
- By Justin Riddiough
- December 10, 2023
Open Weights and Parameters in Open Source AI
The terms “weights” and “parameters” hold the key to the magic behind intelligent systems.
OSS Capital is working towards a standarized definition of open-weights: Read more about it here
The Basics:
1. What are Weights?
- In an AI model, weights are the numerical values assigned to the connections between neurons in a neural network. Think of them as the strengths of these connections, determining how much influence one neuron has on another.
Example: In image recognition, a weight might signify the importance of a specific pixel in identifying a particular feature, like the edges of an object.
- Weights Illustrated
- Code Example
Understanding Weights: The Secret Sauce of Neural Networks
Imagine you’re trying to predict house prices based on features like size and location. In the world of artificial intelligence, a special tool called a neural network can be trained to do just that! But how does this network learn to make accurate predictions? Here’s where a crucial concept comes in: weights.
Think of weights as dials on a mixing board. In a neural network, these dials adjust the influence of different pieces of information (like house size and location) when making a prediction (like the price). By adjusting these weights during training, the network learns which features are more important for accurate predictions.
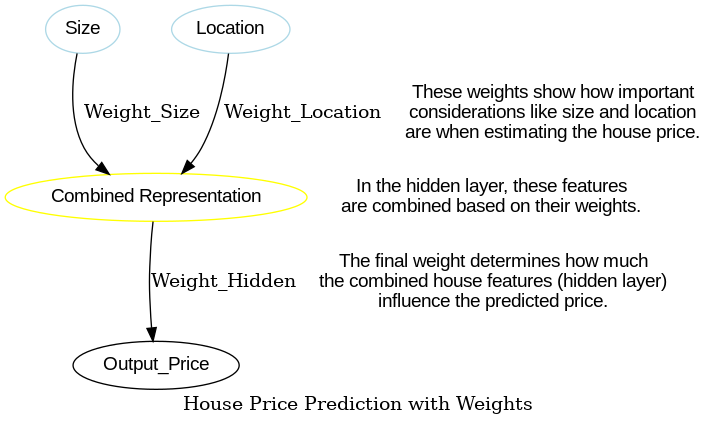
import torch.nn as nn
# Imagine we're building a system to predict house prices based on features
# like size (square footage) and location (distance to city center).
class PricePredictor(nn.Module):
def __init__(self, num_features, hidden_size, output_size):
super(PricePredictor, self).__init__()
# The first layer takes various features (like size and location)
# and combines them with weights to create a hidden representation.
# Imagine this like a brainstorming session where different aspects
# of the house are considered. The weights determine how much emphasis
# is placed on each feature.
self.hidden_layer = nn.Linear(num_features, hidden_size)
def forward(self, features):
# The features are like individual pieces of information about the house.
# We pass them through the hidden layer, where they are transformed
# based on the weights we assigned earlier.
hidden_representation = self.hidden_layer(features)
# Now, imagine we have a realtor with experience. They take the
# combined information from the hidden layer (like the overall impression
# of the house) and use their knowledge (encoded in another weight)
# to estimate the final price.
output_price = nn.Linear(hidden_size, output_size)(hidden_representation)
return output_price
# Example usage (assuming features is a tensor containing house data)
model = PricePredictor(2, 4, 1) # 2 features (e.g., size, location), 4 hidden units, 1 output (price)
predicted_price = model(features)
# During training, the weights are adjusted to improve the model's accuracy
# in predicting house prices.
2. Understanding Parameters:
- Parameters, on the other hand, encompass a broader category. They include weights but extend to other factors like biases and learning rates. Parameters fine-tune the behavior of the model during training, making it adaptable to diverse datasets.
Example: Biases in parameters allow the model to account for factors that might not be explicitly present in the training data, enhancing its ability to generalize.
Why Do They Matter?
1. Learning from Data:
- Weights play a crucial role in learning from data. During training, the model adjusts these weights to minimize the difference between predicted and actual outcomes, optimizing its ability to make accurate predictions.
Example: In a language model, weights adjust to assign probabilities to different words, improving the accuracy of predicting the next word in a sentence.
2. Adaptability and Generalization:
- Parameters contribute to the adaptability and generalization of AI models. By adjusting weights and other parameters, the model learns not only from specific examples but also generalizes patterns, enhancing its performance on unseen data.
Example: A self-driving car model adjusts parameters to recognize and adapt to various road conditions, ensuring safe navigation.
The Significance in Open Source AI:
1. Transparency and Collaboration:
- In the spirit of open-source AI, sharing weights and parameters is akin to revealing the recipe of a successful dish. Transparency in these model details encourages collaboration, allowing developers worldwide to understand, improve, and build upon existing models.
Example: Sharing the weights of a sentiment analysis model allows others to scrutinize and enhance its accuracy for diverse cultural contexts.
2. Reproducibility and Benchmarking:
- Openly sharing weights and parameters facilitates reproducibility in AI experiments. Researchers can replicate and benchmark models consistently, fostering a culture of rigorous evaluation and continuous improvement.
Example: A researcher shares the parameters of a machine translation model, enabling others to reproduce and compare its performance with alternative translation models.
An Analogy:
Imagine weights as the brushstrokes of an artist and parameters as the palette of colors. The artist (AI model) learns to create a masterpiece (make predictions) by adjusting the brushstrokes (weights) and experimenting with different colors (parameters).
Think of parameters as the artist’s toolkit besides the weights (brushstrokes). They include things like biases (adjusting the starting point) and learning rate (how quickly the artist learns). These elements fine-tune the model’s behavior during training, making it adaptable to diverse datasets.
In open-source AI, understanding and sharing these intricate details empower the community to create more intelligent, transparent, and collaborative AI solutions.


