vainbrand, Dmitri and Kashinkunti, Prethvi and Bernauer, Julie and Catanzaro, Bryan and others},
395 title = {Efficient large-scale language model training on gpu clusters using megatron-lm},
396}
397
398@article{ouyang2022training,
399 year = {2022},
400 journal = {arXiv preprint arXiv:2203.02155},
401 author = {Ouyang, Long and Wu, Jeff and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll L and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and others},
402 title = {Training language models to follow instructions with human feedback},
403}
404
405@misc{Runway-url,
406 year = {2022},
407 howpublished = {\url{https://runwayml.com/text-to-video/}},
408 author = {Runway},
409 title = {Text to video.},
410}
411
412@misc{chatgpt-url,
413 year = {2022},
414 howpublished = {\url{https://openai.com/blog/chatgpt/}},
415 author = {OpenAI},
416 title = {ChatGPT: Optimizing Language Models for Dialogue},
417}
418
419@misc{gpt4,
420 year = {2023},
421 howpublished = {\url{https://openai.com/research/gpt-4}},
422 author = {OpenAI},
423 title = {GPT-4},
424}
425
426@misc{chatgpt-news-url,
427 year = {2022},
428 howpublished = {\url{https://www.gartner.com/en/newsroom/press-releases/2022-12-08-why-is-chatgpt-making-waves-in-the-ai-market}},
429 author = {Bern Elliot and Meghan Rimol DeLisi},
430 title = {Why is ChatGPT Making Waves in the AI Market?},
431}
432
433@misc{dalle2-mitigations-url,
434 year = {2022},
435 howpublished = {\url{https://openai.com/blog/dall-e-2-pre-training-mitigations/}},
436 author = {Alex Nichol},
437 title = {DALL·E 2 Pre-Training Mitigations},
438}
439
440@misc{imagen-problematic-url,
441 year = {2022},
442 howpublished = {\url{https://www.insidehook.com/daily_brief/tech/google-imagen-text-to-image}},
443 author = {Kirk Miller},
444 title = {Google Admits Its Mind-Blowing Text-to-Image AI Is Endlessly Problematic},
445}
446
447@misc{ip-concerns-url,
448 year = {2022},
449 howpublished = {\url{https://techcrunch.com/2022/12/13/image-generating-ai-can-copy-and-paste-from-training-data-raising-ip-concerns/}},
450 author = {Kyle Wiggers},
451 title = {Image-generating AI can copy and paste from training data, raising IP concerns},
452}
453
454@misc{midjourney-terms-of-service-url,
455 year = {2022},
456 howpublished = {\url{https://midjourney.gitbook.io/docs/terms-of-service}},
457 author = {Midjourney},
458 title = {Midjourney: Terms of Service},
459}
460
461@misc{stable-diffusion-opt-out-url,
462 year = {2022},
463 howpublished = {\url{https://www.technologyreview.com/2022/12/16/1065247/artists-can-now-opt-out-of-the-next-version-of-stable-diffusion/}},
464 author = {Melissa Heikkilä},
465 title = {Artists can now opt out of the next version of Stable Diffusion},
466}
467
468@misc{AI-harming-url,
469 year = {2022},
470 howpublished = {\url{https://www.numenta.com/blog/2022/05/24/ai-is-harming-our-planet/}},
471 author = {Charmaine Lai, Subutai Ahmad, Donna Dubinsky and Christy Maver},
472 title = {AI is harming our planet: addressing AI's staggering energy cost},
473}
474
475@misc{deepfake-url,
476 year = {2022},
477 howpublished = {\url{https://techcrunch.com/2022/08/24/deepfakes-for-all-uncensored-ai-art-model-prompts-ethics-questions/}},
478 author = {Kyle Wiggers},
479 title = {Deepfakes for all: Uncensored AI art model prompts ethics questions},
480}
481
482@misc{chatgpt-school-banned-url,
483 year = {2022},
484 howpublished = {\url{https://www.nbcnews.com/tech/tech-news/new-york-city-public-schools-ban-chatgpt-devices-networks-rcna64446}},
485 author = {Kalhan Rosenblatt},
486 title = {ChatGPT banned from New York City public schools’ devices and networks},
487}
488
489@misc{chatgpt-stackoverflow-banned-url,
490 year = {2022},
491 howpublished = {\url{https://meta.stackoverflow.com/questions/421831/temporary-policy-chatgpt-is-banned}},
492 author = {Stack Overflow},
493 title = {Temporary policy: ChatGPT is banned.},
494}
495
496@misc{promptbase-url,
497 year = {2022},
498 howpublished = {\url{https://promptbase.com}},
499 author = {PromptBase},
500 title = {PromptBase official website.},
501}
502
503@misc{ghost-writer-url,
504 year = {2023},
505 howpublished = {\url{https://www.theinformation.com/articles/ghost-writer-microsoft-looks-to-add-openais-chatbot-technology-to-word-email}},
506 author = {Aaron Holmes and Kevin McLaughlin},
507 title = {Ghost Writer: Microsoft Looks to Add OpenAI’s Chatbot Technology to Word, Email.},
508}
509
510@misc{david-holz-url,
511 year = {2022},
512 howpublished = {\url{https://www.theregister.com/2022/08/01/david_holz_midjourney/}},
513 author = {David Holz and Thomas Claburn},
514 title = {David Holz, founder of AI art generator Midjourney, on the future of imaging.},
515}
516
517@misc{stable-diffusion-url,
518 year = {2022},
519 howpublished = {\url{https://github.com/CompVis/stable-diffusion}},
520 author = {Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer},
521 title = {Stable Diffusion GitHub repository.},
522}
523
524@inproceedings{zhang2022fine,
525 year = {2022},
526 booktitle = {EMNLP},
527 author = {Zhang, Zhiyuan and Lyu, Lingjuan and Ma, Xingjun and Wang, Chenguang and Sun, Xu},
528 title = {Fine-mixing: Mitigating Backdoors in Fine-tuned Language Models},
529}
530
531@inproceedings{sun2023defending,
532 year = {2023},
533 booktitle = {AAAI},
534 author = {Sun, Xiaofei and Li, Xiaoya and Meng, Yuxian and Ao, Xiang and Lyu, Lingjuan and Li, Jiwei and Zhang, Tianwei},
535 title = {Defending against backdoor attacks in natural language generation},
536}
537
538@misc{stable-diffusion-litigation-url,
539 year = {2023},
540 howpublished = {\url{https://stablediffusionlitigation.com}},
541 author = {Matthew Butterick},
542 title = {Stable Diffusion litigation},
543}
544
545@misc{clip-retrieval-url,
546 year = {2022},
547 howpublished = {\url{https://rom1504.github.io/clip-retrieval/}},
548 author = {Romain Beaumont},
549 title = {Clip Retrieval System},
550}
551
552@misc{haveibeentrained-url,
553 year = {2022},
554 howpublished = {\url{https://haveibeentrained.com}},
555 author = {SpawningAI},
556 title = {Have I Been Trained?},
557}
558
559@misc{exploring-the-training-data-url,
560 year = {2022},
561 howpublished = {\url{https://simonwillison.net/2022/Sep/5/laion-aesthetics-weeknotes/}},
562 author = {Simon Willison and Andy Baio},
563 title = {Exploring the training data behind Stable Diffusion},
564}
565
566@misc{github-copilot-investigation-url,
567 year = {2022},
568 howpublished = {\url{https://githubcopilotinvestigation.com/}},
569 author = {Matthew Butterick},
570 title = {GitHub Copilot investigation},
571}
572
573@misc{devs-dont-rely-url,
574 year = {2022},
575 howpublished = {\url{https://www.reversinglabs.com/blog/devs-dont-rely-on-github-copilot-legal-risk-is-real}},
576 author = {Richi Jennings},
577 title = {Devs: Don’t rely on GitHub Copilot — legal risk gets real},
578}
579
580@misc{getty-images-url,
581 year = {2023},
582 howpublished = {\url{https://www.theverge.com/2023/1/17/23558516/ai-art-copyright-stable-diffusion-getty-images-lawsuit}},
583 author = {James Vincent},
584 title = {Getty Images is suing the creators of AI art tool Stable Diffusion for scraping its content},
585}
586
587@misc{copyright-url,
588 year = {2023},
589 howpublished = {\url{https://www.copyright.gov/what-is-copyright/}},
590 author = {U.S. Copyright Office},
591 title = {What is Copyright?},
592}
593
594@misc{stable-diffusion-model-card-url,
595 year = {2022},
596 howpublished = {\url{https://github.com/CompVis/stable-diffusion/blob/main/Stable_Diffusion_v1_Model_Card.md}},
597 author = {Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer},
598 title = {Stable Diffusion v1 Model Card.},
599}
600
601@misc{AI-models-spit-url,
602 year = {2023},
603 howpublished = {\url{https://www.technologyreview.com/2023/02/03/1067786/ai-models-spit-out-photos-of-real-people-and-copyrighted-images/}},
604 author = {Melissa Heikkilä},
605 title = {AI models spit out photos of real people and copyrighted images.},
606}
607
608@misc{chatgpt-theft-url,
609 year = {2023},
610 howpublished = {\url{https://www.techgoing.com/microsoft-and-amazon-guard-against-chatgpt-theft-ban-employees-from-sharing-sensitive-data/}},
611 author = {James Lopez},
612 title = {Microsoft, and Amazon guard against ChatGPT theft, ban employees from sharing sensitive data.},
613}
614
615@misc{AI-written-classifier-url,
616 year = {2023},
617 howpublished = {\url{https://openai.com/blog/new-ai-classifier-for-indicating-ai-written-text/}},
618 author = {Jan Hendrik Kirchner and Lama Ahmad and Scott Aaronson and Jan Leike},
619 title = {New AI classifier for indicating AI-written text.},
620}
621
622@misc{chatgpt-replace-url,
623 year = {2023},
624 howpublished = {\url{https://www.businessinsider.com/chatgpt-jobs-at-risk-replacement-artificial-intelligence-ai-labor-trends-2023-02}},
625 author = {Aaron Mok and Jacob Zinkula},
626 title = {ChatGPT may be coming for our jobs. Here are the 10 roles that AI is most likely to replace.},
627}
628
629@article{lazaridou2021pitfalls,
630 year = {2021},
631 journal = {arXiv preprint arXiv:2102.01951},
632 author = {Lazaridou, Angeliki and Kuncoro, Adhiguna and Gribovskaya, Elena and Agrawal, Devang and Liska, Adam and Terzi, Tayfun and Gimenez, Mai and d’Autume, C d M and Ruder, Sebastian and Yogatama, Dani and others},
633 title = {Pitfalls of static language modelling},
634}
635
636@article{bickmore2018patient,
637 publisher = {JMIR Publications Inc., Toronto, Canada},
638 year = {2018},
639 pages = {e11510},
640 number = {9},
641 volume = {20},
642 journal = {Journal of medical Internet research},
643 author = {Bickmore, Timothy W and Trinh, Ha and Olafsson, Stefan and O'Leary, Teresa K and Asadi, Reza and Rickles, Nathaniel M and Cruz, Ricardo},
644 title = {Patient and consumer safety risks when using conversational assistants for medical information: an observational study of Siri, Alexa, and Google Assistant},
645}
646
647@inproceedings{welbl2021challenges,
648 year = {2021},
649 pages = {2447--2469},
650 booktitle = {Findings of the Association for Computational Linguistics: EMNLP 2021},
651 author = {Welbl, Johannes and Glaese, Amelia and Uesato, Jonathan and Dathathri, Sumanth and Mellor, John and Hendricks, Lisa Anne and Anderson, Kirsty and Kohli, Pushmeet and Coppin, Ben and Huang, Po-Sen},
652 title = {Challenges in Detoxifying Language Models},
653}
654
655@article{xu2021detoxifying,
656 year = {2021},
657 journal = {arXiv preprint arXiv:2104.06390},
658 author = {Xu, Albert and Pathak, Eshaan and Wallace, Eric and Gururangan, Suchin and Sap, Maarten and Klein, Dan},
659 title = {Detoxifying language models risks marginalizing minority voices},
660}
661
662@article{weidinger2021ethical,
663 year = {2021},
664 journal = {arXiv preprint arXiv:2112.04359},
665 author = {Weidinger, Laura and Mellor, John and Rauh, Maribeth and Griffin, Conor and Uesato, Jonathan and Huang, Po-Sen and Cheng, Myra and Glaese, Mia and Balle, Borja and Kasirzadeh, Atoosa and others},
666 title = {Ethical and social risks of harm from language models},
667}
668
669@article{cetinic2022myth,
670 year = {2022},
671 journal = {arXiv preprint arXiv:2211.15271},
672 author = {Cetinic, Eva},
673 title = {The Myth of Culturally Agnostic AI Models},
674}
675
676@misc{dalle2-bias-url,
677 year = {2022},
678 howpublished = {\url{https://www.wired.com/story/dall-e-2-ai-text-image-bias-social-media/}},
679 author = {Khari Johnson},
680 title = {DALL-E 2 Creates Incredible Images—and Biased Ones You Don’t See.},
681}Attribution
arXiv:2303.01325v2
[cs.AI]
License: cc-by-4.0


