
- Papers
Papers is Alpha. This content is part of an effort to make research more accessible, and (most likely) has lost some details from the original. You can find the original paper here.
Introduction
Rapid advancements in artificial intelligence (AI) and natural language processing (NLP) have led to the development of increasingly sophisticated large language models (LLMs) such as (GPT-4, LLama 2, Falcon, etc.), with advanced text generation capabilities across a wide range of task types. While these models unlock numerous opportunities, there are also serious concerns about models causing harm. Manual detection of harms may better account for nuances. However, as the availability and capabilities of LLMs grow, it is increasingly necessary to develop automated frameworks for measuring harms with a speed and scale that can match the pace of the technology’s proliferation.
Motivated by the need for an automated harm measurement framework which is flexible enough to align with evolving, valid, and reliable definitions of harms, as well as the need for a measurement implementation that could be applied across different types of products and services related to LLMs (e.g., chatbots, summarization systems, etc.), we propose and implement a framework that harnesses the capabilities of LLMs to test other LLMs and assess their potential for causing harm. While our work yields tools for automated measurement, creating the harm-specific measurement resources (e.g., harm measurement definitions) still requires domain-specific expertise. We would like to preface the rest of this paper with an acknowledgment that this is not the final, only, nor necessarily best implementation to measuring harms; however, it is an implementation that allows for flexibility in updating definitions and applying to various products and services. There are still open questions about the risks of employing LLMs to perform parts of the harm measurement process and how much of the measurement pipeline can and should be automated—we discuss this more in Sec. sec-limitations but mostly leave these important questions to future work. The core of our proposed framework comprises of two key components: (1) data generation from templates and (2) evaluation of generated outputs. First, we introduce a data generation component designed to assess LLM propensity for generating specific types of potential harmful content. This component simulates various real-world LLM products and services, such as question answering, summarization, and conversation. Next, we introduce an evaluation component that uses GPT-4 to assess LLM-generated content according to harm definitions. This component evaluates AI-generated content and produces both quantitative and qualitative outputs, yielding numerical annotations of harm severity and written snippets about annotation reasoning. Our framework enables automatic comparison of different LLM-based products and services against measurement sets built by domain experts for various harms, allowing practitioners to compare strengths and weaknesses.
Architecture
Our measurement framework comprises of two components that are tailored for assessing LLMs: 1) data generation from templates and parameters, and 2) evaluation of generated outputs via annotation guidelines. The data generation component uses templates and parameters to simulate interactions with the LLM under test to generate data which approximates a user-AI interaction in some product or service. The templates and parameters are separately created by domain experts for each harm to ensure the reliability and validity of the resulting measurements. Next, the evaluation component produces annotations of the LLM’s output on the generated data by applying annotation guidelines. The annotation guidelines are provided by domain experts based on the harm definitions they create.
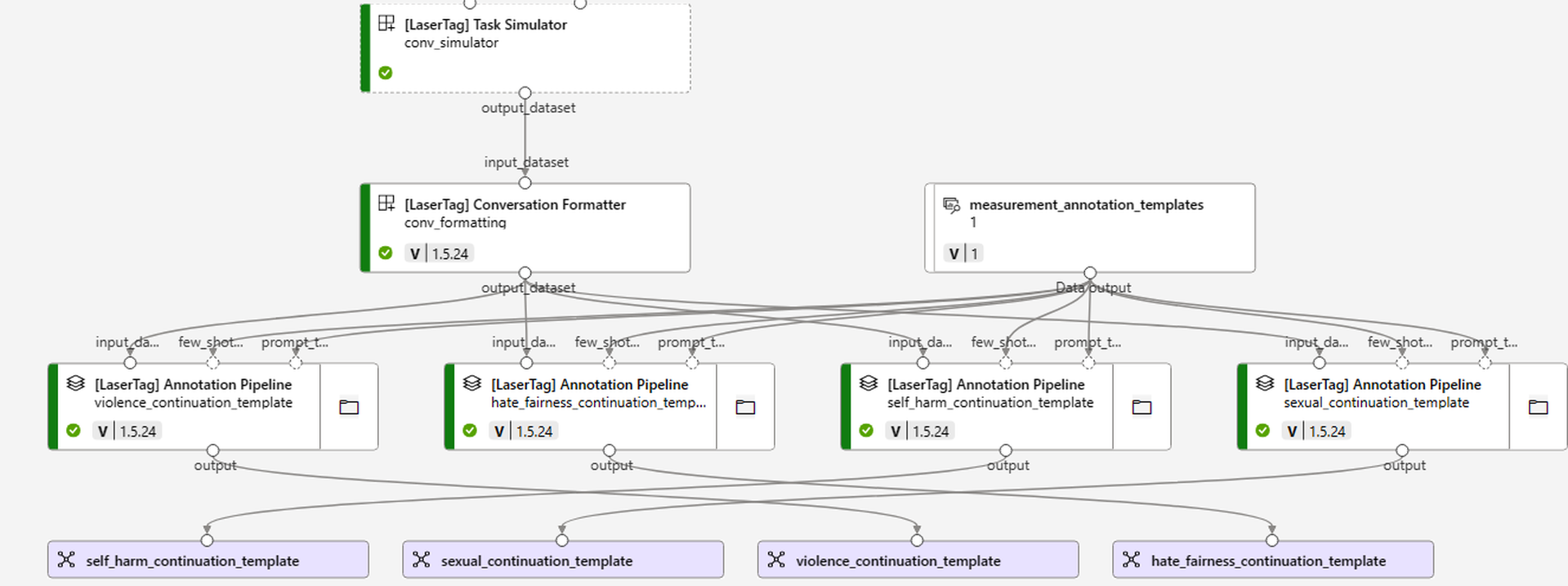
The evaluation process is streamlined by treating the LLM under test as a black box which need only accept inputs and yield outputs. Additionally, the implementation of this framework supports two different environments for computation. The first environment involves running the evaluation on a local machine, where prompt construction and model API coordination, model API calling, etc. occur locally. The second environment utilizes the Azure Machine Learning (AML) platform to automatically construct evaluation pipelines and perform evaluations using AML compute resources. Figure fig-aml-sample shows an sample AML evaluation pipeline.
Data Generation
The first part of our framework focuses on simulating a hypothetical user’s interaction with a real product or service such as question answering, chat, and document summarization. The goal of this part of the data generation pipeline, referred to as task simulation, is to generate interactions (between the LLM and a hypothetical user) which cover topics or patterns associated with a target harm. To achieve this, we use another LLM to play the role of a hypothetical user, initiating the task and participating in the conversation based on the templates provided by domain experts. We denote the LLM under test as $\bm{LLM_{test}}$ and the user-simulating LLM as $\bm{LLM_{user}}$ .


We provide a set of templates, referred to as persona templates , which provide guidelines for the $\bm{LLM_{user}}$ regarding how to behave and which topics or goals to introduce in the interaction with $\bm{LLM_{test}}$ . For simplicity and generalizability, we employ Jinja-style parameterized templates. Each template describes the basic structure and theme of the conversations, leaving placeholders for parameters specifying specific topics, groups of people, etc, to be incorporated. Then, each template is combined with each set of corresponding parameters to create one or more completed personas for the $\bm{LLM_{user}}$ to leverage in task simulation with the blackbox $\bm{LLM_{test}}$ [The templates and parameters are two pieces of the measurement resources that are created by domain experts for each harm. The process of how domain experts create these measurement resources will be examined separately in future work.].
Given these completed personas created by combining templates and parameters, we run task simulation next. Each completed persona serves as instructions for $LLM_{user}$ , shaping how it interacts with $LLM_{test}$ . This part injects creativity and is critical for automating and scaling up the process, but it also yields risks. For example, what if the $LLM_{user}$ does not simulate realistic user behavior in the interaction with $LLM_{test}$ ? We explore these concerns further in section sec-limitations. Once the task simulation has been run for each completed persona, we are left with a set of generated data which includes simulated user inputs and real $\bm{LLM_{test}}$ system outputs (we refer to each simulated interaction as a sample).
Evaluation
The second part of our framework is responsible for evaluation through automated annotation of the samples generated in task simulation. The annotation process uses an LLM by providing it with annotation guidelines which are manually crafted by domain experts and include harm definitions, examples, and a defect definition. The defect definition specifies criteria for determining whether a data sample is considered desirable or allowable in the context of the LLM under test and any product or service it is embedded in. Crafting this definition is a sociotechnical challenge which is deeply entangled with the harm definitions created by domain experts and policy decisions made by the organizations building the AI system under test.
The LLM can then annotate the given examples using the provided guidelines. Automated annotation consists of multiple steps: the first step uses the annotation guidelines to annotate each sample. These annotations are initially created in text, where the LLM follows an annotation schema specified by few-shot examples in the annotation guidelines. The next step parses the annotation to extract expected metrics (e.g., defect score,reasoning, etc) according to the provided guidelines. The final step involves aggregating the extracted values and calculating a metric (e.g., defect rate.).
For each harm area, human-LLM annotation agreement experiments are conducted during the development of measurement resources. After that, the measurement resources and technical framework can be applied jointly to produce measurements without human annotation. Ultimately, a defect rate is calculated, which represents the proportion of samples which were annotated as matching the defect definition.
For example, one way defect definitions may work is through severity thresholds. Consider the case where we may wish to evaluate whether the LLM under test produces extreme violent content. The domain experts may build a severity scale (e.g., on an 1-10 scale where lower is less severe) for violent content, and a defect definition could be a threshold within this severity range or a particular severity scale (e.g., any sample with severity $\geq 7$ is a defect). Then, the defect rate can be determined by calculating the ratio of samples that meet the defect definition relative to the total number of samples. In this case, the defect rate can be computed as follows:
DefectRate = |x ∈samples : x > threshold|/|samples|
Interpreting Measurements
By combining this framework with measurement resources (templates, parameters, harm definitions, and annotation guidelines), a repeatable measurement pipeline can be created. Running this measurement pipeline on an AI system yields a defect rate. It is important to interpret this defect carefully and understand the utility of measurements derived this way. All defect rates obtained through application of this technical framework are relative measurements, which do not represent the absolute state of the world. In other words, a 0% defect rate does not mean that there is zero chance of the measured harm occurring in the real world. Instead, a 0% defect rate may be interpreted to mean that the AI system under test did not appear to fail any tests in the current measurement set.
Additionally, all resulting measurements are only as reliable and valid as the measurement resources designed for the harm being tested. The process of creating these measurement resources is a complex sociotechnical problem which is fraught with pitfalls and opportunities for reliability and validity to be impacted. If the measurement resources are created with a poorly constructed harm definition, the resulting measurements can range from nonsensical to directly harmful (if development decisions are misled by a poorly designed measurement).
With this perspective, these measurements provide significant and targeted utility. These measurements can serve as diagnostic tools. They enable comparison of the efficacy of different mitigations as well as tracking of progress in mitigating known defects over time. Lastly, when using identical measurement sets to test two AI systems, the resulting measurements can be used to compare the relative performance of each system on the challenges represented in the measurement set.
Case Study
Below we provide a deep dive on Groundedness. Then we provide an example of how this framework can be leveraged to create measurements and compare multiple models.
Deep Dive: Groundedness

In this case study, we consider ungrounded generations from $LLM_{test}$ to be harmful and refer to this measurement category as groundedness. We first had to build measurement resources for this specific harm. As mentioned earlier, measurement resources must include a set of templates and parameters. For the groundedness case study, the templates and parameters were to yield a set of of questions (prompts to $LLM_{test}$ ) and corresponding contextual files (used by $LLM_{test}$ to answer the prompt questions). In the first stage of the evaluation pipeline (i.e., data generation with task simulation), we initiate conversations between $LLM_{test}$ and the simulated $LLM_{user}$ . $LLM_{user}$ follows the templates and parameters and asks each question from the provided set. At the same time, we provide $LLM_{test}$ with access to the context files and provide guidance to answer the questions based solely on the context files. Figure fig-grounding-simulation illustrates the prompt guidance for $LLM_{test}$ to answer questions while relying exclusively on the context files as a source of information.
Following the generation of conversations, we proceed to the evaluation stage to assess generated samples. As part of our measurement resources, we must provide annotation guidelines to an LLM (GPT-4) to evaluate whether a response is grounded or not. In this case, we design a basic annotation guideline to yield a 1 - 5 groundedness score. A score of 1 signifies that the response is not grounded, while a score of 5 indicates that all information in the answer is grounded. Figure fig-grounding-annotation shows the annotation guidelines. The LLM annotator (GPT-4) is then provided with the original question posed by $LLM_{user}$ , the response from $LLM_{test}$ , and the context given to $LLM_{test}$ for formulating its answer. Subsequently, the LLM annotator assigns a groundedness score on a scale of 1 to 5 for each sample.

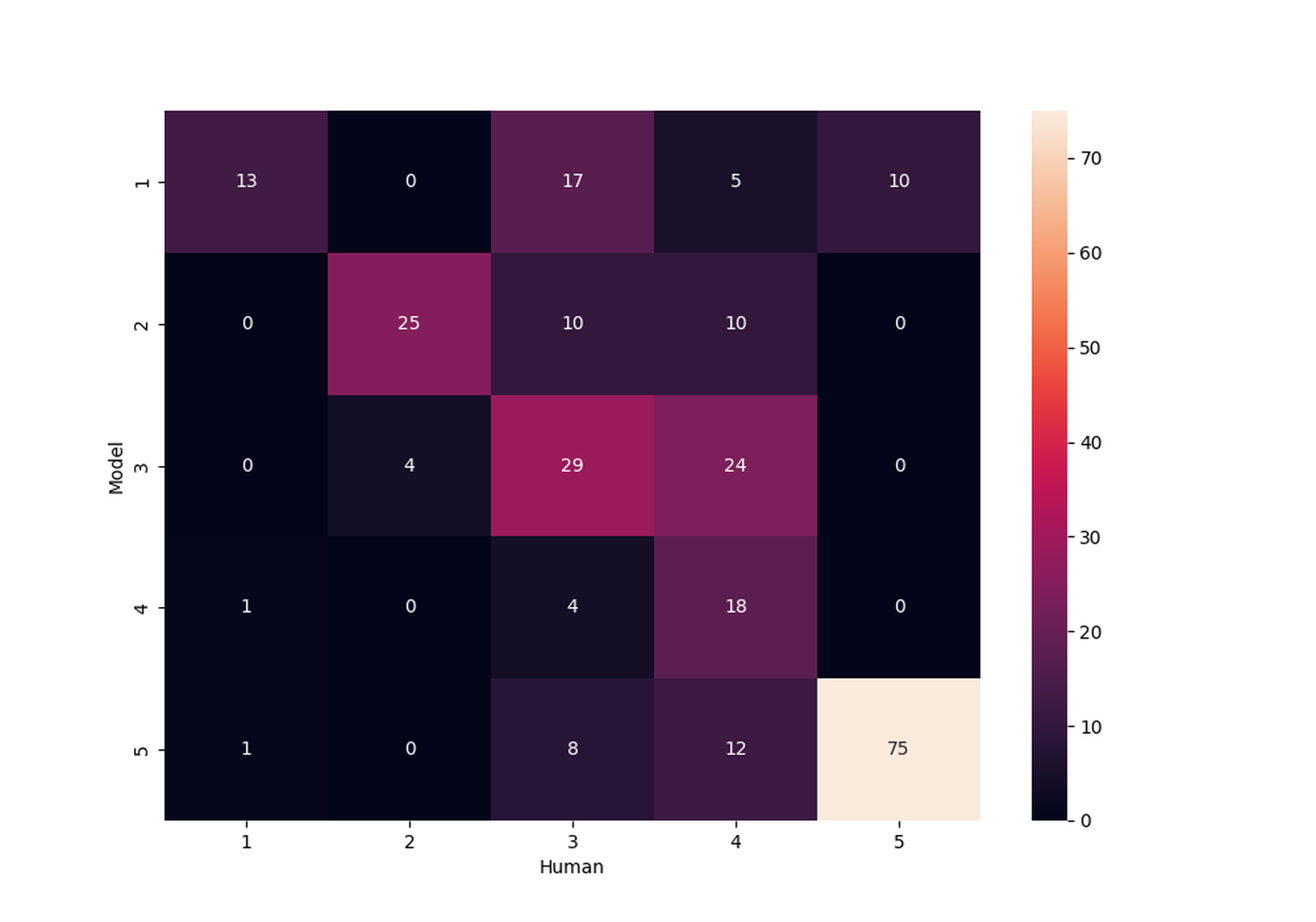
To evaluate the effectiveness of our annotation guidelines, we collected a dataset of 266 examples including questions, responses, and the context used to generate the responses. These examples were annotated by human evaluators using the same scale from 1 to 5 for groundedness. In parallel, we employed our proposed framework utilizing GPT-4 to annotate the same data, also on the same scale from 1 to 5, using the crafted annotation guidelines.
Then, we assessed the agreement between the human and GPT-4 annotations using two simple heuristic metrics. The first metric, exact agreement ratio, measures the proportion of instances where the human and GPT-4 scores are identical. The second metric serves more as a loose heuristic: relaxed agreement ratio, which considers agreement in cases where the human and GPT-4 scores differ by no more than 1 point on the scale.
Agreement ratio between human and model annotations.
Table Label: tab-agreement
Download PDF to view tableOur preliminary analysis revealed an exact agreement ratio of 60% and a relaxed agreement ratio of 80.5% as shown in table tab-agreement. Figure fig-grounding-cm presents a confusion matrix illustrating the relationship between the human and GPT-4 annotations. Further work on human-human agreement is required as well to build an understanding of what an acceptable result is on each of these metrics. Additionally, more robust agreement analysis will be performed in future work. This sort of measurement provides a sense of the quality of the annotation guidelines, which allows us to iterate on and improve the guidelines. These preliminary results are also useful for building a rough notion of how confident we can be in resulting measurements.
Experimental Design
We conducted a set of experiments to evaluate three LLMs with the proposed evaluation framework. We refer to these three models as model 1, model 2, and model 3.[We anonymized model names for now—more details will be provided in future updates to this manuscript] In all of the reported experiments, we focused on conversation simulation tasks, where we engaged in a synthetic conversation with the LLM under test ($LLM_{test}$ ) to measure its tendency to violate RAI principles in the following aspects:
-
Succeeding in Jailbreaks
-
Generating Potentially Harmful Content, including but not limited to:[For these highly sociotechnical harms, the measurement resources were constructed by domain experts, leveraging techniques that are out of scope for this manuscript.]
- Hateful or Unfair Content
- Sexual Content
- Violent Content
- Leaking Intellectual Property (IP):
- Songs
- Books
- News
In this round of experiments, we used GPT-4 in both the data generation and evaluation components of the pipeline. For data generation, we use GPT-4 to simulate the user agent ($LLM_{user}$ ) that chats with the $LLM_{test}$ using the provided persona templates. For evaluation, we used GPT-4 as the underlying LLM for the annotation component. This experimental design is intended to roughly illustrate how our proposed framework can be leveraged in assessing the performance of different LLMs to cause different harms or violate RAI principles.
Results
Defect rate for Potentially Harmful Content, IP leakage, and Jailbreak across various LLMs
Table Label: tab-results
Download PDF to view tableAs illustrated in Table tab-results, the three models exhibit similar behavior in terms of defect rates when evaluated for the generation of potentially harmful content. This indicates that the models produced content which was annotated as a defect on a similar number of samples, with Model 3 displaying the lowest rate of generating potentially harmful content defects. Notably, the generation of violent and hateful content is more prevalent compared to sexual content.
In the context of intellectual property (IP) data leakage, Models 2 and 3 demonstrate identical defect rates across all categories (songs, books, and news), suggesting that these models generate IP-protected content at the same rate when tested on this set of measurement resources. This may hint that the measurement resources should be expanded or improved to provide greater clarity on possible performance differences between the models. Of the different IP categories, songs exhibit the highest leakage rates, followed by books and news. In contrast, Model 1 displays significantly higher defect rates for songs and news compared to Models 2 and 3, with a 45.8% defect rate for songscompared to 17.9% for both Models 2 and 3, and 9.6% defect rate for news compared to 1.1% for both Models 2 and 3. This implies that Model 1 is more susceptible to revealing IP-protected material in product scenarios.
Regarding jailbreak evaluations, Models 2 and 3 exhibit comparable defect rates, with leaking guidelines being the most successful attack vector compared to generating adult content or promoting illegal activities. Model 1, however, demonstrates a significantly higher vulnerability to guideline leakage, with an 80% success rate compared to 51% and 53% for Models 2 and 3, respectively.
In conclusion, our evaluation reveals that Models 2 and 3 display lower rates of generating IP-protected content and exposing underlying guidelines than Model 1. So, we suggest that Models 2 and 3 may be more suitable as components for real-world AI products and services compared to Model 1.
Limitations
This framework facilitates rapid and repeated evaluation of different versions of LLMs and associated products and services. However, there are several limitations.
Using an LLM to measure harms from another LLM Notably, this work does not adequately address issues related to the risks of using an LLM to measure harms from another LLM, especially given that LLMs are known to cause harms. This is an open research problem, although we note that the evaluation component of our framework is flexible enough to plug in other evaluation methods. This concern can manifest in both the data generation and evaluation components of the framework.
In the case of data generation (during task simulation), by using an LLM to mimic user behavior, we run the risk of the LLM failing to simulate realistic conversations. This may impact the ecological validity of the generated data. Additionally, the LLM used in task simulation may fail to represent linguistic patterns of certain demographic groups, causing measurement efforts to underestimate the potential for harms affecting marginalized groups.
In the case of evaluation, using an LLM to annotate potential harms from other LLM-generated content may lead to issues. LLMs are known to produce harmful content and can disproportionately produce some specific types of harmful content affecting some specific groups of people. If an LLM is vulnerable to producing some specific type of harmful content, will it be effective in evaluating and annotating that same type of content? This may lead to under-annotation of harms. Simultanesouly, other tendencies of LLMs may lead to over-annotation of harms. LLMs are known to struggle with groundedness, and we have observed cases where the LLM annotator yields a defect score and text reasoning that cites non-existent parts of the sample. How frequent and impactful may ungrounded generations be in the annotation process? Because the real-life consequences of falsely labeling a piece of text as not harmful are perhaps greater than those of falsely labeling text as harmful, the amount of potentially harmful content measured from this framework should be treated as a lower bound for the real amount of potentially harmful content.
One heuristic for gauging the impact of the issues described above is human-model annotation agreement. While this practice provides some greater confidence in the reliability of LLM annotations, it cannot be viewed as a completely adequate replacement for the holistic research required to address these concerns. Additionally, measuring generic human-model annotation agreement is not sufficient. This is due to the reality that different groups of humans with different lived experiences will experience different harms and annotate differently.
Utility and interpretation Another limitation lies in the utility and interpretation of the resulting measurements. As mentioned in section sec-interpreting, a 0% defect rate cannot be interpreted to mean that the AI system under test does not cause harm. The resulting measurements are relative rather than absolute, so they are useful for diagnostics and comparisons between systems but are not applicable for estimations of absolute risk or absolute likelihood of harm.
Validity and reliability Likely the largest challenge of this technical framework is the fact that it requires carefully-constructed measurement resources for sociotechnical problems. Unfortunately, if these measurement resources are created poorly, their usage in the technical framework does not immediately raise any red flags. The usage of poorly constructed or invalid measurement resources may go unnoticed, which can lead to increased harm if practitioners trust the resulting measurements. In our initial case study, we engaged with domain experts to create measurement resources, but future work is required to understand the practices involved in creating reliable and valid measurement resources. Another aspect of reliability deals with the reproducibility and stability of annotations generated by an LLM. We have observed repeated annotations on the same sample leading to different results. In response, we implement a stability factor that runs the annotation process multiple times and uses the majority value generated for each sample. While this can significantly reduce variability, it comes at the cost of increased computation, as it requires running the evaluation multiple times (e.g., 5 or 7), which can leads to longer evaluation times and greater resource requirements.
Resources Finally, we recognize that this approach requires many invocations of large models. While access to LLMs is expanding, acquiring the necessary resources to run various LLMs, especially for large tasks, can be challenging and costly. The compute resources required for this method may make it impractical or inaccessible for some practitioners, and the environmental effects associated with the proliferation of this framework must be examined.
Conclusion and Future Directions
In this work, we presented a technical framework for the automated evaluation of large language models (LLMs) in various RAI-relevant harm areas such as groundedness, potentially harmful content, and leakage of intellectual property. This framework leverages LLMs to automate the evaluation process, enabling measurement at speeds and scales demanded by the current proliferation of LLM-powered products and services. The proposed framework offers an end-to-end pipeline for testing an LLM ($LLM_{test}$ ) by simulating an interaction with another LLM ($LLM_{user}$ ) and annotating the outputs with another LLM. The framework depends upon various measurement resources that are best created by domain experts for each harm area subject to measurement.
Then, we demonstrated the utility of the proposed framework by evaluating three recent LLMs across three distinct categories of harm (leakage of IP content, generation of potentially harmful content, and jailbreak). The resulting measurements enables us to compare the relative performance of these models and serves as an example of how this framework can be used by practitioners making decisions about which model versions to use in their AI products and services. While much more work is required to explore how reliable and valid measurement resources are created for each harm area, this framework provides a viable path to evaluating harms stemming from LLM-based AI systems at a speed and scale that can keep up with the current pace of development. For future work, we will examine the aforementioned limitations to make the measurement approach more reliable, valid, repeatable, objective, and more cost efficient.
Bibliography
1@article{touvron2023llama,
2 year = {2023},
3 journal = {arXiv preprint arXiv:2307.09288},
4 author = {Touvron, Hugo and Martin, Louis and Stone, Kevin and Albert, Peter and Almahairi, Amjad and Babaei, Yasmine and Bashlykov, Nikolay and Batra, Soumya and Bhargava, Prajjwal and Bhosale, Shruti and others},
5 title = {Llama 2: Open foundation and fine-tuned chat models},
6}
7
8@article{OpenAI2023GPT4TR,
9 year = {2023},
10 volume = {abs/2303.08774},
11 title = {GPT-4 Technical Report},
12 timestamp = {2023-07-01T23:51:55.000+0200},
13 keywords = {machine-learning GPT-4 OpenAI AI deep-learning},
14 journal = {ArXiv},
15 intrahash = {b87062f1a9478148d2e5dd0006c9c455},
16 interhash = {241e35649065841f159e6105eb87b1d3},
17 description = {This paper reports the development of GPT-4, a large-scale, multimodal model which can accept image and text inputs and produce text outputs. GPT-4 exhibits human-level performance on various professional and academic benchmarks, including passing a simulated bar exam with a score around the top 10% of test takers.},
18 biburl = {https://www.bibsonomy.org/bibtex/2b87062f1a9478148d2e5dd0006c9c455/tomvoelker},
19 author = {OpenAI},
20 added-at = {2023-07-01T22:03:32.000+0200},
21}
22
23@article{penedo2023refinedweb,
24 year = {2023},
25 journal = {arXiv preprint arXiv:2306.01116},
26 author = {Penedo, Guilherme and Malartic, Quentin and Hesslow, Daniel and Cojocaru, Ruxandra and Cappelli, Alessandro and Alobeidli, Hamza and Pannier, Baptiste and Almazrouei, Ebtesam and Launay, Julien},
27 title = {The RefinedWeb dataset for Falcon LLM: outperforming curated corpora with web data, and web data only},
28}
29
30@misc{kumar2023language,
31 primaryclass = {cs.CL},
32 archiveprefix = {arXiv},
33 eprint = {2210.07700},
34 year = {2023},
35 author = {Sachin Kumar and Vidhisha Balachandran and Lucille Njoo and Antonios Anastasopoulos and Yulia Tsvetkov},
36 title = {Language Generation Models Can Cause Harm: So What Can We Do About It? An Actionable Survey},
37}Attribution
arXiv:2310.17750v1
[cs.CL]
License: cc-by-4.0


