
Papers is Alpha. This content is part of an effort to make research more accessible, and (most likely) has lost some details from the original. You can find the original paper here.
Introduction
The development of responsible AI systemshas become a significant concern as AI technologies continue to permeate various aspects of society. While AI holds the potential to benefit humanity, concerns regarding biasesand the lack of transparency and accountabilityhinder its ability to unlock human capabilities on a large scale. In response, AI practitioners[We use the term practitioners to cover a wide range of stakeholders including AI engineers, developers, researchers, designers, ethics experts.] are actively exploring ways to enhance responsible AI development and deployment. One popular approach is the use of tools such as checklistsor guideline cardsthat are designed to promote AI fairness, transparency, and sustainability. These tools provide practical frameworks that enable practitioners to systematically assess and address ethical considerations throughout the AI development lifecycle. By incorporating checklists and guideline cards into their workflows, practitioners can evaluate key aspects such as data sources, model training, and decision-making processes to mitigate potential biases, ensure transparency, and promote the long-term sustainability of AI. However, these tools face two main challenges, creating a mismatch between their potential to support ethical AI development and their current design.
The first challenge is that these tools often exhibit a static nature, lacking the ability to dynamically incorporate the latest advancements in responsible AI literature and international standards. In the rapidly evolving field of responsible AI, new ethical considerations and regulatory guidelines constantly emerge (e.g., the EU AI Act). It is therefore crucial for AI practitioners to stay updated of these developments to ensure their AI systems align with the current ethical and responsible AI practices. While checklists and guideline cards are increasingly used to assist and enhance the development of responsible AI systems, can quickly become outdated (e.g., the AI Blindspots deck has undergone several iterations), limiting their effectiveness in addressing evolving concerns related to fairness, transparency, and accountability.
The second challenge is that these tools often prioritize individual usage instead of promoting collaboration among AI practitioners. While individual adoption of responsible AI practices is important, fostering collaboration among practitioners can facilitate collective learning and a broader understanding of responsible AI principles (e.g., the inclusion of “crowd audits”of algorithmic harms has not yet been integrated into responsible AI tools). By emphasizing individual usage, these tools may inadvertently hinder the exchange of ideas, best practices, and lessons learned among practitioners. On the other hand, collaboration is crucial in addressing complex ethical and societal challenges associated with AI systems. Therefore, it is essential to enhance the collaborative nature of these tools, enabling knowledge sharing and fostering a community-driven approach to responsible AI development and deployment.
To overcome these challenges, we developed an adaptable and updatable method that consists of actionable guidelines. These guidelines aim to address the static and often non-collaborative nature of existing responsible AI tools. To achieve this, we focused on answering two main research questions (RQs):
RQ1 : How can actionable responsible AI guidelines be systematically developed?
RQ2: How can responsible AI guidelines be implemented into a practical tool, and to what extent the tool is usable?
In addressing these two questions, we made three main contributions:
- Our method enables the integration of dynamic and comprehensive content in responsible AI tool (e.g., checklists or guideline cards) (sec-method). It facilitates easy updating of responsible AI guidelines from research papers and ISO[International Organization for Standardization.] standards, ensuring that the content remains relevant and up to date. Our method has yielded 22 actionable guidelines that can be implemented by a diverse range of AI practitioners, centered around what practitioners need to do, rather than specific implementation details.
- We validated our method through a case study conducted at a large tech company, where we designed and deployed a tool that provides interactive and actionable guidelines (sec-userstudy). Initially, we conducted a formative study involving 10 AI practitioners to identify the key design requirements for populating the tool with responsible AI guidelines. Based on these requirements, we designed and populated the tool, which was then evaluated for its usability and effectiveness in an interview study with an additional set of 14 AI practitioners. The guidelines were found to be practical and actionable, effectively encouraging self-reflection and facilitating a better understanding of the ethical considerations involved in AI development.
- In light of these findings, we discuss how our method contributes to the idea of “Responsible AI by Design” by contextualizing the guidelines, informing existing or new theories, and offering practical recommendations for designing responsible AI toolkits with the aim of fostering collaboration and enabling organizational accountability (sec-discussion).
Related Work
We surveyed various lines of research that our work draws upon, and grouped them into two main areas: i) AI regulation and governance, and ii) responsible AI practices and toolkits.
AI Regulation and Governance
The landscape of AI regulation and governance is constantly evolving. At the time of writing, the European Union (EU) has endorsed new transparency and risk-management rules for AI systems known as the EU AI Act, which is expected to become law in 2023. Similarly, the United States (US) has recently passed a blueprint of the AI Bill of Rights in late 2022. This bill comprises “five principles and associated practices to help guide the design, use, and deployment of automated systems to protect the rights of the American public in the age of AI.” While both the EU and US share a conceptual alignment on key principles of responsible AI, such as fairness and explainability, as well as the importance of international standards (e.g., ISO), the specific AI risk management regimes they are developing are potentially diverging, creating an “artificial divide”. The EU aims to become the leading regulator for AI globally, while the US takes the view that excessive regulation may impede innovation.
Notable predecessors to AI regulations include the EU GDPR law on data protection and privacy, the US Anti-discrimination Act, and the UK Equality Act 2010. GDPR’s Article 25 mandates that data controllers must implement appropriate technical and organizational measures during the design and implementation stages of data processing to safeguard the rights of data subjects. The Anti-discrimination Act prohibits employment decisions based on an individual’s race, color, religion, sex (including gender identity, sexual orientation, and pregnancy), national origin, age (40 or older), disability, or genetic information. This legislation ensures fairness in AI-assisted hiring systems. Similarly, the UK Equality Act provides legal protection against discrimination in the workplace and wider society.
The National Institute of Standards and Technology (NIST), a renowned organization for developing frameworks and standards, recently published an AI risk management framework. According to the NIST framework, an AI system is defined as “an engineered or machine-based system capable of generating outputs such as predictions, recommendations, or decisions that influence real or virtual environments, based on a given set of objectives. These systems are designed to operate with varying levels of autonomy.” Similarly, the Principled Artificial Intelligence white paper from the Berkman Klein Centerhighlights eight key thematic trends that represent a growing consensus on responsible AI. These themes include privacy, accountability, safety and security, transparency and explainability, fairness and non-discrimination, human control of technology, professional responsibility, and the promotion of human values.
As AI regulation and governance continue to evolve, AI practitioners are faced with the challenge of staying updated with the changing guidelines and regulations, requiring significant time and effort. Therefore, the focus of this work is to develop an adaptable methodology for generating responsible AI guidelines.
Responsible AI Practices and Toolkits
Responsible AI Practices.
A growing body of research, typically discussed in conferences with a long-standing commitment to human-centered design, such as the Conference on Human Factors in Computing Systems (CHI) and the Conference on Computer-Supported Cooperative Work and Social Computing (CSCW), as well as in newer conferences like the Conference on AI, Ethics, and Society (AIES) and the Conference on Fairness, Accountability, and Transparency (FAccT), focuses on the work practices of AI practitioners in addressing responsible AI issues. This strand of research encompasses various aspects of responsible AI, including fairness, explainability, sustainability, and best practices for data and model documentation and evaluation.
Fairness is a fundamental value in responsible AI, but its definition is complex and multifaceted. To assess bias in classification outputs, various research efforts have introduced quantitative metrics such as disparate impact and equalized odds, as discussed by Dixon et al.. Another concept explored in the literature is “equality of opportunity,” advocated by Hardt et al., which ensures that predictive models are equally accurate across different groups defined by protected attributes like race or gender.
Explainable AI (XAI) is another aspect of responsible AI. XAI involves tools and frameworks that assist end users and stakeholders in understanding and interpreting predictions made by machine learning models. Furthermore, the environmental impact of training AI models should also be considered. Numerous reports have highlighted the significant carbon footprint associated with deep learning and large language models.
Best practices for data documentation and model evaluation have also been developed to promote fairness in AI systems. Gebru et al.proposed “Datasheets for Datasets” as a comprehensive means of providing information about a dataset, including data provenance, key characteristics, relevant regulations, test results, and potential biases. Similarly, Bender et al.introduced “data statements” as qualitative summaries that offer crucial context about a dataset’s population, aiding in identifying biases and understanding generalizability. For model evaluation, Mitchell et al.suggested the use of model cards, which provide standardized information about machine learning models, including their intended use, performance metrics, potential biases, and data limitations. Transparent reporting practices, such as the TRIPOD statement by Collins et al.in the medical domain, emphasize standardized and comprehensive reporting to enhance credibility and reproducibility of AI prediction models.
Responsible AI Toolkits
Translating these practices into practical responsible AI is another area of growing research. New tools and frameworks are being proposed to assist developers in mitigating biases, explaining algorithmic decisions, and ensuring privacy-preserving AI systems.
Fairness auditing tools typically offer a set of metrics to test for potential biases, and algorithms to mitigate biases that may arise in AI models. For instance, Google’s fairness-indicators toolkitenables developers to evaluate the distribution of datasets, performance of models across user-defined groups, and delve into individual slices to identify root causes and areas for improvement. IBM’s AI Fairness 360implements metrics for comparing subgroups of datasets (e.g., differential fairness and bias amplification) and algorithms for mitigating biases (e.g., learning fair representations, adversarial debiasing). Microsoft’s Fairlearn provides metrics to assess the negative impact on specific groups by a model and compare multiple models in terms of fairness and accuracy metrics. It also offers algorithms to mitigate unfairness across various AI tasks and definitions of fairness.
Explainable AI systems are typically achieved through interpretable models or model-agnostic methods. Interpretable models employ simpler models like linear or logistic regression to explain the outputs of black-box models. On the other hand, model-agnostic methods (e.g., LIMEor SHAP) have shown effectiveness with any model. IBM’s AI Explainability 360 provides metrics that serve as quantitative proxies for the quality of explanations and offers guidance to developers and practitioners on ensuring AI explainability. Another research direction introduced new genres of AI-related visualizations for explainability, drawing inspiration from domains such as visual storytelling, uncertainty visualizations, and visual analytics. Examples include Google’s explorables, which are interactive visual explanations of the internal workings of AI techniques; model and data cards that support model transparency and accountability (e.g., NVIDIA’s Model Card++); computational notebook additions for data validations like AIF360, Fairlearn, and Aequitas; and data exploration dashboards such as Google’s Know Your Dataand Microsoft’s Responsible AI dashboard.
Ensuring privacy-preserving AI systems is commonly attributed to the practice of “Privacy by Design”, which involves integrating data privacy considerations throughout the AI lifecycle, particularly during the design stage to ensure compliance with laws, regulations, and standardssuch as the European General Data Protection Regulation (GDPR). IBM’s AI Privacy 360 is an example of a toolkit that assesses privacy risks and helps mitigate potential privacy concerns. It includes modules for data anonymization (training a model on anonymized data) and data minimization (collecting only relevant and necessary data for model training) to evaluate privacy risks and ensure compliance with privacy regulations.
While many toolkits and frameworks emphasize the importance of involving stakeholders from diverse roles and backgrounds, they often lack sufficient support for collaborative action. Wong et al.have also highlighted the “mismatch between the promise of toolkits and their current design” in terms of supporting collaboration. Collaboration is key to enhance creativity by allowing AI practitioners to share knowledge with other stakeholders. To address this gap, we aim to develop a set of actionable guidelines that will facilitate the engagement of a diverse range of stakeholders in AI ethics. By doing so, we hope to take a significant step forward in fostering collaboration and inclusivity within the field.
Author Positionality Statement
Understanding researcher positionality is crucial for transparently examining our perspectives on methodology, data collection, and analyses. In this paper, we situate ourselves in a Western country during the 21st century, writing as authors primarily engaged in academic and industry research. Our team comprises three males and two females from Southern, Eastern, and North Europe, and Middle East with diverse ethnic and religious backgrounds. Our collective expertise spans various fields, including human-computer interaction (HCI), ubiquitous computing, software engineering, artificial intelligence, data visualization, and digital humanities.
It is important to recognize that our backgrounds and experiences have shaped our positionality. As HCI researchers affiliated with a predominantly Western organization, we acknowledge the need to expand the understanding of the research questions and methodology presented in this paper. Consequently, our positionality may have influenced the subjectivity inherent in framing our research questions, selecting our methodology, designing our study, and interpreting and analyzing our data.
Method for Generating Responsible AI Guidelines
To answer our RQ1 , we followed a four-step process (Figure fig-steps), based on the methodology proposed by Michie et al.. This process allowed us to identify the essential element of a guideline, referred to as the “active ingredient,” focusing on the “what” rather than the “how”. A similar parallel can be drawn in software engineering, where the “what” represents the software requirements and the “how” represents the software design, both of which are important for a successful software product. However, by shifting the focus to the “what,” AI practitioners can develop a clearer understanding of the objectives and goals they need to achieve, fostering a deeper comprehension of complex underlying ethical concepts. Throughout this process, we actively engaged a diverse group of stakeholders, including AI engineers, researchers, and experts in law and standardization. As a result, we were able to develop a total of 22 responsible AI guidelines.

Compiling a List of Papers on Responsible AI
In the first step, we compiled a list of key scientific articles focusing on responsible AI guidelines for AI practitioners (discussed in detail in sec-sub-raipractices). We created this list by targeting influential papers published in renowned computer science conferences, such as the ACM CHI, CSCW, FAccT, AAAI/ACM Conference on AI, Ethics, and Society (AIES), and scientific literature from the medical domain (e.g., the Annals of Internal Medicine). Note that we did not conduct a systematic literature but rather relied on snowball sampling by identifying key publications related to the topic at hand. Overall, we identified 17 key papers that covered a broad range of responsible AI aspects, including fairness, explainability, sustainability, and best practices for data and model documentation and evaluation.
Creating a Catalog of Responsible AI Guidelines From the Papers
For each source, we compiled a list of techniques that could be employed to create responsible AI guidelines, focusing on the actions developers should consider during AI development. Following the methodology proposed by Michie et al.(which was also used to identify community engagement techniques by Dittus et al.), we sought techniques that describe the “active ingredient” of what needs to be done. This means that the phrasing of the technique should focus on what developers need to do (what ), rather than the specific implementation details (how ). In total, we formulated a set of 16 techniques based on relevant literature sources.
For instance, a recommended practice for ensuring fairness involves evaluating an AI system across different demographic groups. In this case, the technique specifies “what” needs to be done rather than “how” it should be implemented (e.g., using common fairness metrics such as demographic parity or equalized odds). We then conducted an iterative review of the collection of techniques to identify duplicates, which were instances where multiple sources referred to the same technique. For example, four sources indicated that data biases could affect the model, emphasizing the need to report the characteristics of training and testing datasets. We consolidated such instances by retaining the specific actions to be taken (e.g., reporting dataset characteristics). This process resulted in an initial list of 16 distinct techniques. We provided a concise summary sentence for each technique, utilizing active verbs to emphasize the recommended actions for developers.
Examining the Catalog With AI Developers and Standardization Experts Through Interviews
The catalog of techniques underwent eleven iterations to ensure clarity and comprehensive thematic coverage. The iterations were carried out by two authors, with the first author conducting interviews with five AI researchers and developers. During the interviews, the participants were asked to consider their current AI projects and provide insights on the implementation of each technique, focusing on the “how” aspect. This served two purposes: firstly, to identify any statements that were unclear or vague, prompting suggestions for alternative phrasing; and secondly, to expand the catalog further. The interviews yielded two main recommendations for improvement: i) mapping duplicate techniques to the same underlying action(s); and ii) adding examples to support each technique.
In addition to the interviews, the two authors who developed the initial catalog conducted a series of six 1-hour workshops with two standardization experts from a large organization. The purpose of these workshops was to review the initial catalog for ISO compliance. The standardization experts examined six AI-related ISOs, including ISO 38507, ISO 23894, ISO 5338, ISO 24028, ISO 24027, and ISO 24368, which were developed at the time of writing (we provide a high-level summary[Note that the summary provided is a brief and simplified description due to a paywall restriction.] of each ISO next). The experts provided input on any missing techniques and mapped each technique in the initial catalog to the corresponding ISO that covers it. As a result of this exercise, six new techniques (#2, #7, #12, #13, #14, #21) were added to the catalog.
ISO 38507 (Governance, 28 pages). It provides guidance to organizations on how to effectively and responsibly govern the use of AI (e.g., identify potential harms and risks for each intended use(s) of the systems). It offers recommendations to the governing body of an organization, as well as various stakeholders such as executive managers, external specialists, public authorities, service providers, assessors, and auditors. The standard is applicable to organizations of all types and sizes, regardless of their reliance on data or information technologies, addressing both current and future uses of AI and their implications.
ISO 23894 (Risk Management, 26 pages). It offers guidance to organizations involved in the development, production, deployment, or use of products, systems, and services utilizing AI to effectively manage AI-related risks (e.g., develop mechanisms for incentivizing reporting of system harms). It provides recommendations on integrating risk management into AI activities and functions, along with describing processes for the successful implementation and integration of AI risk management. The guidance is adaptable to suit the specific needs and context of any organization.
ISO 5338 (AI Lifecycle Process, 27 pages). It establishes a framework for describing the life cycle of AI systems that rely on machine learning and heuristic systems. It defines processes and concepts (e.g., through reporting of harms and risks, obtaining approval of intended uses) that enable the effective definition, control, management, execution, and enhancement of AI systems throughout their life cycle stages. These processes are applicable to organizations or projects involved in the development or procurement of AI systems, providing a structured approach to their development and implementation.
ISO 24028 (Trustworthiness, 43 pages). It provides an overview of trustworthiness in AI systems, covering various aspects. It explores approaches to establish trust in AI systems through transparency, explainability, and controllability. It also addresses potential engineering pitfalls, associated threats, and risks to AI systems, offering mitigation techniques. Additionally, it discusses approaches to assess and ensure the availability, resiliency, reliability, accuracy, safety, security, and privacy of AI systems. However, it does not specify the levels of trustworthiness for AI systems.
ISO 24027 (Bias, 39 pages). It focuses on bias (i.e., related to protected attributes, such as age, gender, and ethnicity, being used in the training of AI) in AI systems, particularly in the context of AI-aided decision-making. It provides techniques and methods for measuring and assessing bias, with the objective of identifying and addressing vulnerabilities related to bias. The standard covers all phases of the AI system lifecycle, encompassing data collection, training, continual learning, design, testing, evaluation, and use.
ISO 24368 (Ethical and Societal Concerns, 48 pages). It offers a broad introduction to ethical and societal concerns related to AI. It provides information on principles, processes, and methods in this field and is aimed at technologists, regulators, interest groups, and society as a whole. It does not promote any specific set of values or value systems. Additionally, the document provides an overview of existing International Standards that tackle issues arising from ethical and societal concerns in AI.
While our method is comprehensive, it is important to note that the responsible AI guidelines were checked against six ISOs in their current form. However, the flexibility of our approach allows for amending or adding new responsible AI techniques as scientific literature advances and ISO standards evolve. At the time of writing, there are additional ISOs that are in the committee draft stage and can be included in the guidelines, such as ISO 42001 (AI management system), ISO 5469 (Functional safety), ISO 5259 (Data quality), ISO 6254 (Explainability), and ISO 12831 (Testing).
Responsible AI guidelines. 22 techniques that describe a responsible AI guideline (i.e., an actionable item that a developer should consider during the AI development lifecycle). These techniques are grounded in the scientific literature (main sources are reported), and were checked for ISO compliance: ISO 38507 (Governance); ISO 23894 (Risk management); ISO 5338 (AI lifecycle processes); ISO 24028 (Trustworthiness); ISO 24027 (Bias); ISO 24368 (Ethical considerations). They were also cross-referenced with the EU AI Act’s articles, following guidance from. Each technique is followed by an example, and the techniques are categorized thematically into six categories, concerning the intended uses, harms, system, data, oversight, and team .
Table Label: tbl-techniques
Download PDF to view tableRevising the Catalog
In response to the interviews with AI developers and standardization experts, we incorporated an example for each guideline. For instance, under the guideline on system interpretability (guideline #9), the example provided reads: “output feature importance and provide human-understandable explanations.” Furthermore, we simplified the language by avoiding domain-specific or technical jargon. We also categorized each guideline into six thematically distinct categories, namely intended uses , harms , system , data , oversight , and team .
Recognizing that certain guidelines may only be applicable at specific stages (e.g., monitoring AI after deployment), we assigned them to three phases based on previous research (e.g.,). These phases are development (designing and coding the system), deployment (transferring the system into the production stage), and use (actual usage of the system). For example, guidelines like identifying the system’s intended uses (guideline #1) are relevant to all three phases, while those related to system updates (guideline #14) or decommissioning (guideline #13) are applicable during the use phase. The revised and final catalog, consisting of 22 unique guidelines, is presented in Table tbl-techniques. To ensure the timeliness and relevance of our guidelines, we cross-referenced them with the articles of the EU AI Actby following guidance provided by Golpayegani et al..
Evaluation of a tool using our Responsible AI Guidelines
Populating a Tool Using Our Responsible AI Guidelines
Eliciting Requirements of the Tool Through a Formative Study
To determine the design requirements for implementing our 22 guidelines into a responsible AI tool, we conducted a formative study involving interviews with AI practitioners. We used open-ended questions during these interviews to gather insights and perspectives from the participants.
Participants and Procedure. We recruited 10 AI practitioners (4 females and 6 males) who were in their 30s and 40s and employed at a large tech company. The participants had a range of work experience, spanning from 1 to 8 years, and were skilled in areas such as data science, data visualization, UX design, natural language processing, and machine learning. Participants were asked to consider their ongoing AI projects, and the interviewer guided them through the 22 guidelines. The interviewer prompted participants to reflect on how these guidelines could be incorporated into an interactive responsible AI tool.
Design Requirements. By conducting an inductive thematic analysis of the interview transcripts, two authors identified three key design requirements, supported by quotes from our participants (referred to as FP). These requirements pertained to unpacking complexity of AI Ethics , to increasing awareness , and to providing examples and reading materials : The first requirement was about offering an easy-to-use functionality that unpacks the complexity of AI Ethics. The tool’s functionality should be user-friendly, allowing for effortless interaction and navigation through complex terminology to enhance the overall user experience. As expressed by FP5, “the sheer number of the guidelines is the main difficulty […] they should be separated in bite-sized questions and allow me to understand the complex terminology used” . To assist users in systematically moving through the guidelines, FP9 suggested that “the system should provide clear navigation […] for example, using a progress bar.” . The second requirement was about increasing awareness. The tool should increase users’ awareness of ethical considerations. FP5 emphasized the importance of “gaining insights while engaging with the 22 guidelines,” while FP8 described this need as having “visual feedback or a score that shows how responsible [their] AI system is.” . Yet, the user FP2 suggested that the implementation of the feedback “should not make me anxious and feel like I have not done enough” . FP5 also recommended that the tool should store user’s answers and produce a documentation of their tool experience: “there should be some functionality there that captures the answers I gave, so it’d help me reflect” . The third requirement was about providing examples and reading materials. The tool should incorporate examples to assist users in comprehending and effectively utilizing the system. FP9 suggested that “references to these guidelines or practical examples could be added. These additions would enhance the sense of credibility.”

Designing and Populating the Tool
We then describe the content and design choices, as well as the tool’s flow and interactions.
Content and Design Choices. Using the 22 guidelines (Table tbl-techniques), we designed and developed an interactive responsible AI tool. Each guideline is presented as a rectangular box, with both the front and back sides being interactive boxes—creating a notion of a digital card. The front side includes a symbolic graphic collage representing the guideline, a brief guideline name, and a concise textual description. On the other hand, the back side includes an example illustrating how the guideline can be applied in an AI system, along with input fields where users can document their specific implementation of the guideline within their context (Figure fig-card-elements).
Digital cards often replicate the appearance and interactions of physical cards, allowing for gestures like stacking, shuffling, and swiping. In our interactive responsible AI tool, guidelines can be viewed from both sides by using the flipping button located in the bottom-left corner, and users have the option to put the guidelines back into a stack for further consideration. We explored different layout options for displaying the guidelines, considering previous research that involved scrolling through a deck or organizing them into multiple groups. However, due to the limited screen size and repetitive guidelines for each phase, we opted to stack the guidelines into three groups based on the phase of the AI system: i) development (designing and coding), ii) deployment (transitioning into production), and iii) use (actual usage of the system). The number of guidelines in each group varied: 20 for development, 19 for deployment, and 21 for use (sec-method, Step 4) to accommodate the specific requirements of each phase.
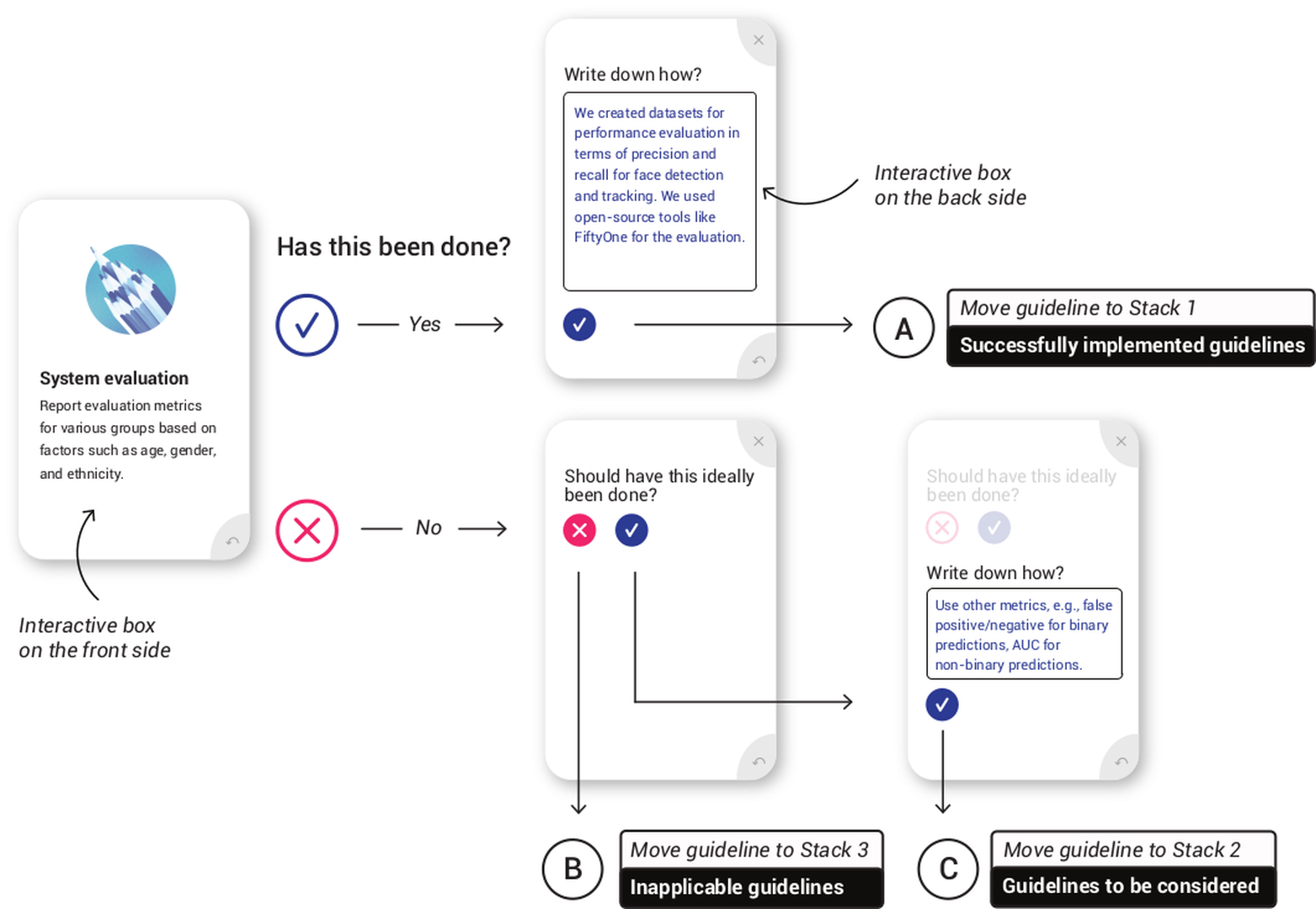
Flow and Interactions. The interactive tool includes two follow-up questions for each guideline, as shown in Figure fig-game-sorting. These questions offer users a systematic approach to consider each guideline within a specific context of their own projects. The first question asks the developer whether the guideline has been successfully implemented in their AI system. For example, a guideline related to fairness asks the developer to consider if they have reported evaluation metrics for various groups based on factors such as age, gender, and ethnicity (technique #8 in Table tbl-techniques). This prompts the developer to evaluate whether fairness has been addressed in their AI system. If the developer answers “yes,” they are then prompted to provide specific details on how fairness was implemented. Upon sharing this information, the tool moves the guideline to the “successfully implemented” stack. In contrast, if the developer answers “no,” the tool asks a second follow-up question regarding whether the guideline should be implemented in a future iteration of the AI system. If the developer answers “yes,” they are prompted to provide specific details on how to implement it. The tool then moves the guideline to the “should be considered” stack. However, if the developer answers “no” to both questions, indicating that the guideline is not applicable to their AI system, the tool moves the guideline to the “inapplicable” stack.
The layout of the tool consists of three sections, as shown in Figure fig-ui-sections. In the first section, users can enter the name of the developed AI system (Figure fig-ui-sectionsA) and select the phase it belongs to (Figure fig-ui-sectionsB). Once the phase is selected, the second section displays a stack of guidelines (Figure fig-ui-sectionsC). As users interact with the stack, a counter on the left side color-codes the guidelines and indicates their assignment to the three stacks. The counter also shows the number of remaining guidelines. Blue leaves represent guidelines that have been successfully used, magenta leaves represent guidelines for future considerations, and empty leaves represent inapplicable guidelines. After completing the sorting process, the user is presented with an automatically generated report (available for download as a PDF) that separates the guidelines into the three distinct stacks (Figure fig-ui-sectionsD). If desired, the user can repeat the guideline sorting procedure for other phases (Figure fig-ui-sectionsE).
Evaluating the Tool’s Usability and Revising It
To answer our RQ2 and evaluate the tool, we conducted an interview study with 14 additional AI researchers and developers.
Participants
We recruited participants from the same large research-intensive technology company.[Participants who took part in the formative study were not eligible to participate in this evaluation study.] The recruitment process took place in October and November 2022. All participants had significant expertise in AI, including areas such as machine learning, deep learning, and computer vision. Additionally, each participant was actively involved in at least one ongoing AI project during the time of the interviews. Table tab-demographics summarizes participants’ demographics.
Procedure
Ahead of the interviews, we sent an email to all participants, providing a concise explanation of the study along with a brief demographics survey. The survey consisted of questions regarding participants’ age, domain of expertise, and years of experience in AI system development. The survey is available in Appendix app-demographics-survey. It is important to note that our organization approved the study, and we adhered to established guidelines for user studies, ensuring that no personal identifiers were collected, personal information was removed, and the data remained accessible solely to the research team.
During the interview session, we presented our tool to the participants and allocated 20 minutes (or less if they completed the task sooner) for them to interact with the guidelines. To make the scenario as realistic as possible, we encouraged participants to reflect on their ongoing AI projects and consider how the guidelines could be applied in those specific contexts. Subsequently, we administered the System Usability Scale (SUS)to assess the usability of the tool. We further engaged participants by asking about their preferences, dislikes, and the relevance of the guidelines to their work. We also sought their suggestions for improvements and potential use cases for the tool. The session concluded with a discussion on enhancing the tool’s usability through shared ideas and insights.
We piloted our study with two researchers (1 female, 1 male), which helped us make minor changes to the study guide (e.g., clarifying question-wording and changing the order of questions for a better interview flow). These pilot interviews were not included in the analysis.
Analysis
Two authors conducted an inductive thematic analysis (bottom-up) of the interview transcripts, following established coding methodologies. The authors used sticky notes on the Miro platformto capture the participants’ answers, and collaboratively created affinity diagrams based on these notes. They held seven meetings, totaling 14 hours, to discuss and resolve any disagreements that arose during the analysis process. Feedback from the last author was sought during these meetings. In some cases, a single note was relevant to multiple themes, leading to overlap between themes. All themes included quotes from at least two participants, indicating that data saturation had been achieved. As a result, participant recruitment was concluded after the $14^{\text{th}}$ interview. The resulting themes, along with their corresponding codes, are provided in Table tab-codebook-interviews in the Appendix.
Results
First, we present the results regarding the usability and effectiveness of our tool. Then, we provide feedback from our participants regarding potential improvements to the tool.
Usability and Effectiveness . The guidelines were generally well-received by the participants, with a majority considering them as a valuable tool for raising awareness and facilitating self-learning about responsible AI (12 out of 14 participants). For example, one participant expressed, [P3]It made me reflect on my previous choices and how I would describe my decisions when I had to develop the system. Additionally, seven participants acknowledged the usefulness of the provided examples, which helped them think about potential scenarios and make the guidelines more actionable. Some participants also appreciated the visual simplicity of the guidelines (mentioned by 3 out of 14 participants) and the sequential flow of information, which allowed them to have a more pleasant experience and sufficient time to digest the information (mentioned by 2 out of 14 participants).
Participants, on average, rated the guidelines’ usability with a score of 66 out of 100 in SUS, with a standard deviation of 16.01. This indicates a generally positive user experience. However, participants also identified areas where improvements could be made, which we discuss next.
Improvements.
Although participants found the guidelines to be a valuable starting point for reflection and engagement with AI ethical considerations, they also provided recommendations for improvement. Many participants expressed the desire for guidelines tailored to their specific project and role (10/14): [P6]It would be helpful if the guidelines were tailored to the specific tasks or challenges I encounter in my project, such as processing the data set and seeking feedback from other people. Additionally, five participants suggested making the tool more collaborative, allowing them to engage with other experts and stakeholders: [P1]I appreciated that the guidelines emphasized the importance of seeking support from experts when needed. It would be great if the tool facilitated collaboration and discussions with other stakeholders. Some participants found the tool’s summary to be less useful and were uncertain about its future application (3/14), while others expressed the need to keep the examples visible throughout the process (currently, they disappear after consideration).

Revisions
Based on the feedback, we made three revisions to our tool (Figure fig-prompts-revision). That is, we: a) added roles; b) implemented features to foster collaboration; and c) improved user experience.
Adding Roles. To assign roles to each guideline (Table tbl-techniques-roles in the Appendix), we referred to previous literature that focused on understanding the best practices of AI practitioners and the development and evaluation of responsible AI toolkits. Wang et al.interviewed UX practitioners and responsible AI experts to understand their work practices. UX practitioners included designers, researchers, and engineers, while responsible AI experts included ethics advisors and specialists. Wong et al.analyzed 27 ethics toolkits to identify the intended audience of these toolkits, specifically those who are expected to engage in AI ethics work. The intended audience roles identified included software engineers, data scientists, designers, members of cross-functional or cross-disciplinary teams, risk or internal governance teams, C-level executives, and board members. Additionally, Madaio et al.co-designed a fairness checklist with a diverse set of stakeholders, including product managers, data scientists and AI/ML engineers, designers, software engineers, researchers, and consultants. Following guidance therefore from these studies, we formulated three roles as follows:
-
Decision-maker or Advisor: This role includes individuals such as product managers, C-suite executives, ethics advisors/responsible AI consultants, and ethical board members.
-
Engineer or Researcher: This role includes AI/ML engineers, AI/ML researchers, data scientists, software engineers, UX engineers, and UX researchers.
-
Designer: This role includes interaction designers and UX designers.
Fostering Collaboration. Our participants also recognized the potential to enhance the collaborative nature of the tool, allowing them to share knowledge with other stakeholders. To achieve this, we implemented two user interface features. First, we introduced a feature that enables users to keep a history of their interactions with the tool by revising their answers and tracking the changes made. When users revise the content of the guidelines, the newly generated content is stored in a “responsible AI knowledge base.” This functionality allows distributed teams to leverage this content, fostering a shared understanding of the project at hand. Additionally, the interface utilizes color coding to indicate the relevance or irrelevance of guidelines at different points in time. Second, we redesigned the PDF summary to include responsible AI blindspots, which encompass specific actions to be taken and shared among the development team. This improvement enhances the utility of the summary by highlighting areas that require attention and providing actionable insights.
Improving User Experience. While our participants appreciated the simplicity of the user interface, we modified our initial idea of mimicking physical interactions, such as flipping. This decision was made based on feedback from users who found it challenging to remember the guideline while writing the corresponding action after the guideline was flipped. Instead, in the revised version of the tool, we adopted a simplified approach. Both the guideline and its corresponding example(s) are now visible at all times to ensure better usability. We achieved this by dividing each guideline into two side-by-side parts: the left side displays the guideline, while the right side presents its examples in interactive boxes. By making both the guideline and examples consistently visible, users can easily refer to the information they need while formulating their responses. This design change aims to improve the user experience and enhance the effectiveness of the tool in guiding responsible AI practices.
Discussion
To assist AI practitioners in navigating the rapidly evolving landscape of AI ethics, governance, and regulations, we have developed a method for generating actionable guidelines for responsible AI. This method enables easy updates of guidelines based on research papers and ISO standards, ensuring that the content remains relevant and up-to-date. We validated this method through a use case study at a large tech company, where we designed and evaluated a tool that uses our responsible AI guidelines. We conducted a formative study involving 10 AI practitioners to design the tool, and further evaluated it through an interview study with an additional 14 AI practitioners. The results indicate that the guidelines were perceived as practical and actionable, promoting self-reflection and enhancing understanding of the ethical considerations associated with AI during the early stages of development. In light of these results, we discuss how our method contributes to the idea of “Responsible AI by Design”, that is, a design-first approach that considers responsible AI values throughout the development lifecycle and across business roles. We discuss the inherent problem of decontextualization in responsible AI toolkits, the concept of meta-responsibility, and provide practical recommendations for designing responsible AI toolkits with the aim of fostering collaboration and enabling organizational accountability.
Theoretical Implications
Decontextualization
The inherent challenge in responsible AI toolkits lies in their attempt to reconcile the tension between scalability and context specificity. Traditional approaches to toolkit development have often favored a universal, top-down approach that assumes a one-size-fits-all solution. However, participatory development, such as the methodology we followed in designing and populating a responsible AI toolkit with our guidelines, emphasizes the importance of tailoring responsible AI guidelines to specific contexts and job roles needs. It is crucial therefore to recognize that different AI practitioners, such as designers, developers, engineers, and advisors, have distinct requirements and considerations that cannot be treated as identical. This highlights the complexity of developing toolkits that cater to a diverse range of practitioners while accounting for their unique roles and settings—the problem of decontextualization in responsible AI toolkits.
To tackle the problem of decontextualization, our proposed method incorporates two key elements: actionable guidelines and follow-up questions . Firstly, the integration of actionable guidelines, tailored to different roles and projects, provides practical steps and recommendations that technical practitioners can easily implement, or C-level executives can make informed decisions upon. These guidelines serve as a starting point for ethical decision-making throughout the AI lifecycle, contributing to the vision of responsible AI by design (borrowing from the idea of `privacy by design’[“Privacy by design” is a standard practice for incorporating data protection into the design of technology. In other words, data protection is achieved when it is already integrated into the technology during its design and development.]). Secondly, the inclusion of follow-up questions enhances our toolkit’s ability to capture the complexities of different social and organizational contexts. Expanding upon the concept that follow-up questions are an effective means of communication, as they help in gaining deeper insights, clarifying responses, and uncovering underlying meanings, AI practitioners can engage with these questions to explore the ethical considerations and challenges that are unique to their deployment context.
Meta-responsibility
Scholars have long recognized the need for a socio-technical approach that considers the contextual factors governing the use of AI systems, including social, organizational, and cultural factors. In fact, Ackermanintroduced the concept of socio-technical gap to highlight the disparity between human requirements in technology deployment contexts (socio-requirements) and the technical solutions. This gap arises due to the flexible and nuanced nature of human activity compared to the rigid and brittle nature of computational mechanisms, resulting from necessary formalization and abstraction. Along these lines,introduced the concept of meta-responsibility to stress that AI systems should be viewed as systems of systems (ecosystems) rather than single entities. To establish a regime of meta-responsibility, Stahl argued for an adaptive governance structure to effectively respond to new insights and external influences (e.g., upcoming AI regulation), and for a knowledge base that equips AI stakeholders with technical, ethical, legal, and social understanding. By integrating ethical, legal, and social knowledge into the AI development process—what Stahl referred to as adaptive governance structure, and offering recommendations for areas that require additional attention (i.e., responsible AI blindspots), our work contribute to this line of research by providing empirical evidence to it and pushing the theoretical boundaries further.
Practical Implications
Recommendations for designing responsible AI toolkits
Our responsible AI guidelines, populated in a usable tool, leverage the concept of nudging to encourage users to consider the ethical implications of AI systems. Nudging has demonstrated effectiveness in various domains, such as mitigating the dissemination of misinformation on social media through the use of checklists, or guiding users towards more private and secure choices.
Nudges can be implemented in various ways. For instance, the confront type of nudge incorporates elements of “reminding consequences” and “providing multiple viewpoints,” encouraging users to consider alternative directions and diverse perspectives. In the case of our guidelines, these two concepts are utilized to remind AI developers about the ethical considerations of AI systems and to prompt them to think critically about alternative viewpoints, thus helping them avoid confirmation bias. Further research could explore additional types of nudges, such as incorporating visual cues (e.g., just-in-time nudges within development tools), facilitating positive behavior (e.g., enabling social comparisons by recognizing and appreciating developers who promote ethical values within the organization), or fostering empathy (e.g., instigating empathy by presenting the environmental impact of an AI system through easily understandable animations).
While the format of our tool proved to be useful, it offers a starting point to explore other formats and interactions for populating and contextualizing the guidelines. For example, structuring the guidelines into a narrative might be useful to unpack the complexity of particularly complex guidelines, such as guideline #15—ensuring compliance with agreements and legal requirements when handling data. This guideline can be further sub-divided into sequential steps providing more context and explanations. Moreover, future responsible AI tools can incorporate configurable parameters or customization widgets to align with specific requirements of the developed AI systems or user preferences. Additionally, the use of Language Models (LLMs) can be explored to further customize and adapt the provided examples within the tool. Finally, more research can be done on exploring responsible AI tools as a method for artifact creation. This includes automatic generation of summary reports, model cards, or responsible AI certificates.
Recommendations for fostering collaboration and enabling organizational accountability
While individual adoption of responsible AI best practices is crucial, promoting collaboration among diverse AI stakeholders is equally important. Many existing responsible AI toolkits prioritize individual usage. However, addressing complex ethical and societal challenges associated with AI systems requires collaborative actions. Our interactive tool populated with actionable guidelines addresses this need by offering features that facilitate collaboration. First, the tool stores users’ inputs in a responsible AI knowledge base, enabling distributed teams to access and leverage this knowledge for a shared understanding of a particular AI system. This promotes collaboration and a collective approach to ethical considerations. Second, the tool automatically generates a report that summarizes the user’s considerations. This report can be downloaded as a PDF and includes responsible AI blindspots, which are specific actions to be taken by individuals or shared among the development team. Highlighting these blindspots fosters awareness and prompts collective action towards responsible AI practices.
In addition to fostering collaboration, our interactive tool can be used to enable organizational accountability. Similar to Google’s five-stage internal algorithmic auditing framework, our guidelines serve as a practical tool for closing the AI accountability gap. The automatically generated report plays a crucial role in this process by providing a summary of the guidelines that were effectively implemented, those that should be considered for future development, and the non-applicable ones. These reports establish an additional chain of accountability that can be shared with stakeholders at various levels, including managers, senior leadership, and AI engineers. By offering more oversight and the ability to troubleshoot if needed, these reports help mitigate unintentional harm. However, it is important to note that when an organization adopts our guidelines, it should establish clear ethical guidelines for their intended uses. Our tool is not intended to discourage developers from using it due to the fear of being held accountable for their responses. On the contrary, developers’ responses, as documented in the report, provide an opportunity to identify potential ethical issues and address them early in the design stages. This proactive approach prevents the need for post-hoc fixes and repairs, aligning with the principle of addressing ethical considerations during the development process rather than as an afterthought—the idea of Responsible AI by Design .
Limitations and Future Work
Our work has four main limitations that highlight the need for future research efforts.
Firstly, although we followed a rigorous four-step process involving multiple stakeholders, the list of 22 guidelines may not be exhaustive. The rapidly evolving nature of AI ethics, governance, and regulations necessitates an ongoing effort to stay abreast of emerging developments. However, one of the strengths of our method lies in its modular design, which allows for ongoing refinement and expansion of the set of guidelines. This ensures that our responsible AI tool maintains its relevance and stays up to date in the ever-evolving landscape of AI ethics, governance, and regulations. As new ISOs are established, addressing specific aspects of AI systems such as functional safety (ISO 5469), data quality (ISO 5259), and explainability (ISO 6254), our tool can be readily extended to include these guidelines. Moreover, as the scientific community progresses in its understanding of ethical considerations in AI, our tool can incorporate new insights and recommendations to enhance its comprehensive coverage.
Secondly, it is important to consider the qualitative nature of our user study, which involved in-depth interviews and analysis of participants’ responses. The findings from this study should be interpreted with caution, understanding that the reported frequency of themes should be viewed in a comparative context rather than taken at face value. This approach helps to avoid potential misinterpretation or overgeneralization of the results.
Thirdly, we need to acknowledge the limitations associated with the sample size and demographics of our user study. The study was conducted with a specific group of participants, and therefore, the findings may not fully represent the practices and perspectives of all AI practitioners. Our sample predominantly consisted of male participants, which aligns with the gender distribution reported in Stack Overflow’s 2022 Developer Survey, where 92.85% of professional developer respondents identified as male. Additionally, our participants were drawn from a large research-focused technology company. While the results may offer insights into practices within certain companies, they serve as a case study for future research. Furthermore, we did not explicitly consider participants’ specific roles, despite their expertise spanning various domains and levels. Future studies could explore the considerations of ethical values in AI systems across organizations and different roles and areas of expertise. Previous research has indicated different understandings of responsible AI values between practitioners and the general public, suggesting the potential for similar research methods to be applied in this area.
Last but not least, our qualitative data suggests indicators of ease of use for AI practitioners but does not provide direct information on the actual effectiveness of the guidelines. Understanding the impact of guidelines (or other AI toolkits) requires long-term studies that consider multiple projects, with some utilizing the toolkit and others not. One potential avenue, as suggested by clinical researchers developing deep learning tools for patient care, is to conduct observational studies with users of the AI system to assess its performance. Another approach is to use proxies, such as measuring users’ attitudes, beliefs, and mindset regarding ethical values before and after utilizing the guidelines. We intend to explore these directions in future research.
Conclusion
We proposed a method that allows for easy updating of responsible AI guidelines derived from research papers and ISO standards, ensuring that the content of responsible AI tools remains relevant and up to date. To validate the effectiveness of our method, we developed and deployed an interactive tool that provides actionable guidelines, which were generated by a team comprising engineers, standardization experts, and a lawyer. Our findings indicate that the guidelines were well-received, as they were perceived as practical and actionable, fostering self-reflection and facilitating a deeper understanding of the ethical considerations associated with AI during the initial phases of design and development.
Additional Materials For the User Study
- How old are you?
- What is your gender? [Male, Female, Non-binary, Prefer not to say, Open-ended option]
- How many years of experience do you have in AI systems?
- What’s your educational background?
- In which country do you currently reside?
- What is domain or sector of your work? (e.g., health, energy, education, finance, technology, food)
- What kinds of AI systems do you work on? (e.g., machine learning, computer vision, NLP, game theory, robotics)
Constructed themes for the user study.
Table Label: tab-codebook-interviews
Download PDF to view tableResponsible AI Guidelines and Roles
Responsible AI Guidelines and Roles. Each guideline has been assigned to one or more relevant roles. Based on previous literature, we have identified three main roles: a) decision-maker or advisor; b) engineer or researcher; and c) designer. The label `All’ indicates that a given guideline is applicable to all three roles.
Table Label: tbl-techniques-roles
Download PDF to view tableBibliography
1@article{cavoukian2009privacy,
2 numpages = {5},
3 url = {https://iab.org/wp-content/IAB-uploads/2011/03/fred_carter.pdf},
4 volume = {5},
5 journal = {Information and privacy commissioner of Ontario, Canada},
6 year = {2009},
7 author = {Cavoukian, Ann},
8 title = {Privacy by Design: The 7 Foundational Principles},
9}
10
11@article{cavoukian2010privacy,
12 url = {10.1007/s12394-010-0053-z},
13 doi = {10.1007/s12394-010-0053-z},
14 pages = {405--413},
15 number = {2},
16 volume = {3},
17 journal = {Identity in the Information Society},
18 day = {01},
19 month = {August},
20 year = {2010},
21 author = {Cavoukian, Ann and Taylor, Scott and Abrams, Martin E.},
22 title = {Privacy by Design: essential for organizational accountability and strong business practices},
23}
24
25@inproceedings{maurice2022how,
26 numpages = {14},
27 doi = {10.1145/3531146.3533097},
28 pages = {310--323},
29 series = {FAccT '22},
30 publisher = {ACM},
31 booktitle = {2022 ACM Conference on Fairness, Accountability, and Transparency},
32 year = {2022},
33 author = {Jakesch, Maurice and Bu\c{c}inca, Zana and Amershi, Saleema and Olteanu, Alexandra},
34 title = {How Different Groups Prioritize Ethical Values for Responsible AI},
35}
36
37@inproceedings{beede2020human,
38 numpages = {12},
39 url = {https://doi.org/10.1145/3313831.3376718},
40 isbn = {9781450367080},
41 doi = {10.1145/3313831.3376718},
42 pages = {1–12},
43 series = {CHI '20},
44 publisher = {ACM},
45 booktitle = {Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems},
46 year = {2020},
47 author = {Beede, Emma and Baylor, Elizabeth and Hersch, Fred and Iurchenko, Anna and Wilcox, Lauren and Ruamviboonsuk, Paisan and Vardoulakis, Laura M.},
48 title = {{A Human-Centered Evaluation of a Deep Learning System Deployed in Clinics for the Detection of Diabetic Retinopathy}},
49}
50
51@inproceedings{havens2020situated,
52 url = {https://aclanthology.org/2020.gebnlp-1.10},
53 pages = {107--124},
54 publisher = {Association for Computational Linguistics},
55 booktitle = {Proceedings of the Second Workshop on Gender Bias in Natural Language Processing},
56 month = {December},
57 year = {2020},
58 author = {Havens, Lucy and Terras, Melissa and Bach, Benjamin and Alex, Beatrice},
59 title = {Situated Data, Situated Systems: A Methodology to Engage with Power Relations in Natural Language Processing Research},
60}
61
62@article{acquisti2017nudges,
63 numpages = {41},
64 issue_date = {May 2018},
65 url = {https://doi.org/10.1145/3054926},
66 doi = {10.1145/3054926},
67 number = {3},
68 volume = {50},
69 publisher = {ACM},
70 journal = {ACM Comput. Surv.},
71 month = {aug},
72 year = {2017},
73 author = {Acquisti, Alessandro and Adjerid, Idris and Balebako, Rebecca and Brandimarte, Laura and Cranor, Lorrie Faith and Komanduri, Saranga and Leon, Pedro Giovanni and Sadeh, Norman and Schaub, Florian and Sleeper, Manya and Wang, Yang and Wilson, Shomir},
74 title = {{Nudges for Privacy and Security: Understanding and Assisting Users’ Choices Online}},
75}
76
77@article{arrieta2020explainable,
78 doi = {10.1016/j.inffus.2019.12.012},
79 pages = {82--115},
80 volume = {58},
81 publisher = {Elsevier},
82 journal = {Information fusion},
83 year = {2020},
84 author = {Arrieta, Alejandro Barredo and D{\'\i}az-Rodr{\'\i}guez, Natalia and Del Ser, Javier and Bennetot, Adrien and Tabik, Siham and Barbado, Alberto and Garc{\'\i}a, Salvador and Gil-L{\'o}pez, Sergio and Molina, Daniel and Benjamins, Richard and others},
85 title = {{Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI}},
86}
87
88@article{arya2019one,
89 journal = {arXiv preprint arXiv:1909.03012},
90 year = {2019},
91 author = {Arya, Vijay and Bellamy, Rachel KE and Chen, Pin-Yu and Dhurandhar, Amit and Hind, Michael and Hoffman, Samuel C and Houde, Stephanie and Liao, Q Vera and Luss, Ronny and Mojsilovi{\'c}, Aleksandra and others},
92 title = {{One Explanation Does Not Fit All: A Toolkit And Taxonomy Of AI Explainability Techniques}},
93}
94
95@article{baeza2018bias,
96 doi = {10.1145/3209581},
97 pages = {54--61},
98 number = {6},
99 volume = {61},
100 publisher = {ACM},
101 journal = {Communications of the ACM},
102 year = {2018},
103 author = {Baeza-Yates, Ricardo},
104 title = {{Bias on the web}},
105}
106
107@article{bender2018data,
108 url = {https://aclanthology.org/Q18-1041},
109 doi = {10.1162/tacl_a_00041},
110 pages = {587--604},
111 volume = {6},
112 publisher = {MIT Press},
113 journal = {Transactions of the Association for Computational Linguistics},
114 year = {2018},
115 author = {Bender, Emily M. and Friedman, Batya},
116 title = {{Data Statements for Natural Language Processing: Toward Mitigating System Bias and Enabling Better Science}},
117}
118
119@techreport{bird2020fairlearn,
120 institution = {Microsoft},
121 url = {https://www.microsoft.com/en-us/research/publication/fairlearn-a-toolkit-for-assessing-and-improving-fairness-in-ai/},
122 month = {May},
123 year = {2020},
124 author = {Bird, Sarah and Dudík, Miro and Edgar, Richard and Horn, Brandon and Lutz, Roman and Milan, Vanessa and Sameki, Mehrnoosh and Wallach, Hanna and Walker, Kathleen},
125 title = {{Fairlearn: A toolkit for assessing and improving fairness in AI}},
126}
127
128@article{braun2006thematic,
129 doi = {10.1191/1478088706qp063oa},
130 pages = {77--101},
131 number = {2},
132 volume = {3},
133 publisher = {Routledge},
134 journal = {Qualitative Research in Psychology},
135 year = {2006},
136 author = {Virginia Braun and Victoria Clarke},
137 title = {{Using thematic analysis in psychology}},
138}
139
140@article{brooke1996sus,
141 pages = {4--7},
142 number = {194},
143 volume = {189},
144 journal = {Usability Evaluation in Industry},
145 year = {1996},
146 author = {Brooke, John and others},
147 title = {{SUS: A ``Quick and Dirty'' Usability Scale}},
148}
149
150@inproceedings{buolamwini2018gender,
151 organization = {PMLR},
152 url = {https://proceedings.mlr.press/v81/buolamwini18a.html},
153 pages = {77--91},
154 booktitle = {Conference on fairness, accountability and transparency},
155 year = {2018},
156 author = {Buolamwini, Joy and Gebru, Timnit},
157 title = {{Gender shades: Intersectional accuracy disparities in commercial gender classification}},
158}
159
160@inproceedings{caraban2019ways,
161 numpages = {15},
162 url = {https://doi.org/10.1145/3290605.3300733},
163 doi = {10.1145/3290605.3300733},
164 pages = {1–15},
165 series = {CHI '19},
166 publisher = {ACM},
167 booktitle = {Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems},
168 year = {2019},
169 author = {Caraban, Ana and Karapanos, Evangelos and Gon\c{c}alves, Daniel and Campos, Pedro},
170 title = {{23 Ways to Nudge: A Review of Technology-Mediated Nudging in Human-Computer Interaction}},
171}
172
173@article{cardInteractions_2020,
174 pages = {88--101},
175 number = {3},
176 volume = {12},
177 publisher = {University of Rhode Island},
178 journal = {Media Literacy Education},
179 year = {2020},
180 author = {Stefan Werning},
181 title = {{Making data playable: a game co-creation method to promote creative data literacy}},
182}
183
184@article{collins2015transparent,
185 doi = {10.1161/CIRCULATIONAHA.114.014508},
186 pages = {148--158},
187 number = {3},
188 volume = {102},
189 publisher = {Oxford University Press},
190 journal = {Journal of British Surgery},
191 year = {2015},
192 author = {Collins, Gary S and Reitsma, Johannes B and Altman, Douglas G and Moons, Karel GM},
193 title = {{Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): the TRIPOD statement}},
194}
195
196@inproceedings{cramer2019translation,
197 doi = {10.1145/3290607.3299057},
198 pages = {1--8},
199 booktitle = {Extended Abstracts of the 2019 CHI Conference on Human Factors in Computing Systems},
200 year = {2019},
201 author = {Cramer, Henriette and Garcia-Gathright, Jean and Reddy, Sravana and Springer, Aaron and Takeo Bouyer, Romain},
202 title = {{Translation, tracks \& data: an algorithmic bias effort in practice}},
203}
204
205@article{dittus2017community,
206 doi = {10.1145/3134674},
207 pages = {1--22},
208 number = {CSCW},
209 volume = {1},
210 publisher = {ACM},
211 journal = {Proc. of the ACM on Human-Computer Interaction},
212 year = {2017},
213 author = {Dittus, Martin and Aiello, Luca Maria and Quercia, Daniele},
214 title = {{Community engagement triage: lightweight prompts for systematic reviews}},
215}
216
217@inproceedings{dixon2018measuring,
218 doi = {10.1145/3278721.3278729},
219 pages = {67--73},
220 booktitle = {Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society},
221 year = {2018},
222 author = {Dixon, Lucas and Li, John and Sorensen, Jeffrey and Thain, Nithum and Vasserman, Lucy},
223 title = {{Measuring and mitigating unintended bias in text classification}},
224}
225
226@inproceedings{dworkdifferential,
227 doi = {10.1007/978-3-540-79228-4_1},
228 pages = {1--19},
229 publisher = {Springer},
230 booktitle = {Theory and Applications of Models of Computation},
231 year = {2008},
232 author = {Dwork, Cynthia},
233 title = {{Differential Privacy: A Survey of Results}},
234}
235
236@article{fjeld2020principled,
237 doi = {10.2139/ssrn.3518482},
238 number = {2020-1},
239 journal = {Berkman Klein Center Research Publication},
240 year = {2020},
241 author = {Fjeld, Jessica and Achten, Nele and Hilligoss, Hannah and Nagy, Adam and Srikumar, Madhulika},
242 title = {{Principled artificial intelligence: Mapping consensus in ethical and rights-based approaches to principles for AI}},
243}
244
245@inproceedings{foulds2020intersectional,
246 organization = {IEEE},
247 doi = {10.1109/ICDE48307.2020.00203},
248 pages = {1918--1921},
249 booktitle = {2020 IEEE 36th International Conference on Data Engineering (ICDE)},
250 year = {2020},
251 author = {Foulds, James R and Islam, Rashidul and Keya, Kamrun Naher and Pan, Shimei},
252 title = {{An intersectional definition of fairness}},
253}
254
255@article{gebru2021datasheets,
256 numpages = {7},
257 issue_date = {December 2021},
258 doi = {10.1145/3458723},
259 pages = {86–-92},
260 number = {12},
261 volume = {64},
262 publisher = {ACM},
263 journal = {Commun. ACM},
264 month = {nov},
265 year = {2021},
266 author = {Gebru, Timnit and Morgenstern, Jamie and Vecchione, Briana and Vaughan, Jennifer Wortman and Wallach, Hanna and III, Hal Daum\'{e} and Crawford, Kate},
267 title = {{Datasheets for Datasets}},
268}
269
270@article{hao2019training,
271 url = {https://www.technologyreview.com/2019/06/06/239031/training-a-single-ai-model-can-emit-as-much-carbon-as-five-cars-in-their-lifetimes/},
272 journal = {MIT technology Review},
273 year = {2019},
274 author = {Hao, Karen},
275 title = {{Training a single AI model can emit as much carbon as five cars in their lifetimes}},
276}
277
278@article{hardt2016equality,
279 url = {https://proceedings.neurips.cc/paper_files/paper/2016/file/9d2682367c3935defcb1f9e247a97c0d-Paper.pdf},
280 volume = {29},
281 journal = {Advances in neural information processing systems},
282 year = {2016},
283 author = {Hardt, Moritz and Price, Eric and Srebro, Nati},
284 title = {{Equality of opportunity in supervised learning}},
285}
286
287@article{holland2018dataset,
288 journal = {arXiv preprint arXiv:1805.03677},
289 year = {2018},
290 author = {Holland, Sarah and Hosny, Ahmed and Newman, Sarah and Joseph, Joshua and Chmielinski, Kasia},
291 title = {{The dataset nutrition label: A framework to drive higher data quality standards}},
292}
293
294@article{jahanbakhsh2021exploring,
295 numpages = {42},
296 issue_date = {April 2021},
297 url = {https://doi.org/10.1145/3449092},
298 doi = {10.1145/3449092},
299 number = {CSCW1},
300 volume = {5},
301 publisher = {ACM},
302 journal = {Proc. ACM Hum.-Comput. Interact.},
303 month = {apr},
304 year = {2021},
305 author = {Jahanbakhsh, Farnaz and Zhang, Amy X. and Berinsky, Adam J. and Pennycook, Gordon and Rand, David G. and Karger, David R.},
306 title = {{Exploring Lightweight Interventions at Posting Time to Reduce the Sharing of Misinformation on Social Media}},
307}
308
309@article{jobin2019global,
310 doi = {10.1038/s42256-019-0088-2},
311 pages = {389--399},
312 number = {9},
313 volume = {1},
314 publisher = {Nature Publishing Group},
315 journal = {Nature Machine Intelligence},
316 year = {2019},
317 author = {Jobin, Anna and Ienca, Marcello and Vayena, Effy},
318 title = {{The global landscape of AI ethics guidelines}},
319}
320
321@book{kissinger2021age,
322 publisher = {John Murray London},
323 year = {2021},
324 author = {Kissinger, Henry and Schmidt, Eric and Huttenlocher, Daniel P},
325 title = {{The age of AI: And our human future}},
326}
327
328@inproceedings{kulesza2015principles,
329 doi = {10.1145/2678025.2701399},
330 pages = {126--137},
331 booktitle = {Proceedings of the 20th international conference on intelligent user interfaces},
332 year = {2015},
333 author = {Kulesza, Todd and Burnett, Margaret and Wong, Weng-Keen and Stumpf, Simone},
334 title = {{Principles of explanatory debugging to personalize interactive machine learning}},
335}
336
337@article{lundberg2017unified,
338 url = {https://proceedings.neurips.cc/paper_files/paper/2017/file/8a20a8621978632d76c43dfd28b67767-Paper.pdf},
339 volume = {30},
340 journal = {Advances in neural information processing systems},
341 year = {2017},
342 author = {Lundberg, Scott M and Lee, Su-In},
343 title = {{A unified approach to interpreting model predictions}},
344}
345
346@inproceedings{madaio2020co,
347 pages = {1--14},
348 booktitle = {Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems},
349 year = {2020},
350 author = {Madaio, Michael A and Stark, Luke and Wortman Vaughan, Jennifer and Wallach, Hanna},
351 title = {{Co-designing checklists to understand organizational challenges and opportunities around fairness in AI}},
352}
353
354@article{mcdonald2019reliability,
355 numpages = {23},
356 issue_date = {November 2019},
357 url = {https://doi.org/10.1145/3359174},
358 doi = {10.1145/3359174},
359 volume = {3},
360 publisher = {ACM},
361 journal = {Proc. ACM Hum.-Comput. Interact.},
362 month = {nov},
363 year = {2019},
364 author = {McDonald, Nora and Schoenebeck, Sarita and Forte, Andrea},
365 title = {{Reliability and Inter-Rater Reliability in Qualitative Research: Norms and Guidelines for CSCW and HCI Practice}},
366}
367
368@article{michie2013behavior,
369 doi = {10.1007/s12160-013-9486-6},
370 number = {1},
371 volume = {46},
372 publisher = {Springer},
373 journal = {Annals of Behavioral Medicine},
374 year = {2013},
375 author = {Michie, Susan and Richardson, Michelle and Johnston, Marie and Abraham, Charles and Francis, Jill and Hardeman, Wendy and Eccles, Martin and Cane, James and Wood, Caroline},
376 title = {{The behavior change technique taxonomy (v1) of 93 hierarchically clustered techniques}},
377}
378
379@book{miles1994qualitative,
380 publisher = {Sage},
381 year = {1994},
382 author = {Miles, Matthew and Huberman, Michael},
383 title = {{Qualitative Data Analysis: A Methods Sourcebook}},
384}
385
386@article{mitchell2018prediction,
387 journal = {arXiv preprint arXiv:1811.07867},
388 year = {2018},
389 author = {Mitchell, Shira and Potash, Eric and Barocas, Solon and D'Amour, Alexander and Lum, Kristian},
390 title = {{Prediction-based decisions and fairness: A catalogue of choices, assumptions, and definitions}},
391}
392
393@inproceedings{mitchell2019model,
394 numpages = {10},
395 url = {https://doi.org/10.1145/3287560.3287596},
396 doi = {10.1145/3287560.3287596},
397 pages = {220–229},
398 series = {FAT* '19},
399 publisher = {ACM},
400 booktitle = {Proceedings of the Conference on Fairness, Accountability, and Transparency},
401 year = {2019},
402 author = {Mitchell, Margaret and Wu, Simone and Zaldivar, Andrew and Barnes, Parker and Vasserman, Lucy and Hutchinson, Ben and Spitzer, Elena and Raji, Inioluwa Deborah and Gebru, Timnit},
403 title = {{Model Cards for Model Reporting}},
404}
405
406@inproceedings{raji2020closing,
407 pages = {33--44},
408 booktitle = {Proceedings of the 2020 conference on fairness, accountability, and transparency},
409 year = {2020},
410 author = {Raji, Inioluwa Deborah and Smart, Andrew and White, Rebecca N and Mitchell, Margaret and Gebru, Timnit and Hutchinson, Ben and Smith-Loud, Jamila and Theron, Daniel and Barnes, Parker},
411 title = {{Closing the AI accountability gap: Defining an end-to-end framework for internal algorithmic auditing}},
412}
413
414@article{rakova2021responsible,
415 doi = {10.1145/3449081},
416 pages = {1--23},
417 volume = {5},
418 publisher = {ACM},
419 journal = {Proceedings of the ACM on Human-Computer Interaction},
420 year = {2021},
421 author = {Rakova, Bogdana and Yang, Jingying and Cramer, Henriette and Chowdhury, Rumman},
422 title = {{Where responsible AI meets reality: Practitioner perspectives on enablers for shifting organizational practices}},
423}
424
425@inproceedings{ribeiro2016should,
426 doi = {10.1145/2939672.2939778},
427 pages = {1135--1144},
428 booktitle = {Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining},
429 year = {2016},
430 author = {Ribeiro, Marco Tulio and Singh, Sameer and Guestrin, Carlos},
431 title = {{``Why should i trust you?'' Explaining the predictions of any classifier}},
432}
433
434@book{saldana2015coding,
435 publisher = {Sage},
436 year = {2015},
437 author = {Salda{\~n}a, Johnny},
438 title = {{The Coding Manual for Qualitative Researchers}},
439}
440
441@article{saleiro2018aequitas,
442 journal = {arXiv preprint arXiv:1811.05577},
443 year = {2018},
444 author = {Saleiro, Pedro and Kuester, Benedict and Hinkson, Loren and London, Jesse and Stevens, Abby and Anisfeld, Ari and Rodolfa, Kit T and Ghani, Rayid},
445 title = {{Aequitas: A bias and fairness audit toolkit}},
446}
447
448@article{sharir2020cost,
449 journal = {arXiv preprint arXiv:2004.08900},
450 year = {2020},
451 author = {Sharir, Or and Peleg, Barak and Shoham, Yoav},
452 title = {{The cost of training nlp models: A concise overview}},
453}
454
455@article{shneiderman2020bridging,
456 doi = {10.1145/3419764},
457 pages = {1--31},
458 number = {4},
459 volume = {10},
460 publisher = {ACM},
461 journal = {ACM Transactions on Interactive Intelligent Systems (TiiS)},
462 year = {2020},
463 author = {Shneiderman, Ben},
464 title = {{Bridging the gap between ethics and practice: guidelines for reliable, safe, and trustworthy human-centered AI systems}},
465}
466
467@article{shneiderman2021responsible,
468 doi = {10.1145/3445973},
469 pages = {32--35},
470 number = {8},
471 volume = {64},
472 publisher = {ACM},
473 journal = {Communications of the ACM},
474 year = {2021},
475 author = {Shneiderman, Ben},
476 title = {{Responsible AI: Bridging from ethics to practice}},
477}
478
479@article{strubell2019energy,
480 doi = {10.1609/aaai.v34i09.7123},
481 pages = {13693--13696},
482 number = {09},
483 volume = {34},
484 journal = {Proceedings of the AAAI Conference on Artificial Intelligence},
485 month = {Apr.},
486 year = {2020},
487 author = {Strubell, Emma and Ganesh, Ananya and McCallum, Andrew},
488 title = {{Energy and Policy Considerations for Modern Deep Learning Research}},
489}
490
491@inproceedings{tahaei2021deciding,
492 numpages = {24},
493 url = {https://www.usenix.org/conference/soups2021/presentation/tahaei},
494 publisher = {{USENIX Association}},
495 booktitle = {{Seventeenth Symposium on Usable Privacy and Security (SOUPS '21)}},
496 year = {2021},
497 author = {Tahaei, Mohammad and Frik, Alisa and Vaniea, Kami},
498 title = {{Deciding on Personalized Ads: Nudging Developers About User Privacy}},
499}
500
501@article{toolkitReview_2022,
502 doi = {10.48550/ARXIV.2202.08792},
503 publisher = {arXiv},
504 year = {2022},
505 author = {Wong, Richmond Y. and Madaio, Michael A. and Merrill, Nick},
506 title = {Seeing Like a Toolkit: How Toolkits Envision the Work of AI Ethics},
507}
508
509@inproceedings{verma2018fairness,
510 organization = {IEEE},
511 pages = {1--7},
512 booktitle = {2018 ieee/acm international workshop on software fairness (fairware)},
513 year = {2018},
514 author = {Verma, Sahil and Rubin, Julia},
515 title = {{Fairness definitions explained}},
516}
517
518@inproceedings{wang2020revise,
519 organization = {Springer},
520 doi = {10.1007/s11263-022-01625-5},
521 pages = {733--751},
522 booktitle = {European Conference on Computer Vision},
523 year = {2020},
524 author = {Wang, Angelina and Narayanan, Arvind and Russakovsky, Olga},
525 title = {{REVISE: A tool for measuring and mitigating bias in visual datasets}},
526}
527
528@inproceedings{zemel2013learning,
529 organization = {PMLR},
530 url = {https://proceedings.mlr.press/v28/zemel13.html},
531 pages = {325--333},
532 booktitle = {International conference on machine learning},
533 year = {2013},
534 author = {Zemel, Rich and Wu, Yu and Swersky, Kevin and Pitassi, Toni and Dwork, Cynthia},
535 title = {{Learning fair representations}},
536}
537
538@inproceedings{zhang2018mitigating,
539 doi = {10.1145/3278721.3278779},
540 pages = {335--340},
541 booktitle = {Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society},
542 year = {2018},
543 author = {Zhang, Brian Hu and Lemoine, Blake and Mitchell, Margaret},
544 title = {{Mitigating unwanted biases with adversarial learning}},
545}
546
547@article{sambasivan2018toward,
548 doi = {10.1145/3298735},
549 pages = {68--71},
550 number = {1},
551 volume = {26},
552 publisher = {ACM},
553 journal = {Interactions},
554 year = {2018},
555 author = {Sambasivan, Nithya and Holbrook, Jess},
556 title = {Toward responsible AI for the next billion users},
557}
558
559@article{frluckaj2022gender,
560 doi = {10.1145/3555190},
561 pages = {1--31},
562 number = {CSCW2},
563 volume = {6},
564 publisher = {ACM},
565 journal = {Proceedings of the ACM on Human-Computer Interaction},
566 year = {2022},
567 author = {Frluckaj, Hana and Dabbish, Laura and Widder, David Gray and Qiu, Huilian Sophie and Herbsleb, James},
568 title = {Gender and Participation in Open Source Software Development},
569}
570
571@article{mittelstadt2016ethics,
572 doi = {10.1177/2053951716679679},
573 pages = {2053951716679679},
574 number = {2},
575 volume = {3},
576 publisher = {Sage},
577 journal = {Big Data \& Society},
578 year = {2016},
579 author = {Mittelstadt, Brent Daniel and Allo, Patrick and Taddeo, Mariarosaria and Wachter, Sandra and Floridi, Luciano},
580 title = {The ethics of algorithms: Mapping the debate},
581}
582
583@book{sauro2011practical,
584 publisher = {Measuring Usability LLC},
585 year = {2011},
586 author = {Sauro, Jeff},
587 title = {A practical guide to the system usability scale: Background, benchmarks \& best practices},
588}
589
590@inproceedings{wang2023designing,
591 doi = {10.1145/3544548.3581278},
592 pages = {1--16},
593 booktitle = {Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems},
594 year = {2023},
595 author = {Wang, Qiaosi and Madaio, Michael and Kane, Shaun and Kapania, Shivani and Terry, Michael and Wilcox, Lauren},
596 title = {Designing Responsible AI: Adaptations of UX Practice to Meet Responsible AI Challenges},
597}
598
599@article{wong2023seeing,
600 doi = {10.1145/3579621},
601 pages = {1--27},
602 number = {CSCW1},
603 volume = {7},
604 publisher = {ACM},
605 journal = {Proceedings of the ACM on Human-Computer Interaction},
606 year = {2023},
607 author = {Wong, Richmond Y and Madaio, Michael A and Merrill, Nick},
608 title = {Seeing like a toolkit: How toolkits envision the work of AI ethics},
609}
610
611@article{liao2021human,
612 doi = {10.48550/ARXIV.2110.10790},
613 year = {2021},
614 author = {Liao, Q. Vera and Varshney, Kush R.},
615 title = {{Human-Centered Explainable AI (XAI): From Algorithms to User Experiences}},
616}
617
618@article{gunning2019xai,
619 doi = {10.1126/scirobotics.aay7120},
620 number = {37},
621 volume = {4},
622 journal = {Science Robotics},
623 year = {2019},
624 author = {David Gunning and Mark Stefik and Jaesik Choi and Timothy Miller and Simone Stumpf and Guang-Zhong Yang},
625 title = {{XAI---Explainable artificial intelligence}},
626}
627
628@book{shneiderman2022human,
629 publisher = {Oxford University Press},
630 year = {2022},
631 author = {Shneiderman, Ben},
632 title = {Human-centered AI},
633}
634
635@inproceedings{elsayed2023responsible,
636 doi = {10.1145/3544548.3580771},
637 pages = {1--14},
638 booktitle = {Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems},
639 year = {2023},
640 author = {Elsayed-Ali, Salma and Berger, Sara E and Santana, Vagner Figueredo De and Becerra Sandoval, Juana Catalina},
641 title = {Responsible \& Inclusive Cards: An Online Card Tool to Promote Critical Reflection in Technology Industry Work Practices},
642}
643
644@inproceedings{amershi2019guidelines,
645 doi = {10.1145/3290605.3300233},
646 pages = {1--13},
647 booktitle = {Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems},
648 year = {2019},
649 author = {Amershi, Saleema and Weld, Dan and Vorvoreanu, Mihaela and Fourney, Adam and Nushi, Besmira and Collisson, Penny and Suh, Jina and Iqbal, Shamsi and Bennett, Paul N and Inkpen, Kori and others},
650 title = {Guidelines for human-AI interaction},
651}
652
653@misc{AIBlindspotsV1,
654 howpublished = {\url{https://data-en-maatschappij.ai/en/tools/ai-blindspot}},
655 note = {Accessed: February 2023},
656 year = {2019},
657 author = {{Knowledge Centre Data and Society}},
658 title = {{AI Blindspots Card Set 1.0}},
659}
660
661@misc{AIBlindspotsV2,
662 howpublished = {\url{https://data-en-maatschappij.ai/en/tools/ai-blindspots-2.0}},
663 note = {Accessed: February 2023},
664 year = {2019},
665 author = {{Knowledge Centre Data and Society}},
666 title = {{AI Blindspots Card Set 2,0}},
667}
668
669@article{shen2021everyday,
670 doi = {10.1145/3479577},
671 pages = {1--29},
672 number = {CSCW2},
673 volume = {5},
674 publisher = {ACM},
675 journal = {Proceedings of the ACM on Human-Computer Interaction},
676 year = {2021},
677 author = {Shen, Hong and DeVos, Alicia and Eslami, Motahhare and Holstein, Kenneth},
678 title = {Everyday algorithm auditing: Understanding the power of everyday users in surfacing harmful algorithmic behaviors},
679}
680
681@inproceedings{tahaei2023human,
682 doi = {10.1145/3544549.3583178},
683 pages = {1--4},
684 booktitle = {Extended Abstracts of the 2023 CHI Conference on Human Factors in Computing Systems},
685 year = {2023},
686 author = {Tahaei, Mohammad and Constantinides, Marios and Quercia, Daniele and Kennedy, Sean and Muller, Michael and Stumpf, Simone and Liao, Q Vera and Baeza-Yates, Ricardo and Aroyo, Lora and Holbrook, Jess and others},
687 title = {Human-Centered Responsible Artificial Intelligence: Current \& Future Trends},
688}
689
690@inproceedings{ehsan2020human,
691 organization = {Springer},
692 doi = {10.1007/978-3-030-60117-1_33},
693 pages = {449--466},
694 booktitle = {HCI International 2020-Late Breaking Papers: Multimodality and Intelligence: 22nd HCI International Conference, HCII 2020, Copenhagen, Denmark, July 19--24, 2020, Proceedings 22},
695 year = {2020},
696 author = {Ehsan, Upol and Riedl, Mark O},
697 title = {Human-centered explainable ai: Towards a reflective sociotechnical approach},
698}
699
700@inproceedings{narayanan21fairness,
701 booktitle = {Tutorial presented at the Conf. on Fairness, Accountability, and Transparency},
702 year = {21},
703 author = {Narayanan, Arvind},
704 title = {Fairness definitions and their politics},
705}
706
707@inproceedings{golpayegani2023high,
708 doi = {10.1145/3593013.3594050},
709 pages = {905--915},
710 booktitle = {Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency},
711 year = {2023},
712 author = {Golpayegani, Delaram and Pandit, Harshvardhan J and Lewis, Dave},
713 title = {To Be High-Risk, or Not To Be—Semantic Specifications and Implications of the AI Act’s High-Risk AI Applications and Harmonised Standards},
714}
715
716@article{michie2011strengthening,
717 doi = {https://doi.org/10.1186/1748-5908-6-10},
718 pages = {1--8},
719 number = {1},
720 volume = {6},
721 publisher = {BioMed Central},
722 journal = {Implementation Science},
723 year = {2011},
724 author = {Michie, Susan and Abraham, Charles and Eccles, Martin P and Francis, Jill J and Hardeman, Wendy and Johnston, Marie},
725 title = {Strengthening evaluation and implementation by specifying components of behaviour change interventions: a study protocol},
726}
727
728@article{guest2006many,
729 doi = {10.1177/1525822X05279903},
730 pages = {59--82},
731 number = {1},
732 volume = {18},
733 publisher = {Sage},
734 journal = {Field methods},
735 year = {2006},
736 author = {Guest, Greg and Bunce, Arwen and Johnson, Laura},
737 title = {How many interviews are enough? An experiment with data saturation and variability},
738}
739
740@article{fossey2002understanding,
741 doi = {10.1046/j.1440-1614.2002.01100.x},
742 pages = {717--732},
743 number = {6},
744 volume = {36},
745 publisher = {Sage},
746 journal = {Australian \& New Zealand journal of psychiatry},
747 year = {2002},
748 author = {Fossey, Ellie and Harvey, Carol and McDermott, Fiona and Davidson, Larry},
749 title = {Understanding and evaluating qualitative research},
750}
751
752@article{morley2021initial,
753 doi = {10.1007/978-3-030-81907-1_10},
754 pages = {153--183},
755 publisher = {Springer},
756 journal = {Ethics, governance, and policies in artificial intelligence},
757 year = {2021},
758 author = {Morley, Jessica and Floridi, Luciano and Kinsey, Libby and Elhalal, Anat},
759 title = {From what to how: an initial review of publicly available AI ethics tools, methods and research to translate principles into practices},
760}
761
762@article{stahl2023embedding,
763 doi = {10.1038/s41598-023-34622-w},
764 pages = {7586},
765 number = {1},
766 volume = {13},
767 publisher = {Nature},
768 journal = {Scientific Reports},
769 year = {2023},
770 author = {Stahl, Bernd Carsten},
771 title = {Embedding responsibility in intelligent systems: from AI ethics to responsible AI ecosystems},
772}
773
774@inproceedings{toreini2020relationship,
775 doi = {10.1145/3351095.3372834},
776 pages = {272--283},
777 booktitle = {Proceedings of the 2020 conference on fairness, accountability, and transparency},
778 year = {2020},
779 author = {Toreini, Ehsan and Aitken, Mhairi and Coopamootoo, Kovila and Elliott, Karen and Zelaya, Carlos Gonzalez and Van Moorsel, Aad},
780 title = {The relationship between trust in AI and trustworthy machine learning technologies},
781}
782
783@article{varshney2019trustworthy,
784 doi = {10.1145/3313109},
785 pages = {26--29},
786 number = {3},
787 volume = {25},
788 publisher = {ACM},
789 journal = {XRDS: Crossroads, The ACM Magazine for Students},
790 year = {2019},
791 author = {Varshney, Kush R},
792 title = {Trustworthy machine learning and artificial intelligence},
793}
794
795@inproceedings{knowles2021sanction,
796 doi = {10.1145/3442188.3445890},
797 pages = {262--271},
798 booktitle = {Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency},
799 year = {2021},
800 author = {Knowles, Bran and Richards, John T},
801 title = {The sanction of authority: Promoting public trust in AI},
802}
803
804@article{tahaei2023toward,
805 year = {2023},
806 journal = {arXiv preprint arXiv:2302.05284},
807 author = {Tahaei, Mohammad and Constantinides, Marios and Quercia, Daniele and Muller, Michael},
808 title = {A Systematic Literature Review of Human-Centered, Ethical, and Responsible AI},
809}
810
811@inproceedings{liao2022designing,
812 doi = {10.1145/3531146.3533182},
813 year = {2022},
814 pages = {1257--1268},
815 booktitle = {Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency},
816 author = {Liao, Q Vera and Sundar, S Shyam},
817 title = {Designing for responsible trust in AI systems: A communication perspective},
818}
819
820@article{ackerman2000intellectual,
821 doi = {10.1207/S15327051HCI1523_5},
822 publisher = {Taylor \& Francis},
823 year = {2000},
824 pages = {179--203},
825 number = {2-3},
826 volume = {15},
827 journal = {Human--Computer Interaction},
828 author = {Ackerman, Mark S},
829 title = {The intellectual challenge of CSCW: the gap between social requirements and technical feasibility},
830}
831
832@book{aggarwal2005software,
833 publisher = {New Age International},
834 year = {2005},
835 author = {Aggarwal, KK},
836 title = {Software engineering},
837}
838
839@article{weger2014relative,
840 doi = {10.1080/10904018.2013.813234},
841 publisher = {Taylor \& Francis},
842 year = {2014},
843 pages = {13--31},
844 number = {1},
845 volume = {28},
846 journal = {International Journal of Listening},
847 author = {Weger Jr, Harry and Castle Bell, Gina and Minei, Elizabeth M and Robinson, Melissa C},
848 title = {The relative effectiveness of active listening in initial interactions},
849}Attribution
arXiv:2307.15158v1
[cs.HC]
License: cc-by-4.0


